Thoughts on Architecture and Performance #33
Replies: 2 comments 3 replies
-
|
First, congrats on the shot! Sorry you're not feeling well :/ Please don't feel obligated to dig into this while you're feeling shitty. You're very kind for putting this level of thought and work in while not feeling well. So, back to the post; Beautifully documented. With regards to the current CPU utilization and Disk IO, I've had a few folks run this against their system starting from the root directory and it is not efficient whatsoever. Currently pretty taxing because it's not breaking up the load into separate workers at all.
Love this. That idea also opens up the opportunity to do just a portion of the work and collect the directory tree for further actions at a later date. Additionally this was my original hope for the approach to scanning systems. But when I started pillager I had a very fragile grasp of using go's concurrency model for worker fan-in fan-out. I'm still not great at it, but at least it makes more sense 😂
This is a brilliant idea. That would essentially take the current thought of a "rule system" and expand it towards a system that can pivot and take actions based on rules found, if I'm interpreting you correctly. This could easily get very complex, like you mentioned, so I think taking a good bit of care here to ensure the design starts with writing up a few interfaces and defining their methods might be a good way to think through the implementation of this in a "pseudo-code"-esque way. The whole architecture makes a lot of sense. The most logical path for implementing each of these to me is in discrete packages, if possible. That will keep the code easy to digest and very flexible for expansion. There is a lot of potential for it to turn into a bit of a rats nest if all the pieces get too tightly coupled but I am not too worried about it. I think we should be able to get a good separation of duties between the different stages and then allow the cmd/pillager package to be the consuming package that chains together the execution of these pieces. |
Beta Was this translation helpful? Give feedback.
-
That's alright, my mind is like a dog. I have to walk it every day even in the rain :P
I honestly am still getting used to Go concurrency. I'm so used to the thread model that its taken me some time to grasp its nuances. Interfaces are still really bizarre to me. Not in the sense that I don't know how to use them, but they just seem like black magic to me.
This has actually been on my mind and I have been thinking about adding a loopback layer between Tier 3 and 4. Basically, rather than have one hound routine directly calling another, it would be handed off to a loopback controller which would determine if it needs to be re-queed(looped back). This extra layer would provide a lot of transparency to how jobs are passing through the |

Beta Was this translation helpful? Give feedback.
-
|
This video is basically my bible for interfaces. Granted, I've never fully taken advantage of their potential but shout out to Todd McLeod for his awesome videos. I'm sure you already know the stuff in this video but hey, never hurts. https://www.youtube.com/watch?v=gfoVLXQ5ujM I like to use interfaces to explicitly document the methods offered by a given type and then hold myself accountable with an interface assignment so it'll check me at the compiler. I know you can use them to perform polymorphism but I've never utilized that functionality even though I genuinely would like to. // Check myself before I wreck myself
// at compile time and ensure my receiver methods
// are all exactly as documented
var _ Kenobi = grievous{}
type grievous struct {
Name string
}
// Kenobi contains the available methods for the
// howdy type
type Kenobi interface {
HelloThere() string
}
// HelloThere should greet general kenobi
func (g *grievous) HelloThere() string {
return fmt.Sprintf("Hello, there %s", h.Name)
}
Ohhhh yeah. For sure. Probably thinking we're gonna be using lots of
Wait groups for days. Also |
Beta Was this translation helpful? Give feedback.
-
I am primarily a functional programmer, so I don't have a ton of experience with OOP. Structuring everything as input-output keeps my code super modular and efficient. I think that comes from belief about KISS as well. Simple is always better in my opinion. I think OOP can be really powerful in certain cases but it can also overcomplicate simple tasks. That's typically why I avoid things like polymorphism because they obfuscate control flow and data interaction.
Yeah, channels will be the primary method of communication I imagine. I have had some interesting results shipping more complex objects into channels so I think it will depend on the specifics.
So I actually prefer semaphores, bounded channels, and worker pools consuming entries from a channel over wait groups. When I was building gomap(pure go nmap) I had some very bad experiences with wait groups. I found their behavior to be very inconsistent and slow in certain contexts. A worker pool consuming entries asynchronously from a channel blew the wait group implementation out of the water in terms of performance and consistency. This may have just been my particular use case but it definitely left an impression. Some links if you're interested: |
Beta Was this translation helpful? Give feedback.
-
I've honestly not implemented concurrency enough times to develop an opinion here so I'm super open to diving into this approach. So any input or ideas you have as this project goes along are very welcome as I'd like to improve here. I'll take a look at the links you've shared thanks for those!
Completely new to the functional programming approach, but again, it's just something I haven't explored as I have always thought in types and receiver methods. So curious to see your ideas here as well. My comfort zone is absolutely in OOP but it's mostly just that, a comfort zone so, not I'm not really attached to anything. Whatever fits the task. |
Beta Was this translation helpful? Give feedback.
-
Hi @brittonhayes,
I had some time today to think about Pillager architecture and control flow. I have mocked up a small diagram to illustrate what I am thinking. In full disclosure, yesterday I received my vaccine and I have been running a fever for the past 24. If any of this is a little incoherent it may be my fevered mind XD
To provide a little explanation of what you are looking at here:
Tier 1: This is the first and most asynchronous section. By using
godirwalk's unsorted non-deterministic tree traversal method, the dispatcher can deploy hundreds of tree crawling subroutines as it spiders. These routines are responsible for the high-level categorization of files and the first decision about whatHound Routinewill be dispatched for a particular file. The disk IO here is minimized slightly by the work ofgodirwalkbut this stage will be dominated by non-sequential disk seeks.Tier 2: This layer exists solely to reduce disk IO. Since the
godirwalkdispatcher is only seeking to files, not reading them, it can dispatch and traverse the file system much faster than the hound routines can read and analyze the files. By sending results to an intermediate accumulator/semaphore, expensive IO can be limited, preventing deadlocks and other OS issues. Also by feeding into separate semaphores, hound routines memory and CPU usage can be controlled on a much more detailed level.Tier 3: This by far is the largest and most computationally expensive section. In my current vision, hound routines are segmented modules designed to analyze a file in a particular way. For example, the
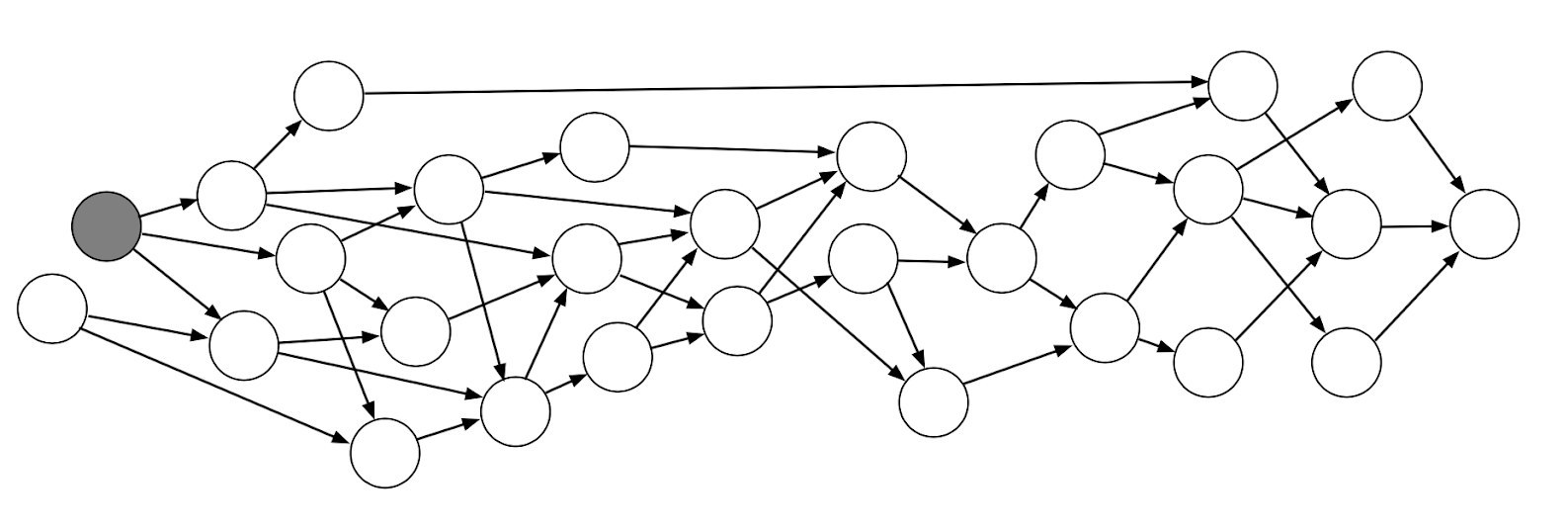 Basically this means that hound routines can trigger other hound routines if they detect certain parameters. While this adds another layer of complexity, it provides a radically more powerful solution in cases where the original dispatcher incorrectly categorizes a file or in the case the file is sufficiently complex that a multi-stage analysis would be preferable.
Basically this means that hound routines can trigger other hound routines if they detect certain parameters. While this adds another layer of complexity, it provides a radically more powerful solution in cases where the original dispatcher incorrectly categorizes a file or in the case the file is sufficiently complex that a multi-stage analysis would be preferable.
SSH_KEYhound routine would be responsible for parsing and collecting any suspected key files. As such, these modules can be stacked horizontally and easily expanded on as the project grows. Another property of hound routines is that they can operate "acyclically"(see below)Teir 4: The results accumulator doesn't warrant a huge amount of discussion and does exactly what it says. Since Go is great at this, this will be trivial to implement compared to other languages 🙏
Teir 5: Final results presentation and ultimate delivery appear to be something you have already solved in a really satisfactory way. We obviously want to make the results easy to read and easily ingestible by another program. Give all the options you have already, I think we are in a pretty solid position.
Beta Was this translation helpful? Give feedback.
All reactions