RFC: Transformations (e.g. casting/coercion) #100
Comments
|
It seems to me like a huge overengineered overcomplication and a turnoff. The appeal of Zod is in its ridiculously simple API and a single |
|
First of all, Maybe @ivosabev is right that Another advantage of |
|
@ivosabev What you're proposing is a degenerate case of what I'm proposing. I'm definitely not going to implement any sort of transformation layer where you can't strongly define both the input and the output types. The minute I publish your implementation of That said I can introduce some syntactic sugar that gets closer. Because you're right that the API is pretty wordy. I'm open to a const schema = z.any().transform(z.number(), x => Number(x));The current schema would define the allowed input and the first argument is the type you're converting to. Keep in mind that this method still returns a ZodTransformation instance. I like this a lot more since it feels extremely readable and you can see the data "flow" through Zod from left to right. Plus every type (both inputs and outputs) are still typed and enforced by Zod. |
|
@krzkaczor the output of the function would be pre-determined by the schema on which you call BTW I'm super open to a PR for opaque types. It's actually the oldest open issue currently: #3 |
|
@vriad Wow, this is great, I have been thinking the whole weekend about an api that would make compile safe factory functions possible for myzod schemas, and also allow the check method to work. It’s allmost identical to your api, and completely agree with your conclusions, this is awesome! I think with this design you can get the benefits of myzod without the problems I described here: |
Additional complicationsType guards
const stringToNumber = z.transformation(z.string(), z.number(), parseFloat);
const data = "12";
if(stringToNumber.check(data)){
data; // still a string
}I think perhaps typeguards aren't really compatible with any sort of coercion/transformation and it might be better just to get rid of them. @kasperpeulen UnionsNot sure how I didn't see this issue before. Consider a union of ZodTransformers: const transformerUnion = z.union([
z.transformer(z.string(), z.number(), x => parseFloat(x)),
z.transformer(z.string(), z.number().int(), x => parseInt(x)),
])What should happen when you do One solution is to have union unions return the value from the first of its child schemas that passes transformation/validation, in the order they were passed into Another solution is just to disallow passing transformers in unions (and any other types that would cause problems) 🤷♂️ |
|
I think this is a great idea, it's difficult to ensure at compile time that you've gotten a number from a form, instead of a string. I tried this out: const formSchema = z.object({
number: z.transformer(z.string(), z.number(), (data)=>parseFloat(data))
})but the {
"code": "invalid_type",
"expected": "number",
"message": "Expected number, received nan",
"path": [],
"received": "nan"
}which kind of ruins it for the exact case I'm looking for |
|
@blocka yeah that's a bug, that'd be fixed before this gets shipped. the alpha contains the dumbest possible implementation. |
👍 in |
|
I'll be digging deeper into this as I have time, but my first thought is that it would be nice to have async transformations. That is, you could do something like |
|
@vriad @gcanti Regarding type guards, so what I like about your implementation is that you have a check method for both the input and the output schema. const stringToNumber = z.transformer(z.string(), z.number(), parseFloat);
declare const data: unknown;
if (stringToNumber.input.check(data)){
data; // string now
}
if (stringToNumber.output.check(data)) {
data; // number now
}To have a One practical case, is that you may have a union, but not an easy discriminant on this union, then you can now use the check method of the output schema. const GetProject = object({
method: literal("GET"),
path: z.tuple([literal("api"), literal("project"), number()]),
});
const CreateProject = object({
method: literal("POST"),
path: tuple([literal("api"), literal("project")]),
body: projectSchema,
});
const UpdateProject = object({
method: literal("PUT"),
path: tuple([literal("api"), literal("project"), number()]),
body: projectSchema,
});
const DeleteProject = object({
method: literal("DELETE"),
path: tuple([literal("api"), literal("project"), number()]),
});
export const Routes = z.union([
GetProject,
CreateProject,
UpdateProject,
DeleteProject,
// GetTodo,
// CreateTodo,
]);
async function router(request: { method: string, url: string, body: unknown }) {
try {
const route = Routes.parse({...request, path: removePrefix(request.url, "/").split("/")});
if (GetProjects.check(route)) {
return await ProjectController.get(route.path[2]);
} else if (CreateProject.check(route)) {
return await ProjectController.create(route.body);
} else {
// etc.
}
} catch {
return await response404();
}
}However, with defaults, it is quite easy to add discriminants to your type, we are using this now in myzod: export const routesSchema = z.union([
object({
name: literal("GET_PROJECT").default(),
path: z.tuple([literal("api"), literal("project"), number()]),
method: literal("GET"),
}),
object({
name: literal("CREATE_PROJECT").default(),
path: tuple([literal("api"), literal("project")]),
method: literal("POST"),
body: projectSchema,
})
]); |
|
Are transforms supposed to bubble up the object trees? I'm not getting what I'm expecting. const ID = z.transformer(z.number(), z.string(), n => String(n));
const node = z.object({
id: ID
});
const result = node.parse({ id: 5 }); // returns { id: 5 } not { id: '5' }Interestingly, |
|
Another thought I'm having on this one is similar to #88. That is, it would be a pretty reasonable case to see an external tool parsing, validating, and creating error messages. Right now, all these things are run in zod in separate closures, which means that you have to plumb these things in multiple times, and pay the runtime cost multiple times as well. For the sake of example, let's say Date.parse throws an error that includes a "code" property instead of returning NaN when there is an invalid input. This is similar to what npm libraries sometimes do. const DateString = z.string().refine(s => {
try {
Date.parse(s);
return true;
} catch (e) {
return false;
}
}, 'need e.code here');
z.transformer(DateString, z.number(), s => Date.parse(s));I don't want to have to run Date.parse 2-3 times to parse each input. This example is fairly small, but for some types, the runtime cost could start adding up. It would be nice to have a single closure that can encompass (1) validation (2) error code generation, and (3) transformations. |
|
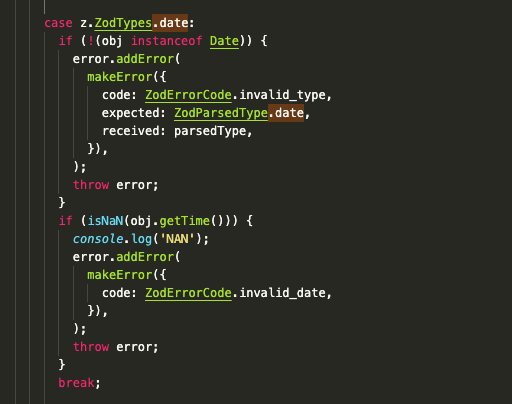
@chrbala This isn't documented but Zod doesn't allow invalid Dates. Here's the code from
So you can represent what you're describing with just this: const dateString = z.transformer(z.string(), s => !isNaN(Date.parse(s)));
const dateStringToNumber = z.string().transform(z.date(), s => new Date(s)).transform(z.number(), d => d.getTime());Each of these only does one Date.parse (or rather, And to your previous point: there's currently a bug in what gets returned from the parser. It's still using the old behavior of returning the exact same object you pass in. Whoops. I'm going to refactor the parser to return a deep clone of all inputs (to the greatest extent possible). |
|
This works for my usages const singleToArray = z
.transformer(
z.union([z.string(), z.array(z.string())]),
z.array(z.string()),
n => Array.isArray(n) ? n : [n]
)This is a really cool feature! I also love that it's type safe. It allows me to add flexibility into the inputs but narrow for the output. Edit: with a simple helper import * as z from "zod";
function singleToArray<T extends z.ZodType<any>>(arrayType: T) {
return z
.transformer(
z.union([arrayType, z.array(arrayType)]),
z.array(arrayType),
n => Array.isArray(n) ? n : [n]
)
}
const stringArrayWithSingle = singleToArray(z.string())
const result = stringArrayWithSingle.parse('5');
const parsed = stringArrayWithSingle.parse(['5']);
console.log(result, parsed) |
|
Perhaps Date was a poor example because it has a builtin type in Zod. I'm more interested in the broader case where parsing, error code generation, and transforming can all happen in the same closure (or provide sufficient context sharing, etc) with arbitrary types for convenience and performance. e.g. with simple-duration. (Again, let's say simple-duration has an error code which we can use in the refinement.) If the type refine fails, sd.parse is only run once here, but if it passes, it gets run in both the refine and the transformer. You can see it on this RunKit where the single Dates and simple-duration are of course fairly trivial data types, but conceivably there could be sufficiently complex data types (e.g. zipped data, etc) where doing multiple parses would eat into performance. Perhaps this point could be moved to a different issue, however. I could see |
|
Returning back to the issue of unions - what if there was an explicit resolver function like Perhaps z.union could be a variadic function that by default picks the first schema that matches left-to-right, but optionally can specify a second resolver argument. const float = z.transformer(z.string(), z.number(), x => parseFloat(x));
const int = z.transformer(z.string(), z.number().int(), x => parseInt(x));
const leftToRightNum = z.union([float, int]);
const withResolverNum = z.union([float, int], val =>
val % 1 === 0 ? int : float
);This is kind of a trivial example, but it would line up well for people who already do type resolutions with GraphQL in some way, and the explicitness is nice. |
|
@chrbala But what's |
|
I guess I was actually skipping a step there. That's the value that gets passed in to the schema, and I was forgetting that it wouldn't have yet been parsed to a number. So, more accurately: const float = z.transformer(z.string(), z.number(), x => parseFloat(x));
const int = z.transformer(z.string(), z.number().int(), x => parseInt(x));
const resolveType = (val: unknown) =>
typeof val === 'string' && parseFloat(val) % 1 === 0 ? int : float;
const number = z.union([float, int], resolveType);
number.parse('12.5');
|
|
The simple duration case I can see the issue, it's that you want the input to be a refined type, ie a string which can be parsed into a simple duration (which is a number type). The problem is conflating validity of the transform input vs transforming the result. It just so happens the method for doing those two things with simple-duration is the same. Let me break down two paths this problem could take For the sake of the example, let's say I am dealing with Percentages. I want to handle 1. Refined typesimport * as z from 'zod'
const percentageString = z.string().refine(val => /^\d?\d?\d%$/.test(val), 'Invalid % string')
const fractionOfOneString = z.string().refine(val => Number(val) >= 0 && Number(val) <= 1, 'Must be number between 0 and 1')
const fractionOfOne = z.number().refine(val => val >= 0 && val <= 1, 'Must be number between 0 and 1')
// Transformer handles very specific inputs
const percentage = z.transformer(z.union([percentageString, fractionOfOneString, fractionOfOne]), fractionOfOne, val => {
if(percentageString.check(val)) {
return Number(val.substr(0, val.length - 1)) / 100
}
if (fractionOfOneString.check(val)) {
return Number(val)
}
return val
})
console.log(percentage.parse('50%')) // 0.5
console.log(percentage.parse('0.5')) // 0.5
console.log(percentage.parse(0.5)) // 0.5Here we have created refined types which can represent each of the inputs we want to support. Then we have another type which can convert between those inputs and a desired type. 2. Transformer handling refinementsThe other option is to support raw unrefined inputs in the transformer, then throw the parser errors directly from the parser (@vriad unsure if this is how you should return errors inside transforms) import * as z from 'zod'
const fractionOfOne = z.number().refine(val => val >= 0 && val <= 1, 'Must be number between 0 and 1')
// Transformer handles any string or number
const percentage = z.transformer(z.union([z.string(), z.number()]), fractionOfOne, val => {
if(typeof val === 'string') {
if (/^\d?\d?\d%$/.test(val)) {
return Number(val.substr(0, val.length - 1)) / 100
}
if (Number(val) >= 0 && Number(val) <= 1) {
return Number(val)
}
throw new Error(`${val} is not a percentage string`)
}
if (fractionOfOne.check(val)) {
return val
}
throw new Error(`Cannot parse into a percentage: ${val}`)
})
console.log(percentage.parse('50%')) // 0.5
console.log(percentage.parse('0.5')) // 0.5
console.log(percentage.parse(0.5)) // 0.5
console.log(percentage.parse('0.5%')) // This will throwI think percentages are a really good example to demonstrate the purpose of this feature. (in my mind anyways). I see these two approaches as both valid, but @vriad may have other thoughts |
|
Wow, this is looking great!!! Instead of z.string()
.transform(val => val.trim())
.transform(val => val.toLowerCase())
.transform(val => val.slice(0,5)) |
|
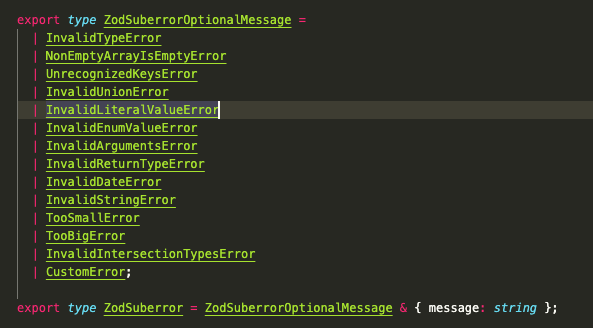
The root of the issue is that you can't throw "intentional" ZodErrors from inside transforms. Any error that gets thrown will be treated as unexpected. In the current implementation, Zod doesn't try to catch transformation errors, so when they occur a "true" system error will be thrown. I propose something like this: const Sqrt = z.number().transform(z.number(), (num, ctx)=>{
if(num < 0) return ctx.customError("Input must be positive");
return Math.sqrt(num);
})This would be functionally equivalent to this: const Sqrt = z.number()
.refine(num => num >= 0, "Input must be positive")
.transform(z.number(), (num)=>Math.sqrt(num))Blatantly ripping this off from Yup's This way, if the transformation function returns an instance of ZodError, the parser will incorporate that error into the standard ZodError handling pipeline. Any non-Zod errors will be thrown as "true errors". And if people want the ability to throw errors besides the const Doubler = z.number().transform(z.number(), (num, ctx)=>{
if(isNaN(num)) {
return ctx.makeError({
code: z.ZodErrorCode.invalid_type,
expected: z.ZodParsedType.number,
received: z.ZodParsedType.nan
});
}
return num * 2;
})The argument to
|
|
Makes sense! I have a couple thoughts:
|
|
@vriad awesome! With makeError/customError and it returning the deeply transformed object rather than the original I think this is pretty close to ready to go!
@chrbala check out my percentages example, here is it rewritten using the custom error function, also destructured the context, good idea import * as z from 'zod'
const fractionOfOne = z.number().refine(val => val >= 0 && val <= 1, 'Must be number between 0 and 1')
// Transformer handles any string or number
const percentage = z.transformer(z.union([z.string(), z.number()]), fractionOfOne, (val, { customError }) => {
if(typeof val === 'string') {
if (/^\d?\d?\d%$/.test(val)) {
return Number(val.substr(0, val.length - 1)) / 100
}
if (Number(val) >= 0 && Number(val) <= 1) {
return Number(val)
}
return makeError(`${val} is not a percentage string`)
}
if (fractionOfOne.check(val)) {
return val
}
return makeError(`Cannot parse into a percentage: ${val}`)
})
console.log(percentage.parse('50%')) // 0.5
console.log(percentage.parse('0.5')) // 0.5
console.log(percentage.parse(0.5)) // 0.5
console.log(percentage.parse('0.5%')) // This will throw |
|
I added a (really messy) implementation of transformations in a side project. I doesn't follow the RFC and is a little bit oversimplified, but maybe it is of any help. import * as z from 'zod';
export function parseAndTransform<T>(schema: z.ZodType<T>, value: unknown): T {
try {
return schema.parse(value);
} catch {}
const transformedValue = _parseAndTransform(schema, value);
return schema.parse(transformedValue);
}
function _parseAndTransform<T>(
schema: z.ZodType<T> | undefined,
value: unknown
): T | unknown {
if (!schema) {
return value;
}
const transform = transformByZodType[schema._def.t];
if (!transform) {
return value;
}
return transform(value, schema);
}
export const transformByZodType: {
[T in z.ZodTypes]?: (value: unknown, schema: z.ZodType<any>) => unknown;
} = {
[z.ZodTypes.number]: (v) => {
const n = Number(v);
if (!isNaN(n)) {
return n;
}
return v;
},
[z.ZodTypes.boolean]: (v) => {
return Boolean(v);
},
[z.ZodTypes.date]: (v, _s) => {
const s = _s as z.ZodDate;
if (s.check(v)) return v;
if (isString(v) || isNumber(v)) {
return new Date(v);
}
return v;
},
[z.ZodTypes.array]: (v, _s) => {
const s = _s as z.ZodArray<any>;
if (!isArrayLike(v) && !isIterable(v)) {
return v;
}
const array: unknown[] = Array.from(v);
return array.map((e) => {
return _parseAndTransform(s._def.type, e);
});
},
[z.ZodTypes.union]: (v, _s) => {
const s = _s as z.ZodUnion<any>;
for (const subSchema of s._def.options) {
const parsedValue = _parseAndTransform(subSchema, v);
if (s.check(parsedValue)) {
return parsedValue;
}
}
return v;
},
[z.ZodTypes.object]: (object, _s) => {
const s = _s as z.ZodObject<any>;
if (!isObject(object)) {
return object;
}
return Object.fromEntries(
Object.entries(object).map(([k, v]) => [
k,
_parseAndTransform(s._def.shape()[k], v),
])
);
},
[z.ZodTypes.record]: (object, _s) => {
const s = _s as z.ZodRecord;
if (!isObject(object)) {
return object;
}
return Object.fromEntries(
Object.entries(object).map(([k, v]) => [
k,
_parseAndTransform(s._def.valueType, v),
])
);
},
};
function isNumber(v: unknown): v is number {
return typeof v === 'number';
}
function isString(v: unknown): v is string {
return typeof v === 'string';
}
function isObject(v: unknown): v is string {
return typeof v === 'object';
}
function isArrayLike(v: unknown): v is ArrayLike<unknown> {
return isObject(v) && 'length' in (v as any);
}
function isIterable(v: unknown): v is Iterable<unknown> {
if (v == null) {
return false;
}
return isObject(v) && typeof v[Symbol.iterator] === 'function';
}Tests: import { parseAndTransform } from './parseAndTransform';
import * as z from 'zod';
describe('parseAndTransform', () => {
it('should transform numbers if possible', () => {
expect(parseAndTransform(z.number(), '1')).toEqual(1);
expect(() => parseAndTransform(z.number(), 'abc'))
.toThrowErrorMatchingInlineSnapshot(`
"1 validation issue(s)
Issue #0: invalid_type at
Expected number, received string
"
`);
});
it('should transform booleans', () => {
expect(parseAndTransform(z.boolean(), 1)).toEqual(true);
expect(parseAndTransform(z.boolean(), 0)).toEqual(false);
expect(parseAndTransform(z.boolean(), null)).toEqual(false);
});
it('should transform dates if possible', () => {
expect(parseAndTransform(z.date(), '2010-01-01')).toEqual(
new Date('2010-01-01')
);
expect(parseAndTransform(z.date(), 0)).toEqual(new Date(0));
expect(() => parseAndTransform(z.date(), true))
.toThrowErrorMatchingInlineSnapshot(`
"1 validation issue(s)
Issue #0: invalid_type at
Expected date, received boolean
"
`);
});
it('should transform arrays if possible', () => {
expect(parseAndTransform(z.array(z.number()), ['1', '2'])).toEqual([1, 2]);
expect(
parseAndTransform(z.array(z.number()), { 0: '1', length: 1 })
).toEqual([1]);
});
it('should transform unions if possible', () => {
expect(
parseAndTransform(z.union([z.number(), z.date()]), '2001-01-01')
).toEqual(new Date('2001-01-01'));
expect(parseAndTransform(z.union([z.number(), z.date()]), '123')).toEqual(
123
);
});
it('should transform objects if possible', () => {
expect(
parseAndTransform(
z.object({
a: z.number(),
b: z.string(),
c: z.boolean(),
}),
{
a: '1',
b: 's',
c: null,
}
)
).toEqual({
a: 1,
b: 's',
c: false,
});
});
it('should transform nested objects if possible', () => {
expect(
parseAndTransform(
z.object({
a: z.object({
b: z.number(),
}),
}),
{
a: {
b: '1',
},
}
)
).toEqual({
a: {
b: 1,
},
});
});
}); |
|
I have done more investigations and have come across the following 3 use cases, divided by separators: Is there something that could be done to improve deep structural sharing between the input and output types? It seems like allowing something like this would make certain patterns much easier. import * as z from 'zod';
const id = z.transformer(z.number(), z.string(), n => String(n));
const node = z.transformer(
z.object({
id,
}),
z.object({
ID: id,
}),
({ id }) => ({ ID: id })
);
node.parse({ id: 5 }); // would like { ID: "5" }, but this throws "Expected number, received string"How would you get both the input and output types for a schema? z.TypeOf is only one type. Maybe introspection into the schema to get the input and output runtime schemas would work well for both getting the schemas themselves and their associated TS types. e.g. const num = z.number();
const str = z.string();
const field = z.transformer(num, string, n => String(n));
const obj = z.object({
field,
});
field.getInput(); // num
field.getOutput(); // str
obj.getInput(); // equivalent of z.object({ field: z.number() });
obj.getOutput(); // equivalent of z.object({ field: z.string() });And in this case, getOutput() would preferably return the output types of all children in the schema, like the first section of this comment mentions. I see that there are
My inclination is that (1) would probably be useful and (2) might get overcomplicated quickly. And what’s to say that a sequence of transformations is what makes sense in (2), rather than a tree or graph shape. (2) seems too complex for zod to incorporate. |
|
Hi all, Firstly a big thanks for the library - its matching up to my current fp and meta-programming abilities quite well. I have been a huge fan of fp-ts and io-ts for a while, but every-time I went to use them I ended up just not having the time to invest in levelling up my functional abilities. Zod (and lodash/fp) have been the "just right" amount of learning & immediate productivity gain I needed :) (one day I hope to get back to some of the more "hardcore" fp patterns!) In any-case I wanted to share a snippet from my explorations (based on this thread and fumbling around) with transformations from the last 2 days. As it may give a perspective of how an fp-layman like myself might use them. import { cond, isBoolean } from 'lodash/fp'
/**
* Field Coercion Rules
* Note: the design goal here is to bake in some fault tolerance into our API adapters.
* We connect to things like Zapier and Airtable where Users have created solutions that don't necessarily
* match well with default parsing rules. As such we want to be able to adapt these over time and inject them.
*/
export const isTrueString = (data: string) => /^(?:true|x|\[x\]|y|yes|1)$/.test(data)
export const isFalseString = (data: string) => /^(?:false| |\[ \]|n|no|0)$/.test(data)
export const isZeroOrOne = (data: number) => data === 1 || data === 0
/**
* Coerce Types
* Every type Coercion method has a corresponding test method.
* We use this to test if we can coerce the type.
* Note: There must be a better way of doing this... it doesn't seem dry at all, but is fairly readable.
* When we write transforms for other types like Number or Array the coerce method
* and testCoerce method difference will likely be more pronounced.
*/
export const coerceBoolean = cond<any, boolean>([
[isBoolean, data => Boolean(data)],
[isTrueString, stubTrue],
[isFalseString, stubFalse],
[isZeroOrOne, isZeroOrOne]
])
export const testCoerceBoolean = cond<any, boolean>([
[isBoolean, stubTrue],
[isTrueString, stubTrue],
[isFalseString, stubTrue],
[isZeroOrOne, stubTrue],
[stubTrue, stubFalse]
])
/**
* Transforms
*/
export const zToBoolean = z
.any()
.refine(value => testCoerceBoolean(value), {
params: ??, // Not sure what to put here - I want 'value', but its out of scope -> any ideas?
message: "Cannot coerce value to boolean."
})
.transform(
z.boolean(),
(data) => coerceBoolean(data)
)
/*
* How I use it
*/
const usermodel = z
.object({
id: z.number(),
name: z.string(),
hasSignedUp: zToBoolean
})
const incomingData = {
id: 1234,
name: 'Dan',
hasSignedUp: 'yes'
}
function getUser(){
try {
return usermodel.parse(incomingData)
} catch (error) {
console.error(error)
throw new Error("boom") //Not sure if I need to do this :)
}
}Hopefully there is something useful here to give perspective to those further down the rabbit hole than I Thanks again for the great work people :) |
|
To throw a curveball into the discussion -- this could potentially be solved by having parametrisable schemas (see #153). That way, you can specify a string schema for the field which is coming in as a string, and validate as such. Then you have a typed object you can transform somehow outside the scope of this library, and the transformed type is an instance of the same type but with a different type parameter. Like so: // Foo comes in with an ISO 8601-encoded date string, but we want to return it as a Date object
export type Foo<T> = {
name: string
date: T
}
const fooSchema = <T>(valueSchema: z.ZodSchema<T>) => z.object({
name: z.string(),
date: valueSchema
})
function validateFoo(raw: unknown): Foo<Date> {
// First validate as ISO string, maybe using validator.js:
const fooWithDatesAsStrings: Foo<string> = fooSchema(z.string().refine(isISO8601)).parse(raw)
// Then transform using our own logic
return {
...fooWithDatesAsStrings,
date: new Date(fooWithDatesAsStrings.date)
}
}By separating the validation logic from the transformation logic, we avoid scope creep in the library, and allow more transformation flexibility. It probably keeps the internal types simpler too! |
|
Transformers are now in beta as part of Zod 2! https://github.com/vriad/zod/tree/v2 |
|
Thank you, looks great 🎉
For anyone stumbling upon it, a temporary solution is to use |
|
Yeah this is an issue with several methods, not just transformers. Notably You should either add those checks before the call z.string().min(5).transform(val => val.trim());
// OR
z.string().transform(z.string().min(5), val => val.trim());depending on your use case. |
|
Why should |
|
They don't break the "transform chain" but they return a different type than the original instance.
So you can't access ZodString methods on those. |
|
I just wanted to share the results of my experiments from a couple of weeks ago - the scope was specifically narrow and focused on coercion and what I may want such functions to do when they fail: pip-types. The code is fairly readable and the pattern basically goes:
The tests are not exhaustive and it was more an exploration in understanding how I would use transforms over building a library to be used. I am now pulling across some of this into my current client project. Hopefully this helps others 🐑 |
|
I recently started using Zod, so I'm new, and I hesitate to drop in on a long-running convo, but this thread has me wondering, is there no way to address the "chaining order matters" issue for strings? Requiring the user to understand that transforming a type or making it optional/nullable causes the string refinement helper functions to be unavailable seems non-developer-friendly. Seeing a typescript error for a string-specific refinement after I make the type optional is confusing even as a non-beginner and would feel like a bug. Optionality/nullability naturally comes first in validation ordering, since there's no point in testing a pattern or length when the value doesn't exist. Wouldn't it be cleaner and more understandable to remove support for the direct helpers and offer a set of Ultimately (if my understanding is correct) they're all just refinements and Just my thoughts as a Zod beginner. Love the lib. ❤️ |
@ntilwalli you can do that with the spread syntax. // validators.js
export const validateEmail = [
(val) => ...,
{
message: ...,
path: ...,
params: ...,
}
];// test.js
import { validateEmail } from "./validators.js";
const OptionalEmail = z.string().optional().refine(...validateEmail); |
|
@colinhacks I think this issue can be closed, given that |
|
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions. |
This is the proposed API for implementing data transformation functionality in Zod.
Proposed approach
No need to over complicate things. The problem to solve is how Zod should handle/support transformations from type A to type B. So I propose the creation of a new class
ZodTransformer. This class is a subtype ofZodType(so you can use it like any other schema —.refine,.parse, etc).Internally, instances of this class will have these properties
input: ZodType: an input schemaoutput: ZodType: an output schematransformer: (arg: T['_type']) => U['_type']: a transformer functionThere is only one transformer function, not a "transform chain" like in Yup (👋 @jquense). This makes it easier for Zod to statically type the function. Any sort of functional composition/piping can be done using libraries external to Zod.
You would create an instance using the
ZodTransformer.createstatic factory method (aliased toz.transformer):Usage
Coercing a string into a number.
.input/.output.transformmethodEvery ZodTransform instance will have a.transformmethod. This method lets you easily chain transforms, instead of requiring many nested calls toz.transform().Every ZodType instance (the base class for all Zod schemas) will have a
.transformmethod. This method lets you easily create a ZodTransform, using your current schema as the input:.toTransformerfunction.transformmethod has been moved to the base ZodType class instead of only existing on ZodTransform.As you can see above, the first method call is
.transformer(which is a factory function that returns a ZodTransform). All subsequent calls are to.transform()(a chainable method on the ZodTransformer class).To make the syntax for defining chains of transforms more consistent, I propose a
toTransformerfunction:With this you could rewrite
trimAndMultiplylike so:##.cleanThis section is now irrelevant and will now be implemented by overloading
.transform()There will be redundancy if you are chaining together transforms that don't cast/coerce the type. For instance:
I propose a
.cleanmethod that obviates the need for the redundantz.string()calls. Instead it usesthis.outputas both the input and output schema of the returned ZodTransform..default
Transformations make the setting of default values possible for the first time.
Complications
Separate input and output types
There are some tricky bits here. Before now, there was no concept of "input types" and "output types" for a Zod schema. Every schema was only associated with one type.
Now, ZodTransformers have different types for their inputs and outputs. There are issues with this. Consider a simple function schema:
This returns a simple function that checks if the input is more than 5. As you can see the call to
.implementautomatically infers/enforces the argument and return types (there's no need for a type signature onnum).Now what if we switch out the input (
z.number()) withstringToNumberfrom above?It's not really clear what should happen here. The function expects the input to be a number, but the transformer expects a string. Should myFunc("8") work?
Type guards
I think perhaps typeguards aren't really compatible with any sort of coercion/transformation and it might be better just to get rid of them. @kasperpeulen
Unions
Not sure how I didn't see this issue before.
Consider a union of ZodTransformers:
What should happen when you do
transformerUnion.parse('12.5')? Zod would need to choose which of the transformed values to return.One solution is to have union unions return the value from the first of its child schemas that passes transformation/validation, in the order they were passed into
z.union([arg1,arg2,etc]). In the example above it would return the float, and never even executeparseInt.Another solution is just to disallow passing transformers in unions (and any other types that would cause problems) 🤷♂️
Design consideration
One of my design considerations was trying to keep all data mutation/transformation fully contained within ZodTransformers. This leads to a level of verbosity that may be jarring. Instead of adding a
.default()method to every Zod schema, you have to "convert" your schema into a ZodTransformer first, then you can use its.defaultmethod yourself.Try it
Most of this has already been implemented in the alpha branch, so you can play around with it. Open to any questions or concerns with this proposal. 🤙
yarn add zod@alphaTagging for relevance: @krzkaczor @ivosabev @jquense @chrbala @JakeGinnivan @cybervaldez @tuchk4 @escobar5
The text was updated successfully, but these errors were encountered: