Underlying enum class to support the
-
+
DataType
@@ -467,7 +467,7 @@
In the case that you need to use the
-
+
DataType
@@ -476,7 +476,7 @@
ex. trtorch::DataType type =
-
+
DataType::kFloat
@@ -612,7 +612,7 @@
-
+
DataType
@@ -696,7 +696,7 @@
Get the enum value of the
-
+
DataType
@@ -775,7 +775,7 @@
Comparision operator for
-
+
DataType
@@ -865,7 +865,7 @@
Comparision operator for
-
+
DataType
@@ -951,7 +951,7 @@
Comparision operator for
-
+
DataType
@@ -1041,7 +1041,7 @@
Comparision operator for
-
+
DataType
diff --git a/docs/_cpp_api/classtrtorch_1_1CompileSpec_1_1DeviceType.html b/docs/_cpp_api/classtrtorch_1_1CompileSpec_1_1DeviceType.html
index acb0528810..1d1772a40c 100644
--- a/docs/_cpp_api/classtrtorch_1_1CompileSpec_1_1DeviceType.html
+++ b/docs/_cpp_api/classtrtorch_1_1CompileSpec_1_1DeviceType.html
@@ -392,7 +392,7 @@
This class is a nested type of
-
+
Struct CompileSpec
@@ -435,7 +435,7 @@
This class is compatable with c10::DeviceTypes (but will check for TRT support) but the only applicable value is at::kCUDA, which maps to
-
+
DeviceType::kGPU
@@ -443,7 +443,7 @@
To use the
-
+
DataType
@@ -452,7 +452,7 @@
ex. trtorch::DeviceType type =
-
+
DeviceType::kGPU
@@ -481,7 +481,7 @@
Underlying enum class to support the
-
+
DeviceType
@@ -490,7 +490,7 @@
In the case that you need to use the
-
+
DeviceType
@@ -499,7 +499,7 @@
ex. trtorch::DeviceType type =
-
+
DeviceType::kGPU
@@ -766,7 +766,7 @@
Comparison operator for
-
+
DeviceType
@@ -852,7 +852,7 @@
Comparison operator for
-
+
DeviceType
diff --git a/docs/_cpp_api/classtrtorch_1_1ptq_1_1Int8CacheCalibrator.html b/docs/_cpp_api/classtrtorch_1_1ptq_1_1Int8CacheCalibrator.html
index f043962260..d13bc517fd 100644
--- a/docs/_cpp_api/classtrtorch_1_1ptq_1_1Int8CacheCalibrator.html
+++ b/docs/_cpp_api/classtrtorch_1_1ptq_1_1Int8CacheCalibrator.html
@@ -865,7 +865,7 @@
Convience function to convert to a IInt8Calibrator* to easily be assigned to the ptq_calibrator field in
-
+
CompileSpec
diff --git a/docs/_cpp_api/classtrtorch_1_1ptq_1_1Int8Calibrator.html b/docs/_cpp_api/classtrtorch_1_1ptq_1_1Int8Calibrator.html
index 797c91a841..552fbd4d3d 100644
--- a/docs/_cpp_api/classtrtorch_1_1ptq_1_1Int8Calibrator.html
+++ b/docs/_cpp_api/classtrtorch_1_1ptq_1_1Int8Calibrator.html
@@ -926,7 +926,7 @@
Convience function to convert to a IInt8Calibrator* to easily be assigned to the ptq_calibrator field in
-
+
CompileSpec
diff --git a/docs/_cpp_api/file_cpp_api_include_trtorch_logging.h.html b/docs/_cpp_api/file_cpp_api_include_trtorch_logging.h.html
index 28c3b28c94..e54f3aab7c 100644
--- a/docs/_cpp_api/file_cpp_api_include_trtorch_logging.h.html
+++ b/docs/_cpp_api/file_cpp_api_include_trtorch_logging.h.html
@@ -407,7 +407,7 @@
)
-
+
Contents
diff --git a/docs/_cpp_api/file_cpp_api_include_trtorch_macros.h.html b/docs/_cpp_api/file_cpp_api_include_trtorch_macros.h.html
index ff83ad0cbb..3730db95da 100644
--- a/docs/_cpp_api/file_cpp_api_include_trtorch_macros.h.html
+++ b/docs/_cpp_api/file_cpp_api_include_trtorch_macros.h.html
@@ -392,7 +392,7 @@
)
-
+
Contents
diff --git a/docs/_cpp_api/file_cpp_api_include_trtorch_ptq.h.html b/docs/_cpp_api/file_cpp_api_include_trtorch_ptq.h.html
index e2c6adc7bd..43d78bb1c1 100644
--- a/docs/_cpp_api/file_cpp_api_include_trtorch_ptq.h.html
+++ b/docs/_cpp_api/file_cpp_api_include_trtorch_ptq.h.html
@@ -402,7 +402,7 @@
)
-
+
Contents
diff --git a/docs/_cpp_api/file_cpp_api_include_trtorch_trtorch.h.html b/docs/_cpp_api/file_cpp_api_include_trtorch_trtorch.h.html
index cbb1c8a391..687ea513c9 100644
--- a/docs/_cpp_api/file_cpp_api_include_trtorch_trtorch.h.html
+++ b/docs/_cpp_api/file_cpp_api_include_trtorch_trtorch.h.html
@@ -402,7 +402,7 @@
)
-
+
Contents
@@ -547,7 +547,7 @@
-
-
-
-
-
+
Class CompileSpec::DeviceType
diff --git a/docs/_cpp_api/function_trtorch_8h_1a3eace458ae9122f571fabfc9ef1b9e3a.html b/docs/_cpp_api/function_trtorch_8h_1a3eace458ae9122f571fabfc9ef1b9e3a.html
index a6aa986ac0..1d15d10c2a 100644
--- a/docs/_cpp_api/function_trtorch_8h_1a3eace458ae9122f571fabfc9ef1b9e3a.html
+++ b/docs/_cpp_api/function_trtorch_8h_1a3eace458ae9122f571fabfc9ef1b9e3a.html
@@ -459,7 +459,7 @@
:
-
+
trtorch::CompileSpec
diff --git a/docs/_cpp_api/function_trtorch_8h_1af19cb866b0520fc84b69a1cf25a52b65.html b/docs/_cpp_api/function_trtorch_8h_1af19cb866b0520fc84b69a1cf25a52b65.html
index 143288c087..9513f38991 100644
--- a/docs/_cpp_api/function_trtorch_8h_1af19cb866b0520fc84b69a1cf25a52b65.html
+++ b/docs/_cpp_api/function_trtorch_8h_1af19cb866b0520fc84b69a1cf25a52b65.html
@@ -423,6 +423,9 @@
)
+
+ ¶
+
-
@@ -470,7 +473,7 @@
:
-
+
trtorch::CompileSpec
diff --git a/docs/_cpp_api/namespace_trtorch.html b/docs/_cpp_api/namespace_trtorch.html
index fd747baf1d..65dd616a2b 100644
--- a/docs/_cpp_api/namespace_trtorch.html
+++ b/docs/_cpp_api/namespace_trtorch.html
@@ -378,7 +378,7 @@
-
+
Contents
@@ -440,7 +440,7 @@
-
-
-
-
-
+
Class CompileSpec::DeviceType
diff --git a/docs/_cpp_api/namespace_trtorch__logging.html b/docs/_cpp_api/namespace_trtorch__logging.html
index 28fe619697..6da91d52aa 100644
--- a/docs/_cpp_api/namespace_trtorch__logging.html
+++ b/docs/_cpp_api/namespace_trtorch__logging.html
@@ -373,7 +373,7 @@
-
+
Contents
diff --git a/docs/_cpp_api/namespace_trtorch__ptq.html b/docs/_cpp_api/namespace_trtorch__ptq.html
index 55807907c4..53fb113684 100644
--- a/docs/_cpp_api/namespace_trtorch__ptq.html
+++ b/docs/_cpp_api/namespace_trtorch__ptq.html
@@ -373,7 +373,7 @@
-
+
Contents
diff --git a/docs/_cpp_api/structtrtorch_1_1CompileSpec.html b/docs/_cpp_api/structtrtorch_1_1CompileSpec.html
index 5ab4b8daad..4650623324 100644
--- a/docs/_cpp_api/structtrtorch_1_1CompileSpec.html
+++ b/docs/_cpp_api/structtrtorch_1_1CompileSpec.html
@@ -408,7 +408,7 @@
-
-
-
-
+
Struct CompileSpec::InputRange
@@ -759,7 +759,10 @@
DataType
- ::kFloat
+ ::
+
+ kFloat
+
¶
@@ -865,7 +868,10 @@
DeviceType
- ::kGPU
+ ::
+
+ kGPU
+
¶
@@ -1045,7 +1051,7 @@
-
Underlying enum class to support the
-
+
DataType
@@ -1054,7 +1060,7 @@
In the case that you need to use the
-
+
DataType
@@ -1063,7 +1069,7 @@
ex. trtorch::DataType type =
-
+
DataType::kFloat
@@ -1184,7 +1190,7 @@
-
-
+
DataType
@@ -1262,7 +1268,7 @@
-
Get the enum value of the
-
+
DataType
@@ -1335,7 +1341,7 @@
-
Comparision operator for
-
+
DataType
@@ -1422,7 +1428,7 @@
-
Comparision operator for
-
+
DataType
@@ -1505,7 +1511,7 @@
-
Comparision operator for
-
+
DataType
@@ -1592,7 +1598,7 @@
-
Comparision operator for
-
+
DataType
@@ -1665,7 +1671,7 @@
This class is compatable with c10::DeviceTypes (but will check for TRT support) but the only applicable value is at::kCUDA, which maps to
-
+
DeviceType::kGPU
@@ -1673,7 +1679,7 @@
To use the
-
+
DataType
@@ -1682,7 +1688,7 @@
ex. trtorch::DeviceType type =
-
+
DeviceType::kGPU
@@ -1708,7 +1714,7 @@
-
Underlying enum class to support the
-
+
DeviceType
@@ -1717,7 +1723,7 @@
In the case that you need to use the
-
+
DeviceType
@@ -1726,7 +1732,7 @@
ex. trtorch::DeviceType type =
-
+
DeviceType::kGPU
@@ -1969,7 +1975,7 @@
-
Comparison operator for
-
+
DeviceType
@@ -2052,7 +2058,7 @@
-
Comparison operator for
-
+
DeviceType
diff --git a/docs/_cpp_api/structtrtorch_1_1CompileSpec_1_1InputRange.html b/docs/_cpp_api/structtrtorch_1_1CompileSpec_1_1InputRange.html
index c87755f91e..0620aef0db 100644
--- a/docs/_cpp_api/structtrtorch_1_1CompileSpec_1_1InputRange.html
+++ b/docs/_cpp_api/structtrtorch_1_1CompileSpec_1_1InputRange.html
@@ -392,7 +392,7 @@
This struct is a nested type of
-
+
Struct CompileSpec
diff --git a/docs/_notebooks/Resnet50-example.html b/docs/_notebooks/Resnet50-example.html
index 7bff2ba3f8..2c22d0b157 100644
--- a/docs/_notebooks/Resnet50-example.html
+++ b/docs/_notebooks/Resnet50-example.html
@@ -380,7 +380,7 @@
-
-
+
What’s next
@@ -646,26 +646,26 @@
-# Copyright 2019 NVIDIA Corporation. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
+# Copyright 2019 NVIDIA Corporation. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
-  +
+
TRTorch Getting Started - ResNet 50
@@ -753,7 +753,7 @@
-!nvidia-smi
+!nvidia-smi
@@ -815,9 +815,13 @@
-
- ## 1. Requirements
-
+
+
+
+ ## 1. Requirements
+
+
+
Follow the steps in
@@ -827,9 +831,13 @@
to prepare a Docker container, within which you can run this notebook.
-
- ## 2. ResNet-50 Overview
-
+
+
+
+ ## 2. ResNet-50 Overview
+
+
+
PyTorch has a model repository called the PyTorch Hub, which is a source for high quality implementations of common models. We can get our ResNet-50 model from there pretrained on ImageNet.
@@ -859,9 +867,9 @@
-import torch
-resnet50_model = torch.hub.load('pytorch/vision:v0.6.0', 'resnet50', pretrained=True)
-resnet50_model.eval()
+import torch
+resnet50_model = torch.hub.load('pytorch/vision:v0.6.0', 'resnet50', pretrained=True)
+resnet50_model.eval()
@@ -1068,7 +1076,7 @@
- All pre-trained models expect input images normalized in the same way, i.e. mini-batches of 3-channel RGB images of shape
+ All pre-trained models expect input images normalized in the same way, i.e. mini-batches of 3-channel RGB images of shape
(3
@@ -1164,13 +1172,13 @@
-!mkdir ./data
-!wget -O ./data/img0.JPG "https://d17fnq9dkz9hgj.cloudfront.net/breed-uploads/2018/08/siberian-husky-detail.jpg?bust=1535566590&width=630"
-!wget -O ./data/img1.JPG "https://www.hakaimagazine.com/wp-content/uploads/header-gulf-birds.jpg"
-!wget -O ./data/img2.JPG "https://www.artis.nl/media/filer_public_thumbnails/filer_public/00/f1/00f1b6db-fbed-4fef-9ab0-84e944ff11f8/chimpansee_amber_r_1920x1080.jpg__1920x1080_q85_subject_location-923%2C365_subsampling-2.jpg"
-!wget -O ./data/img3.JPG "https://www.familyhandyman.com/wp-content/uploads/2018/09/How-to-Avoid-Snakes-Slithering-Up-Your-Toilet-shutterstock_780480850.jpg"
+!mkdir ./data
+!wget -O ./data/img0.JPG "https://d17fnq9dkz9hgj.cloudfront.net/breed-uploads/2018/08/siberian-husky-detail.jpg?bust=1535566590&width=630"
+!wget -O ./data/img1.JPG "https://www.hakaimagazine.com/wp-content/uploads/header-gulf-birds.jpg"
+!wget -O ./data/img2.JPG "https://www.artis.nl/media/filer_public_thumbnails/filer_public/00/f1/00f1b6db-fbed-4fef-9ab0-84e944ff11f8/chimpansee_amber_r_1920x1080.jpg__1920x1080_q85_subject_location-923%2C365_subsampling-2.jpg"
+!wget -O ./data/img3.JPG "https://www.familyhandyman.com/wp-content/uploads/2018/09/How-to-Avoid-Snakes-Slithering-Up-Your-Toilet-shutterstock_780480850.jpg"
-!wget -O ./data/imagenet_class_index.json "https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json"
+!wget -O ./data/imagenet_class_index.json "https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json"
@@ -1251,7 +1259,7 @@
-!pip install pillow matplotlib
+!pip install pillow matplotlib
@@ -1288,25 +1296,25 @@
-from PIL import Image
-from torchvision import transforms
-import matplotlib.pyplot as plt
+from PIL import Image
+from torchvision import transforms
+import matplotlib.pyplot as plt
-fig, axes = plt.subplots(nrows=2, ncols=2)
+fig, axes = plt.subplots(nrows=2, ncols=2)
-for i in range(4):
- img_path = './data/img%d.JPG'%i
- img = Image.open(img_path)
- preprocess = transforms.Compose([
- transforms.Resize(256),
- transforms.CenterCrop(224),
- transforms.ToTensor(),
- transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
-])
- input_tensor = preprocess(img)
- plt.subplot(2,2,i+1)
- plt.imshow(img)
- plt.axis('off')
+for i in range(4):
+ img_path = './data/img%d.JPG'%i
+ img = Image.open(img_path)
+ preprocess = transforms.Compose([
+ transforms.Resize(256),
+ transforms.CenterCrop(224),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
+])
+ input_tensor = preprocess(img)
+ plt.subplot(2,2,i+1)
+ plt.imshow(img)
+ plt.axis('off')
@@ -1328,12 +1336,12 @@
-import json
+import json
-with open("./data/imagenet_class_index.json") as json_file:
- d = json.load(json_file)
+with open("./data/imagenet_class_index.json") as json_file:
+ d = json.load(json_file)
-print("Number of classes in ImageNet: {}".format(len(d)))
+print("Number of classes in ImageNet: {}".format(len(d)))
@@ -1359,36 +1367,36 @@
-import numpy as np
+import numpy as np
-def rn50_preprocess():
- preprocess = transforms.Compose([
- transforms.Resize(256),
- transforms.CenterCrop(224),
- transforms.ToTensor(),
- transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
- ])
- return preprocess
+def rn50_preprocess():
+ preprocess = transforms.Compose([
+ transforms.Resize(256),
+ transforms.CenterCrop(224),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
+ ])
+ return preprocess
-# decode the results into ([predicted class, description], probability)
-def predict(img_path, model):
- img = Image.open(img_path)
- preprocess = rn50_preprocess()
- input_tensor = preprocess(img)
- input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
+# decode the results into ([predicted class, description], probability)
+def predict(img_path, model):
+ img = Image.open(img_path)
+ preprocess = rn50_preprocess()
+ input_tensor = preprocess(img)
+ input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
- # move the input and model to GPU for speed if available
- if torch.cuda.is_available():
- input_batch = input_batch.to('cuda')
- model.to('cuda')
+ # move the input and model to GPU for speed if available
+ if torch.cuda.is_available():
+ input_batch = input_batch.to('cuda')
+ model.to('cuda')
- with torch.no_grad():
- output = model(input_batch)
- # Tensor of shape 1000, with confidence scores over Imagenet's 1000 classes
- sm_output = torch.nn.functional.softmax(output[0], dim=0)
+ with torch.no_grad():
+ output = model(input_batch)
+ # Tensor of shape 1000, with confidence scores over Imagenet's 1000 classes
+ sm_output = torch.nn.functional.softmax(output[0], dim=0)
- ind = torch.argmax(sm_output)
- return d[str(ind.item())], sm_output[ind] #([predicted class, description], probability)
+ ind = torch.argmax(sm_output)
+ return d[str(ind.item())], sm_output[ind] #([predicted class, description], probability)
@@ -1403,17 +1411,17 @@
-for i in range(4):
- img_path = './data/img%d.JPG'%i
- img = Image.open(img_path)
+for i in range(4):
+ img_path = './data/img%d.JPG'%i
+ img = Image.open(img_path)
- pred, prob = predict(img_path, resnet50_model)
- print('{} - Predicted: {}, Probablility: {}'.format(img_path, pred, prob))
+ pred, prob = predict(img_path, resnet50_model)
+ print('{} - Predicted: {}, Probablility: {}'.format(img_path, pred, prob))
- plt.subplot(2,2,i+1)
- plt.imshow(img);
- plt.axis('off');
- plt.title(pred[1])
+ plt.subplot(2,2,i+1)
+ plt.imshow(img);
+ plt.axis('off');
+ plt.title(pred[1])
@@ -1458,38 +1466,38 @@
-import time
-import numpy as np
+import time
+import numpy as np
-import torch.backends.cudnn as cudnn
-cudnn.benchmark = True
+import torch.backends.cudnn as cudnn
+cudnn.benchmark = True
-def benchmark(model, input_shape=(1024, 1, 224, 224), dtype='fp32', nwarmup=50, nruns=10000):
- input_data = torch.randn(input_shape)
- input_data = input_data.to("cuda")
- if dtype=='fp16':
- input_data = input_data.half()
+def benchmark(model, input_shape=(1024, 1, 224, 224), dtype='fp32', nwarmup=50, nruns=10000):
+ input_data = torch.randn(input_shape)
+ input_data = input_data.to("cuda")
+ if dtype=='fp16':
+ input_data = input_data.half()
- print("Warm up ...")
- with torch.no_grad():
- for _ in range(nwarmup):
- features = model(input_data)
- torch.cuda.synchronize()
- print("Start timing ...")
- timings = []
- with torch.no_grad():
- for i in range(1, nruns+1):
- start_time = time.time()
- features = model(input_data)
- torch.cuda.synchronize()
- end_time = time.time()
- timings.append(end_time - start_time)
- if i%100==0:
- print('Iteration %d/%d, ave batch time %.2f ms'%(i, nruns, np.mean(timings)*1000))
+ print("Warm up ...")
+ with torch.no_grad():
+ for _ in range(nwarmup):
+ features = model(input_data)
+ torch.cuda.synchronize()
+ print("Start timing ...")
+ timings = []
+ with torch.no_grad():
+ for i in range(1, nruns+1):
+ start_time = time.time()
+ features = model(input_data)
+ torch.cuda.synchronize()
+ end_time = time.time()
+ timings.append(end_time - start_time)
+ if i%100==0:
+ print('Iteration %d/%d, ave batch time %.2f ms'%(i, nruns, np.mean(timings)*1000))
- print("Input shape:", input_data.size())
- print("Output features size:", features.size())
- print('Average batch time: %.2f ms'%(np.mean(timings)*1000))
+ print("Input shape:", input_data.size())
+ print("Output features size:", features.size())
+ print('Average batch time: %.2f ms'%(np.mean(timings)*1000))
@@ -1504,9 +1512,9 @@
-# Model benchmark without TRTorch/TensorRT
-model = resnet50_model.eval().to("cuda")
-benchmark(model, input_shape=(128, 3, 224, 224), nruns=1000)
+# Model benchmark without TRTorch/TensorRT
+model = resnet50_model.eval().to("cuda")
+benchmark(model, input_shape=(128, 3, 224, 224), nruns=1000)
@@ -1536,9 +1544,13 @@
-
- ## 3. Creating TorchScript modules
-
+
+
+
+ ## 3. Creating TorchScript modules
+
+
+
To compile with TRTorch, the model must first be in
@@ -1591,8 +1603,8 @@
-model = resnet50_model.eval().to("cuda")
-traced_model = torch.jit.trace(model, [torch.randn((128, 3, 224, 224)).to("cuda")])
+model = resnet50_model.eval().to("cuda")
+traced_model = torch.jit.trace(model, [torch.randn((128, 3, 224, 224)).to("cuda")])
@@ -1610,8 +1622,8 @@
-# This is just an example, and not required for the purposes of this demo
-torch.jit.save(traced_model, "resnet_50_traced.jit.pt")
+# This is just an example, and not required for the purposes of this demo
+torch.jit.save(traced_model, "resnet_50_traced.jit.pt")
@@ -1626,8 +1638,8 @@
-# Obtain the average time taken by a batch of input
-benchmark(traced_model, input_shape=(128, 3, 224, 224), nruns=1000)
+# Obtain the average time taken by a batch of input
+benchmark(traced_model, input_shape=(128, 3, 224, 224), nruns=1000)
@@ -1657,9 +1669,13 @@
-
- ## 4. Compiling with TRTorch
-
+
+
+
+ ## 4. Compiling with TRTorch
+
+
+
TorchScript modules behave just like normal PyTorch modules and are intercompatible. From TorchScript we can now compile a TensorRT based module. This module will still be implemented in TorchScript but all the computation will be done in TensorRT.
@@ -1685,15 +1701,15 @@
-import trtorch
+import trtorch
-# The compiled module will have precision as specified by "op_precision".
-# Here, it will have FP16 precision.
-trt_model_fp32 = trtorch.compile(traced_model, {
- "input_shapes": [(128, 3, 224, 224)],
- "op_precision": torch.float32, # Run with FP32
- "workspace_size": 1 << 20
-})
+# The compiled module will have precision as specified by "op_precision".
+# Here, it will have FP16 precision.
+trt_model_fp32 = trtorch.compile(traced_model, {
+ "input_shapes": [(128, 3, 224, 224)],
+ "op_precision": torch.float32, # Run with FP32
+ "workspace_size": 1 << 20
+})
@@ -1710,8 +1726,8 @@
-# Obtain the average time taken by a batch of input
-benchmark(trt_model_fp32, input_shape=(128, 3, 224, 224), nruns=1000)
+# Obtain the average time taken by a batch of input
+benchmark(trt_model_fp32, input_shape=(128, 3, 224, 224), nruns=1000)
@@ -1757,15 +1773,15 @@
-import trtorch
+import trtorch
-# The compiled module will have precision as specified by "op_precision".
-# Here, it will have FP16 precision.
-trt_model = trtorch.compile(traced_model, {
- "input_shapes": [(128, 3, 224, 224)],
- "op_precision": torch.half, # Run with FP16
- "workspace_size": 1 << 20
-})
+# The compiled module will have precision as specified by "op_precision".
+# Here, it will have FP16 precision.
+trt_model = trtorch.compile(traced_model, {
+ "input_shapes": [(128, 3, 224, 224)],
+ "op_precision": torch.half, # Run with FP16
+ "workspace_size": 1 << 20
+})
@@ -1781,8 +1797,8 @@
-# Obtain the average time taken by a batch of input
-benchmark(trt_model, input_shape=(128, 3, 224, 224), dtype='fp16', nruns=1000)
+# Obtain the average time taken by a batch of input
+benchmark(trt_model, input_shape=(128, 3, 224, 224), dtype='fp16', nruns=1000)
@@ -1812,9 +1828,13 @@
-
- ## 5. Conclusion
-
+
+
+
+ ## 5. Conclusion
+
+
+
In this notebook, we have walked through the complete process of compiling TorchScript models with TRTorch for ResNet-50 model and test the performance impact of the optimization. With TRTorch, we observe a speedup of
@@ -1826,9 +1846,9 @@
with FP16.
-
+
What’s next
-
+
¶
diff --git a/docs/_notebooks/lenet-getting-started.html b/docs/_notebooks/lenet-getting-started.html
index 034ee524aa..99c0d6f8f1 100644
--- a/docs/_notebooks/lenet-getting-started.html
+++ b/docs/_notebooks/lenet-getting-started.html
@@ -326,7 +326,7 @@
-
- ## 1. Requirements
-
+
+
+
+ ## 1. Requirements
+
+
+
Follow the steps in
@@ -835,9 +839,13 @@
to prepare a Docker container, within which you can run this notebook.
-
- ## 2. Creating TorchScript modules
-
+
+
+
+ ## 2. Creating TorchScript modules
+
+
+
Here we create two submodules for a feature extractor and a classifier and stitch them together in a single LeNet module. In this case this is overkill but modules give us granular control over our program including where we decide to optimize and where we don’t. It is also the unit that the TorchScript compiler operates on. So you can decide to only convert/optimize the feature extractor and leave the classifier in standard PyTorch or you can convert the whole thing. When compiling your module
to TorchScript, there are two paths: Tracing and Scripting.
@@ -852,45 +860,45 @@
-import torch
-from torch import nn
-import torch.nn.functional as F
+import torch
+from torch import nn
+import torch.nn.functional as F
-class LeNetFeatExtractor(nn.Module):
- def __init__(self):
- super(LeNetFeatExtractor, self).__init__()
- self.conv1 = nn.Conv2d(1, 6, 3)
- self.conv2 = nn.Conv2d(6, 16, 3)
+class LeNetFeatExtractor(nn.Module):
+ def __init__(self):
+ super(LeNetFeatExtractor, self).__init__()
+ self.conv1 = nn.Conv2d(1, 6, 3)
+ self.conv2 = nn.Conv2d(6, 16, 3)
- def forward(self, x):
- x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
- x = F.max_pool2d(F.relu(self.conv2(x)), 2)
- return x
+ def forward(self, x):
+ x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
+ x = F.max_pool2d(F.relu(self.conv2(x)), 2)
+ return x
-class LeNetClassifier(nn.Module):
- def __init__(self):
- super(LeNetClassifier, self).__init__()
- self.fc1 = nn.Linear(16 * 6 * 6, 120)
- self.fc2 = nn.Linear(120, 84)
- self.fc3 = nn.Linear(84, 10)
+class LeNetClassifier(nn.Module):
+ def __init__(self):
+ super(LeNetClassifier, self).__init__()
+ self.fc1 = nn.Linear(16 * 6 * 6, 120)
+ self.fc2 = nn.Linear(120, 84)
+ self.fc3 = nn.Linear(84, 10)
- def forward(self, x):
- x = torch.flatten(x,1)
- x = F.relu(self.fc1(x))
- x = F.relu(self.fc2(x))
- x = self.fc3(x)
- return x
+ def forward(self, x):
+ x = torch.flatten(x,1)
+ x = F.relu(self.fc1(x))
+ x = F.relu(self.fc2(x))
+ x = self.fc3(x)
+ return x
-class LeNet(nn.Module):
- def __init__(self):
- super(LeNet, self).__init__()
- self.feat = LeNetFeatExtractor()
- self.classifer = LeNetClassifier()
+class LeNet(nn.Module):
+ def __init__(self):
+ super(LeNet, self).__init__()
+ self.feat = LeNetFeatExtractor()
+ self.classifer = LeNetClassifier()
- def forward(self, x):
- x = self.feat(x)
- x = self.classifer(x)
- return x
+ def forward(self, x):
+ x = self.feat(x)
+ x = self.classifer(x)
+ return x
@@ -909,39 +917,39 @@
-import time
-import numpy as np
+import time
+import numpy as np
-import torch.backends.cudnn as cudnn
-cudnn.benchmark = True
+import torch.backends.cudnn as cudnn
+cudnn.benchmark = True
-def benchmark(model, input_shape=(1024, 1, 32, 32), dtype='fp32', nwarmup=50, nruns=10000):
- input_data = torch.randn(input_shape)
- input_data = input_data.to("cuda")
- if dtype=='fp16':
- input_data = input_data.half()
+def benchmark(model, input_shape=(1024, 1, 32, 32), dtype='fp32', nwarmup=50, nruns=10000):
+ input_data = torch.randn(input_shape)
+ input_data = input_data.to("cuda")
+ if dtype=='fp16':
+ input_data = input_data.half()
- print("Warm up ...")
- with torch.no_grad():
- for _ in range(nwarmup):
- features = model(input_data)
- torch.cuda.synchronize()
- print("Start timing ...")
- timings = []
- with torch.no_grad():
- for i in range(1, nruns+1):
- start_time = time.time()
- features = model(input_data)
- torch.cuda.synchronize()
- end_time = time.time()
- timings.append(end_time - start_time)
- if i%1000==0:
- print('Iteration %d/%d, ave batch time %.2f ms'%(i, nruns, np.mean(timings)*1000))
+ print("Warm up ...")
+ with torch.no_grad():
+ for _ in range(nwarmup):
+ features = model(input_data)
+ torch.cuda.synchronize()
+ print("Start timing ...")
+ timings = []
+ with torch.no_grad():
+ for i in range(1, nruns+1):
+ start_time = time.time()
+ features = model(input_data)
+ torch.cuda.synchronize()
+ end_time = time.time()
+ timings.append(end_time - start_time)
+ if i%1000==0:
+ print('Iteration %d/%d, ave batch time %.2f ms'%(i, nruns, np.mean(timings)*1000))
- print("Input shape:", input_data.size())
- print("Output features size:", features.size())
+ print("Input shape:", input_data.size())
+ print("Output features size:", features.size())
- print('Average batch time: %.2f ms'%(np.mean(timings)*1000))
+ print('Average batch time: %.2f ms'%(np.mean(timings)*1000))
@@ -962,8 +970,8 @@
-model = LeNet()
-model.to("cuda").eval()
+model = LeNet()
+model.to("cuda").eval()
@@ -1004,7 +1012,7 @@
-benchmark(model)
+benchmark(model)
@@ -1056,8 +1064,8 @@
-traced_model = torch.jit.trace(model, torch.empty([1,1,32,32]).to("cuda"))
-traced_model
+traced_model = torch.jit.trace(model, torch.empty([1,1,32,32]).to("cuda"))
+traced_model
@@ -1100,7 +1108,7 @@
-benchmark(traced_model)
+benchmark(traced_model)
@@ -1149,8 +1157,8 @@
-model = LeNet().to("cuda").eval()
-script_model = torch.jit.script(model)
+model = LeNet().to("cuda").eval()
+script_model = torch.jit.script(model)
@@ -1166,7 +1174,7 @@
-script_model
+script_model
@@ -1209,7 +1217,7 @@
-benchmark(script_model)
+benchmark(script_model)
@@ -1239,9 +1247,13 @@
-
- ## 3. Compiling with TRTorch
-
+
+
+
+ ## 3. Compiling with TRTorch
+
+
+
TorchScript traced model
@@ -1261,28 +1273,28 @@
-import trtorch
+import trtorch
-# We use a batch-size of 1024, and half precision
-compile_settings = {
- "input_shapes": [
- {
- "min" : [1024, 1, 32, 32],
- "opt" : [1024, 1, 33, 33],
- "max" : [1024, 1, 34, 34],
- }
- ],
- "op_precision": torch.half # Run with FP16
-}
+# We use a batch-size of 1024, and half precision
+compile_settings = {
+ "input_shapes": [
+ {
+ "min" : [1024, 1, 32, 32],
+ "opt" : [1024, 1, 33, 33],
+ "max" : [1024, 1, 34, 34],
+ }
+ ],
+ "op_precision": torch.half # Run with FP16
+}
-trt_ts_module = trtorch.compile(traced_model, compile_settings)
+trt_ts_module = trtorch.compile(traced_model, compile_settings)
-input_data = torch.randn((1024, 1, 32, 32))
-input_data = input_data.half().to("cuda")
+input_data = torch.randn((1024, 1, 32, 32))
+input_data = input_data.half().to("cuda")
-input_data = input_data.half()
-result = trt_ts_module(input_data)
-torch.jit.save(trt_ts_module, "trt_ts_module.ts")
+input_data = input_data.half()
+result = trt_ts_module(input_data)
+torch.jit.save(trt_ts_module, "trt_ts_module.ts")
@@ -1297,7 +1309,7 @@
-benchmark(trt_ts_module, input_shape=(1024, 1, 32, 32), dtype="fp16")
+benchmark(trt_ts_module, input_shape=(1024, 1, 32, 32), dtype="fp16")
@@ -1346,28 +1358,28 @@
-import trtorch
+import trtorch
-# We use a batch-size of 1024, and half precision
-compile_settings = {
- "input_shapes": [
- {
- "min" : [1024, 1, 32, 32],
- "opt" : [1024, 1, 33, 33],
- "max" : [1024, 1, 34, 34],
- }
- ],
- "op_precision": torch.half # Run with FP16
-}
+# We use a batch-size of 1024, and half precision
+compile_settings = {
+ "input_shapes": [
+ {
+ "min" : [1024, 1, 32, 32],
+ "opt" : [1024, 1, 33, 33],
+ "max" : [1024, 1, 34, 34],
+ }
+ ],
+ "op_precision": torch.half # Run with FP16
+}
-trt_script_module = trtorch.compile(script_model, compile_settings)
+trt_script_module = trtorch.compile(script_model, compile_settings)
-input_data = torch.randn((1024, 1, 32, 32))
-input_data = input_data.half().to("cuda")
+input_data = torch.randn((1024, 1, 32, 32))
+input_data = input_data.half().to("cuda")
-input_data = input_data.half()
-result = trt_script_module(input_data)
-torch.jit.save(trt_script_module, "trt_script_module.ts")
+input_data = input_data.half()
+result = trt_script_module(input_data)
+torch.jit.save(trt_script_module, "trt_script_module.ts")
@@ -1382,7 +1394,7 @@
-benchmark(trt_script_module, input_shape=(1024, 1, 32, 32), dtype="fp16")
+benchmark(trt_script_module, input_shape=(1024, 1, 32, 32), dtype="fp16")
@@ -1421,9 +1433,9 @@
In this notebook, we have walked through the complete process of compiling TorchScript models with TRTorch and test the performance impact of the optimization.
-
+
What’s next
-
+
¶
diff --git a/docs/_notebooks/ssd-object-detection-demo.html b/docs/_notebooks/ssd-object-detection-demo.html
index 5843220367..2de3efd2d0 100644
--- a/docs/_notebooks/ssd-object-detection-demo.html
+++ b/docs/_notebooks/ssd-object-detection-demo.html
@@ -760,26 +760,26 @@
-# Copyright 2020 NVIDIA Corporation. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
+# Copyright 2020 NVIDIA Corporation. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
-
+
Object Detection with TRTorch (SSD)
@@ -877,9 +877,13 @@
-
- ## 1. Requirements
-
+
+
+
+ ## 1. Requirements
+
+
+
Follow the steps in
@@ -902,18 +906,22 @@
-%%capture
-%%bash
-# Known working versions
-pip install numpy==1.19 scipy==1.5.2 Pillow==6.2.0 scikit-image==0.17.2 matplotlib==3.3.0
+%%capture
+%%bash
+# Known working versions
+pip install numpy==1.19 scipy==1.5.2 Pillow==6.2.0 scikit-image==0.17.2 matplotlib==3.3.0
-
- ## 2. SSD
-
+
+
+
+ ## 2. SSD
+
+
+
Single Shot MultiBox Detector model for object detection
@@ -922,8 +930,8 @@
-
@@ -943,12 +951,12 @@
- 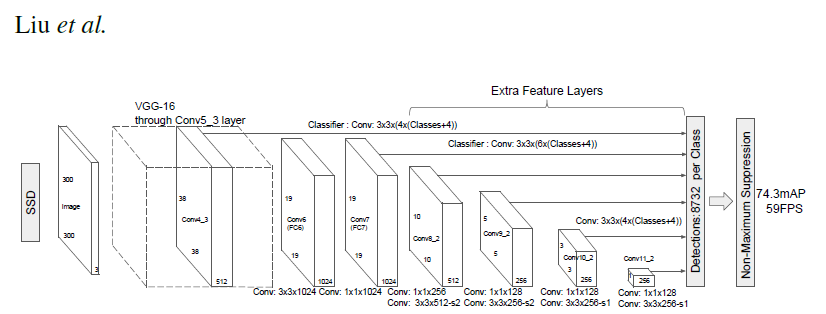 +
+ 
-
+
@@ -1007,10 +1015,10 @@
-import torch
+import torch
-# List of available models in PyTorch Hub from Nvidia/DeepLearningExamples
-torch.hub.list('NVIDIA/DeepLearningExamples:torchhub')
+# List of available models in PyTorch Hub from Nvidia/DeepLearningExamples
+torch.hub.list('NVIDIA/DeepLearningExamples:torchhub')
@@ -1057,9 +1065,9 @@
-# load SSD model pretrained on COCO from Torch Hub
-precision = 'fp32'
-ssd300 = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_ssd', model_math=precision);
+# load SSD model pretrained on COCO from Torch Hub
+precision = 'fp32'
+ssd300 = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_ssd', model_math=precision);
@@ -1103,23 +1111,23 @@
-# Sample images from the COCO validation set
-uris = [
- 'http://images.cocodataset.org/val2017/000000397133.jpg',
- 'http://images.cocodataset.org/val2017/000000037777.jpg',
- 'http://images.cocodataset.org/val2017/000000252219.jpg'
-]
+# Sample images from the COCO validation set
+uris = [
+ 'http://images.cocodataset.org/val2017/000000397133.jpg',
+ 'http://images.cocodataset.org/val2017/000000037777.jpg',
+ 'http://images.cocodataset.org/val2017/000000252219.jpg'
+]
-# For convenient and comprehensive formatting of input and output of the model, load a set of utility methods.
-utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_ssd_processing_utils')
+# For convenient and comprehensive formatting of input and output of the model, load a set of utility methods.
+utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_ssd_processing_utils')
-# Format images to comply with the network input
-inputs = [utils.prepare_input(uri) for uri in uris]
-tensor = utils.prepare_tensor(inputs, False)
+# Format images to comply with the network input
+inputs = [utils.prepare_input(uri) for uri in uris]
+tensor = utils.prepare_tensor(inputs, False)
-# The model was trained on COCO dataset, which we need to access in order to
-# translate class IDs into object names.
-classes_to_labels = utils.get_coco_object_dictionary()
+# The model was trained on COCO dataset, which we need to access in order to
+# translate class IDs into object names.
+classes_to_labels = utils.get_coco_object_dictionary()
@@ -1157,15 +1165,15 @@
-# Next, we run object detection
-model = ssd300.eval().to("cuda")
-detections_batch = model(tensor)
+# Next, we run object detection
+model = ssd300.eval().to("cuda")
+detections_batch = model(tensor)
-# By default, raw output from SSD network per input image contains 8732 boxes with
-# localization and class probability distribution.
-# Let’s filter this output to only get reasonable detections (confidence>40%) in a more comprehensive format.
-results_per_input = utils.decode_results(detections_batch)
-best_results_per_input = [utils.pick_best(results, 0.40) for results in results_per_input]
+# By default, raw output from SSD network per input image contains 8732 boxes with
+# localization and class probability distribution.
+# Let’s filter this output to only get reasonable detections (confidence>40%) in a more comprehensive format.
+results_per_input = utils.decode_results(detections_batch)
+best_results_per_input = [utils.pick_best(results, 0.40) for results in results_per_input]
@@ -1186,25 +1194,25 @@
-from matplotlib import pyplot as plt
-import matplotlib.patches as patches
+from matplotlib import pyplot as plt
+import matplotlib.patches as patches
-# The utility plots the images and predicted bounding boxes (with confidence scores).
-def plot_results(best_results):
- for image_idx in range(len(best_results)):
- fig, ax = plt.subplots(1)
- # Show original, denormalized image...
- image = inputs[image_idx] / 2 + 0.5
- ax.imshow(image)
- # ...with detections
- bboxes, classes, confidences = best_results[image_idx]
- for idx in range(len(bboxes)):
- left, bot, right, top = bboxes[idx]
- x, y, w, h = [val * 300 for val in [left, bot, right - left, top - bot]]
- rect = patches.Rectangle((x, y), w, h, linewidth=1, edgecolor='r', facecolor='none')
- ax.add_patch(rect)
- ax.text(x, y, "{} {:.0f}%".format(classes_to_labels[classes[idx] - 1], confidences[idx]*100), bbox=dict(facecolor='white', alpha=0.5))
- plt.show()
+# The utility plots the images and predicted bounding boxes (with confidence scores).
+def plot_results(best_results):
+ for image_idx in range(len(best_results)):
+ fig, ax = plt.subplots(1)
+ # Show original, denormalized image...
+ image = inputs[image_idx] / 2 + 0.5
+ ax.imshow(image)
+ # ...with detections
+ bboxes, classes, confidences = best_results[image_idx]
+ for idx in range(len(bboxes)):
+ left, bot, right, top = bboxes[idx]
+ x, y, w, h = [val * 300 for val in [left, bot, right - left, top - bot]]
+ rect = patches.Rectangle((x, y), w, h, linewidth=1, edgecolor='r', facecolor='none')
+ ax.add_patch(rect)
+ ax.text(x, y, "{} {:.0f}%".format(classes_to_labels[classes[idx] - 1], confidences[idx]*100), bbox=dict(facecolor='white', alpha=0.5))
+ plt.show()
@@ -1220,8 +1228,8 @@
-# Visualize results without TRTorch/TensorRT
-plot_results(best_results_per_input)
+# Visualize results without TRTorch/TensorRT
+plot_results(best_results_per_input)
@@ -1263,40 +1271,40 @@
-import time
-import numpy as np
+import time
+import numpy as np
-import torch.backends.cudnn as cudnn
-cudnn.benchmark = True
+import torch.backends.cudnn as cudnn
+cudnn.benchmark = True
-# Helper function to benchmark the model
-def benchmark(model, input_shape=(1024, 1, 32, 32), dtype='fp32', nwarmup=50, nruns=1000):
- input_data = torch.randn(input_shape)
- input_data = input_data.to("cuda")
- if dtype=='fp16':
- input_data = input_data.half()
+# Helper function to benchmark the model
+def benchmark(model, input_shape=(1024, 1, 32, 32), dtype='fp32', nwarmup=50, nruns=1000):
+ input_data = torch.randn(input_shape)
+ input_data = input_data.to("cuda")
+ if dtype=='fp16':
+ input_data = input_data.half()
- print("Warm up ...")
- with torch.no_grad():
- for _ in range(nwarmup):
- features = model(input_data)
- torch.cuda.synchronize()
- print("Start timing ...")
- timings = []
- with torch.no_grad():
- for i in range(1, nruns+1):
- start_time = time.time()
- pred_loc, pred_label = model(input_data)
- torch.cuda.synchronize()
- end_time = time.time()
- timings.append(end_time - start_time)
- if i%100==0:
- print('Iteration %d/%d, avg batch time %.2f ms'%(i, nruns, np.mean(timings)*1000))
+ print("Warm up ...")
+ with torch.no_grad():
+ for _ in range(nwarmup):
+ features = model(input_data)
+ torch.cuda.synchronize()
+ print("Start timing ...")
+ timings = []
+ with torch.no_grad():
+ for i in range(1, nruns+1):
+ start_time = time.time()
+ pred_loc, pred_label = model(input_data)
+ torch.cuda.synchronize()
+ end_time = time.time()
+ timings.append(end_time - start_time)
+ if i%100==0:
+ print('Iteration %d/%d, avg batch time %.2f ms'%(i, nruns, np.mean(timings)*1000))
- print("Input shape:", input_data.size())
- print("Output location prediction size:", pred_loc.size())
- print("Output label prediction size:", pred_label.size())
- print('Average batch time: %.2f ms'%(np.mean(timings)*1000))
+ print("Input shape:", input_data.size())
+ print("Output location prediction size:", pred_loc.size())
+ print("Output label prediction size:", pred_label.size())
+ print('Average batch time: %.2f ms'%(np.mean(timings)*1000))
@@ -1319,9 +1327,9 @@
-# Model benchmark without TRTorch/TensorRT
-model = ssd300.eval().to("cuda")
-benchmark(model, input_shape=(128, 3, 300, 300), nruns=1000)
+# Model benchmark without TRTorch/TensorRT
+model = ssd300.eval().to("cuda")
+benchmark(model, input_shape=(128, 3, 300, 300), nruns=1000)
@@ -1353,9 +1361,13 @@
-
- ## 3. Creating TorchScript modules
-
+
+
+
+ ## 3. Creating TorchScript modules
+
+
+
To compile with TRTorch, the model must first be in
@@ -1385,8 +1397,8 @@
-model = ssd300.eval().to("cuda")
-traced_model = torch.jit.trace(model, [torch.randn((1,3,300,300)).to("cuda")])
+model = ssd300.eval().to("cuda")
+traced_model = torch.jit.trace(model, [torch.randn((1,3,300,300)).to("cuda")])
@@ -1404,8 +1416,8 @@
-# This is just an example, and not required for the purposes of this demo
-torch.jit.save(traced_model, "ssd_300_traced.jit.pt")
+# This is just an example, and not required for the purposes of this demo
+torch.jit.save(traced_model, "ssd_300_traced.jit.pt")
@@ -1420,8 +1432,8 @@
-# Obtain the average time taken by a batch of input with Torchscript compiled modules
-benchmark(traced_model, input_shape=(128, 3, 300, 300), nruns=1000)
+# Obtain the average time taken by a batch of input with Torchscript compiled modules
+benchmark(traced_model, input_shape=(128, 3, 300, 300), nruns=1000)
@@ -1453,9 +1465,13 @@
-
- ## 4. Compiling with TRTorch TorchScript modules behave just like normal PyTorch modules and are intercompatible. From TorchScript we can now compile a TensorRT based module. This module will still be implemented in TorchScript but all the computation will be done in TensorRT.
-
+
+
+
+ ## 4. Compiling with TRTorch TorchScript modules behave just like normal PyTorch modules and are intercompatible. From TorchScript we can now compile a TensorRT based module. This module will still be implemented in TorchScript but all the computation will be done in TensorRT.
+
+
+
@@ -1466,23 +1482,27 @@
-import trtorch
+import trtorch
-# The compiled module will have precision as specified by "op_precision".
-# Here, it will have FP16 precision.
-trt_model = trtorch.compile(traced_model, {
- "input_shapes": [(3, 3, 300, 300)],
- "op_precision": torch.half, # Run with FP16
- "workspace_size": 1 << 20
-})
+# The compiled module will have precision as specified by "op_precision".
+# Here, it will have FP16 precision.
+trt_model = trtorch.compile(traced_model, {
+ "input_shapes": [(3, 3, 300, 300)],
+ "op_precision": torch.half, # Run with FP16
+ "workspace_size": 1 << 20
+})
-
- ## 5. Running Inference
-
+
+
+
+ ## 5. Running Inference
+
+
+
Next, we run object detection
@@ -1496,14 +1516,14 @@
-# using a TRTorch module is exactly the same as how we usually do inference in PyTorch i.e. model(inputs)
-detections_batch = trt_model(tensor.to(torch.half)) # convert the input to half precision
+# using a TRTorch module is exactly the same as how we usually do inference in PyTorch i.e. model(inputs)
+detections_batch = trt_model(tensor.to(torch.half)) # convert the input to half precision
-# By default, raw output from SSD network per input image contains 8732 boxes with
-# localization and class probability distribution.
-# Let’s filter this output to only get reasonable detections (confidence>40%) in a more comprehensive format.
-results_per_input = utils.decode_results(detections_batch)
-best_results_per_input_trt = [utils.pick_best(results, 0.40) for results in results_per_input]
+# By default, raw output from SSD network per input image contains 8732 boxes with
+# localization and class probability distribution.
+# Let’s filter this output to only get reasonable detections (confidence>40%) in a more comprehensive format.
+results_per_input = utils.decode_results(detections_batch)
+best_results_per_input_trt = [utils.pick_best(results, 0.40) for results in results_per_input]
@@ -1521,8 +1541,8 @@
-# Visualize results with TRTorch/TensorRT
-plot_results(best_results_per_input_trt)
+# Visualize results with TRTorch/TensorRT
+plot_results(best_results_per_input_trt)
@@ -1571,16 +1591,16 @@
-batch_size = 128
+batch_size = 128
-# Recompiling with batch_size we use for evaluating performance
-trt_model = trtorch.compile(traced_model, {
- "input_shapes": [(batch_size, 3, 300, 300)],
- "op_precision": torch.half, # Run with FP16
- "workspace_size": 1 << 20
-})
+# Recompiling with batch_size we use for evaluating performance
+trt_model = trtorch.compile(traced_model, {
+ "input_shapes": [(batch_size, 3, 300, 300)],
+ "op_precision": torch.half, # Run with FP16
+ "workspace_size": 1 << 20
+})
-benchmark(trt_model, input_shape=(batch_size, 3, 300, 300), nruns=1000, dtype="fp16")
+benchmark(trt_model, input_shape=(batch_size, 3, 300, 300), nruns=1000, dtype="fp16")
diff --git a/docs/genindex.html b/docs/genindex.html
index 49024a4473..d8854460f3 100644
--- a/docs/genindex.html
+++ b/docs/genindex.html
@@ -677,37 +677,21 @@
trtorch::CompileGraph (C++ function)
- ,
-
- [1]
-
trtorch::CompileSpec (C++ struct)
- ,
-
- [1]
-
trtorch::CompileSpec::allow_gpu_fallback (C++ member)
- ,
-
- [1]
-
trtorch::CompileSpec::capability (C++ member)
- ,
-
- [1]
-
@@ -721,34 +705,14 @@
[2]
- ,
-
- [3]
-
- ,
-
- [4]
-
- ,
-
- [5]
-
trtorch::CompileSpec::DataType (C++ class)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
@@ -764,40 +728,16 @@
[2]
,
-
- [3]
-
- ,
-
- [4]
-
- ,
-
- [5]
-
- ,
- [6]
+ [3]
,
- [7]
+ [4]
,
- [8]
-
- ,
-
- [9]
-
- ,
-
- [10]
-
- ,
-
- [11]
+ [5]
@@ -805,16 +745,8 @@
trtorch::CompileSpec::DataType::operator bool (C++ function)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
@@ -822,16 +754,8 @@
trtorch::CompileSpec::DataType::operator Value (C++ function)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
@@ -843,28 +767,12 @@
[1]
,
-
- [2]
-
- ,
-
- [3]
-
- ,
- [4]
+ [2]
,
- [5]
-
- ,
-
- [6]
-
- ,
-
- [7]
+ [3]
@@ -876,28 +784,12 @@
[1]
,
-
- [2]
-
- ,
-
- [3]
-
- ,
- [4]
+ [2]
,
- [5]
-
- ,
-
- [6]
-
- ,
-
- [7]
+ [3]
@@ -905,16 +797,8 @@
trtorch::CompileSpec::DataType::Value (C++ enum)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
@@ -922,16 +806,8 @@
trtorch::CompileSpec::DataType::Value::kChar (C++ enumerator)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
@@ -939,16 +815,8 @@
trtorch::CompileSpec::DataType::Value::kFloat (C++ enumerator)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
@@ -956,51 +824,27 @@
trtorch::CompileSpec::DataType::Value::kHalf (C++ enumerator)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
trtorch::CompileSpec::debug (C++ member)
- ,
-
- [1]
-
trtorch::CompileSpec::device (C++ member)
- ,
-
- [1]
-
trtorch::CompileSpec::DeviceType (C++ class)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
@@ -1016,40 +860,16 @@
[2]
,
-
- [3]
-
- ,
-
- [4]
-
- ,
-
- [5]
-
- ,
- [6]
+ [3]
,
- [7]
+ [4]
,
- [8]
-
- ,
-
- [9]
-
- ,
-
- [10]
-
- ,
-
- [11]
+ [5]
@@ -1057,16 +877,8 @@
trtorch::CompileSpec::DeviceType::operator bool (C++ function)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
@@ -1074,16 +886,8 @@
trtorch::CompileSpec::DeviceType::operator Value (C++ function)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
@@ -1091,16 +895,8 @@
trtorch::CompileSpec::DeviceType::operator!= (C++ function)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
@@ -1108,16 +904,8 @@
trtorch::CompileSpec::DeviceType::operator== (C++ function)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
@@ -1125,16 +913,8 @@
trtorch::CompileSpec::DeviceType::Value (C++ enum)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
@@ -1142,16 +922,8 @@
trtorch::CompileSpec::DeviceType::Value::kDLA (C++ enumerator)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
@@ -1159,62 +931,34 @@
trtorch::CompileSpec::DeviceType::Value::kGPU (C++ enumerator)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
trtorch::CompileSpec::EngineCapability (C++ enum)
- ,
-
- [1]
-
trtorch::CompileSpec::EngineCapability::kDEFAULT (C++ enumerator)
- ,
-
- [1]
-
trtorch::CompileSpec::EngineCapability::kSAFE_DLA (C++ enumerator)
- ,
-
- [1]
-
trtorch::CompileSpec::EngineCapability::kSAFE_GPU (C++ enumerator)
- ,
-
- [1]
-
trtorch::CompileSpec::input_ranges (C++ member)
- ,
-
- [1]
-
@@ -1224,14 +968,6 @@
[1]
- ,
-
- [2]
-
- ,
-
- [3]
-
@@ -1265,38 +1001,6 @@
[7]
- ,
-
- [8]
-
- ,
-
- [9]
-
- ,
-
- [10]
-
- ,
-
- [11]
-
- ,
-
- [12]
-
- ,
-
- [13]
-
- ,
-
- [14]
-
- ,
-
- [15]
-
@@ -1306,14 +1010,6 @@
[1]
- ,
-
- [2]
-
- ,
-
- [3]
-
@@ -1323,14 +1019,6 @@
[1]
- ,
-
- [2]
-
- ,
-
- [3]
-
@@ -1340,32 +1028,16 @@
[1]
- ,
-
- [2]
-
- ,
-
- [3]
-
trtorch::CompileSpec::max_batch_size (C++ member)
- ,
-
- [1]
-
trtorch::CompileSpec::num_avg_timing_iters (C++ member)
- ,
-
- [1]
-
@@ -1375,63 +1047,35 @@
trtorch::CompileSpec::num_min_timing_iters (C++ member)
- ,
-
- [1]
-
trtorch::CompileSpec::op_precision (C++ member)
- ,
-
- [1]
-
trtorch::CompileSpec::ptq_calibrator (C++ member)
- ,
-
- [1]
-
trtorch::CompileSpec::refit (C++ member)
- ,
-
- [1]
-
trtorch::CompileSpec::strict_types (C++ member)
- ,
-
- [1]
-
trtorch::CompileSpec::workspace_size (C++ member)
- ,
-
- [1]
-
-
- trtorch::ConvertGraphToTRTEngine (C++ function)
-
- ,
- [1]
+ trtorch::ConvertGraphToTRTEngine (C++ function)
diff --git a/docs/objects.inv b/docs/objects.inv
index 5b9856090f..15f76af02c 100644
Binary files a/docs/objects.inv and b/docs/objects.inv differ
diff --git a/docs/searchindex.js b/docs/searchindex.js
index 9eda3beb46..879b329c9c 100644
--- a/docs/searchindex.js
+++ b/docs/searchindex.js
@@ -1 +1 @@
-Search.setIndex({docnames:["_cpp_api/class_view_hierarchy","_cpp_api/classtrtorch_1_1CompileSpec_1_1DataType","_cpp_api/classtrtorch_1_1CompileSpec_1_1DeviceType","_cpp_api/classtrtorch_1_1ExtraInfo_1_1DataType","_cpp_api/classtrtorch_1_1ExtraInfo_1_1DeviceType","_cpp_api/classtrtorch_1_1ptq_1_1Int8CacheCalibrator","_cpp_api/classtrtorch_1_1ptq_1_1Int8Calibrator","_cpp_api/define_macros_8h_1a18d295a837ac71add5578860b55e5502","_cpp_api/define_macros_8h_1a20c1fbeb21757871c52299dc52351b5f","_cpp_api/define_macros_8h_1a25ee153c325dfc7466a33cbd5c1ff055","_cpp_api/define_macros_8h_1a48d6029a45583a06848891cb0e86f7ba","_cpp_api/define_macros_8h_1a71b02dddfabe869498ad5a88e11c440f","_cpp_api/define_macros_8h_1a9d31d0569348d109b1b069b972dd143e","_cpp_api/define_macros_8h_1abe87b341f562fd1cf40b7672e4d759da","_cpp_api/define_macros_8h_1ae1c56ab8a40af292a9a4964651524d84","_cpp_api/dir_cpp","_cpp_api/dir_cpp_api","_cpp_api/dir_cpp_api_include","_cpp_api/dir_cpp_api_include_trtorch","_cpp_api/enum_logging_8h_1a5f612ff2f783ff4fbe89d168f0d817d4","_cpp_api/file_cpp_api_include_trtorch_logging.h","_cpp_api/file_cpp_api_include_trtorch_macros.h","_cpp_api/file_cpp_api_include_trtorch_ptq.h","_cpp_api/file_cpp_api_include_trtorch_trtorch.h","_cpp_api/file_view_hierarchy","_cpp_api/function_logging_8h_1a118d65b179defff7fff279eb9cd126cb","_cpp_api/function_logging_8h_1a396a688110397538f8b3fb7dfdaf38bb","_cpp_api/function_logging_8h_1a9b420280bfacc016d7e36a5704021949","_cpp_api/function_logging_8h_1aa533955a2b908db9e5df5acdfa24715f","_cpp_api/function_logging_8h_1abc57d473f3af292551dee8b9c78373ad","_cpp_api/function_logging_8h_1adf5435f0dbb09c0d931a1b851847236b","_cpp_api/function_logging_8h_1aef44b69c62af7cf2edc8875a9506641a","_cpp_api/function_ptq_8h_1a4422781719d7befedb364cacd91c6247","_cpp_api/function_ptq_8h_1a5f33b142bc2f3f2aaf462270b3ad7e31","_cpp_api/function_trtorch_8h_1a2cf17d43ba9117b3b4d652744b4f0447","_cpp_api/function_trtorch_8h_1a3eace458ae9122f571fabfc9ef1b9e3a","_cpp_api/function_trtorch_8h_1a536bba54b70e44554099d23fa3d7e804","_cpp_api/function_trtorch_8h_1a726f6e7091b6b7be45b5a4275b2ffb10","_cpp_api/function_trtorch_8h_1ab01696cfe08b6a5293c55935a9713c25","_cpp_api/function_trtorch_8h_1ae38897d1ca4438227c970029d0f76fb5","_cpp_api/function_trtorch_8h_1af19cb866b0520fc84b69a1cf25a52b65","_cpp_api/namespace_trtorch","_cpp_api/namespace_trtorch__logging","_cpp_api/namespace_trtorch__ptq","_cpp_api/program_listing_file_cpp_api_include_trtorch_logging.h","_cpp_api/program_listing_file_cpp_api_include_trtorch_macros.h","_cpp_api/program_listing_file_cpp_api_include_trtorch_ptq.h","_cpp_api/program_listing_file_cpp_api_include_trtorch_trtorch.h","_cpp_api/structtrtorch_1_1CompileSpec","_cpp_api/structtrtorch_1_1CompileSpec_1_1InputRange","_cpp_api/structtrtorch_1_1ExtraInfo","_cpp_api/structtrtorch_1_1ExtraInfo_1_1InputRange","_cpp_api/trtorch_cpp","_cpp_api/unabridged_api","_cpp_api/unabridged_orphan","_notebooks/Resnet50-example","_notebooks/lenet-getting-started","_notebooks/ssd-object-detection-demo","contributors/conversion","contributors/lowering","contributors/phases","contributors/runtime","contributors/system_overview","contributors/useful_links","contributors/writing_converters","index","py_api/logging","py_api/trtorch","tutorials/getting_started","tutorials/installation","tutorials/ptq","tutorials/trtorchc","tutorials/use_from_pytorch"],envversion:{"sphinx.domains.c":2,"sphinx.domains.changeset":1,"sphinx.domains.citation":1,"sphinx.domains.cpp":3,"sphinx.domains.index":1,"sphinx.domains.javascript":2,"sphinx.domains.math":2,"sphinx.domains.python":2,"sphinx.domains.rst":2,"sphinx.domains.std":1,"sphinx.ext.intersphinx":1,nbsphinx:3,sphinx:56},filenames:["_cpp_api/class_view_hierarchy.rst","_cpp_api/classtrtorch_1_1CompileSpec_1_1DataType.rst","_cpp_api/classtrtorch_1_1CompileSpec_1_1DeviceType.rst","_cpp_api/classtrtorch_1_1ExtraInfo_1_1DataType.rst","_cpp_api/classtrtorch_1_1ExtraInfo_1_1DeviceType.rst","_cpp_api/classtrtorch_1_1ptq_1_1Int8CacheCalibrator.rst","_cpp_api/classtrtorch_1_1ptq_1_1Int8Calibrator.rst","_cpp_api/define_macros_8h_1a18d295a837ac71add5578860b55e5502.rst","_cpp_api/define_macros_8h_1a20c1fbeb21757871c52299dc52351b5f.rst","_cpp_api/define_macros_8h_1a25ee153c325dfc7466a33cbd5c1ff055.rst","_cpp_api/define_macros_8h_1a48d6029a45583a06848891cb0e86f7ba.rst","_cpp_api/define_macros_8h_1a71b02dddfabe869498ad5a88e11c440f.rst","_cpp_api/define_macros_8h_1a9d31d0569348d109b1b069b972dd143e.rst","_cpp_api/define_macros_8h_1abe87b341f562fd1cf40b7672e4d759da.rst","_cpp_api/define_macros_8h_1ae1c56ab8a40af292a9a4964651524d84.rst","_cpp_api/dir_cpp.rst","_cpp_api/dir_cpp_api.rst","_cpp_api/dir_cpp_api_include.rst","_cpp_api/dir_cpp_api_include_trtorch.rst","_cpp_api/enum_logging_8h_1a5f612ff2f783ff4fbe89d168f0d817d4.rst","_cpp_api/file_cpp_api_include_trtorch_logging.h.rst","_cpp_api/file_cpp_api_include_trtorch_macros.h.rst","_cpp_api/file_cpp_api_include_trtorch_ptq.h.rst","_cpp_api/file_cpp_api_include_trtorch_trtorch.h.rst","_cpp_api/file_view_hierarchy.rst","_cpp_api/function_logging_8h_1a118d65b179defff7fff279eb9cd126cb.rst","_cpp_api/function_logging_8h_1a396a688110397538f8b3fb7dfdaf38bb.rst","_cpp_api/function_logging_8h_1a9b420280bfacc016d7e36a5704021949.rst","_cpp_api/function_logging_8h_1aa533955a2b908db9e5df5acdfa24715f.rst","_cpp_api/function_logging_8h_1abc57d473f3af292551dee8b9c78373ad.rst","_cpp_api/function_logging_8h_1adf5435f0dbb09c0d931a1b851847236b.rst","_cpp_api/function_logging_8h_1aef44b69c62af7cf2edc8875a9506641a.rst","_cpp_api/function_ptq_8h_1a4422781719d7befedb364cacd91c6247.rst","_cpp_api/function_ptq_8h_1a5f33b142bc2f3f2aaf462270b3ad7e31.rst","_cpp_api/function_trtorch_8h_1a2cf17d43ba9117b3b4d652744b4f0447.rst","_cpp_api/function_trtorch_8h_1a3eace458ae9122f571fabfc9ef1b9e3a.rst","_cpp_api/function_trtorch_8h_1a536bba54b70e44554099d23fa3d7e804.rst","_cpp_api/function_trtorch_8h_1a726f6e7091b6b7be45b5a4275b2ffb10.rst","_cpp_api/function_trtorch_8h_1ab01696cfe08b6a5293c55935a9713c25.rst","_cpp_api/function_trtorch_8h_1ae38897d1ca4438227c970029d0f76fb5.rst","_cpp_api/function_trtorch_8h_1af19cb866b0520fc84b69a1cf25a52b65.rst","_cpp_api/namespace_trtorch.rst","_cpp_api/namespace_trtorch__logging.rst","_cpp_api/namespace_trtorch__ptq.rst","_cpp_api/program_listing_file_cpp_api_include_trtorch_logging.h.rst","_cpp_api/program_listing_file_cpp_api_include_trtorch_macros.h.rst","_cpp_api/program_listing_file_cpp_api_include_trtorch_ptq.h.rst","_cpp_api/program_listing_file_cpp_api_include_trtorch_trtorch.h.rst","_cpp_api/structtrtorch_1_1CompileSpec.rst","_cpp_api/structtrtorch_1_1CompileSpec_1_1InputRange.rst","_cpp_api/structtrtorch_1_1ExtraInfo.rst","_cpp_api/structtrtorch_1_1ExtraInfo_1_1InputRange.rst","_cpp_api/trtorch_cpp.rst","_cpp_api/unabridged_api.rst","_cpp_api/unabridged_orphan.rst","_notebooks/Resnet50-example.ipynb","_notebooks/lenet-getting-started.ipynb","_notebooks/ssd-object-detection-demo.ipynb","contributors/conversion.rst","contributors/lowering.rst","contributors/phases.rst","contributors/runtime.rst","contributors/system_overview.rst","contributors/useful_links.rst","contributors/writing_converters.rst","index.rst","py_api/logging.rst","py_api/trtorch.rst","tutorials/getting_started.rst","tutorials/installation.rst","tutorials/ptq.rst","tutorials/trtorchc.rst","tutorials/use_from_pytorch.rst"],objects:{"":{"trtorch::CheckMethodOperatorSupport":[38,1,1,"_CPPv4N7trtorch26CheckMethodOperatorSupportERKN5torch3jit6ModuleENSt6stringE"],"trtorch::CheckMethodOperatorSupport::method_name":[38,2,1,"_CPPv4N7trtorch26CheckMethodOperatorSupportERKN5torch3jit6ModuleENSt6stringE"],"trtorch::CheckMethodOperatorSupport::module":[38,2,1,"_CPPv4N7trtorch26CheckMethodOperatorSupportERKN5torch3jit6ModuleENSt6stringE"],"trtorch::CompileGraph":[39,1,1,"_CPPv4N7trtorch12CompileGraphERKN5torch3jit6ModuleE11CompileSpec"],"trtorch::CompileGraph::info":[39,2,1,"_CPPv4N7trtorch12CompileGraphERKN5torch3jit6ModuleE11CompileSpec"],"trtorch::CompileGraph::module":[39,2,1,"_CPPv4N7trtorch12CompileGraphERKN5torch3jit6ModuleE11CompileSpec"],"trtorch::CompileSpec":[50,3,1,"_CPPv4N7trtorch11CompileSpecE"],"trtorch::CompileSpec::CompileSpec":[50,1,1,"_CPPv4N7trtorch11CompileSpec11CompileSpecENSt6vectorINSt6vectorI7int64_tEEEE"],"trtorch::CompileSpec::CompileSpec::fixed_sizes":[50,2,1,"_CPPv4N7trtorch11CompileSpec11CompileSpecENSt6vectorINSt6vectorI7int64_tEEEE"],"trtorch::CompileSpec::CompileSpec::input_ranges":[50,2,1,"_CPPv4N7trtorch11CompileSpec11CompileSpecENSt6vectorI10InputRangeEE"],"trtorch::CompileSpec::DataType":[50,3,1,"_CPPv4N7trtorch11CompileSpec8DataTypeE"],"trtorch::CompileSpec::DataType::DataType":[50,1,1,"_CPPv4N7trtorch11CompileSpec8DataType8DataTypeEv"],"trtorch::CompileSpec::DataType::DataType::t":[50,2,1,"_CPPv4N7trtorch11CompileSpec8DataType8DataTypeEN3c1010ScalarTypeE"],"trtorch::CompileSpec::DataType::Value":[50,4,1,"_CPPv4N7trtorch11CompileSpec8DataType5ValueE"],"trtorch::CompileSpec::DataType::Value::kChar":[50,5,1,"_CPPv4N7trtorch11CompileSpec8DataType5Value5kCharE"],"trtorch::CompileSpec::DataType::Value::kFloat":[50,5,1,"_CPPv4N7trtorch11CompileSpec8DataType5Value6kFloatE"],"trtorch::CompileSpec::DataType::Value::kHalf":[50,5,1,"_CPPv4N7trtorch11CompileSpec8DataType5Value5kHalfE"],"trtorch::CompileSpec::DataType::operator Value":[50,1,1,"_CPPv4NK7trtorch11CompileSpec8DataTypecv5ValueEv"],"trtorch::CompileSpec::DataType::operator bool":[50,1,1,"_CPPv4N7trtorch11CompileSpec8DataTypecvbEv"],"trtorch::CompileSpec::DataType::operator!=":[50,1,1,"_CPPv4NK7trtorch11CompileSpec8DataTypeneEN8DataType5ValueE"],"trtorch::CompileSpec::DataType::operator!=::other":[50,2,1,"_CPPv4NK7trtorch11CompileSpec8DataTypeneEN8DataType5ValueE"],"trtorch::CompileSpec::DataType::operator==":[50,1,1,"_CPPv4NK7trtorch11CompileSpec8DataTypeeqEN8DataType5ValueE"],"trtorch::CompileSpec::DataType::operator==::other":[50,2,1,"_CPPv4NK7trtorch11CompileSpec8DataTypeeqEN8DataType5ValueE"],"trtorch::CompileSpec::DeviceType":[50,3,1,"_CPPv4N7trtorch11CompileSpec10DeviceTypeE"],"trtorch::CompileSpec::DeviceType::DeviceType":[50,1,1,"_CPPv4N7trtorch11CompileSpec10DeviceType10DeviceTypeEv"],"trtorch::CompileSpec::DeviceType::DeviceType::t":[50,2,1,"_CPPv4N7trtorch11CompileSpec10DeviceType10DeviceTypeEN3c1010DeviceTypeE"],"trtorch::CompileSpec::DeviceType::Value":[50,4,1,"_CPPv4N7trtorch11CompileSpec10DeviceType5ValueE"],"trtorch::CompileSpec::DeviceType::Value::kDLA":[50,5,1,"_CPPv4N7trtorch11CompileSpec10DeviceType5Value4kDLAE"],"trtorch::CompileSpec::DeviceType::Value::kGPU":[50,5,1,"_CPPv4N7trtorch11CompileSpec10DeviceType5Value4kGPUE"],"trtorch::CompileSpec::DeviceType::operator Value":[50,1,1,"_CPPv4NK7trtorch11CompileSpec10DeviceTypecv5ValueEv"],"trtorch::CompileSpec::DeviceType::operator bool":[50,1,1,"_CPPv4N7trtorch11CompileSpec10DeviceTypecvbEv"],"trtorch::CompileSpec::DeviceType::operator!=":[50,1,1,"_CPPv4NK7trtorch11CompileSpec10DeviceTypeneE10DeviceType"],"trtorch::CompileSpec::DeviceType::operator!=::other":[50,2,1,"_CPPv4NK7trtorch11CompileSpec10DeviceTypeneE10DeviceType"],"trtorch::CompileSpec::DeviceType::operator==":[50,1,1,"_CPPv4NK7trtorch11CompileSpec10DeviceTypeeqE10DeviceType"],"trtorch::CompileSpec::DeviceType::operator==::other":[50,2,1,"_CPPv4NK7trtorch11CompileSpec10DeviceTypeeqE10DeviceType"],"trtorch::CompileSpec::EngineCapability":[50,4,1,"_CPPv4N7trtorch11CompileSpec16EngineCapabilityE"],"trtorch::CompileSpec::EngineCapability::kDEFAULT":[50,5,1,"_CPPv4N7trtorch11CompileSpec16EngineCapability8kDEFAULTE"],"trtorch::CompileSpec::EngineCapability::kSAFE_DLA":[50,5,1,"_CPPv4N7trtorch11CompileSpec16EngineCapability9kSAFE_DLAE"],"trtorch::CompileSpec::EngineCapability::kSAFE_GPU":[50,5,1,"_CPPv4N7trtorch11CompileSpec16EngineCapability9kSAFE_GPUE"],"trtorch::CompileSpec::InputRange":[51,3,1,"_CPPv4N7trtorch11CompileSpec10InputRangeE"],"trtorch::CompileSpec::InputRange::InputRange":[51,1,1,"_CPPv4N7trtorch11CompileSpec10InputRange10InputRangeENSt6vectorI7int64_tEENSt6vectorI7int64_tEENSt6vectorI7int64_tEE"],"trtorch::CompileSpec::InputRange::InputRange::max":[51,2,1,"_CPPv4N7trtorch11CompileSpec10InputRange10InputRangeENSt6vectorI7int64_tEENSt6vectorI7int64_tEENSt6vectorI7int64_tEE"],"trtorch::CompileSpec::InputRange::InputRange::min":[51,2,1,"_CPPv4N7trtorch11CompileSpec10InputRange10InputRangeENSt6vectorI7int64_tEENSt6vectorI7int64_tEENSt6vectorI7int64_tEE"],"trtorch::CompileSpec::InputRange::InputRange::opt":[51,2,1,"_CPPv4N7trtorch11CompileSpec10InputRange10InputRangeENSt6vectorI7int64_tEENSt6vectorI7int64_tEENSt6vectorI7int64_tEE"],"trtorch::CompileSpec::InputRange::max":[51,6,1,"_CPPv4N7trtorch11CompileSpec10InputRange3maxE"],"trtorch::CompileSpec::InputRange::min":[51,6,1,"_CPPv4N7trtorch11CompileSpec10InputRange3minE"],"trtorch::CompileSpec::InputRange::opt":[51,6,1,"_CPPv4N7trtorch11CompileSpec10InputRange3optE"],"trtorch::CompileSpec::allow_gpu_fallback":[50,6,1,"_CPPv4N7trtorch11CompileSpec18allow_gpu_fallbackE"],"trtorch::CompileSpec::capability":[50,6,1,"_CPPv4N7trtorch11CompileSpec10capabilityE"],"trtorch::CompileSpec::debug":[50,6,1,"_CPPv4N7trtorch11CompileSpec5debugE"],"trtorch::CompileSpec::device":[50,6,1,"_CPPv4N7trtorch11CompileSpec6deviceE"],"trtorch::CompileSpec::input_ranges":[50,6,1,"_CPPv4N7trtorch11CompileSpec12input_rangesE"],"trtorch::CompileSpec::max_batch_size":[50,6,1,"_CPPv4N7trtorch11CompileSpec14max_batch_sizeE"],"trtorch::CompileSpec::num_avg_timing_iters":[50,6,1,"_CPPv4N7trtorch11CompileSpec20num_avg_timing_itersE"],"trtorch::CompileSpec::num_min_timing_iters":[50,6,1,"_CPPv4N7trtorch11CompileSpec20num_min_timing_itersE"],"trtorch::CompileSpec::op_precision":[50,6,1,"_CPPv4N7trtorch11CompileSpec12op_precisionE"],"trtorch::CompileSpec::ptq_calibrator":[50,6,1,"_CPPv4N7trtorch11CompileSpec14ptq_calibratorE"],"trtorch::CompileSpec::refit":[50,6,1,"_CPPv4N7trtorch11CompileSpec5refitE"],"trtorch::CompileSpec::strict_types":[50,6,1,"_CPPv4N7trtorch11CompileSpec12strict_typesE"],"trtorch::CompileSpec::workspace_size":[50,6,1,"_CPPv4N7trtorch11CompileSpec14workspace_sizeE"],"trtorch::ConvertGraphToTRTEngine":[40,1,1,"_CPPv4N7trtorch23ConvertGraphToTRTEngineERKN5torch3jit6ModuleENSt6stringE11CompileSpec"],"trtorch::ConvertGraphToTRTEngine::info":[40,2,1,"_CPPv4N7trtorch23ConvertGraphToTRTEngineERKN5torch3jit6ModuleENSt6stringE11CompileSpec"],"trtorch::ConvertGraphToTRTEngine::method_name":[40,2,1,"_CPPv4N7trtorch23ConvertGraphToTRTEngineERKN5torch3jit6ModuleENSt6stringE11CompileSpec"],"trtorch::ConvertGraphToTRTEngine::module":[40,2,1,"_CPPv4N7trtorch23ConvertGraphToTRTEngineERKN5torch3jit6ModuleENSt6stringE11CompileSpec"],"trtorch::dump_build_info":[37,1,1,"_CPPv4N7trtorch15dump_build_infoEv"],"trtorch::get_build_info":[34,1,1,"_CPPv4N7trtorch14get_build_infoEv"],"trtorch::logging::Level":[19,4,1,"_CPPv4N7trtorch7logging5LevelE"],"trtorch::logging::Level::kDEBUG":[19,5,1,"_CPPv4N7trtorch7logging5Level6kDEBUGE"],"trtorch::logging::Level::kERROR":[19,5,1,"_CPPv4N7trtorch7logging5Level6kERRORE"],"trtorch::logging::Level::kGRAPH":[19,5,1,"_CPPv4N7trtorch7logging5Level6kGRAPHE"],"trtorch::logging::Level::kINFO":[19,5,1,"_CPPv4N7trtorch7logging5Level5kINFOE"],"trtorch::logging::Level::kINTERNAL_ERROR":[19,5,1,"_CPPv4N7trtorch7logging5Level15kINTERNAL_ERRORE"],"trtorch::logging::Level::kWARNING":[19,5,1,"_CPPv4N7trtorch7logging5Level8kWARNINGE"],"trtorch::logging::get_is_colored_output_on":[27,1,1,"_CPPv4N7trtorch7logging24get_is_colored_output_onEv"],"trtorch::logging::get_logging_prefix":[31,1,1,"_CPPv4N7trtorch7logging18get_logging_prefixEv"],"trtorch::logging::get_reportable_log_level":[25,1,1,"_CPPv4N7trtorch7logging24get_reportable_log_levelEv"],"trtorch::logging::log":[29,1,1,"_CPPv4N7trtorch7logging3logE5LevelNSt6stringE"],"trtorch::logging::log::lvl":[29,2,1,"_CPPv4N7trtorch7logging3logE5LevelNSt6stringE"],"trtorch::logging::log::msg":[29,2,1,"_CPPv4N7trtorch7logging3logE5LevelNSt6stringE"],"trtorch::logging::set_is_colored_output_on":[28,1,1,"_CPPv4N7trtorch7logging24set_is_colored_output_onEb"],"trtorch::logging::set_is_colored_output_on::colored_output_on":[28,2,1,"_CPPv4N7trtorch7logging24set_is_colored_output_onEb"],"trtorch::logging::set_logging_prefix":[26,1,1,"_CPPv4N7trtorch7logging18set_logging_prefixENSt6stringE"],"trtorch::logging::set_logging_prefix::prefix":[26,2,1,"_CPPv4N7trtorch7logging18set_logging_prefixENSt6stringE"],"trtorch::logging::set_reportable_log_level":[30,1,1,"_CPPv4N7trtorch7logging24set_reportable_log_levelE5Level"],"trtorch::logging::set_reportable_log_level::lvl":[30,2,1,"_CPPv4N7trtorch7logging24set_reportable_log_levelE5Level"],"trtorch::ptq::Int8CacheCalibrator":[5,3,1,"_CPPv4I0EN7trtorch3ptq19Int8CacheCalibratorE"],"trtorch::ptq::Int8CacheCalibrator::Algorithm":[5,7,1,"_CPPv4I0EN7trtorch3ptq19Int8CacheCalibratorE"],"trtorch::ptq::Int8CacheCalibrator::Int8CacheCalibrator":[5,1,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibrator19Int8CacheCalibratorERKNSt6stringE"],"trtorch::ptq::Int8CacheCalibrator::Int8CacheCalibrator::cache_file_path":[5,2,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibrator19Int8CacheCalibratorERKNSt6stringE"],"trtorch::ptq::Int8CacheCalibrator::getBatch":[5,1,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibrator8getBatchEA_PvA_PKci"],"trtorch::ptq::Int8CacheCalibrator::getBatch::bindings":[5,2,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibrator8getBatchEA_PvA_PKci"],"trtorch::ptq::Int8CacheCalibrator::getBatch::names":[5,2,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibrator8getBatchEA_PvA_PKci"],"trtorch::ptq::Int8CacheCalibrator::getBatch::nbBindings":[5,2,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibrator8getBatchEA_PvA_PKci"],"trtorch::ptq::Int8CacheCalibrator::getBatchSize":[5,1,1,"_CPPv4NK7trtorch3ptq19Int8CacheCalibrator12getBatchSizeEv"],"trtorch::ptq::Int8CacheCalibrator::operator nvinfer1::IInt8Calibrator*":[5,1,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibratorcvPN8nvinfer115IInt8CalibratorEEv"],"trtorch::ptq::Int8CacheCalibrator::readCalibrationCache":[5,1,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibrator20readCalibrationCacheER6size_t"],"trtorch::ptq::Int8CacheCalibrator::readCalibrationCache::length":[5,2,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibrator20readCalibrationCacheER6size_t"],"trtorch::ptq::Int8CacheCalibrator::writeCalibrationCache":[5,1,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibrator21writeCalibrationCacheEPKv6size_t"],"trtorch::ptq::Int8CacheCalibrator::writeCalibrationCache::cache":[5,2,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibrator21writeCalibrationCacheEPKv6size_t"],"trtorch::ptq::Int8CacheCalibrator::writeCalibrationCache::length":[5,2,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibrator21writeCalibrationCacheEPKv6size_t"],"trtorch::ptq::Int8Calibrator":[6,3,1,"_CPPv4I00EN7trtorch3ptq14Int8CalibratorE"],"trtorch::ptq::Int8Calibrator::Algorithm":[6,7,1,"_CPPv4I00EN7trtorch3ptq14Int8CalibratorE"],"trtorch::ptq::Int8Calibrator::DataLoaderUniquePtr":[6,7,1,"_CPPv4I00EN7trtorch3ptq14Int8CalibratorE"],"trtorch::ptq::Int8Calibrator::Int8Calibrator":[6,1,1,"_CPPv4N7trtorch3ptq14Int8Calibrator14Int8CalibratorE19DataLoaderUniquePtrRKNSt6stringEb"],"trtorch::ptq::Int8Calibrator::Int8Calibrator::cache_file_path":[6,2,1,"_CPPv4N7trtorch3ptq14Int8Calibrator14Int8CalibratorE19DataLoaderUniquePtrRKNSt6stringEb"],"trtorch::ptq::Int8Calibrator::Int8Calibrator::dataloader":[6,2,1,"_CPPv4N7trtorch3ptq14Int8Calibrator14Int8CalibratorE19DataLoaderUniquePtrRKNSt6stringEb"],"trtorch::ptq::Int8Calibrator::Int8Calibrator::use_cache":[6,2,1,"_CPPv4N7trtorch3ptq14Int8Calibrator14Int8CalibratorE19DataLoaderUniquePtrRKNSt6stringEb"],"trtorch::ptq::Int8Calibrator::getBatch":[6,1,1,"_CPPv4N7trtorch3ptq14Int8Calibrator8getBatchEA_PvA_PKci"],"trtorch::ptq::Int8Calibrator::getBatch::bindings":[6,2,1,"_CPPv4N7trtorch3ptq14Int8Calibrator8getBatchEA_PvA_PKci"],"trtorch::ptq::Int8Calibrator::getBatch::names":[6,2,1,"_CPPv4N7trtorch3ptq14Int8Calibrator8getBatchEA_PvA_PKci"],"trtorch::ptq::Int8Calibrator::getBatch::nbBindings":[6,2,1,"_CPPv4N7trtorch3ptq14Int8Calibrator8getBatchEA_PvA_PKci"],"trtorch::ptq::Int8Calibrator::getBatchSize":[6,1,1,"_CPPv4NK7trtorch3ptq14Int8Calibrator12getBatchSizeEv"],"trtorch::ptq::Int8Calibrator::operator nvinfer1::IInt8Calibrator*":[6,1,1,"_CPPv4N7trtorch3ptq14Int8CalibratorcvPN8nvinfer115IInt8CalibratorEEv"],"trtorch::ptq::Int8Calibrator::readCalibrationCache":[6,1,1,"_CPPv4N7trtorch3ptq14Int8Calibrator20readCalibrationCacheER6size_t"],"trtorch::ptq::Int8Calibrator::readCalibrationCache::length":[6,2,1,"_CPPv4N7trtorch3ptq14Int8Calibrator20readCalibrationCacheER6size_t"],"trtorch::ptq::Int8Calibrator::writeCalibrationCache":[6,1,1,"_CPPv4N7trtorch3ptq14Int8Calibrator21writeCalibrationCacheEPKv6size_t"],"trtorch::ptq::Int8Calibrator::writeCalibrationCache::cache":[6,2,1,"_CPPv4N7trtorch3ptq14Int8Calibrator21writeCalibrationCacheEPKv6size_t"],"trtorch::ptq::Int8Calibrator::writeCalibrationCache::length":[6,2,1,"_CPPv4N7trtorch3ptq14Int8Calibrator21writeCalibrationCacheEPKv6size_t"],"trtorch::ptq::make_int8_cache_calibrator":[33,1,1,"_CPPv4I0EN7trtorch3ptq26make_int8_cache_calibratorE19Int8CacheCalibratorI9AlgorithmERKNSt6stringE"],"trtorch::ptq::make_int8_cache_calibrator::Algorithm":[33,7,1,"_CPPv4I0EN7trtorch3ptq26make_int8_cache_calibratorE19Int8CacheCalibratorI9AlgorithmERKNSt6stringE"],"trtorch::ptq::make_int8_cache_calibrator::cache_file_path":[33,2,1,"_CPPv4I0EN7trtorch3ptq26make_int8_cache_calibratorE19Int8CacheCalibratorI9AlgorithmERKNSt6stringE"],"trtorch::ptq::make_int8_calibrator":[32,1,1,"_CPPv4I00EN7trtorch3ptq20make_int8_calibratorE14Int8CalibratorI9Algorithm10DataLoaderE10DataLoaderRKNSt6stringEb"],"trtorch::ptq::make_int8_calibrator::Algorithm":[32,7,1,"_CPPv4I00EN7trtorch3ptq20make_int8_calibratorE14Int8CalibratorI9Algorithm10DataLoaderE10DataLoaderRKNSt6stringEb"],"trtorch::ptq::make_int8_calibrator::DataLoader":[32,7,1,"_CPPv4I00EN7trtorch3ptq20make_int8_calibratorE14Int8CalibratorI9Algorithm10DataLoaderE10DataLoaderRKNSt6stringEb"],"trtorch::ptq::make_int8_calibrator::cache_file_path":[32,2,1,"_CPPv4I00EN7trtorch3ptq20make_int8_calibratorE14Int8CalibratorI9Algorithm10DataLoaderE10DataLoaderRKNSt6stringEb"],"trtorch::ptq::make_int8_calibrator::dataloader":[32,2,1,"_CPPv4I00EN7trtorch3ptq20make_int8_calibratorE14Int8CalibratorI9Algorithm10DataLoaderE10DataLoaderRKNSt6stringEb"],"trtorch::ptq::make_int8_calibrator::use_cache":[32,2,1,"_CPPv4I00EN7trtorch3ptq20make_int8_calibratorE14Int8CalibratorI9Algorithm10DataLoaderE10DataLoaderRKNSt6stringEb"],STR:[7,0,1,"c.STR"],TRTORCH_API:[8,0,1,"c.TRTORCH_API"],TRTORCH_HIDDEN:[9,0,1,"c.TRTORCH_HIDDEN"],TRTORCH_MAJOR_VERSION:[10,0,1,"c.TRTORCH_MAJOR_VERSION"],TRTORCH_MINOR_VERSION:[14,0,1,"c.TRTORCH_MINOR_VERSION"],TRTORCH_PATCH_VERSION:[11,0,1,"c.TRTORCH_PATCH_VERSION"],TRTORCH_VERSION:[12,0,1,"c.TRTORCH_VERSION"],XSTR:[13,0,1,"c.XSTR"],trtorch:[67,8,0,"-"]},"trtorch.logging":{Level:[66,9,1,""],get_is_colored_output_on:[66,10,1,""],get_logging_prefix:[66,10,1,""],get_reportable_log_level:[66,10,1,""],log:[66,10,1,""],set_is_colored_output_on:[66,10,1,""],set_logging_prefix:[66,10,1,""],set_reportable_log_level:[66,10,1,""]},"trtorch.logging.Level":{Debug:[66,11,1,""],Error:[66,11,1,""],Info:[66,11,1,""],InternalError:[66,11,1,""],Warning:[66,11,1,""]},trtorch:{DeviceType:[67,9,1,""],EngineCapability:[67,9,1,""],TensorRTCompileSpec:[67,10,1,""],check_method_op_support:[67,10,1,""],compile:[67,10,1,""],convert_method_to_trt_engine:[67,10,1,""],dtype:[67,9,1,""],dump_build_info:[67,10,1,""],get_build_info:[67,10,1,""],logging:[66,8,0,"-"]}},objnames:{"0":["c","macro","C macro"],"1":["cpp","function","C++ function"],"10":["py","function","Python function"],"11":["py","attribute","Python attribute"],"2":["cpp","functionParam","functionParam"],"3":["cpp","class","C++ class"],"4":["cpp","enum","C++ enum"],"5":["cpp","enumerator","C++ enumerator"],"6":["cpp","member","C++ member"],"7":["cpp","templateParam","templateParam"],"8":["py","module","Python module"],"9":["py","class","Python class"]},objtypes:{"0":"c:macro","1":"cpp:function","10":"py:function","11":"py:attribute","2":"cpp:functionParam","3":"cpp:class","4":"cpp:enum","5":"cpp:enumerator","6":"cpp:member","7":"cpp:templateParam","8":"py:module","9":"py:class"},terms:{"001s":55,"00f1b6db":55,"01s":55,"04s":55,"07s":55,"0c106ec84f199a0fbcf1199010166986da732f9b0907768c9ac5ea5b120772db":69,"11k":55,"12a":55,"16280mib":55,"1x1":57,"24k":55,"2_20200626":69,"2c365_subsampl":55,"2mib":55,"300w":55,"300x300":57,"31c":55,"32w":55,"32x32":55,"33c":55,"33w":55,"34c":55,"34w":55,"353k":55,"35c":55,"35k":55,"35w":55,"36c":55,"37c":55,"43w":55,"442k":55,"4fef":55,"53k":55,"55k":55,"774kb":55,"818977576572eadaf62c80434a25afe44dbaa32ebda3a0919e389dcbe74f8656":69,"81k":55,"84e944ff11f8":55,"891mib":55,"9205bed204e2ae7aafd2e01cce0f21309e281e18d5bfd7172ef8541771539d41":69,"94k":55,"9ab0":55,"abstract":[61,64],"byte":67,"case":[1,2,3,4,48,50,56,57,58,61,64,69,70],"catch":[59,68],"char":[5,6,46,68],"class":[32,33,46,47,48,50,54,55,56,57,61,64,66,67,68,70],"const":[1,2,3,4,5,6,32,33,35,36,38,39,40,46,47,48,50,59,64,68,70],"default":[1,2,3,4,5,6,19,32,33,45,47,48,50,55,57,67,68,70,71,72],"enum":[1,2,3,4,44,47,48,50,54,66,70],"export":69,"final":[58,60,62,69],"float":[67,68,71],"function":[1,2,3,4,5,6,48,49,50,51,54,55,56,57,59,61,64,68,72],"import":[55,56,57,59,68,71,72],"int":[5,6,46,68],"long":58,"new":[1,2,3,4,5,6,35,39,48,49,50,51,55,56,61,62,64,66,68],"public":[1,2,3,4,5,6,46,47,48,49,50,51,70],"return":[1,2,3,4,5,6,25,27,32,33,34,35,36,38,39,40,44,45,46,47,48,50,55,56,59,60,61,62,64,66,67,68,70],"short":59,"static":[48,49,50,51,58,64,67,68],"super":[46,56,68],"throw":[59,68],"true":[1,2,3,4,6,47,48,50,55,56,57,59,64,67,68,70,72],"try":[55,56,62,68,72],"void":[5,6,26,28,29,30,37,44,46,47],"while":70,And:68,Are:44,Bus:55,But:68,CompileSpec:[],CompileSpecstruct:[],For:[55,56,57,58,68,69,72],IDs:57,Its:64,Not:5,One:[67,68],PRs:68,Thats:68,The:[2,4,48,50,55,56,57,58,59,60,61,62,64,66,69,70,71,72],Then:[69,70,72],There:[6,55,57,58,64,68,70],These:[58,61],Use:[48,50,64,67,70],Useful:65,Using:[6,55,57,65],Will:38,With:[55,68,70],___torch_mangle_10:68,___torch_mangle_4847:61,___torch_mangle_5:68,___torch_mangle_9:68,__attribute__:45,__gnuc__:45,__init__:[56,68],__torch__:[61,68],__torch___pytorch_detection_ssd_src_model_ssd300_trt_engin:61,__torch___torchvision_models_resnet____torch_mangle_4847_resnet_trt_engin:61,__visibility__:45,_all_:59,_convolut:68,_jit_to_tensorrt:[67,72],a100:[55,56],aarch64:62,abl:[55,56,58,59,64,65,70,72],about:[57,58,61,64,67,68,71],abov:[30,57,68],acceler:[55,56,68],accept:[48,49,50,51,61,64,71],access:[57,59,64,65,68,72],accord:64,accuraci:[57,70],achiev:[55,56],across:59,acthardtanh:64,activ:[68,70],activationtyp:64,actual:[56,59,61,64,66,68],adaptiveavgpool2d:55,add:[29,58,59,64,66,68,69],add_:[59,68],add_patch:57,addactiv:64,added:[30,58],addit:[57,59,68],addlay:68,addshuffl:68,advanc:70,affin:55,after:[57,58,65,68,71],again:[46,57,61,64],against:[68,71],agre:[55,56,57],ahead:68,aim:59,algorithm:[5,6,32,33,46,70],all:[19,44,45,46,47,55,56,57,59,61,67,68,70,71],alloc:64,allow:[48,49,50,51,55,56,57,58,59,67,71],allow_gpu_fallback:[47,48,50,67,72],almost:68,alpha:57,alreadi:[55,58,59,68,71],also:[33,55,56,57,58,64,65,68,69,70],alwai:[5,6,28],amazonaw:55,amp:55,analog:68,analogu:64,analysi:[55,57],ani:[55,56,57,58,64,67,68,69,71],annot:[57,64,68],anoth:68,aot:[65,68],apach:[55,56,57],apex:57,api:[15,17,18,44,45,46,47,62,64,67,68,70,72],apidirectori:[24,52],append:[55,56,57],appli:70,applic:[2,4,33,48,50,55,56,57,59,62,68,71,72],approach:[55,56],apr:68,aquir:68,architectur:[57,65,69],archiv:69,aren:68,arg:[58,68],argc:68,argmax:55,argument:[59,61,64,68,71],argv:68,around:[61,64,68],arrai:[5,6,58],arrayref:[47,48,49,50,51],arti:55,arxiv:70,aspect:71,assembl:[58,68],assign:[5,6],associ:[58,64,68],associatevalueandivalu:64,associatevalueandtensor:[64,68],assum:72,aten:[59,63,64,68],attach:57,attribut:[59,61,68],aug:55,auto:[46,64,68,70],automat:[55,56,68],avail:[55,56,57,64,69],ave:[55,56],averag:[48,50,55,56,57,67,71],avg:[57,71],avgpool:[55,57],avoid:55,await:55,axes:55,axi:55,back:[59,61,62,68],back_insert:46,backbon:57,backend:[55,56,57,67,72],background:57,base:[37,52,53,55,56,57,61,66,68,69,70],bash:[57,69],basi:[55,56,57],basic:71,batch:[5,6,46,48,50,55,56,57,67,70,71],batch_norm:64,batch_siz:[46,57,70],batched_data_:46,batchnorm2d:55,batchnorm:[57,59],batchtyp:46,bazel:[62,69],bazel_vers:69,bazelbuild:69,bazelisk:69,bazelvers:69,bbox:57,bdist_wheel:69,becaus:[64,68,69],becom:64,been:[58,64,68],befor:[57,59,62,64,65,68,69],begin:[46,69],beginn:68,behav:[55,57],behavior:67,being:68,below:[57,64,68],benchmark:56,benefit:[64,68],best:[48,49,50,51,55,56,69],best_result:57,best_results_per_input:57,best_results_per_input_trt:57,better:[55,56,57,68,70],between:[57,64,70],bia:[55,56,59,68],bin:[55,69],binari:[46,70],bind:[5,6,46],bird:55,bit:[64,67,68],blob:63,block0:59,block1:59,block:[58,59],bn1:55,bn2:55,bn3:55,bool:[1,2,3,4,5,6,27,28,32,38,44,46,47,48,50,59,64,66,67,68,70],bot:57,both:[55,56,57,68,69],bottleneck:55,bound:57,box:57,branch:69,breed:55,briefli:68,bsd:[44,45,46,47],buffer:[5,6],bug:69,build:[32,33,34,48,50,58,60,62,64,67,68,70,71],build_fil:69,builderconfig:47,built:[62,69,71],bust:55,bzl:69,c10:[1,2,3,4,47,48,49,50,51,68,70],c96b:55,c_api:63,c_str:[64,68],cach:[5,6,32,33,46,55,57,68,70,71],cache_:46,cache_fil:46,cache_file_path:[5,6,32,33,46],cache_file_path_:46,cache_size_:46,calcul:[58,68],calibr:[5,6,32,33,46,48,50,68,70,71],calibration_cache_fil:[32,33,70],calibration_dataload:[32,70],calibration_dataset:70,call:[32,33,35,39,48,50,55,56,57,59,61,64,67,68,72],callmethod:68,can:[1,2,3,4,6,32,33,36,40,48,49,50,51,55,56,57,58,59,60,61,62,64,67,68,69,70,71,72],cannot:[55,56,57,59,68],cap:55,capabl:[47,48,50,67,71,72],captur:57,cast:[5,6,59],cat:69,caught:59,caus:[64,69],cdll:68,ceil_mod:55,cell:57,centercrop:55,cerr:68,certifi:55,cf0691493d05062fe3239cf76773bae4c5124f4b039050dbdd291c652af3ab2a:69,chain:64,chanc:64,chang:[33,55,56,59,62,70],channel:55,check:[1,2,3,4,38,48,50,57,59,64,67,68,69,71],check_method_op_support:67,checkmethodoperatorsupport:[23,41,47,52,53,68],checkpoint:57,checkpoint_from_distribut:57,chimpansee_amber_r_1920x1080:55,chimpanze:55,choos:[68,69],cifar10:70,cifar:70,classes_to_label:57,classif:[56,57,68],classifi:56,clear:46,cli:[68,71],close:68,closer:59,cloudfront:55,coco:57,cocodataset:57,code:[55,56,57,62,65,68],collect:68,color:[27,28,66],colored_output_on:[28,44,66],com:[55,56,63,68,69,70],come:[55,56],command:[55,68,69,71],comment:69,common:[55,57,58,59],common_subexpression_elimin:59,commun:68,compar:57,comparis:[1,3,48,50],comparison:[2,4,48,50],compat:[1,2,3,4,48,50,59,61,69],compil:[35,36,38,39,40,48,50,55,56,57,59,61,64,67,70,71,72],compile_set:[56,68],compile_spec:[67,70],compilegraph:[23,41,47,52,53,68,70],compilespec:[0,5,6,23,35,36,39,40,41,47,52,53,67,68,70],compilespecstruct:[0,52],complet:[55,56,57,68],complex:68,compli:57,complianc:[55,56,57],compliat:70,compon:[56,60,62,68],compos:[55,56,57,68],composit:68,comprehens:57,comput:[55,56,57,69,70],conclus:55,condit:[55,56,57],confid:[55,57],config:69,configur:[35,36,39,40,65,67,68,69,70],connect:[55,59],consid:[55,68],consol:71,consolid:68,constant:[58,59,68],constexpr:[1,2,3,4,47,48,50],construct:[1,2,3,4,5,6,48,49,50,51,58,59,60,62,64,68],constructor:[1,3,48,50,61,68],consum:[6,58,68],contain:[32,38,55,56,57,58,59,64,67,68,69,70],content:70,context:[58,60,61,62],continu:[55,56,57],contributor:68,control:[55,56,57,68],conv1:[55,56,68],conv2:[55,56,68],conv2d:[55,56,68],conv3:55,conv4_x:57,conv5_x:57,conv:68,conveni:57,convers:[55,57,59,61,67,68],conversionctx:[64,68],convert:[5,6,35,36,38,39,40,56,57,59,60,62,65,67,72],convert_method_to_trt_engin:[67,72],convertgraphtotrtengin:[23,41,47,52,53,68],convien:[48,50],convienc:[5,6],convolut:[57,70],coordin:62,copi:[46,55,56,57,64],copyright:[44,45,46,47,55,56,57,68],core:[55,56,57,59,62,68],corpor:[44,45,46,47,55,56,57],correct:69,correspond:[55,57,64],coupl:[55,56,58,62],cout:68,cp35:[],cp35m:[],cp36:69,cp36m:69,cp37:69,cp37m:69,cp38:69,cpp:[16,17,18,44,45,46,47,54,59,62,68,70],cpp_frontend:70,cppdirectori:[24,52],cppdoc:68,creat:[32,33,55,56,57,58,61,64,67,71],credit:68,csrc:[59,63],cstddef:70,ctx:[64,68],ctype:68,cu102:69,cuda:[48,50,55,56,57,61,67,68,69,72],cudafloattyp:68,cudnn8:69,cudnn:[55,56,57],curl:69,current:[25,64],custom:69,cycler:55,d17fnq9dkz9hgj:55,data:[1,3,5,6,32,33,46,48,50,55,56,57,58,60,62,64,70],data_dir:70,dataflow:[64,68],dataload:[6,32,33,46,48,50,70],dataloader_:46,dataloaderopt:70,dataloaderuniqueptr:[6,46],dataset:[33,57,70],datatyp:[2,4,23,41,47,48,50,52,53,67],datatypeclass:[0,52],dateutil:55,dbg:69,dead_code_elimin:59,deal:64,debug:[19,28,47,48,50,64,66,67,71,72],debugg:[67,71],decid:56,decod:55,decode_result:57,dedic:59,deep:[55,56,57,64,65,70],deeplearn:63,deeplearningexampl:57,def:[55,56,57,68],defin:[1,2,3,4,5,6,19,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,45,48,49,50,51,54,55,56,68,70,71],definit:[54,64],delet:[1,2,3,4,47,48,50,59],demo:[55,57,70],demonstr:[55,56,57],denorm:57,dep:69,depend:[33,34,55,57,58,62,68],depickl:61,deploi:[55,56,65,68,70],deploy:[55,56,68,70,71],describ:[48,50,55,56,57,64,67,68,72],deseri:[67,68],design:[55,56],destroi:64,destructor:64,detail:[55,68],detect:[55,61],detections_batch:57,determin:59,develop:[55,56,65,68,69],deviat:71,devic:[2,4,47,48,50,55,56,67,68,71],device_typ:[67,72],devicetyp:[0,23,41,47,48,50,52,53,67],dict:[57,67],dictionari:[67,68,72],differ:[33,56,57,59,62,65,68],differenti:[55,56],dilat:55,dim:55,dimens:59,directli:[64,65,70],directori:[20,21,22,23,24,44,45,46,47,52,55,69,70],disabl:[66,69,71],disclos:69,disp:55,displai:71,dist:[55,69],distdir:69,distribut:[55,56,57,67,68,70],dla:[2,4,48,50,67,71],doc:[62,63,69],docker:[55,56,57],docsrc:62,document:[44,45,46,47,52,53,62,68,70,72],doe:[45,46,55,57,59,64,70],doesn:68,doing:[57,58,59,68,70],domain:70,don:[56,64,70],done:[55,57,58,62],dont:44,down:[55,56,69],download:[57,69],downsampl:55,doxygen_should_skip_thi:[46,47],driver:[55,69],drop:[57,69],dtype:[55,56,57,67],due:[5,6,55,57],dump:[37,69,71],dump_build_info:[23,41,47,52,53,67],dure:[64,70,71],dynam:[48,49,50,51,67],each:[5,6,48,50,57,58,59,61,64,67,68],eager:[55,56],earlier:55,easi:[58,59,68,71],easier:[60,62,64,68,70],easiest:69,easili:[5,6],ecc:55,ecosystem:[55,56,57],edgecolor:57,edu:70,effect:[59,68,70],effici:64,either:[48,49,50,51,55,56,57,64,67,68,69,71],element:61,element_typ:46,els:[45,46,67],emb:68,embed:[61,68,71],emit:58,empti:[56,68],emum:[19,48,50],enabl:[5,6,27,55,56,57,66,67],encount:69,end:[46,64,68],end_dim:68,end_tim:[55,56,57],endif:[45,46,47],enforc:68,engin:[1,2,3,4,35,36,39,40,48,49,50,51,58,60,62,65,67,68,70,71,72],engine_converted_from_jit:68,enginecap:[47,48,50,67,72],enhanc:57,ensur:[33,59],enter:58,entri:[48,50,64,67],entropi:[32,33,70],enumer:[1,2,3,4,19,48,50],eps:55,equival:[35,39,55,56,57,60,62,64,67,68],equivil:[36,40],error:[19,58,59,62,66,68,69],etc:67,eval:[55,56,57,68],evalu:[57,60,61,62],evaluated_value_map:[58,64],even:68,everi:68,everyth:19,exactli:57,exampl:[55,56,57,61,62,64,68,70],except:[55,56,57],exception_elimin:59,execpt:59,execut:[55,56,57,59,60,61,62,67,68,70],execute_engin:[61,68],exeuct:61,exhaust:68,exist:[6,35,36,38,39,40,55,67,69,70],expand:59,expect:[55,59,64,68],experi:[55,56],explic:46,explicit:[5,6,47,59,65,70],explicitli:[70,72],explict:46,explictli:[1,3,48,50],express:[55,56,57],extend:[60,62,64,68],extent:[65,68],extra:[48,50,68],extract:68,extractor:56,f16:[68,71],f32:71,facecolor:57,factori:[6,32,33,70],fail:68,fallback:[64,71],fals:[1,2,3,4,5,6,46,47,48,50,55,57,67,68,72],famili:[55,56,57],familyhandyman:55,fan:55,fashion:68,fbed:55,fc1:[56,68],fc2:[56,68],fc3:[56,68],feat:[56,68],featur:[55,56,57,68,70,71,72],fed:[5,6],feed:[32,33,68],feel:65,few:[55,56],field:[5,6,70],fig:[55,57],file:[1,2,3,4,5,6,7,8,9,10,11,12,13,14,19,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,48,49,50,51,55,56,57,61,62,67,68,69,70,71],file_path:71,filer_publ:55,filer_public_thumbnail:55,fill:[55,56],filter:57,find:[6,57,68],finish:57,first:[55,56,57,58,59,68,70],five:57,fix:[48,50,55,57],fixed_s:[47,48,50],flag:[69,71],flatten:[56,68],flatten_convert:68,flexibl:[55,56,57],float16:[67,71],float32:[55,67,71],flow:[55,56,57,64,68],fly:68,follow:[55,56,57,68,69,70,71],footprint:[55,56],forc:71,form:58,format:[55,56,57,67,71],forum:69,forward:[32,33,35,39,56,61,64,67,68,70,72],found:[44,45,46,47,55,57,68,69,70],fp16:[1,3,48,50,56,57,65,67,68],fp32:[1,3,48,50,56,57,65,70],framework:[55,56,57],freed:64,freez:68,freeze_modul:59,from:[1,2,3,4,5,6,32,33,46,48,49,50,51,55,56,57,58,59,60,61,62,64,65,68,70,71],fssl:69,fstream:[22,46],full:[64,68,70,71],fulli:[38,59,67,68,70],fuse:[55,56],fuse_addmm_branch:59,fuse_flatten_linear:59,fuse_linear:59,fusion:64,futur:[55,56],gain:57,gaurd:45,gcc:[62,68],gear:70,gener:[5,6,33,55,56,57,59,61,62,64,68,70,71],get:[1,2,3,4,5,6,25,34,46,48,49,50,51,57,59,64,66,69,70,72],get_batch_impl:46,get_build_info:[23,41,47,52,53,67],get_coco_object_dictionari:57,get_is_colored_output_on:[20,42,44,52,53,66],get_logging_prefix:[20,42,44,52,53,66],get_reportable_log_level:[20,42,44,52,53,66],getattr:[59,61,68],getbatch:[5,6,46],getbatchs:[5,6,46],getdimens:[64,68],getoutput:[64,68],getting_start:[],github:[55,56,57,63,68,69,70],give:56,given:[48,50,55,57,59,67,68,71,72],global:[29,68],gnu:69,goal:64,going:[46,68],good:[46,64],got:68,govern:[55,56,57],gpu:[2,4,35,36,39,40,48,50,55,56,67,68,71,72],granular:56,graph:[19,35,36,38,39,40,47,55,56,57,58,60,62,64,65,67,68],great:[55,56,57,68],green_mamba:55,gtc:65,guard:59,guard_elimin:59,gulf:55,hack:46,hakaimagazin:55,half:[56,57,67,68,71,72],handl:[57,59,61],happen:[55,56,68],hardtanh:64,hardwar:[55,56,57],has:[55,56,57,58,59,62,64,68,70],hash:69,have:[33,46,55,56,57,58,59,64,65,68,69,70,71],haven:68,head:57,header:[55,68],help:[28,55,56,58,64,68,71],helper:[55,56,57,64],here:[46,55,56,57,58,61,68,69,70],hermet:69,hfile:[24,52],hidden:45,high:[55,57,59,68],higher:[59,68],hinton:70,hold:[48,49,50,51,58,64,70],holder:61,home:69,hood:62,host:69,how:[5,6,55,57,68,72],howev:[33,55,56,57,69],html:[63,68,69,70],http:[55,56,57,63,68,69,70],http_archiv:69,hub:[55,57],huski:55,idea:59,ident:71,idx:57,ifndef:[46,47],ifstream:46,iint8calibr:[5,6,32,33,46,47,48,50,70],iint8entropycalibrator2:[5,6,32,33,46,70],iint8minmaxcalibr:[32,33,70],ilay:64,imag:[55,57,70],image_idx:57,imagenet:55,imagenet_cla:55,imagenet_class_index:55,images_:70,img0:55,img1:55,img2:55,img3:55,img:55,img_path:55,impact:[55,56,57],implement:[5,6,55,56,57,59,61,68,70],impli:[55,56,57],implic:59,imshow:[55,57],in_featur:[55,56],in_shap:68,in_tensor:68,incas:46,includ:[16,18,19,34,37,44,45,46,47,54,55,56,57,67,68,69,70,71],includedirectori:[24,52],ind:55,independ:[55,57],index:[63,65,70],inetworkdefinit:58,infer:[55,56,59,68,70],info:[19,35,36,39,40,47,48,50,64,66,68,71],inform:[30,34,37,57,58,65,67,68,70,71,72],infrastructur:70,ingest:62,inherit:[52,53,70],inlin:[46,59,68],inplac:55,input0:68,input1:68,input2:68,input:[5,6,33,46,48,49,50,51,55,56,57,58,59,61,64,67,68,70,71,72],input_0:[61,68],input_batch:55,input_data:[55,56,57,68],input_file_path:71,input_rang:[47,48,50],input_s:68,input_shap:[55,56,57,67,68,70,71,72],input_tensor:55,inputrang:[23,41,47,48,50,52,53,68],inputrangeclass:[0,52],inspect:[56,64,68],instal:[55,57,65,68],instanc:[55,56,59,68],instanti:[60,61,62,64,68],instatin:[1,2,3,4,48,50],instead:[58,59,68,71],instnanti:61,instruct:[68,69],insur:69,int16_t:47,int64_t:[47,48,49,50,51,70],int8:[1,3,46,48,50,65,67,70,71],int8_t:47,int8cachecalibr:[22,33,43,46,52,53],int8cachecalibratortempl:[0,52],int8calibr:[5,22,32,43,46,52,53],int8calibratorstruct:[0,52],integ:67,integr:[55,56,65],intent:59,intercompat:[55,57],interest:59,interfac:[1,2,3,4,48,50,61,62,64,68,70],intermedi:[19,55,56,68],intern:[2,4,19,48,50,55,56,57,64,68],internal_error:66,internalerror:66,interpret:[55,56,61],intro_to_torchscript_tutori:68,introduc:[55,56,57],invok:68,involv:[55,56],ios:46,iostream:[22,46,68],is_avail:55,is_train:70,iscustomclass:64,issu:[5,6,55,56,68,69],istensor:64,istream_iter:46,it_:46,item:55,itensor:[58,64,68],iter:[22,46,48,50,55,56,57,58,67,71],its:[33,55,56,57,58,61,64],itself:[1,2,3,4,48,50,59,69,71,72],ivalu:[58,61,64,68],jetson:[55,56,67],jit:[35,36,38,39,40,47,55,56,57,58,59,60,61,62,63,64,67,68,71,72],jpeg:55,jpg:[55,57],jpg__1920x1080_q85_subject_loc:55,json:55,json_fil:55,just:[46,47,55,57,59,65,68,72],kchar:[1,3,47,48,50],kclip:64,kcpu:[2,4,48,50],kcuda:[2,4,48,50,68],kdebug:[19,44,46],kdefault:[47,48,50],kdla:[2,4,47,48,50],kei:[67,68],kernel:[48,50,55,56,64,67,68,71],kernel_s:[55,56],kerror:[19,44],kfloat:[1,3,47,48,50],kgpu:[2,4,47,48,50],kgraph:[19,44,59],khalf:[1,3,47,48,50,68],ki8:70,kind:[55,56,57,58,67],kinfo:[19,44,46],kinternal_error:[19,44],kiwisolv:55,know:[44,64],known:57,kriz:70,krizhevski:70,ksafe_dla:[47,48,50],ksafe_gpu:[47,48,50],ktest:70,ktrain:70,kwarn:[19,44],label:[57,70],laid:68,lambda:[64,68],languag:[55,56,57,68],larg:[55,56,60,62,68,70],larger:70,last:[57,59],later:[33,68],latest:69,law:[55,56,57],layer1:55,layer2:55,layer3:55,layer4:55,layer:[48,50,55,56,57,58,59,64,67,68,70,71],ld_library_path:69,ldd:69,learn:[65,68,69,70],least:55,leav:[56,59],left:57,len:[55,57],lenet:[57,68],lenet_script:68,lenetclassifi:[56,68],lenetfeatextractor:[56,68],length:[5,6,46,55],let:[48,50,55,56,57,59,64,71],level:[20,25,29,30,42,44,46,52,53,55,56,59,62,66,68],levelnamespac:[0,52],leverag:[55,56,57,70],lib:[55,59,68,69],librari:[34,44,45,46,47,55,56,57,60,61,62,64,68],libtorch:[6,37,55,56,57,64,68,69,70],libtorch_pre_cxx11_abi:69,libtrtorch:[68,69,71],licens:[44,45,46,47,55,56,57,68],like:[55,56,57,58,59,61,64,68,69,70,71],limit:[55,56,57,59,70],line:[68,71],linear:[55,56,68],linewidth:57,link:[58,65,68,71],linux:[62,68,69],linux_x86_64:69,list:[20,21,22,23,38,54,57,58,61,64,67,68,69],listconstruct:[58,61,68],listunpack:[61,68],live:64,load:[55,57,61,68,69,70,71,72],loader:[55,56,57],local:[55,57,59,68],locat:[57,70],log:[18,19,21,22,24,41,46,52,53,54,59,64,67],log_debug:64,logger:66,loggingenum:[0,52],loglevel:66,longer:[55,56],look:[58,59,68,70,72],loop_unrol:59,lorikeet:55,loss:70,lot:64,lower:[19,72],lower_graph:59,lower_tupl:59,loweralltupl:59,lowersimpletupl:59,lvl:[29,30,44],machin:[55,56,61,69,70],macro:[7,8,9,10,11,12,13,14,18,20,23,24,44,47,52,54],made:[57,59,60,62],mai:[55,56,57,58,61,62,68,70],main:[57,59,60,61,62,64,68],maintain:[61,64],major:[55,56,57,62],make:[55,56,57,58,68,69,70],make_data_load:[6,70],make_int8_cache_calibr:[22,43,46,52,53,70],make_int8_calibr:[22,33,43,46,52,53,70],manag:[58,60,62,64,68],mangag:59,manual:69,map:[2,4,48,50,58,59,60,62,64,68,70,72],master:[63,69,70],match:[48,50,59,69],matmul:[59,68],matplotlib:[55,57],matrix:63,matur:62,max:[47,48,49,50,51,56,64,67,68,71],max_batch_s:[47,48,50,67,71,72],max_c:71,max_h:71,max_n:71,max_pool2d:[56,68],max_val:64,max_w:71,maximum:[48,49,50,51,67,68,71],maxpool2d:55,maxpool:55,mean:[48,50,55,56,57,64,65,67,68,71],mechan:64,media:55,meet:67,member:[48,49,50,51,67],memori:[22,23,46,47,55,56,59,64,68],mention:55,menu:71,messag:[19,29,30,66,71],metadata:[61,64],method:[35,36,38,39,40,55,56,57,59,64,67,68,69,72],method_nam:[36,38,40,47,67,68],mig:55,might:59,min:[47,48,49,50,51,56,64,67,68,71],min_c:71,min_h:71,min_n:71,min_val:64,min_w:71,mini:55,minim:[48,50,67,70,71],minimum:[48,49,50,51,66,68],minmax:[32,33,70],miss:68,mix:57,mkdir:[55,69],mobilenet_v2:72,mod:[68,70],mode:[68,70],mode_:70,model:[61,68,70,72],model_math:57,modern:57,modifi:69,modul:[35,36,38,39,40,47,55,56,57,60,61,62,64,65,67,70,71,72],modular:68,momentum:55,more:[55,56,57,58,65,68,70,72],most:62,move:[32,46,47,55,56,59,61,68,70],msg:[29,44,66],much:[64,70],multipl:[61,70],must:[48,50,55,57,64,67,68,69,71],n01749939:55,n01820546:55,n02110185:55,n02481823:55,name:[5,6,36,38,40,46,55,57,61,64,67,68,69,72],namespac:[0,44,46,47,54,59,65,70],nano:69,nativ:[62,63,68],native_funct:63,nbbind:[5,6,46],ncol:55,necessari:44,need:[1,2,3,4,30,33,45,48,50,57,58,59,64,68,69,70],nest:[52,53],net:[55,64,68],network:[32,33,55,56,57,64,68,70],neural:[55,57],new_lay:64,new_local_repositori:69,new_siz:70,newer:[55,56],next:[5,6,57,58,61,70],ngc:57,nice:69,ninja:69,nlp:[32,33,70],no_grad:[55,56,57],node:[59,64,68],node_info:[64,68],noexcept:70,none:[57,64],normal:[1,2,3,4,48,50,55,56,57,68,70],noskipw:46,note:[2,4,48,50,55,64,68,69],notebook:[55,56,57,62],notic:[56,57],now:[55,56,57,59,62,64,68,69,72],nrow:55,nrun:[55,56,57],nullptr:[46,47,48,50],num:71,num_avg_timing_it:[47,48,50,67,72],num_it:71,num_min_timing_it:[47,48,50,67,72],number:[5,6,48,50,55,59,64,67,68,71],numer:71,numpi:[55,56,57],nvidia:[35,36,39,40,44,45,46,47,55,56,57,63,67,68,69,70,71],nvidia_deeplearningexamples_torchhub:57,nvidia_ncf:57,nvidia_ssd:57,nvidia_ssd_processing_util:57,nvidia_tacotron2:57,nvidia_waveglow:57,nvinfer1:[5,6,32,33,46,47,48,50,64,70],nvinfer:[22,46],nwarmup:[55,56,57],object:[1,2,3,4,5,6,48,49,50,51,64,67,68,72],observ:55,obsolet:57,obtain:[55,56,57],obvious:68,octet:55,off:[55,57,61],offici:69,ofstream:[46,68],older:62,olefil:55,onc:[44,45,46,47,58,59,61,68,70],one:[57,59,64,66,68],ones:[44,55,56,57,68,69],onli:[2,4,5,6,19,33,46,48,50,56,57,59,62,64,66,67,68,69,70,71],onnx:59,onto:[61,71],op_precis:[47,48,50,55,56,57,67,68,70,71,72],open:[55,56],oper:[1,2,3,4,5,6,38,46,47,48,50,55,56,58,59,60,61,62,64,65,67,70,71],ops:[55,57,59,68],opset:[60,62],opt:[47,48,49,50,51,56,67,68,69],opt_c:71,opt_h:71,opt_n:71,opt_w:71,optim:[48,49,50,51,55,56,57,59,65,68,71],optimi:68,optimin:[48,49,50,51],optimiz:[55,56,57],option:[46,67,69,70,71],order:[48,50,57,64,68],org:[55,56,57,63,68,69,70],origin:57,original_nam:56,other:[1,2,3,4,47,48,50,55,56,57,58,59,61,65,67,68,71],otherwis:69,our:[55,56,57,62,68],out:[38,46,55,56,58,59,60,62,64,66,67,68,69],out_featur:[55,56],out_shap:68,out_tensor:[64,68],output0:59,output:[27,28,48,50,55,56,57,58,59,61,64,66,68,69,71],output_file_path:71,output_s:55,outself:68,over:[55,56,60,62],overkil:56,overrid:[5,6,32,33,46,70],overview:[63,65],own:[55,56,64,68],p100:55,packag:[55,59,68,71],pad:55,page:65,pair:[64,70],paper:[55,57],paramet:[1,2,3,4,5,6,28,29,30,32,33,35,36,38,39,40,48,49,50,51,58,59,64,66,67,68],parent:[16,17,18,20,21,22,23],pars:68,part:[62,71],particular:56,pass:[58,60,61,62,64,68,70],patch:57,path:[6,15,16,17,18,32,33,55,56,57,68,69,70,71],path_to_trtorch_root:69,pathwai:68,pattern:[64,68],peephole_optimz:59,per:57,perf:55,perform:[32,33,55,56,57],performac:[48,49,50,51,70],permiss:[55,56,57],persist:55,phase:[19,64,68],pick:[56,68],pick_best:57,pickler:61,pid:55,pil:55,pillow:[55,57],pip3:69,pip3_import:69,pip:[55,57,69],pip_instal:69,pipelin:[68,71],piplein:68,place:[59,69,70],plan:[62,71],platform:[55,56,62,69],pleas:69,plot:57,plot_result:57,plt:[55,57],point:[67,68],pointer:[5,6,70],pop:61,portabl:[55,56,57,61],posit:71,possibl:[55,56],post:[32,33,48,50,65,68,71],power:[55,56,68],practic:[55,56],pragma:[44,45,46,47,70],pre:55,pre_cxx11_abi:69,precis:[48,50,56,57,65,67,68,70,71],pred:55,pred_label:57,pred_loc:57,predict:[55,57],prefer:68,prefix:[26,28,44,66],prepar:[55,56,57],prepare_input:57,prepare_tensor:57,preprint:70,preprocess:[55,70],preserv:[68,70],prespect:68,pretrain:[55,57,72],pretti:68,previous:[33,68],prim:[58,59,61,68],primarili:[62,68],primer:57,print:[19,38,46,55,56,57,66,67,68,72],priorit:69,privat:[5,6,46,47,70],prob:55,probabl:[55,57],probablil:55,process:[55,56,57,68,71,72],produc:[48,49,50,51,58,61,64,68],product:[55,56],profil:[48,49,50,51],program:[20,21,22,23,33,54,55,56,57,60,62,65,68,71],propog:59,provid:[5,6,48,50,61,64,67,68,69,70,72],providi:[60,62],ptq:[5,6,18,20,24,41,52,53,54,65,71],ptq_calibr:[5,6,47,48,50,70],ptqtemplat:[0,52],pull:69,pure:38,purpos:[55,57,69],push:61,push_back:46,pwr:55,py_test_dep:69,pypars:55,pyplot:[55,57],python3:[55,59,68,69],python:[55,56,57,62,71],python_api:63,pytorch:[55,57,60,61,62,64,67,68,69,70],pytorch_vision_v0:55,qualiti:[55,57],quantiz:[32,33,65,68,71],quantizatiom:[48,50],question:68,quickli:[68,70,71],quit:[64,68],rais:59,raiseexcept:59,rand:68,randn:[55,56,57,68,72],rang:[48,49,50,51,55,56,57,67,68,71],rather:59,raw:57,read:[5,6,32,33,46,70],readcalibrationcach:[5,6,46],readm:[55,56,57],realiz:61,realli:64,reason:[1,3,48,50,57,68],recalibr:33,recipi:57,recognit:[55,70],recomend:[32,33],recommend:[32,33,68,69],recompil:57,record:[55,56,58,68],rect:57,rectangl:57,recurs:58,recursivescriptmodul:56,reduc:[55,56,59,60,62,70],refer:[60,62],referenc:[57,69],refit:[47,48,50,67,72],reflect:47,regard:69,regist:[61,64],registernodeconversionpattern:[64,68],registri:[58,68],reinterpret_cast:46,relationship:[52,53],relu:[55,56,68],remain:[55,56,57,59,70],remov:[55,57],remove_contigu:59,remove_dropout:59,remove_to:59,repack:61,replac:[57,59],report:[25,46],reportable_log_level:66,repositori:[55,57,62],repres:[48,49,50,51,64,66],represent:[55,56,59,64,68],request:[55,68],requir:[33,55,56,57,58,59,66,67,68,69,70,71],research:[55,56],reserv:[44,45,46,47,55,56,57],reset:46,residu:55,resiz:55,resnet50:55,resnet50_model:55,resnet:[57,61],resnet_50_trac:55,resnet_trt:61,resolv:[55,58,59,60,62],resourc:[58,70],respons:[33,55,61],restrict:[48,50,67,71],result:[55,56,58,59,67,68],results_per_input:57,ret:59,reus:[59,70],rgb:55,right:[44,45,46,47,55,56,57,59,62,64],rn50_preprocess:55,root:[44,45,46,47,55,57,69,70],rule:69,run:[2,4,36,40,48,50,55,56,57,58,59,60,61,62,64,65,67,68,69,70,71,72],runtim:[55,56,57,65,68],safe:[64,67],safe_dla:[67,71],safe_gpu:[67,71],safeti:[48,50,67],same:[55,57,61,68,69,72],sampl:[55,70],satisfi:55,save:[33,46,55,56,57,61,67,71],saw:68,scalar:64,scalartyp:[1,3,47,48,50],scale:70,schema:[64,68],scikit:57,scipi:57,scope:59,score:[55,57],scratch:33,script:[38,55,57,59,67,68,72],script_model:[56,68,72],scriptmodul:[67,68],sdk:[55,56,57,63],seamlessli:65,search:65,section:70,secur:69,see:[38,55,56,57,59,61,67,68],select:[32,33,36,40,48,50,55,56,67,70,71],self:[56,59,61,64,68],self_1:[61,68],sens:68,sent:55,separ:[55,56,57],sequenti:55,serial:[36,40,60,62,67,68],serializ:61,seril:61,serv:[61,71],set:[5,6,19,28,30,33,35,36,39,40,48,49,50,51,55,56,57,58,59,60,61,62,65,66,67,68,69,70,71],set_is_colored_output_on:[20,42,44,52,53,66],set_logging_prefix:[20,42,44,52,53,66],set_reportable_log_level:[20,42,44,52,53,66],setalpha:64,setbeta:64,setnam:[64,68],setreshapedimens:68,setup:70,sever:[19,29,66],sha256:69,shape:[48,49,50,51,55,56,57,64,67],share:69,ship:68,should:[1,3,5,6,33,47,48,50,55,58,64,65,66,67,70,71],show:[55,57],shown:68,shuffl:68,shutterstock_780480850:55,siberian:55,siberian_huski:55,side:[59,68],signifi:[48,49,50,51],signific:57,significantli:59,similar:[57,64,68,72],simonyan:70,simpil:70,simpl:[56,68],simpli:[56,59],simplic:[55,57],simplifi:58,sinc:[56,59,68,70],singl:[48,49,50,51,56,59,68,70,71],singular:64,site:[59,68,69],six:55,size:[5,6,46,48,49,50,51,55,56,57,59,67,68,70,71],size_t:[5,6,46,70],slither:55,sm_output:55,small:59,smi:55,snake:55,softmax:[55,57,59],softwar:[55,56,57],sole:70,some:[58,59,60,61,62,64,68,70],someth:[45,59],sort:[64,72],sourc:[44,45,46,47,55,57,62,67],space:70,spec:[67,72],specif:[35,39,55,56,57,59,60,62,67],specifi:[5,6,55,57,64,65,66,67,68,71,72],specifii:67,speed:[55,57],speedup:55,src:[61,63],ssd300:57,ssd300_trt:61,ssd:61,ssd_300_trace:57,ssd_trace:71,ssd_trt:71,sstream:[22,46],stabl:63,stack:[61,70],stage:58,stand:61,standard:[55,56,57,65,71,72],start:[57,58,69,72],start_dim:68,start_tim:[55,56,57],state:[58,64,68],statement:59,static_cast:46,statu:46,std:[5,6,26,29,31,32,33,34,36,38,40,44,46,47,48,49,50,51,55,68,70],stdout:[37,66,67],steamlin:70,step:[55,56,57,65,70],still:[46,55,57,70],stitch:[56,68],stop:68,storag:70,store:[6,58,61,64,68],str:[21,45,46,52,53,55,66,67],straight:64,stream:55,strict:71,strict_typ:[47,48,50,67,72],strictli:67,stride:[55,56,57],string:[5,6,20,22,23,26,29,31,32,33,34,36,38,40,44,46,47,64,67,68,70],stringstream:46,strip_prefix:69,strong:[55,56],struct:[1,2,3,4,23,41,47,70],structur:[33,48,50,55,56,62,64,68],style:[44,45,46,47],sub:68,subdirectori:54,subexpress:59,subgraph:[58,59,64,68],subject:62,submodul:[56,68],subplot:[55,57],subset:70,successfulli:[55,57],sudo:69,suffic:59,suggest:57,suit:65,support:[1,2,3,4,28,38,48,49,50,51,55,56,57,63,67,68,69,71],sure:[68,69],sxm2:55,symbol:69,synchron:[55,56,57],system:[55,57,58,64,65,69],take:[35,36,38,39,40,55,56,57,58,60,61,62,64,67,68,70,72],taken:[55,57],talk:65,tar:[69,70],tarbal:[68,70],target:[2,4,48,50,55,56,57,62,65,67,68,70,71,72],targets_:70,task:[32,33,70],techinqu:68,techniqu:70,tell:64,temp:55,templat:[22,43,46,47,52,53,68],tensor:[46,48,49,50,51,55,56,57,58,59,61,64,68,70],tensorcontain:64,tensorlist:64,tensorrt:[1,2,3,4,5,6,32,33,35,36,37,39,40,47,48,49,50,51,55,56,57,58,59,60,62,64,65,67,68,70,71,72],tensorrtcompilespec:[67,72],term:70,termin:[28,68,71],tesla:55,test:[55,56,57,62,69,71],text:[57,66],tgz:69,than:[59,65],thats:[58,70],thei:[48,50,57,58,59,64,69,71],them:[55,56,57,61,68,69],theori:58,therebi:61,therefor:[33,68],thi:[1,2,3,4,32,33,44,45,46,47,48,49,50,51,55,56,57,58,59,60,61,62,64,68,69,70,71,72],thing:56,think:64,third_parti:[62,69],those:58,though:[55,57,62,64,68,71],three:[48,49,50,51,60,62],threshold:71,thrid_parti:69,through:[55,56,57,58,59,61,65,68],time:[48,50,55,56,57,58,59,60,62,64,67,68,70,71],tini:70,titan:[55,56],titl:55,tmp:68,tocustomclass:64,todim:68,togeth:[56,58,64,68],toilet:55,too:69,tool:[55,56,64,68],toolchain:62,top:[57,62],torch:[1,2,3,4,6,22,32,33,35,36,38,39,40,46,47,48,50,55,56,57,59,61,63,64,67,68,69,70,71,72],torch_scirpt_modul:68,torch_script_modul:68,torchbind:61,torchhub:57,torchscript:[35,36,38,39,40,55,57,60,61,62,67,71,72],torchvis:[55,61,72],toronto:70,totensor:55,tovec:68,toward:70,trace:[57,67,68],traced_model:[55,56,57,68],track:[64,70],track_running_stat:55,trade:57,tradit:70,traget:[35,39],train:[32,33,48,50,55,57,65,68,71],trainabl:59,transform:[55,56,68,70],translat:[57,68],travers:[60,62],treat:71,tree:[44,45,46,47,70],trigger:[56,68],trim:70,trt:[1,2,3,4,5,6,48,50,58,59,61,64,68],trt_lenet_script:68,trt_mod:[68,70],trt_model:[55,57,72],trt_model_fp32:55,trt_script_modul:56,trt_ts_modul:[56,68],trtorch:[0,1,2,3,4,5,6,17,19,24,44,45,46,48,49,50,51,53,54,58,59,60,61,62,69,70,71],trtorch_api:[21,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,44,45,46,47,52,53],trtorch_check:64,trtorch_hidden:[21,45,52,53],trtorch_major_vers:[21,45,52,53],trtorch_minor_vers:[21,45,52,53],trtorch_patch_vers:[21,45,52,53],trtorch_py_dep:69,trtorch_unus:64,trtorch_vers:[21,45,52,53],trtorchc:65,trtorchfil:[24,52],trtorchnamespac:[0,52],ts_model:68,tue:55,tune:[55,56,57],tupl:[61,67,68],tupleconstruct:[59,61],tupleunpack:59,tutori:[68,70],two:[55,56,57,64,68,69,70,71],txt:69,type:[1,2,3,4,32,49,51,52,53,55,58,61,64,66,67,68,70,71],typenam:[5,6,32,33,46],typic:[58,64],ubuntu:69,uint64_t:[47,48,50],unabl:[64,68],uncom:69,uncorr:55,under:[44,45,46,47,55,56,57,62],underli:[1,2,3,4,48,50,64],understand:68,union:[64,68],uniqu:6,unique_ptr:[6,32],unit:56,unless:[55,56,57],unlik:[65,68,69,72],unpack_addmm:59,unpack_log_softmax:59,unqiue_ptr:6,unsqueez:55,unstabl:62,unsupport:[38,67],unsur:64,untest:62,until:[58,62,64,69],unwrap:64,unwrap_distribut:57,unwraptodoubl:64,unwraptoint:68,unzip:69,upgrad:55,upload:55,upstream:68,uri:57,url:69,usag:[55,68],use:[1,2,3,4,5,6,32,33,48,50,55,56,57,58,59,61,62,64,66,67,68,69,70,71,72],use_cach:[5,6,32,46],use_cache_:46,use_subset:70,usecas:69,used:[1,2,3,4,5,6,46,48,49,50,51,55,57,58,59,61,64,66,67,68,70,71],useful:64,user:[44,55,56,60,61,62,68,69,70],uses:[32,33,46,55,56,57,64,69,70],using:[1,2,3,4,35,36,39,40,46,48,50,55,56,57,64,65,67,68,70,71,72],using_int:68,usr:[55,69],usual:57,util:[64,67,68],val2017:57,val:57,valid:[2,4,48,50,57,64],valu:[1,2,3,4,19,47,48,50,58,61,64,66,68],value_tensor_map:[58,64],varient:59,vector:[22,23,46,47,48,49,50,51,68,70],verbios:71,verbos:71,veri:[70,72],version:[34,37,55,56,57,62,69],vgg16:70,vgg:57,via:[55,57,65,67],virtual:70,vision:55,visit:57,visual:[],volatil:55,volta:[55,56],wai:[55,68,69,71],walk:[55,56,57],want:[44,48,50,55,56,68,72],warm:[55,56,57],warn:[19,46,55,64,66,71],warranti:[55,56,57],websit:69,weight:[58,68],welcom:68,well:[55,56,57,68,70],were:[57,68],wget:55,what:[6,57,59,68],whatev:61,when:[28,46,48,50,55,56,58,59,60,61,62,64,66,67,68,69,70,71],where:[55,56,58,59,64,68,70],whether:[6,70],which:[2,4,33,35,36,39,40,48,50,55,56,57,58,59,60,61,62,64,67,68,70,72],whilst:57,white:57,whl:69,whole:[55,56],whose:59,width:55,within:[55,56,57,60,62],without:[55,56,57,64,68,70],work:[46,56,57,59,62,64,70],worker:70,workflow:72,workspac:[48,50,67,69,70,71],workspace_s:[47,48,50,55,57,67,70,71],world:[55,56],would:[64,68,69,71,72],wrap:[60,61,62,68,72],wrapper:64,write:[5,6,32,33,46,55,56,57,58,65,68,70],writecalibrationcach:[5,6,46],www:[55,56,57,68,69,70],x64:69,x86_64:[62,69],xavier:[55,56],xstr:[21,45,52,53],yaml:63,you:[1,2,3,4,32,33,48,50,55,56,57,58,59,61,62,64,65,67,68,69,70,71,72],your:[55,56,57,64,65,68,69,72],yourself:68,zip:[61,69],zisserman:70},titles:["Class Hierarchy","Class CompileSpec::DataType","Class CompileSpec::DeviceType","Class CompileSpec::DataType","Class CompileSpec::DeviceType","Template Class Int8CacheCalibrator","Template Class Int8Calibrator","Define STR","Define TRTORCH_API","Define TRTORCH_HIDDEN","Define TRTORCH_MAJOR_VERSION","Define TRTORCH_PATCH_VERSION","Define TRTORCH_VERSION","Define XSTR","Define TRTORCH_MINOR_VERSION","Directory cpp","Directory api","Directory include","Directory trtorch","Enum Level","File logging.h","File macros.h","File ptq.h","File trtorch.h","File Hierarchy","Function trtorch::logging::get_reportable_log_level","Function trtorch::logging::set_logging_prefix","Function trtorch::logging::get_is_colored_output_on","Function trtorch::logging::set_is_colored_output_on","Function trtorch::logging::log","Function trtorch::logging::set_reportable_log_level","Function trtorch::logging::get_logging_prefix","Template Function trtorch::ptq::make_int8_calibrator","Template Function trtorch::ptq::make_int8_cache_calibrator","Function trtorch::get_build_info","Function trtorch::CompileGraph","Function trtorch::ConvertGraphToTRTEngine","Function trtorch::dump_build_info","Function trtorch::CheckMethodOperatorSupport","Function trtorch::CompileGraph","Function trtorch::ConvertGraphToTRTEngine","Namespace trtorch","Namespace trtorch::logging","Namespace trtorch::ptq","Program Listing for File logging.h","Program Listing for File macros.h","Program Listing for File ptq.h","Program Listing for File trtorch.h","Struct CompileSpec","Struct CompileSpec::InputRange","Struct CompileSpec","Struct CompileSpec::InputRange","TRTorch C++ API","Full API","Full API","TRTorch Getting Started - ResNet 50","TRTorch Getting Started - LeNet","Object Detection with TRTorch (SSD)","Conversion Phase","Lowering Phase","Compiler Phases","Runtime Phase","System Overview","Useful Links for TRTorch Development","Writing Converters","TRTorch","trtorch.logging","trtorch","Getting Started","Installation","Post Training Quantization (PTQ)","trtorchc","Using TRTorch Directly From PyTorch"],titleterms:{"class":[0,1,2,3,4,5,6,22,23,41,43,52,53],"enum":[19,20,42,52,53,67],"function":[20,22,23,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,52,53,63,67],CompileSpec:[],The:68,Used:59,Useful:63,Using:[68,72],aarch64:69,abi:69,addmm:59,advic:64,ahead:65,api:[16,20,21,22,23,52,53,54,63,65,69],applic:70,arg:64,avail:63,background:[61,64,68],base:[5,6],benchmark:[55,57],binari:69,branch:59,build:69,checkmethodoperatorsupport:38,citat:70,cli:69,code:59,compil:[60,62,65,68,69],compilegraph:[35,39],compilespec:[1,2,3,4,48,49,50,51],conclus:[56,57],construct:61,content:[20,21,22,23,41,42,43,55,56,57],context:64,contigu:59,contract:64,contributor:65,convers:[58,60,62,64],convert:[58,64,68],convertgraphtotrtengin:[36,40],cpp:[15,20,21,22,23],creat:[68,70],cudnn:69,custom:68,cxx11:69,datatyp:[1,3],dead:59,debug:69,defin:[7,8,9,10,11,12,13,14,21,52,53],definit:[20,21,22,23],depend:69,descript:[55,57],deseri:61,detail:57,detect:57,detector:57,develop:63,devicetyp:[2,4],dimens:63,directli:72,directori:[15,16,17,18,54],disk:68,distribut:69,documen:65,document:[1,2,3,4,5,6,7,8,9,10,11,12,13,14,19,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,48,49,50,51,63,65],dropout:59,dump_build_info:37,easier:63,elimin:59,eliminatecommonsubexpress:59,engin:61,envior:69,evalu:58,execept:59,execut:[],executor:61,expect:63,file:[18,20,21,22,23,24,44,45,46,47,52,54],flatten:59,fp16:55,fp32:55,freez:59,from:[69,72],full:[52,53,54],fuse:59,gaurd:59,get:[55,56,65,68],get_build_info:34,get_is_colored_output_on:27,get_logging_prefix:31,get_reportable_log_level:25,gpu:65,graph:[59,61],guarante:64,half:55,hierarchi:[0,24,52],hood:68,how:70,includ:[17,20,21,22,23],indic:65,infer:57,inherit:[5,6],inputrang:[49,51],instal:69,int8cachecalibr:5,int8calibr:6,jetson:69,jit:65,layer:63,learn:[55,56,57],lenet:56,level:19,librari:69,linear:59,link:63,list:[44,45,46,47],local:69,log:[20,25,26,27,28,29,30,31,42,44,66],logsoftmax:59,loop:59,lower:[59,60,62],macro:[21,45],make_int8_cache_calibr:33,make_int8_calibr:32,measur:57,model:[55,56,57],modul:[59,68],multibox:57,namespac:[20,22,23,41,42,43,52,53],nativ:69,native_op:63,nest:[1,2,3,4,48,49,50,51],next:[55,56],node:58,notebook:[],nvidia:65,object:[55,56,57],oper:68,optimz:59,other:64,overview:[55,56,57,62],own:70,packag:69,pass:59,pattern:59,peephol:59,phase:[58,59,60,61,62],post:70,pre:69,precis:55,precompil:69,prerequisit:69,program:[44,45,46,47],ptq:[22,32,33,43,46,70],python:[63,65,68,69],pytorch:[56,63,65,72],quantiz:70,quickstart:68,read:63,redund:59,refer:57,regist:68,relationship:[1,2,3,4,5,6,48,49,50,51],releas:69,remov:59,resnet:55,respons:64,result:[57,61],runtim:[60,61,62],sampl:57,save:68,script:56,serial:61,set_is_colored_output_on:28,set_logging_prefix:26,set_reportable_log_level:30,setup:69,shot:57,singl:[55,57],sometim:63,sourc:69,speedup:57,ssd:57,start:[55,56,65,68],str:7,struct:[48,49,50,51,52,53],subdirectori:[15,16,17],submodul:67,system:62,tarbal:69,templat:[5,6,32,33],tensorrt:[61,63,69],time:65,torchscript:[56,65,68],trace:[55,56],train:70,trtorch:[18,20,21,22,23,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,47,52,55,56,57,63,65,66,67,68,72],trtorch_api:8,trtorch_hidden:9,trtorch_major_vers:10,trtorch_minor_vers:14,trtorch_patch_vers:11,trtorch_vers:12,trtorchc:[68,71],tupl:59,type:[5,6,48,50],under:68,unpack:59,unrol:59,unsupport:68,using:69,util:[55,57],visual:57,weight:64,what:[55,56,64],work:68,write:64,xstr:13,your:70}})
\ No newline at end of file
+Search.setIndex({docnames:["_cpp_api/class_view_hierarchy","_cpp_api/classtrtorch_1_1CompileSpec_1_1DataType","_cpp_api/classtrtorch_1_1CompileSpec_1_1DeviceType","_cpp_api/classtrtorch_1_1ptq_1_1Int8CacheCalibrator","_cpp_api/classtrtorch_1_1ptq_1_1Int8Calibrator","_cpp_api/define_macros_8h_1a18d295a837ac71add5578860b55e5502","_cpp_api/define_macros_8h_1a20c1fbeb21757871c52299dc52351b5f","_cpp_api/define_macros_8h_1a25ee153c325dfc7466a33cbd5c1ff055","_cpp_api/define_macros_8h_1a48d6029a45583a06848891cb0e86f7ba","_cpp_api/define_macros_8h_1a71b02dddfabe869498ad5a88e11c440f","_cpp_api/define_macros_8h_1a9d31d0569348d109b1b069b972dd143e","_cpp_api/define_macros_8h_1abe87b341f562fd1cf40b7672e4d759da","_cpp_api/define_macros_8h_1ae1c56ab8a40af292a9a4964651524d84","_cpp_api/dir_cpp","_cpp_api/dir_cpp_api","_cpp_api/dir_cpp_api_include","_cpp_api/dir_cpp_api_include_trtorch","_cpp_api/enum_logging_8h_1a5f612ff2f783ff4fbe89d168f0d817d4","_cpp_api/file_cpp_api_include_trtorch_logging.h","_cpp_api/file_cpp_api_include_trtorch_macros.h","_cpp_api/file_cpp_api_include_trtorch_ptq.h","_cpp_api/file_cpp_api_include_trtorch_trtorch.h","_cpp_api/file_view_hierarchy","_cpp_api/function_logging_8h_1a118d65b179defff7fff279eb9cd126cb","_cpp_api/function_logging_8h_1a396a688110397538f8b3fb7dfdaf38bb","_cpp_api/function_logging_8h_1a9b420280bfacc016d7e36a5704021949","_cpp_api/function_logging_8h_1aa533955a2b908db9e5df5acdfa24715f","_cpp_api/function_logging_8h_1abc57d473f3af292551dee8b9c78373ad","_cpp_api/function_logging_8h_1adf5435f0dbb09c0d931a1b851847236b","_cpp_api/function_logging_8h_1aef44b69c62af7cf2edc8875a9506641a","_cpp_api/function_ptq_8h_1a4422781719d7befedb364cacd91c6247","_cpp_api/function_ptq_8h_1a5f33b142bc2f3f2aaf462270b3ad7e31","_cpp_api/function_trtorch_8h_1a2cf17d43ba9117b3b4d652744b4f0447","_cpp_api/function_trtorch_8h_1a3eace458ae9122f571fabfc9ef1b9e3a","_cpp_api/function_trtorch_8h_1a726f6e7091b6b7be45b5a4275b2ffb10","_cpp_api/function_trtorch_8h_1ab01696cfe08b6a5293c55935a9713c25","_cpp_api/function_trtorch_8h_1af19cb866b0520fc84b69a1cf25a52b65","_cpp_api/namespace_trtorch","_cpp_api/namespace_trtorch__logging","_cpp_api/namespace_trtorch__ptq","_cpp_api/program_listing_file_cpp_api_include_trtorch_logging.h","_cpp_api/program_listing_file_cpp_api_include_trtorch_macros.h","_cpp_api/program_listing_file_cpp_api_include_trtorch_ptq.h","_cpp_api/program_listing_file_cpp_api_include_trtorch_trtorch.h","_cpp_api/structtrtorch_1_1CompileSpec","_cpp_api/structtrtorch_1_1CompileSpec_1_1InputRange","_cpp_api/trtorch_cpp","_cpp_api/unabridged_api","_cpp_api/unabridged_orphan","_notebooks/Resnet50-example","_notebooks/lenet-getting-started","_notebooks/ssd-object-detection-demo","contributors/conversion","contributors/lowering","contributors/phases","contributors/runtime","contributors/system_overview","contributors/useful_links","contributors/writing_converters","index","py_api/logging","py_api/trtorch","tutorials/getting_started","tutorials/installation","tutorials/ptq","tutorials/trtorchc","tutorials/use_from_pytorch"],envversion:{"sphinx.domains.c":2,"sphinx.domains.changeset":1,"sphinx.domains.citation":1,"sphinx.domains.cpp":3,"sphinx.domains.index":1,"sphinx.domains.javascript":2,"sphinx.domains.math":2,"sphinx.domains.python":2,"sphinx.domains.rst":2,"sphinx.domains.std":1,"sphinx.ext.intersphinx":1,nbsphinx:3,sphinx:56},filenames:["_cpp_api/class_view_hierarchy.rst","_cpp_api/classtrtorch_1_1CompileSpec_1_1DataType.rst","_cpp_api/classtrtorch_1_1CompileSpec_1_1DeviceType.rst","_cpp_api/classtrtorch_1_1ptq_1_1Int8CacheCalibrator.rst","_cpp_api/classtrtorch_1_1ptq_1_1Int8Calibrator.rst","_cpp_api/define_macros_8h_1a18d295a837ac71add5578860b55e5502.rst","_cpp_api/define_macros_8h_1a20c1fbeb21757871c52299dc52351b5f.rst","_cpp_api/define_macros_8h_1a25ee153c325dfc7466a33cbd5c1ff055.rst","_cpp_api/define_macros_8h_1a48d6029a45583a06848891cb0e86f7ba.rst","_cpp_api/define_macros_8h_1a71b02dddfabe869498ad5a88e11c440f.rst","_cpp_api/define_macros_8h_1a9d31d0569348d109b1b069b972dd143e.rst","_cpp_api/define_macros_8h_1abe87b341f562fd1cf40b7672e4d759da.rst","_cpp_api/define_macros_8h_1ae1c56ab8a40af292a9a4964651524d84.rst","_cpp_api/dir_cpp.rst","_cpp_api/dir_cpp_api.rst","_cpp_api/dir_cpp_api_include.rst","_cpp_api/dir_cpp_api_include_trtorch.rst","_cpp_api/enum_logging_8h_1a5f612ff2f783ff4fbe89d168f0d817d4.rst","_cpp_api/file_cpp_api_include_trtorch_logging.h.rst","_cpp_api/file_cpp_api_include_trtorch_macros.h.rst","_cpp_api/file_cpp_api_include_trtorch_ptq.h.rst","_cpp_api/file_cpp_api_include_trtorch_trtorch.h.rst","_cpp_api/file_view_hierarchy.rst","_cpp_api/function_logging_8h_1a118d65b179defff7fff279eb9cd126cb.rst","_cpp_api/function_logging_8h_1a396a688110397538f8b3fb7dfdaf38bb.rst","_cpp_api/function_logging_8h_1a9b420280bfacc016d7e36a5704021949.rst","_cpp_api/function_logging_8h_1aa533955a2b908db9e5df5acdfa24715f.rst","_cpp_api/function_logging_8h_1abc57d473f3af292551dee8b9c78373ad.rst","_cpp_api/function_logging_8h_1adf5435f0dbb09c0d931a1b851847236b.rst","_cpp_api/function_logging_8h_1aef44b69c62af7cf2edc8875a9506641a.rst","_cpp_api/function_ptq_8h_1a4422781719d7befedb364cacd91c6247.rst","_cpp_api/function_ptq_8h_1a5f33b142bc2f3f2aaf462270b3ad7e31.rst","_cpp_api/function_trtorch_8h_1a2cf17d43ba9117b3b4d652744b4f0447.rst","_cpp_api/function_trtorch_8h_1a3eace458ae9122f571fabfc9ef1b9e3a.rst","_cpp_api/function_trtorch_8h_1a726f6e7091b6b7be45b5a4275b2ffb10.rst","_cpp_api/function_trtorch_8h_1ab01696cfe08b6a5293c55935a9713c25.rst","_cpp_api/function_trtorch_8h_1af19cb866b0520fc84b69a1cf25a52b65.rst","_cpp_api/namespace_trtorch.rst","_cpp_api/namespace_trtorch__logging.rst","_cpp_api/namespace_trtorch__ptq.rst","_cpp_api/program_listing_file_cpp_api_include_trtorch_logging.h.rst","_cpp_api/program_listing_file_cpp_api_include_trtorch_macros.h.rst","_cpp_api/program_listing_file_cpp_api_include_trtorch_ptq.h.rst","_cpp_api/program_listing_file_cpp_api_include_trtorch_trtorch.h.rst","_cpp_api/structtrtorch_1_1CompileSpec.rst","_cpp_api/structtrtorch_1_1CompileSpec_1_1InputRange.rst","_cpp_api/trtorch_cpp.rst","_cpp_api/unabridged_api.rst","_cpp_api/unabridged_orphan.rst","_notebooks/Resnet50-example.ipynb","_notebooks/lenet-getting-started.ipynb","_notebooks/ssd-object-detection-demo.ipynb","contributors/conversion.rst","contributors/lowering.rst","contributors/phases.rst","contributors/runtime.rst","contributors/system_overview.rst","contributors/useful_links.rst","contributors/writing_converters.rst","index.rst","py_api/logging.rst","py_api/trtorch.rst","tutorials/getting_started.rst","tutorials/installation.rst","tutorials/ptq.rst","tutorials/trtorchc.rst","tutorials/use_from_pytorch.rst"],objects:{"":{"trtorch::CheckMethodOperatorSupport":[35,1,1,"_CPPv4N7trtorch26CheckMethodOperatorSupportERKN5torch3jit6ModuleENSt6stringE"],"trtorch::CheckMethodOperatorSupport::method_name":[35,2,1,"_CPPv4N7trtorch26CheckMethodOperatorSupportERKN5torch3jit6ModuleENSt6stringE"],"trtorch::CheckMethodOperatorSupport::module":[35,2,1,"_CPPv4N7trtorch26CheckMethodOperatorSupportERKN5torch3jit6ModuleENSt6stringE"],"trtorch::CompileGraph":[33,1,1,"_CPPv4N7trtorch12CompileGraphERKN5torch3jit6ModuleE11CompileSpec"],"trtorch::CompileGraph::info":[33,2,1,"_CPPv4N7trtorch12CompileGraphERKN5torch3jit6ModuleE11CompileSpec"],"trtorch::CompileGraph::module":[33,2,1,"_CPPv4N7trtorch12CompileGraphERKN5torch3jit6ModuleE11CompileSpec"],"trtorch::CompileSpec":[44,3,1,"_CPPv4N7trtorch11CompileSpecE"],"trtorch::CompileSpec::CompileSpec":[44,1,1,"_CPPv4N7trtorch11CompileSpec11CompileSpecENSt6vectorINSt6vectorI7int64_tEEEE"],"trtorch::CompileSpec::CompileSpec::fixed_sizes":[44,2,1,"_CPPv4N7trtorch11CompileSpec11CompileSpecENSt6vectorINSt6vectorI7int64_tEEEE"],"trtorch::CompileSpec::CompileSpec::input_ranges":[44,2,1,"_CPPv4N7trtorch11CompileSpec11CompileSpecENSt6vectorI10InputRangeEE"],"trtorch::CompileSpec::DataType":[44,3,1,"_CPPv4N7trtorch11CompileSpec8DataTypeE"],"trtorch::CompileSpec::DataType::DataType":[44,1,1,"_CPPv4N7trtorch11CompileSpec8DataType8DataTypeEv"],"trtorch::CompileSpec::DataType::DataType::t":[44,2,1,"_CPPv4N7trtorch11CompileSpec8DataType8DataTypeEN3c1010ScalarTypeE"],"trtorch::CompileSpec::DataType::Value":[44,4,1,"_CPPv4N7trtorch11CompileSpec8DataType5ValueE"],"trtorch::CompileSpec::DataType::Value::kChar":[44,5,1,"_CPPv4N7trtorch11CompileSpec8DataType5Value5kCharE"],"trtorch::CompileSpec::DataType::Value::kFloat":[44,5,1,"_CPPv4N7trtorch11CompileSpec8DataType5Value6kFloatE"],"trtorch::CompileSpec::DataType::Value::kHalf":[44,5,1,"_CPPv4N7trtorch11CompileSpec8DataType5Value5kHalfE"],"trtorch::CompileSpec::DataType::kChar":[1,5,1,"_CPPv4N7trtorch11CompileSpec8DataType5Value5kCharE"],"trtorch::CompileSpec::DataType::kFloat":[1,5,1,"_CPPv4N7trtorch11CompileSpec8DataType5Value6kFloatE"],"trtorch::CompileSpec::DataType::kHalf":[1,5,1,"_CPPv4N7trtorch11CompileSpec8DataType5Value5kHalfE"],"trtorch::CompileSpec::DataType::operator Value":[44,1,1,"_CPPv4NK7trtorch11CompileSpec8DataTypecv5ValueEv"],"trtorch::CompileSpec::DataType::operator bool":[44,1,1,"_CPPv4N7trtorch11CompileSpec8DataTypecvbEv"],"trtorch::CompileSpec::DataType::operator!=":[44,1,1,"_CPPv4NK7trtorch11CompileSpec8DataTypeneEN8DataType5ValueE"],"trtorch::CompileSpec::DataType::operator!=::other":[44,2,1,"_CPPv4NK7trtorch11CompileSpec8DataTypeneEN8DataType5ValueE"],"trtorch::CompileSpec::DataType::operator==":[44,1,1,"_CPPv4NK7trtorch11CompileSpec8DataTypeeqEN8DataType5ValueE"],"trtorch::CompileSpec::DataType::operator==::other":[44,2,1,"_CPPv4NK7trtorch11CompileSpec8DataTypeeqEN8DataType5ValueE"],"trtorch::CompileSpec::DeviceType":[44,3,1,"_CPPv4N7trtorch11CompileSpec10DeviceTypeE"],"trtorch::CompileSpec::DeviceType::DeviceType":[44,1,1,"_CPPv4N7trtorch11CompileSpec10DeviceType10DeviceTypeEv"],"trtorch::CompileSpec::DeviceType::DeviceType::t":[44,2,1,"_CPPv4N7trtorch11CompileSpec10DeviceType10DeviceTypeEN3c1010DeviceTypeE"],"trtorch::CompileSpec::DeviceType::Value":[44,4,1,"_CPPv4N7trtorch11CompileSpec10DeviceType5ValueE"],"trtorch::CompileSpec::DeviceType::Value::kDLA":[44,5,1,"_CPPv4N7trtorch11CompileSpec10DeviceType5Value4kDLAE"],"trtorch::CompileSpec::DeviceType::Value::kGPU":[44,5,1,"_CPPv4N7trtorch11CompileSpec10DeviceType5Value4kGPUE"],"trtorch::CompileSpec::DeviceType::kDLA":[2,5,1,"_CPPv4N7trtorch11CompileSpec10DeviceType5Value4kDLAE"],"trtorch::CompileSpec::DeviceType::kGPU":[2,5,1,"_CPPv4N7trtorch11CompileSpec10DeviceType5Value4kGPUE"],"trtorch::CompileSpec::DeviceType::operator Value":[44,1,1,"_CPPv4NK7trtorch11CompileSpec10DeviceTypecv5ValueEv"],"trtorch::CompileSpec::DeviceType::operator bool":[44,1,1,"_CPPv4N7trtorch11CompileSpec10DeviceTypecvbEv"],"trtorch::CompileSpec::DeviceType::operator!=":[44,1,1,"_CPPv4NK7trtorch11CompileSpec10DeviceTypeneE10DeviceType"],"trtorch::CompileSpec::DeviceType::operator!=::other":[44,2,1,"_CPPv4NK7trtorch11CompileSpec10DeviceTypeneE10DeviceType"],"trtorch::CompileSpec::DeviceType::operator==":[44,1,1,"_CPPv4NK7trtorch11CompileSpec10DeviceTypeeqE10DeviceType"],"trtorch::CompileSpec::DeviceType::operator==::other":[44,2,1,"_CPPv4NK7trtorch11CompileSpec10DeviceTypeeqE10DeviceType"],"trtorch::CompileSpec::EngineCapability":[44,4,1,"_CPPv4N7trtorch11CompileSpec16EngineCapabilityE"],"trtorch::CompileSpec::EngineCapability::kDEFAULT":[44,5,1,"_CPPv4N7trtorch11CompileSpec16EngineCapability8kDEFAULTE"],"trtorch::CompileSpec::EngineCapability::kSAFE_DLA":[44,5,1,"_CPPv4N7trtorch11CompileSpec16EngineCapability9kSAFE_DLAE"],"trtorch::CompileSpec::EngineCapability::kSAFE_GPU":[44,5,1,"_CPPv4N7trtorch11CompileSpec16EngineCapability9kSAFE_GPUE"],"trtorch::CompileSpec::InputRange":[45,3,1,"_CPPv4N7trtorch11CompileSpec10InputRangeE"],"trtorch::CompileSpec::InputRange::InputRange":[45,1,1,"_CPPv4N7trtorch11CompileSpec10InputRange10InputRangeENSt6vectorI7int64_tEENSt6vectorI7int64_tEENSt6vectorI7int64_tEE"],"trtorch::CompileSpec::InputRange::InputRange::max":[45,2,1,"_CPPv4N7trtorch11CompileSpec10InputRange10InputRangeENSt6vectorI7int64_tEENSt6vectorI7int64_tEENSt6vectorI7int64_tEE"],"trtorch::CompileSpec::InputRange::InputRange::min":[45,2,1,"_CPPv4N7trtorch11CompileSpec10InputRange10InputRangeENSt6vectorI7int64_tEENSt6vectorI7int64_tEENSt6vectorI7int64_tEE"],"trtorch::CompileSpec::InputRange::InputRange::opt":[45,2,1,"_CPPv4N7trtorch11CompileSpec10InputRange10InputRangeENSt6vectorI7int64_tEENSt6vectorI7int64_tEENSt6vectorI7int64_tEE"],"trtorch::CompileSpec::InputRange::max":[45,6,1,"_CPPv4N7trtorch11CompileSpec10InputRange3maxE"],"trtorch::CompileSpec::InputRange::min":[45,6,1,"_CPPv4N7trtorch11CompileSpec10InputRange3minE"],"trtorch::CompileSpec::InputRange::opt":[45,6,1,"_CPPv4N7trtorch11CompileSpec10InputRange3optE"],"trtorch::CompileSpec::allow_gpu_fallback":[44,6,1,"_CPPv4N7trtorch11CompileSpec18allow_gpu_fallbackE"],"trtorch::CompileSpec::capability":[44,6,1,"_CPPv4N7trtorch11CompileSpec10capabilityE"],"trtorch::CompileSpec::debug":[44,6,1,"_CPPv4N7trtorch11CompileSpec5debugE"],"trtorch::CompileSpec::device":[44,6,1,"_CPPv4N7trtorch11CompileSpec6deviceE"],"trtorch::CompileSpec::input_ranges":[44,6,1,"_CPPv4N7trtorch11CompileSpec12input_rangesE"],"trtorch::CompileSpec::kDEFAULT":[44,5,1,"_CPPv4N7trtorch11CompileSpec16EngineCapability8kDEFAULTE"],"trtorch::CompileSpec::kSAFE_DLA":[44,5,1,"_CPPv4N7trtorch11CompileSpec16EngineCapability9kSAFE_DLAE"],"trtorch::CompileSpec::kSAFE_GPU":[44,5,1,"_CPPv4N7trtorch11CompileSpec16EngineCapability9kSAFE_GPUE"],"trtorch::CompileSpec::max_batch_size":[44,6,1,"_CPPv4N7trtorch11CompileSpec14max_batch_sizeE"],"trtorch::CompileSpec::num_avg_timing_iters":[44,6,1,"_CPPv4N7trtorch11CompileSpec20num_avg_timing_itersE"],"trtorch::CompileSpec::num_min_timing_iters":[44,6,1,"_CPPv4N7trtorch11CompileSpec20num_min_timing_itersE"],"trtorch::CompileSpec::op_precision":[44,6,1,"_CPPv4N7trtorch11CompileSpec12op_precisionE"],"trtorch::CompileSpec::ptq_calibrator":[44,6,1,"_CPPv4N7trtorch11CompileSpec14ptq_calibratorE"],"trtorch::CompileSpec::refit":[44,6,1,"_CPPv4N7trtorch11CompileSpec5refitE"],"trtorch::CompileSpec::strict_types":[44,6,1,"_CPPv4N7trtorch11CompileSpec12strict_typesE"],"trtorch::CompileSpec::workspace_size":[44,6,1,"_CPPv4N7trtorch11CompileSpec14workspace_sizeE"],"trtorch::ConvertGraphToTRTEngine":[36,1,1,"_CPPv4N7trtorch23ConvertGraphToTRTEngineERKN5torch3jit6ModuleENSt6stringE11CompileSpec"],"trtorch::ConvertGraphToTRTEngine::info":[36,2,1,"_CPPv4N7trtorch23ConvertGraphToTRTEngineERKN5torch3jit6ModuleENSt6stringE11CompileSpec"],"trtorch::ConvertGraphToTRTEngine::method_name":[36,2,1,"_CPPv4N7trtorch23ConvertGraphToTRTEngineERKN5torch3jit6ModuleENSt6stringE11CompileSpec"],"trtorch::ConvertGraphToTRTEngine::module":[36,2,1,"_CPPv4N7trtorch23ConvertGraphToTRTEngineERKN5torch3jit6ModuleENSt6stringE11CompileSpec"],"trtorch::dump_build_info":[34,1,1,"_CPPv4N7trtorch15dump_build_infoEv"],"trtorch::get_build_info":[32,1,1,"_CPPv4N7trtorch14get_build_infoEv"],"trtorch::logging::Level":[17,4,1,"_CPPv4N7trtorch7logging5LevelE"],"trtorch::logging::Level::kDEBUG":[17,5,1,"_CPPv4N7trtorch7logging5Level6kDEBUGE"],"trtorch::logging::Level::kERROR":[17,5,1,"_CPPv4N7trtorch7logging5Level6kERRORE"],"trtorch::logging::Level::kGRAPH":[17,5,1,"_CPPv4N7trtorch7logging5Level6kGRAPHE"],"trtorch::logging::Level::kINFO":[17,5,1,"_CPPv4N7trtorch7logging5Level5kINFOE"],"trtorch::logging::Level::kINTERNAL_ERROR":[17,5,1,"_CPPv4N7trtorch7logging5Level15kINTERNAL_ERRORE"],"trtorch::logging::Level::kWARNING":[17,5,1,"_CPPv4N7trtorch7logging5Level8kWARNINGE"],"trtorch::logging::get_is_colored_output_on":[25,1,1,"_CPPv4N7trtorch7logging24get_is_colored_output_onEv"],"trtorch::logging::get_logging_prefix":[29,1,1,"_CPPv4N7trtorch7logging18get_logging_prefixEv"],"trtorch::logging::get_reportable_log_level":[23,1,1,"_CPPv4N7trtorch7logging24get_reportable_log_levelEv"],"trtorch::logging::kDEBUG":[17,5,1,"_CPPv4N7trtorch7logging5Level6kDEBUGE"],"trtorch::logging::kERROR":[17,5,1,"_CPPv4N7trtorch7logging5Level6kERRORE"],"trtorch::logging::kGRAPH":[17,5,1,"_CPPv4N7trtorch7logging5Level6kGRAPHE"],"trtorch::logging::kINFO":[17,5,1,"_CPPv4N7trtorch7logging5Level5kINFOE"],"trtorch::logging::kINTERNAL_ERROR":[17,5,1,"_CPPv4N7trtorch7logging5Level15kINTERNAL_ERRORE"],"trtorch::logging::kWARNING":[17,5,1,"_CPPv4N7trtorch7logging5Level8kWARNINGE"],"trtorch::logging::log":[27,1,1,"_CPPv4N7trtorch7logging3logE5LevelNSt6stringE"],"trtorch::logging::log::lvl":[27,2,1,"_CPPv4N7trtorch7logging3logE5LevelNSt6stringE"],"trtorch::logging::log::msg":[27,2,1,"_CPPv4N7trtorch7logging3logE5LevelNSt6stringE"],"trtorch::logging::set_is_colored_output_on":[26,1,1,"_CPPv4N7trtorch7logging24set_is_colored_output_onEb"],"trtorch::logging::set_is_colored_output_on::colored_output_on":[26,2,1,"_CPPv4N7trtorch7logging24set_is_colored_output_onEb"],"trtorch::logging::set_logging_prefix":[24,1,1,"_CPPv4N7trtorch7logging18set_logging_prefixENSt6stringE"],"trtorch::logging::set_logging_prefix::prefix":[24,2,1,"_CPPv4N7trtorch7logging18set_logging_prefixENSt6stringE"],"trtorch::logging::set_reportable_log_level":[28,1,1,"_CPPv4N7trtorch7logging24set_reportable_log_levelE5Level"],"trtorch::logging::set_reportable_log_level::lvl":[28,2,1,"_CPPv4N7trtorch7logging24set_reportable_log_levelE5Level"],"trtorch::ptq::Int8CacheCalibrator":[3,3,1,"_CPPv4I0EN7trtorch3ptq19Int8CacheCalibratorE"],"trtorch::ptq::Int8CacheCalibrator::Algorithm":[3,7,1,"_CPPv4I0EN7trtorch3ptq19Int8CacheCalibratorE"],"trtorch::ptq::Int8CacheCalibrator::Int8CacheCalibrator":[3,1,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibrator19Int8CacheCalibratorERKNSt6stringE"],"trtorch::ptq::Int8CacheCalibrator::Int8CacheCalibrator::cache_file_path":[3,2,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibrator19Int8CacheCalibratorERKNSt6stringE"],"trtorch::ptq::Int8CacheCalibrator::getBatch":[3,1,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibrator8getBatchEA_PvA_PKci"],"trtorch::ptq::Int8CacheCalibrator::getBatch::bindings":[3,2,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibrator8getBatchEA_PvA_PKci"],"trtorch::ptq::Int8CacheCalibrator::getBatch::names":[3,2,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibrator8getBatchEA_PvA_PKci"],"trtorch::ptq::Int8CacheCalibrator::getBatch::nbBindings":[3,2,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibrator8getBatchEA_PvA_PKci"],"trtorch::ptq::Int8CacheCalibrator::getBatchSize":[3,1,1,"_CPPv4NK7trtorch3ptq19Int8CacheCalibrator12getBatchSizeEv"],"trtorch::ptq::Int8CacheCalibrator::operator nvinfer1::IInt8Calibrator*":[3,1,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibratorcvPN8nvinfer115IInt8CalibratorEEv"],"trtorch::ptq::Int8CacheCalibrator::readCalibrationCache":[3,1,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibrator20readCalibrationCacheER6size_t"],"trtorch::ptq::Int8CacheCalibrator::readCalibrationCache::length":[3,2,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibrator20readCalibrationCacheER6size_t"],"trtorch::ptq::Int8CacheCalibrator::writeCalibrationCache":[3,1,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibrator21writeCalibrationCacheEPKv6size_t"],"trtorch::ptq::Int8CacheCalibrator::writeCalibrationCache::cache":[3,2,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibrator21writeCalibrationCacheEPKv6size_t"],"trtorch::ptq::Int8CacheCalibrator::writeCalibrationCache::length":[3,2,1,"_CPPv4N7trtorch3ptq19Int8CacheCalibrator21writeCalibrationCacheEPKv6size_t"],"trtorch::ptq::Int8Calibrator":[4,3,1,"_CPPv4I00EN7trtorch3ptq14Int8CalibratorE"],"trtorch::ptq::Int8Calibrator::Algorithm":[4,7,1,"_CPPv4I00EN7trtorch3ptq14Int8CalibratorE"],"trtorch::ptq::Int8Calibrator::DataLoaderUniquePtr":[4,7,1,"_CPPv4I00EN7trtorch3ptq14Int8CalibratorE"],"trtorch::ptq::Int8Calibrator::Int8Calibrator":[4,1,1,"_CPPv4N7trtorch3ptq14Int8Calibrator14Int8CalibratorE19DataLoaderUniquePtrRKNSt6stringEb"],"trtorch::ptq::Int8Calibrator::Int8Calibrator::cache_file_path":[4,2,1,"_CPPv4N7trtorch3ptq14Int8Calibrator14Int8CalibratorE19DataLoaderUniquePtrRKNSt6stringEb"],"trtorch::ptq::Int8Calibrator::Int8Calibrator::dataloader":[4,2,1,"_CPPv4N7trtorch3ptq14Int8Calibrator14Int8CalibratorE19DataLoaderUniquePtrRKNSt6stringEb"],"trtorch::ptq::Int8Calibrator::Int8Calibrator::use_cache":[4,2,1,"_CPPv4N7trtorch3ptq14Int8Calibrator14Int8CalibratorE19DataLoaderUniquePtrRKNSt6stringEb"],"trtorch::ptq::Int8Calibrator::getBatch":[4,1,1,"_CPPv4N7trtorch3ptq14Int8Calibrator8getBatchEA_PvA_PKci"],"trtorch::ptq::Int8Calibrator::getBatch::bindings":[4,2,1,"_CPPv4N7trtorch3ptq14Int8Calibrator8getBatchEA_PvA_PKci"],"trtorch::ptq::Int8Calibrator::getBatch::names":[4,2,1,"_CPPv4N7trtorch3ptq14Int8Calibrator8getBatchEA_PvA_PKci"],"trtorch::ptq::Int8Calibrator::getBatch::nbBindings":[4,2,1,"_CPPv4N7trtorch3ptq14Int8Calibrator8getBatchEA_PvA_PKci"],"trtorch::ptq::Int8Calibrator::getBatchSize":[4,1,1,"_CPPv4NK7trtorch3ptq14Int8Calibrator12getBatchSizeEv"],"trtorch::ptq::Int8Calibrator::operator nvinfer1::IInt8Calibrator*":[4,1,1,"_CPPv4N7trtorch3ptq14Int8CalibratorcvPN8nvinfer115IInt8CalibratorEEv"],"trtorch::ptq::Int8Calibrator::readCalibrationCache":[4,1,1,"_CPPv4N7trtorch3ptq14Int8Calibrator20readCalibrationCacheER6size_t"],"trtorch::ptq::Int8Calibrator::readCalibrationCache::length":[4,2,1,"_CPPv4N7trtorch3ptq14Int8Calibrator20readCalibrationCacheER6size_t"],"trtorch::ptq::Int8Calibrator::writeCalibrationCache":[4,1,1,"_CPPv4N7trtorch3ptq14Int8Calibrator21writeCalibrationCacheEPKv6size_t"],"trtorch::ptq::Int8Calibrator::writeCalibrationCache::cache":[4,2,1,"_CPPv4N7trtorch3ptq14Int8Calibrator21writeCalibrationCacheEPKv6size_t"],"trtorch::ptq::Int8Calibrator::writeCalibrationCache::length":[4,2,1,"_CPPv4N7trtorch3ptq14Int8Calibrator21writeCalibrationCacheEPKv6size_t"],"trtorch::ptq::make_int8_cache_calibrator":[31,1,1,"_CPPv4I0EN7trtorch3ptq26make_int8_cache_calibratorE19Int8CacheCalibratorI9AlgorithmERKNSt6stringE"],"trtorch::ptq::make_int8_cache_calibrator::Algorithm":[31,7,1,"_CPPv4I0EN7trtorch3ptq26make_int8_cache_calibratorE19Int8CacheCalibratorI9AlgorithmERKNSt6stringE"],"trtorch::ptq::make_int8_cache_calibrator::cache_file_path":[31,2,1,"_CPPv4I0EN7trtorch3ptq26make_int8_cache_calibratorE19Int8CacheCalibratorI9AlgorithmERKNSt6stringE"],"trtorch::ptq::make_int8_calibrator":[30,1,1,"_CPPv4I00EN7trtorch3ptq20make_int8_calibratorE14Int8CalibratorI9Algorithm10DataLoaderE10DataLoaderRKNSt6stringEb"],"trtorch::ptq::make_int8_calibrator::Algorithm":[30,7,1,"_CPPv4I00EN7trtorch3ptq20make_int8_calibratorE14Int8CalibratorI9Algorithm10DataLoaderE10DataLoaderRKNSt6stringEb"],"trtorch::ptq::make_int8_calibrator::DataLoader":[30,7,1,"_CPPv4I00EN7trtorch3ptq20make_int8_calibratorE14Int8CalibratorI9Algorithm10DataLoaderE10DataLoaderRKNSt6stringEb"],"trtorch::ptq::make_int8_calibrator::cache_file_path":[30,2,1,"_CPPv4I00EN7trtorch3ptq20make_int8_calibratorE14Int8CalibratorI9Algorithm10DataLoaderE10DataLoaderRKNSt6stringEb"],"trtorch::ptq::make_int8_calibrator::dataloader":[30,2,1,"_CPPv4I00EN7trtorch3ptq20make_int8_calibratorE14Int8CalibratorI9Algorithm10DataLoaderE10DataLoaderRKNSt6stringEb"],"trtorch::ptq::make_int8_calibrator::use_cache":[30,2,1,"_CPPv4I00EN7trtorch3ptq20make_int8_calibratorE14Int8CalibratorI9Algorithm10DataLoaderE10DataLoaderRKNSt6stringEb"],STR:[5,0,1,"c.STR"],TRTORCH_API:[6,0,1,"c.TRTORCH_API"],TRTORCH_HIDDEN:[7,0,1,"c.TRTORCH_HIDDEN"],TRTORCH_MAJOR_VERSION:[8,0,1,"c.TRTORCH_MAJOR_VERSION"],TRTORCH_MINOR_VERSION:[12,0,1,"c.TRTORCH_MINOR_VERSION"],TRTORCH_PATCH_VERSION:[9,0,1,"c.TRTORCH_PATCH_VERSION"],TRTORCH_VERSION:[10,0,1,"c.TRTORCH_VERSION"],XSTR:[11,0,1,"c.XSTR"],trtorch:[61,8,0,"-"]},"trtorch.logging":{Level:[60,9,1,""],get_is_colored_output_on:[60,10,1,""],get_logging_prefix:[60,10,1,""],get_reportable_log_level:[60,10,1,""],log:[60,10,1,""],set_is_colored_output_on:[60,10,1,""],set_logging_prefix:[60,10,1,""],set_reportable_log_level:[60,10,1,""]},"trtorch.logging.Level":{Debug:[60,11,1,""],Error:[60,11,1,""],Info:[60,11,1,""],InternalError:[60,11,1,""],Warning:[60,11,1,""]},trtorch:{DeviceType:[61,9,1,""],EngineCapability:[61,9,1,""],TensorRTCompileSpec:[61,10,1,""],check_method_op_support:[61,10,1,""],compile:[61,10,1,""],convert_method_to_trt_engine:[61,10,1,""],dtype:[61,9,1,""],dump_build_info:[61,10,1,""],get_build_info:[61,10,1,""],logging:[60,8,0,"-"]}},objnames:{"0":["c","macro","C macro"],"1":["cpp","function","C++ function"],"10":["py","function","Python function"],"11":["py","attribute","Python attribute"],"2":["cpp","functionParam","functionParam"],"3":["cpp","class","C++ class"],"4":["cpp","enum","C++ enum"],"5":["cpp","enumerator","C++ enumerator"],"6":["cpp","member","C++ member"],"7":["cpp","templateParam","templateParam"],"8":["py","module","Python module"],"9":["py","class","Python class"]},objtypes:{"0":"c:macro","1":"cpp:function","10":"py:function","11":"py:attribute","2":"cpp:functionParam","3":"cpp:class","4":"cpp:enum","5":"cpp:enumerator","6":"cpp:member","7":"cpp:templateParam","8":"py:module","9":"py:class"},terms:{"001s":49,"00f1b6db":49,"01s":49,"04s":49,"07s":49,"0c106ec84f199a0fbcf1199010166986da732f9b0907768c9ac5ea5b120772db":63,"11k":49,"12a":49,"16280mib":49,"1x1":51,"24k":49,"2_20200626":63,"2c365_subsampl":49,"2mib":49,"300w":49,"300x300":51,"31c":49,"32w":49,"32x32":49,"33c":49,"33w":49,"34c":49,"34w":49,"353k":49,"35c":49,"35k":49,"35w":49,"36c":49,"37c":49,"43w":49,"442k":49,"4fef":49,"53k":49,"55k":49,"774kb":49,"818977576572eadaf62c80434a25afe44dbaa32ebda3a0919e389dcbe74f8656":63,"81k":49,"84e944ff11f8":49,"891mib":49,"9205bed204e2ae7aafd2e01cce0f21309e281e18d5bfd7172ef8541771539d41":63,"94k":49,"9ab0":49,"abstract":[55,58],"byte":61,"case":[1,2,44,50,51,52,55,58,63,64],"catch":[53,62],"char":[3,4,42,62],"class":[30,31,42,43,44,48,49,50,51,55,58,60,61,62,64],"const":[1,2,3,4,30,31,33,35,36,42,43,44,53,58,62,64],"default":[1,2,3,4,17,30,31,41,43,44,49,51,61,62,64,65,66],"enum":[1,2,40,43,44,48,60,64],"export":63,"final":[52,54,56,63],"float":[61,62,65],"function":[1,2,3,4,44,45,48,49,50,51,53,55,58,62,66],"import":[49,50,51,53,62,65,66],"int":[3,4,42,62],"long":52,"new":[1,2,3,4,33,44,45,49,50,55,56,58,60,62],"public":[1,2,3,4,42,43,44,45,64],"return":[1,2,3,4,23,25,30,31,32,33,35,36,40,41,42,43,44,49,50,53,54,55,56,58,60,61,62,64],"short":53,"static":[44,45,52,58,61,62],"super":[42,50,62],"throw":[53,62],"true":[1,2,4,43,44,49,50,51,53,58,61,62,64,66],"try":[49,50,56,62,66],"void":[3,4,24,26,27,28,34,40,42,43],"while":64,And:62,Are:40,Bus:49,But:62,For:[49,50,51,52,62,63,66],IDs:51,Its:58,Not:3,One:[61,62],PRs:62,Thats:62,The:[2,44,49,50,51,52,53,54,55,56,58,60,63,64,65,66],Then:[63,64,66],There:[4,49,51,52,58,62,64],These:[52,55],Use:[44,58,61,64],Useful:59,Using:[4,49,51,59],Will:35,With:[49,62,64],___torch_mangle_10:62,___torch_mangle_4847:55,___torch_mangle_5:62,___torch_mangle_9:62,__attribute__:41,__gnuc__:41,__init__:[50,62],__torch__:[55,62],__torch___pytorch_detection_ssd_src_model_ssd300_trt_engin:55,__torch___torchvision_models_resnet____torch_mangle_4847_resnet_trt_engin:55,__visibility__:41,_all_:53,_convolut:62,_jit_to_tensorrt:[61,66],a100:[49,50],aarch64:56,abl:[49,50,52,53,58,59,64,66],about:[51,52,55,58,61,62,65],abov:[28,51,62],acceler:[49,50,62],accept:[44,45,55,58,65],access:[51,53,58,59,62,66],accord:58,accuraci:[51,64],achiev:[49,50],across:53,acthardtanh:58,activ:[62,64],activationtyp:58,actual:[50,53,55,58,60,62],adaptiveavgpool2d:49,add:[27,52,53,58,60,62,63],add_:[53,62],add_patch:51,addactiv:58,added:[28,52],addit:[51,53,62],addlay:62,addshuffl:62,advanc:64,affin:49,after:[51,52,59,62,65],again:[42,51,55,58],against:[62,65],agre:[49,50,51],ahead:62,aim:53,algorithm:[3,4,30,31,42,64],all:[17,40,41,42,43,49,50,51,53,55,61,62,64,65],alloc:58,allow:[44,45,49,50,51,52,53,61,65],allow_gpu_fallback:[43,44,61,66],almost:62,alpha:51,alreadi:[49,52,53,62,65],also:[31,49,50,51,52,58,59,62,63,64],alwai:[3,4,26],amazonaw:49,amp:49,analog:62,analogu:58,analysi:[49,51],ani:[49,50,51,52,58,61,62,63,65],annot:[51,58,62],anoth:62,aot:[59,62],apach:[49,50,51],apex:51,api:[13,15,16,40,41,42,43,56,58,61,62,64,66],apidirectori:[22,46],append:[49,50,51],appli:64,applic:[2,31,44,49,50,51,53,56,62,65,66],approach:[49,50],apr:62,aquir:62,architectur:[51,59,63],archiv:63,aren:62,arg:[52,62],argc:62,argmax:49,argument:[53,55,58,62,65],argv:62,around:[55,58,62],arrai:[3,4,52],arrayref:[43,44,45],arti:49,arxiv:64,aspect:65,assembl:[52,62],assign:[3,4],associ:[52,58,62],associatevalueandivalu:58,associatevalueandtensor:[58,62],assum:66,aten:[53,57,58,62],attach:51,attribut:[53,55,62],aug:49,auto:[42,58,62,64],automat:[49,50,62],avail:[49,50,51,58,63],ave:[49,50],averag:[44,49,50,51,61,65],avg:[51,65],avgpool:[49,51],avoid:49,await:49,axes:49,axi:49,back:[53,55,56,62],back_insert:42,backbon:51,backend:[49,50,51,61,66],background:51,base:[34,46,47,49,50,51,55,60,62,63,64],bash:[51,63],basi:[49,50,51],basic:65,batch:[3,4,42,44,49,50,51,61,64,65],batch_norm:58,batch_siz:[42,51,64],batched_data_:42,batchnorm2d:49,batchnorm:[51,53],batchtyp:42,bazel:[56,63],bazel_vers:63,bazelbuild:63,bazelisk:63,bazelvers:63,bbox:51,bdist_wheel:63,becaus:[58,62,63],becom:58,been:[52,58,62],befor:[51,53,56,58,59,62,63],begin:[42,63],beginn:62,behav:[49,51],behavior:61,being:62,below:[51,58,62],benchmark:50,benefit:[58,62],best:[44,45,49,50,63],best_result:51,best_results_per_input:51,best_results_per_input_trt:51,better:[49,50,51,62,64],between:[51,58,64],bia:[49,50,53,62],bin:[49,63],binari:[42,64],bind:[3,4,42],bird:49,bit:[58,61,62],blob:57,block0:53,block1:53,block:[52,53],bn1:49,bn2:49,bn3:49,bool:[1,2,3,4,25,26,30,35,40,42,43,44,53,58,60,61,62,64],bot:51,both:[49,50,51,62,63],bottleneck:49,bound:51,box:51,branch:63,breed:49,briefli:62,bsd:[40,41,42,43],buffer:[3,4],bug:63,build:[30,31,32,44,52,54,56,58,61,62,64,65],build_fil:63,builderconfig:43,built:[56,63,65],bust:49,bzl:63,c10:[1,2,43,44,45,62,64],c96b:49,c_api:57,c_str:[58,62],cach:[3,4,30,31,42,49,51,62,64,65],cache_:42,cache_fil:42,cache_file_path:[3,4,30,31,42],cache_file_path_:42,cache_size_:42,calcul:[52,62],calibr:[3,4,30,31,42,44,62,64,65],calibration_cache_fil:[30,31,64],calibration_dataload:[30,64],calibration_dataset:64,call:[30,31,33,44,49,50,51,53,55,58,61,62,66],callmethod:62,can:[1,2,4,30,31,36,44,45,49,50,51,52,53,54,55,56,58,61,62,63,64,65,66],cannot:[49,50,51,53,62],cap:49,capabl:[43,44,61,65,66],captur:51,cast:[3,4,53],cat:63,caught:53,caus:[58,63],cdll:62,ceil_mod:49,cell:51,centercrop:49,cerr:62,certifi:49,cf0691493d05062fe3239cf76773bae4c5124f4b039050dbdd291c652af3ab2a:63,chain:58,chanc:58,chang:[31,49,50,53,56,64],channel:49,check:[1,2,35,44,51,53,58,61,62,63,65],check_method_op_support:61,checkmethodoperatorsupport:[21,37,43,46,47,62],checkpoint:51,checkpoint_from_distribut:51,chimpansee_amber_r_1920x1080:49,chimpanze:49,choos:[62,63],cifar10:64,cifar:64,classes_to_label:51,classif:[50,51,62],classifi:50,clear:42,cli:[62,65],close:62,closer:53,cloudfront:49,coco:51,cocodataset:51,code:[49,50,51,56,59,62],collect:62,color:[25,26,60],colored_output_on:[26,40,60],com:[49,50,57,62,63,64],come:[49,50],command:[49,62,63,65],comment:63,common:[49,51,52,53],common_subexpression_elimin:53,commun:62,compar:51,comparis:[1,44],comparison:[2,44],compat:[1,2,44,53,55,63],compil:[33,35,36,44,49,50,51,53,55,58,61,64,65,66],compile_set:[50,62],compile_spec:[61,64],compilegraph:[21,37,43,46,47,62,64],compilespec:[0,3,4,21,33,36,37,43,46,47,61,62,64],compilespecstruct:[0,46],complet:[49,50,51,62],complex:62,compli:51,complianc:[49,50,51],compliat:64,compon:[50,54,56,62],compos:[49,50,51,62],composit:62,comprehens:51,comput:[49,50,51,63,64],conclus:49,condit:[49,50,51],confid:[49,51],config:63,configur:[33,36,59,61,62,63,64],connect:[49,53],consid:[49,62],consol:65,consolid:62,constant:[52,53,62],constexpr:[1,2,43,44],construct:[1,2,3,4,44,45,52,53,54,56,58,62],constructor:[1,44,55,62],consum:[4,52,62],contain:[30,35,49,50,51,52,53,58,61,62,63,64],content:64,context:[52,54,55,56],continu:[49,50,51],contributor:62,control:[49,50,51,62],conv1:[49,50,62],conv2:[49,50,62],conv2d:[49,50,62],conv3:49,conv4_x:51,conv5_x:51,conv:62,conveni:51,convers:[49,51,53,55,61,62],conversionctx:[58,62],convert:[3,4,33,35,36,50,51,53,54,56,59,61,66],convert_method_to_trt_engin:[61,66],convertgraphtotrtengin:[21,37,43,46,47,62],convien:44,convienc:[3,4],convolut:[51,64],coordin:56,copi:[42,49,50,51,58],copyright:[40,41,42,43,49,50,51,62],core:[49,50,51,53,56,62],corpor:[40,41,42,43,49,50,51],correct:63,correspond:[49,51,58],coupl:[49,50,52,56],cout:62,cp36:63,cp36m:63,cp37:63,cp37m:63,cp38:63,cpp:[14,15,16,40,41,42,43,48,53,56,62,64],cpp_frontend:64,cppdirectori:[22,46],cppdoc:62,creat:[30,31,49,50,51,52,55,58,61,65],credit:62,csrc:[53,57],cstddef:64,ctx:[58,62],ctype:62,cu102:63,cuda:[44,49,50,51,55,61,62,63,66],cudafloattyp:62,cudnn8:63,cudnn:[49,50,51],curl:63,current:[23,58],custom:63,cycler:49,d17fnq9dkz9hgj:49,data:[1,3,4,30,31,42,44,49,50,51,52,54,56,58,64],data_dir:64,dataflow:[58,62],dataload:[4,30,31,42,44,64],dataloader_:42,dataloaderopt:64,dataloaderuniqueptr:[4,42],dataset:[31,51,64],datatyp:[2,21,37,43,44,46,47,61],datatypeclass:[0,46],dateutil:49,dbg:63,dead_code_elimin:53,deal:58,debug:[17,26,43,44,58,60,61,65,66],debugg:[61,65],decid:50,decod:49,decode_result:51,dedic:53,deep:[49,50,51,58,59,64],deeplearn:57,deeplearningexampl:51,def:[49,50,51,62],defin:[1,2,3,4,17,23,24,25,26,27,28,29,30,31,32,33,34,35,36,41,44,45,48,49,50,62,64,65],definit:[48,58],delet:[1,2,43,44,53],demo:[49,51,64],demonstr:[49,50,51],denorm:51,dep:63,depend:[31,32,49,51,52,56,62],depickl:55,deploi:[49,50,59,62,64],deploy:[49,50,62,64,65],describ:[44,49,50,51,58,61,62,66],deseri:[61,62],design:[49,50],destroi:58,destructor:58,detail:[49,62],detect:[49,55],detections_batch:51,determin:53,develop:[49,50,59,62,63],deviat:65,devic:[2,43,44,49,50,61,62,65],device_typ:[61,66],devicetyp:[0,21,37,43,44,46,47,61],dict:[51,61],dictionari:[61,62,66],differ:[31,50,51,53,56,59,62],differenti:[49,50],dilat:49,dim:49,dimens:53,directli:[58,59,64],directori:[18,19,20,21,22,40,41,42,43,46,49,63,64],disabl:[60,63,65],disclos:63,disp:49,displai:65,dist:[49,63],distdir:63,distribut:[49,50,51,61,62,64],dla:[2,44,61,65],doc:[56,57,63],docker:[49,50,51],docsrc:56,document:[40,41,42,43,46,47,56,62,64,66],doe:[41,42,49,51,53,58,64],doesn:62,doing:[51,52,53,62,64],domain:64,don:[50,58,64],done:[49,51,52,56],dont:40,down:[49,50,63],download:[51,63],downsampl:49,doxygen_should_skip_thi:[42,43],driver:[49,63],drop:[51,63],dtype:[49,50,51,61],due:[3,4,49,51],dump:[34,63,65],dump_build_info:[21,37,43,46,47,61],dure:[58,64,65],dynam:[44,45,61],each:[3,4,44,51,52,53,55,58,61,62],eager:[49,50],earlier:49,easi:[52,53,62,65],easier:[54,56,58,62,64],easiest:63,easili:[3,4],ecc:49,ecosystem:[49,50,51],edgecolor:51,edu:64,effect:[53,62,64],effici:58,either:[44,45,49,50,51,58,61,62,63,65],element:55,element_typ:42,els:[41,42,61],emb:62,embed:[55,62,65],emit:52,empti:[50,62],emum:[17,44],enabl:[3,4,25,49,50,51,60,61],encount:63,end:[42,58,62],end_dim:62,end_tim:[49,50,51],endif:[41,42,43],enforc:62,engin:[1,2,33,36,44,45,52,54,56,59,61,62,64,65,66],engine_converted_from_jit:62,enginecap:[43,44,61,66],enhanc:51,ensur:[31,53],enter:52,entri:[44,58,61],entropi:[30,31,64],enumer:[1,2,17,44],eps:49,equival:[33,49,50,51,54,56,58,61,62],equivil:36,error:[17,52,53,56,60,62,63],etc:61,eval:[49,50,51,62],evalu:[51,54,55,56],evaluated_value_map:[52,58],even:62,everi:62,everyth:17,exactli:51,exampl:[49,50,51,55,56,58,62,64],except:[49,50,51],exception_elimin:53,execpt:53,execut:[49,50,51,53,54,55,56,61,62,64],execute_engin:[55,62],exeuct:55,exhaust:62,exist:[4,33,35,36,49,61,63,64],expand:53,expect:[49,53,58,62],experi:[49,50],explic:42,explicit:[3,4,43,53,59,64],explicitli:[64,66],explict:42,explictli:[1,44],express:[49,50,51],extend:[54,56,58,62],extent:[59,62],extra:[44,62],extract:62,extractor:50,f16:[62,65],f32:65,facecolor:51,factori:[4,30,31,64],fail:62,fallback:[58,65],fals:[1,2,3,4,42,43,44,49,51,61,62,66],famili:[49,50,51],familyhandyman:49,fan:49,fashion:62,fbed:49,fc1:[50,62],fc2:[50,62],fc3:[50,62],feat:[50,62],featur:[49,50,51,62,64,65,66],fed:[3,4],feed:[30,31,62],feel:59,few:[49,50],field:[3,4,64],fig:[49,51],file:[1,2,3,4,5,6,7,8,9,10,11,12,17,23,24,25,26,27,28,29,30,31,32,33,34,35,36,44,45,49,50,51,55,56,61,62,63,64,65],file_path:65,filer_publ:49,filer_public_thumbnail:49,fill:[49,50],filter:51,find:[4,51,62],finish:51,first:[49,50,51,52,53,62,64],five:51,fix:[44,49,51],fixed_s:[43,44],flag:[63,65],flatten:[50,62],flatten_convert:62,flexibl:[49,50,51],float16:[61,65],float32:[49,61,65],flow:[49,50,51,58,62],fly:62,follow:[49,50,51,62,63,64,65],footprint:[49,50],forc:65,form:52,format:[49,50,51,61,65],forum:63,forward:[30,31,33,50,55,58,61,62,64,66],found:[40,41,42,43,49,51,62,63,64],fp16:[1,44,50,51,59,61,62],fp32:[1,44,50,51,59,64],framework:[49,50,51],freed:58,freez:62,freeze_modul:53,from:[1,2,3,4,30,31,42,44,45,49,50,51,52,53,54,55,56,58,59,62,64,65],fssl:63,fstream:[20,42],full:[58,62,64,65],fulli:[35,53,61,62,64],fuse:[49,50],fuse_addmm_branch:53,fuse_flatten_linear:53,fuse_linear:53,fusion:58,futur:[49,50],gain:51,gaurd:41,gcc:[56,62],gear:64,gener:[3,4,31,49,50,51,53,55,56,58,62,64,65],get:[1,2,3,4,23,32,42,44,45,51,53,58,60,63,64,66],get_batch_impl:42,get_build_info:[21,37,43,46,47,61],get_coco_object_dictionari:51,get_is_colored_output_on:[18,38,40,46,47,60],get_logging_prefix:[18,38,40,46,47,60],get_reportable_log_level:[18,38,40,46,47,60],getattr:[53,55,62],getbatch:[3,4,42],getbatchs:[3,4,42],getdimens:[58,62],getoutput:[58,62],github:[49,50,51,57,62,63,64],give:50,given:[44,49,51,53,61,62,65,66],global:[27,62],gnu:63,goal:58,going:[42,62],good:[42,58],got:62,govern:[49,50,51],gpu:[2,33,36,44,49,50,61,62,65,66],granular:50,graph:[17,33,35,36,43,49,50,51,52,54,56,58,59,61,62],great:[49,50,51,62],green_mamba:49,gtc:59,guard:53,guard_elimin:53,gulf:49,hack:42,hakaimagazin:49,half:[50,51,61,62,65,66],handl:[51,53,55],happen:[49,50,62],hardtanh:58,hardwar:[49,50,51],has:[49,50,51,52,53,56,58,62,64],hash:63,have:[31,42,49,50,51,52,53,58,59,62,63,64,65],haven:62,head:51,header:[49,62],help:[26,49,50,52,58,62,65],helper:[49,50,51,58],here:[42,49,50,51,52,55,62,63,64],hermet:63,hfile:[22,46],hidden:41,high:[49,51,53,62],higher:[53,62],hinton:64,hold:[44,45,52,58,64],holder:55,home:63,hood:56,host:63,how:[3,4,49,51,62,66],howev:[31,49,50,51,63],html:[57,62,63,64],http:[49,50,51,57,62,63,64],http_archiv:63,hub:[49,51],huski:49,idea:53,ident:65,idx:51,ifndef:[42,43],ifstream:42,iint8calibr:[3,4,30,31,42,43,44,64],iint8entropycalibrator2:[3,4,30,31,42,64],iint8minmaxcalibr:[30,31,64],ilay:58,imag:[49,51,64],image_idx:51,imagenet:49,imagenet_cla:49,imagenet_class_index:49,images_:64,img0:49,img1:49,img2:49,img3:49,img:49,img_path:49,impact:[49,50,51],implement:[3,4,49,50,51,53,55,62,64],impli:[49,50,51],implic:53,imshow:[49,51],in_featur:[49,50],in_shap:62,in_tensor:62,incas:42,includ:[14,16,17,32,34,40,41,42,43,48,49,50,51,61,62,63,64,65],includedirectori:[22,46],ind:49,independ:[49,51],index:[57,59,64],inetworkdefinit:52,infer:[49,50,53,62,64],info:[17,33,36,43,44,58,60,62,65],inform:[28,32,34,51,52,59,61,62,64,65,66],infrastructur:64,ingest:56,inherit:[46,47,64],inlin:[42,53,62],inplac:49,input0:62,input1:62,input2:62,input:[3,4,31,42,44,45,49,50,51,52,53,55,58,61,62,64,65,66],input_0:[55,62],input_batch:49,input_data:[49,50,51,62],input_file_path:65,input_rang:[43,44],input_s:62,input_shap:[49,50,51,61,62,64,65,66],input_tensor:49,inputrang:[21,37,43,44,46,47,62],inputrangeclass:[0,46],inspect:[50,58,62],instal:[49,51,59,62],instanc:[49,50,53,62],instanti:[54,55,56,58,62],instatin:[1,2,44],instead:[52,53,62,65],instnanti:55,instruct:[62,63],insur:63,int16_t:43,int64_t:[43,44,45,64],int8:[1,42,44,59,61,64,65],int8_t:43,int8cachecalibr:[20,31,39,42,46,47],int8cachecalibratortempl:[0,46],int8calibr:[3,20,30,39,42,46,47],int8calibratorstruct:[0,46],integ:61,integr:[49,50,59],intent:53,intercompat:[49,51],interest:53,interfac:[1,2,44,55,56,58,62,64],intermedi:[17,49,50,62],intern:[2,17,44,49,50,51,58,62],internal_error:60,internalerror:60,interpret:[49,50,55],intro_to_torchscript_tutori:62,introduc:[49,50,51],invok:62,involv:[49,50],ios:42,iostream:[20,42,62],is_avail:49,is_train:64,iscustomclass:58,issu:[3,4,49,50,62,63],istensor:58,istream_iter:42,it_:42,item:49,itensor:[52,58,62],iter:[20,42,44,49,50,51,52,61,65],its:[31,49,50,51,52,55,58],itself:[1,2,44,53,63,65,66],ivalu:[52,55,58,62],jetson:[49,50,61],jit:[33,35,36,43,49,50,51,52,53,54,55,56,57,58,61,62,65,66],jpeg:49,jpg:[49,51],jpg__1920x1080_q85_subject_loc:49,json:49,json_fil:49,just:[42,43,49,51,53,59,62,66],kchar:[1,43,44],kclip:58,kcpu:[2,44],kcuda:[2,44,62],kdebug:[17,40,42],kdefault:[43,44],kdla:[2,43,44],kei:[61,62],kernel:[44,49,50,58,61,62,65],kernel_s:[49,50],kerror:[17,40],kfloat:[1,43,44],kgpu:[2,43,44],kgraph:[17,40,53],khalf:[1,43,44,62],ki8:64,kind:[49,50,51,52,61],kinfo:[17,40,42],kinternal_error:[17,40],kiwisolv:49,know:[40,58],known:51,kriz:64,krizhevski:64,ksafe_dla:[43,44],ksafe_gpu:[43,44],ktest:64,ktrain:64,kwarn:[17,40],label:[51,64],laid:62,lambda:[58,62],languag:[49,50,51,62],larg:[49,50,54,56,62,64],larger:64,last:[51,53],later:[31,62],latest:63,law:[49,50,51],layer1:49,layer2:49,layer3:49,layer4:49,layer:[44,49,50,51,52,53,58,61,62,64,65],ld_library_path:63,ldd:63,learn:[59,62,63,64],least:49,leav:[50,53],left:51,len:[49,51],lenet:[51,62],lenet_script:62,lenetclassifi:[50,62],lenetfeatextractor:[50,62],length:[3,4,42,49],let:[44,49,50,51,53,58,65],level:[18,23,27,28,38,40,42,46,47,49,50,53,56,60,62],levelnamespac:[0,46],leverag:[49,50,51,64],lib:[49,53,62,63],librari:[32,40,41,42,43,49,50,51,54,55,56,58,62],libtorch:[4,34,49,50,51,58,62,63,64],libtorch_pre_cxx11_abi:63,libtrtorch:[62,63,65],licens:[40,41,42,43,49,50,51,62],like:[49,50,51,52,53,55,58,62,63,64,65],limit:[49,50,51,53,64],line:[62,65],linear:[49,50,62],linewidth:51,link:[52,59,62,65],linux:[56,62,63],linux_x86_64:63,list:[18,19,20,21,35,48,51,52,55,58,61,62,63],listconstruct:[52,55,62],listunpack:[55,62],live:58,load:[49,51,55,62,63,64,65,66],loader:[49,50,51],local:[49,51,53,62],locat:[51,64],log:[16,17,19,20,22,37,42,46,47,48,53,58,61],log_debug:58,logger:60,loggingenum:[0,46],loglevel:60,longer:[49,50],look:[52,53,62,64,66],loop_unrol:53,lorikeet:49,loss:64,lot:58,lower:[17,66],lower_graph:53,lower_tupl:53,loweralltupl:53,lowersimpletupl:53,lvl:[27,28,40],machin:[49,50,55,63,64],macro:[5,6,7,8,9,10,11,12,16,18,21,22,40,43,46,48],made:[51,53,54,56],mai:[49,50,51,52,55,56,62,64],main:[51,53,54,55,56,58,62],maintain:[55,58],major:[49,50,51,56],make:[49,50,51,52,62,63,64],make_data_load:[4,64],make_int8_cache_calibr:[20,39,42,46,47,64],make_int8_calibr:[20,31,39,42,46,47,64],manag:[52,54,56,58,62],mangag:53,manual:63,map:[2,44,52,53,54,56,58,62,64,66],master:[57,63,64],match:[44,53,63],matmul:[53,62],matplotlib:[49,51],matrix:57,matur:56,max:[43,44,45,50,58,61,62,65],max_batch_s:[43,44,61,65,66],max_c:65,max_h:65,max_n:65,max_pool2d:[50,62],max_val:58,max_w:65,maximum:[44,45,61,62,65],maxpool2d:49,maxpool:49,mean:[44,49,50,51,58,59,61,62,65],mechan:58,media:49,meet:61,member:[44,45,61],memori:[20,21,42,43,49,50,53,58,62],mention:49,menu:65,messag:[17,27,28,60,65],metadata:[55,58],method:[33,35,36,49,50,51,53,58,61,62,63,66],method_nam:[35,36,43,61,62],mig:49,might:53,min:[43,44,45,50,58,61,62,65],min_c:65,min_h:65,min_n:65,min_val:58,min_w:65,mini:49,minim:[44,61,64,65],minimum:[44,45,60,62],minmax:[30,31,64],miss:62,mix:51,mkdir:[49,63],mobilenet_v2:66,mod:[62,64],mode:[62,64],mode_:64,model:[55,62,64,66],model_math:51,modern:51,modifi:63,modul:[33,35,36,43,49,50,51,54,55,56,58,59,61,64,65,66],modular:62,momentum:49,more:[49,50,51,52,59,62,64,66],most:56,move:[30,42,43,49,50,53,55,62,64],msg:[27,40,60],much:[58,64],multipl:[55,64],must:[44,49,51,58,61,62,63,65],n01749939:49,n01820546:49,n02110185:49,n02481823:49,name:[3,4,35,36,42,49,51,55,58,61,62,63,66],namespac:[0,40,42,43,48,53,59,64],nano:63,nativ:[56,57,62],native_funct:57,nbbind:[3,4,42],ncol:49,necessari:40,need:[1,2,28,31,41,44,51,52,53,58,62,63,64],nest:[46,47],net:[49,58,62],network:[30,31,49,50,51,58,62,64],neural:[49,51],new_lay:58,new_local_repositori:63,new_siz:64,newer:[49,50],next:[3,4,51,52,55,64],ngc:51,nice:63,ninja:63,nlp:[30,31,64],no_grad:[49,50,51],node:[53,58,62],node_info:[58,62],noexcept:64,none:[51,58],normal:[1,2,44,49,50,51,62,64],noskipw:42,note:[2,44,49,58,62,63],notebook:[49,50,51,56],notic:[50,51],now:[49,50,51,53,56,58,62,63,66],nrow:49,nrun:[49,50,51],nullptr:[42,43,44],num:65,num_avg_timing_it:[43,44,61,66],num_it:65,num_min_timing_it:[43,44,61,66],number:[3,4,44,49,53,58,61,62,65],numer:65,numpi:[49,50,51],nvidia:[33,36,40,41,42,43,49,50,51,57,61,62,63,64,65],nvidia_deeplearningexamples_torchhub:51,nvidia_ncf:51,nvidia_ssd:51,nvidia_ssd_processing_util:51,nvidia_tacotron2:51,nvidia_waveglow:51,nvinfer1:[3,4,30,31,42,43,44,58,64],nvinfer:[20,42],nwarmup:[49,50,51],object:[1,2,3,4,44,45,58,61,62,66],observ:49,obsolet:51,obtain:[49,50,51],obvious:62,octet:49,off:[49,51,55],offici:63,ofstream:[42,62],older:56,olefil:49,onc:[40,41,42,43,52,53,55,62,64],one:[51,53,58,60,62],ones:[40,49,50,51,62,63],onli:[2,3,4,17,31,42,44,50,51,53,56,58,60,61,62,63,64,65],onnx:53,onto:[55,65],op_precis:[43,44,49,50,51,61,62,64,65,66],open:[49,50],oper:[1,2,3,4,35,42,43,44,49,50,52,53,54,55,56,58,59,61,64,65],ops:[49,51,53,62],opset:[54,56],opt:[43,44,45,50,61,62,63],opt_c:65,opt_h:65,opt_n:65,opt_w:65,optim:[44,45,49,50,51,53,59,62,65],optimi:62,optimin:[44,45],optimiz:[49,50,51],option:[42,61,63,64,65],order:[44,51,58,62],org:[49,50,51,57,62,63,64],origin:51,original_nam:50,other:[1,2,43,44,49,50,51,52,53,55,59,61,62,65],otherwis:63,our:[49,50,51,56,62],out:[35,42,49,50,52,53,54,56,58,60,61,62,63],out_featur:[49,50],out_shap:62,out_tensor:[58,62],output0:53,output:[25,26,44,49,50,51,52,53,55,58,60,62,63,65],output_file_path:65,output_s:49,outself:62,over:[49,50,54,56],overkil:50,overrid:[3,4,30,31,42,64],overview:[57,59],own:[49,50,58,62],p100:49,packag:[49,53,62,65],pad:49,page:59,pair:[58,64],paper:[49,51],paramet:[1,2,3,4,26,27,28,30,31,33,35,36,44,45,52,53,58,60,61,62],parent:[14,15,16,18,19,20,21],pars:62,part:[56,65],particular:50,pass:[52,54,55,56,58,62,64],patch:51,path:[4,13,14,15,16,30,31,49,50,51,62,63,64,65],path_to_trtorch_root:63,pathwai:62,pattern:[58,62],peephole_optimz:53,per:51,perf:49,perform:[30,31,49,50,51],performac:[44,45,64],permiss:[49,50,51],persist:49,phase:[17,58,62],pick:[50,62],pick_best:51,pickler:55,pid:49,pil:49,pillow:[49,51],pip3:63,pip3_import:63,pip:[49,51,63],pip_instal:63,pipelin:[62,65],piplein:62,place:[53,63,64],plan:[56,65],platform:[49,50,56,63],pleas:63,plot:51,plot_result:51,plt:[49,51],point:[61,62],pointer:[3,4,64],pop:55,portabl:[49,50,51,55],posit:65,possibl:[49,50],post:[30,31,44,59,62,65],power:[49,50,62],practic:[49,50],pragma:[40,41,42,43,64],pre:49,pre_cxx11_abi:63,precis:[44,50,51,59,61,62,64,65],pred:49,pred_label:51,pred_loc:51,predict:[49,51],prefer:62,prefix:[24,26,40,60],prepar:[49,50,51],prepare_input:51,prepare_tensor:51,preprint:64,preprocess:[49,64],preserv:[62,64],prespect:62,pretrain:[49,51,66],pretti:62,previous:[31,62],prim:[52,53,55,62],primarili:[56,62],primer:51,print:[17,35,42,49,50,51,60,61,62,66],priorit:63,privat:[3,4,42,43,64],prob:49,probabl:[49,51],probablil:49,process:[49,50,51,62,65,66],produc:[44,45,52,55,58,62],product:[49,50],profil:[44,45],program:[18,19,20,21,31,48,49,50,51,54,56,59,62,65],propog:53,provid:[3,4,44,55,58,61,62,63,64,66],providi:[54,56],ptq:[3,4,16,18,22,37,46,47,48,59,65],ptq_calibr:[3,4,43,44,64],ptqtemplat:[0,46],pull:63,pure:35,purpos:[49,51,63],push:55,push_back:42,pwr:49,py_test_dep:63,pypars:49,pyplot:[49,51],python3:[49,53,62,63],python:[49,50,51,56,65],python_api:57,pytorch:[49,51,54,55,56,58,61,62,63,64],pytorch_vision_v0:49,qualiti:[49,51],quantiz:[30,31,59,62,65],quantizatiom:44,question:62,quickli:[62,64,65],quit:[58,62],rais:53,raiseexcept:53,rand:62,randn:[49,50,51,62,66],rang:[44,45,49,50,51,61,62,65],rather:53,raw:51,read:[3,4,30,31,42,64],readcalibrationcach:[3,4,42],readm:[49,50,51],realiz:55,realli:58,reason:[1,44,51,62],recalibr:31,recipi:51,recognit:[49,64],recomend:[30,31],recommend:[30,31,62,63],recompil:51,record:[49,50,52,62],rect:51,rectangl:51,recurs:52,recursivescriptmodul:50,reduc:[49,50,53,54,56,64],refer:[54,56],referenc:[51,63],refit:[43,44,61,66],reflect:43,regard:63,regist:[55,58],registernodeconversionpattern:[58,62],registri:[52,62],reinterpret_cast:42,relationship:[46,47],relu:[49,50,62],remain:[49,50,51,53,64],remov:[49,51],remove_contigu:53,remove_dropout:53,remove_to:53,repack:55,replac:[51,53],report:[23,42],reportable_log_level:60,repositori:[49,51,56],repres:[44,45,58,60],represent:[49,50,53,58,62],request:[49,62],requir:[31,49,50,51,52,53,60,61,62,63,64,65],research:[49,50],reserv:[40,41,42,43,49,50,51],reset:42,residu:49,resiz:49,resnet50:49,resnet50_model:49,resnet:[51,55],resnet_50_trac:49,resnet_trt:55,resolv:[49,52,53,54,56],resourc:[52,64],respons:[31,49,55],restrict:[44,61,65],result:[49,50,52,53,61,62],results_per_input:51,ret:53,reus:[53,64],rgb:49,right:[40,41,42,43,49,50,51,53,56,58],rn50_preprocess:49,root:[40,41,42,43,49,51,63,64],rule:63,run:[2,36,44,49,50,51,52,53,54,55,56,58,59,61,62,63,64,65,66],runtim:[49,50,51,59,62],safe:[58,61],safe_dla:[61,65],safe_gpu:[61,65],safeti:[44,61],same:[49,51,55,62,63,66],sampl:[49,64],satisfi:49,save:[31,42,49,50,51,55,61,65],saw:62,scalar:58,scalartyp:[1,43,44],scale:64,schema:[58,62],scikit:51,scipi:51,scope:53,score:[49,51],scratch:31,script:[35,49,51,53,61,62,66],script_model:[50,62,66],scriptmodul:[61,62],sdk:[49,50,51,57],seamlessli:59,search:59,section:64,secur:63,see:[35,49,50,51,53,55,61,62],select:[30,31,36,44,49,50,61,64,65],self:[50,53,55,58,62],self_1:[55,62],sens:62,sent:49,separ:[49,50,51],sequenti:49,serial:[36,54,56,61,62],serializ:55,seril:55,serv:[55,65],set:[3,4,17,26,28,31,33,36,44,45,49,50,51,52,53,54,55,56,59,60,61,62,63,64,65],set_is_colored_output_on:[18,38,40,46,47,60],set_logging_prefix:[18,38,40,46,47,60],set_reportable_log_level:[18,38,40,46,47,60],setalpha:58,setbeta:58,setnam:[58,62],setreshapedimens:62,setup:64,sever:[17,27,60],sha256:63,shape:[44,45,49,50,51,58,61],share:63,ship:62,should:[1,3,4,31,43,44,49,52,58,59,60,61,64,65],show:[49,51],shown:62,shuffl:62,shutterstock_780480850:49,siberian:49,siberian_huski:49,side:[53,62],signifi:[44,45],signific:51,significantli:53,similar:[51,58,62,66],simonyan:64,simpil:64,simpl:[50,62],simpli:[50,53],simplic:[49,51],simplifi:52,sinc:[50,53,62,64],singl:[44,45,50,53,62,64,65],singular:58,site:[53,62,63],six:49,size:[3,4,42,44,45,49,50,51,53,61,62,64,65],size_t:[3,4,42,64],slither:49,sm_output:49,small:53,smi:49,snake:49,softmax:[49,51,53],softwar:[49,50,51],sole:64,some:[52,53,54,55,56,58,62,64],someth:[41,53],sort:[58,66],sourc:[40,41,42,43,49,51,56,61],space:64,spec:[61,66],specif:[33,49,50,51,53,54,56,61],specifi:[3,4,49,51,58,59,60,61,62,65,66],specifii:61,speed:[49,51],speedup:49,src:[55,57],ssd300:51,ssd300_trt:55,ssd:55,ssd_300_trace:51,ssd_trace:65,ssd_trt:65,sstream:[20,42],stabl:57,stack:[55,64],stage:52,stand:55,standard:[49,50,51,59,65,66],start:[51,52,63,66],start_dim:62,start_tim:[49,50,51],state:[52,58,62],statement:53,static_cast:42,statu:42,std:[3,4,24,27,29,30,31,32,35,36,40,42,43,44,45,49,62,64],stdout:[34,60,61],steamlin:64,step:[49,50,51,59,64],still:[42,49,51,64],stitch:[50,62],stop:62,storag:64,store:[4,52,55,58,62],str:[19,41,42,46,47,49,60,61],straight:58,stream:49,strict:65,strict_typ:[43,44,61,66],strictli:61,stride:[49,50,51],string:[3,4,18,20,21,24,27,29,30,31,32,35,36,40,42,43,58,61,62,64],stringstream:42,strip_prefix:63,strong:[49,50],struct:[1,2,21,37,43,64],structur:[31,44,49,50,56,58,62],style:[40,41,42,43],sub:62,subdirectori:48,subexpress:53,subgraph:[52,53,58,62],subject:56,submodul:[50,62],subplot:[49,51],subset:64,successfulli:[49,51],sudo:63,suffic:53,suggest:51,suit:59,support:[1,2,26,35,44,45,49,50,51,57,61,62,63,65],sure:[62,63],sxm2:49,symbol:63,synchron:[49,50,51],system:[49,51,52,58,59,63],take:[33,35,36,49,50,51,52,54,55,56,58,61,62,64,66],taken:[49,51],talk:59,tar:[63,64],tarbal:[62,64],target:[2,44,49,50,51,56,59,61,62,64,65,66],targets_:64,task:[30,31,64],techinqu:62,techniqu:64,tell:58,temp:49,templat:[20,39,42,43,46,47,62],tensor:[42,44,45,49,50,51,52,53,55,58,62,64],tensorcontain:58,tensorlist:58,tensorrt:[1,2,3,4,30,31,33,34,36,43,44,45,49,50,51,52,53,54,56,58,59,61,62,64,65,66],tensorrtcompilespec:[61,66],term:64,termin:[26,62,65],tesla:49,test:[49,50,51,56,63,65],text:[51,60],tgz:63,than:[53,59],thats:[52,64],thei:[44,51,52,53,58,63,65],them:[49,50,51,55,62,63],theori:52,therebi:55,therefor:[31,62],thi:[1,2,30,31,40,41,42,43,44,45,49,50,51,52,53,54,55,56,58,62,63,64,65,66],thing:50,think:58,third_parti:[56,63],those:52,though:[49,51,56,58,62,65],three:[44,45,54,56],threshold:65,thrid_parti:63,through:[49,50,51,52,53,55,59,62],time:[44,49,50,51,52,53,54,56,58,61,62,64,65],tini:64,titan:[49,50],titl:49,tmp:62,tocustomclass:58,todim:62,togeth:[50,52,58,62],toilet:49,too:63,tool:[49,50,58,62],toolchain:56,top:[51,56],torch:[1,2,4,20,30,31,33,35,36,42,43,44,49,50,51,53,55,57,58,61,62,63,64,65,66],torch_scirpt_modul:62,torch_script_modul:62,torchbind:55,torchhub:51,torchscript:[33,35,36,49,51,54,55,56,61,65,66],torchvis:[49,55,66],toronto:64,totensor:49,tovec:62,toward:64,trace:[51,61,62],traced_model:[49,50,51,62],track:[58,64],track_running_stat:49,trade:51,tradit:64,traget:33,train:[30,31,44,49,51,59,62,65],trainabl:53,transform:[49,50,62,64],translat:[51,62],travers:[54,56],treat:65,tree:[40,41,42,43,64],trigger:[50,62],trim:64,trt:[1,2,3,4,44,52,53,55,58,62],trt_lenet_script:62,trt_mod:[62,64],trt_model:[49,51,66],trt_model_fp32:49,trt_script_modul:50,trt_ts_modul:[50,62],trtorch:[0,1,2,3,4,15,17,22,40,41,42,44,45,47,48,52,53,54,55,56,63,64,65],trtorch_api:[19,23,24,25,26,27,28,29,30,31,32,33,34,35,36,40,41,42,43,46,47],trtorch_check:58,trtorch_hidden:[19,41,46,47],trtorch_major_vers:[19,41,46,47],trtorch_minor_vers:[19,41,46,47],trtorch_patch_vers:[19,41,46,47],trtorch_py_dep:63,trtorch_unus:58,trtorch_vers:[19,41,46,47],trtorchc:59,trtorchfil:[22,46],trtorchnamespac:[0,46],ts_model:62,tue:49,tune:[49,50,51],tupl:[55,61,62],tupleconstruct:[53,55],tupleunpack:53,tutori:[62,64],two:[49,50,51,58,62,63,64,65],txt:63,type:[1,2,30,45,46,47,49,52,55,58,60,61,62,64,65],typenam:[3,4,30,31,42],typic:[52,58],ubuntu:63,uint64_t:[43,44],unabl:[58,62],uncom:63,uncorr:49,under:[40,41,42,43,49,50,51,56],underli:[1,2,44,58],understand:62,union:[58,62],uniqu:4,unique_ptr:[4,30],unit:50,unless:[49,50,51],unlik:[59,62,63,66],unpack_addmm:53,unpack_log_softmax:53,unqiue_ptr:4,unsqueez:49,unstabl:56,unsupport:[35,61],unsur:58,untest:56,until:[52,56,58,63],unwrap:58,unwrap_distribut:51,unwraptodoubl:58,unwraptoint:62,unzip:63,upgrad:49,upload:49,upstream:62,uri:51,url:63,usag:[49,62],use:[1,2,3,4,30,31,44,49,50,51,52,53,55,56,58,60,61,62,63,64,65,66],use_cach:[3,4,30,42],use_cache_:42,use_subset:64,usecas:63,used:[1,2,3,4,42,44,45,49,51,52,53,55,58,60,61,62,64,65],useful:58,user:[40,49,50,54,55,56,62,63,64],uses:[30,31,42,49,50,51,58,63,64],using:[1,2,33,36,42,44,49,50,51,58,59,61,62,64,65,66],using_int:62,usr:[49,63],usual:51,util:[58,61,62],val2017:51,val:51,valid:[2,44,51,58],valu:[1,2,17,43,44,52,55,58,60,62],value_tensor_map:[52,58],varient:53,vector:[20,21,42,43,44,45,62,64],verbios:65,verbos:65,veri:[64,66],version:[32,34,49,50,51,56,63],vgg16:64,vgg:51,via:[49,51,59,61],virtual:64,vision:49,visit:51,volatil:49,volta:[49,50],wai:[49,62,63,65],walk:[49,50,51],want:[40,44,49,50,62,66],warm:[49,50,51],warn:[17,42,49,58,60,65],warranti:[49,50,51],websit:63,weight:[52,62],welcom:62,well:[49,50,51,62,64],were:[51,62],wget:49,what:[4,51,53,62],whatev:55,when:[26,42,44,49,50,52,53,54,55,56,58,60,61,62,63,64,65],where:[49,50,52,53,58,62,64],whether:[4,64],which:[2,31,33,36,44,49,50,51,52,53,54,55,56,58,61,62,64,66],whilst:51,white:51,whl:63,whole:[49,50],whose:53,width:49,within:[49,50,51,54,56],without:[49,50,51,58,62,64],work:[42,50,51,53,56,58,64],worker:64,workflow:66,workspac:[44,61,63,64,65],workspace_s:[43,44,49,51,61,64,65],world:[49,50],would:[58,62,63,65,66],wrap:[54,55,56,62,66],wrapper:58,write:[3,4,30,31,42,49,50,51,52,59,62,64],writecalibrationcach:[3,4,42],www:[49,50,51,62,63,64],x64:63,x86_64:[56,63],xavier:[49,50],xstr:[19,41,46,47],yaml:57,you:[1,2,30,31,44,49,50,51,52,53,55,56,58,59,61,62,63,64,65,66],your:[49,50,51,58,59,62,63,66],yourself:62,zip:[55,63],zisserman:64},titles:["Class Hierarchy","Class CompileSpec::DataType","Class CompileSpec::DeviceType","Template Class Int8CacheCalibrator","Template Class Int8Calibrator","Define STR","Define TRTORCH_API","Define TRTORCH_HIDDEN","Define TRTORCH_MAJOR_VERSION","Define TRTORCH_PATCH_VERSION","Define TRTORCH_VERSION","Define XSTR","Define TRTORCH_MINOR_VERSION","Directory cpp","Directory api","Directory include","Directory trtorch","Enum Level","File logging.h","File macros.h","File ptq.h","File trtorch.h","File Hierarchy","Function trtorch::logging::get_reportable_log_level","Function trtorch::logging::set_logging_prefix","Function trtorch::logging::get_is_colored_output_on","Function trtorch::logging::set_is_colored_output_on","Function trtorch::logging::log","Function trtorch::logging::set_reportable_log_level","Function trtorch::logging::get_logging_prefix","Template Function trtorch::ptq::make_int8_calibrator","Template Function trtorch::ptq::make_int8_cache_calibrator","Function trtorch::get_build_info","Function trtorch::CompileGraph","Function trtorch::dump_build_info","Function trtorch::CheckMethodOperatorSupport","Function trtorch::ConvertGraphToTRTEngine","Namespace trtorch","Namespace trtorch::logging","Namespace trtorch::ptq","Program Listing for File logging.h","Program Listing for File macros.h","Program Listing for File ptq.h","Program Listing for File trtorch.h","Struct CompileSpec","Struct CompileSpec::InputRange","TRTorch C++ API","Full API","Full API","TRTorch Getting Started - ResNet 50","TRTorch Getting Started - LeNet","Object Detection with TRTorch (SSD)","Conversion Phase","Lowering Phase","Compiler Phases","Runtime Phase","System Overview","Useful Links for TRTorch Development","Writing Converters","TRTorch","trtorch.logging","trtorch","Getting Started","Installation","Post Training Quantization (PTQ)","trtorchc","Using TRTorch Directly From PyTorch"],titleterms:{"class":[0,1,2,3,4,20,21,37,39,46,47],"enum":[17,18,38,46,47,61],"function":[18,20,21,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,46,47,57,61],The:62,Used:53,Useful:57,Using:[62,66],aarch64:63,abi:63,addmm:53,advic:58,ahead:59,api:[14,18,19,20,21,46,47,48,57,59,63],applic:64,arg:58,avail:57,background:[55,58,62],base:[3,4],benchmark:[49,51],binari:63,branch:53,build:63,checkmethodoperatorsupport:35,citat:64,cli:63,code:53,compil:[54,56,59,62,63],compilegraph:33,compilespec:[1,2,44,45],conclus:[50,51],construct:55,content:[18,19,20,21,37,38,39,49,50,51],context:58,contigu:53,contract:58,contributor:59,convers:[52,54,56,58],convert:[52,58,62],convertgraphtotrtengin:36,cpp:[13,18,19,20,21],creat:[62,64],cudnn:63,custom:62,cxx11:63,datatyp:1,dead:53,debug:63,defin:[5,6,7,8,9,10,11,12,19,46,47],definit:[18,19,20,21],depend:63,descript:[49,51],deseri:55,detail:51,detect:51,detector:51,develop:57,devicetyp:2,dimens:57,directli:66,directori:[13,14,15,16,48],disk:62,distribut:63,documen:59,document:[1,2,3,4,5,6,7,8,9,10,11,12,17,23,24,25,26,27,28,29,30,31,32,33,34,35,36,44,45,57,59],dropout:53,dump_build_info:34,easier:57,elimin:53,eliminatecommonsubexpress:53,engin:55,envior:63,evalu:52,execept:53,executor:55,expect:57,file:[16,18,19,20,21,22,40,41,42,43,46,48],flatten:53,fp16:49,fp32:49,freez:53,from:[63,66],full:[46,47,48],fuse:53,gaurd:53,get:[49,50,59,62],get_build_info:32,get_is_colored_output_on:25,get_logging_prefix:29,get_reportable_log_level:23,gpu:59,graph:[53,55],guarante:58,half:49,hierarchi:[0,22,46],hood:62,how:64,includ:[15,18,19,20,21],indic:59,infer:51,inherit:[3,4],inputrang:45,instal:63,int8cachecalibr:3,int8calibr:4,jetson:63,jit:59,layer:57,learn:[49,50,51],lenet:50,level:17,librari:63,linear:53,link:57,list:[40,41,42,43],local:63,log:[18,23,24,25,26,27,28,29,38,40,60],logsoftmax:53,loop:53,lower:[53,54,56],macro:[19,41],make_int8_cache_calibr:31,make_int8_calibr:30,measur:51,model:[49,50,51],modul:[53,62],multibox:51,namespac:[18,20,21,37,38,39,46,47],nativ:63,native_op:57,nest:[1,2,44,45],next:[49,50],node:52,nvidia:59,object:[49,50,51],oper:62,optimz:53,other:58,overview:[49,50,51,56],own:64,packag:63,pass:53,pattern:53,peephol:53,phase:[52,53,54,55,56],post:64,pre:63,precis:49,precompil:63,prerequisit:63,program:[40,41,42,43],ptq:[20,30,31,39,42,64],python:[57,59,62,63],pytorch:[50,57,59,66],quantiz:64,quickstart:62,read:57,redund:53,refer:51,regist:62,relationship:[1,2,3,4,44,45],releas:63,remov:53,resnet:49,respons:58,result:[51,55],runtim:[54,55,56],sampl:51,save:62,script:50,serial:55,set_is_colored_output_on:26,set_logging_prefix:24,set_reportable_log_level:28,setup:63,shot:51,singl:[49,51],sometim:57,sourc:63,speedup:51,ssd:51,start:[49,50,59,62],str:5,struct:[44,45,46,47],subdirectori:[13,14,15],submodul:61,system:56,tarbal:63,templat:[3,4,30,31],tensorrt:[55,57,63],time:59,torchscript:[50,59,62],trace:[49,50],train:64,trtorch:[16,18,19,20,21,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,43,46,49,50,51,57,59,60,61,62,66],trtorch_api:6,trtorch_hidden:7,trtorch_major_vers:8,trtorch_minor_vers:12,trtorch_patch_vers:9,trtorch_vers:10,trtorchc:[62,65],tupl:53,type:[3,4,44],under:62,unpack:53,unrol:53,unsupport:62,using:63,util:[49,51],visual:51,weight:58,what:[49,50,58],work:62,write:58,xstr:11,your:64}})
\ No newline at end of file
diff --git a/docs/sitemap.xml b/docs/sitemap.xml
index 5a383133a7..8fe073f6ea 100644
--- a/docs/sitemap.xml
+++ b/docs/sitemap.xml
@@ -1 +1 @@
-https://nvidia.github.io/TRTorch/_cpp_api/class_view_hierarchy.html https://nvidia.github.io/TRTorch/_cpp_api/classtrtorch_1_1CompileSpec_1_1DataType.html https://nvidia.github.io/TRTorch/_cpp_api/classtrtorch_1_1CompileSpec_1_1DeviceType.html https://nvidia.github.io/TRTorch/_cpp_api/classtrtorch_1_1ExtraInfo_1_1DataType.html https://nvidia.github.io/TRTorch/_cpp_api/classtrtorch_1_1ExtraInfo_1_1DeviceType.html https://nvidia.github.io/TRTorch/_cpp_api/classtrtorch_1_1ptq_1_1Int8CacheCalibrator.html https://nvidia.github.io/TRTorch/_cpp_api/classtrtorch_1_1ptq_1_1Int8Calibrator.html https://nvidia.github.io/TRTorch/_cpp_api/define_macros_8h_1a18d295a837ac71add5578860b55e5502.html https://nvidia.github.io/TRTorch/_cpp_api/define_macros_8h_1a20c1fbeb21757871c52299dc52351b5f.html https://nvidia.github.io/TRTorch/_cpp_api/define_macros_8h_1a25ee153c325dfc7466a33cbd5c1ff055.html https://nvidia.github.io/TRTorch/_cpp_api/define_macros_8h_1a48d6029a45583a06848891cb0e86f7ba.html https://nvidia.github.io/TRTorch/_cpp_api/define_macros_8h_1a71b02dddfabe869498ad5a88e11c440f.html https://nvidia.github.io/TRTorch/_cpp_api/define_macros_8h_1a9d31d0569348d109b1b069b972dd143e.html https://nvidia.github.io/TRTorch/_cpp_api/define_macros_8h_1abe87b341f562fd1cf40b7672e4d759da.html https://nvidia.github.io/TRTorch/_cpp_api/define_macros_8h_1ae1c56ab8a40af292a9a4964651524d84.html https://nvidia.github.io/TRTorch/_cpp_api/dir_cpp.html https://nvidia.github.io/TRTorch/_cpp_api/dir_cpp_api.html https://nvidia.github.io/TRTorch/_cpp_api/dir_cpp_api_include.html https://nvidia.github.io/TRTorch/_cpp_api/dir_cpp_api_include_trtorch.html https://nvidia.github.io/TRTorch/_cpp_api/enum_logging_8h_1a5f612ff2f783ff4fbe89d168f0d817d4.html https://nvidia.github.io/TRTorch/_cpp_api/file_cpp_api_include_trtorch_logging.h.html https://nvidia.github.io/TRTorch/_cpp_api/file_cpp_api_include_trtorch_macros.h.html https://nvidia.github.io/TRTorch/_cpp_api/file_cpp_api_include_trtorch_ptq.h.html https://nvidia.github.io/TRTorch/_cpp_api/file_cpp_api_include_trtorch_trtorch.h.html https://nvidia.github.io/TRTorch/_cpp_api/file_view_hierarchy.html https://nvidia.github.io/TRTorch/_cpp_api/function_logging_8h_1a118d65b179defff7fff279eb9cd126cb.html https://nvidia.github.io/TRTorch/_cpp_api/function_logging_8h_1a396a688110397538f8b3fb7dfdaf38bb.html https://nvidia.github.io/TRTorch/_cpp_api/function_logging_8h_1a9b420280bfacc016d7e36a5704021949.html https://nvidia.github.io/TRTorch/_cpp_api/function_logging_8h_1aa533955a2b908db9e5df5acdfa24715f.html https://nvidia.github.io/TRTorch/_cpp_api/function_logging_8h_1abc57d473f3af292551dee8b9c78373ad.html https://nvidia.github.io/TRTorch/_cpp_api/function_logging_8h_1adf5435f0dbb09c0d931a1b851847236b.html https://nvidia.github.io/TRTorch/_cpp_api/function_logging_8h_1aef44b69c62af7cf2edc8875a9506641a.html https://nvidia.github.io/TRTorch/_cpp_api/function_ptq_8h_1a4422781719d7befedb364cacd91c6247.html https://nvidia.github.io/TRTorch/_cpp_api/function_ptq_8h_1a5f33b142bc2f3f2aaf462270b3ad7e31.html https://nvidia.github.io/TRTorch/_cpp_api/function_trtorch_8h_1a2cf17d43ba9117b3b4d652744b4f0447.html https://nvidia.github.io/TRTorch/_cpp_api/function_trtorch_8h_1a3eace458ae9122f571fabfc9ef1b9e3a.html https://nvidia.github.io/TRTorch/_cpp_api/function_trtorch_8h_1a536bba54b70e44554099d23fa3d7e804.html https://nvidia.github.io/TRTorch/_cpp_api/function_trtorch_8h_1a726f6e7091b6b7be45b5a4275b2ffb10.html https://nvidia.github.io/TRTorch/_cpp_api/function_trtorch_8h_1ab01696cfe08b6a5293c55935a9713c25.html https://nvidia.github.io/TRTorch/_cpp_api/function_trtorch_8h_1ae38897d1ca4438227c970029d0f76fb5.html https://nvidia.github.io/TRTorch/_cpp_api/function_trtorch_8h_1af19cb866b0520fc84b69a1cf25a52b65.html https://nvidia.github.io/TRTorch/_cpp_api/namespace_trtorch.html https://nvidia.github.io/TRTorch/_cpp_api/namespace_trtorch__logging.html https://nvidia.github.io/TRTorch/_cpp_api/namespace_trtorch__ptq.html https://nvidia.github.io/TRTorch/_cpp_api/program_listing_file_cpp_api_include_trtorch_logging.h.html https://nvidia.github.io/TRTorch/_cpp_api/program_listing_file_cpp_api_include_trtorch_macros.h.html https://nvidia.github.io/TRTorch/_cpp_api/program_listing_file_cpp_api_include_trtorch_ptq.h.html https://nvidia.github.io/TRTorch/_cpp_api/program_listing_file_cpp_api_include_trtorch_trtorch.h.html https://nvidia.github.io/TRTorch/_cpp_api/structtrtorch_1_1CompileSpec.html https://nvidia.github.io/TRTorch/_cpp_api/structtrtorch_1_1CompileSpec_1_1InputRange.html https://nvidia.github.io/TRTorch/_cpp_api/structtrtorch_1_1ExtraInfo.html https://nvidia.github.io/TRTorch/_cpp_api/structtrtorch_1_1ExtraInfo_1_1InputRange.html https://nvidia.github.io/TRTorch/_cpp_api/trtorch_cpp.html https://nvidia.github.io/TRTorch/_cpp_api/unabridged_api.html https://nvidia.github.io/TRTorch/_cpp_api/unabridged_orphan.html https://nvidia.github.io/TRTorch/_notebooks/Resnet50-example.html https://nvidia.github.io/TRTorch/_notebooks/lenet-getting-started.html https://nvidia.github.io/TRTorch/_notebooks/ssd-object-detection-demo.html https://nvidia.github.io/TRTorch/contributors/conversion.html https://nvidia.github.io/TRTorch/contributors/lowering.html https://nvidia.github.io/TRTorch/contributors/phases.html https://nvidia.github.io/TRTorch/contributors/runtime.html https://nvidia.github.io/TRTorch/contributors/system_overview.html https://nvidia.github.io/TRTorch/contributors/useful_links.html https://nvidia.github.io/TRTorch/contributors/writing_converters.html https://nvidia.github.io/TRTorch/index.html https://nvidia.github.io/TRTorch/py_api/logging.html https://nvidia.github.io/TRTorch/py_api/trtorch.html https://nvidia.github.io/TRTorch/tutorials/getting_started.html https://nvidia.github.io/TRTorch/tutorials/installation.html https://nvidia.github.io/TRTorch/tutorials/ptq.html https://nvidia.github.io/TRTorch/tutorials/trtorchc.html https://nvidia.github.io/TRTorch/tutorials/use_from_pytorch.html https://nvidia.github.io/TRTorch/genindex.html https://nvidia.github.io/TRTorch/py-modindex.html https://nvidia.github.io/TRTorch/search.html https://nvidia.github.io/TRTorch/_cpp_api/class_view_hierarchy.html https://nvidia.github.io/TRTorch/_cpp_api/classtrtorch_1_1CompileSpec_1_1DataType.html https://nvidia.github.io/TRTorch/_cpp_api/classtrtorch_1_1CompileSpec_1_1DeviceType.html https://nvidia.github.io/TRTorch/_cpp_api/classtrtorch_1_1ptq_1_1Int8CacheCalibrator.html https://nvidia.github.io/TRTorch/_cpp_api/classtrtorch_1_1ptq_1_1Int8Calibrator.html https://nvidia.github.io/TRTorch/_cpp_api/define_macros_8h_1a18d295a837ac71add5578860b55e5502.html https://nvidia.github.io/TRTorch/_cpp_api/define_macros_8h_1a20c1fbeb21757871c52299dc52351b5f.html https://nvidia.github.io/TRTorch/_cpp_api/define_macros_8h_1a25ee153c325dfc7466a33cbd5c1ff055.html https://nvidia.github.io/TRTorch/_cpp_api/define_macros_8h_1a48d6029a45583a06848891cb0e86f7ba.html https://nvidia.github.io/TRTorch/_cpp_api/define_macros_8h_1a71b02dddfabe869498ad5a88e11c440f.html https://nvidia.github.io/TRTorch/_cpp_api/define_macros_8h_1a9d31d0569348d109b1b069b972dd143e.html https://nvidia.github.io/TRTorch/_cpp_api/define_macros_8h_1abe87b341f562fd1cf40b7672e4d759da.html https://nvidia.github.io/TRTorch/_cpp_api/define_macros_8h_1ae1c56ab8a40af292a9a4964651524d84.html https://nvidia.github.io/TRTorch/_cpp_api/dir_cpp.html https://nvidia.github.io/TRTorch/_cpp_api/dir_cpp_api.html https://nvidia.github.io/TRTorch/_cpp_api/dir_cpp_api_include.html https://nvidia.github.io/TRTorch/_cpp_api/dir_cpp_api_include_trtorch.html https://nvidia.github.io/TRTorch/_cpp_api/enum_logging_8h_1a5f612ff2f783ff4fbe89d168f0d817d4.html https://nvidia.github.io/TRTorch/_cpp_api/file_cpp_api_include_trtorch_logging.h.html https://nvidia.github.io/TRTorch/_cpp_api/file_cpp_api_include_trtorch_macros.h.html https://nvidia.github.io/TRTorch/_cpp_api/file_cpp_api_include_trtorch_ptq.h.html https://nvidia.github.io/TRTorch/_cpp_api/file_cpp_api_include_trtorch_trtorch.h.html https://nvidia.github.io/TRTorch/_cpp_api/file_view_hierarchy.html https://nvidia.github.io/TRTorch/_cpp_api/function_logging_8h_1a118d65b179defff7fff279eb9cd126cb.html https://nvidia.github.io/TRTorch/_cpp_api/function_logging_8h_1a396a688110397538f8b3fb7dfdaf38bb.html https://nvidia.github.io/TRTorch/_cpp_api/function_logging_8h_1a9b420280bfacc016d7e36a5704021949.html https://nvidia.github.io/TRTorch/_cpp_api/function_logging_8h_1aa533955a2b908db9e5df5acdfa24715f.html https://nvidia.github.io/TRTorch/_cpp_api/function_logging_8h_1abc57d473f3af292551dee8b9c78373ad.html https://nvidia.github.io/TRTorch/_cpp_api/function_logging_8h_1adf5435f0dbb09c0d931a1b851847236b.html https://nvidia.github.io/TRTorch/_cpp_api/function_logging_8h_1aef44b69c62af7cf2edc8875a9506641a.html https://nvidia.github.io/TRTorch/_cpp_api/function_ptq_8h_1a4422781719d7befedb364cacd91c6247.html https://nvidia.github.io/TRTorch/_cpp_api/function_ptq_8h_1a5f33b142bc2f3f2aaf462270b3ad7e31.html https://nvidia.github.io/TRTorch/_cpp_api/function_trtorch_8h_1a2cf17d43ba9117b3b4d652744b4f0447.html https://nvidia.github.io/TRTorch/_cpp_api/function_trtorch_8h_1a3eace458ae9122f571fabfc9ef1b9e3a.html https://nvidia.github.io/TRTorch/_cpp_api/function_trtorch_8h_1a726f6e7091b6b7be45b5a4275b2ffb10.html https://nvidia.github.io/TRTorch/_cpp_api/function_trtorch_8h_1ab01696cfe08b6a5293c55935a9713c25.html https://nvidia.github.io/TRTorch/_cpp_api/function_trtorch_8h_1af19cb866b0520fc84b69a1cf25a52b65.html https://nvidia.github.io/TRTorch/_cpp_api/namespace_trtorch.html https://nvidia.github.io/TRTorch/_cpp_api/namespace_trtorch__logging.html https://nvidia.github.io/TRTorch/_cpp_api/namespace_trtorch__ptq.html https://nvidia.github.io/TRTorch/_cpp_api/program_listing_file_cpp_api_include_trtorch_logging.h.html https://nvidia.github.io/TRTorch/_cpp_api/program_listing_file_cpp_api_include_trtorch_macros.h.html https://nvidia.github.io/TRTorch/_cpp_api/program_listing_file_cpp_api_include_trtorch_ptq.h.html https://nvidia.github.io/TRTorch/_cpp_api/program_listing_file_cpp_api_include_trtorch_trtorch.h.html https://nvidia.github.io/TRTorch/_cpp_api/structtrtorch_1_1CompileSpec.html https://nvidia.github.io/TRTorch/_cpp_api/structtrtorch_1_1CompileSpec_1_1InputRange.html https://nvidia.github.io/TRTorch/_cpp_api/trtorch_cpp.html https://nvidia.github.io/TRTorch/_cpp_api/unabridged_api.html https://nvidia.github.io/TRTorch/_cpp_api/unabridged_orphan.html https://nvidia.github.io/TRTorch/_notebooks/Resnet50-example.html https://nvidia.github.io/TRTorch/_notebooks/lenet-getting-started.html https://nvidia.github.io/TRTorch/_notebooks/ssd-object-detection-demo.html https://nvidia.github.io/TRTorch/contributors/conversion.html https://nvidia.github.io/TRTorch/contributors/lowering.html https://nvidia.github.io/TRTorch/contributors/phases.html https://nvidia.github.io/TRTorch/contributors/runtime.html https://nvidia.github.io/TRTorch/contributors/system_overview.html https://nvidia.github.io/TRTorch/contributors/useful_links.html https://nvidia.github.io/TRTorch/contributors/writing_converters.html https://nvidia.github.io/TRTorch/index.html https://nvidia.github.io/TRTorch/py_api/logging.html https://nvidia.github.io/TRTorch/py_api/trtorch.html https://nvidia.github.io/TRTorch/tutorials/getting_started.html https://nvidia.github.io/TRTorch/tutorials/installation.html https://nvidia.github.io/TRTorch/tutorials/ptq.html https://nvidia.github.io/TRTorch/tutorials/trtorchc.html https://nvidia.github.io/TRTorch/tutorials/use_from_pytorch.html https://nvidia.github.io/TRTorch/genindex.html https://nvidia.github.io/TRTorch/py-modindex.html https://nvidia.github.io/TRTorch/search.html
Underlying enum class to support the
-
+
DataType
@@ -467,7 +467,7 @@
In the case that you need to use the
-
+
DataType
@@ -476,7 +476,7 @@
ex. trtorch::DataType type =
-
+
DataType::kFloat
@@ -612,7 +612,7 @@
-
+
DataType
@@ -696,7 +696,7 @@
Get the enum value of the
-
+
DataType
@@ -775,7 +775,7 @@
Comparision operator for
-
+
DataType
@@ -865,7 +865,7 @@
Comparision operator for
-
+
DataType
@@ -951,7 +951,7 @@
Comparision operator for
-
+
DataType
@@ -1041,7 +1041,7 @@
Comparision operator for
-
+
DataType
diff --git a/docs/_cpp_api/classtrtorch_1_1CompileSpec_1_1DeviceType.html b/docs/_cpp_api/classtrtorch_1_1CompileSpec_1_1DeviceType.html
index acb0528810..1d1772a40c 100644
--- a/docs/_cpp_api/classtrtorch_1_1CompileSpec_1_1DeviceType.html
+++ b/docs/_cpp_api/classtrtorch_1_1CompileSpec_1_1DeviceType.html
@@ -392,7 +392,7 @@
This class is a nested type of
-
+
Struct CompileSpec
@@ -435,7 +435,7 @@
This class is compatable with c10::DeviceTypes (but will check for TRT support) but the only applicable value is at::kCUDA, which maps to
-
+
DeviceType::kGPU
@@ -443,7 +443,7 @@
To use the
-
+
DataType
@@ -452,7 +452,7 @@
ex. trtorch::DeviceType type =
-
+
DeviceType::kGPU
@@ -481,7 +481,7 @@
Underlying enum class to support the
-
+
DeviceType
@@ -490,7 +490,7 @@
In the case that you need to use the
-
+
DeviceType
@@ -499,7 +499,7 @@
ex. trtorch::DeviceType type =
-
+
DeviceType::kGPU
@@ -766,7 +766,7 @@
Comparison operator for
-
+
DeviceType
@@ -852,7 +852,7 @@
Comparison operator for
-
+
DeviceType
diff --git a/docs/_cpp_api/classtrtorch_1_1ptq_1_1Int8CacheCalibrator.html b/docs/_cpp_api/classtrtorch_1_1ptq_1_1Int8CacheCalibrator.html
index f043962260..d13bc517fd 100644
--- a/docs/_cpp_api/classtrtorch_1_1ptq_1_1Int8CacheCalibrator.html
+++ b/docs/_cpp_api/classtrtorch_1_1ptq_1_1Int8CacheCalibrator.html
@@ -865,7 +865,7 @@
Convience function to convert to a IInt8Calibrator* to easily be assigned to the ptq_calibrator field in
-
+
CompileSpec
diff --git a/docs/_cpp_api/classtrtorch_1_1ptq_1_1Int8Calibrator.html b/docs/_cpp_api/classtrtorch_1_1ptq_1_1Int8Calibrator.html
index 797c91a841..552fbd4d3d 100644
--- a/docs/_cpp_api/classtrtorch_1_1ptq_1_1Int8Calibrator.html
+++ b/docs/_cpp_api/classtrtorch_1_1ptq_1_1Int8Calibrator.html
@@ -926,7 +926,7 @@
Convience function to convert to a IInt8Calibrator* to easily be assigned to the ptq_calibrator field in
-
+
CompileSpec
diff --git a/docs/_cpp_api/file_cpp_api_include_trtorch_logging.h.html b/docs/_cpp_api/file_cpp_api_include_trtorch_logging.h.html
index 28c3b28c94..e54f3aab7c 100644
--- a/docs/_cpp_api/file_cpp_api_include_trtorch_logging.h.html
+++ b/docs/_cpp_api/file_cpp_api_include_trtorch_logging.h.html
@@ -407,7 +407,7 @@
+
Contents
+
Contents
+
Contents
+
Contents
-
+
Class CompileSpec::DeviceType
diff --git a/docs/_cpp_api/function_trtorch_8h_1a3eace458ae9122f571fabfc9ef1b9e3a.html b/docs/_cpp_api/function_trtorch_8h_1a3eace458ae9122f571fabfc9ef1b9e3a.html
index a6aa986ac0..1d15d10c2a 100644
--- a/docs/_cpp_api/function_trtorch_8h_1a3eace458ae9122f571fabfc9ef1b9e3a.html
+++ b/docs/_cpp_api/function_trtorch_8h_1a3eace458ae9122f571fabfc9ef1b9e3a.html
@@ -459,7 +459,7 @@
+
Contents
-
+
Class CompileSpec::DeviceType
diff --git a/docs/_cpp_api/namespace_trtorch__logging.html b/docs/_cpp_api/namespace_trtorch__logging.html
index 28fe619697..6da91d52aa 100644
--- a/docs/_cpp_api/namespace_trtorch__logging.html
+++ b/docs/_cpp_api/namespace_trtorch__logging.html
@@ -373,7 +373,7 @@
+
Contents
+
Contents
-
+
Struct CompileSpec::InputRange
@@ -759,7 +759,10 @@
Underlying enum class to support the
-
+
DataType
@@ -1054,7 +1060,7 @@
In the case that you need to use the
-
+
DataType
@@ -1063,7 +1069,7 @@
ex. trtorch::DataType type =
-
+
DataType::kFloat
@@ -1184,7 +1190,7 @@
-
+
DataType
@@ -1262,7 +1268,7 @@
Get the enum value of the
-
+
DataType
@@ -1335,7 +1341,7 @@
Comparision operator for
-
+
DataType
@@ -1422,7 +1428,7 @@
Comparision operator for
-
+
DataType
@@ -1505,7 +1511,7 @@
Comparision operator for
-
+
DataType
@@ -1592,7 +1598,7 @@
Comparision operator for
-
+
DataType
@@ -1665,7 +1671,7 @@
This class is compatable with c10::DeviceTypes (but will check for TRT support) but the only applicable value is at::kCUDA, which maps to
-
+
DeviceType::kGPU
@@ -1673,7 +1679,7 @@
To use the
-
+
DataType
@@ -1682,7 +1688,7 @@
ex. trtorch::DeviceType type =
-
+
DeviceType::kGPU
@@ -1708,7 +1714,7 @@
Underlying enum class to support the
-
+
DeviceType
@@ -1717,7 +1723,7 @@
In the case that you need to use the
-
+
DeviceType
@@ -1726,7 +1732,7 @@
ex. trtorch::DeviceType type =
-
+
DeviceType::kGPU
@@ -1969,7 +1975,7 @@
Comparison operator for
-
+
DeviceType
@@ -2052,7 +2058,7 @@
Comparison operator for
-
+
DeviceType
diff --git a/docs/_cpp_api/structtrtorch_1_1CompileSpec_1_1InputRange.html b/docs/_cpp_api/structtrtorch_1_1CompileSpec_1_1InputRange.html
index c87755f91e..0620aef0db 100644
--- a/docs/_cpp_api/structtrtorch_1_1CompileSpec_1_1InputRange.html
+++ b/docs/_cpp_api/structtrtorch_1_1CompileSpec_1_1InputRange.html
@@ -392,7 +392,7 @@
This struct is a nested type of
-
+
Struct CompileSpec
diff --git a/docs/_notebooks/Resnet50-example.html b/docs/_notebooks/Resnet50-example.html
index 7bff2ba3f8..2c22d0b157 100644
--- a/docs/_notebooks/Resnet50-example.html
+++ b/docs/_notebooks/Resnet50-example.html
@@ -380,7 +380,7 @@
-
- ## 1. Requirements
-
+ ## 1. Requirements
+
Follow the steps in
- ## 2. ResNet-50 Overview
-
+ ## 2. ResNet-50 Overview
+
PyTorch has a model repository called the PyTorch Hub, which is a source for high quality implementations of common models. We can get our ResNet-50 model from there pretrained on ImageNet.
- All pre-trained models expect input images normalized in the same way, i.e. mini-batches of 3-channel RGB images of shape
+ All pre-trained models expect input images normalized in the same way, i.e. mini-batches of 3-channel RGB images of shape
- ## 3. Creating TorchScript modules
-
+ ## 3. Creating TorchScript modules
+
To compile with TRTorch, the model must first be in
@@ -1591,8 +1603,8 @@
- ## 4. Compiling with TRTorch
-
+ ## 4. Compiling with TRTorch
+
TorchScript modules behave just like normal PyTorch modules and are intercompatible. From TorchScript we can now compile a TensorRT based module. This module will still be implemented in TorchScript but all the computation will be done in TensorRT.
- ## 5. Conclusion
-
+ ## 5. Conclusion
+
In this notebook, we have walked through the complete process of compiling TorchScript models with TRTorch for ResNet-50 model and test the performance impact of the optimization. With TRTorch, we observe a speedup of
@@ -1826,9 +1846,9 @@
- ## 1. Requirements
-
+ ## 1. Requirements
+
Follow the steps in
- ## 2. Creating TorchScript modules
-
+ ## 2. Creating TorchScript modules
+
Here we create two submodules for a feature extractor and a classifier and stitch them together in a single LeNet module. In this case this is overkill but modules give us granular control over our program including where we decide to optimize and where we don’t. It is also the unit that the TorchScript compiler operates on. So you can decide to only convert/optimize the feature extractor and leave the classifier in standard PyTorch or you can convert the whole thing. When compiling your module
to TorchScript, there are two paths: Tracing and Scripting.
@@ -852,45 +860,45 @@
- ## 3. Compiling with TRTorch
-
+ ## 3. Compiling with TRTorch
+
In this notebook, we have walked through the complete process of compiling TorchScript models with TRTorch and test the performance impact of the optimization.
-
- ## 1. Requirements
-
+ ## 1. Requirements
+
Follow the steps in
- ## 2. SSD
-
+ ## 2. SSD
+
-
-
- ## 3. Creating TorchScript modules
-
+ ## 3. Creating TorchScript modules
+
To compile with TRTorch, the model must first be in
@@ -1385,8 +1397,8 @@
- ## 4. Compiling with TRTorch TorchScript modules behave just like normal PyTorch modules and are intercompatible. From TorchScript we can now compile a TensorRT based module. This module will still be implemented in TorchScript but all the computation will be done in TensorRT.
-
+ ## 4. Compiling with TRTorch TorchScript modules behave just like normal PyTorch modules and are intercompatible. From TorchScript we can now compile a TensorRT based module. This module will still be implemented in TorchScript but all the computation will be done in TensorRT.
+
- ## 5. Running Inference
-
+ ## 5. Running Inference
+
Next, we run object detection
)
diff --git a/docs/_cpp_api/file_cpp_api_include_trtorch_macros.h.html b/docs/_cpp_api/file_cpp_api_include_trtorch_macros.h.html
index ff83ad0cbb..3730db95da 100644
--- a/docs/_cpp_api/file_cpp_api_include_trtorch_macros.h.html
+++ b/docs/_cpp_api/file_cpp_api_include_trtorch_macros.h.html
@@ -392,7 +392,7 @@
)
diff --git a/docs/_cpp_api/file_cpp_api_include_trtorch_ptq.h.html b/docs/_cpp_api/file_cpp_api_include_trtorch_ptq.h.html
index e2c6adc7bd..43d78bb1c1 100644
--- a/docs/_cpp_api/file_cpp_api_include_trtorch_ptq.h.html
+++ b/docs/_cpp_api/file_cpp_api_include_trtorch_ptq.h.html
@@ -402,7 +402,7 @@
)
diff --git a/docs/_cpp_api/file_cpp_api_include_trtorch_trtorch.h.html b/docs/_cpp_api/file_cpp_api_include_trtorch_trtorch.h.html
index cbb1c8a391..687ea513c9 100644
--- a/docs/_cpp_api/file_cpp_api_include_trtorch_trtorch.h.html
+++ b/docs/_cpp_api/file_cpp_api_include_trtorch_trtorch.h.html
@@ -402,7 +402,7 @@
)
@@ -547,7 +547,7 @@
:
-
+
trtorch::CompileSpec
diff --git a/docs/_cpp_api/function_trtorch_8h_1af19cb866b0520fc84b69a1cf25a52b65.html b/docs/_cpp_api/function_trtorch_8h_1af19cb866b0520fc84b69a1cf25a52b65.html
index 143288c087..9513f38991 100644
--- a/docs/_cpp_api/function_trtorch_8h_1af19cb866b0520fc84b69a1cf25a52b65.html
+++ b/docs/_cpp_api/function_trtorch_8h_1af19cb866b0520fc84b69a1cf25a52b65.html
@@ -423,6 +423,9 @@
)
+
+ ¶
+
:
-
+
trtorch::CompileSpec
diff --git a/docs/_cpp_api/namespace_trtorch.html b/docs/_cpp_api/namespace_trtorch.html
index fd747baf1d..65dd616a2b 100644
--- a/docs/_cpp_api/namespace_trtorch.html
+++ b/docs/_cpp_api/namespace_trtorch.html
@@ -378,7 +378,7 @@
@@ -440,7 +440,7 @@
diff --git a/docs/_cpp_api/namespace_trtorch__ptq.html b/docs/_cpp_api/namespace_trtorch__ptq.html
index 55807907c4..53fb113684 100644
--- a/docs/_cpp_api/namespace_trtorch__ptq.html
+++ b/docs/_cpp_api/namespace_trtorch__ptq.html
@@ -373,7 +373,7 @@
diff --git a/docs/_cpp_api/structtrtorch_1_1CompileSpec.html b/docs/_cpp_api/structtrtorch_1_1CompileSpec.html
index 5ab4b8daad..4650623324 100644
--- a/docs/_cpp_api/structtrtorch_1_1CompileSpec.html
+++ b/docs/_cpp_api/structtrtorch_1_1CompileSpec.html
@@ -408,7 +408,7 @@
DataType
- ::kFloat
+ ::
+
+ kFloat
+
¶
@@ -865,7 +868,10 @@
DeviceType
- ::kGPU
+ ::
+
+ kGPU
+
¶
@@ -1045,7 +1051,7 @@
-# Copyright 2019 NVIDIA Corporation. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
+# Copyright 2019 NVIDIA Corporation. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
![]() +
+ ![]()
TRTorch Getting Started - ResNet 50
@@ -753,7 +753,7 @@
-!nvidia-smi
+!nvidia-smi
+
@@ -827,9 +831,13 @@
to prepare a Docker container, within which you can run this notebook.
+
-import torch
-resnet50_model = torch.hub.load('pytorch/vision:v0.6.0', 'resnet50', pretrained=True)
-resnet50_model.eval()
+import torch
+resnet50_model = torch.hub.load('pytorch/vision:v0.6.0', 'resnet50', pretrained=True)
+resnet50_model.eval()
(3
@@ -1164,13 +1172,13 @@
-!mkdir ./data
-!wget -O ./data/img0.JPG "https://d17fnq9dkz9hgj.cloudfront.net/breed-uploads/2018/08/siberian-husky-detail.jpg?bust=1535566590&width=630"
-!wget -O ./data/img1.JPG "https://www.hakaimagazine.com/wp-content/uploads/header-gulf-birds.jpg"
-!wget -O ./data/img2.JPG "https://www.artis.nl/media/filer_public_thumbnails/filer_public/00/f1/00f1b6db-fbed-4fef-9ab0-84e944ff11f8/chimpansee_amber_r_1920x1080.jpg__1920x1080_q85_subject_location-923%2C365_subsampling-2.jpg"
-!wget -O ./data/img3.JPG "https://www.familyhandyman.com/wp-content/uploads/2018/09/How-to-Avoid-Snakes-Slithering-Up-Your-Toilet-shutterstock_780480850.jpg"
+!mkdir ./data
+!wget -O ./data/img0.JPG "https://d17fnq9dkz9hgj.cloudfront.net/breed-uploads/2018/08/siberian-husky-detail.jpg?bust=1535566590&width=630"
+!wget -O ./data/img1.JPG "https://www.hakaimagazine.com/wp-content/uploads/header-gulf-birds.jpg"
+!wget -O ./data/img2.JPG "https://www.artis.nl/media/filer_public_thumbnails/filer_public/00/f1/00f1b6db-fbed-4fef-9ab0-84e944ff11f8/chimpansee_amber_r_1920x1080.jpg__1920x1080_q85_subject_location-923%2C365_subsampling-2.jpg"
+!wget -O ./data/img3.JPG "https://www.familyhandyman.com/wp-content/uploads/2018/09/How-to-Avoid-Snakes-Slithering-Up-Your-Toilet-shutterstock_780480850.jpg"
-!wget -O ./data/imagenet_class_index.json "https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json"
+!wget -O ./data/imagenet_class_index.json "https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json"
-!pip install pillow matplotlib
+!pip install pillow matplotlib
-from PIL import Image
-from torchvision import transforms
-import matplotlib.pyplot as plt
+from PIL import Image
+from torchvision import transforms
+import matplotlib.pyplot as plt
-fig, axes = plt.subplots(nrows=2, ncols=2)
+fig, axes = plt.subplots(nrows=2, ncols=2)
-for i in range(4):
- img_path = './data/img%d.JPG'%i
- img = Image.open(img_path)
- preprocess = transforms.Compose([
- transforms.Resize(256),
- transforms.CenterCrop(224),
- transforms.ToTensor(),
- transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
-])
- input_tensor = preprocess(img)
- plt.subplot(2,2,i+1)
- plt.imshow(img)
- plt.axis('off')
+for i in range(4):
+ img_path = './data/img%d.JPG'%i
+ img = Image.open(img_path)
+ preprocess = transforms.Compose([
+ transforms.Resize(256),
+ transforms.CenterCrop(224),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
+])
+ input_tensor = preprocess(img)
+ plt.subplot(2,2,i+1)
+ plt.imshow(img)
+ plt.axis('off')
-import json
+import json
-with open("./data/imagenet_class_index.json") as json_file:
- d = json.load(json_file)
+with open("./data/imagenet_class_index.json") as json_file:
+ d = json.load(json_file)
-print("Number of classes in ImageNet: {}".format(len(d)))
+print("Number of classes in ImageNet: {}".format(len(d)))
-import numpy as np
+import numpy as np
-def rn50_preprocess():
- preprocess = transforms.Compose([
- transforms.Resize(256),
- transforms.CenterCrop(224),
- transforms.ToTensor(),
- transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
- ])
- return preprocess
+def rn50_preprocess():
+ preprocess = transforms.Compose([
+ transforms.Resize(256),
+ transforms.CenterCrop(224),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
+ ])
+ return preprocess
-# decode the results into ([predicted class, description], probability)
-def predict(img_path, model):
- img = Image.open(img_path)
- preprocess = rn50_preprocess()
- input_tensor = preprocess(img)
- input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
+# decode the results into ([predicted class, description], probability)
+def predict(img_path, model):
+ img = Image.open(img_path)
+ preprocess = rn50_preprocess()
+ input_tensor = preprocess(img)
+ input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
- # move the input and model to GPU for speed if available
- if torch.cuda.is_available():
- input_batch = input_batch.to('cuda')
- model.to('cuda')
+ # move the input and model to GPU for speed if available
+ if torch.cuda.is_available():
+ input_batch = input_batch.to('cuda')
+ model.to('cuda')
- with torch.no_grad():
- output = model(input_batch)
- # Tensor of shape 1000, with confidence scores over Imagenet's 1000 classes
- sm_output = torch.nn.functional.softmax(output[0], dim=0)
+ with torch.no_grad():
+ output = model(input_batch)
+ # Tensor of shape 1000, with confidence scores over Imagenet's 1000 classes
+ sm_output = torch.nn.functional.softmax(output[0], dim=0)
- ind = torch.argmax(sm_output)
- return d[str(ind.item())], sm_output[ind] #([predicted class, description], probability)
+ ind = torch.argmax(sm_output)
+ return d[str(ind.item())], sm_output[ind] #([predicted class, description], probability)
-for i in range(4):
- img_path = './data/img%d.JPG'%i
- img = Image.open(img_path)
+for i in range(4):
+ img_path = './data/img%d.JPG'%i
+ img = Image.open(img_path)
- pred, prob = predict(img_path, resnet50_model)
- print('{} - Predicted: {}, Probablility: {}'.format(img_path, pred, prob))
+ pred, prob = predict(img_path, resnet50_model)
+ print('{} - Predicted: {}, Probablility: {}'.format(img_path, pred, prob))
- plt.subplot(2,2,i+1)
- plt.imshow(img);
- plt.axis('off');
- plt.title(pred[1])
+ plt.subplot(2,2,i+1)
+ plt.imshow(img);
+ plt.axis('off');
+ plt.title(pred[1])
-import time
-import numpy as np
+import time
+import numpy as np
-import torch.backends.cudnn as cudnn
-cudnn.benchmark = True
+import torch.backends.cudnn as cudnn
+cudnn.benchmark = True
-def benchmark(model, input_shape=(1024, 1, 224, 224), dtype='fp32', nwarmup=50, nruns=10000):
- input_data = torch.randn(input_shape)
- input_data = input_data.to("cuda")
- if dtype=='fp16':
- input_data = input_data.half()
+def benchmark(model, input_shape=(1024, 1, 224, 224), dtype='fp32', nwarmup=50, nruns=10000):
+ input_data = torch.randn(input_shape)
+ input_data = input_data.to("cuda")
+ if dtype=='fp16':
+ input_data = input_data.half()
- print("Warm up ...")
- with torch.no_grad():
- for _ in range(nwarmup):
- features = model(input_data)
- torch.cuda.synchronize()
- print("Start timing ...")
- timings = []
- with torch.no_grad():
- for i in range(1, nruns+1):
- start_time = time.time()
- features = model(input_data)
- torch.cuda.synchronize()
- end_time = time.time()
- timings.append(end_time - start_time)
- if i%100==0:
- print('Iteration %d/%d, ave batch time %.2f ms'%(i, nruns, np.mean(timings)*1000))
+ print("Warm up ...")
+ with torch.no_grad():
+ for _ in range(nwarmup):
+ features = model(input_data)
+ torch.cuda.synchronize()
+ print("Start timing ...")
+ timings = []
+ with torch.no_grad():
+ for i in range(1, nruns+1):
+ start_time = time.time()
+ features = model(input_data)
+ torch.cuda.synchronize()
+ end_time = time.time()
+ timings.append(end_time - start_time)
+ if i%100==0:
+ print('Iteration %d/%d, ave batch time %.2f ms'%(i, nruns, np.mean(timings)*1000))
- print("Input shape:", input_data.size())
- print("Output features size:", features.size())
- print('Average batch time: %.2f ms'%(np.mean(timings)*1000))
+ print("Input shape:", input_data.size())
+ print("Output features size:", features.size())
+ print('Average batch time: %.2f ms'%(np.mean(timings)*1000))
-# Model benchmark without TRTorch/TensorRT
-model = resnet50_model.eval().to("cuda")
-benchmark(model, input_shape=(128, 3, 224, 224), nruns=1000)
+# Model benchmark without TRTorch/TensorRT
+model = resnet50_model.eval().to("cuda")
+benchmark(model, input_shape=(128, 3, 224, 224), nruns=1000)
+
-model = resnet50_model.eval().to("cuda")
-traced_model = torch.jit.trace(model, [torch.randn((128, 3, 224, 224)).to("cuda")])
+model = resnet50_model.eval().to("cuda")
+traced_model = torch.jit.trace(model, [torch.randn((128, 3, 224, 224)).to("cuda")])
-# This is just an example, and not required for the purposes of this demo
-torch.jit.save(traced_model, "resnet_50_traced.jit.pt")
+# This is just an example, and not required for the purposes of this demo
+torch.jit.save(traced_model, "resnet_50_traced.jit.pt")
-# Obtain the average time taken by a batch of input
-benchmark(traced_model, input_shape=(128, 3, 224, 224), nruns=1000)
+# Obtain the average time taken by a batch of input
+benchmark(traced_model, input_shape=(128, 3, 224, 224), nruns=1000)
-
+
-import trtorch
+import trtorch
-# The compiled module will have precision as specified by "op_precision".
-# Here, it will have FP16 precision.
-trt_model_fp32 = trtorch.compile(traced_model, {
- "input_shapes": [(128, 3, 224, 224)],
- "op_precision": torch.float32, # Run with FP32
- "workspace_size": 1 << 20
-})
+# The compiled module will have precision as specified by "op_precision".
+# Here, it will have FP16 precision.
+trt_model_fp32 = trtorch.compile(traced_model, {
+ "input_shapes": [(128, 3, 224, 224)],
+ "op_precision": torch.float32, # Run with FP32
+ "workspace_size": 1 << 20
+})
@@ -1710,8 +1726,8 @@
-# Obtain the average time taken by a batch of input
-benchmark(trt_model_fp32, input_shape=(128, 3, 224, 224), nruns=1000)
+# Obtain the average time taken by a batch of input
+benchmark(trt_model_fp32, input_shape=(128, 3, 224, 224), nruns=1000)
-import trtorch
+import trtorch
-# The compiled module will have precision as specified by "op_precision".
-# Here, it will have FP16 precision.
-trt_model = trtorch.compile(traced_model, {
- "input_shapes": [(128, 3, 224, 224)],
- "op_precision": torch.half, # Run with FP16
- "workspace_size": 1 << 20
-})
+# The compiled module will have precision as specified by "op_precision".
+# Here, it will have FP16 precision.
+trt_model = trtorch.compile(traced_model, {
+ "input_shapes": [(128, 3, 224, 224)],
+ "op_precision": torch.half, # Run with FP16
+ "workspace_size": 1 << 20
+})
-# Obtain the average time taken by a batch of input
-benchmark(trt_model, input_shape=(128, 3, 224, 224), dtype='fp16', nruns=1000)
+# Obtain the average time taken by a batch of input
+benchmark(trt_model, input_shape=(128, 3, 224, 224), dtype='fp16', nruns=1000)
+
with FP16.
+
What’s next
-
+
¶
diff --git a/docs/_notebooks/lenet-getting-started.html b/docs/_notebooks/lenet-getting-started.html
index 034ee524aa..99c0d6f8f1 100644
--- a/docs/_notebooks/lenet-getting-started.html
+++ b/docs/_notebooks/lenet-getting-started.html
@@ -326,7 +326,7 @@
+
@@ -835,9 +839,13 @@
to prepare a Docker container, within which you can run this notebook.
+
-import torch
-from torch import nn
-import torch.nn.functional as F
+import torch
+from torch import nn
+import torch.nn.functional as F
-class LeNetFeatExtractor(nn.Module):
- def __init__(self):
- super(LeNetFeatExtractor, self).__init__()
- self.conv1 = nn.Conv2d(1, 6, 3)
- self.conv2 = nn.Conv2d(6, 16, 3)
+class LeNetFeatExtractor(nn.Module):
+ def __init__(self):
+ super(LeNetFeatExtractor, self).__init__()
+ self.conv1 = nn.Conv2d(1, 6, 3)
+ self.conv2 = nn.Conv2d(6, 16, 3)
- def forward(self, x):
- x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
- x = F.max_pool2d(F.relu(self.conv2(x)), 2)
- return x
+ def forward(self, x):
+ x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
+ x = F.max_pool2d(F.relu(self.conv2(x)), 2)
+ return x
-class LeNetClassifier(nn.Module):
- def __init__(self):
- super(LeNetClassifier, self).__init__()
- self.fc1 = nn.Linear(16 * 6 * 6, 120)
- self.fc2 = nn.Linear(120, 84)
- self.fc3 = nn.Linear(84, 10)
+class LeNetClassifier(nn.Module):
+ def __init__(self):
+ super(LeNetClassifier, self).__init__()
+ self.fc1 = nn.Linear(16 * 6 * 6, 120)
+ self.fc2 = nn.Linear(120, 84)
+ self.fc3 = nn.Linear(84, 10)
- def forward(self, x):
- x = torch.flatten(x,1)
- x = F.relu(self.fc1(x))
- x = F.relu(self.fc2(x))
- x = self.fc3(x)
- return x
+ def forward(self, x):
+ x = torch.flatten(x,1)
+ x = F.relu(self.fc1(x))
+ x = F.relu(self.fc2(x))
+ x = self.fc3(x)
+ return x
-class LeNet(nn.Module):
- def __init__(self):
- super(LeNet, self).__init__()
- self.feat = LeNetFeatExtractor()
- self.classifer = LeNetClassifier()
+class LeNet(nn.Module):
+ def __init__(self):
+ super(LeNet, self).__init__()
+ self.feat = LeNetFeatExtractor()
+ self.classifer = LeNetClassifier()
- def forward(self, x):
- x = self.feat(x)
- x = self.classifer(x)
- return x
+ def forward(self, x):
+ x = self.feat(x)
+ x = self.classifer(x)
+ return x
-import time
-import numpy as np
+import time
+import numpy as np
-import torch.backends.cudnn as cudnn
-cudnn.benchmark = True
+import torch.backends.cudnn as cudnn
+cudnn.benchmark = True
-def benchmark(model, input_shape=(1024, 1, 32, 32), dtype='fp32', nwarmup=50, nruns=10000):
- input_data = torch.randn(input_shape)
- input_data = input_data.to("cuda")
- if dtype=='fp16':
- input_data = input_data.half()
+def benchmark(model, input_shape=(1024, 1, 32, 32), dtype='fp32', nwarmup=50, nruns=10000):
+ input_data = torch.randn(input_shape)
+ input_data = input_data.to("cuda")
+ if dtype=='fp16':
+ input_data = input_data.half()
- print("Warm up ...")
- with torch.no_grad():
- for _ in range(nwarmup):
- features = model(input_data)
- torch.cuda.synchronize()
- print("Start timing ...")
- timings = []
- with torch.no_grad():
- for i in range(1, nruns+1):
- start_time = time.time()
- features = model(input_data)
- torch.cuda.synchronize()
- end_time = time.time()
- timings.append(end_time - start_time)
- if i%1000==0:
- print('Iteration %d/%d, ave batch time %.2f ms'%(i, nruns, np.mean(timings)*1000))
+ print("Warm up ...")
+ with torch.no_grad():
+ for _ in range(nwarmup):
+ features = model(input_data)
+ torch.cuda.synchronize()
+ print("Start timing ...")
+ timings = []
+ with torch.no_grad():
+ for i in range(1, nruns+1):
+ start_time = time.time()
+ features = model(input_data)
+ torch.cuda.synchronize()
+ end_time = time.time()
+ timings.append(end_time - start_time)
+ if i%1000==0:
+ print('Iteration %d/%d, ave batch time %.2f ms'%(i, nruns, np.mean(timings)*1000))
- print("Input shape:", input_data.size())
- print("Output features size:", features.size())
+ print("Input shape:", input_data.size())
+ print("Output features size:", features.size())
- print('Average batch time: %.2f ms'%(np.mean(timings)*1000))
+ print('Average batch time: %.2f ms'%(np.mean(timings)*1000))
-model = LeNet()
-model.to("cuda").eval()
+model = LeNet()
+model.to("cuda").eval()
-benchmark(model)
+benchmark(model)
-traced_model = torch.jit.trace(model, torch.empty([1,1,32,32]).to("cuda"))
-traced_model
+traced_model = torch.jit.trace(model, torch.empty([1,1,32,32]).to("cuda"))
+traced_model
-benchmark(traced_model)
+benchmark(traced_model)
-model = LeNet().to("cuda").eval()
-script_model = torch.jit.script(model)
+model = LeNet().to("cuda").eval()
+script_model = torch.jit.script(model)
-script_model
+script_model
-benchmark(script_model)
+benchmark(script_model)
+
TorchScript traced model
@@ -1261,28 +1273,28 @@
-import trtorch
+import trtorch
-# We use a batch-size of 1024, and half precision
-compile_settings = {
- "input_shapes": [
- {
- "min" : [1024, 1, 32, 32],
- "opt" : [1024, 1, 33, 33],
- "max" : [1024, 1, 34, 34],
- }
- ],
- "op_precision": torch.half # Run with FP16
-}
+# We use a batch-size of 1024, and half precision
+compile_settings = {
+ "input_shapes": [
+ {
+ "min" : [1024, 1, 32, 32],
+ "opt" : [1024, 1, 33, 33],
+ "max" : [1024, 1, 34, 34],
+ }
+ ],
+ "op_precision": torch.half # Run with FP16
+}
-trt_ts_module = trtorch.compile(traced_model, compile_settings)
+trt_ts_module = trtorch.compile(traced_model, compile_settings)
-input_data = torch.randn((1024, 1, 32, 32))
-input_data = input_data.half().to("cuda")
+input_data = torch.randn((1024, 1, 32, 32))
+input_data = input_data.half().to("cuda")
-input_data = input_data.half()
-result = trt_ts_module(input_data)
-torch.jit.save(trt_ts_module, "trt_ts_module.ts")
+input_data = input_data.half()
+result = trt_ts_module(input_data)
+torch.jit.save(trt_ts_module, "trt_ts_module.ts")
-benchmark(trt_ts_module, input_shape=(1024, 1, 32, 32), dtype="fp16")
+benchmark(trt_ts_module, input_shape=(1024, 1, 32, 32), dtype="fp16")
-import trtorch
+import trtorch
-# We use a batch-size of 1024, and half precision
-compile_settings = {
- "input_shapes": [
- {
- "min" : [1024, 1, 32, 32],
- "opt" : [1024, 1, 33, 33],
- "max" : [1024, 1, 34, 34],
- }
- ],
- "op_precision": torch.half # Run with FP16
-}
+# We use a batch-size of 1024, and half precision
+compile_settings = {
+ "input_shapes": [
+ {
+ "min" : [1024, 1, 32, 32],
+ "opt" : [1024, 1, 33, 33],
+ "max" : [1024, 1, 34, 34],
+ }
+ ],
+ "op_precision": torch.half # Run with FP16
+}
-trt_script_module = trtorch.compile(script_model, compile_settings)
+trt_script_module = trtorch.compile(script_model, compile_settings)
-input_data = torch.randn((1024, 1, 32, 32))
-input_data = input_data.half().to("cuda")
+input_data = torch.randn((1024, 1, 32, 32))
+input_data = input_data.half().to("cuda")
-input_data = input_data.half()
-result = trt_script_module(input_data)
-torch.jit.save(trt_script_module, "trt_script_module.ts")
+input_data = input_data.half()
+result = trt_script_module(input_data)
+torch.jit.save(trt_script_module, "trt_script_module.ts")
-benchmark(trt_script_module, input_shape=(1024, 1, 32, 32), dtype="fp16")
+benchmark(trt_script_module, input_shape=(1024, 1, 32, 32), dtype="fp16")
+
What’s next
-
+
¶
diff --git a/docs/_notebooks/ssd-object-detection-demo.html b/docs/_notebooks/ssd-object-detection-demo.html
index 5843220367..2de3efd2d0 100644
--- a/docs/_notebooks/ssd-object-detection-demo.html
+++ b/docs/_notebooks/ssd-object-detection-demo.html
@@ -760,26 +760,26 @@
-# Copyright 2020 NVIDIA Corporation. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
+# Copyright 2020 NVIDIA Corporation. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
![]() +
+ ![]()
Object Detection with TRTorch (SSD)
@@ -877,9 +877,13 @@
-
+
@@ -902,18 +906,22 @@
-%%capture
-%%bash
-# Known working versions
-pip install numpy==1.19 scipy==1.5.2 Pillow==6.2.0 scikit-image==0.17.2 matplotlib==3.3.0
+%%capture
+%%bash
+# Known working versions
+pip install numpy==1.19 scipy==1.5.2 Pillow==6.2.0 scikit-image==0.17.2 matplotlib==3.3.0
-
+
Single Shot MultiBox Detector model for object detection
@@ -922,8 +930,8 @@
@@ -943,12 +951,12 @@
@@ -1007,10 +1015,10 @@
+
+
-import torch
+import torch
-# List of available models in PyTorch Hub from Nvidia/DeepLearningExamples
-torch.hub.list('NVIDIA/DeepLearningExamples:torchhub')
+# List of available models in PyTorch Hub from Nvidia/DeepLearningExamples
+torch.hub.list('NVIDIA/DeepLearningExamples:torchhub')
-# load SSD model pretrained on COCO from Torch Hub
-precision = 'fp32'
-ssd300 = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_ssd', model_math=precision);
+# load SSD model pretrained on COCO from Torch Hub
+precision = 'fp32'
+ssd300 = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_ssd', model_math=precision);
-# Sample images from the COCO validation set
-uris = [
- 'http://images.cocodataset.org/val2017/000000397133.jpg',
- 'http://images.cocodataset.org/val2017/000000037777.jpg',
- 'http://images.cocodataset.org/val2017/000000252219.jpg'
-]
+# Sample images from the COCO validation set
+uris = [
+ 'http://images.cocodataset.org/val2017/000000397133.jpg',
+ 'http://images.cocodataset.org/val2017/000000037777.jpg',
+ 'http://images.cocodataset.org/val2017/000000252219.jpg'
+]
-# For convenient and comprehensive formatting of input and output of the model, load a set of utility methods.
-utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_ssd_processing_utils')
+# For convenient and comprehensive formatting of input and output of the model, load a set of utility methods.
+utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_ssd_processing_utils')
-# Format images to comply with the network input
-inputs = [utils.prepare_input(uri) for uri in uris]
-tensor = utils.prepare_tensor(inputs, False)
+# Format images to comply with the network input
+inputs = [utils.prepare_input(uri) for uri in uris]
+tensor = utils.prepare_tensor(inputs, False)
-# The model was trained on COCO dataset, which we need to access in order to
-# translate class IDs into object names.
-classes_to_labels = utils.get_coco_object_dictionary()
+# The model was trained on COCO dataset, which we need to access in order to
+# translate class IDs into object names.
+classes_to_labels = utils.get_coco_object_dictionary()
-# Next, we run object detection
-model = ssd300.eval().to("cuda")
-detections_batch = model(tensor)
+# Next, we run object detection
+model = ssd300.eval().to("cuda")
+detections_batch = model(tensor)
-# By default, raw output from SSD network per input image contains 8732 boxes with
-# localization and class probability distribution.
-# Let’s filter this output to only get reasonable detections (confidence>40%) in a more comprehensive format.
-results_per_input = utils.decode_results(detections_batch)
-best_results_per_input = [utils.pick_best(results, 0.40) for results in results_per_input]
+# By default, raw output from SSD network per input image contains 8732 boxes with
+# localization and class probability distribution.
+# Let’s filter this output to only get reasonable detections (confidence>40%) in a more comprehensive format.
+results_per_input = utils.decode_results(detections_batch)
+best_results_per_input = [utils.pick_best(results, 0.40) for results in results_per_input]
-from matplotlib import pyplot as plt
-import matplotlib.patches as patches
+from matplotlib import pyplot as plt
+import matplotlib.patches as patches
-# The utility plots the images and predicted bounding boxes (with confidence scores).
-def plot_results(best_results):
- for image_idx in range(len(best_results)):
- fig, ax = plt.subplots(1)
- # Show original, denormalized image...
- image = inputs[image_idx] / 2 + 0.5
- ax.imshow(image)
- # ...with detections
- bboxes, classes, confidences = best_results[image_idx]
- for idx in range(len(bboxes)):
- left, bot, right, top = bboxes[idx]
- x, y, w, h = [val * 300 for val in [left, bot, right - left, top - bot]]
- rect = patches.Rectangle((x, y), w, h, linewidth=1, edgecolor='r', facecolor='none')
- ax.add_patch(rect)
- ax.text(x, y, "{} {:.0f}%".format(classes_to_labels[classes[idx] - 1], confidences[idx]*100), bbox=dict(facecolor='white', alpha=0.5))
- plt.show()
+# The utility plots the images and predicted bounding boxes (with confidence scores).
+def plot_results(best_results):
+ for image_idx in range(len(best_results)):
+ fig, ax = plt.subplots(1)
+ # Show original, denormalized image...
+ image = inputs[image_idx] / 2 + 0.5
+ ax.imshow(image)
+ # ...with detections
+ bboxes, classes, confidences = best_results[image_idx]
+ for idx in range(len(bboxes)):
+ left, bot, right, top = bboxes[idx]
+ x, y, w, h = [val * 300 for val in [left, bot, right - left, top - bot]]
+ rect = patches.Rectangle((x, y), w, h, linewidth=1, edgecolor='r', facecolor='none')
+ ax.add_patch(rect)
+ ax.text(x, y, "{} {:.0f}%".format(classes_to_labels[classes[idx] - 1], confidences[idx]*100), bbox=dict(facecolor='white', alpha=0.5))
+ plt.show()
-# Visualize results without TRTorch/TensorRT
-plot_results(best_results_per_input)
+# Visualize results without TRTorch/TensorRT
+plot_results(best_results_per_input)
-import time
-import numpy as np
+import time
+import numpy as np
-import torch.backends.cudnn as cudnn
-cudnn.benchmark = True
+import torch.backends.cudnn as cudnn
+cudnn.benchmark = True
-# Helper function to benchmark the model
-def benchmark(model, input_shape=(1024, 1, 32, 32), dtype='fp32', nwarmup=50, nruns=1000):
- input_data = torch.randn(input_shape)
- input_data = input_data.to("cuda")
- if dtype=='fp16':
- input_data = input_data.half()
+# Helper function to benchmark the model
+def benchmark(model, input_shape=(1024, 1, 32, 32), dtype='fp32', nwarmup=50, nruns=1000):
+ input_data = torch.randn(input_shape)
+ input_data = input_data.to("cuda")
+ if dtype=='fp16':
+ input_data = input_data.half()
- print("Warm up ...")
- with torch.no_grad():
- for _ in range(nwarmup):
- features = model(input_data)
- torch.cuda.synchronize()
- print("Start timing ...")
- timings = []
- with torch.no_grad():
- for i in range(1, nruns+1):
- start_time = time.time()
- pred_loc, pred_label = model(input_data)
- torch.cuda.synchronize()
- end_time = time.time()
- timings.append(end_time - start_time)
- if i%100==0:
- print('Iteration %d/%d, avg batch time %.2f ms'%(i, nruns, np.mean(timings)*1000))
+ print("Warm up ...")
+ with torch.no_grad():
+ for _ in range(nwarmup):
+ features = model(input_data)
+ torch.cuda.synchronize()
+ print("Start timing ...")
+ timings = []
+ with torch.no_grad():
+ for i in range(1, nruns+1):
+ start_time = time.time()
+ pred_loc, pred_label = model(input_data)
+ torch.cuda.synchronize()
+ end_time = time.time()
+ timings.append(end_time - start_time)
+ if i%100==0:
+ print('Iteration %d/%d, avg batch time %.2f ms'%(i, nruns, np.mean(timings)*1000))
- print("Input shape:", input_data.size())
- print("Output location prediction size:", pred_loc.size())
- print("Output label prediction size:", pred_label.size())
- print('Average batch time: %.2f ms'%(np.mean(timings)*1000))
+ print("Input shape:", input_data.size())
+ print("Output location prediction size:", pred_loc.size())
+ print("Output label prediction size:", pred_label.size())
+ print('Average batch time: %.2f ms'%(np.mean(timings)*1000))
-# Model benchmark without TRTorch/TensorRT
-model = ssd300.eval().to("cuda")
-benchmark(model, input_shape=(128, 3, 300, 300), nruns=1000)
+# Model benchmark without TRTorch/TensorRT
+model = ssd300.eval().to("cuda")
+benchmark(model, input_shape=(128, 3, 300, 300), nruns=1000)
-
+
-model = ssd300.eval().to("cuda")
-traced_model = torch.jit.trace(model, [torch.randn((1,3,300,300)).to("cuda")])
+model = ssd300.eval().to("cuda")
+traced_model = torch.jit.trace(model, [torch.randn((1,3,300,300)).to("cuda")])
-# This is just an example, and not required for the purposes of this demo
-torch.jit.save(traced_model, "ssd_300_traced.jit.pt")
+# This is just an example, and not required for the purposes of this demo
+torch.jit.save(traced_model, "ssd_300_traced.jit.pt")
-# Obtain the average time taken by a batch of input with Torchscript compiled modules
-benchmark(traced_model, input_shape=(128, 3, 300, 300), nruns=1000)
+# Obtain the average time taken by a batch of input with Torchscript compiled modules
+benchmark(traced_model, input_shape=(128, 3, 300, 300), nruns=1000)
-
+
-import trtorch
+import trtorch
-# The compiled module will have precision as specified by "op_precision".
-# Here, it will have FP16 precision.
-trt_model = trtorch.compile(traced_model, {
- "input_shapes": [(3, 3, 300, 300)],
- "op_precision": torch.half, # Run with FP16
- "workspace_size": 1 << 20
-})
+# The compiled module will have precision as specified by "op_precision".
+# Here, it will have FP16 precision.
+trt_model = trtorch.compile(traced_model, {
+ "input_shapes": [(3, 3, 300, 300)],
+ "op_precision": torch.half, # Run with FP16
+ "workspace_size": 1 << 20
+})
-
+
-# using a TRTorch module is exactly the same as how we usually do inference in PyTorch i.e. model(inputs)
-detections_batch = trt_model(tensor.to(torch.half)) # convert the input to half precision
+# using a TRTorch module is exactly the same as how we usually do inference in PyTorch i.e. model(inputs)
+detections_batch = trt_model(tensor.to(torch.half)) # convert the input to half precision
-# By default, raw output from SSD network per input image contains 8732 boxes with
-# localization and class probability distribution.
-# Let’s filter this output to only get reasonable detections (confidence>40%) in a more comprehensive format.
-results_per_input = utils.decode_results(detections_batch)
-best_results_per_input_trt = [utils.pick_best(results, 0.40) for results in results_per_input]
+# By default, raw output from SSD network per input image contains 8732 boxes with
+# localization and class probability distribution.
+# Let’s filter this output to only get reasonable detections (confidence>40%) in a more comprehensive format.
+results_per_input = utils.decode_results(detections_batch)
+best_results_per_input_trt = [utils.pick_best(results, 0.40) for results in results_per_input]
-# Visualize results with TRTorch/TensorRT
-plot_results(best_results_per_input_trt)
+# Visualize results with TRTorch/TensorRT
+plot_results(best_results_per_input_trt)
-batch_size = 128
+batch_size = 128
-# Recompiling with batch_size we use for evaluating performance
-trt_model = trtorch.compile(traced_model, {
- "input_shapes": [(batch_size, 3, 300, 300)],
- "op_precision": torch.half, # Run with FP16
- "workspace_size": 1 << 20
-})
+# Recompiling with batch_size we use for evaluating performance
+trt_model = trtorch.compile(traced_model, {
+ "input_shapes": [(batch_size, 3, 300, 300)],
+ "op_precision": torch.half, # Run with FP16
+ "workspace_size": 1 << 20
+})
-benchmark(trt_model, input_shape=(batch_size, 3, 300, 300), nruns=1000, dtype="fp16")
+benchmark(trt_model, input_shape=(batch_size, 3, 300, 300), nruns=1000, dtype="fp16")
trtorch::CompileGraph (C++ function)
- ,
-
- [1]
-
[2]
- ,
-
- [3]
-
- ,
-
- [4]
-
- ,
-
- [5]
-
[2]
,
-
- [3]
-
- ,
-
- [4]
-
- ,
-
- [5]
-
- ,
- [6]
+ [3]
,
- [7]
+ [4]
,
- [8]
-
- ,
-
- [9]
-
- ,
-
- [10]
-
- ,
-
- [11]
+ [5]
trtorch::CompileSpec::DataType::operator bool (C++ function)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
trtorch::CompileSpec::DataType::operator Value (C++ function)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
[1]
,
-
- [2]
-
- ,
-
- [3]
-
- ,
- [4]
+ [2]
,
- [5]
-
- ,
-
- [6]
-
- ,
-
- [7]
+ [3]
[1]
,
-
- [2]
-
- ,
-
- [3]
-
- ,
- [4]
+ [2]
,
- [5]
-
- ,
-
- [6]
-
- ,
-
- [7]
+ [3]
trtorch::CompileSpec::DataType::Value (C++ enum)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
trtorch::CompileSpec::DataType::Value::kChar (C++ enumerator)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
trtorch::CompileSpec::DataType::Value::kFloat (C++ enumerator)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
trtorch::CompileSpec::DataType::Value::kHalf (C++ enumerator)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
[2]
,
-
- [3]
-
- ,
-
- [4]
-
- ,
-
- [5]
-
- ,
- [6]
+ [3]
,
- [7]
+ [4]
,
- [8]
-
- ,
-
- [9]
-
- ,
-
- [10]
-
- ,
-
- [11]
+ [5]
trtorch::CompileSpec::DeviceType::operator bool (C++ function)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
trtorch::CompileSpec::DeviceType::operator Value (C++ function)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
trtorch::CompileSpec::DeviceType::operator!= (C++ function)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
trtorch::CompileSpec::DeviceType::operator== (C++ function)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
trtorch::CompileSpec::DeviceType::Value (C++ enum)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
trtorch::CompileSpec::DeviceType::Value::kDLA (C++ enumerator)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
trtorch::CompileSpec::DeviceType::Value::kGPU (C++ enumerator)
,
-
- [1]
-
- ,
- [2]
-
- ,
-
- [3]
+ [1]
[1]
- ,
-
- [2]
-
- ,
-
- [3]
-
[7]
- ,
-
- [8]
-
- ,
-
- [9]
-
- ,
-
- [10]
-
- ,
-
- [11]
-
- ,
-
- [12]
-
- ,
-
- [13]
-
- ,
-
- [14]
-
- ,
-
- [15]
-
[1]
- ,
-
- [2]
-
- ,
-
- [3]
-
[1]
- ,
-
- [2]
-
- ,
-
- [3]
-
[1]
- ,
-
- [2]
-
- ,
-
- [3]
-
trtorch::CompileSpec::num_min_timing_iters (C++ member)
- ,
-
- [1]
-