diff --git a/.dev_scripts/github/update_model_index.py b/.dev_scripts/github/update_model_index.py
index b7ff4a4da2..3e673bdd2b 100755
--- a/.dev_scripts/github/update_model_index.py
+++ b/.dev_scripts/github/update_model_index.py
@@ -164,9 +164,11 @@ def parse_md(md_file):
i += 1
# parse table
- elif lines[i][0] == '|' and i + 1 < len(lines) and \
- (lines[i + 1][:3] == '| :' or lines[i + 1][:2] == '|:'
- or lines[i + 1][:2] == '|-'):
+ elif (lines[i][0] == '|') and (i + 1 < len(lines)) and (
+ lines[i + 1][:3] == '| :' or lines[i + 1][:2] == '|:'
+ or lines[i + 1][:2] == '|-') and (
+ 'SKIP THIS TABLE' not in lines[i - 2] # for aot-gan
+ ):
cols = [col.strip() for col in lines[i].split('|')][1:-1]
config_idx = cols.index('Method')
checkpoint_idx = cols.index('Download')
diff --git a/README.md b/README.md
index 768cd6785a..5d001f6fcb 100644
--- a/README.md
+++ b/README.md
@@ -127,6 +127,7 @@ Supported algorithms:
- [x] [DeepFillv1](configs/inpainting/deepfillv1/README.md) (CVPR'2018)
- [x] [PConv](configs/inpainting/partial_conv/README.md) (ECCV'2018)
- [x] [DeepFillv2](configs/inpainting/deepfillv2/README.md) (CVPR'2019)
+- [x] [AOT-GAN](configs/inpainting/AOT-GAN/README.md) (TVCG'2021)
diff --git a/README_zh-CN.md b/README_zh-CN.md
index 6173e67777..a2057ee419 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -125,6 +125,7 @@ pip3 install -e .
- [x] [DeepFillv1](configs/inpainting/deepfillv1/README.md) (CVPR'2018)
- [x] [PConv](configs/inpainting/partial_conv/README.md) (ECCV'2018)
- [x] [DeepFillv2](configs/inpainting/deepfillv2/README.md) (CVPR'2019)
+- [x] [AOT-GAN](configs/inpainting/AOT-GAN/README.md) (TVCG'2021)
diff --git a/configs/inpainting/AOT-GAN/AOT-GAN_512x512_4x12_places.py b/configs/inpainting/AOT-GAN/AOT-GAN_512x512_4x12_places.py
new file mode 100644
index 0000000000..9bac8319bf
--- /dev/null
+++ b/configs/inpainting/AOT-GAN/AOT-GAN_512x512_4x12_places.py
@@ -0,0 +1,187 @@
+model = dict(
+ type='AOTInpaintor',
+ encdec=dict(
+ type='AOTEncoderDecoder',
+ encoder=dict(type='AOTEncoder'),
+ decoder=dict(type='AOTDecoder'),
+ dilation_neck=dict(
+ type='AOTBlockNeck', dilation_rates=(1, 2, 4, 8), num_aotblock=8)),
+ disc=dict(
+ type='SoftMaskPatchDiscriminator',
+ in_channels=3,
+ base_channels=64,
+ num_conv=3,
+ with_spectral_norm=True,
+ ),
+ loss_gan=dict(
+ type='GANLoss',
+ gan_type='smgan',
+ loss_weight=0.01,
+ ),
+ loss_composed_percep=dict(
+ type='PerceptualLoss',
+ vgg_type='vgg19',
+ layer_weights={
+ '1': 1.,
+ '6': 1.,
+ '11': 1.,
+ '20': 1.,
+ '29': 1.,
+ },
+ layer_weights_style={
+ '8': 1.,
+ '17': 1.,
+ '26': 1.,
+ '31': 1.,
+ },
+ perceptual_weight=0.1,
+ style_weight=250),
+ loss_out_percep=True,
+ loss_l1_valid=dict(
+ type='L1Loss',
+ loss_weight=1.,
+ ),
+ pretrained=None)
+
+train_cfg = dict(disc_step=1)
+test_cfg = dict(metrics=['l1', 'psnr', 'ssim'])
+
+dataset_type = 'ImgInpaintingDataset'
+input_shape = (512, 512)
+
+mask_root = 'data/masks'
+
+train_pipeline = [
+ dict(type='LoadImageFromFile', key='gt_img', channel_order='rgb'),
+ dict(
+ type='LoadMask',
+ mask_mode='set',
+ mask_config=dict(
+ mask_list_file=f'{mask_root}/train_places_mask_list.txt',
+ prefix=mask_root,
+ io_backend='disk',
+ flag='unchanged',
+ file_client_kwargs=dict())),
+ dict(
+ type='RandomResizedCrop',
+ keys=['gt_img'],
+ crop_size=input_shape,
+ ),
+ dict(type='Flip', keys=['gt_img', 'mask'], direction='horizontal'),
+ dict(
+ type='Resize',
+ keys=['mask'],
+ scale=input_shape,
+ keep_ratio=False,
+ interpolation='nearest'),
+ dict(type='RandomRotation', keys=['mask'], degrees=(0.0, 45.0)),
+ dict(
+ type='ColorJitter',
+ keys=['gt_img'],
+ brightness=0.5,
+ contrast=0.5,
+ saturation=0.5,
+ hue=0.5),
+ dict(
+ type='Normalize',
+ keys=['gt_img'],
+ mean=[127.5] * 3,
+ std=[127.5] * 3,
+ to_rgb=False),
+ dict(type='GetMaskedImage'),
+ dict(
+ type='Collect',
+ keys=['gt_img', 'masked_img', 'mask'],
+ meta_keys=['gt_img_path']),
+ dict(type='ImageToTensor', keys=['gt_img', 'masked_img', 'mask'])
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', key='gt_img', channel_order='rgb'),
+ dict(
+ type='LoadMask',
+ mask_mode='set',
+ mask_config=dict(
+ mask_list_file=f'{mask_root}/mask_0.5-0.6_list.txt',
+ prefix=mask_root + '/mask_512',
+ io_backend='disk',
+ flag='unchanged',
+ file_client_kwargs=dict())),
+ dict(
+ type='RandomResizedCrop',
+ keys=['gt_img'],
+ crop_size=(512, 512),
+ ),
+ dict(
+ type='Normalize',
+ keys=['gt_img'],
+ mean=[127.5] * 3,
+ std=[127.5] * 3,
+ to_rgb=True),
+ dict(type='GetMaskedImage'),
+ dict(
+ type='Collect',
+ keys=['gt_img', 'masked_img', 'mask'],
+ meta_keys=['gt_img_path']),
+ dict(type='ImageToTensor', keys=['gt_img', 'masked_img', 'mask'])
+]
+
+data_root = 'data/places365'
+
+data = dict(
+ workers_per_gpu=4,
+ train_dataloader=dict(samples_per_gpu=12, drop_last=True),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/train_places_img_list.txt',
+ data_prefix=data_root,
+ pipeline=train_pipeline,
+ test_mode=False),
+ val=dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/val_places_img_list.txt',
+ data_prefix=data_root,
+ pipeline=test_pipeline,
+ test_mode=True),
+ test=dict(
+ type=dataset_type,
+ ann_file=(f'{data_root}/val_places_img_list.txt'),
+ data_prefix=data_root,
+ pipeline=test_pipeline,
+ test_mode=True))
+
+optimizers = dict(
+ generator=dict(type='Adam', lr=0.0001, betas=(0.0, 0.9)),
+ disc=dict(type='Adam', lr=0.0001, betas=(0.0, 0.9)))
+
+lr_config = dict(policy='Fixed', by_epoch=False)
+
+checkpoint_config = dict(by_epoch=False, interval=10000)
+log_config = dict(
+ interval=100,
+ hooks=[
+ dict(type='TextLoggerHook', by_epoch=False),
+ dict(type='TensorboardLoggerHook'),
+ dict(type='PaviLoggerHook', init_kwargs=dict(project='mmedit'))
+ ])
+
+visual_config = dict(
+ type='VisualizationHook',
+ output_dir='visual',
+ interval=1000,
+ res_name_list=['gt_img', 'masked_img', 'fake_res', 'fake_img'],
+)
+
+evaluation = dict(interval=50000)
+
+total_iters = 500002
+dist_params = dict(backend='nccl')
+log_level = 'INFO'
+work_dir = './workdirs/aotgan_places'
+load_from = None
+resume_from = None
+workflow = [('train', 10000)]
+exp_name = 'AOT-GAN_512x512_4x12_places'
+find_unused_parameters = False
diff --git a/configs/inpainting/AOT-GAN/README.md b/configs/inpainting/AOT-GAN/README.md
new file mode 100644
index 0000000000..88ca892694
--- /dev/null
+++ b/configs/inpainting/AOT-GAN/README.md
@@ -0,0 +1,62 @@
+# AOT-GAN (TVCG'2021)
+
+> [AOT-GAN: Aggregated Contextual Transformations for High-Resolution Image Inpainting](https://arxiv.org/pdf/2104.01431.pdf)
+
+
+
+## Abstract
+
+
+
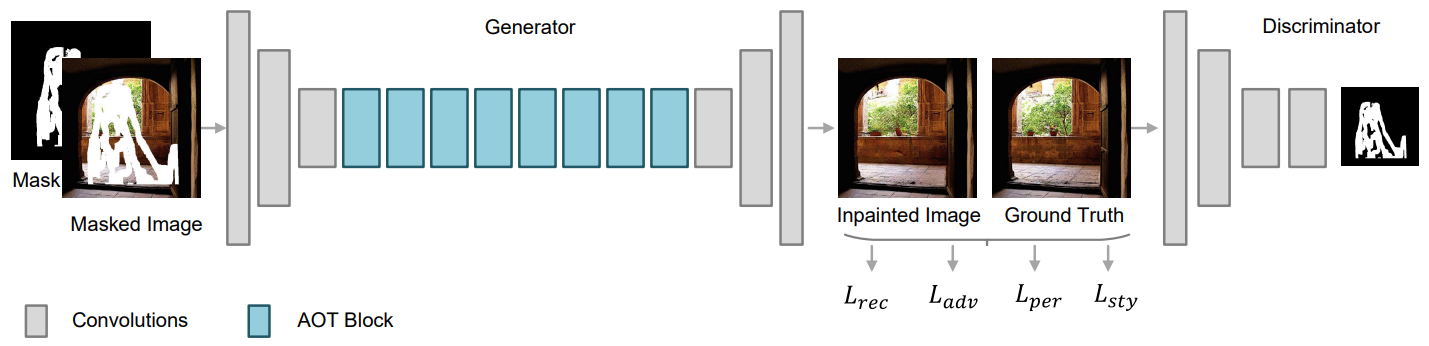
+State-of-the-art image inpainting approaches can suffer from generating distorted structures and blurry textures in high-resolution images (e.g., 512x512). The challenges mainly drive from (1) image content reasoning from distant contexts, and (2) fine-grained texture synthesis for a large missing region. To overcome these two challenges, we propose an enhanced GAN-based model, named Aggregated COntextual-Transformation GAN (AOT-GAN), for high-resolution image inpainting. Specifically, to enhance context reasoning, we construct the generator of AOT-GAN by stacking multiple layers of a proposed AOT block. The AOT blocks aggregate contextual transformations from various receptive fields, allowing to capture both informative distant image contexts and rich patterns of interest for context reasoning. For improving texture synthesis, we enhance the discriminator of AOT-GAN by training it with a tailored mask-prediction task. Such a training objective forces the discriminator to distinguish the detailed appearances of real and synthesized patches, and in turn, facilitates the generator to synthesize clear textures. Extensive comparisons on Places2, the most challenging benchmark with 1.8 million high-resolution images of 365 complex scenes, show that our model outperforms the state-of-the-art by a significant margin in terms of FID with 38.60% relative improvement. A user study including more than 30 subjects further validates the superiority of AOT-GAN. We further evaluate the proposed AOT-GAN in practical applications, e.g., logo removal, face editing, and object removal. Results show that our model achieves promising completions in the real world. We release code and models in [this https URL](https://github.com/researchmm/AOT-GAN-for-Inpainting).
+
+
+
+
+
+
+
+