| ID | Problem |
|---|---|
| 000 | 表设计 |
| 001 | 数据如何分片 |
| 002 | 如何实现高可用 |
| 003 | 如何实现高性能 |
| 003 | 如何实现高可靠 |
| 004 | 如何自定义线程池以及使用与导入🙋🐓 |
| 005 | 如何利用CountDownLatch使用与导入 |
| 007 | 如何控制数据一致性 |
| 008 | 如何实现幂等性 |
| 009 | 数据的导入性能 -- 数据说明 |
three-high-import 项目意义在于利用多线程进行千万级别导入,实现可扩展,高性能,高可用,高可靠三个高,本项目可以在千万级别数据实现无差别高性能数据上报
与导入,与普通导入相比性能提高10倍左右,而且规避风险在偶尔的机器宕机,网络波动等情况出现时,仍能够实现数据一致,数据可靠,数据重试,数据报警等功能,在一些重要数据
例如: 对账 , 账户金额,账单等,需要每日定时任务而且有高风险的数据实现数据无错误!
如果你完全没接触过 SpringBoot、CountDownLatch、线程池、工作队列、工作窃取等 等请先行学习一下前面的基础
下载项目后 -- 执数据建表语句 -- 建三个库 bill_1(import_data_step,import_data_task,import_point_202003) bill_2(import_data_step,import_data_task,import_point_202003) bill_3(point)
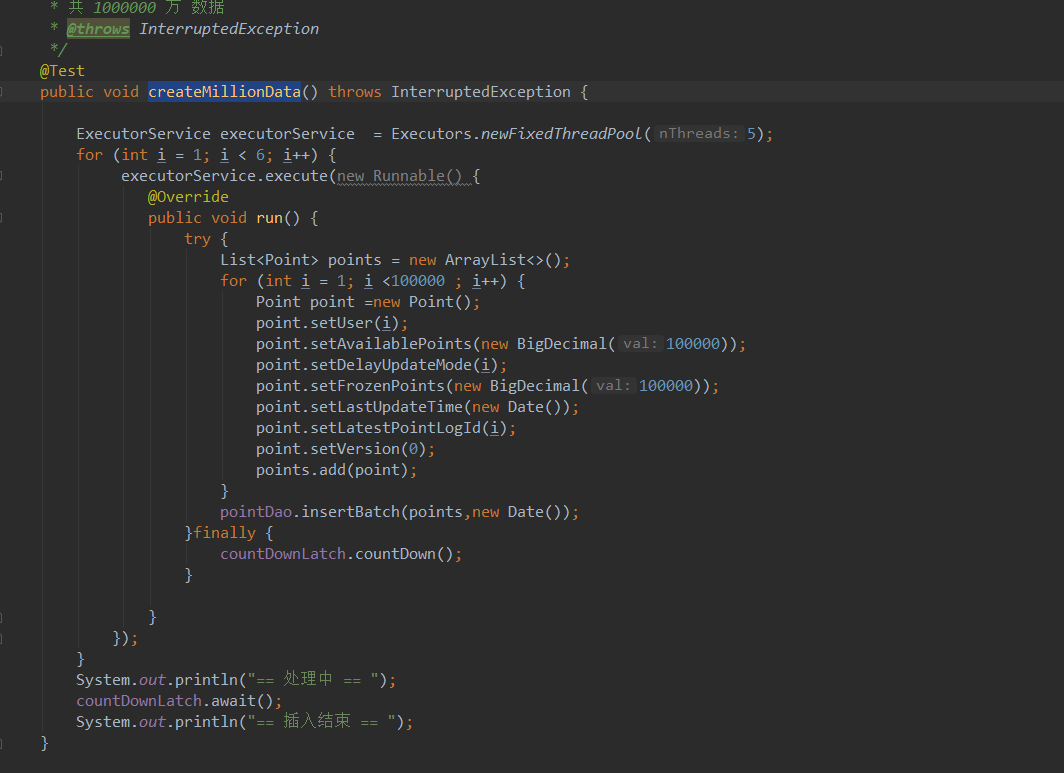
/**
* import —— point
* @throws InterruptedException
*/
@Test
public void importAll() throws InterruptedException {
timerRunner.timeGo();
Thread.currentThread().sleep(50000);
}
Point表该表为模拟数据表,主要记录用户日常操作!
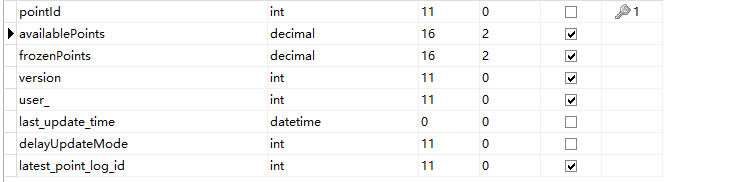
import_point_201908 该表用于记录 增量数据导入

import_data_step 该表用于记录分片范围多线程执行分片各个起点
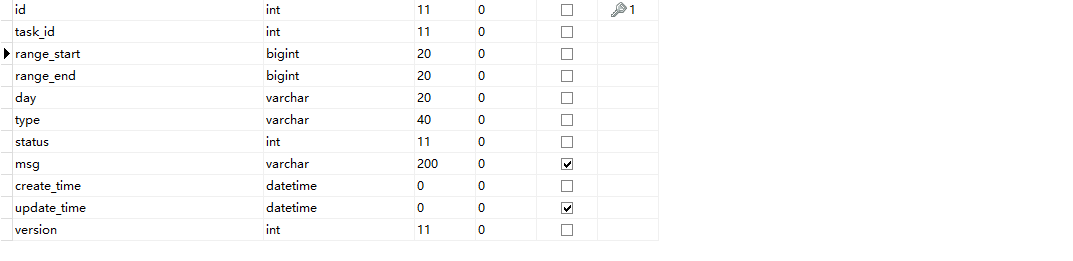
import_data_task 该表用于记录任务数量
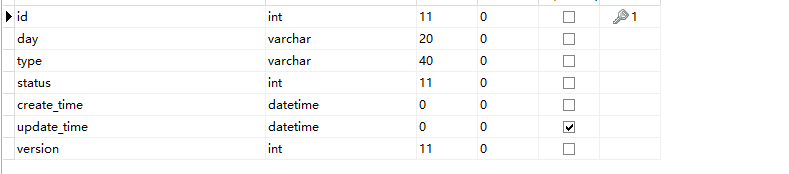
分片方法有很多种,这里介绍我的分片方法 -- MAX(ID) / 定义范围 进行循环计算范围 已 point 表为例,取point表的id 最大值按照每个范围区间进行取余预算,然后id从0开始,进行 区间+ 例如区间为1000 则数据为: 0-1000 , 1000-2000 , 2000-3000 最后一位的数字如果有余数则多加1 详情请看 three-high-import queryPointSteps
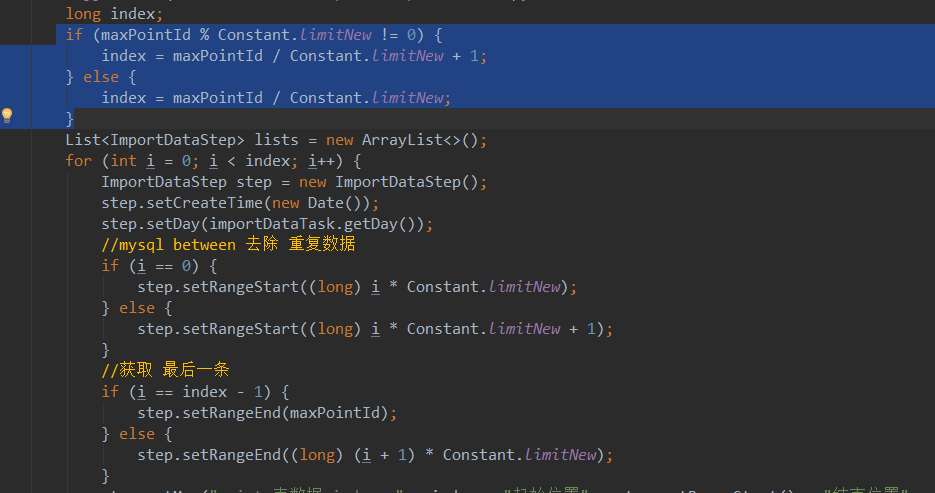
在three-high-import 系统 中会利用事务来保护task 和 step 表的 范围数据 一致性 因为这个是导入的基础 ! 如果一个发生失败则等待下次重试
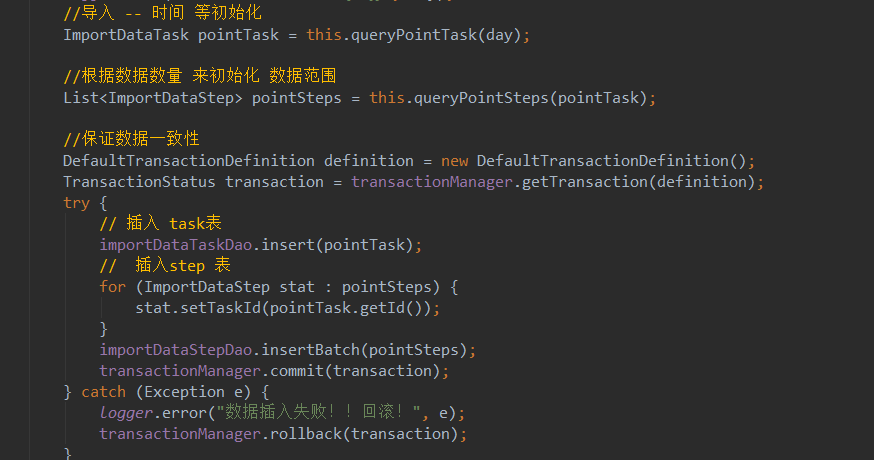
在three-high-import 系统 中有重试机制,因为每次定时任务每次查询的为未开始和发生错误的数据,那么无论多少次数据都是可以不断的去查询去重试, 任务结束后,又发生错误的数据会继续重试,但是只会重试当前批次,利用step里面得范围数据来将错误范围降低到最小,实现高可用!
利用批次导入,再多线程的情况下会比单线程导入数据更加快速,提升性能大概10倍左右 , 在three-high-import 系统 给出了利用多线程的countdowmlatch,线程池,future ....来进行导入 让大家理解更透彻
基础请看线程池精讲,使用与导入请看TimerRunner2 ....等
基础请看CountDownLatch ,使用与导入请看TimerRunner2
利用了手动事务,在需要插入的数据中进行手动事务.
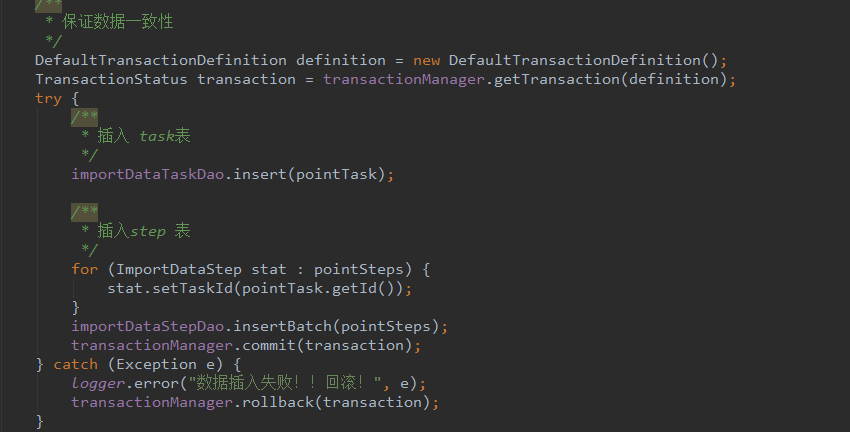
幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同,本系统因为利用分片保护错误区域特性 , 无论多少次执行都不会影响已经导入的数据!
定时任务配置频率不要太频繁,尽量要搞清自己的数据大概时间,要设置结束为标志,这样可以节省性能与实践!
数据报警后,再次开启定时任务,因为数据可重试,则继续导入!