MongoDB & Sharding
- 저장되는 데이터 수가 많은가?
- 서비스의 타입
- 테이블의 관계가 중요한가?
네이버페이 (2019.11.04 기사 기준)
- 가입자수 : 3000만명
- 월 결제자 수(건수X) : 1000만명
- 결제자 당 하루 평균 5건의 가계부 데이터가 등록된다고 가정한다면 월 평균 5 x 30 x 1000만개(15억개)의 가계부 데이터가 등록됨. => 대용량 데이터의 처리가 필요
가계부 서비스 특성
- 등록과 조회의 작업 비중이 높다.
- 한번 등록된 내역은 수정되는 경우가 적다.
- 카테고리 재설정 정도?
- 이 부분은 팀원분들의 의견을 들어보고 싶습니다.
가계부 서비스와 관련해서 접목시켜 볼 수 있는 MongoDB의 장점은 아래와 같습니다.
- RDB에 비해 성능이 100배 이상 빠르다.
- 별도의 캐시 솔루션이 필요하지 않을 만큼 성능 문제에서 우월하다.
- 샤드 추가가 간편하다.
- MongoDB는 이미 shard를 위한 아키텍처가 설계되어 있으며 사용하기만 하면 된다. 새 node를 추가해도 자체 로직으로 데이터 분산이 이루어 진다.
-
대용량 데이터의 처리와 트래픽 분산을 위해서 샤딩같은 DB 클러스터링 기법을 적용해보고 싶습니다.
-
DB 클러스터링을 구현할 경우 조인이 필요한 데이터 구조 보다는 비정형의 데이터가 유리합니다. => 조인할 데이터가 어느 샤드에 있는지 관리하는 비용이 발생.
그렇게 되면 MySQL 같은 RDB 를 사용하는 이점이 줄어들 것이고 클러스터링이 어려운 MySQL 보다는 애초에 비정형의 데이터 구조에 유리하고 샤딩이 쉬운 MongoDB가 더 좋을 것 같습니다.
-
4.0 버전부터 Multi-Document Transaction이 지원됨.
하나의 거대한 데이터베이스 테이블을 수평 분할하여 여러 개의 작은 단위로 나눈 후, 물리적으로 다른 위치에 분산하여 저장·관리하는 기술
하나의 DB에 모든 데이터를 쌓게 될 경우
- 늘어나는 용량에 따라 느려지는 CRUD => 서비스 성능에 영향
- 모든 트래픽이 한 곳으로 모인다.
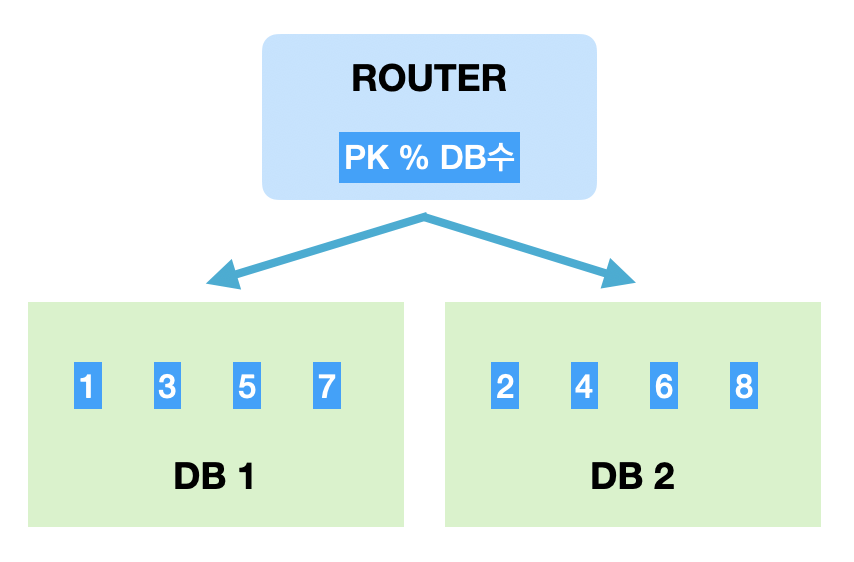
샤딩 Key(PK)를 모듈러 연산한 결과로 DB를 특정하는 방식.
- 장점 : 레인지샤딩에 비해 데이터가 균일하게 분산.
- 단점 : DB를 추가 증설하는 과정에서 이미 적재된 데이터의 재정렬이 필요.
모듈러샤딩은 데이터량이 일정 수준에서 유지될 것으로 예상되는 데이터 성격을 가진 곳에 적용할 때 어울리는 방식입니다. 데이터가 꾸준히 늘어날 수 있는 경우라도 적재속도가 그리 빠르지 않다면 모듈러방식을 통해 분산처리하는 것도 고려해볼 법 합니다. 무엇보다 데이터가 균일하게 분산된다는 점은 트래픽을 안정적으로 소화하면서도 DB리소스를 최대한 활용할 수 있는 방법이기 때문입니다.
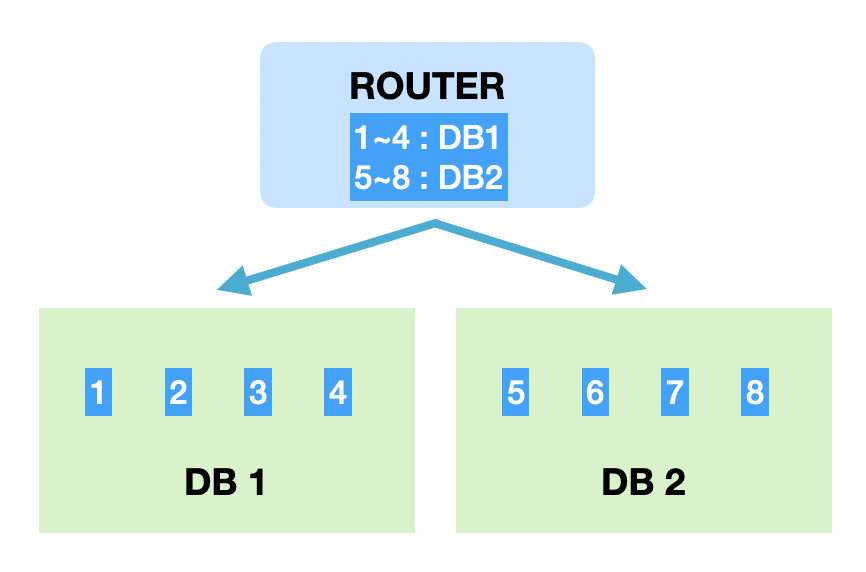
샤딩 Key(PK)의 범위를 기준으로 DB를 특정하는 방식.
- 장점 : 모듈러샤딩에 비해 기본적으로 증설에 재정렬 비용이 들지 않는다.
- 단점 : 일부 DB에 데이터가 몰릴 수 있다.
레인지샤딩의 가장 큰 장점은 증설작업에 드는 비용이 크지 않다는 점입니다. 데이터가 급격히 증가할 여지가 있다면 레인지방식도 좋은 선택. 다만 활성유저가 몰린 DB로 트래픽이나 데이터량이 몰릴 수 있고, 이런 상황이 발생하면 또 다시 부하분산을 위해 해당 DB를 재정렬하는 작업이 필요하고, 반대로 트래픽이 저조한 DB는 통합작업을 통해 유지비용을 아끼도록 관리해야 합니다.
가계부 서비스는 데이터가 꾸준히 증가하는 서비스기 때문에 modular 방식보다는 range 방식이 확장성 부분에서 유리할 것 같습니다. 그렇다면 샤딩 키를 어떤 기준으로 선정할 것인가를 고려해보아야 하는데
날짜를 기준으로 샤딩
가계부 서비스는 특성상 현재 시점과 근접한 데이터로의 접근이 빈번합니다. 이 경우 년도 같은 날짜를 기준으로 샤딩 키를 선정하면 최근 시점의 데이터를 담고 있는 특정 샤드로 트래픽이 몰리기 때문에 샤딩의 효과를 보기 어렵다고 생각됩니다.
유저를 기준으로 샤딩
유저 id를 기준으로 샤딩키를 선정하면 월 1000만명의 트래픽을 각 샤드로 균등하게 분배시킬 수 있습니다. 하지만 이 경우에는 가계부 데이터가 쌓이다 보면 대용량 데이터가 형성되고 샤드 내에서 다시 한번 샤딩이 필요한 시점이 오게 됩니다. 그리고 서비스 이용이 더 활발한 그룹의 샤드에 트래픽이 몰릴 수도 있을 것 같습니다.
혼합?
가계부 서비스를 생각해 봤을때 최근 시점에서 꽤 오래된 데이터에 접근하는 횟수가 잦을까? 라는 생각이 듭니다.
그래서 유저를 기준으로 샤딩을 한 다음 각 샤드 내에서 최근 데이터를 Hot 데이터, 예전 데이터를 Cold 데이터로 분리하여 저장하는 기법을 적용하는 것도 생각해 볼 수 있을 것 같습니다. 그러나 구현이 쉬울지는...
구현이 너무 어렵다면 유저를 기준으로 샤딩을 시키는 부분까지만 구현을 해봐도 큰 경험이 될 것 같아요.