You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
# 举例:特征加工
from pyspark.ml.feature import VectorAssembler
featuresCreator = VectorAssembler(
inputCols=[col[0] for col in labels[2:]] + [encoder.getOutputCol()],
outputCol='features'
)
一、大数据框架及Spark介绍
1.1 大数据框架
2003年,Google公布了3篇大数据奠基性论文,为大数据存储及分布式处理的核心问题提供了思路:非结构化文件分布式存储(GFS)、分布式计算(MapReduce)及结构化数据存储(BigTable),并奠定了现代大数据技术的理论基础,而后大数据技术便快速发展,诞生了很多日新月异的技术。
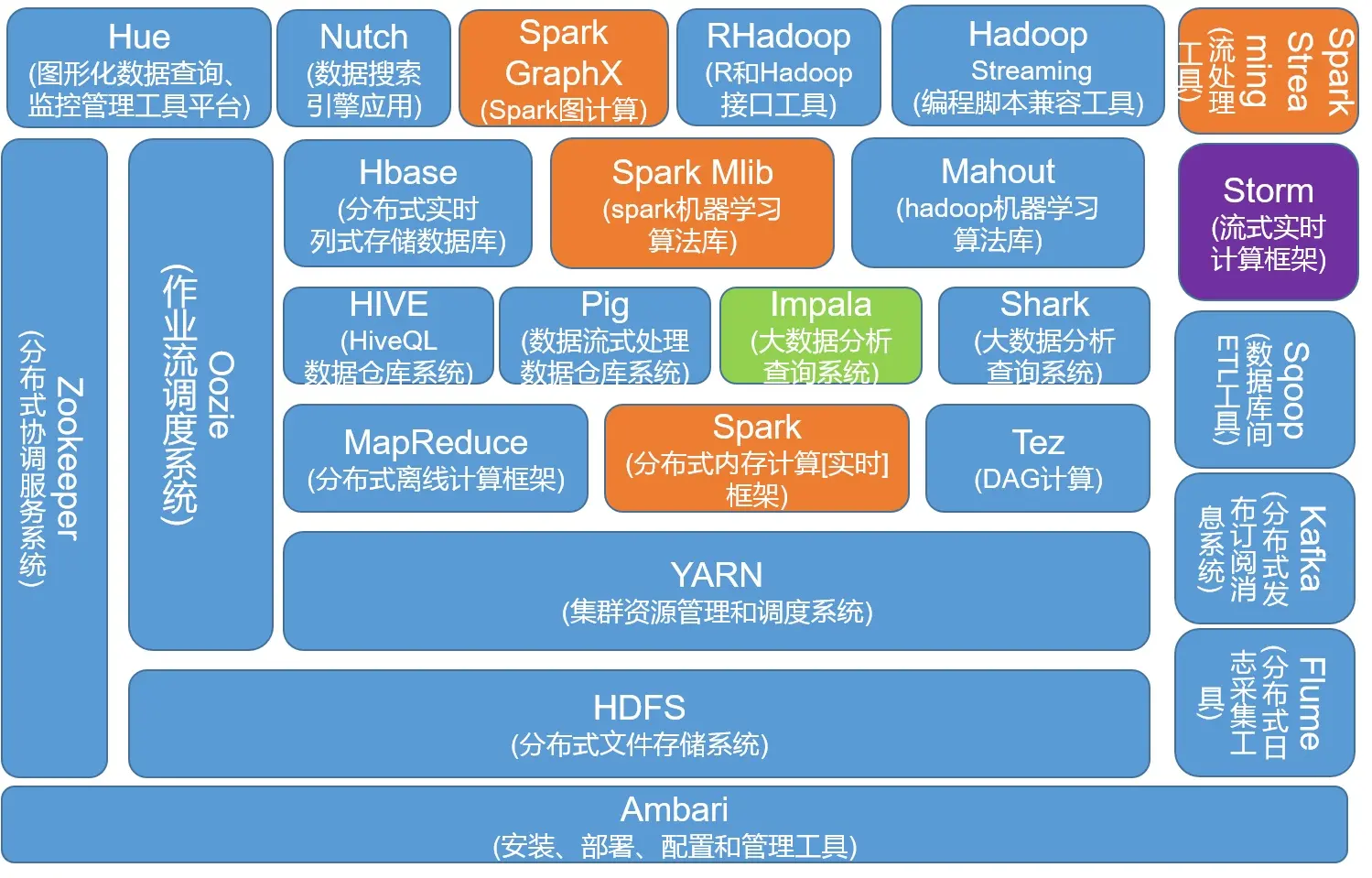
归纳现有大数据框架解决的核心问题及相关技术主要为:
1.2 Spark的介绍
Spark是一个分布式内存批计算处理框架,Spark集群由Driver, Cluster Manager(Standalone,Yarn 或 Mesos),以及Worker Node组成。对于每个Spark应用程序,Worker Node上存在一个Executor进程,Executor进程中包括多个Task线程。
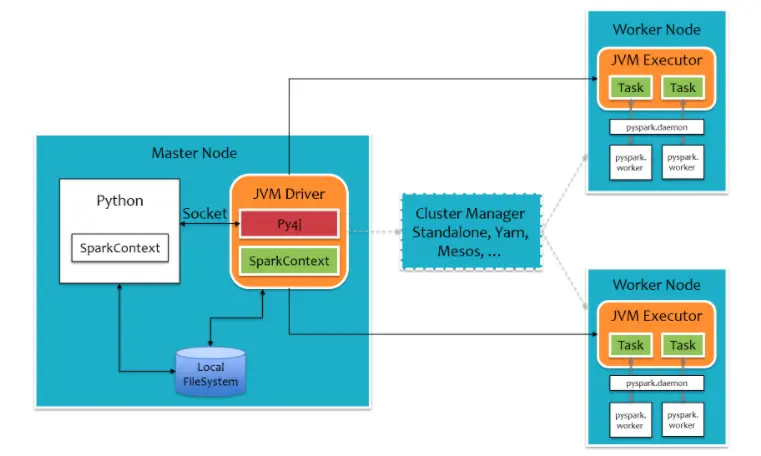
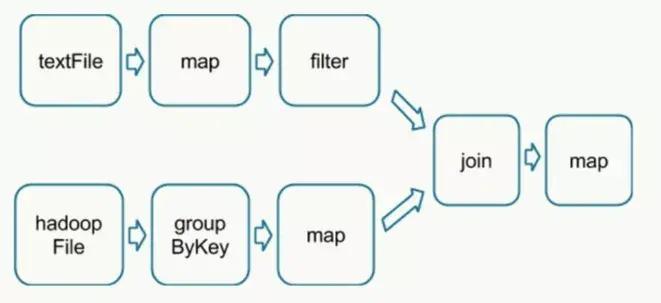
在执行具体的程序时,Spark会将程序拆解成一个任务DAG(有向无环图),再根据DAG决定程序各步骤执行的方法。该程序先分别从textFile和HadoopFile读取文件,经过一些列操作后再进行join,最终得到处理结果。
PySpark是Spark的Python API,通过Pyspark可以方便地使用 Python编写 Spark 应用程序, 其支持 了Spark 的大部分功能,例如 Spark SQL、DataFrame、Streaming、MLLIB(ML)和 Spark Core。
二、PySpark分布式机器学习
2.1 PySpark机器学习库
Pyspark中支持两个机器学习库:mllib及ml,区别在于ml主要操作的是DataFrame,而mllib操作的是RDD,即二者面向的数据集不一样。相比于mllib在RDD提供的基础操作,ml在DataFrame上的抽象级别更高,数据和操作耦合度更低。
pyspark.ml训练机器学习库有三个主要的抽象类:Transformer、Estimator、Pipeline。
2.2 PySpark分布式机器学习原理
在分布式训练中,用于训练模型的工作负载会在多个微型处理器之间进行拆分和共享,这些处理器称为工作器节点,通过这些工作器节点并行工作以加速模型训练。 分布式训练可用于传统的 ML 模型,但更适用于计算和时间密集型任务,如用于训练深度神经网络。分布式训练有两种主要类型:数据并行及模型并行,主要代表有Spark ML,Parameter Server和TensorFlow。
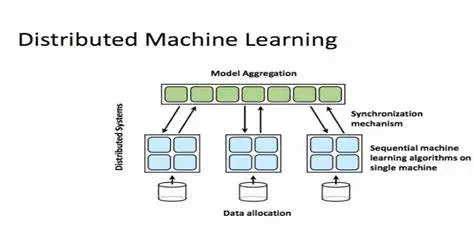
spark的分布式训练的实现为数据并行:按行对数据进行分区,从而可以对数百万甚至数十亿个实例进行分布式训练。 以其核心的梯度下降算法为例:
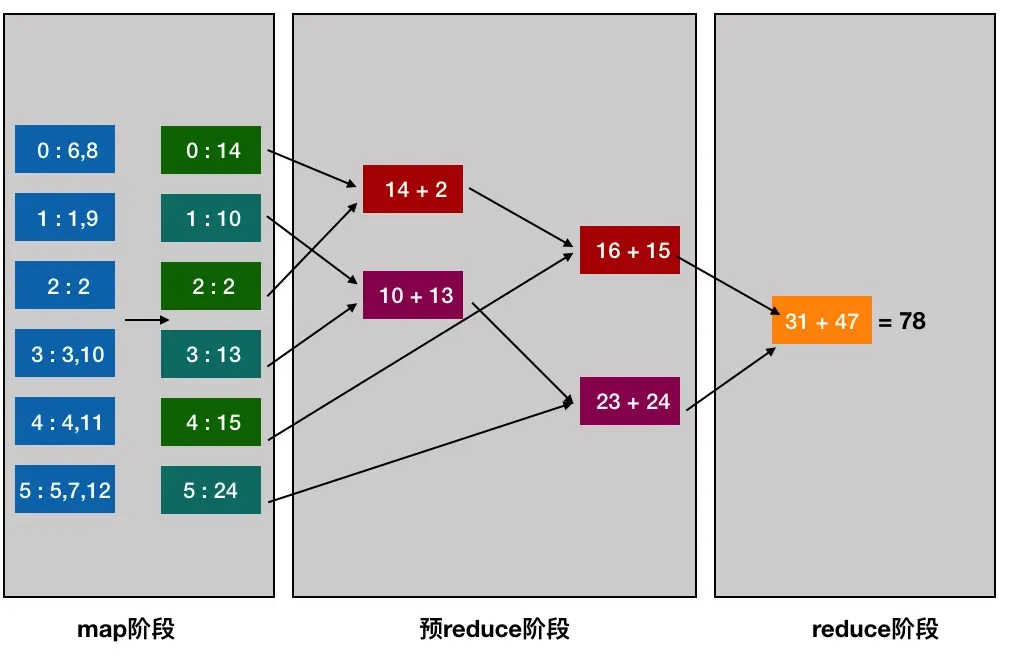
1、首先对数据划分至各计算节点;
2、把当前的模型参数广播到各个计算节点(当模型参数量较大时会比较耗带宽资源);
3、各计算节点进行数据抽样得到mini batch的数据,分别计算梯度,再通过treeAggregate操作汇总梯度,得到最终梯度gradientSum;
4、利用gradientSum更新模型权重(这里采用的阻断式的梯度下降方式,当各节点有数据倾斜时,每轮的时间起决于最慢的节点。这是Spark并行训练效率较低的主要原因)。
PySpark项目实战
本项目通过PySpark实现机器学习建模全流程:数据的载入,数据分析,特征加工,二分类模型训练及评估。
文章首发于算法进阶,公众号阅读原文可访问GitHub项目源码
The text was updated successfully, but these errors were encountered: