
아래는 당신이 이 프로그램으로 할 수 있는 것들입니다:
- Instagram API를 사용하지 않고 게시물/프로필/해시태그 데이터 얻기.
crawler.py - 게시물에 좋아요 자동으로 누르기.
liker.py
이 크롤러는 instagram 웹사이트의 업데이트 때문에 실패할 수 있습니다. 만약 문제가 생기면 저에게 연락해주세요.
- Chrome 브라우저가 설치되어 있어야 합니다.
- chromedriver를 다운로드 하고 bin 폴더에 넣어주세요:
./inscrawler/bin/chromedriver - Selenium을 설치해주세요:
pip3 install -r requirements.txt cp inscrawler/secret.py.dist inscrawler/secret.py
위치 인자(positional arguments):
mode
options: [posts, posts_full, profile, hashtag]
선택적 인자(optional arguments):
-n NUMBER, --number NUMBER
number of returned posts
-u USERNAME, --username USERNAME
instagram의 사용자 이름
-t TAG, --tag TAG instagram의 태그 이름
-o OUTPUT, --output OUTPUT
출력 파일 이름(json 형식)
--debug 프로그램이 어떻게 브라우저를 자동화 하는지 보기
--fetch_comments 댓글 가져오기
# 댓글이 너무 많다면 flag를 키면 데이터를 가져오는데 매우 오래 걸릴 수 있습니다.
--fetch_likes_plays 좋아요/재생 수 가져오기
--fetch_likers 좋아요 한 모든 사용자 가져오기
# 인스타그램은 좋아요 한 사용자를 가져오는데 속도 제한(rate limit)이 있습니다. 좋아요 한 사용자가 너무 많다면 데이터를 가져오는데 매우 오래 걸릴 수 있습니다.
--fetch_mentions 캡션/댓글들에서 멘션된 사용자들을 가져오기 (@로 시작하는)
--fetch_hashtags 캡션/댓글에 있는 해시태그들 가져오기 (#로 시작하는)
--fetch_details 사용자 이름과 사진 캡션을 가져오기
# "해시태그" 검색에서만 가능
python crawler.py posts_full -u cal_foodie -n 100 -o ./output
python crawler.py posts_full -u cal_foodie -n 10 --fetch_likers --fetch_likes_plays
python crawler.py posts_full -u cal_foodie -n 10 --fetch_comments
python crawler.py profile -u cal_foodie -o ./output
python crawler.py hashtag -t taiwan -o ./output
python crawler.py hashtag -t taiwan -o ./output --fetch_details
python crawler.py posts -u cal_foodie -n 100 -o ./output # deprecated
posts모드를 선택하면, 각 게시물에 대하여 url, 캡션, 첫번째 사진을 얻습니다;posts_full을 선택하면, 각 게시물에 대하여 url, 캡션, 모든 사진, 시간, 댓글들, 좋아요와 조회 수를 얻습니다.posts_full모드는posts보다 더 오래걸립니다. [posts는 더 이상 사용되지 않습니다. 최근의 게시물들에 대해서, 더 이상 게시물 캡션을 빠르게 얻는 방법이 없습니다.]-n,--number으로 게시물 수를 지정하지 않으면, 기본적으로 100개의 해시태그 게시물과(모드: hashtag) 모든 사용자의 게시물들(모드: posts)을 리턴합니다.-o,--output으로 출력 경로를 지정하지 않으면 결과를 콘솔 창에 출력합니다.- 인스타그램이 데이터 요청에 대해 속도 제한을 설정했기 때문에, 게시물의 개수가 1000개를 넘으면 데이터를 얻는데 시간이 많이 걸립니다.
- 사용자의 게시물이 10000개를 넘는다면 이 크롤러를 사용하지 마세요.
posts의 데이터 형식:

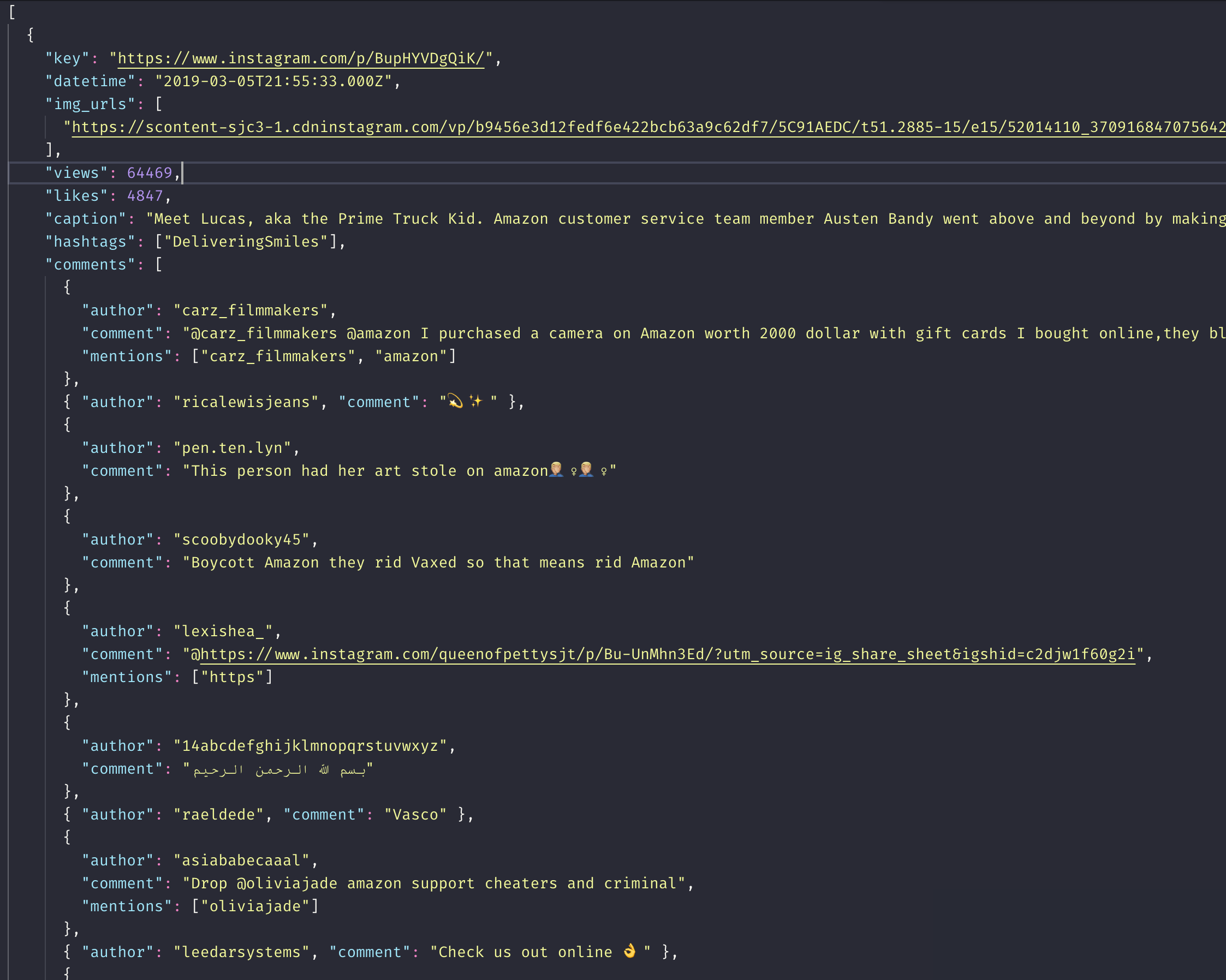
posts_full의 데이터 형식:

당신의 사용자 이름/비밀번호를 secret.py에 설정하거나 환경 변수에 설정하세요.
positional arguments:
tag
optional arguments:
-n NUMBER, --number NUMBER (default 1000)
number of posts to like
python liker.py foodie