



This repository implements a Advantage Actor-Critic agent baseline for the pysc2 environment as described in the DeepMind paper StarCraft II: A New Challenge for Reinforcement Learning. We use a synchronous variant of A3C (A2C) to effectively train on GPUs and otherwise stay as close as possible to the agent described in the paper.
This repository is part of a research project at the Autonomous Systems Labs , TU Darmstadt by Daniel Palenicek, Marcel Hussing, and Simon Meister.
- A2C agent
- FullyConv architecture
- support all spatial screen and minimap observations as well as non-spatial player observations
- support the full action space as described in the DeepMind paper (predicting all arguments independently)
- support training on all mini games
- report results for all mini games
- LSTM architecture
- Multi-GPU training
This project is licensed under the MIT License (refer to the LICENSE file for details).
On the mini games, we get the following results:
| Map | best mean score (ours) | best mean score (DeepMind) | episodes (ours) |
|---|---|---|---|
| MoveToBeacon | 26 | 26 | 8K |
| CollectMineralShards | 97 | 103 | 300K |
| FindAndDefeatZerglings | 45 | 45 | 450K |
| DefeatRoaches | 65 | 100 | - |
| DefeatZerglingsAndBanelings | 68 | 62 | - |
| CollectMineralsAndGas | - | 3978 | - |
| BuildMarines | - | 3 | - |
In the following we show plots for the score over episodes.
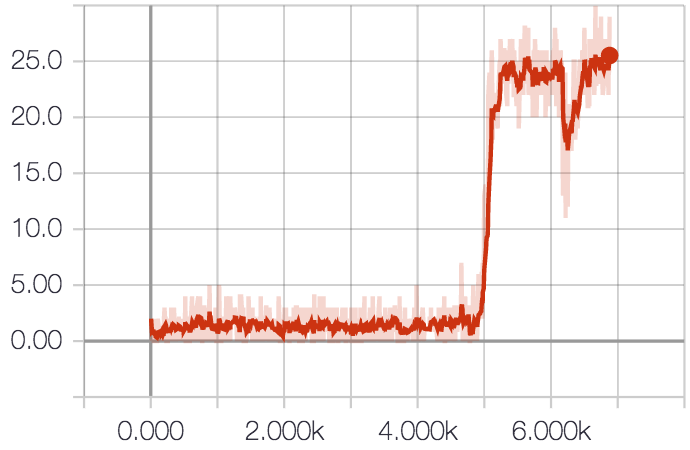
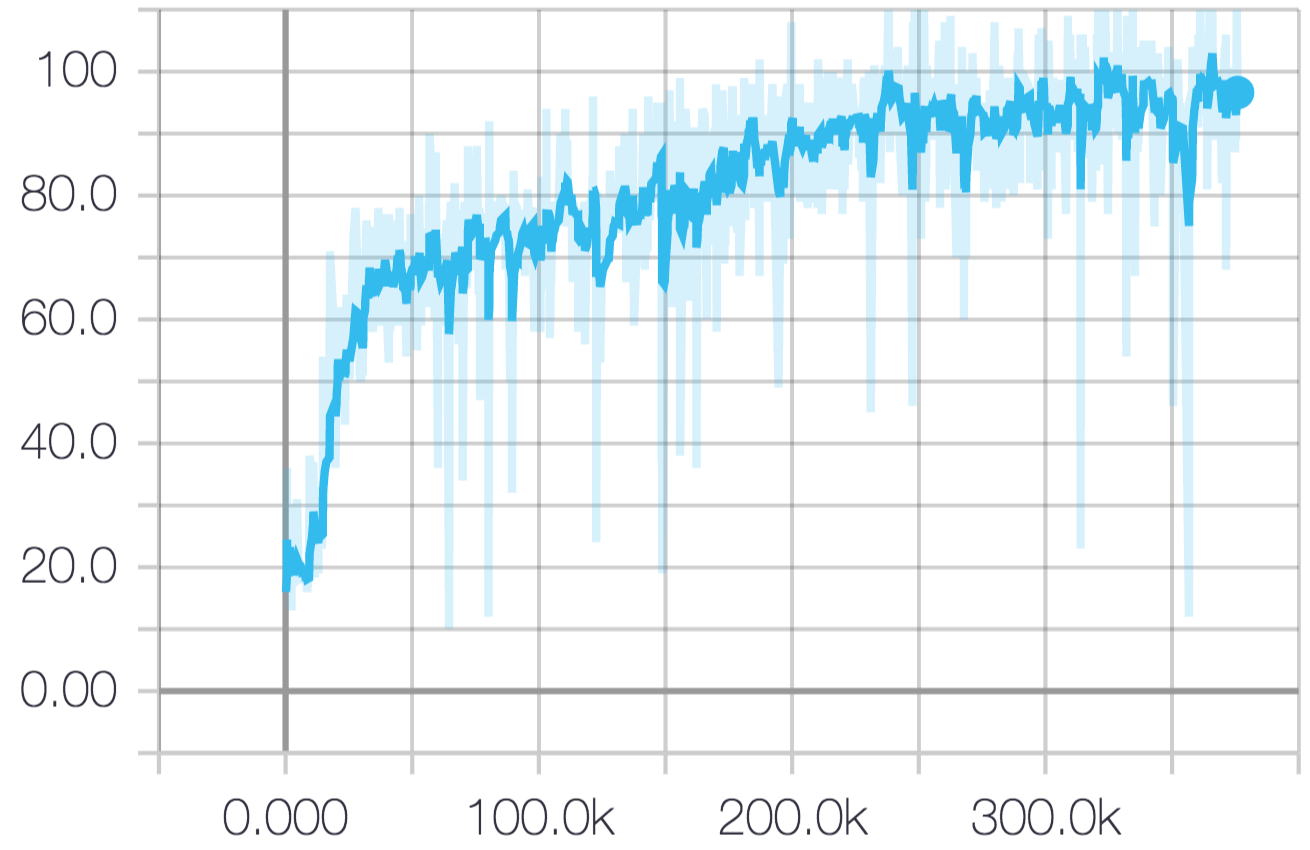

Note that the DeepMind mean scores are their best individual scores after 100 runs for each game, where the initial learning rate was randomly sampled for each run. We use a constant initial learning rate for a much smaller number of runs due to limited hardware. All agents use the same FullyConv agent.
With default settings (32 environments), learning MoveToBeacon well takes between 3K and 8K total episodes. This varies each run depending on random initialization and action sampling.
- for fast training, a GPU is recommended. We ran each experiment on a single Titan X Pascal (12GB).
- Python 3
- pysc2 (tested with v1.2)
- TensorFlow (tested with 1.4.0)
- StarCraft II and mini games (see below or pysc2)
pip install numpy tensorflow-gpu pysc2==1.2- Install StarCraft II. On Linux, use 3.16.1.
- Download the
mini games
and extract them to your
StarcraftII/Maps/directory.
- run and train:
python run.py my_experiment --map MoveToBeacon. - run and evalutate without training:
python run.py my_experiment --map MoveToBeacon --eval.
You can visualize the agents during training or evaluation with the --vis flag.
See run.py for all arguments.
Summaries are written to out/summary/<experiment_name>
and model checkpoints are written to out/models/<experiment_name>.
The code in rl/environment.py is based on
OpenAI baselines,
with adaptions from
sc2aibot.
Some of the code in rl/agents/a2c/runner.py is loosely based on
sc2aibot.