[EPIC] Graphql schema refactor #4261
Comments
|
Thanks a lot for the research @pieh . |
|
@MarcCoet There is not much distinction between fields with no data and with conflicting types in terms of creating schema currently - gatsby discards fields with have conflicting types (so they become fields with no data at the stage of creating schema) - the distinction is more for website/apps developers - they have data but field is not in schema. You can use my proof of concept branch (at least for testing things out) - it has all basic features of getting fields - it can resolve local files, linked nodes (both of single and multiple types - unions) and of course inline fields. But to get full feature set I would have to implement this 3 more times in different places (filtering, sorting, grouping). Or you now can use I totally get your time concern and frustration about this issue - I have this problem too with some of my sites - it's hard to explain your content editors why things suddenly stopped working when they cleared some optional field ( this is why I started working on this! ), but this has to be done right sooner than later, as features that will need to be refactored will pile up. |
It wouldn't — the schema stitching process basically takes two entirely separate schemas and lets you query both of them at the same time. Unless people name their types the same as the default Gatsby ones, there'd be no interaction between the two schemas. |
|
Love the direction you're going here! This feels like the right approach and direction for a refactor and will unlock a lot of really nice capabilities! |
|
About schema stitching - I was researching this a bit earlier and |
|
Huh! That'd be amazing! Yeah, there's a ton of possibilities here — you could link to tweets, flickr images, facebook profiles, etc. anything accessible via an API and as long as you have the right source plugin installed, everything would be linked up. That'd be crazy powerful. |
|
@pieh @KyleAMathews This is something I've got a bit of experience with. When I was at IBM, we needed to keep data sources discrete, but allow them to be combined in queries to avoid complex data processing on the front-end. I ended up creating and open sourcing GrAMPS to address this. (I wrote up a "hello world" example in this post.) One of the goals of GrAMPS is to allow what I've clumsily dubbed "asynchronous stitching", where a data source can define how it extends another data source if that data source exists in the schema. This would allow plugins to build on each other when possible, but wouldn't require them to be The logic behind this wouldn't require GrAMPS to function; it's basically checking the schema for a given type before applying the I'm not sure how well this fits into the overall goal of this RFC, but I think it could help us implement the "Schema Builder" with more flexibility and extendability. Happy to help out on this however I can. Let me know if you want me to expand on any of this. |
|
@jlengstorf Wow, GrAMPS is cool! Not sure if it will fit, but I will definitely read up more on it (either to use it or at least steal some ideas!) I will for sure reach out to you for your insight. I'd like to keep this RFC to not focus on implementation details (too much 😄). I want this to serve as requirements gathering place so we could later design APIs that could be extended if needed (to not over-engineer initial refactor) but not changed (wishful thinking 😄). I think we could expose same internal APIs to plugins but to do that they need to be well designed and not be subject to breaking changes in near future. |
|
Hi. Has there been any update on this issue? Just wondering. I really wanna use Contentful + graphql ... but this issue makes it very hard to do so :( |
|
Just reading into this concept. I wrote a custom source plugin where a field from my JSON API can be null. These fields don't end up in my schema as I would expect. Are there any updates on this? @pieh Awesome work! Keep it up 😊 |
|
Was talking to @sgrove today with @calcsam and he had a really interesting idea which could apply here. Basically it was how to estimate when you've sufficiently inferred a graphql type from data. He said you could assign a "novelty" score to each type you're inferring i.e. how novel do you expect each new item to be. You evaluate sample data item by item. Each time you "learn" something new e.g. a new field, the expected novelty score goes up. Whenever an item matches the existing inferred type, the expected novelty score drops. After evaluating enough new items and not learning anything new, you can quit. This could speed up processing large data sets as we could pull out random samples and often times (especially on data that has representative data for each field on every object) we could stop the inference process quite a bit sooner than we do now. |
|
@sgrove mentioned this lib too https://github.com/cristianoc/REInfer |
|
@stefanprobst btw, instead of projection as an object, we should include a GraphQL fragment. |
|
@freiksenet Interesting!! I did projection as an object mainly because it connects nicely with what |
|
@stefanprobst right, that makes sense. We can keep it as is for now. Fragment is more flexible cause one can include eg nested fields. I'm borrowing it from here |
|
@freiksenet I'm all for allowing fragments to extend the selection set! Nested fields should work with the projection object as well though, e.g. |
|
@stefanprobst Hey, why do you have this line in the code? const updateSchema = async () => {
const tc = addInferredType(`SitePage`)
// this line
delete tc.gqType._gqcInputTypeComposer
addResolvers(tc)
addTypeToRootQuery(tc)
return schemaComposer.buildSchema({ directives })
} |
|
@freiksenet Sorry should have put a comment there. |
|
Shouldn't |
|
In type inference, if a TypeComposer already exists, we use it. This is done not mainly because of schema updating, but a TypeComposer can be created when parsing SDL in the step before. One consequence for schema updating is that we re-use a TypeComposer that has the previously produced InputTypeComposer on an internal property. There certainly are more elegant ways to invalidate or reuse this input type - since we want to get rid of schema updating at some point anyway I didn't put much effort into that though. |
|
@stefanprobst got it. I can't find date type anywhere in code, how is it added to the composer? |
|
Right, never mind, it's build in GraphQL Compose. |
|
@freiksenet Sorry it took a bit longer - there is now a branch with everything squashed, merged with master, and with the original tests added at https://github.com/stefanprobst/gatsby/tree/schema-refactor-v2 |
|
@stefanprobs Thank you! That's very helpful. |
|
@stefanprobst I do'nt quite understand this code: You are getting projection from AST then merging that same projection back into selection set. Why? |
|
Some status update, pinging @ChristopherBiscardi who is blocked on the changes.
My one week prediction is probably overly optimistic, but I hope to get something running until the end of the week. Let's see how it goes. |
|
Also I feel I'd make a similar thing that was done with lokijs and put the new schema thing under a flag. Without the flag, the two new apis won't work, but otherwise it should (hopefully) work identically. I feel many changes that @stefanprobst did to the APIs/internal logic are very good, but I want to first release something that's fully compatible before possibly adding those for 3.0. |
|
@freiksenet Thanks for the update! Sounds like a great plan!
This is what's happening: |
|
Also for info: except for a few tests that didn't make sense anymore (I left a comment there) all the old tests are ported and passing - except (i) sorting |
|
Hiya! This issue has gone quiet. Spooky quiet. 👻 We get a lot of issues, so we currently close issues after 30 days of inactivity. It’s been at least 20 days since the last update here. If we missed this issue or if you want to keep it open, please reply here. You can also add the label "not stale" to keep this issue open! Thanks for being a part of the Gatsby community! 💪💜 |
|
Everyone: We have an alpha version of our new Schema Customization API ready, and we'd love your feedback! For more info check out this blogpost. |
|
This is released now in 2.2.x. |
|
Im running into an issue when using the new schema customisation with gatsby-source-contentful. Defining a type where one of the fields points to a reference array always returns Ie: |
|
@sami616 Could you file a bug report for this, and if possible include a test repo to reproduce the error? That would be very helpful, thank you! |
|
@stefanprobst will try to file a bug report today - thanks! |
Who will own this?
What Area of Responsibility does this fall into? Who will own the work, and who needs to be aware of the work?
Area of Responsibility:
Select the Area of Responsibility most impacted by this Epic
Admin
Cloud
Customer Success
Dashboard
Developer Relations
OSS
Learning
Marketing
Sales
Summary
Make graphql schema generation code more maintainable and easier to add new features like allowing user specified types on fields instead of automatic inferring.
How will this impact Gatsby?
Domains
List the impacted domains here
Components
List the impacted Components here
Goals
What are the top 3 goals you want to accomplish with this epic? All goals should be specific, measurable, actionable, realistic, and timebound.
How will we know this epic is a success?
What changes must we see, or what must be created for us to know the project was a success. How will we know when the project is done? How will we measure success?
User Can Statement
Metrics to Measure Success
Additional Description
In a few sentences, describe the current status of the epic, what we know, and what's already been done.
What are the risks to the epic?
In a few sentences, describe what high-level questions we still need to answer about the project. How could this go wrong? What are the trade-offs? Do we need to close a door to go through this one?
What questions do we still need to answer, or what resources do we need?
Is there research to be done? Are there things we don’t know? Are there documents we need access to? Is there contact info we need? Add those questions as bullet points here.
How will we complete the epic?
What are the steps involved in taking this from idea through to reality?
How else could we accomplish the same goal?
Are there other ways to accomplish the goals you listed above? How else could we do the same thing?
--- This is stub epic - need to convert old description to new format
Main issue im trying to solve is that type inferring will not create fields/types for source data that:
This is not inferring implementation issue - it’s just this approach simply can’t handle such cases.
My approach to handle that is to allow defining field types by
Filenodes will always have same data structure)Problem:
Current implementation of schema creation looks something like this:

Input/output type creation is not abstracted and implementation has to be duplicated for each source of information.
In my proof of concept ( repository ) I added another source (graphql schema definition language) and just implemented subset of functionality:

As testing ground I used this barebones repository. Things to look for:
Implementing it way this way is fine for proof of concept but it’s unmaintainable in long term. So I want to introduce common middleman interface:
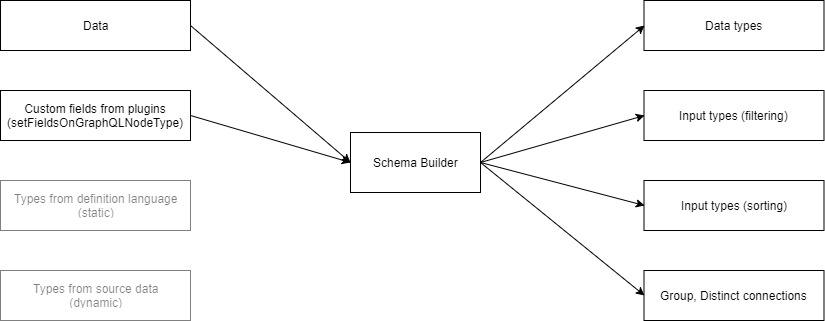
Goals:
Questions:
developmode but it can refresh data (builtin refresh for filesystem source +__refreshhook to refresh all source data) - it might be worth looking to be able to refresh schema too?markdownetc and then we have fields from github graphql apirepository- if there’s no connection between them then then this would be out of scope for this RFC), but if we would like to add connection - for example allow linking frontmatter field to github repository then this would need to be thought out ahead of time. I was looking atgraphql-toolsschema stitching and it does have some nice tooling for merging schemas and option to add resolvers between schemas - is this something that was planned to be used for that?The text was updated successfully, but these errors were encountered: