Implement copy-on-write for all backends #157
Comments
|
Still stuck on assignment overloading: nim-lang/Nim#6348 and nim-lang/Nim#6786 |
|
Outcome of my research. A tentative copy-on-write object to be used in a single-threaded context or a master thread + slave thread managed by OpenMP that only works on already allocated memory: Forum thread. {.experimental.}
type
Storage[T] = ref object
refcount: int
data: seq[T]
# lock / guard ?
type COWobject[T] = object
metadata: int
storage: Storage[T]
proc detach[T](c: var COWobject[T]) =
# Note: this only works without races if only the main thread can access this.
# Also increment is only done on assignment, slices do not increment.
if c.storage.refcount == 1:
return
let old_store = c.storage
var fresh_store: Storage[T]
new fresh_store
fresh_store.refcount = 1
deepCopy(fresh_store.data, old_store.data)
c.storage = fresh_store
dec old_store.refcount
proc `=`[T](dst: var CowObject[T]; src: CowObject[T]) =
inc src.storage.refcount
system.`=`(dst, src)
proc `=destroy`[T](c: CowObject[T]) =
# Note from Nim manual: destructors are tied to a variable
# And will not trigger for say slices.
dec c.storage.refcount
proc toCowObj[T](s: varargs[T]): COWobject[T] {.noInit.} =
result.metadata = 1337
new result.storage
result.storage.data = @s
proc `[]`[T](c: COWobject[T], idx: int): T =
c.storage.data[idx]
proc `[]`[T](c: var COWobject[T], idx: int): var T =
detach c
c.storage.data[idx]
proc `[]=`[T](c: var COWobject[T], idx: int, val: T) =
detach c
c.storage.data[idx] = val
proc main() =
let a = toCowObj(1, 2, 3, 4, 5)
let b = a
var c = a
let d = c
var e = c
let f = e
let g = f
c[1] += 10
e[2] = 100
echo "\n\nMemory location"
echo "a: [1, 2, 3, 4, 5]: " & $a.repr
echo "b: [1, 2, 3, 4, 5]: " & $b.repr
echo "c: [1, 12, 3, 4, 5]: " & $c.repr
echo "d: [1, 2, 3, 4, 5]: " & $d.repr
echo "e: [1, 2, 100, 4, 5]: " & $e.repr
echo "f: [1, 2, 3, 4, 5]: " & $f.repr
echo "g: [1, 2, 3, 4, 5]: " & $g.repr
echo "\n\n"
echo "a: [1, 2, 3, 4, 5]: " & $a
echo "b: [1, 2, 3, 4, 5]: " & $b
echo "c: [1, 12, 3, 4, 5]: " & $c
echo "d: [1, 2, 3, 4, 5]: " & $d
echo "e: [1, 2, 100, 4, 5]: " & $e
echo "f: [1, 2, 3, 4, 5]: " & $f
echo "g: [1, 2, 3, 4, 5]: " & $g
main()Concurrent thread-safe versionCurrently there is no plan to make that thread-safe with different Tensors in different thread sharing the same memory. First of all Nim In case this is needed is the future, here is some research around copy-on-write, concurrency, lock, lock-free or wait-free data structure NimNim offers several intrinsics by default:
Undocumented intrinsics in atomics.nim The locks module, with a very nice "withLock" template. And several lock examples in the manual Warnings - lock-free is not the solution to everything
Benchmarks
Reference-counting
AtomicsR/W lock (many readers or one writer)Read-copy-update (RCU)
Copy on write
Software Transactional Memory |
|
WIP in #159 Further research
|
|
After tinkering for a few hours, I have definite proof that copy-on-write does not work cleanly for a neural net library so I will use reference semantics by default and require cloning for deep copies.
Last things
Edit: summary I did for Nim forum
import ../src/arraymancer, sequtils
let ctx = newContext Tensor[int] # Context that will track operations applied on the tensor to compute gradient in the future
let W = ctx.variable toSeq(1..8).toTensor.reshape(2,4) # What is the refcount? --> it's 0
let x = toSeq(11..22).toTensor.reshape(4,3)
let X = ctx.variable x # What is the refcount? it's 1 until x goes out of scopeThe refcount and logic required becomes hard to follow and will probably lead to an overengineered solution (or test suite).
let foo = toCowObj(1, 2, 3, 4, 5)
var bar: CowObject[int]
system.`=`(bar, foo) |
|
Closed by #160 |
While I love value semantics and still thinks it is best to avoid this type of questions:
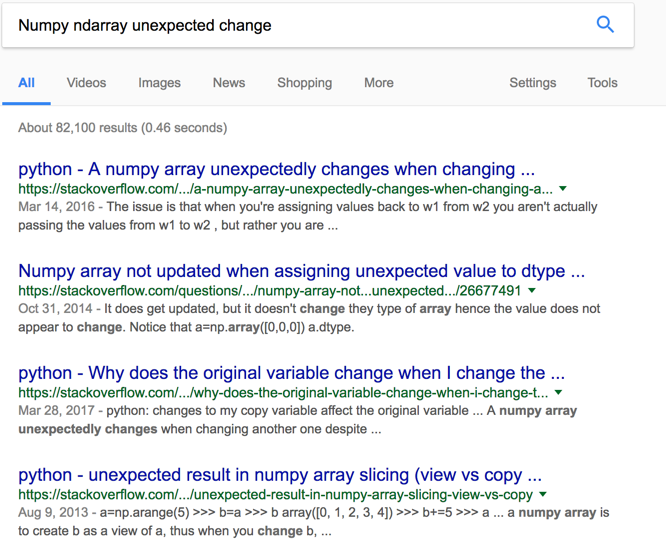
I think:
cannot be ignored.
Most Arraymancer performance issues come from memory allocation and are due to value semantics. The alternative, using
unsafeView,unsafeSlice,unsafeSqueeze, etc is clunky as it litters the codebase with low-level details.With "copy-on-write", it is possible to be:
by only copying when necessary, i.e. when a value is mutable.
Benefits expected:
if refcount = 1optimization for var assignment .That would make Arraymancer depends on the refcounting GC and it would be much better to use destructors and the future
=moveand=sinkin Implement=moveand=sinkoperators (destructors) #150 for that.Limitations:
resultwill still requireunsafeViewandunsafeUnsqueezefor shallow-copies. (Obviously slice mutation does not copy but overwrite in-place).This is perfectly reasonable in my opinion.
This superseeds #19
The text was updated successfully, but these errors were encountered: