 This is a guest post by James "SubStack" Halliday, originally posted on his blog, and reposted here with permission.
This is a guest post by James "SubStack" Halliday, originally posted on his blog, and reposted here with permission.
Writing applications as a sequence of tiny services that all talk to each other over the network has many upsides, but it can be annoyingly tedious to get all the subsystems up and running.
- -Running a seaport can help with getting all the services to talk to each other, but running the processes is another matter, especially when you have new code to push into production.
- -fleet aims to make it really easy for anyone on your team to push new code from git to an armada of servers and manage all the processes in your stack.
- -To start using fleet, just install the fleet command with npm:
- -npm install -g fleet- -
Then on one of your servers, start a fleet hub. From a fresh directory, give it a passphrase and a port to listen on:
- -fleet hub --port=7000 --secret=beepboop- -
Now fleet is listening on :7000 for commands and has started a git server on :7001 over http. There's no ssh keys or post commit hooks to configure, just run that command and you're ready to go!
- -Next set up some worker drones to run your processes. You can have as many workers as you like on a single server but each worker should be run from a separate directory. Just do:
- -fleet drone --hub=x.x.x.x:7000 --secret=beepboop- -
where x.x.x.x is the address where the fleet hub is running. Spin up a few of these drones.
- -Now navigate to the directory of the app you want to deploy. First set a remote so you don't need to type --hub and --secret all the time.
- -fleet remote add default --hub=x.x.x.x:7000 --secret=beepboop- -
Fleet just created a fleet.json file for you to save your settings.
- -From the same app directory, to deploy your code just do:
- -fleet deploy- -
The deploy command does a git push to the fleet hub's git http server and then the hub instructs all the drones to pull from it. Your code gets checked out into a new directory on all the fleet drones every time you deploy.
- -Because fleet is designed specifically for managing applications with lots of tiny services, the deploy command isn't tied to running any processes. Starting processes is up to the programmer but it's super simple. Just use the fleet spawn command:
- -fleet spawn -- node server.js 8080- -
By default fleet picks a drone at random to run the process on. You can specify which drone you want to run a particular process on with the --drone switch if it matters.
- -Start a few processes across all your worker drones and then show what is running with the fleet ps command:
- -fleet ps -drone#3dfe17b8 -├─┬ pid#1e99f4 -│ ├── status: running -│ ├── commit: webapp/1b8050fcaf8f1b02b9175fcb422644cb67dc8cc5 -│ └── command: node server.js 8888 -└─┬ pid#d7048a - ├── status: running - ├── commit: webapp/1b8050fcaf8f1b02b9175fcb422644cb67dc8cc5 - └── command: node server.js 8889- -
Now suppose that you have new code to push out into production. By default, fleet lets you spin up new services without disturbing your existing services. If you fleet deploy again after checking in some new changes to git, the next time you fleet spawn a new process, that process will be spun up in a completely new directory based on the git commit hash. To stop a process, just use fleet stop.
- -This approach lets you verify that the new services work before bringing down the old services. You can even start experimenting with heterogeneous and incremental deployment by hooking into a custom http proxy!
- -Even better, if you use a service registry like seaport for managing the host/port tables, you can spin up new ad-hoc staging clusters all the time without disrupting the normal operation of your site before rolling out new code to users.
- -Fleet has many more commands that you can learn about with its git-style manpage-based help system! Just do fleet help to get a list of all the commands you can run.
- -fleet help -Usage: fleet <command> [<args>] - -The commands are: - deploy Push code to drones. - drone Connect to a hub as a worker. - exec Run commands on drones. - hub Create a hub for drones to connect. - monitor Show service events system-wide. - ps List the running processes on the drones. - remote Manage the set of remote hubs. - spawn Run services on drones. - stop Stop processes running on drones. - -For help about a command, try `fleet help `.- -
npm install -g fleet and check out the code on github!
- - diff --git a/locale/fa/blog/module/service-logging-in-json-with-bunyan.md b/locale/fa/blog/module/service-logging-in-json-with-bunyan.md
deleted file mode 100644
index 4e2692e78f74..000000000000
--- a/locale/fa/blog/module/service-logging-in-json-with-bunyan.md
+++ /dev/null
@@ -1,340 +0,0 @@
----
-title: Service logging in JSON with Bunyan
-author: trentmick
-date: 2012-03-28T19:25:26.000Z
-status: publish
-category: module
-slug: service-logging-in-json-with-bunyan
-layout: blog-post.hbs
----
-
-
-
-
diff --git a/locale/fa/blog/module/service-logging-in-json-with-bunyan.md b/locale/fa/blog/module/service-logging-in-json-with-bunyan.md
deleted file mode 100644
index 4e2692e78f74..000000000000
--- a/locale/fa/blog/module/service-logging-in-json-with-bunyan.md
+++ /dev/null
@@ -1,340 +0,0 @@
----
-title: Service logging in JSON with Bunyan
-author: trentmick
-date: 2012-03-28T19:25:26.000Z
-status: publish
-category: module
-slug: service-logging-in-json-with-bunyan
-layout: blog-post.hbs
----
-
-
-
-
Service logs are gold, if you can mine them. We scan them for occasional debugging. Perhaps we grep them looking for errors or warnings, or setup an occasional nagios log regex monitor. If that. This is a waste of the best channel for data about a service.
- -"Log. (Huh) What is it good for. Absolutely ..."
- --
-
- debugging -
- monitors tools that alert operators -
- non real-time analysis (business or operational analysis) -
- historical analysis -
These are what logs are good for. The current state of logging is barely adequate for the first of these. Doing reliable analysis, and even monitoring, of varied "printf-style" logs is a grueling or hacky task that most either don't bother with, fallback to paying someone else to do (viz. Splunk's great successes), or, for web sites, punt and use the plethora of JavaScript-based web analytics tools.
- -Let's log in JSON. Let's format log records with a filter outside the app. Let's put more info in log records by not shoehorning into a printf-message. Debuggability can be improved. Monitoring and analysis can definitely be improved. Let's not write another regex-based parser, and use the time we've saved writing tools to collate logs from multiple nodes and services, to query structured logs (from all services, not just web servers), etc.
- -At Joyent we use node.js for running many core services -- loosely coupled through HTTP REST APIs and/or AMQP. In this post I'll draw on experiences from my work on Joyent's SmartDataCenter product and observations of Joyent Cloud operations to suggest some improvements to service logging. I'll show the (open source) Bunyan logging library and tool that we're developing to improve the logging toolchain.
- -Current State of Log Formatting
- -# apache access log
-10.0.1.22 - - [15/Oct/2010:11:46:46 -0700] "GET /favicon.ico HTTP/1.1" 404 209
-fe80::6233:4bff:fe29:3173 - - [15/Oct/2010:11:46:58 -0700] "GET / HTTP/1.1" 200 44
-
-# apache error log
-[Fri Oct 15 11:46:46 2010] [error] [client 10.0.1.22] File does not exist: /Library/WebServer/Documents/favicon.ico
-[Fri Oct 15 11:46:58 2010] [error] [client fe80::6233:4bff:fe29:3173] File does not exist: /Library/WebServer/Documents/favicon.ico
-
-# Mac /var/log/secure.log
-Oct 14 09:20:56 banana loginwindow[41]: in pam_sm_authenticate(): Failed to determine Kerberos principal name.
-Oct 14 12:32:20 banana com.apple.SecurityServer[25]: UID 501 authenticated as user trentm (UID 501) for right 'system.privilege.admin'
-
-# an internal joyent agent log
-[2012-02-07 00:37:11.898] [INFO] AMQPAgent - Publishing success.
-[2012-02-07 00:37:11.910] [DEBUG] AMQPAgent - { req_id: '8afb8d99-df8e-4724-8535-3d52adaebf25',
- timestamp: '2012-02-07T00:37:11.898Z',
-
-# typical expressjs log output
-[Mon, 21 Nov 2011 20:52:11 GMT] 200 GET /foo (1ms)
-Blah, some other unstructured output to from a console.log call.
-What're we doing here? Five logs at random. Five different date formats. As Paul Querna points out we haven't improved log parsability in 20 years. Parsability is enemy number one. You can't use your logs until you can parse the records, and faced with the above the inevitable solution is a one-off regular expression.
- -The current state of the art is various parsing libs, analysis tools and homebrew scripts ranging from grep to Perl, whose scope is limited to a few niches log formats.
- -JSON for Logs
- -JSON.parse() solves all that. Let's log in JSON. But it means a change in thinking: The first-level audience for log files shouldn't be a person, but a machine.
That is not said lightly. The "Unix Way" of small focused tools lightly coupled with text output is important. JSON is less "text-y" than, e.g., Apache common log format. JSON makes grep and awk awkward. Using less directly on a log is handy.
But not handy enough. That 80's pastel jumpsuit awkwardness you're feeling isn't the JSON, it's your tools. Time to find a json tool -- json is one, bunyan described below is another one. Time to learn your JSON library instead of your regex library: JavaScript, Python, Ruby, Java, Perl.
Time to burn your log4j Layout classes and move formatting to the tools side. Creating a log message with semantic information and throwing that away to make a string is silly. The win at being able to trivially parse log records is huge. The possibilities at being able to add ad hoc structured information to individual log records is interesting: think program state metrics, think feeding to Splunk, or loggly, think easy audit logs.
- -Introducing Bunyan
- -Bunyan is a node.js module for logging in JSON and a bunyan CLI tool to view those logs.
Logging with Bunyan basically looks like this:
- -$ cat hi.js
-var Logger = require('bunyan');
-var log = new Logger({name: 'hello' /*, ... */});
-log.info("hi %s", "paul");
-And you'll get a log record like this:
- -$ node hi.js
-{"name":"hello","hostname":"banana.local","pid":40026,"level":30,"msg":"hi paul","time":"2012-03-28T17:25:37.050Z","v":0}
-Pipe that through the bunyan tool that is part of the "node-bunyan" install to get more readable output:
$ node hi.js | ./node_modules/.bin/bunyan # formatted text output
-[2012-02-07T18:50:18.003Z] INFO: hello/40026 on banana.local: hi paul
-
-$ node hi.js | ./node_modules/.bin/bunyan -j # indented JSON output
-{
- "name": "hello",
- "hostname": "banana.local",
- "pid": 40087,
- "level": 30,
- "msg": "hi paul",
- "time": "2012-03-28T17:26:38.431Z",
- "v": 0
-}
-Bunyan is log4j-like: create a Logger with a name, call log.info(...), etc. However it has no intention of reproducing much of the functionality of log4j. IMO, much of that is overkill for the types of services you'll tend to be writing with node.js.
Longer Bunyan Example
- -Let's walk through a bigger example to show some interesting things in Bunyan. We'll create a very small "Hello API" server using the excellent restify library -- which we used heavily here at Joyent. (Bunyan doesn't require restify at all, you can easily use Bunyan with Express or whatever.)
- -You can follow along in https://github.com/trentm/hello-json-logging if you like. Note that I'm using the current HEAD of the bunyan and restify trees here, so details might change a bit. Prerequisite: a node 0.6.x installation.
- -git clone https://github.com/trentm/hello-json-logging.git
-cd hello-json-logging
-make
-Bunyan Logger
- -Our server first creates a Bunyan logger:
- -var Logger = require('bunyan');
-var log = new Logger({
- name: 'helloapi',
- streams: [
- {
- stream: process.stdout,
- level: 'debug'
- },
- {
- path: 'hello.log',
- level: 'trace'
- }
- ],
- serializers: {
- req: Logger.stdSerializers.req,
- res: restify.bunyan.serializers.response,
- },
-});
-Every Bunyan logger must have a name. Unlike log4j, this is not a hierarchical dotted namespace. It is just a name field for the log records.
- -Every Bunyan logger has one or more streams, to which log records are written. Here we've defined two: logging at DEBUG level and above is written to stdout, and logging at TRACE and above is appended to 'hello.log'.
- -Bunyan has the concept of serializers: a registry of functions that know how to convert a JavaScript object for a certain log record field to a nice JSON representation for logging. For example, here we register the Logger.stdSerializers.req function to convert HTTP Request objects (using the field name "req") to JSON. More on serializers later.
Restify Server
- -Restify 1.x and above has bunyan support baked in. You pass in your Bunyan logger like this:
- -var server = restify.createServer({
- name: 'Hello API',
- log: log // Pass our logger to restify.
-});
-Our simple API will have a single GET /hello?name=NAME endpoint:
server.get({path: '/hello', name: 'SayHello'}, function(req, res, next) {
- var caller = req.params.name || 'caller';
- req.log.debug('caller is "%s"', caller);
- res.send({"hello": caller});
- return next();
-});
-If we run that, node server.js, and call the endpoint, we get the expected restify response:
$ curl -iSs http://0.0.0.0:8080/hello?name=paul
-HTTP/1.1 200 OK
-Access-Control-Allow-Origin: *
-Access-Control-Allow-Headers: Accept, Accept-Version, Content-Length, Content-MD5, Content-Type, Date, X-Api-Version
-Access-Control-Expose-Headers: X-Api-Version, X-Request-Id, X-Response-Time
-Server: Hello API
-X-Request-Id: f6aaf942-c60d-4c72-8ddd-bada459db5e3
-Access-Control-Allow-Methods: GET
-Connection: close
-Content-Length: 16
-Content-MD5: Xmn3QcFXaIaKw9RPUARGBA==
-Content-Type: application/json
-Date: Tue, 07 Feb 2012 19:12:35 GMT
-X-Response-Time: 4
-
-{"hello":"paul"}
-Setup Server Logging
- -Let's add two things to our server. First, we'll use the server.pre to hook into restify's request handling before routing where we'll log the request.
server.pre(function (request, response, next) {
- request.log.info({req: request}, 'start'); // (1)
- return next();
-});
-This is the first time we've seen this log.info style with an object as the first argument. Bunyan logging methods (log.trace, log.debug, ...) all support an optional first object argument with extra log record fields:
log.info(<object> fields, <string> msg, ...)
-Here we pass in the restify Request object, req. The "req" serializer we registered above will come into play here, but bear with me.
Remember that we already had this debug log statement in our endpoint handler:
- -req.log.debug('caller is "%s"', caller); // (2)
-Second, use the restify server after event to log the response:
server.on('after', function (req, res, route) {
- req.log.info({res: res}, "finished"); // (3)
-});
-Log Output
- -Now lets see what log output we get when somebody hits our API's endpoint:
- -$ curl -iSs http://0.0.0.0:8080/hello?name=paul
-HTTP/1.1 200 OK
-...
-X-Request-Id: 9496dfdd-4ec7-4b59-aae7-3fed57aed5ba
-...
-
-{"hello":"paul"}
-Here is the server log:
- -[trentm@banana:~/tm/hello-json-logging]$ node server.js
-... intro "listening at" log message elided ...
-{"name":"helloapi","hostname":"banana.local","pid":40341,"level":30,"req":{"method":"GET","url":"/hello?name=paul","headers":{"user-agent":"curl/7.19.7 (universal-apple-darwin10.0) libcurl/7.19.7 OpenSSL/0.9.8r zlib/1.2.3","host":"0.0.0.0:8080","accept":"*/*"},"remoteAddress":"127.0.0.1","remotePort":59831},"msg":"start","time":"2012-03-28T17:37:29.506Z","v":0}
-{"name":"helloapi","hostname":"banana.local","pid":40341,"route":"SayHello","req_id":"9496dfdd-4ec7-4b59-aae7-3fed57aed5ba","level":20,"msg":"caller is \"paul\"","time":"2012-03-28T17:37:29.507Z","v":0}
-{"name":"helloapi","hostname":"banana.local","pid":40341,"route":"SayHello","req_id":"9496dfdd-4ec7-4b59-aae7-3fed57aed5ba","level":30,"res":{"statusCode":200,"headers":{"access-control-allow-origin":"*","access-control-allow-headers":"Accept, Accept-Version, Content-Length, Content-MD5, Content-Type, Date, X-Api-Version","access-control-expose-headers":"X-Api-Version, X-Request-Id, X-Response-Time","server":"Hello API","x-request-id":"9496dfdd-4ec7-4b59-aae7-3fed57aed5ba","access-control-allow-methods":"GET","connection":"close","content-length":16,"content-md5":"Xmn3QcFXaIaKw9RPUARGBA==","content-type":"application/json","date":"Wed, 28 Mar 2012 17:37:29 GMT","x-response-time":3}},"msg":"finished","time":"2012-03-28T17:37:29.510Z","v":0}
-Lets look at each in turn to see what is interesting -- pretty-printed with node server.js | ./node_modules/.bin/bunyan -j:
{ // (1)
- "name": "helloapi",
- "hostname": "banana.local",
- "pid": 40442,
- "level": 30,
- "req": {
- "method": "GET",
- "url": "/hello?name=paul",
- "headers": {
- "user-agent": "curl/7.19.7 (universal-apple-darwin10.0) libcurl/7.19.7 OpenSSL/0.9.8r zlib/1.2.3",
- "host": "0.0.0.0:8080",
- "accept": "*/*"
- },
- "remoteAddress": "127.0.0.1",
- "remotePort": 59834
- },
- "msg": "start",
- "time": "2012-03-28T17:39:44.880Z",
- "v": 0
-}
-Here we logged the incoming request with request.log.info({req: request}, 'start'). The use of the "req" field triggers the "req" serializer registered at Logger creation.
Next the req.log.debug in our handler:
{ // (2)
- "name": "helloapi",
- "hostname": "banana.local",
- "pid": 40442,
- "route": "SayHello",
- "req_id": "9496dfdd-4ec7-4b59-aae7-3fed57aed5ba",
- "level": 20,
- "msg": "caller is \"paul\"",
- "time": "2012-03-28T17:39:44.883Z",
- "v": 0
-}
-and the log of response in the "after" event:
- -{ // (3)
- "name": "helloapi",
- "hostname": "banana.local",
- "pid": 40442,
- "route": "SayHello",
- "req_id": "9496dfdd-4ec7-4b59-aae7-3fed57aed5ba",
- "level": 30,
- "res": {
- "statusCode": 200,
- "headers": {
- "access-control-allow-origin": "*",
- "access-control-allow-headers": "Accept, Accept-Version, Content-Length, Content-MD5, Content-Type, Date, X-Api-Version",
- "access-control-expose-headers": "X-Api-Version, X-Request-Id, X-Response-Time",
- "server": "Hello API",
- "x-request-id": "9496dfdd-4ec7-4b59-aae7-3fed57aed5ba",
- "access-control-allow-methods": "GET",
- "connection": "close",
- "content-length": 16,
- "content-md5": "Xmn3QcFXaIaKw9RPUARGBA==",
- "content-type": "application/json",
- "date": "Wed, 28 Mar 2012 17:39:44 GMT",
- "x-response-time": 5
- }
- },
- "msg": "finished",
- "time": "2012-03-28T17:39:44.886Z",
- "v": 0
-}
-Two useful details of note here:
- --
-
The last two log messages include a "req_id" field (added to the
- -req.loglogger by restify). Note that this is the same UUID as the "X-Request-Id" header in thecurlresponse. This means that if you usereq.logfor logging in your API handlers you will get an easy way to collate all logging for particular requests.If your's is an SOA system with many services, a best practice is to carry that X-Request-Id/req_id through your system to enable collating handling of a single top-level request.
-The last two log messages include a "route" field. This tells you to which handler restify routed the request. While possibly useful for debugging, this can be very helpful for log-based monitoring of endpoints on a server.
-
Recall that we also setup all logging to go the "hello.log" file. This was set at the TRACE level. Restify will log more detail of its operation at the trace level. See my "hello.log" for an example. The bunyan tool does a decent job of nicely formatting multiline messages and "req"/"res" keys (with color, not shown in the gist).
This is logging you can use effectively.
- -Other Tools
- -Bunyan is just one of many options for logging in node.js-land. Others (that I know of) supporting JSON logging are winston and logmagic. Paul Querna has an excellent post on using JSON for logging, which shows logmagic usage and also touches on topics like the GELF logging format, log transporting, indexing and searching.
- -Final Thoughts
- -Parsing challenges won't ever completely go away, but it can for your logs if you use JSON. Collating log records across logs from multiple nodes is facilitated by a common "time" field. Correlating logging across multiple services is enabled by carrying a common "req_id" (or equivalent) through all such logs.
- -Separate log files for a single service is an anti-pattern. The typical Apache example of separate access and error logs is legacy, not an example to follow. A JSON log provides the structure necessary for tooling to easily filter for log records of a particular type.
- -JSON logs bring possibilities. Feeding to tools like Splunk becomes easy. Ad hoc fields allow for a lightly spec'd comm channel from apps to other services: records with a "metric" could feed to statsd, records with a "loggly: true" could feed to loggly.com.
- -Here I've described a very simple example of restify and bunyan usage for node.js-based API services with easy JSON logging. Restify provides a powerful framework for robust API services. Bunyan provides a light API for nice JSON logging and the beginnings of tooling to help consume Bunyan JSON logs.
- -Update (29-Mar-2012): Fix styles somewhat for RSS readers.
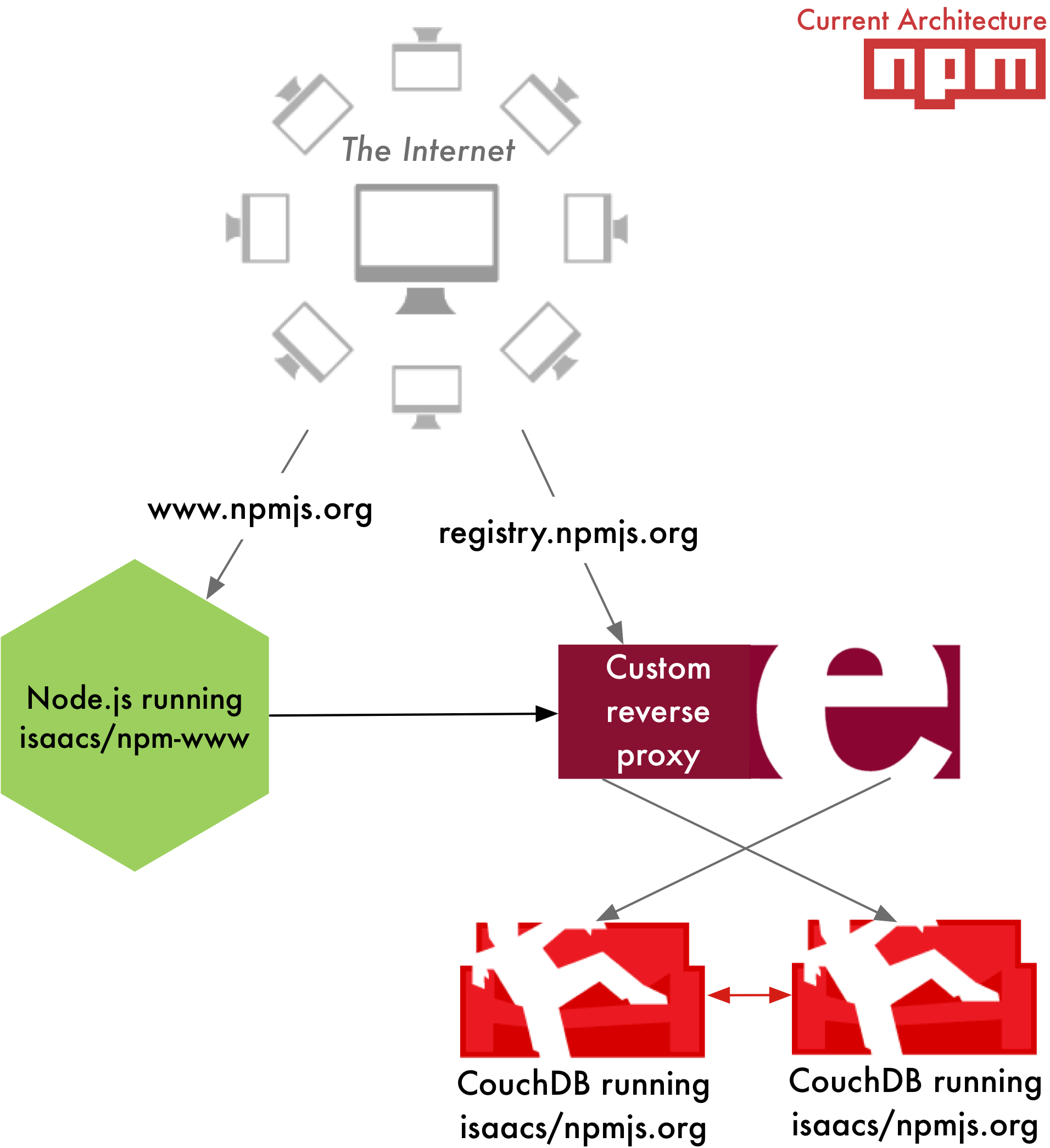
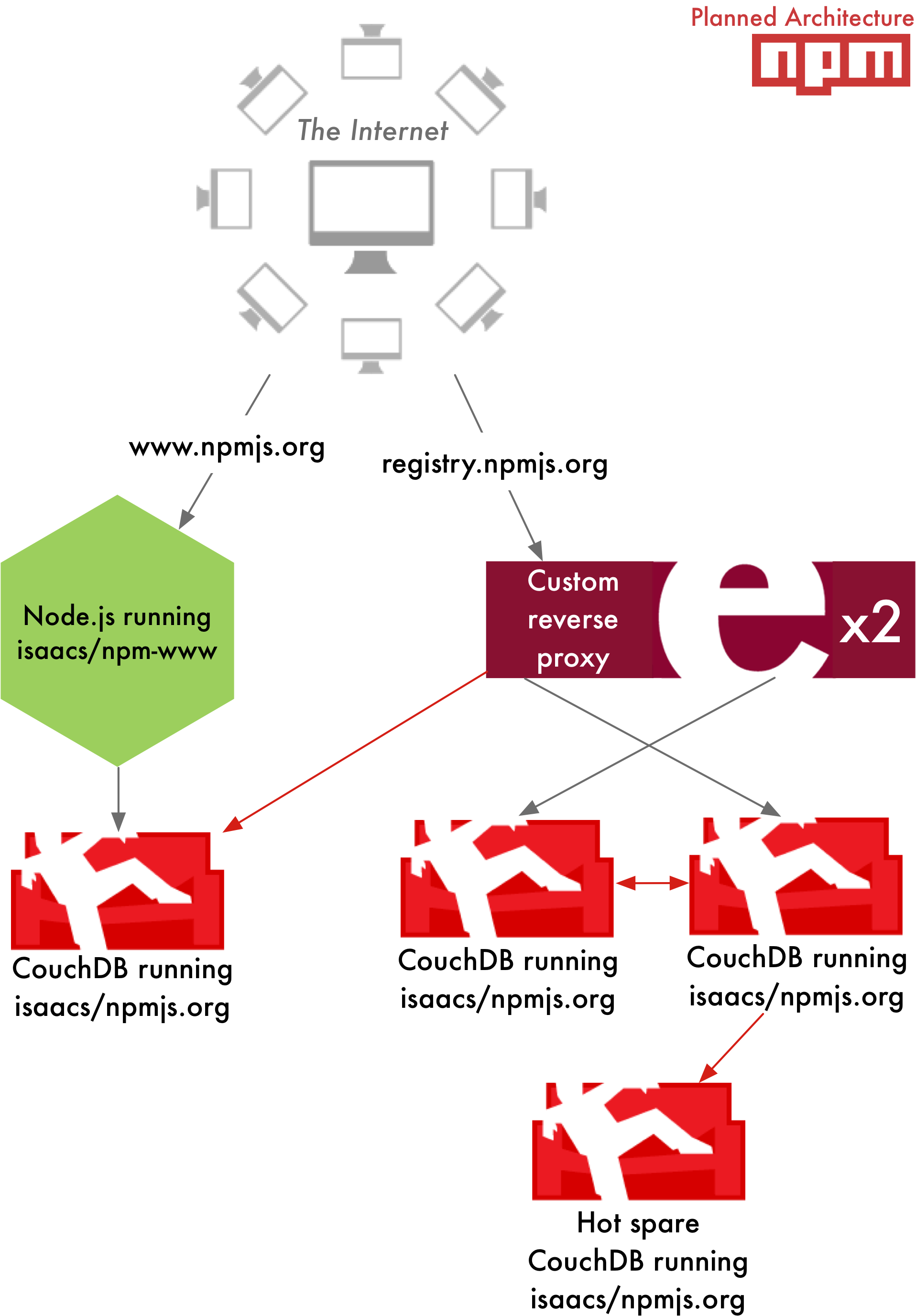
diff --git a/locale/fa/blog/npm/2013-outage-postmortem.md b/locale/fa/blog/npm/2013-outage-postmortem.md deleted file mode 100644 index 01c2cb5238d4..000000000000 --- a/locale/fa/blog/npm/2013-outage-postmortem.md +++ /dev/null @@ -1,86 +0,0 @@ ---- -date: 2013-11-26T15:14:59.000Z -author: Charlie Robbins -title: Keeping The npm Registry Awesome -slug: npm-post-mortem -category: npm -layout: blog-post.hbs ---- - -We know the availability and overall health of The npm Registry is paramount to everyone using Node.js as well as the larger JavaScript community and those of your using it for [some][browserify] [awesome][dotc] [projects][npm-rubygems] [and ideas][npm-python]. Between November 4th and November 15th 2013 The npm Registry had several hours of downtime over three distinct time periods: - -1. November 4th -- 16:30 to 15:00 UTC -2. November 13th -- 15:00 to 19:30 UTC -3. November 15th -- 15:30 to 18:00 UTC - -The root cause of these downtime was insufficient resources: both hardware and human. This is a full post-mortem where we will be look at how npmjs.org works, what went wrong, how we changed the previous architecture of The npm Registry to fix it, as well next steps we are taking to prevent this from happening again. - -All of the next steps require additional expenditure from Nodejitsu: both servers and labor. This is why along with this post-mortem we are announcing our [crowdfunding campaign: scalenpm.org](https://scalenpm.org)! Our goal is to raise enough funds so that Nodejitsu can continue to run The npm Registry as a free service for _you, the community._ - -Please take a minute now to donate at [https://scalenpm.org](https://scalenpm.org)! - -## How does npmjs.org work? - -There are two distinct components that make up npmjs.org operated by different people: - -* **http://registry.npmjs.org**: The main CouchApp (Github: [isaacs/npmjs.org](https://github.com/isaacs/npmjs.org)) that stores both package tarballs and metadata. It is operated by Nodejitsu since we [acquired IrisCouch in May](https://www.nodejitsu.com/company/press/2013/05/22/iriscouch/). The primary system administrator is [Jason Smith](https://github.com/jhs), the current CTO at Nodejitsu, cofounder of IrisCouch, and the System Administrator of registry.npmjs.org since 2011. -* **https://npmjs.com**: The npmjs website that you interact with using a web browser. It is a Node.js program (Github: [isaacs/npm-www](https://github.com/isaacs/npm-www)) maintained and operated by Isaac and running on a Joyent Public Cloud SmartMachine. - -Here is a high-level summary of the _old architecture:_ - -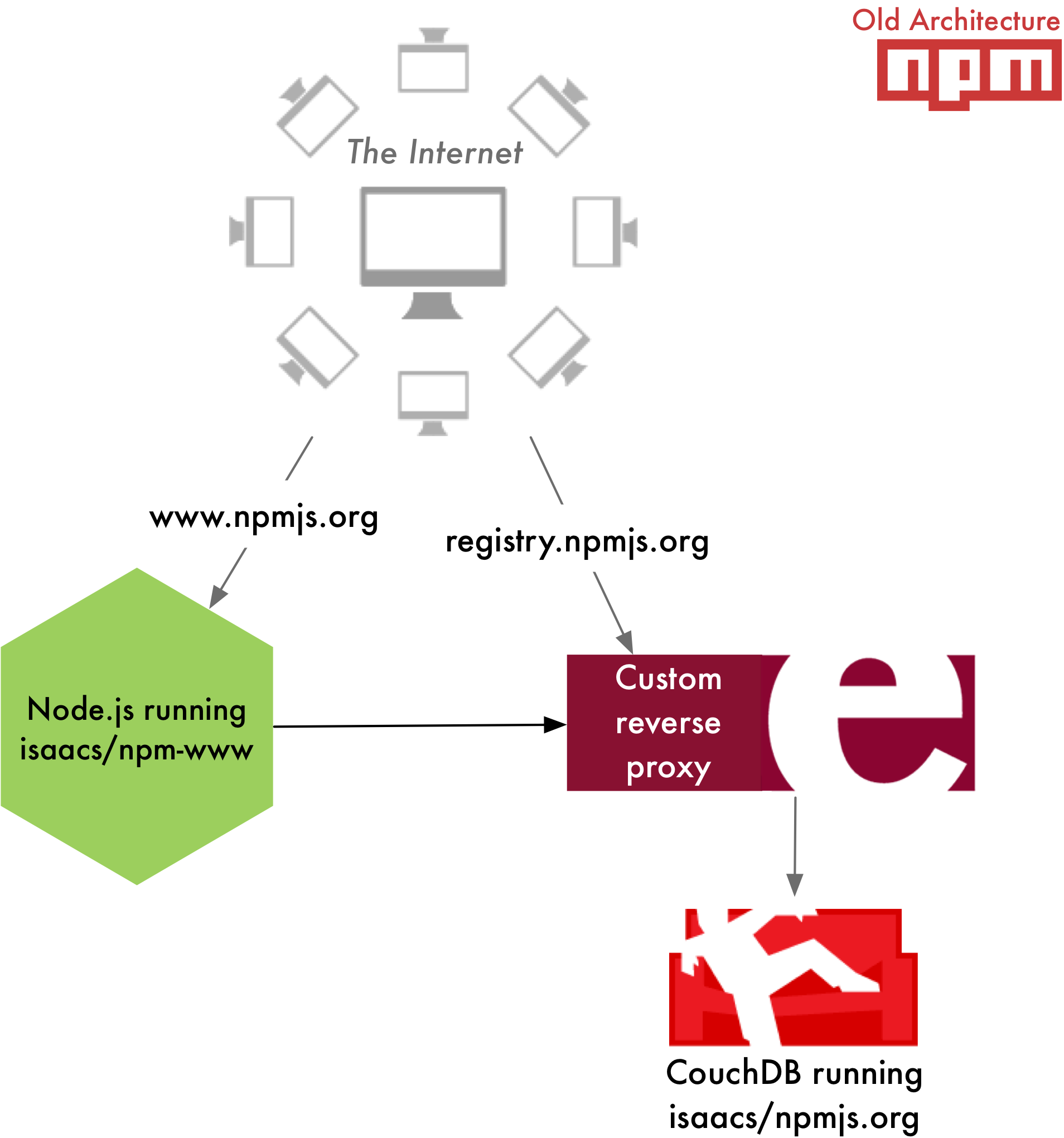 -
-  -
-  -
- 
-Photo by Luc Viatour (flickr)
Managing dependencies is a fundamental problem in building complex software. The terrific success of github and npm have made code reuse especially easy in the Node world, where packages don't exist in isolation but rather as nodes in a large graph. The software is constantly changing (releasing new versions), and each package has its own constraints about what other packages it requires to run (dependencies). npm keeps track of these constraints, and authors express what kind of changes are compatible using semantic versioning, allowing authors to specify that their package will work with even future versions of its dependencies as long as the semantic versions are assigned properly. - -
-This does mean that when you "npm install" a package with dependencies, there's no guarantee that you'll get the same set of code now that you would have gotten an hour ago, or that you would get if you were to run it again an hour later. You may get a bunch of bug fixes now that weren't available an hour ago. This is great during development, where you want to keep up with changes upstream. It's not necessarily what you want for deployment, though, where you want to validate whatever bits you're actually shipping. - -
-Put differently, it's understood that all software changes incur some risk, and it's critical to be able to manage this risk on your own terms. Taking that risk in development is good because by definition that's when you're incorporating and testing software changes. On the other hand, if you're shipping production software, you probably don't want to take this risk when cutting a release candidate (i.e. build time) or when you actually ship (i.e. deploy time) because you want to validate whatever you ship. - -
-You can address a simple case of this problem by only depending on specific versions of packages, allowing no semver flexibility at all, but this falls apart when you depend on packages that don't also adopt the same principle. Many of us at Joyent started wondering: can we generalize this approach? - -
-Shrinkwrapping packages
-That brings us to npm shrinkwrap[1]: - -
- -``` -NAME - npm-shrinkwrap -- Lock down dependency versions - -SYNOPSIS - npm shrinkwrap - -DESCRIPTION - This command locks down the versions of a package's dependencies so - that you can control exactly which versions of each dependency will - be used when your package is installed. -``` - -Let's consider package A: - -
-{
- "name": "A",
- "version": "0.1.0",
- "dependencies": {
- "B": "<0.1.0"
- }
-}package B: - -
-{
- "name": "B",
- "version": "0.0.1",
- "dependencies": {
- "C": "<0.1.0"
- }
-}and package C: - -
-{
- "name": "C,
- "version": "0.0.1"
-}If these are the only versions of A, B, and C available in the registry, then a normal "npm install A" will install: - -
-A@0.1.0
-└─┬ B@0.0.1
- └── C@0.0.1Then if B@0.0.2 is published, then a fresh "npm install A" will install: - -
-A@0.1.0
-└─┬ B@0.0.2
- └── C@0.0.1assuming the new version did not modify B's dependencies. Of course, the new version of B could include a new version of C and any number of new dependencies. As we said before, if A's author doesn't want that, she could specify a dependency on B@0.0.1. But if A's author and B's author are not the same person, there's no way for A's author to say that she does not want to pull in newly published versions of C when B hasn't changed at all. - -
-In this case, A's author can use - -
-# npm shrinkwrapThis generates npm-shrinkwrap.json, which will look something like this: - -
-{
- "name": "A",
- "dependencies": {
- "B": {
- "version": "0.0.1",
- "dependencies": {
- "C": { "version": "0.1.0" }
- }
- }
- }
-}The shrinkwrap command has locked down the dependencies based on what's currently installed in node_modules. When "npm install" installs a package with a npm-shrinkwrap.json file in the package root, the shrinkwrap file (rather than package.json files) completely drives the installation of that package and all of its dependencies (recursively). So now the author publishes A@0.1.0, and subsequent installs of this package will use B@0.0.1 and C@0.1.0, regardless the dependencies and versions listed in A's, B's, and C's package.json files. If the authors of B and C publish new versions, they won't be used to install A because the shrinkwrap refers to older versions. Even if you generate a new shrinkwrap, it will still reference the older versions, since "npm shrinkwrap" uses what's installed locally rather than what's available in the registry. - -
-Using shrinkwrapped packages
-Using a shrinkwrapped package is no different than using any other package: you can "npm install" it by hand, or add a dependency to your package.json file and "npm install" it. - -
-Building shrinkwrapped packages
-To shrinkwrap an existing package: - -
--
-
- Run "npm install" in the package root to install the current versions of all dependencies. -
- Validate that the package works as expected with these versions. -
- Run "npm shrinkwrap", add npm-shrinkwrap.json to git, and publish your package. -
To add or update a dependency in a shrinkwrapped package: - -
--
-
- Run "npm install" in the package root to install the current versions of all dependencies. -
- Add or update dependencies. "npm install" each new or updated package individually and then update package.json. -
- Validate that the package works as expected with the new dependencies. -
- Run "npm shrinkwrap", commit the new npm-shrinkwrap.json, and publish your package. -
You can still use npm outdated(1) to view which dependencies have newer versions available. - -
-For more details, check out the full docs on npm shrinkwrap, from which much of the above is taken. - -
-Why not just check node_modules into git?
-One previously proposed solution is to "npm install" your dependencies during development and commit the results into source control. Then you deploy your app from a specific git SHA knowing you've got exactly the same bits that you tested in development. This does address the problem, but it has its own issues: for one, binaries are tricky because you need to "npm install" them to get their sources, but this builds the [system-dependent] binary too. You can avoid checking in the binaries and use "npm rebuild" at build time, but we've had a lot of difficulty trying to do this.[2] At best, this is second-class treatment for binary modules, which are critical for many important types of Node applications.[3] - -
-Besides the issues with binary modules, this approach just felt wrong to many of us. There's a reason we don't check binaries into source control, and it's not just because they're platform-dependent. (After all, we could build and check in binaries for all supported platforms and operating systems.) It's because that approach is error-prone and redundant: error-prone because it introduces a new human failure mode where someone checks in a source change but doesn't regenerate all the binaries, and redundant because the binaries can always be built from the sources alone. An important principle of software version control is that you don't check in files derived directly from other files by a simple transformation.[4] Instead, you check in the original sources and automate the transformations via the build process. - -
-Dependencies are just like binaries in this regard: they're files derived from a simple transformation of something else that is (or could easily be) already available: the name and version of the dependency. Checking them in has all the same problems as checking in binaries: people could update package.json without updating the checked-in module (or vice versa). Besides that, adding new dependencies has to be done by hand, introducing more opportunities for error (checking in the wrong files, not checking in certain files, inadvertently changing files, and so on). Our feeling was: why check in this whole dependency tree (and create a mess for binary add-ons) when we could just check in the package name and version and have the build process do the rest? - -
-Finally, the approach of checking in node_modules doesn't really scale for us. We've got at least a dozen repos that will use restify, and it doesn't make sense to check that in everywhere when we could instead just specify which version each one is using. There's another principle at work here, which is separation of concerns: each repo specifies what it needs, while the build process figures out where to get it. - -
-What if an author republishes an existing version of a package?
-We're not suggesting deploying a shrinkwrapped package directly and running "npm install" to install from shrinkwrap in production. We already have a build process to deal with binary modules and other automateable tasks. That's where we do the "npm install". We tar up the result and distribute the tarball. Since we test each build before shipping, we won't deploy something we didn't test. - -
-It's still possible to pick up newly published versions of existing packages at build time. We assume force publish is not that common in the first place, let alone force publish that breaks compatibility. If you're worried about this, you can use git SHAs in the shrinkwrap or even consider maintaining a mirror of the part of the npm registry that you use and require human confirmation before mirroring unpublishes. - -
-Final thoughts
-Of course, the details of each use case matter a lot, and the world doesn't have to pick just one solution. If you like checking in node_modules, you should keep doing that. We've chosen the shrinkwrap route because that works better for us. - -
-It's not exactly news that Joyent is heavy on Node. Node is the heart of our SmartDataCenter (SDC) product, whose public-facing web portal, public API, Cloud Analytics, provisioning, billing, heartbeating, and other services are all implemented in Node. That's why it's so important to us to have robust components (like logging and REST) and tools for understanding production failures postmortem, profile Node apps in production, and now managing Node dependencies. Again, we're interested to hear feedback from others using these tools. - -
--Dave Pacheco blogs at dtrace.org. - -
[1] Much of this section is taken directly from the "npm shrinkwrap" documentation. - -
-[2] We've had a lot of trouble with checking in node_modules with binary dependencies. The first problem is figuring out exactly which files not to check in (.o, .node, .dynlib, .so, *.a, ...). When Mark went to apply this to one of our internal services, the "npm rebuild" step blew away half of the dependency tree because it ran "make clean", which in dependency ldapjs brings the repo to a clean slate by blowing away its dependencies. Later, a new (but highly experienced) engineer on our team was tasked with fixing a bug in our Node-based DHCP server. To fix the bug, we went with a new dependency. He tried checking in node_modules, which added 190,000 lines of code (to this repo that was previously a few hundred LOC). And despite doing everything he could think of to do this correctly and test it properly, the change broke the build because of the binary modules. So having tried this approach a few times now, it appears quite difficult to get right, and as I pointed out above, the lack of actual documentation and real world examples suggests others either aren't using binary modules (which we know isn't true) or haven't had much better luck with this approach. - -
-[3] Like a good Node-based distributed system, our architecture uses lots of small HTTP servers. Each of these serves a REST API using restify. restify uses the binary module node-dtrace-provider, which gives each of our services deep DTrace-based observability for free. So literally almost all of our components are or will soon be depending on a binary add-on. Additionally, the foundation of Cloud Analytics are a pair of binary modules that extract data from DTrace and kstat. So this isn't a corner case for us, and we don't believe we're exceptional in this regard. The popular hiredis package for interfacing with redis from Node is also a binary module. - -
-[4] Note that I said this is an important principle for software version control, not using git in general. People use git for lots of things where checking in binaries and other derived files is probably fine. Also, I'm not interested in proselytizing; if you want to do this for software version control too, go ahead. But don't do it out of ignorance of existing successful software engineering practices.
diff --git a/locale/fa/blog/npm/npm-1-0-global-vs-local-installation.md b/locale/fa/blog/npm/npm-1-0-global-vs-local-installation.md deleted file mode 100644 index 380eb5f48601..000000000000 --- a/locale/fa/blog/npm/npm-1-0-global-vs-local-installation.md +++ /dev/null @@ -1,67 +0,0 @@ ---- -title: "npm 1.0: Global vs Local installation" -author: Isaac Schlueter -date: 2011-03-24T06:07:13.000Z -status: publish -category: npm -slug: npm-1-0-global-vs-local-installation -layout: blog-post.hbs ---- - -npm 1.0 is in release candidate mode. Go get it!
- -More than anything else, the driving force behind the npm 1.0 rearchitecture was the desire to simplify what a package installation directory structure looks like.
- -In npm 0.x, there was a command called bundle that a lot of people liked. bundle let you install your dependencies locally in your project, but even still, it was basically a hack that never really worked very reliably.
Also, there was that activation/deactivation thing. That’s confusing.
- -Two paths
- -In npm 1.0, there are two ways to install things:
- -- globally —- This drops modules in
{prefix}/lib/node_modules, and puts executable files in{prefix}/bin, where{prefix}is usually something like/usr/local. It also installs man pages in{prefix}/share/man, if they’re supplied. - locally —- This installs your package in the current working directory. Node modules go in
./node_modules, executables go in./node_modules/.bin/, and man pages aren’t installed at all.
Which to choose
- -Whether to install a package globally or locally depends on the global config, which is aliased to the -g command line switch.
Just like how global variables are kind of gross, but also necessary in some cases, global packages are important, but best avoided if not needed.
- -In general, the rule of thumb is:
- -- If you’re installing something that you want to use in your program, using
require('whatever'), then install it locally, at the root of your project. - If you’re installing something that you want to use in your shell, on the command line or something, install it globally, so that its binaries end up in your
PATHenvironment variable.
When you can't choose
- -Of course, there are some cases where you want to do both. Coffee-script and Express both are good examples of apps that have a command line interface, as well as a library. In those cases, you can do one of the following:
- -- Install it in both places. Seriously, are you that short on disk space? It’s fine, really. They’re tiny JavaScript programs.
- Install it globally, and then
npm link coffee-scriptornpm link express(if you’re on a platform that supports symbolic links.) Then you only need to update the global copy to update all the symlinks as well.
The first option is the best in my opinion. Simple, clear, explicit. The second is really handy if you are going to re-use the same library in a bunch of different projects. (More on npm link in a future installment.)
You can probably think of other ways to do it by messing with environment variables. But I don’t recommend those ways. Go with the grain.
- -Slight exception: It’s not always the cwd.
- -Let’s say you do something like this:
- -cd ~/projects/foo # go into my project
-npm install express # ./node_modules/express
-cd lib/utils # move around in there
-vim some-thing.js # edit some stuff, work work work
-npm install redis # ./lib/utils/node_modules/redis!? ew.In this case, npm will install redis into ~/projects/foo/node_modules/redis. Sort of like how git will work anywhere within a git repository, npm will work anywhere within a package, defined by having a node_modules folder.
Test runners and stuff
- -If your package's scripts.test command uses a command-line program installed by one of your dependencies, not to worry. npm makes ./node_modules/.bin the first entry in the PATH environment variable when running any lifecycle scripts, so this will work fine, even if your program is not globally installed:
-
-
{ "name" : "my-program"
-, "version" : "1.2.3"
-, "dependencies": { "express": "*", "coffee-script": "*" }
-, "devDependencies": { "vows": "*" }
-, "scripts":
- { "test": "vows test/*.js"
- , "preinstall": "cake build" } }npm 1.0 is in release candidate mode. Go get it!
- -In npm 0.x, there was a command called link. With it, you could “link-install” a package so that changes would be reflected in real-time. This is especially handy when you’re actually building something. You could make a few changes, run the command again, and voila, your new code would be run without having to re-install every time.
Of course, compiled modules still have to be rebuilt. That’s not ideal, but it’s a problem that will take more powerful magic to solve.
- -In npm 0.x, this was a pretty awful kludge. Back then, every package existed in some folder like:
- -prefix/lib/node/.npm/my-package/1.3.6/package
-and the package’s version and name could be inferred from the path. Then, symbolic links were set up that looked like:
- -prefix/lib/node/my-package@1.3.6 -> ./.npm/my-package/1.3.6/package
-It was easy enough to point that symlink to a different location. However, since the package.json file could change, that meant that the connection between the version and the folder was not reliable.
- -At first, this was just sort of something that we dealt with by saying, “Relink if you change the version.” However, as more and more edge cases arose, eventually the solution was to give link packages this fakey version of “9999.0.0-LINK-hash” so that npm knew it was an impostor. Sometimes the package was treated as if it had the 9999.0.0 version, and other times it was treated as if it had the version specified in the package.json.
- -A better way
- -For npm 1.0, we backed up and looked at what the actual use cases were. Most of the time when you link something you want one of the following:
- --
-
- globally install this package I’m working on so that I can run the command it creates and test its stuff as I work on it. -
- locally install my thing into some other thing that depends on it, so that the other thing can
require()it.
-
And, in both cases, changes should be immediately apparent and not require any re-linking.
- -Also, there’s a third use case that I didn’t really appreciate until I started writing more programs that had more dependencies:
- -Globally install something, and use it in development in a bunch of projects, and then update them all at once so that they all use the latest version.
Really, the second case above is a special-case of this third case.
- -Link devel → global
- -The first step is to link your local project into the global install space. (See global vs local installation for more on this global/local business.)
- -I do this as I’m developing node projects (including npm itself).
- -cd ~/dev/js/node-tap # go into the project dir
-npm link # create symlinks into {prefix}
-Because of how I have my computer set up, with /usr/local as my install prefix, I end up with a symlink from /usr/local/lib/node_modules/tap pointing to ~/dev/js/node-tap, and the executable linked to /usr/local/bin/tap.
Of course, if you set your paths differently, then you’ll have different results. (That’s why I tend to talk in terms of prefix rather than /usr/local.)
Link global → local
- -When you want to link the globally-installed package into your local development folder, you run npm link pkg where pkg is the name of the package that you want to install.
For example, let’s say that I wanted to write some tap tests for my node-glob package. I’d first do the steps above to link tap into the global install space, and then I’d do this:
- -cd ~/dev/js/node-glob # go to the project that uses the thing.
-npm link tap # link the global thing into my project.
-Now when I make changes in ~/dev/js/node-tap, they’ll be immediately reflected in ~/dev/js/node-glob/node_modules/tap.
Link to stuff you don’t build
- -Let’s say I have 15 sites that all use express. I want the benefits of local development, but I also want to be able to update all my dev folders at once. You can globally install express, and then link it into your local development folder.
- -npm install express -g # install express globally
-cd ~/dev/js/my-blog # development folder one
-npm link express # link the global express into ./node_modules
-cd ~/dev/js/photo-site # other project folder
-npm link express # link express into here, as well
-
- # time passes
- # TJ releases some new stuff.
- # you want this new stuff.
-
-npm update express -g # update the global install.
- # this also updates my project folders.
-Caveat: Not For Real Servers
- -npm link is a development tool. It’s awesome for managing packages on your local development box. But deploying with npm link is basically asking for problems, since it makes it super easy to update things without realizing it.
- -Caveat 2: Sorry, Windows!
- -I highly doubt that a native Windows node will ever have comparable symbolic link support to what Unix systems provide. I know that there are junctions and such, and I've heard legends about symbolic links on Windows 7.
- -When there is a native windows port of Node, if that native windows port has `fs.symlink` and `fs.readlink` support that is exactly identical to the way that they work on Unix, then this should work fine.
- -But I wouldn't hold my breath. Any bugs about this not working on a native Windows system (ie, not Cygwin) will most likely be closed with wontfix.
Aside: Credit where Credit’s Due
- -Back before the Great Package Management Wars of Node 0.1, before npm or kiwi or mode or seed.js could do much of anything, and certainly before any of them had more than 2 users, Mikeal Rogers invited me to the Couch.io offices for lunch to talk about this npm registry thingie I’d mentioned wanting to build. (That is, to convince me to use CouchDB for it.)
- -Since he was volunteering to build the first version of it, and since couch is pretty much the ideal candidate for this use-case, it was an easy sell.
- -While I was there, he said, “Look. You need to be able to link a project directory as if it was installed as a package, and then have it all Just Work. Can you do that?”
- -I was like, “Well, I don’t know… I mean, there’s these edge cases, and it doesn’t really fit with the existing folder structure very well…”
- -“Dude. Either you do it, or I’m going to have to do it, and then there’ll be another package manager in node, instead of writing a registry for npm, and it won’t be as good anyway. Don’t be python.”
- -The rest is history.
diff --git a/locale/fa/blog/npm/npm-1-0-released.md b/locale/fa/blog/npm/npm-1-0-released.md deleted file mode 100644 index abc105708d44..000000000000 --- a/locale/fa/blog/npm/npm-1-0-released.md +++ /dev/null @@ -1,39 +0,0 @@ ---- -title: "npm 1.0: Released" -author: Isaac Schlueter -date: 2011-05-01T15:09:45.000Z -status: publish -category: npm -slug: npm-1-0-released -layout: blog-post.hbs ---- - -npm 1.0 has been released. Here are the highlights:
- -- Global vs local installation
- ls displays a tree, instead of being a remote search
- No more “activation” concept - dependencies are nested
- Updates to link command
- Install script cleans up any 0.x cruft it finds. (That is, it removes old packages, so that they can be installed properly.)
- Simplified “search” command. One line per package, rather than one line per version.
- Renovated “completion” approach
- More help topics
- Simplified folder structure
The focus is on npm being a development tool, rather than an apt-wannabe.
- -Installing it
- -To get the new version, run this command:
- -curl https://npmjs.com/install.sh | sh This will prompt to ask you if it’s ok to remove all the old 0.x cruft. If you want to not be asked, then do this:
- -curl https://npmjs.com/install.sh | clean=yes sh Or, if you want to not do the cleanup, and leave the old stuff behind, then do this:
- -curl https://npmjs.com/install.sh | clean=no sh A lot of people in the node community were brave testers and helped make this release a lot better (and swifter) than it would have otherwise been. Thanks :)
- -Code Freeze
- -npm will not have any major feature enhancements or architectural changes for at least 6 months. There are interesting developments planned that leverage npm in some ways, but it’s time to let the client itself settle. Also, I want to focus attention on some other problems for a little while.
- -Of course, bug reports are always welcome.
- -See you at NodeConf!
diff --git a/locale/fa/blog/npm/npm-1-0-the-new-ls.md b/locale/fa/blog/npm/npm-1-0-the-new-ls.md deleted file mode 100644 index b2b72067e91f..000000000000 --- a/locale/fa/blog/npm/npm-1-0-the-new-ls.md +++ /dev/null @@ -1,147 +0,0 @@ ---- -title: "npm 1.0: The New 'ls'" -author: Isaac Schlueter -date: 2011-03-18T06:22:17.000Z -status: publish -category: npm -slug: npm-1-0-the-new-ls -layout: blog-post.hbs ---- - -This is the first in a series of hopefully more than 1 posts, each detailing some aspect of npm 1.0.
- -In npm 0.x, the ls command was a combination of both searching the registry as well as reporting on what you have installed.
As the registry has grown in size, this has gotten unwieldy. Also, since npm 1.0 manages dependencies differently, nesting them in node_modules folder and installing locally by default, there are different things that you want to view.
The functionality of the ls command was split into two different parts. search is now the way to find things on the registry (and it only reports one line per package, instead of one line per version), and ls shows a tree view of the packages that are installed locally.
Here’s an example of the output:
- -$ npm ls
-npm@1.0.0 /Users/isaacs/dev-src/js/npm
-├── semver@1.0.1
-├─┬ ronn@0.3.5
-│ └── opts@1.2.1
-└─┬ express@2.0.0rc3 extraneous
- ├─┬ connect@1.1.0
- │ ├── qs@0.0.7
- │ └── mime@1.2.1
- ├── mime@1.2.1
- └── qs@0.0.7
-This is after I’ve done npm install semver ronn express in the npm source directory. Since express isn’t actually a dependency of npm, it shows up with that “extraneous” marker.
Let’s see what happens when we create a broken situation:
- -$ rm -rf ./node_modules/express/node_modules/connect
-$ npm ls
-npm@1.0.0 /Users/isaacs/dev-src/js/npm
-├── semver@1.0.1
-├─┬ ronn@0.3.5
-│ └── opts@1.2.1
-└─┬ express@2.0.0rc3 extraneous
- ├── UNMET DEPENDENCY connect >= 1.1.0 < 2.0.0
- ├── mime@1.2.1
- └── qs@0.0.7
-Tree views are great for human readability, but some times you want to pipe that stuff to another program. For that output, I took the same datastructure, but instead of building up a treeview string for each line, it spits out just the folders like this:
- -$ npm ls -p
-/Users/isaacs/dev-src/js/npm
-/Users/isaacs/dev-src/js/npm/node_modules/semver
-/Users/isaacs/dev-src/js/npm/node_modules/ronn
-/Users/isaacs/dev-src/js/npm/node_modules/ronn/node_modules/opts
-/Users/isaacs/dev-src/js/npm/node_modules/express
-/Users/isaacs/dev-src/js/npm/node_modules/express/node_modules/connect
-/Users/isaacs/dev-src/js/npm/node_modules/express/node_modules/connect/node_modules/qs
-/Users/isaacs/dev-src/js/npm/node_modules/express/node_modules/connect/node_modules/mime
-/Users/isaacs/dev-src/js/npm/node_modules/express/node_modules/mime
-/Users/isaacs/dev-src/js/npm/node_modules/express/node_modules/qs
-Since you sometimes want a bigger view, I added the --long option to (shorthand: -l) to spit out more info:
$ npm ls -l
-npm@1.0.0
-│ /Users/isaacs/dev-src/js/npm
-│ A package manager for node
-│ git://github.com/isaacs/npm.git
-│ https://npmjs.com/
-├── semver@1.0.1
-│ ./node_modules/semver
-│ The semantic version parser used by npm.
-│ git://github.com/isaacs/node-semver.git
-├─┬ ronn@0.3.5
-│ │ ./node_modules/ronn
-│ │ markdown to roff and html converter
-│ └── opts@1.2.1
-│ ./node_modules/ronn/node_modules/opts
-│ Command line argument parser written in the style of commonjs. To be used with node.js
-└─┬ express@2.0.0rc3 extraneous
- │ ./node_modules/express
- │ Sinatra inspired web development framework
- ├─┬ connect@1.1.0
- │ │ ./node_modules/express/node_modules/connect
- │ │ High performance middleware framework
- │ │ git://github.com/senchalabs/connect.git
- │ ├── qs@0.0.7
- │ │ ./node_modules/express/node_modules/connect/node_modules/qs
- │ │ querystring parser
- │ └── mime@1.2.1
- │ ./node_modules/express/node_modules/connect/node_modules/mime
- │ A comprehensive library for mime-type mapping
- ├── mime@1.2.1
- │ ./node_modules/express/node_modules/mime
- │ A comprehensive library for mime-type mapping
- └── qs@0.0.7
- ./node_modules/express/node_modules/qs
- querystring parser
-
-$ npm ls -lp
-/Users/isaacs/dev-src/js/npm:npm@1.0.0::::
-/Users/isaacs/dev-src/js/npm/node_modules/semver:semver@1.0.1::::
-/Users/isaacs/dev-src/js/npm/node_modules/ronn:ronn@0.3.5::::
-/Users/isaacs/dev-src/js/npm/node_modules/ronn/node_modules/opts:opts@1.2.1::::
-/Users/isaacs/dev-src/js/npm/node_modules/express:express@2.0.0rc3:EXTRANEOUS:::
-/Users/isaacs/dev-src/js/npm/node_modules/express/node_modules/connect:connect@1.1.0::::
-/Users/isaacs/dev-src/js/npm/node_modules/express/node_modules/connect/node_modules/qs:qs@0.0.7::::
-/Users/isaacs/dev-src/js/npm/node_modules/express/node_modules/connect/node_modules/mime:mime@1.2.1::::
-/Users/isaacs/dev-src/js/npm/node_modules/express/node_modules/mime:mime@1.2.1::::
-/Users/isaacs/dev-src/js/npm/node_modules/express/node_modules/qs:qs@0.0.7::::
-And, if you want to get at the globally-installed modules, you can use ls with the global flag:
- -$ npm ls -g
-/usr/local
-├─┬ A@1.2.3 -> /Users/isaacs/dev-src/js/A
-│ ├── B@1.2.3 -> /Users/isaacs/dev-src/js/B
-│ └─┬ npm@0.3.15
-│ └── semver@1.0.1
-├─┬ B@1.2.3 -> /Users/isaacs/dev-src/js/B
-│ └── A@1.2.3 -> /Users/isaacs/dev-src/js/A
-├── glob@2.0.5
-├─┬ npm@1.0.0 -> /Users/isaacs/dev-src/js/npm
-│ ├── semver@1.0.1
-│ └─┬ ronn@0.3.5
-│ └── opts@1.2.1
-└── supervisor@0.1.2 -> /Users/isaacs/dev-src/js/node-supervisor
-
-$ npm ls -gpl
-/usr/local:::::
-/usr/local/lib/node_modules/A:A@1.2.3::::/Users/isaacs/dev-src/js/A
-/usr/local/lib/node_modules/A/node_modules/npm:npm@0.3.15::::/Users/isaacs/dev-src/js/A/node_modules/npm
-/usr/local/lib/node_modules/A/node_modules/npm/node_modules/semver:semver@1.0.1::::/Users/isaacs/dev-src/js/A/node_modules/npm/node_modules/semver
-/usr/local/lib/node_modules/B:B@1.2.3::::/Users/isaacs/dev-src/js/B
-/usr/local/lib/node_modules/glob:glob@2.0.5::::
-/usr/local/lib/node_modules/npm:npm@1.0.0::::/Users/isaacs/dev-src/js/npm
-/usr/local/lib/node_modules/npm/node_modules/semver:semver@1.0.1::::/Users/isaacs/dev-src/js/npm/node_modules/semver
-/usr/local/lib/node_modules/npm/node_modules/ronn:ronn@0.3.5::::/Users/isaacs/dev-src/js/npm/node_modules/ronn
-/usr/local/lib/node_modules/npm/node_modules/ronn/node_modules/opts:opts@1.2.1::::/Users/isaacs/dev-src/js/npm/node_modules/ronn/node_modules/opts
-/usr/local/lib/node_modules/supervisor:supervisor@0.1.2::::/Users/isaacs/dev-src/js/node-supervisor
-Those -> flags are indications that the package is link-installed, which will be covered in the next installment.