
The goal of the TidyTuesdayAltText R data package is to provide insight into the
alternative (alt) text accompanying the data visualizations shared on
Twitter as part of the TidyTuesday social project.1
You can install the development version of TidyTuesdayAltText from
GitHub with:
# install.packages("devtools")
devtools::install_github("spcanelon/TidyTuesdayAltText")The package contains 5 datasets:
library(TidyTuesdayAltText)
?ttTweets2018
?ttTweets2019
?ttTweets2020
?ttTweets2021
?AltTextSubsetOriginal data were collected and made available by Tom Mock (@thomas_mock) using {rtweet}.
Tweets were processed and scraped for alternative text by Silvia Canelón (@spcanelon)
- Data were filtered to remove tweets without attached media (e.g. images)
- Data were supplemented with reply tweets collected using {rtweet}. This was done to identify whether the original tweet or a reply tweet contained an external link (e.g. data source, repository with source code)
- Alternative (alt) text was scraped from tweet images using {RSelenium}. The first image attached to each tweet was considered the primary image and only the primary image from each tweet was scraped for alternative text. The following attributes were used to build the scraper:
- CSS selector:
.css-1dbjc4n.r-1p0dtai.r-1mlwlqe.r-1d2f490.r-11wrixw - Element attribute:
aria-label
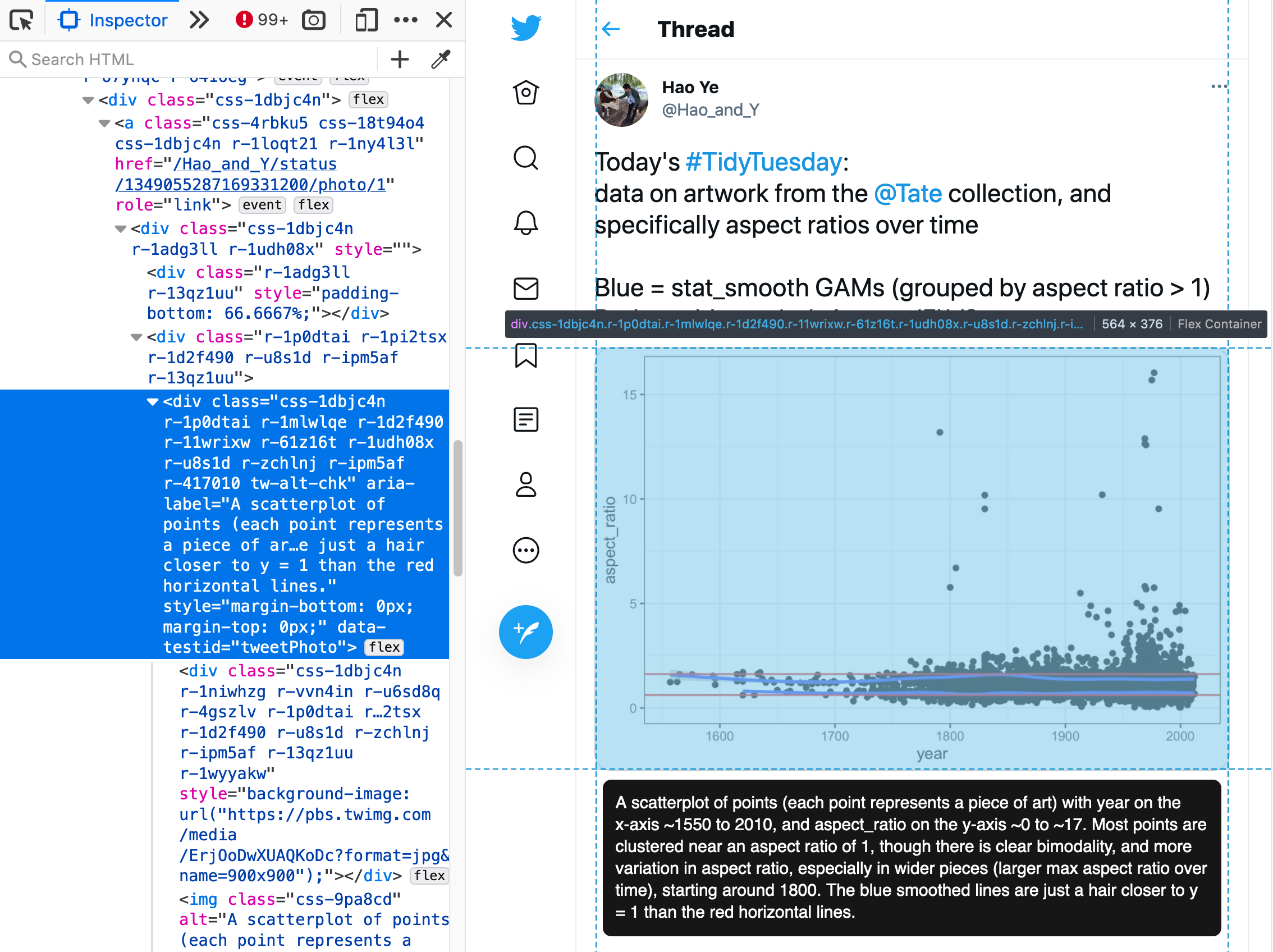
Example of web inspection being used to identify the CSS selector utilized for alt-text web scraping
This data package does not include data that could directly identify the tweet author in order to respect any author’s decision to delete a tweet or make their account private after the data was originally collected.2
To obtain the tweet text, author screen name, and many other tweet
attributes, you can “rehydrate” the TweetIds (or “status” ids3)
using the {rtweet} package.4
A dataset containing the alternative text for media shared between 2018
and 2021 as part of the TidyTuesday social project, and other attributes
of 441 tweets. This is a subset of the 2018-2021 datasets, containing
only tweets with alternative text that isn’t “Image,” the default
alternative text added by the Twitter app in the absence of customized
alternative text. More information can be found using ?AltTextSubset.
- Dates included: April 10, 2018 to April 4, 2021.
- Observations (rows): There are 465 rows in this dataset. Each row represents a single unique tweet post.
- Variables (columns): There are 7 columns in this dataset. They are described below
| variable | data_type | description |
|---|---|---|
| TweetId | character | <chr> Unique tweet identifier |
| ImageUrl | character | <chr> URL to the media shared in the tweet |
| AltText | character | <chr> Alternative text corresponding to the media shared in the tweet |
| HashtagList | list | <list> List of hashtags used in the tweet |
| TweetDate | double | <dttm> Date and time the tweet was posted |
| Year | integer | <fct> Year the tweet was posted |
| UrlCheck | integer | <fct> Denotes whether the tweet included an external link |
Link to the raw data: data-raw/ttTweets2021.csv
A dataset containing the alternative text for media shared in 2021 as
part of the TidyTuesday social project, and other attributes. More
information can be found using ?ttTweets2021.
- Dates included: January 1, 2021 to April 4, 2021.
- Observations (rows): There are 1032 rows in this dataset. Each row represents a single unique tweet post.
- Variables (columns): There are 7 columns in this dataset. They are described below
| variable | data_type | description |
|---|---|---|
| TweetId | character | <chr> Unique tweet identifier |
| ImageUrl | character | <chr> URL to the media shared in the tweet |
| AltText | character | <chr> Alternative text corresponding to the media shared in the tweet |
| HashtagList | list | <list> List of hashtags used in the tweet |
| TweetDate | double | <dttm> Date and time the tweet was posted |
| Year | integer | <fct> Year the tweet was posted |
| UrlCheck | integer | <fct> Denotes whether the tweet included an external link |
Link to the raw data: data-raw/ttTweets2020.csv
A dataset containing the alternative text for media shared in 2020 as
part of the TidyTuesday social project, and other attributes. More
information can be found using ?ttTweets2020.
- Dates included: January 1, 2020 to December 31, 2020
- Observations (rows): There are 3374 rows in this dataset. Each row represents a single unique tweet post.
- Variables (columns): There are 7 columns in this dataset. They are described below
| variable | data_type | description |
|---|---|---|
| TweetId | character | <chr> Unique tweet identifier |
| ImageUrl | character | <chr> URL to the media shared in the tweet |
| AltText | character | <chr> Alternative text corresponding to the media shared in the tweet |
| HashtagList | list | <list> List of hashtags used in the tweet |
| TweetDate | double | <dttm> Date and time the tweet was posted |
| Year | integer | <fct> Year the tweet was posted |
| UrlCheck | integer | <fct> Denotes whether the tweet included an external link |
Link to the raw data: data-raw/ttTweets2019.csv
A dataset containing the alternative text for media shared in 2019 as
part of the TidyTuesday social project, and other attributes. More
information can be found using ?ttTweets2019.
- Dates included: January 1, 2019 to December 31, 2019.
- Observations (rows): There are 2022 rows in this dataset. Each row represents a single unique tweet post.
- Variables (columns): There are 7 columns in this dataset. They are described below
| variable | data_type | description |
|---|---|---|
| TweetId | character | <chr> Unique tweet identifier |
| ImageUrl | character | <chr> URL to the media shared in the tweet |
| AltText | character | <chr> Alternative text corresponding to the media shared in the tweet |
| HashtagList | list | <list> List of hashtags used in the tweet |
| TweetDate | double | <dttm> Date and time the tweet was posted |
| Year | integer | <fct> Year the tweet was posted |
| UrlCheck | integer | <fct> Denotes whether the tweet included an external link |
Link to the raw data: data-raw/ttTweets2018.csv
A dataset containing the alternative text for media shared in 2018 as
part of the TidyTuesday social project, and other attributes. More
information can be found using ?ttTweets2018.
- Dates included: April 2, 2018 to December 31, 2018.
- Observations (rows): There are 709 rows in this dataset. Each row represents a single unique tweet post.
- Variables (columns): There are 7 columns in this dataset. They are described below
| variable | data_type | description |
|---|---|---|
| TweetId | character | <chr> Unique tweet identifier |
| ImageUrl | character | <chr> URL to the media shared in the tweet |
| AltText | character | <chr> Alternative text corresponding to the media shared in the tweet |
| HashtagList | list | <list> List of hashtags used in the tweet |
| TweetDate | double | <dttm> Date and time the tweet was posted |
| Year | integer | <fct> Year the tweet was posted |
| UrlCheck | integer | <fct> Denotes whether the tweet included an external link |
To cite the TidyTuesdayAltText package, please use:
citation("TidyTuesdayAltText")
#>
#> To cite TidyTuesdayAltText in publications use:
#>
#> Canelón SP, Mock JT, and Hare E (2021). TidyTuesdayAltText:
#> Alternative text for media attached to TidyTuesday tweets. R package
#> version 0.0.9. https://github.com/spcanelon/TidyTuesdayAltText. doi:
#> ???
#>
#> A BibTeX entry for LaTeX users is
#>
#> @Manual{,
#> title = {TidyTuesdayAltText: Alternative text for media attached to TidyTuesday tweets},
#> author = {Silvia P. Canelón and Thomas Mock and Elizabeth Hare},
#> year = {2021},
#> note = {R package version 0.0.9},
#> url = {https://github.com/spcanelon/TidyTuesdayAltText},
#> }Data and hex logo originally published in:
- Thomas Mock (2021). Tidy Tuesday: A weekly data project aimed at the R ecosystem. https://github.com/rfordatascience/tidytuesday
Many thanks to Liz Hare (@DogGeneticsLLC) for testing the package in development and performing the analyses that went into our CSV Conf 2021 talk.
And thank you to the following resources for providing guidance and inspiration for how this package was organized and documented:
- Chapter 12 Create a data package | rstudio4edu
- The Pudding. Repo: the-pudding/data/foundation-names
- Horst AM, Hill AP, Gorman KB (2020). palmerpenguins: Palmer Archipelago (Antarctica) penguin data. R package version 0.1.0. https://allisonhorst.github.io/palmerpenguins/. doi:10.5281/zenodo.3960218.