[paper]

Figure 1: We address the reconstruction accuracy drop of high spatial-compression autoencoders.

Figure 2: DC-AE speeds up latent diffusion models.
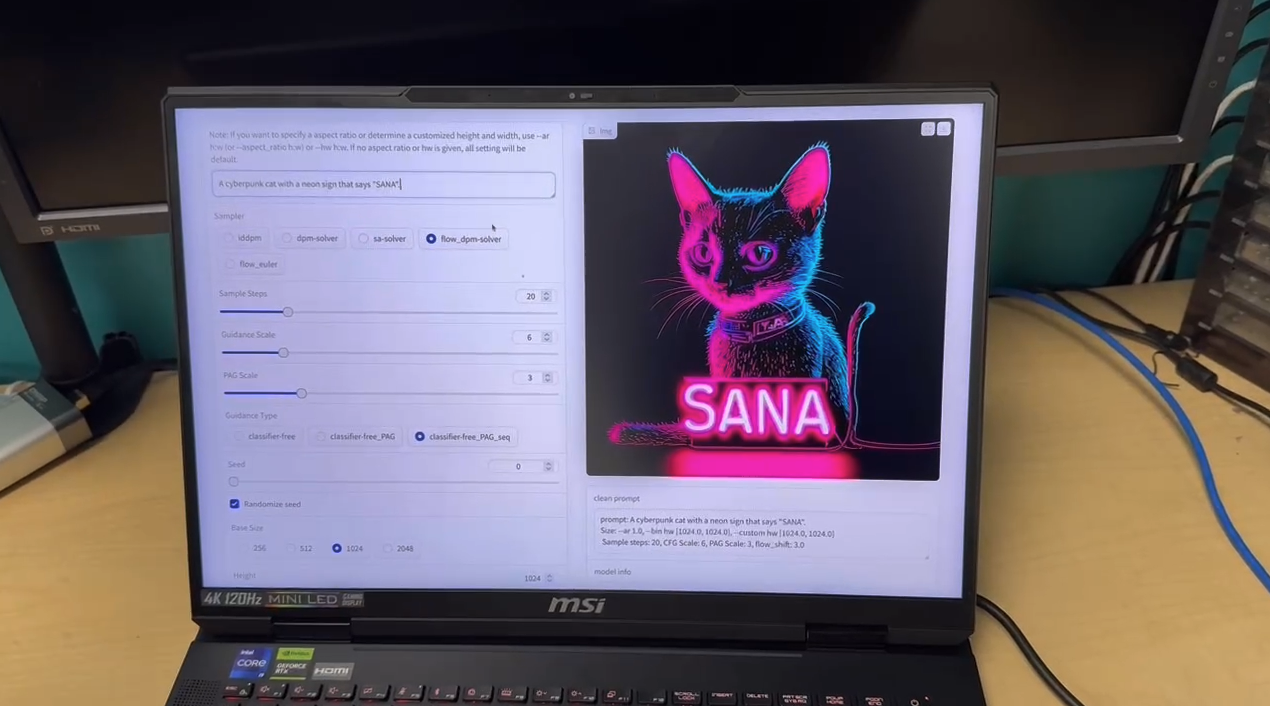

Figure 3: DC-AE enables efficient text-to-image generation on the laptop. For more details, please check our text-to-image diffusion model SANA.
We present Deep Compression Autoencoder (DC-AE), a new family of autoencoder models for accelerating high-resolution diffusion models. Existing autoencoder models have demonstrated impressive results at a moderate spatial compression ratio (e.g., 8x), but fail to maintain satisfactory reconstruction accuracy for high spatial compression ratios (e.g., 64x). We address this challenge by introducing two key techniques: (1) Residual Autoencoding, where we design our models to learn residuals based on the space-to-channel transformed features to alleviate the optimization difficulty of high spatial-compression autoencoders; (2) Decoupled High-Resolution Adaptation, an efficient decoupled three-phases training strategy for mitigating the generalization penalty of high spatial-compression autoencoders. With these designs, we improve the autoencoder's spatial compression ratio up to 128 while maintaining the reconstruction quality. Applying our DC-AE to latent diffusion models, we achieve significant speedup without accuracy drop. For example, on ImageNet 512x512, our DC-AE provides 19.1x inference speedup and 17.9x training speedup on H100 GPU for UViT-H while achieving a better FID, compared with the widely used SD-VAE-f8 autoencoder.
pip install -U diffusersfrom PIL import Image
import torch
import torchvision.transforms as transforms
from torchvision.utils import save_image
from diffusers import AutoencoderDC
device = torch.device("cuda")
dc_ae: AutoencoderDC = AutoencoderDC.from_pretrained(f"mit-han-lab/dc-ae-f64c128-in-1.0-diffusers", torch_dtype=torch.float32).to(device).eval()
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(0.5, 0.5),
])
image = Image.open("assets/fig/girl.png")
x = transform(image)[None].to(device)
latent = dc_ae.encode(x).latent
y = dc_ae.decode(latent).sample
save_image(y * 0.5 + 0.5, "demo_dc_ae.png")Alternatively, you can also use the following script to get the reconstruction result.
python -m applications.dc_ae.demo_dc_ae_model_diffusers model=dc-ae-f32c32-in-1.0-diffusers run_dir=.demo/reconstruction/dc-ae-f32c32-in-1.0-diffusers input_path_list=[assets/fig/girl.png]| Autoencoder | Latent Shape | Training Dataset | Note |
|---|---|---|---|
| dc-ae-f32c32-in-1.0 | ImageNet | ||
| dc-ae-f64c128-in-1.0 | ImageNet | ||
| dc-ae-f128c512-in-1.0 | ImageNet | ||
| dc-ae-f32c32-mix-1.0 | A Mixture of Datasets | ||
| dc-ae-f64c128-mix-1.0 | A Mixture of Datasets | ||
| dc-ae-f128c512-mix-1.0 | A Mixture of Datasets | ||
| dc-ae-f32c32-sana-1.0 | A Mixture of Datasets | The autoencoder used in SANA |
# build DC-AE models
# full DC-AE model list: https://huggingface.co/collections/mit-han-lab/dc-ae-670085b9400ad7197bb1009b
from efficientvit.ae_model_zoo import DCAE_HF
dc_ae = DCAE_HF.from_pretrained(f"mit-han-lab/dc-ae-f64c128-in-1.0")
# encode
from PIL import Image
import torch
import torchvision.transforms as transforms
from torchvision.utils import save_image
from efficientvit.apps.utils.image import DMCrop
device = torch.device("cuda")
dc_ae = dc_ae.to(device).eval()
transform = transforms.Compose([
DMCrop(512), # resolution
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
image = Image.open("assets/fig/girl.png")
x = transform(image)[None].to(device)
latent = dc_ae.encode(x)
print(latent.shape)
# decode
y = dc_ae.decode(latent)
save_image(y * 0.5 + 0.5, "demo_dc_ae.png")Alternatively, you can also use the following script to get the reconstruction result.
python -m applications.dc_ae.demo_dc_ae_model model=dc-ae-f32c32-in-1.0 run_dir=.demo/reconstruction/dc-ae-f32c32-in-1.0 input_path_list=[assets/fig/girl.png]| Autoencoder | Diffusion Model | Params (M) | MACs (G) | ImageNet 512x512 FID (without cfg) | ImageNet 512x512 FID (with cfg) |
|---|---|---|---|---|---|
| DC-AE-f32 | UViT-S | 44.79 | 12.27 | 46.12 | 18.08 |
| DC-AE-f32 | DiT-XL | 674.89 | 118.68 | 9.56 | 2.84 |
| DC-AE-f32 | DiT-XL (train batch size 1024) | 674.89 | 118.68 | 6.88 | 2.41 |
| DC-AE-f32 | UViT-H | 500.87 | 133.25 | 9.83 | 2.53 |
| DC-AE-f64 | UViT-H | 500.87 | 33.25 | 13.96 | 3.01 |
| DC-AE-f64 | UViT-H (train 2000k steps) | 500.87 | 33.25 | 12.26 | 2.66 |
| DC-AE-f32 | UViT-2B | 1580.40 | 414.91 | 8.13 | 2.30 |
| DC-AE-f64 | UViT-2B | 1580.40 | 104.65 | 7.78 | 2.47 |
| DC-AE-f64 | UViT-2B (train 2000k steps) | 1580.40 | 104.65 | 6.50 | 2.25 |
| DC-AE-f32 | USiT-H | 500.87 | 33.25 | 3.80 | 1.89 |
| DC-AE-f32 | USiT-2B | 1580.40 | 414.91 | 2.90 | 1.72 |
# build DC-AE-Diffusion models
# full DC-AE-Diffusion model list: https://huggingface.co/collections/mit-han-lab/dc-ae-diffusion-670dbb8d6b6914cf24c1a49d
from efficientvit.diffusion_model_zoo import DCAE_Diffusion_HF
dc_ae_diffusion = DCAE_Diffusion_HF.from_pretrained(f"mit-han-lab/dc-ae-f64c128-in-1.0-uvit-h-in-512px-train2000k")
# denoising on the latent space
import torch
import numpy as np
from torchvision.utils import save_image
torch.set_grad_enabled(False)
device = torch.device("cuda")
dc_ae_diffusion = dc_ae_diffusion.to(device).eval()
seed = 0
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
eval_generator = torch.Generator(device=device)
eval_generator.manual_seed(seed)
prompts = torch.tensor(
[279, 333, 979, 936, 933, 145, 497, 1, 248, 360, 793, 12, 387, 437, 938, 978], dtype=torch.int, device=device
)
num_samples = prompts.shape[0]
prompts_null = 1000 * torch.ones((num_samples,), dtype=torch.int, device=device)
latent_samples = dc_ae_diffusion.diffusion_model.generate(prompts, prompts_null, 6.0, eval_generator)
latent_samples = latent_samples / dc_ae_diffusion.scaling_factor
# decode
image_samples = dc_ae_diffusion.autoencoder.decode(latent_samples)
save_image(image_samples * 0.5 + 0.5, "demo_dc_ae_diffusion.png", nrow=int(np.sqrt(num_samples)))-
Download the ImageNet dataset to
~/dataset/imagenet. -
Generate reference for FID computation:
torchrun --nnodes=1 --nproc_per_node=8 -m applications.dc_ae.generate_reference \
dataset=imagenet imagenet.resolution=512 imagenet.image_mean=[0.,0.,0.] imagenet.image_std=[1.,1.,1.] split=test \
fid.save_path=assets/data/fid/imagenet_512_val.npz- Run evaluation:
# full DC-AE model list: https://huggingface.co/collections/mit-han-lab/dc-ae-670085b9400ad7197bb1009b
torchrun --nnodes=1 --nproc_per_node=8 -m applications.dc_ae.eval_dc_ae_model dataset=imagenet_512 model=dc-ae-f64c128-in-1.0 run_dir=tmp
# Expected results:
# fid: 0.2167766520628902
# psnr: 26.1489275
# ssim: 0.710486114025116
# lpips: 0.0802311897277832# full DC-AE-Diffusion model list: https://huggingface.co/collections/mit-han-lab/dc-ae-diffusion-670dbb8d6b6914cf24c1a49d
torchrun --nnodes=1 --nproc_per_node=1 -m applications.dc_ae.demo_dc_ae_diffusion_model model=dc-ae-f64c128-in-1.0-uvit-h-in-512px-train2000k run_dir=.demo/diffusion/dc-ae-f64c128-in-1.0-uvit-h-in-512px-train2000kExpected results:

- Generate reference for FID computation:
# generate reference for FID computation
torchrun --nnodes=1 --nproc_per_node=8 -m applications.dc_ae.generate_reference \
dataset=imagenet imagenet.resolution=512 imagenet.image_mean=[0.,0.,0.] imagenet.image_std=[1.,1.,1.] split=train \
fid.save_path=assets/data/fid/imagenet_512_train.npz- Run evaluation without cfg
# full DC-AE-Diffusion model list: https://huggingface.co/collections/mit-han-lab/dc-ae-diffusion-670dbb8d6b6914cf24c1a49d
torchrun --nnodes=1 --nproc_per_node=8 -m applications.dc_ae.eval_dc_ae_diffusion_model dataset=imagenet_512 model=dc-ae-f64c128-in-1.0-uvit-h-in-512px cfg_scale=1.0 run_dir=tmp
# Expected results:
# fid: 13.754458694549271
torchrun --nnodes=1 --nproc_per_node=8 -m applications.dc_ae.eval_dc_ae_diffusion_model dataset=imagenet_512 model=dc-ae-f32c32-in-1.0-usit-h-in-512px cfg_scale=1.0 run_dir=tmp
# Expected results:
# fid: 3.791360749566877- Run evaluation with cfg
# full DC-AE-Diffusion model list: https://huggingface.co/collections/mit-han-lab/dc-ae-diffusion-670dbb8d6b6914cf24c1a49d
# cfg=1.3 for mit-han-lab/dc-ae-f32c32-in-1.0-dit-xl-in-512px
# and cfg=1.5 for all other models
torchrun --nnodes=1 --nproc_per_node=8 -m applications.dc_ae.eval_dc_ae_diffusion_model dataset=imagenet_512 model=dc-ae-f64c128-in-1.0-uvit-h-in-512px cfg_scale=1.5 run_dir=tmp
# Expected results:
# fid: 2.963459255529642
torchrun --nnodes=1 --nproc_per_node=8 -m applications.dc_ae.eval_dc_ae_diffusion_model dataset=imagenet_512 model=dc-ae-f32c32-in-1.0-usit-h-in-512px cfg_scale=1.2 run_dir=tmp
# Expected results:
# fid: 1.883184155951767
torchrun --nnodes=1 --nproc_per_node=8 -m applications.dc_ae.eval_dc_ae_diffusion_model dataset=imagenet_512 model=dc-ae-f32c32-in-1.0-usit-2b-in-512px cfg_scale=1.15 run_dir=tmp
# Expected results:
# fid: 1.7210562991380698# Example: DC-AE-f64
torchrun --nnodes=1 --nproc_per_node=8 -m applications.dc_ae.dc_ae_generate_latent resolution=512 \
image_root_path=~/dataset/imagenet/train batch_size=64 \
model_name=dc-ae-f64c128-in-1.0 scaling_factor=0.2889 \
latent_root_path=assets/data/latent/dc_ae_f64c128_in_1.0/imagenet_512
# Example: DC-AE-f32
torchrun --nnodes=1 --nproc_per_node=8 -m applications.dc_ae.dc_ae_generate_latent resolution=512 \
image_root_path=~/dataset/imagenet/train batch_size=64 \
model_name=dc-ae-f32c32-in-1.0 scaling_factor=0.3189 \
latent_root_path=assets/data/latent/dc_ae_f32c32_in_1.0/imagenet_512# Example: DC-AE-f32 + USiT-H on ImageNet 512x512
torchrun --nnodes=1 --nproc_per_node=8 -m applications.dc_ae.train_dc_ae_diffusion_model resolution=512 \
train_dataset=latent_imagenet latent_imagenet.batch_size=128 latent_imagenet.data_dir=assets/data/latent/dc_ae_f32c32_in_1.0/imagenet_512 \
evaluate_dataset=sample_class sample_class.num_samples=50000 \
autoencoder=dc-ae-f32c32-in-1.0 scaling_factor=0.3189 \
model=uvit uvit.depth=28 uvit.hidden_size=1152 uvit.num_heads=16 uvit.in_channels=32 uvit.patch_size=1 \
uvit.train_scheduler=SiTSampler uvit.eval_scheduler=ODE_dopri5 uvit.num_inference_steps=250 \
optimizer.name=adamw optimizer.lr=1e-4 optimizer.weight_decay=0 optimizer.betas=[0.99,0.99] lr_scheduler.name=constant_with_warmup lr_scheduler.warmup_steps=5000 amp=bf16 \
max_steps=500000 ema_decay=0.9999 \
fid.ref_path=assets/data/fid/imagenet_512_train.npz \
run_dir=.exp/diffusion/imagenet_512/dc_ae_f32c32_in_1.0/usit_xl_1/bs_1024_lr_1e-4_bf16 log=False# Example: DC-AE-f64 + UViT-H on ImageNet 512x512
torchrun --nnodes=1 --nproc_per_node=8 -m applications.dc_ae.train_dc_ae_diffusion_model resolution=512 \
train_dataset=latent_imagenet latent_imagenet.batch_size=128 latent_imagenet.data_dir=assets/data/latent/dc_ae_f64c128_in_1.0/imagenet_512 \
evaluate_dataset=sample_class sample_class.num_samples=50000 \
autoencoder=dc-ae-f64c128-in-1.0 scaling_factor=0.2889 \
model=uvit uvit.depth=28 uvit.hidden_size=1152 uvit.num_heads=16 uvit.in_channels=128 uvit.patch_size=1 \
uvit.train_scheduler=DPM_Solver uvit.eval_scheduler=DPM_Solver \
optimizer.name=adamw optimizer.lr=2e-4 optimizer.weight_decay=0.03 optimizer.betas=[0.99,0.99] lr_scheduler.name=constant_with_warmup lr_scheduler.warmup_steps=5000 amp=bf16 \
max_steps=500000 ema_decay=0.9999 \
fid.ref_path=assets/data/fid/imagenet_512_train.npz \
run_dir=.exp/diffusion/imagenet_512/dc_ae_f64c128_in_1.0/uvit_h_1/bs_1024_lr_2e-4_bf16 log=False# Example: DC-AE-f32 + DiT-XL on ImageNet 512x512
torchrun --nnodes=1 --nproc_per_node=8 -m applications.dc_ae.train_dc_ae_diffusion_model resolution=512 \
train_dataset=latent_imagenet latent_imagenet.batch_size=32 latent_imagenet.data_dir=assets/data/latent/dc_ae_f32c32_in_1.0/imagenet_512 \
evaluate_dataset=sample_class sample_class.num_samples=50000 \
autoencoder=dc-ae-f32c32-in-1.0 scaling_factor=0.3189 \
model=dit dit.learn_sigma=True dit.in_channels=32 dit.patch_size=1 dit.depth=28 dit.hidden_size=1152 dit.num_heads=16 \
dit.train_scheduler=GaussianDiffusion dit.eval_scheduler=GaussianDiffusion \
optimizer.name=adamw optimizer.lr=0.0001 optimizer.weight_decay=0 optimizer.betas=[0.9,0.999] lr_scheduler.name=constant amp=fp16 \
max_steps=3000000 ema_decay=0.9999 \
fid.ref_path=assets/data/fid/imagenet_512_train.npz \
run_dir=.exp/diffusion/imagenet_512/dc_ae_f32c32_in_1.0/dit_xl_1/bs_256_lr_1e-4_fp16 log=False
# Example: DC-AE-f32 + DiT-XL on ImageNet 512x512 with batch size 1024
torchrun --nnodes=1 --nproc_per_node=8 -m applications.dc_ae.train_dc_ae_diffusion_model resolution=512 \
train_dataset=latent_imagenet latent_imagenet.batch_size=128 latent_imagenet.data_dir=assets/data/latent/dc_ae_f32c32_in_1.0/imagenet_512 \
evaluate_dataset=sample_class sample_class.num_samples=50000 \
autoencoder=dc-ae-f32c32-in-1.0 scaling_factor=0.3189 \
model=dit dit.learn_sigma=True dit.in_channels=32 dit.patch_size=1 dit.depth=28 dit.hidden_size=1152 dit.num_heads=16 \
dit.train_scheduler=GaussianDiffusion dit.eval_scheduler=GaussianDiffusion \
optimizer.name=adamw optimizer.lr=0.0002 optimizer.weight_decay=0 optimizer.betas=[0.9,0.999] lr_scheduler.name=constant amp=fp16 \
max_steps=3000000 ema_decay=0.9999 \
fid.ref_path=assets/data/fid/imagenet_512_train.npz \
run_dir=.exp/diffusion/imagenet_512/dc_ae_f32c32_in_1.0/dit_xl_1/bs_1024_lr_2e-4_fp16 log=FalseIf DC-AE is useful or relevant to your research, please kindly recognize our contributions by citing our papers:
@article{chen2024deep,
title={Deep Compression Autoencoder for Efficient High-Resolution Diffusion Models},
author={Chen, Junyu and Cai, Han and Chen, Junsong and Xie, Enze and Yang, Shang and Tang, Haotian and Li, Muyang and Lu, Yao and Han, Song},
journal={arXiv preprint arXiv:2410.10733},
year={2024}
}