You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
# pip install hnswlib # 安装hnswlib
import hnswlib
import numpy as np
# 同上iris数据集,前五个为blue类,中间5个为green类,最后5个为yellow类
dataset2 = np.array([
[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5. , 3.6, 1.4, 0.2],
[6.7, 3. , 5.2, 2.3],
[6.3, 2.5, 5. , 1.9],
[6.5, 3. , 5.2, 2. ],
[6.2, 3.4, 5.4, 2.3],
[5.9, 3. , 5.1, 1.8],
[5.5, 2.4, 3.7, 1. ],
[5.8, 2.7, 3.9, 1.2],
[6. , 2.7, 5.1, 1.6],
[5.4, 3. , 4.5, 1.5],
[6. , 3.4, 4.5, 1.6]
])
# 创建索引
def fit_hnsw_index(features, ef=100, M=16, save_index_file=False):
# Convenience function to create HNSW graph
# features : list of lists containing the embeddings
# ef, M: parameters to tune the HNSW algorithm
num_elements = len(features)
labels_index = np.arange(num_elements)
EMBEDDING_SIZE = len(features[0]) # Declaring index
# possible space options are l2, cosine or ip
p = hnswlib.Index(space='l2', dim=EMBEDDING_SIZE) # Initing index - the maximum number of elements should be known
p.init_index(max_elements=num_elements, ef_construction=ef, M=M) # Element insertion
int_labels = p.add_items(features, labels_index) # Controlling the recall by setting ef
# ef should always be > k
p.set_ef(ef)
# If you want to save the graph to a file
if save_index_file:
p.save_index(save_index_file)
return p
p = fit_hnsw_index(dataset2) # 创建 HNSW 索引
一、KNN(K最近邻算法)原理
一句话可以概括出KNN的算法原理:综合k个“邻居”的标签值作为新样本的预测值。
更具体来讲KNN分类,给定一个训练数据集,对新的样本Xu,在训练数据集中找到与该样本距离最邻近的K(下图k=5)个样本,以这K个样本的最多数所属类别(标签)作为新实例Xu的类别。
由上,可以总结出KNN算法有K值的选择、距离度量和决策方法等三个基本要素,如下分别解析:
1.1 距离度量
KNN算法用距离去度量两两样本间的临近程度,最终为新实例样本确认出最临近的K个实例样本(这也是算法的关键步骤),常用的距离度量方法有曼哈顿距离、欧几里得距离:
曼哈顿、欧几里得距离的计算方法很简单,就是计算两样本(x,y)的各个特征i间的总距离。
如下图(二维特征的情况)蓝线的距离即是曼哈顿距离(想象你在曼哈顿要从一个十字路口开车到另外一个十字路口实际驾驶距离就是这个“曼哈顿距离”,也称为城市街区距离),红线为欧几里得距离:
曼哈顿距离 与 欧几里得距离 同属于闵氏距离的特例(p=1为曼哈顿距离;p=2为欧氏距离)
在多数情况下,KNN使用两者的差异不大。在一些情况的差异如下:
除了曼哈顿距离、欧几里得距离,也可使用其他距离方法,衡量样本间的临近程度,具体可以看下这篇关于【距离度量】的介绍。
闵氏距离注意点:特征量纲差异问题
计算距离时,需要关注到特征量纲差异问题。假设各样本有年龄、工资两个特征变量,如计算欧氏距离的时候,(年龄1-年龄2)² 的值要远小于(工资1-工资2)² ,这意味着在不使用特征缩放的情况下,距离会被工资变量(大的数值)主导。因此,我们需要使用特征缩放来将全部的数值统一到一个量级上来解决此问题。通常的解决方法可以对数据进行“标准化”或“归一化”,对所有数值特征统一到标准的范围如0~1。

1.2 决策方法
决策方法就计算确认到新实例样本最邻近的K个实例样本后,如何确定新实例样本的标签值。
取K个”邻居“平均值或者多数决策的方法,其实也就是经验损失最小化。

1.3 K值的选择
k值是KNN算法的一个超参数,K的含义即参考”邻居“标签值的个数。
有个反直觉的现象,K取值较小时,模型复杂度(容量)高,训练误差会减小,泛化能力减弱;K取值较大时,模型复杂度低,训练误差会增大,泛化能力有一定的提高。
原因是K取值小的时候(如k==1),仅用较小的领域中的训练样本进行预测,模型拟合能力比较强,决策就是只要紧跟着最近的训练样本(邻居)的结果。但是,当训练集包含”噪声样本“时,模型也很容易受这些噪声样本的影响(如图 过拟合情况,噪声样本在哪个位置,决策边界就会画到哪),这样会增大"学习"的方差,也就是容易过拟合。这时,多”听听其他邻居“训练样本的观点就能尽量减少这些噪声的影响。K值取值太大时,情况相反,容易欠拟合。
对于K值的选择,通常可以网格搜索,采用交叉验证的方法选取合适的K值。
二、KNN算法实现
KNN有两种常用的实现方法:暴力搜索法,KD树法。
2.1 暴力搜索法
KNN实现最直接的方法就是暴力搜索(brute-force search),计算输入样本与每一个训练样本的距离,选择前k个最近邻的样本来多数表决。但是,当训练集或特征维度很大时,计算非常耗时,不太可行(对于D维的 N个样本而言,暴力查找方法的复杂度为 O(D*N) ) 。如下实现暴力搜索法的代码实现:
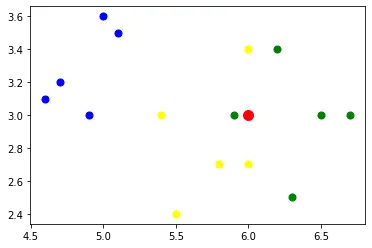
验证新的iris样本的分类效果(训练样本一共有3类:'blue’, 'green', ‘yellow’),输出新样本(红色点)的分类结果为yellow,并绘图表示:
2.2 KD树法
我们知道暴力搜索的缺点是,算法学习时只能盲目计算新样本与其他训练样本的两两距离确认出K个近邻,而近邻样本只是其中的某一部分,如何高效识别先粗筛出这部分?再计算这部分候选样本的距离。
一个解决办法是:利用KD树可以省去对大部分数据点的搜索,从而减少搜索的计算量,提高算法效率最优方法的时间复杂度为 O(n * log(n))。KD树实现KNN算法(主要为两步:1、构建KD树;2、利用KD树快速寻找K最近邻并决策。
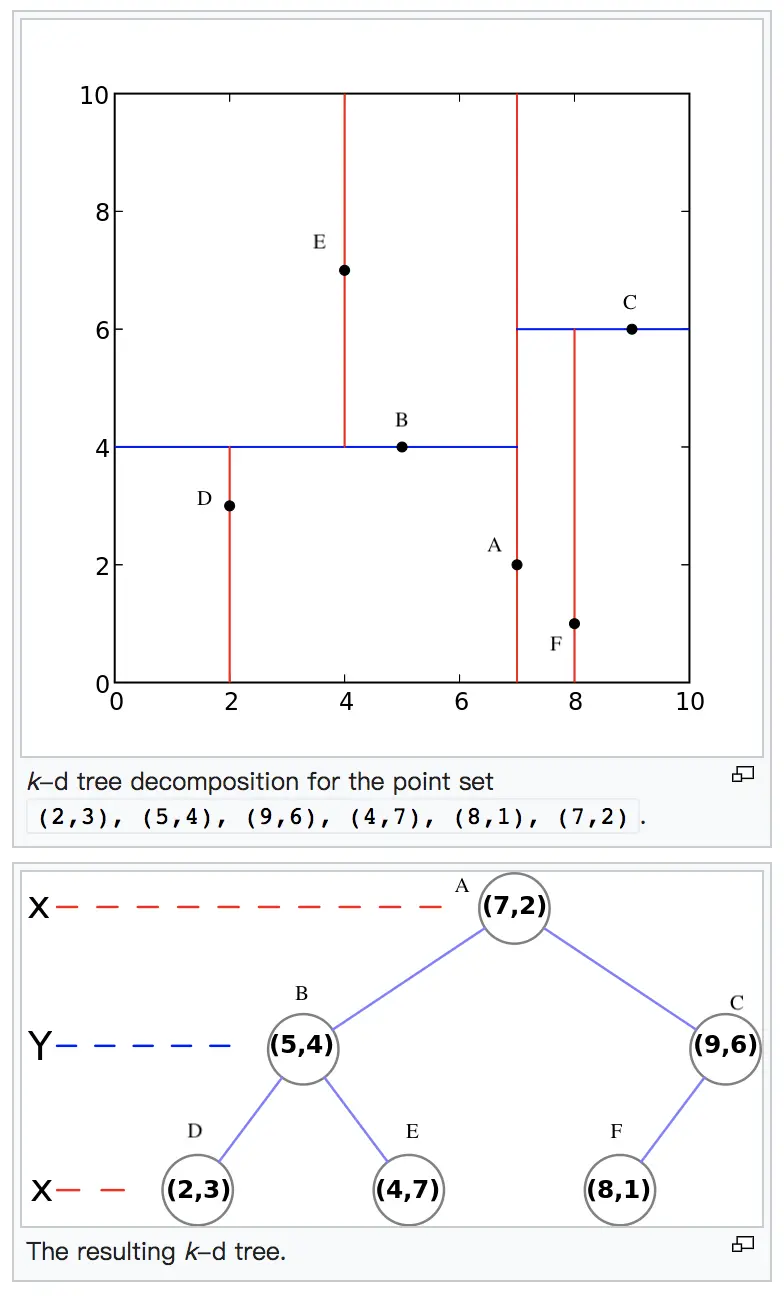
比如我们有二维样本6个,{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},构建kd树的具体步骤为:
1)找到划分的特征:6个数据点在x,y维度上的数据方差分别为6.97,5.37,所以在x轴上方差更大,用第1维特征建树。
2)确定划分中位数点(7,2):根据x维上的值将数据排序,6个数据的中值(所谓中值,即中间大小的值)为7,所以划分点的数据是(7,2)。这样,该节点的分割超平面就是通过(7,2)并垂直于:划分点维度的直线x=7;
3)确定左子空间和右子空间: 分割超平面x=7将整个空间分为两部分:x<=7的部分为左子空间,包含3个节点={(2,3),(5,4),(4,7)};另一部分为右子空间,包含2个节点={(9,6),(8,1)}。
4)用同样的办法划分左子树的节点{(2,3),(5,4),(4,7)}和右子树的节点{(9,6),(8,1)}。最终得到KD树。
最后得到的KD树如下:
当我们生成KD树以后,就可以去预测测试集里面的目标点(待预测样本)。对于一个目标点,我们首先在KD树里面找到对应包含目标点的叶子节点。以目标点为圆心,以目标点到叶子节点样本实例的距离为半径,得到一个超球体,最近邻的点一定在这个超球体内部。然后返回叶子节点的父节点,检查另一个子节点包含的超矩形体是否和超球体相交,如果相交就到这个子节点寻找是否有更加近的近邻,有的话就更新最近邻。如果不相交那就简单了,我们直接返回父节点的父节点,在另一个子树继续搜索最近邻。当回溯到根节点时,算法结束,此时保存的最近邻节点就是最终的最近邻。
从上面的描述可以看出,KD树划分后可以大大减少无效的最近邻搜索,很多样本点由于所在的超矩形体和超球体不相交,根本不需要计算距离。大大节省了计算时间。
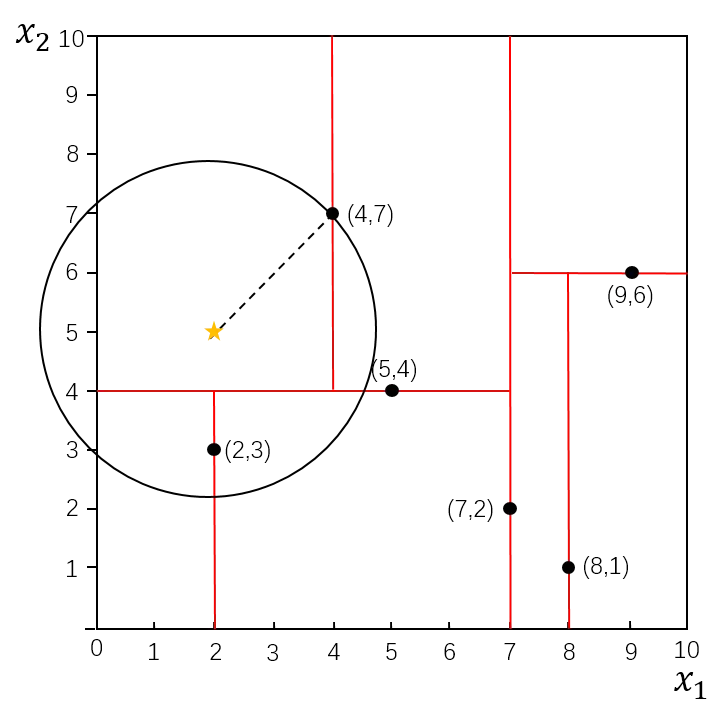
我们利用建立的KD树,具体来看对点(2,4.5)找最近邻的过程。
先进行二叉查找,先从(7,2)查找到(5,4)节点,在进行查找时是由y = 4为分割超平面的,由于查找点为y值为4.5,因此进入右子空间查找到(4,7),形成搜索路径<(7,2),(5,4),(4,7)>,但 (4,7)与目标查找点的距离为3.202,而(5,4)与查找点之间的距离为3.041,所以(5,4)为查询点的最近点; 以(2,4.5)为圆心,以3.041为半径作圆,如下图所示。可见该圆和y = 4超平面交割,所以需要进入(5,4)左子空间进行查找,也就是将(2,3)节点加入搜索路径中得<(7,2),(2,3)>;于是接着搜索至(2,3)叶子节点,(2,3)距离(2,4.5)比(5,4)要近,所以最近邻点更新为(2,3),最近距离更新为1.5;回溯查找至(5,4),直到最后回溯到根结点(7,2)的时候,以(2,4.5)为圆心1.5为半径作圆,并不和x = 7分割超平面交割,如下图所示。至此,搜索路径回溯完,返回最近邻点(2,3),最近距离1.5。
在KD树搜索最近邻的基础上,我们选择到了第一个最近邻样本,就把它置为已选。在第二轮中,我们忽略置为已选的样本,重新选择最近邻,这样跑k次,就得到了目标的K个最近邻,然后根据多数表决法,如果是KNN分类,预测为K个最近邻里面有最多类别数的类别。如果是KNN回归,用K个最近邻样本输出的平均值作为回归预测值。
三、KNN算法的优缺点
3.1 KNN的主要优点
1、算法简单直观,易于应用于回归及多分类任务
2、 对数据没有假设,准确度高,对异常点较不敏感
3、由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此适用于类域的交叉或非线性可分的样本集。
3.2 KNN的主要缺点
1、计算量大,尤其是样本量、特征数非常多的时候。另外KD树、球树之类的模型建立也需要大量的内存
2、只与少量的k相邻样本有关,样本不平衡的时候,对稀有类别的预测准确率低
3、 使用懒散学习方法,导致预测时速度比起逻辑回归之类的算法慢。当要预测时,就临时进行 计算处理。需要计算待分样本与训练样本库中每一个样本的相似度,才能求得与 其最近的K个样本进行决策。
4、与决策树等方法相比,KNN无考虑到不同的特征重要性,各个归一化的特征的影响都是相同的。
5、 相比决策树、逻辑回归模型,KNN模型可解释性弱一些
6、差异性小,不太适合KNN集成进一步提高性能。
四、KNN算法扩展方法
4.1 最近质心算法
这个算法比KNN还简单。它首先把样本按输出类别归类。对于第 L类的CL个样本。它会对这CL个样本的n维特征中每一维特征求平均值,最终该类别以n个平均值形成所谓的质心点。同理,每个类别会最终得到一个质心点。
当我们做预测时,仅仅需要比较预测样本和这些质心的距离,最小的距离对于的质心类别即为预测的类别。这个算法通常用在文本分类处理上。
4.2 ANN
将最近邻算法扩展至大规模数据的方法是使用 ANN 算法(Approximate Nearest Neighbor),以彻底避开暴力距离计算。ANN 是一种在近邻计算搜索过程中允许少量误差的算法,在大规模数据情况下,可以在短时间内获得卓越的准确性。ANN 算法有以下几种:Spotify 的 ANNOY、Google 的 ScaNN、Facebook的Faiss 以及 HNSW 等 ,如下具体介绍HNSW。
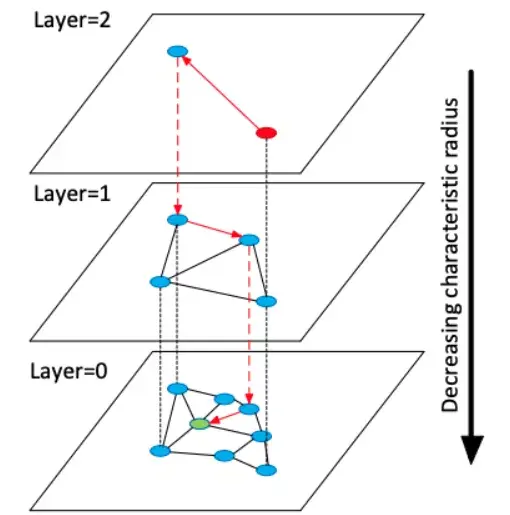
HNSW 是一种基于多层图的 ANN 算法。在插入元素阶段,通过指数衰减概率分布随机选择每个元素的最大层,逐步构建 HNSW 图。这确保 layer=0 时有很多元素能够实现精细搜索,而 layer=2 时支持粗放搜索的元素数量少了 e^-2。最近邻搜索从最上层开始进行粗略搜索,然后逐步向下处理,直至最底层。使用贪心图路径算法遍历图,并找到所需邻居数量。
可以通过hnswlib库简单使用ANN算法(hnswlib还常应用于大规模向量相似度计算),如下iris花示例代码:
创建索引后,通过索引快速查询到k个近似近邻(Approximate Nearest Neighbor),在示例数据集的结果与KNN算法的结果是一样的,近邻的样本索引是[9,12,14],也就是大部分近邻(即第12,14个样本)为“yellow”,最后分类为“yellow”。
文章首发公众号“算法进阶”,公众号阅读原文可访问文章相关代码
The text was updated successfully, but these errors were encountered: