You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
使用 Keras sequential model 定义神经网络(在这里,简单地使用了Dense-Activation(relu)-Dense-Activation(relu)-Dense-Activation(softmax)的结构),通过softmax计算的概率值大小判断是哪个数字的可能性最大
编译模型(利用model.compile()进行模型的编译)
训练模型,并将指标保存到 history 中
保存模型(利用model.save()将模型保存到本地,下次可以直接使用此模型),官方解释如下:
You can use model.save(filepath) to save a Keras model into a single HDF5 file which will contain:
the architecture of the model, allowing to re-create the model
the weights of the model
the training configuration (loss, optimizer)
the state of the optimizer, allowing to resume training exactly where you left off.
You can then use keras.models.load_model(filepath) to reinstantiate your model. load_model will also take care of compiling the model using the saved training configuration (unless the model was never compiled in the first place).
闲暇时间利用tensorflow框架写一些小项目练手~ github项目地址
房价预测线性回归
第1步:进行数据处理
首先读取csv数据,再对x1 x2 ... xn y数据进行归一化处理,接下来添加单独的一列x0(值均为1,常数项)
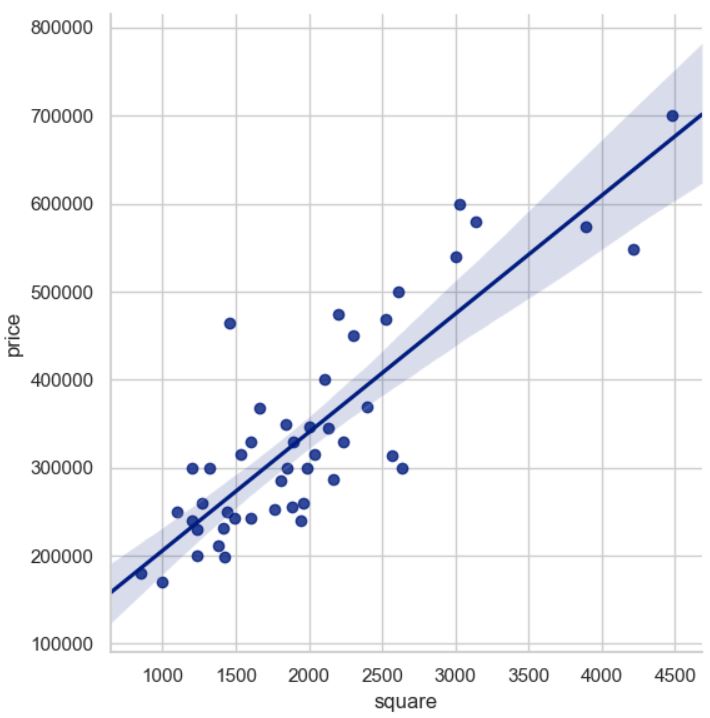
经过归一化处理后的数据结构如下:
第2步:训练模型
在第1步得到的数据基础上进行处理. 首先,需要拿到x y的数据,定义学习率
learning_rate和训练次数epoch,分别输入x y,计算损失loss值,使用梯度下降优化器进行优化操作.GradientDescentOptimizer模型训练好后的数据如下:
第3步:可视化流图
使用tensorboard可以可视化数据流图,可以方便我们查看训练的过程
其中,定义的
with tf.name_scope('xxx'):是为了将相关的部分视为整体展示在tensorboard中,可以更加方便地展开和隐藏,能够更有效地展示模型的结构.第4步:可视化损失loss
每次迭代过程中,损失值的变化趋势如下:
由此可见,随着迭代次数的增多,损失值越来越小,最后趋于平稳,模型越来越优.
手写数字识别
第1步:加载数据集mnist
最后得到的数据集如下:
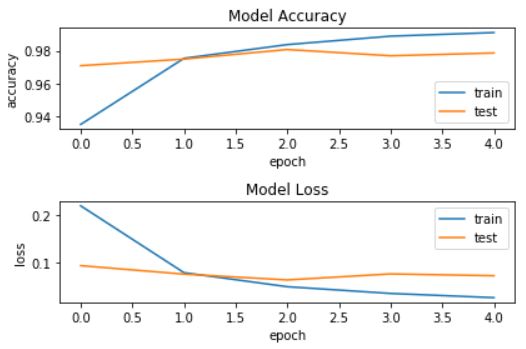
第2步:利用softmax进行手写数字识别
具体流程:
Dense-Activation(relu)-Dense-Activation(relu)-Dense-Activation(softmax)的结构),通过softmax计算的概率值大小判断是哪个数字的可能性最大model.compile()进行模型的编译)model.save()将模型保存到本地,下次可以直接使用此模型),官方解释如下:训练的结果为:
可视化指标效果如下:
保存模型后,如果要实现模型的加载,则可以使用
load_model函数,其中model_path是模型的路径.使用训练好的此模型统计测试集上的分类结果,具体代码如下:得到的结果如下:
由此可见,训练结果还是相当不错的,准确率达到了97.86%.
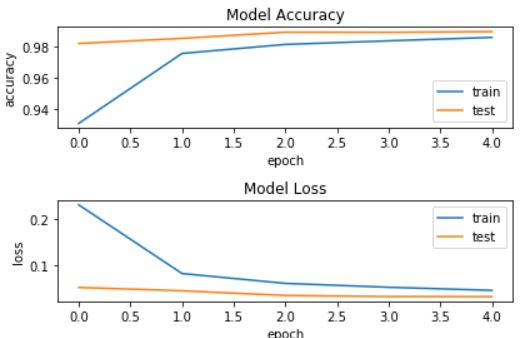
第3步:利用CNN进行手写数字识别
整体的流程和第2步是非常类似的,只是在模型训练的过程中,采用的是CNN卷积神经网络,加入了更多的隐藏层,增加了模型的复杂度,也提高了模型的准确性。具体的神经网络设计如下,分别为
卷积层-卷积层-池化层-dropout层-flatten层-全连接层-dropout层-softmax全连接层,具体参数如下:查看 MNIST CNN 模型网络结构:
具体代码如下:
利用CNN卷积神经网络训练后,可视化指标如下:
验证码识别
第1步:创建验证码数据集
具体步骤如下:
ImageCaptcha最后生成 100 张验证码图像和字符如下:

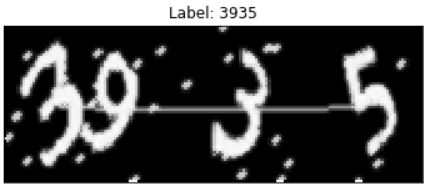
第2步:数据处理
具体步骤:
最后生成的数字灰度图效果如下:
第3步:训练模型
具体步骤(前6步准备工作已经做过了,主要是要进行7-15步的模型训练过程,16-17步是做对应的保存工作):
训练模型得到的参数如下:
实现词云
要实现词云效果,首先需要安装wordcloud库,
pip install wordcloud进行安装即可。1. 英文词云
实现基本的英文词云:
效果展示:
2. 中文词云
其中读取文件使用
text = open('xxx.txt',encoding='UTF-8').read(),注意这里要写encoding='UTF-8',否则无法正确读取内容。要额外引入字体文件,如上例引入了Hiragino.ttf字体。最后生成的效果如下,但是有个问题就是每个词并不是按照中文意思进行断开的,无实际意义,接下来我们处理中文分词问题。3. 中文词云+分词
因为英文文章中每个单词都是使用空格隔开的,因此不需要手动分词,而中文文章每个词是连在一起的,需要引入第三方包jieba进行中文分词操作。核心代码是
text=' '.join(jieba.cut(text)),这样可以使得每个独立的词用空格隔开。最后生成的效果如下:4. 中文词云+分词+黑白蒙版
这里使用了黑白图片作为蒙版,WordCloud()函数中传入mask参数,则可以启用对应的蒙版,这样生成的词云会与蒙版的图形相同。效果如下:
5. 中文词云+分词+彩色蒙版
这里使用了彩色图片作为蒙版,从
wordcloud引入ImageColorGenerator函数,从图片中生成颜色,这样生成的词云颜色和蒙版的颜色是相同的(每个部分的颜色都是大致对应的),效果如下:6. 中文词云+分词+彩色蒙版+自定义颜色
为了实现为词云自定义颜色,我们可以单独实现一个上色函数random_color,在WordCloud()函数中传入color_func参数即可,效果如下:

7. 中文词云+分词+彩色蒙版+关键词权重
为了在词云中凸显词语出现的频率,我们可以采用根据频率上色的方法,频率出现越高则着色越深。先提取关键词和权重,再通过

WordCloud().generate_from_frequencies(freq)生成词云即可,注意这里的freq是词与频次关系的字典。最后生成的效果如下:自编码器图像去噪AE
自编码器深度学习中的一类无监督学习模型,由encoder和decoder两个部分组成。自编码器主要是一种思想,encoder和decoder可以由全连接层\CNN\RNN等模型实现。
第1步:完成模型训练,并保存模型
具体步骤:
可视化噪声图片效果如下:

第2步:加载训练好的模型,用来图像去噪
原始噪声图 vs 去噪后的图片 的效果如下:

变分自编码器VAE
我们经常会有这样的需求:根据很多个样本,学会生成新的样本
以mnist为例,在看过成百上千张图片后,让计算机能够模仿生成一些类似的图片,这些图片在原始数据中并不存在,但是与原来图片看起来相似
简言之就是需要学会数据x的分布,根据数据分布产生新样本
VAE(变分自编码器)和AE(自编码器)的区别:
可以使用
keras.datasets中的mnist或fashion_mnist进行测试:encoder的可视化效果(mnist中的数据在隐层中的形态):
验证生成器能生成什么样的图片:
生成式对抗网络GAN
除VAE以外,生成式对抗网络(GAN)也是一种非常流行的无监督生成式模型.
GAN中包括两个核心网络:
GAN的训练非常困难,有很多需要注意的细节,才能生成质量较高的图片:
完整代码如下:
图片经过卷积的基本结构变化如下:
生成的手写数字图片的动图效果为:
训练好模型后,可直接加载模型,自动生成类似图片:
Inception-v3图片分类
Inception-v3是由Google提出,用于实现ImageNet大规模视觉识别任务的一种神经网络。Inception-v3反复使用了Inception Block,涉及大量的卷积和池化. 这里我们选择加载pre-trained的Inception-v3模型,来完成一些图片分类任务。
Inception-v3的模型结构如下:
训练好的模型包括3个部分:
classify_image_graph_def.pb: Inception-v3模型结构和参数imagenet_2012_challenge_label_map_proto.pbtxt: 从类别编码到类别字符串的对应关系imagenet_synset_to_human_label_map.txt: 从类别字符串到类别名的对应关系定制分类任务
Inception-v3是针对ImageNet图片分类设计的,因此最后一层全连接层的神经元个数和分类标签的个数相同。如果需要特别定制分类任务的话,只需要使用自己的标注数据,然后替换掉最后一层全连接层即可。
最后一层全连接层的神经元个数等于定制分类任务的标签个数,模型只训练最后一层的参数,其他参数保持不变。这样的话保留了Inception-v3对于图像的理解和抽象能力,同时满足了定制的分类任务,属于迁移学习的一种典型应用场景。
The text was updated successfully, but these errors were encountered: