This document’s aim is to present an overview of Scior, also describing its structure and functioning mechanism. Besides the objectives and scope of Scior, we present in this document information regarding the execution and functioning of the software divided into three sections: input, execution, and output.
Please refer to this repository’s main documentation file for instructions about the installation or execution of Scior.
The quality of an information system directly depends on how truthful its information structures are and that we can only achieve such truthfulness with the support of highly expressive ontologies [ref]. Contrary to reference ontologies, which are build with ontologically well-founded languages and that aim to provide such high expressiveness, lightweight ontologies like OWL knowledge graphs are not focused on representation adequacy but are designed with the focus on guaranteeing desirable computational properties, such as computational tractability and decidability [ref].
We propose Scior to increase the semantics of OWL ontologies by classifying their represented domain concepts into foundational ontology concepts–to be more specific, into gUFO ontological categories. Considering that gUFO is “a lightweight implementation of the Unified Foundational Ontology (UFO) suitable for Semantic Web OWL 2 DL applications”, Scior can rely on almost two decades of development of UFO to achieve its objectives.
In its website, gUFO states that one of its key features is that “it includes two taxonomies: one with classes whose instances are individuals (…) and another with classes whose instances are types (…)”. The current version of Scior is limited to a subset of the second hierarchy, the hierarchy of types, as it handles only Endurant Types. I.e., Scior can classify OWL classes into subclasses of the gufo:EndurantType class.
The authors of gUFO document that its usage form is “by specializing and instantiating its elements. Reuse of gUFO consists in instantiating and/or specializing the various classes, object properties and data properties defined in the ontology, inheriting from it the domain-independent distinctions of UFO”. As dealing only with the hierarchy of types, all classifications performed by Scior are formalized with a rdf:type property between the domain class and its identified gUFO type. This strategy is aligned gUFO’s strategy to employ “OWL 2 punning, when a class is also treated as an instance of another class (in this case, :Person rdf:type gufo:Kind and, as defined in gUFO, gufo:Kind rdf:type owl:Class)”. Considering the use of RDF’s instantiation property only, the current implementation of Scior does not address multi-level modeling.
By deciding that the first release of Scior will comprise only Endurant Types, we are addressing two ontological meta-properties of entities: sortality (related to the identity principle the entity may provide or carry) and rigidity, excluding only a third meta-property that is directly associated to the hierarchy of individuals, the ontological nature.
Another scope limitation is that Scior does not handle ontology entities different from owl:Class, rdfs:subClassOf, and rdf:type. I.e., only taxonomical relations are considered. Scior does not consider other properties as object properties and data properties in its current version. However, restricting the number of allowed ontology entities has the benefit of reducing the software’s execution time.
Finally, it is important to register that we aim to evolve the software’s scope is future versions, especially regarding the inclusion of (i) the identification of the ontological nature of entities (i.e., gUFO’s hierarchy of individuals), ( ii) gufo:EventType and gufo:SituationType, (iii) properties different from taxonomical relations (e.g., relational properties, relations, and attributes), and (iv) multi-level modeling.
To define a clear scope for Scior, we defined premises that guided the software development:
- Scior cannot create new classes during its execution.
- Scior assumes that all classes are different from each other.
- Scior only assigns positive or negative classifications to classes. It does not assign equality or difference classifications between classes.
- Scior cannot reclassify classes. I.e., the software can only set types still not (positively or negatively) attributed to a class.
- Interaction is only be available when more than one option is available.
The input ontology file is the only mandatory input for Scior. This file must contain an rdf-based model, which is the ontology to be semantically improved during the software’s execution.
In the current version of Scior, the input file must have at least one class with a gUFO classification so that the software can infer another knowledge from it. I.e., if a user provides as input an ontology with no statement relating one of the ontology’s classes with a gUFO endurant type classification via a rdf:type property, the software will not perform any inference.
As stated in the previous section, Scior performs its inferences reasoning over (the existence or absence of) specialization and instantiation properties (rdfs:subClassOf and rdf:type, respectively), consequently Scior is more likely to infer new knowledge in input models with large taxonomies than in input models with isolated classes.
Please refer to the respective documentation for detailed information about the Scior’s arguments and configurations.
Scior uses three graphs that receive the following names: original graph, working graph, and gUFO graph.
The original graph is the complete input ontology loaded into an RDF Graph using the RDFLib parse function. Scior keeps the original graph in memory because, by the end of its execution, this graph is going to be added with the identified gUFO classifications to be saved as the execution’s output.
Scior, however, has a limited scope and it does not need all the information contained in the original graph for its execution. Using the software over all the RDF statements in the original graph would be more time and resource costly than reducing the graph to another one that contains only the necessary information to perform Scior. Hence, Scior creates a second graph and names it working graph.
The working graph contains only the following RDF statements from the original ontology file: rdf:type and rdfs:subClassOf, which are the predicates needed for manipulating the input’s taxonomical information. The working graph is the one in which Scior is going to perform its implemented rules.
Lastly, Scior loads a reduced version of gUFO containing only Endurant Types into a new graph called gUFO graph. The loaded resource is named gufoEndurantsOnly.ttl and can be found within Scior’s resource folder. This graph is later merged with the working graph and used only for simplifying the acquisition of known gUFO information from the input ontology. If the user has set the argument for saving the gUFO ontology in the generated output file, then Scior uses the gUFO graph for this purpose.
From the working graph, we extract all classes from the ontology and create a data structure–here called OntologyDataClass–for each class with the following fields:
uri: the URI of the class.is_type: Known gUFO classifications that the class has. gUFO classifications that were positively asserted to the class.can_type: Unknown gUFO classifications. Classifications that may be positively or negatively asserted to the class.not_type: Known gUFO classifications that the class does not have. gUFO classifications that were negatively asserted to the class.
During their initialization, all individual dataclasses are inserted into a list named ontology_dataclass_list.
Scior has a specific operation for asserting a gUFO classification to a class. This classification happens at the moment in which one of the implemented rules identifies a new classification for one of the dataclasses in the ontology_dataclass_list.
Once identified as being of a certain type, Scior moves the gUFO classification from this class’s can_type list to its is_type list (for a positive classification) or to its not_type list (for a negative classification). After every classification movement between lists, the inferencing method and consistency evaluation are performed.
Note that, according to the Scior’s premises, classes cannot be reclassified. Hence, moving elements from the is_type list or from the not_type list is never an allowed operation. The absence of a necessary classification in the can_type list configures an inconsistency.
The gUFO categories (i.e., its classes) are available in a hierarchical structure, having restrictions (e.g., completeness and disjointness axioms) between them.
As an example, categorizing a given class as a gufo:Kind also demands us to categorize it as a gufo:Sortal, because gufo:Kinds are subclasses of gufo:Sortals in the gUFO hierarchy of classes. In addition, the class gufo:Sortal is disjoint with the class gufo:NonSortal, meaning that the same class can also be classified as not a gufo:NonSortal and as not a gufo:Role. Each asserted knowledge can cause multiple knowledge to be inferred from it. The most common way to calculate this inferred knowledge is using reasoning engines or reasoners, for short.
Reasoners, and in special OWL Reasoners usually implement various capabilities, performing multiple calculations like type inheritance, transitivity, reflexivity, inconsistency detection, etc. The more complex the ontology is, the more time the reasoner is going to need to complete all its calculations. Reasoning over a whole knowledge graph is usually a time-consuming task.
Scior has a structure that allows us to skip performing a complete reasoning task over the ontology being evaluated. First, because of its restricted scope, where only a few ontology entities are considered, just a small set of inferences is necessary. E.g., as it does not use object properties for the identification of ontological categories, it is unnecessary to perform any type of inference over them.
Intending to ensure data consistency, Scior performs consistency evaluations before and after its execution. The following consistency verifications are performed:
- Verification of possible invalid strings in all lists of an OntologyDataClass.
- Verification of the number of classifications found in each OntologyDataClass list.
- Verification of duplicates in each of its internal lists (
is_type,can_type, andnot_type), guaranteeing that the same classification is never in two lists at the same time. - Verification of multiple final classifications, guaranteeing that two final classifications (gUFO leaf classes) cannot be in the
is_typelist together.
The consistency validation is represented in the first flowchart displayed in this document’s next section.
The diagram below shows an overview about how Scior performs its implemented rules.

As previously pointed out, Scior performs validations before and after the rules’ executions. The rules from the Base Group are performed only once, while all others are treated inside the Loop Rules’ Groups activity, which we are going to decompose later, explaining each step of the execution process. Regarding individual rules, we provide a complete description of each one in a specific documentation.
The hashing is an important part of the rules’ execution process, as its resulting value is used to verify if the rules performed modifications on the processed data. As presented in the image at the beginning of this section, Scior executes the rules in loops until there is no more information to be discovered–i.e., up to when the output hash is the same as the input hash.
The data structure Scior uses for creating the hash is the ontology_dataclass_list. As this data structure contains all information that has been analyzed, its hash allows us to identify any modification that the rules may cause to the data.
For creating this hash value, we concatenate the values of attributes of all its composing OntologyDataClasses (i.e., the strings of their uri, is_type, can_type, and not_type lists).
The image below details the rules’ execution process, representing the existent loop of execution.
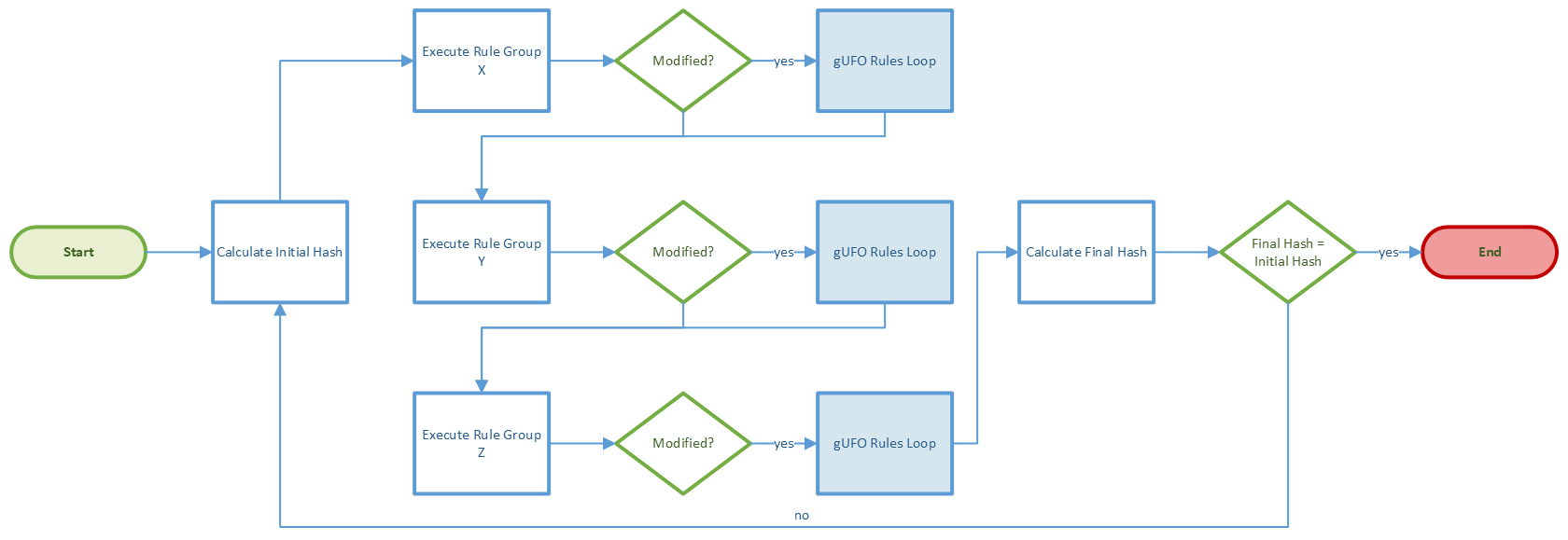
Two execution loops are used to guarantee that all possible classifications can be done. The image above presents the first of these loops, concerning the following groups of rules: Auxiliary, All, Unique, Some, CWA (this last one only when executed in closed-world assumption).
Before entering the execution loop, an initial hash is calculated for the entire list of OntologyDataClasses. The rules from these groups are going to be executed sequentially and, by the end of the executions, a final hash will be created and compared to the initial one. If their values differ from each other, it means that modifications were made, and that it is necessary to restart the loop. If the values match, the process is over.
If a classification is performed during the execution of any rule, a specific loop is invoked, the gUFO Rules Loop (note that this sub-process was simplified in the flowchart to facilitate the overall process visualization). In this loop, the rules from the groups gUFO Positive, gUFO Negative, and gUFO Leaves are performed in a loop similar to the one represented in the flowchart above. This guarantees that all basic gUFO structure is respected and that the other rules will evaluate updated data.