| title | datePublished | cuid | slug | canonical | cover | tags |
|---|---|---|---|---|---|---|
RAPTOR: Tree-based Retrieval for Language Models |
Wed Oct 16 2024 05:21:04 GMT+0000 (Coordinated Universal Time) |
cm2bfc5xg00020albdh92af2x |
raptor-tree-based-retrieval-for-language-models |
llm, information-retrieval, document-processing |
RAPTOR (Recursive Abstractive Processing for Tree-Organized Retrieval) is a new technique for improving retrieval-augmented language models, particularly for long documents: https://arxiv.org/html/2401.18059v1
Most existing retrieval methods only retrieve short, contiguous text chunks, limiting their ability to represent large-scale discourse structure and answer thematic questions that require integrating knowledge from multiple parts of a text.
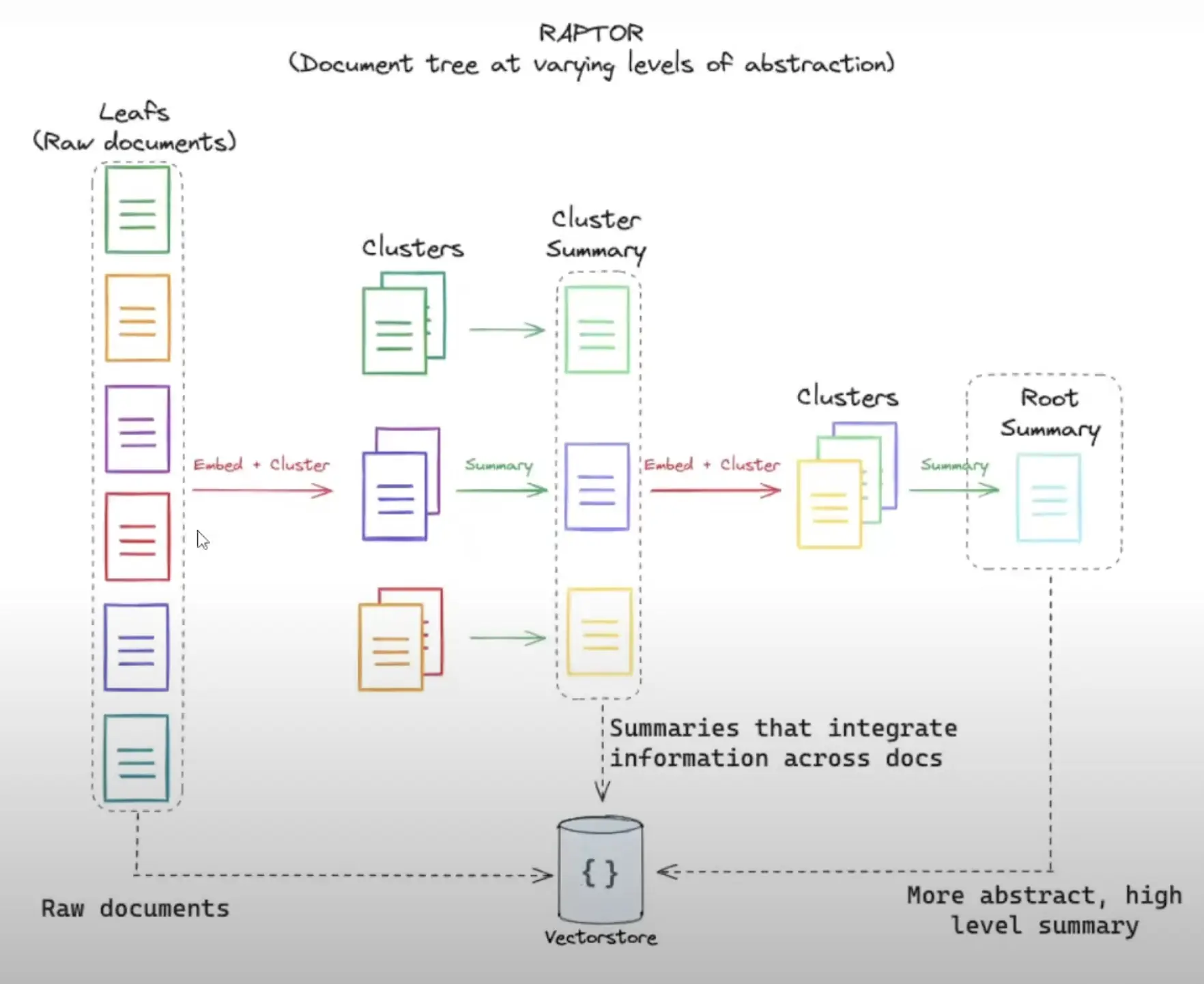
- Recursively embeds, clusters, and summarizes chunks of text
- Constructs a tree with different levels of summarization from bottom up
- At inference time, retrieves from this tree, integrating information across lengthy documents at different levels of abstraction
The process begins by segmenting text into 100-token chunks and embedding them using SBERT. RAPTOR then employs Gaussian Mixture Models for clustering similar chunks, which are summarized using GPT-3.5-turbo. This process is repeated, building the tree from bottom up:
i. Segments text into 100-token chunks ii. Embeds chunks using SBERT iii. Clusters similar chunks iv. Summarizes clusters using GPT-3.5-turbo v. Repeats process, building tree from bottom up
- Collapsed tree method outperforms tree traversal
- Retrieves nodes across all layers based on relevance
- Uses cosine similarity for matching
- Builds hierarchical tree of text summaries
- Retrieves from multiple abstraction levels
- Uses clustering (GMMs) and summarization (LLMs)
- Offers flexible querying (tree traversal / collapsed tree)
- Outperforms traditional methods (e.g., BM25, DPR) on QA tasks
- Excels at complex queries needing multi-part info
- Scales linearly with document length
- Sets new SOTA on some benchmarks when paired with GPT-4
Evaluation was conducted on NarrativeQA, QASPER, and QuALITY datasets, using metrics such as BLEU, ROUGE, METEOR, F1 score, and Accuracy.