diff --git a/README.md b/README.md
index 112ed40de3..3c517c5386 100644
--- a/README.md
+++ b/README.md
@@ -98,6 +98,7 @@ Supported methods:
- [x] [PointRend (CVPR'2020)](configs/point_rend)
- [x] [CGNet (TIP'2020)](configs/cgnet)
- [x] [BiSeNetV2 (IJCV'2021)](configs/bisenetv2)
+- [x] [STDC (CVPR'2021)](configs/stdc)
- [x] [SETR (CVPR'2021)](configs/setr)
- [x] [DPT (ArXiv'2021)](configs/dpt)
- [x] [SegFormer (NeurIPS'2021)](configs/segformer)
diff --git a/README_zh-CN.md b/README_zh-CN.md
index 8be4a56a7b..912734b334 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -97,6 +97,7 @@ MMSegmentation 是一个基于 PyTorch 的语义分割开源工具箱。它是 O
- [x] [PointRend (CVPR'2020)](configs/point_rend)
- [x] [CGNet (TIP'2020)](configs/cgnet)
- [x] [BiSeNetV2 (IJCV'2021)](configs/bisenetv2)
+- [x] [STDC (CVPR'2021)](configs/stdc)
- [x] [SETR (CVPR'2021)](configs/setr)
- [x] [DPT (ArXiv'2021)](configs/dpt)
- [x] [SegFormer (NeurIPS'2021)](configs/segformer)
diff --git a/configs/_base_/models/stdc.py b/configs/_base_/models/stdc.py
new file mode 100644
index 0000000000..e313f0443e
--- /dev/null
+++ b/configs/_base_/models/stdc.py
@@ -0,0 +1,83 @@
+norm_cfg = dict(type='BN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained=None,
+ backbone=dict(
+ type='STDCContextPathNet',
+ backbone_cfg=dict(
+ type='STDCNet',
+ stdc_type='STDCNet1',
+ in_channels=3,
+ channels=(32, 64, 256, 512, 1024),
+ bottleneck_type='cat',
+ num_convs=4,
+ norm_cfg=norm_cfg,
+ act_cfg=dict(type='ReLU'),
+ with_final_conv=False),
+ last_in_channels=(1024, 512),
+ out_channels=128,
+ ffm_cfg=dict(in_channels=384, out_channels=256, scale_factor=4)),
+ decode_head=dict(
+ type='FCNHead',
+ in_channels=256,
+ channels=256,
+ num_convs=1,
+ num_classes=19,
+ in_index=3,
+ concat_input=False,
+ dropout_ratio=0.1,
+ norm_cfg=norm_cfg,
+ align_corners=True,
+ sampler=dict(type='OHEMPixelSampler', thresh=0.7, min_kept=10000),
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=[
+ dict(
+ type='FCNHead',
+ in_channels=128,
+ channels=64,
+ num_convs=1,
+ num_classes=19,
+ in_index=2,
+ norm_cfg=norm_cfg,
+ concat_input=False,
+ align_corners=False,
+ sampler=dict(type='OHEMPixelSampler', thresh=0.7, min_kept=10000),
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ dict(
+ type='FCNHead',
+ in_channels=128,
+ channels=64,
+ num_convs=1,
+ num_classes=19,
+ in_index=1,
+ norm_cfg=norm_cfg,
+ concat_input=False,
+ align_corners=False,
+ sampler=dict(type='OHEMPixelSampler', thresh=0.7, min_kept=10000),
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ dict(
+ type='STDCHead',
+ in_channels=256,
+ channels=64,
+ num_convs=1,
+ num_classes=2,
+ boundary_threshold=0.1,
+ in_index=0,
+ norm_cfg=norm_cfg,
+ concat_input=False,
+ align_corners=False,
+ loss_decode=[
+ dict(
+ type='CrossEntropyLoss',
+ loss_name='loss_ce',
+ use_sigmoid=True,
+ loss_weight=1.0),
+ dict(type='DiceLoss', loss_name='loss_dice', loss_weight=1.0)
+ ]),
+ ],
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/stdc/README.md b/configs/stdc/README.md
new file mode 100644
index 0000000000..8a15b74617
--- /dev/null
+++ b/configs/stdc/README.md
@@ -0,0 +1,71 @@
+# Rethinking BiSeNet For Real-time Semantic Segmentation
+
+## Introduction
+
+
+
+Official Repo
+
+Code Snippet
+
+## Abstract
+
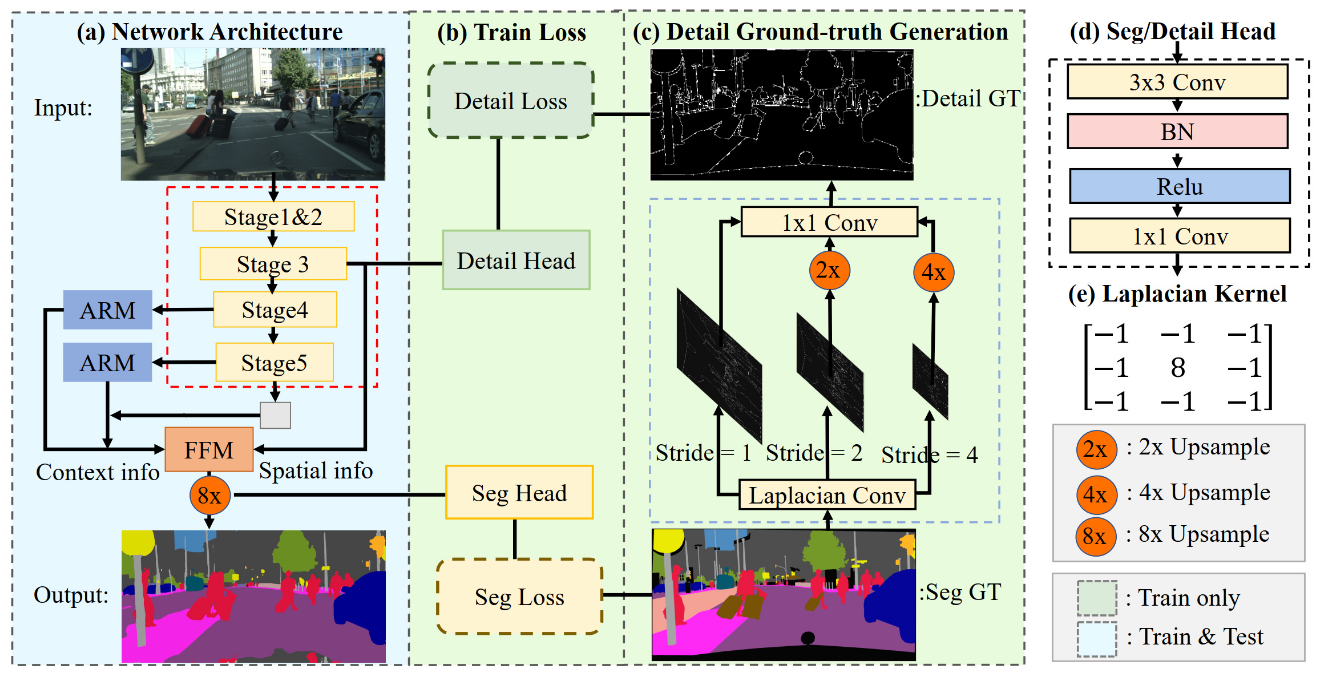
+BiSeNet has been proved to be a popular two-stream network for real-time segmentation. However, its principle of adding an extra path to encode spatial information is time-consuming, and the backbones borrowed from pretrained tasks, e.g., image classification, may be inefficient for image segmentation due to the deficiency of task-specific design. To handle these problems, we propose a novel and efficient structure named Short-Term Dense Concatenate network (STDC network) by removing structure redundancy. Specifically, we gradually reduce the dimension of feature maps and use the aggregation of them for image representation, which forms the basic module of STDC network. In the decoder, we propose a Detail Aggregation module by integrating the learning of spatial information into low-level layers in single-stream manner. Finally, the low-level features and deep features are fused to predict the final segmentation results. Extensive experiments on Cityscapes and CamVid dataset demonstrate the effectiveness of our method by achieving promising trade-off between segmentation accuracy and inference speed. On Cityscapes, we achieve 71.9% mIoU on the test set with a speed of 250.4 FPS on NVIDIA GTX 1080Ti, which is 45.2% faster than the latest methods, and achieve 76.8% mIoU with 97.0 FPS while inferring on higher resolution images.
+
+
+
+
+
+STDC (CVPR'2021)
+
+```latex
+@inproceedings{fan2021rethinking,
+ title={Rethinking BiSeNet For Real-time Semantic Segmentation},
+ author={Fan, Mingyuan and Lai, Shenqi and Huang, Junshi and Wei, Xiaoming and Chai, Zhenhua and Luo, Junfeng and Wei, Xiaolin},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ pages={9716--9725},
+ year={2021}
+}
+```
+
+
+
+## Usage
+
+To use original repositories' [ImageNet Pretrained STDCNet Weights](https://drive.google.com/drive/folders/1wROFwRt8qWHD4jSo8Zu1gp1d6oYJ3ns1) , it is necessary to convert keys.
+
+We provide a script [`stdc2mmseg.py`](../../tools/model_converters/stdc2mmseg.py) in the tools directory to convert the key of models from [the official repo](https://github.com/MichaelFan01/STDC-Seg) to MMSegmentation style.
+
+```shell
+python tools/model_converters/stdc2mmseg.py ${PRETRAIN_PATH} ${STORE_PATH} ${STDC_TYPE}
+```
+
+E.g.
+
+```shell
+python tools/model_converters/stdc2mmseg.py ./STDCNet813M_73.91.tar ./pretrained/stdc1.pth STDC1
+
+python tools/model_converters/stdc2mmseg.py ./STDCNet1446_76.47.tar ./pretrained/stdc2.pth STDC2
+```
+
+This script convert model from `PRETRAIN_PATH` and store the converted model in `STORE_PATH`.
+
+## Results and models
+
+### Cityscapes
+
+| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
+| --------- | --------- | --------- | ------: | -------- | -------------- | ----: | ------------- | --------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| STDC1 (No Pretrain) | STDC1 | 512x1024 | 80000 | 7.15 | 23.06 | 71.52 | 73.35 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/stdc/stdc1_512x1024_80k_cityscapes.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/v0.5/stdc/stdc1_512x1024_80k_cityscapes/stdc1_512x1024_80k_cityscapes_20211125_211245-2c8ba4c5.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/stdc/stdc1_512x1024_80k_cityscapes/stdc1_512x1024_80k_cityscapes_20211125_211245.log.json) |
+| STDC1| STDC1 | 512x1024 | 80000 | - | - | 75.10 | 77.72 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/stdc/stdc1_in1k-pre_512x1024_80k_cityscapes.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/stdc/stdc1_in1k-pre_512x1024_80k_cityscapes/stdc1_in1k-pre_512x1024_80k_cityscapes_20211125_213942-880bb7d0.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/stdc/stdc1_in1k-pre_512x1024_80k_cityscapes/stdc1_in1k-pre_512x1024_80k_cityscapes_20211125_213942.log.json) |
+| STDC2 (No Pretrain) | STDC2 | 512x1024 | 80000 | 8.27 | 23.71 | 73.20 | 75.55 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/stdc/stdc2_512x1024_80k_cityscapes.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/stdc/stdc2_512x1024_80k_cityscapes/stdc2_512x1024_80k_cityscapes_20211125_222450-82333ae0.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/stdc/stdc2_512x1024_80k_cityscapes/stdc2_512x1024_80k_cityscapes_20211125_222450.log.json) |
+| STDC2 | STDC2 | 512x1024 | 80000 | - | - | 77.17 | 79.01 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/stdc/stdc2_in1k-pre_512x1024_80k_cityscapes.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/stdc/stdc2_in1k-pre_512x1024_80k_cityscapes/stdc2_in1k-pre_512x1024_80k_cityscapes_20211125_220437-d2c469f8.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/stdc/stdc2_in1k-pre_512x1024_80k_cityscapes/stdc2_in1k-pre_512x1024_80k_cityscapes_20211125_220437.log.json) |
+
+Note:
+
+- For STDC on Cityscapes dataset, default setting is 4 GPUs with 12 samples per GPU in training.
+- `No Pretrain` means the model is trained from scratch.
+- The FPS is for reference only. The environment is also different from paper setting, whose input size is `512x1024` and `768x1536`, i.e., 50% and 75% of our input size, respectively and using TensorRT.
+- The parameter `fusion_kernel` in `STDCHead` is not learnable. In official repo, `find_unused_parameters=True` is set [here](https://github.com/MichaelFan01/STDC-Seg/blob/59ff37fbd693b99972c76fcefe97caa14aeb619f/train.py#L220). You may check it by printing model parameters of original repo on your own.
diff --git a/configs/stdc/stdc.yml b/configs/stdc/stdc.yml
new file mode 100644
index 0000000000..a23894e332
--- /dev/null
+++ b/configs/stdc/stdc.yml
@@ -0,0 +1,87 @@
+Collections:
+- Name: stdc
+ Metadata:
+ Training Data:
+ - Cityscapes
+ Paper:
+ URL: https://arxiv.org/abs/2104.13188
+ Title: Rethinking BiSeNet For Real-time Semantic Segmentation
+ README: configs/stdc/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmsegmentation/blob/v0.20.0/mmseg/models/backbones/stdc.py#L394
+ Version: v0.20.0
+ Converted From:
+ Code: https://github.com/MichaelFan01/STDC-Seg
+Models:
+- Name: stdc1_512x1024_80k_cityscapes
+ In Collection: stdc
+ Metadata:
+ backbone: STDC1
+ crop size: (512,1024)
+ lr schd: 80000
+ inference time (ms/im):
+ - value: 43.37
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,1024)
+ Training Memory (GB): 7.15
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: Cityscapes
+ Metrics:
+ mIoU: 71.52
+ mIoU(ms+flip): 73.35
+ Config: configs/stdc/stdc1_512x1024_80k_cityscapes.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/v0.5/stdc/stdc1_512x1024_80k_cityscapes/stdc1_512x1024_80k_cityscapes_20211125_211245-2c8ba4c5.pth
+- Name: stdc1_in1k-pre_512x1024_80k_cityscapes
+ In Collection: stdc
+ Metadata:
+ backbone: STDC1
+ crop size: (512,1024)
+ lr schd: 80000
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: Cityscapes
+ Metrics:
+ mIoU: 75.1
+ mIoU(ms+flip): 77.72
+ Config: configs/stdc/stdc1_in1k-pre_512x1024_80k_cityscapes.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/stdc/stdc1_in1k-pre_512x1024_80k_cityscapes/stdc1_in1k-pre_512x1024_80k_cityscapes_20211125_213942-880bb7d0.pth
+- Name: stdc2_512x1024_80k_cityscapes
+ In Collection: stdc
+ Metadata:
+ backbone: STDC2
+ crop size: (512,1024)
+ lr schd: 80000
+ inference time (ms/im):
+ - value: 42.18
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,1024)
+ Training Memory (GB): 8.27
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: Cityscapes
+ Metrics:
+ mIoU: 73.2
+ mIoU(ms+flip): 75.55
+ Config: configs/stdc/stdc2_512x1024_80k_cityscapes.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/stdc/stdc2_512x1024_80k_cityscapes/stdc2_512x1024_80k_cityscapes_20211125_222450-82333ae0.pth
+- Name: stdc2_in1k-pre_512x1024_80k_cityscapes
+ In Collection: stdc
+ Metadata:
+ backbone: STDC2
+ crop size: (512,1024)
+ lr schd: 80000
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: Cityscapes
+ Metrics:
+ mIoU: 77.17
+ mIoU(ms+flip): 79.01
+ Config: configs/stdc/stdc2_in1k-pre_512x1024_80k_cityscapes.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/stdc/stdc2_in1k-pre_512x1024_80k_cityscapes/stdc2_in1k-pre_512x1024_80k_cityscapes_20211125_220437-d2c469f8.pth
diff --git a/configs/stdc/stdc1_512x1024_80k_cityscapes.py b/configs/stdc/stdc1_512x1024_80k_cityscapes.py
new file mode 100644
index 0000000000..849e771e41
--- /dev/null
+++ b/configs/stdc/stdc1_512x1024_80k_cityscapes.py
@@ -0,0 +1,9 @@
+_base_ = [
+ '../_base_/models/stdc.py', '../_base_/datasets/cityscapes.py',
+ '../_base_/default_runtime.py', '../_base_/schedules/schedule_80k.py'
+]
+lr_config = dict(warmup='linear', warmup_iters=1000)
+data = dict(
+ samples_per_gpu=12,
+ workers_per_gpu=4,
+)
diff --git a/configs/stdc/stdc1_in1k-pre_512x1024_80k_cityscapes.py b/configs/stdc/stdc1_in1k-pre_512x1024_80k_cityscapes.py
new file mode 100644
index 0000000000..4845b4dc87
--- /dev/null
+++ b/configs/stdc/stdc1_in1k-pre_512x1024_80k_cityscapes.py
@@ -0,0 +1,6 @@
+_base_ = './stdc1_512x1024_80k_cityscapes.py'
+model = dict(
+ backbone=dict(
+ backbone_cfg=dict(
+ init_cfg=dict(
+ type='Pretrained', checkpoint='./pretrained/stdc1.pth'))))
diff --git a/configs/stdc/stdc2_512x1024_80k_cityscapes.py b/configs/stdc/stdc2_512x1024_80k_cityscapes.py
new file mode 100644
index 0000000000..f7afb506a0
--- /dev/null
+++ b/configs/stdc/stdc2_512x1024_80k_cityscapes.py
@@ -0,0 +1,2 @@
+_base_ = './stdc1_512x1024_80k_cityscapes.py'
+model = dict(backbone=dict(backbone_cfg=dict(stdc_type='STDCNet2')))
diff --git a/configs/stdc/stdc2_in1k-pre_512x1024_80k_cityscapes.py b/configs/stdc/stdc2_in1k-pre_512x1024_80k_cityscapes.py
new file mode 100644
index 0000000000..17c0b15ca7
--- /dev/null
+++ b/configs/stdc/stdc2_in1k-pre_512x1024_80k_cityscapes.py
@@ -0,0 +1,6 @@
+_base_ = './stdc2_512x1024_80k_cityscapes.py'
+model = dict(
+ backbone=dict(
+ backbone_cfg=dict(
+ init_cfg=dict(
+ type='Pretrained', checkpoint='./pretrained/stdc2.pth'))))
diff --git a/mmseg/models/backbones/__init__.py b/mmseg/models/backbones/__init__.py
index cdd171d6ac..434378e993 100644
--- a/mmseg/models/backbones/__init__.py
+++ b/mmseg/models/backbones/__init__.py
@@ -12,6 +12,7 @@
from .resnest import ResNeSt
from .resnet import ResNet, ResNetV1c, ResNetV1d
from .resnext import ResNeXt
+from .stdc import STDCContextPathNet, STDCNet
from .swin import SwinTransformer
from .timm_backbone import TIMMBackbone
from .twins import PCPVT, SVT
@@ -22,5 +23,6 @@
'ResNet', 'ResNetV1c', 'ResNetV1d', 'ResNeXt', 'HRNet', 'FastSCNN',
'ResNeSt', 'MobileNetV2', 'UNet', 'CGNet', 'MobileNetV3',
'VisionTransformer', 'SwinTransformer', 'MixVisionTransformer',
- 'BiSeNetV1', 'BiSeNetV2', 'ICNet', 'TIMMBackbone', 'ERFNet', 'PCPVT', 'SVT'
+ 'BiSeNetV1', 'BiSeNetV2', 'ICNet', 'TIMMBackbone', 'ERFNet', 'PCPVT',
+ 'SVT', 'STDCNet', 'STDCContextPathNet'
]
diff --git a/mmseg/models/backbones/stdc.py b/mmseg/models/backbones/stdc.py
new file mode 100644
index 0000000000..04f2f7a2a7
--- /dev/null
+++ b/mmseg/models/backbones/stdc.py
@@ -0,0 +1,422 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Modified from https://github.com/MichaelFan01/STDC-Seg."""
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmcv.runner.base_module import BaseModule, ModuleList, Sequential
+
+from mmseg.ops import resize
+from ..builder import BACKBONES, build_backbone
+from .bisenetv1 import AttentionRefinementModule
+
+
+class STDCModule(BaseModule):
+ """STDCModule.
+
+ Args:
+ in_channels (int): The number of input channels.
+ out_channels (int): The number of output channels before scaling.
+ stride (int): The number of stride for the first conv layer.
+ norm_cfg (dict): Config dict for normalization layer. Default: None.
+ act_cfg (dict): The activation config for conv layers.
+ num_convs (int): Numbers of conv layers.
+ fusion_type (str): Type of fusion operation. Default: 'add'.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ stride,
+ norm_cfg=None,
+ act_cfg=None,
+ num_convs=4,
+ fusion_type='add',
+ init_cfg=None):
+ super(STDCModule, self).__init__(init_cfg=init_cfg)
+ assert num_convs > 1
+ assert fusion_type in ['add', 'cat']
+ self.stride = stride
+ self.with_downsample = True if self.stride == 2 else False
+ self.fusion_type = fusion_type
+
+ self.layers = ModuleList()
+ conv_0 = ConvModule(
+ in_channels, out_channels // 2, kernel_size=1, norm_cfg=norm_cfg)
+
+ if self.with_downsample:
+ self.downsample = ConvModule(
+ out_channels // 2,
+ out_channels // 2,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ groups=out_channels // 2,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+
+ if self.fusion_type == 'add':
+ self.layers.append(nn.Sequential(conv_0, self.downsample))
+ self.skip = Sequential(
+ ConvModule(
+ in_channels,
+ in_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ groups=in_channels,
+ norm_cfg=norm_cfg,
+ act_cfg=None),
+ ConvModule(
+ in_channels,
+ out_channels,
+ 1,
+ norm_cfg=norm_cfg,
+ act_cfg=None))
+ else:
+ self.layers.append(conv_0)
+ self.skip = nn.AvgPool2d(kernel_size=3, stride=2, padding=1)
+ else:
+ self.layers.append(conv_0)
+
+ for i in range(1, num_convs):
+ out_factor = 2**(i + 1) if i != num_convs - 1 else 2**i
+ self.layers.append(
+ ConvModule(
+ out_channels // 2**i,
+ out_channels // out_factor,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ def forward(self, inputs):
+ if self.fusion_type == 'add':
+ out = self.forward_add(inputs)
+ else:
+ out = self.forward_cat(inputs)
+ return out
+
+ def forward_add(self, inputs):
+ layer_outputs = []
+ x = inputs.clone()
+ for layer in self.layers:
+ x = layer(x)
+ layer_outputs.append(x)
+ if self.with_downsample:
+ inputs = self.skip(inputs)
+
+ return torch.cat(layer_outputs, dim=1) + inputs
+
+ def forward_cat(self, inputs):
+ x0 = self.layers[0](inputs)
+ layer_outputs = [x0]
+ for i, layer in enumerate(self.layers[1:]):
+ if i == 0:
+ if self.with_downsample:
+ x = layer(self.downsample(x0))
+ else:
+ x = layer(x0)
+ else:
+ x = layer(x)
+ layer_outputs.append(x)
+ if self.with_downsample:
+ layer_outputs[0] = self.skip(x0)
+ return torch.cat(layer_outputs, dim=1)
+
+
+class FeatureFusionModule(BaseModule):
+ """Feature Fusion Module. This module is different from FeatureFusionModule
+ in BiSeNetV1. It uses two ConvModules in `self.attention` whose inter
+ channel number is calculated by given `scale_factor`, while
+ FeatureFusionModule in BiSeNetV1 only uses one ConvModule in
+ `self.conv_atten`.
+
+ Args:
+ in_channels (int): The number of input channels.
+ out_channels (int): The number of output channels.
+ scale_factor (int): The number of channel scale factor.
+ Default: 4.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict): The activation config for conv layers.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ scale_factor=4,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ init_cfg=None):
+ super(FeatureFusionModule, self).__init__(init_cfg=init_cfg)
+ channels = out_channels // scale_factor
+ self.conv0 = ConvModule(
+ in_channels, out_channels, 1, norm_cfg=norm_cfg, act_cfg=act_cfg)
+ self.attention = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, 1)),
+ ConvModule(
+ out_channels,
+ channels,
+ 1,
+ norm_cfg=None,
+ bias=False,
+ act_cfg=act_cfg),
+ ConvModule(
+ channels,
+ out_channels,
+ 1,
+ norm_cfg=None,
+ bias=False,
+ act_cfg=None), nn.Sigmoid())
+
+ def forward(self, spatial_inputs, context_inputs):
+ inputs = torch.cat([spatial_inputs, context_inputs], dim=1)
+ x = self.conv0(inputs)
+ attn = self.attention(x)
+ x_attn = x * attn
+ return x_attn + x
+
+
+@BACKBONES.register_module()
+class STDCNet(BaseModule):
+ """This backbone is the implementation of `Rethinking BiSeNet For Real-time
+ Semantic Segmentation `_.
+
+ Args:
+ stdc_type (int): The type of backbone structure,
+ `STDCNet1` and`STDCNet2` denotes two main backbones in paper,
+ whose FLOPs is 813M and 1446M, respectively.
+ in_channels (int): The num of input_channels.
+ channels (tuple[int]): The output channels for each stage.
+ bottleneck_type (str): The type of STDC Module type, the value must
+ be 'add' or 'cat'.
+ norm_cfg (dict): Config dict for normalization layer.
+ act_cfg (dict): The activation config for conv layers.
+ num_convs (int): Numbers of conv layer at each STDC Module.
+ Default: 4.
+ with_final_conv (bool): Whether add a conv layer at the Module output.
+ Default: True.
+ pretrained (str, optional): Model pretrained path. Default: None.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+
+ Example:
+ >>> import torch
+ >>> stdc_type = 'STDCNet1'
+ >>> in_channels = 3
+ >>> channels = (32, 64, 256, 512, 1024)
+ >>> bottleneck_type = 'cat'
+ >>> inputs = torch.rand(1, 3, 1024, 2048)
+ >>> self = STDCNet(stdc_type, in_channels,
+ ... channels, bottleneck_type).eval()
+ >>> outputs = self.forward(inputs)
+ >>> for i in range(len(outputs)):
+ ... print(f'outputs[{i}].shape = {outputs[i].shape}')
+ outputs[0].shape = torch.Size([1, 256, 128, 256])
+ outputs[1].shape = torch.Size([1, 512, 64, 128])
+ outputs[2].shape = torch.Size([1, 1024, 32, 64])
+ """
+
+ arch_settings = {
+ 'STDCNet1': [(2, 1), (2, 1), (2, 1)],
+ 'STDCNet2': [(2, 1, 1, 1), (2, 1, 1, 1, 1), (2, 1, 1)]
+ }
+
+ def __init__(self,
+ stdc_type,
+ in_channels,
+ channels,
+ bottleneck_type,
+ norm_cfg,
+ act_cfg,
+ num_convs=4,
+ with_final_conv=False,
+ pretrained=None,
+ init_cfg=None):
+ super(STDCNet, self).__init__(init_cfg=init_cfg)
+ assert stdc_type in self.arch_settings, \
+ f'invalid structure {stdc_type} for STDCNet.'
+ assert bottleneck_type in ['add', 'cat'],\
+ f'bottleneck_type must be `add` or `cat`, got {bottleneck_type}'
+
+ assert len(channels) == 5,\
+ f'invalid channels length {len(channels)} for STDCNet.'
+
+ self.in_channels = in_channels
+ self.channels = channels
+ self.stage_strides = self.arch_settings[stdc_type]
+ self.prtrained = pretrained
+ self.num_convs = num_convs
+ self.with_final_conv = with_final_conv
+
+ self.stages = ModuleList([
+ ConvModule(
+ self.in_channels,
+ self.channels[0],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ ConvModule(
+ self.channels[0],
+ self.channels[1],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ ])
+ # `self.num_shallow_features` is the number of shallow modules in
+ # `STDCNet`, which is noted as `Stage1` and `Stage2` in original paper.
+ # They are both not used for following modules like Attention
+ # Refinement Module and Feature Fusion Module.
+ # Thus they would be cut from `outs`. Please refer to Figure 4
+ # of original paper for more details.
+ self.num_shallow_features = len(self.stages)
+
+ for strides in self.stage_strides:
+ idx = len(self.stages) - 1
+ self.stages.append(
+ self._make_stage(self.channels[idx], self.channels[idx + 1],
+ strides, norm_cfg, act_cfg, bottleneck_type))
+ # After appending, `self.stages` is a ModuleList including several
+ # shallow modules and STDCModules.
+ # (len(self.stages) ==
+ # self.num_shallow_features + len(self.stage_strides))
+ if self.with_final_conv:
+ self.final_conv = ConvModule(
+ self.channels[-1],
+ max(1024, self.channels[-1]),
+ 1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def _make_stage(self, in_channels, out_channels, strides, norm_cfg,
+ act_cfg, bottleneck_type):
+ layers = []
+ for i, stride in enumerate(strides):
+ layers.append(
+ STDCModule(
+ in_channels if i == 0 else out_channels,
+ out_channels,
+ stride,
+ norm_cfg,
+ act_cfg,
+ num_convs=self.num_convs,
+ fusion_type=bottleneck_type))
+ return Sequential(*layers)
+
+ def forward(self, x):
+ outs = []
+ for stage in self.stages:
+ x = stage(x)
+ outs.append(x)
+ if self.with_final_conv:
+ outs[-1] = self.final_conv(outs[-1])
+ outs = outs[self.num_shallow_features:]
+ return tuple(outs)
+
+
+@BACKBONES.register_module()
+class STDCContextPathNet(BaseModule):
+ """STDCNet with Context Path. The `outs` below is a list of three feature
+ maps from deep to shallow, whose height and width is from small to big,
+ respectively. The biggest feature map of `outs` is outputted for
+ `STDCHead`, where Detail Loss would be calculated by Detail Ground-truth.
+ The other two feature maps are used for Attention Refinement Module,
+ respectively. Besides, the biggest feature map of `outs` and the last
+ output of Attention Refinement Module are concatenated for Feature Fusion
+ Module. Then, this fusion feature map `feat_fuse` would be outputted for
+ `decode_head`. More details please refer to Figure 4 of original paper.
+
+ Args:
+ backbone_cfg (dict): Config dict for stdc backbone.
+ last_in_channels (tuple(int)), The number of channels of last
+ two feature maps from stdc backbone. Default: (1024, 512).
+ out_channels (int): The channels of output feature maps.
+ Default: 128.
+ ffm_cfg (dict): Config dict for Feature Fusion Module. Default:
+ `dict(in_channels=512, out_channels=256, scale_factor=4)`.
+ upsample_mode (str): Algorithm used for upsampling:
+ ``'nearest'`` | ``'linear'`` | ``'bilinear'`` | ``'bicubic'`` |
+ ``'trilinear'``. Default: ``'nearest'``.
+ align_corners (str): align_corners argument of F.interpolate. It
+ must be `None` if upsample_mode is ``'nearest'``. Default: None.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+
+ Return:
+ outputs (tuple): The tuple of list of output feature map for
+ auxiliary heads and decoder head.
+ """
+
+ def __init__(self,
+ backbone_cfg,
+ last_in_channels=(1024, 512),
+ out_channels=128,
+ ffm_cfg=dict(
+ in_channels=512, out_channels=256, scale_factor=4),
+ upsample_mode='nearest',
+ align_corners=None,
+ norm_cfg=dict(type='BN'),
+ init_cfg=None):
+ super(STDCContextPathNet, self).__init__(init_cfg=init_cfg)
+ self.backbone = build_backbone(backbone_cfg)
+ self.arms = ModuleList()
+ self.convs = ModuleList()
+ for channels in last_in_channels:
+ self.arms.append(AttentionRefinementModule(channels, out_channels))
+ self.convs.append(
+ ConvModule(
+ out_channels,
+ out_channels,
+ 3,
+ padding=1,
+ norm_cfg=norm_cfg))
+ self.conv_avg = ConvModule(
+ last_in_channels[0], out_channels, 1, norm_cfg=norm_cfg)
+
+ self.ffm = FeatureFusionModule(**ffm_cfg)
+
+ self.upsample_mode = upsample_mode
+ self.align_corners = align_corners
+
+ def forward(self, x):
+ outs = list(self.backbone(x))
+ avg = F.adaptive_avg_pool2d(outs[-1], 1)
+ avg_feat = self.conv_avg(avg)
+
+ feature_up = resize(
+ avg_feat,
+ size=outs[-1].shape[2:],
+ mode=self.upsample_mode,
+ align_corners=self.align_corners)
+ arms_out = []
+ for i in range(len(self.arms)):
+ x_arm = self.arms[i](outs[len(outs) - 1 - i]) + feature_up
+ feature_up = resize(
+ x_arm,
+ size=outs[len(outs) - 1 - i - 1].shape[2:],
+ mode=self.upsample_mode,
+ align_corners=self.align_corners)
+ feature_up = self.convs[i](feature_up)
+ arms_out.append(feature_up)
+
+ feat_fuse = self.ffm(outs[0], arms_out[1])
+
+ # The `outputs` has four feature maps.
+ # `outs[0]` is outputted for `STDCHead` auxiliary head.
+ # Two feature maps of `arms_out` are outputted for auxiliary head.
+ # `feat_fuse` is outputted for decoder head.
+ outputs = [outs[0]] + list(arms_out) + [feat_fuse]
+ return tuple(outputs)
diff --git a/mmseg/models/decode_heads/__init__.py b/mmseg/models/decode_heads/__init__.py
index 14a2b2d6f1..b5375a1f5a 100644
--- a/mmseg/models/decode_heads/__init__.py
+++ b/mmseg/models/decode_heads/__init__.py
@@ -24,6 +24,7 @@
from .sep_fcn_head import DepthwiseSeparableFCNHead
from .setr_mla_head import SETRMLAHead
from .setr_up_head import SETRUPHead
+from .stdc_head import STDCHead
from .uper_head import UPerHead
__all__ = [
@@ -31,5 +32,6 @@
'UPerHead', 'DepthwiseSeparableASPPHead', 'ANNHead', 'DAHead', 'OCRHead',
'EncHead', 'DepthwiseSeparableFCNHead', 'FPNHead', 'EMAHead', 'DNLHead',
'PointHead', 'APCHead', 'DMHead', 'LRASPPHead', 'SETRUPHead',
- 'SETRMLAHead', 'DPTHead', 'SETRMLAHead', 'SegformerHead', 'ISAHead'
+ 'SETRMLAHead', 'DPTHead', 'SETRMLAHead', 'SegformerHead', 'ISAHead',
+ 'STDCHead'
]
diff --git a/mmseg/models/decode_heads/stdc_head.py b/mmseg/models/decode_heads/stdc_head.py
new file mode 100644
index 0000000000..716001639c
--- /dev/null
+++ b/mmseg/models/decode_heads/stdc_head.py
@@ -0,0 +1,90 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn.functional as F
+
+from ..builder import HEADS
+from .fcn_head import FCNHead
+
+
+@HEADS.register_module()
+class STDCHead(FCNHead):
+ """This head is the implementation of `Rethinking BiSeNet For Real-time
+ Semantic Segmentation `_.
+
+ Args:
+ boundary_threshold (float): The threshold of calculating boundary.
+ Default: 0.1.
+ """
+
+ def __init__(self, boundary_threshold=0.1, **kwargs):
+ super(STDCHead, self).__init__(**kwargs)
+ self.boundary_threshold = boundary_threshold
+ # Using register buffer to make laplacian kernel on the same
+ # device of `seg_label`.
+ self.register_buffer(
+ 'laplacian_kernel',
+ torch.tensor([-1, -1, -1, -1, 8, -1, -1, -1, -1],
+ dtype=torch.float32,
+ requires_grad=False).reshape((1, 1, 3, 3)))
+ self.fusion_kernel = torch.nn.Parameter(
+ torch.tensor([[6. / 10], [3. / 10], [1. / 10]],
+ dtype=torch.float32).reshape(1, 3, 1, 1),
+ requires_grad=False)
+
+ def losses(self, seg_logit, seg_label):
+ """Compute Detail Aggregation Loss."""
+ # Note: The paper claims `fusion_kernel` is a trainable 1x1 conv
+ # parameters. However, it is a constant in original repo and other
+ # codebase because it would not be added into computation graph
+ # after threshold operation.
+ seg_label = seg_label.float()
+ boundary_targets = F.conv2d(
+ seg_label, self.laplacian_kernel, padding=1)
+ boundary_targets = boundary_targets.clamp(min=0)
+ boundary_targets[boundary_targets > self.boundary_threshold] = 1
+ boundary_targets[boundary_targets <= self.boundary_threshold] = 0
+
+ boundary_targets_x2 = F.conv2d(
+ seg_label, self.laplacian_kernel, stride=2, padding=1)
+ boundary_targets_x2 = boundary_targets_x2.clamp(min=0)
+
+ boundary_targets_x4 = F.conv2d(
+ seg_label, self.laplacian_kernel, stride=4, padding=1)
+ boundary_targets_x4 = boundary_targets_x4.clamp(min=0)
+
+ boundary_targets_x4_up = F.interpolate(
+ boundary_targets_x4, boundary_targets.shape[2:], mode='nearest')
+ boundary_targets_x2_up = F.interpolate(
+ boundary_targets_x2, boundary_targets.shape[2:], mode='nearest')
+
+ boundary_targets_x2_up[
+ boundary_targets_x2_up > self.boundary_threshold] = 1
+ boundary_targets_x2_up[
+ boundary_targets_x2_up <= self.boundary_threshold] = 0
+
+ boundary_targets_x4_up[
+ boundary_targets_x4_up > self.boundary_threshold] = 1
+ boundary_targets_x4_up[
+ boundary_targets_x4_up <= self.boundary_threshold] = 0
+
+ boudary_targets_pyramids = torch.stack(
+ (boundary_targets, boundary_targets_x2_up, boundary_targets_x4_up),
+ dim=1)
+
+ boudary_targets_pyramids = boudary_targets_pyramids.squeeze(2)
+ boudary_targets_pyramid = F.conv2d(boudary_targets_pyramids,
+ self.fusion_kernel)
+
+ boudary_targets_pyramid[
+ boudary_targets_pyramid > self.boundary_threshold] = 1
+ boudary_targets_pyramid[
+ boudary_targets_pyramid <= self.boundary_threshold] = 0
+
+ seg_logit = F.interpolate(
+ seg_logit,
+ boundary_targets.shape[2:],
+ mode='bilinear',
+ align_corners=True)
+ loss = super(STDCHead, self).losses(seg_logit,
+ boudary_targets_pyramid.long())
+ return loss
diff --git a/model-index.yml b/model-index.yml
index 6ff11b80a4..0c02909fad 100644
--- a/model-index.yml
+++ b/model-index.yml
@@ -32,6 +32,7 @@ Import:
- configs/segformer/segformer.yml
- configs/sem_fpn/sem_fpn.yml
- configs/setr/setr.yml
+- configs/stdc/stdc.yml
- configs/swin/swin.yml
- configs/twins/twins.yml
- configs/unet/unet.yml
diff --git a/tests/test_models/test_backbones/test_stdc.py b/tests/test_models/test_backbones/test_stdc.py
new file mode 100644
index 0000000000..1e3862b0b3
--- /dev/null
+++ b/tests/test_models/test_backbones/test_stdc.py
@@ -0,0 +1,131 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmseg.models.backbones import STDCContextPathNet
+from mmseg.models.backbones.stdc import (AttentionRefinementModule,
+ FeatureFusionModule, STDCModule,
+ STDCNet)
+
+
+def test_stdc_context_path_net():
+ # Test STDCContextPathNet Standard Forward
+ model = STDCContextPathNet(
+ backbone_cfg=dict(
+ type='STDCNet',
+ stdc_type='STDCNet1',
+ in_channels=3,
+ channels=(32, 64, 256, 512, 1024),
+ bottleneck_type='cat',
+ num_convs=4,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'),
+ with_final_conv=True),
+ last_in_channels=(1024, 512),
+ out_channels=128,
+ ffm_cfg=dict(in_channels=384, out_channels=256, scale_factor=4))
+ model.init_weights()
+ model.train()
+ batch_size = 2
+ imgs = torch.randn(batch_size, 3, 256, 512)
+ feat = model(imgs)
+
+ assert len(feat) == 4
+ # output for segment Head
+ assert feat[0].shape == torch.Size([batch_size, 256, 32, 64])
+ # for auxiliary head 1
+ assert feat[1].shape == torch.Size([batch_size, 128, 16, 32])
+ # for auxiliary head 2
+ assert feat[2].shape == torch.Size([batch_size, 128, 32, 64])
+ # for auxiliary head 3
+ assert feat[3].shape == torch.Size([batch_size, 256, 32, 64])
+
+ # Test input with rare shape
+ batch_size = 2
+ imgs = torch.randn(batch_size, 3, 527, 279)
+ model = STDCContextPathNet(
+ backbone_cfg=dict(
+ type='STDCNet',
+ stdc_type='STDCNet1',
+ in_channels=3,
+ channels=(32, 64, 256, 512, 1024),
+ bottleneck_type='add',
+ num_convs=4,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'),
+ with_final_conv=False),
+ last_in_channels=(1024, 512),
+ out_channels=128,
+ ffm_cfg=dict(in_channels=384, out_channels=256, scale_factor=4))
+ model.init_weights()
+ model.train()
+ feat = model(imgs)
+ assert len(feat) == 4
+
+
+def test_stdcnet():
+ with pytest.raises(AssertionError):
+ # STDC backbone constraints.
+ STDCNet(
+ stdc_type='STDCNet3',
+ in_channels=3,
+ channels=(32, 64, 256, 512, 1024),
+ bottleneck_type='cat',
+ num_convs=4,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'),
+ with_final_conv=False)
+
+ with pytest.raises(AssertionError):
+ # STDC bottleneck type constraints.
+ STDCNet(
+ stdc_type='STDCNet1',
+ in_channels=3,
+ channels=(32, 64, 256, 512, 1024),
+ bottleneck_type='dog',
+ num_convs=4,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'),
+ with_final_conv=False)
+
+ with pytest.raises(AssertionError):
+ # STDC channels length constraints.
+ STDCNet(
+ stdc_type='STDCNet1',
+ in_channels=3,
+ channels=(16, 32, 64, 256, 512, 1024),
+ bottleneck_type='cat',
+ num_convs=4,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='ReLU'),
+ with_final_conv=False)
+
+
+def test_feature_fusion_module():
+ x_ffm = FeatureFusionModule(in_channels=64, out_channels=32)
+ assert x_ffm.conv0.in_channels == 64
+ assert x_ffm.attention[1].in_channels == 32
+ assert x_ffm.attention[2].in_channels == 8
+ assert x_ffm.attention[2].out_channels == 32
+ x1 = torch.randn(2, 32, 32, 64)
+ x2 = torch.randn(2, 32, 32, 64)
+ x_out = x_ffm(x1, x2)
+ assert x_out.shape == torch.Size([2, 32, 32, 64])
+
+
+def test_attention_refinement_module():
+ x_arm = AttentionRefinementModule(128, 32)
+ assert x_arm.conv_layer.in_channels == 128
+ assert x_arm.atten_conv_layer[1].conv.out_channels == 32
+ x = torch.randn(2, 128, 32, 64)
+ x_out = x_arm(x)
+ assert x_out.shape == torch.Size([2, 32, 32, 64])
+
+
+def test_stdc_module():
+ x_stdc = STDCModule(in_channels=32, out_channels=32, stride=4)
+ assert x_stdc.layers[0].conv.in_channels == 32
+ assert x_stdc.layers[3].conv.out_channels == 4
+ x = torch.randn(2, 32, 32, 64)
+ x_out = x_stdc(x)
+ assert x_out.shape == torch.Size([2, 32, 32, 64])
diff --git a/tests/test_models/test_heads/test_stdc_head.py b/tests/test_models/test_heads/test_stdc_head.py
new file mode 100644
index 0000000000..1628209f36
--- /dev/null
+++ b/tests/test_models/test_heads/test_stdc_head.py
@@ -0,0 +1,31 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmseg.models.decode_heads import STDCHead
+from .utils import to_cuda
+
+
+def test_stdc_head():
+ inputs = [torch.randn(1, 32, 21, 21)]
+ head = STDCHead(
+ in_channels=32,
+ channels=8,
+ num_convs=1,
+ num_classes=2,
+ in_index=-1,
+ loss_decode=[
+ dict(
+ type='CrossEntropyLoss', loss_name='loss_ce', loss_weight=1.0),
+ dict(type='DiceLoss', loss_name='loss_dice', loss_weight=1.0)
+ ])
+ if torch.cuda.is_available():
+ head, inputs = to_cuda(head, inputs)
+ outputs = head(inputs)
+ assert isinstance(outputs, torch.Tensor) and len(outputs) == 1
+ assert outputs.shape == torch.Size([1, head.num_classes, 21, 21])
+
+ fake_label = torch.ones_like(
+ outputs[:, 0:1, :, :], dtype=torch.int16).long()
+ loss = head.losses(seg_logit=outputs, seg_label=fake_label)
+ assert loss['loss_ce'] != torch.zeros_like(loss['loss_ce'])
+ assert loss['loss_dice'] != torch.zeros_like(loss['loss_dice'])
diff --git a/tools/model_converters/stdc2mmseg.py b/tools/model_converters/stdc2mmseg.py
new file mode 100644
index 0000000000..9241f86a15
--- /dev/null
+++ b/tools/model_converters/stdc2mmseg.py
@@ -0,0 +1,71 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+
+import mmcv
+import torch
+from mmcv.runner import CheckpointLoader
+
+
+def convert_stdc(ckpt, stdc_type):
+ new_state_dict = {}
+ if stdc_type == 'STDC1':
+ stage_lst = ['0', '1', '2.0', '2.1', '3.0', '3.1', '4.0', '4.1']
+ else:
+ stage_lst = [
+ '0', '1', '2.0', '2.1', '2.2', '2.3', '3.0', '3.1', '3.2', '3.3',
+ '3.4', '4.0', '4.1', '4.2'
+ ]
+ for k, v in ckpt.items():
+ ori_k = k
+ flag = False
+ if 'cp.' in k:
+ k = k.replace('cp.', '')
+ if 'features.' in k:
+ num_layer = int(k.split('.')[1])
+ feature_key_lst = 'features.' + str(num_layer) + '.'
+ stages_key_lst = 'stages.' + stage_lst[num_layer] + '.'
+ k = k.replace(feature_key_lst, stages_key_lst)
+ flag = True
+ if 'conv_list' in k:
+ k = k.replace('conv_list', 'layers')
+ flag = True
+ if 'avd_layer.' in k:
+ if 'avd_layer.0' in k:
+ k = k.replace('avd_layer.0', 'downsample.conv')
+ elif 'avd_layer.1' in k:
+ k = k.replace('avd_layer.1', 'downsample.bn')
+ flag = True
+ if flag:
+ new_state_dict[k] = ckpt[ori_k]
+
+ return new_state_dict
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description='Convert keys in official pretrained STDC1/2 to '
+ 'MMSegmentation style.')
+ parser.add_argument('src', help='src model path')
+ # The dst path must be a full path of the new checkpoint.
+ parser.add_argument('dst', help='save path')
+ parser.add_argument('type', help='model type: STDC1 or STDC2')
+ args = parser.parse_args()
+
+ checkpoint = CheckpointLoader.load_checkpoint(args.src, map_location='cpu')
+ if 'state_dict' in checkpoint:
+ state_dict = checkpoint['state_dict']
+ elif 'model' in checkpoint:
+ state_dict = checkpoint['model']
+ else:
+ state_dict = checkpoint
+
+ assert args.type in ['STDC1',
+ 'STDC2'], 'STD type should be STDC1 or STDC2!'
+ weight = convert_stdc(state_dict, args.type)
+ mmcv.mkdir_or_exist(osp.dirname(args.dst))
+ torch.save(weight, args.dst)
+
+
+if __name__ == '__main__':
+ main()