Collected notes from: 3 Quick Ways To Compare Data with Python.
Photo by Franki Chamaki on Unsplash
you could comapre two numeric files in Excel - of course. But it consumes much time and energy.
years ago, I used to build VBA to compare cell by cell, and have logic returns which imply if two cells are the same - it's faster, but troublesome to code the 'old-fashioned' VBA scripts.
The original article introduces a Python-based approach to quickly compare two files, this is the focus of this note. \
- Check the integrity of data
-
- MD5 Checksum: returns a hexadecimal number for the contents of a file.
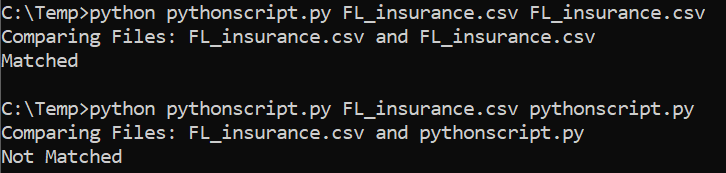
import hashlib, sys files = [sys.argv[1], sys.argv[2]] #these are the arguments we take def md5(fname): md5hash = hashlib.md5() with open(fname) as handle: #opening the file one line at a time for memory considerations for line in handle: md5hash.update(line.encode('utf-8')) return(md5hash.hexdigest()) print('Comparing Files:',files[0],'and',files[1]) if md5(files[0]) == md5(files[1]): print('Matched') else: print('Not Matched')Running above gives: \
-
- the SHA1 algorithm: another hexadecimal algorithm that converts file contents into a string.
import hashlib, sys files = [sys.argv[1], sys.argv[2]] #these are the arguments we take def sha1(fname): sha1hash = hashlib.sha1() with open(fname) as handle: #opening the file one line at a time for memory considerations for line in handle: sha1hash.update(line.encode('utf-8')) return(sha1hash.hexdigest()) print('Comparing Files:',files[0],'and',files[1]) if sha1(files[0]) == sha1(files[1]): print('Matched') else: print('Not Matched')Running above gives: \

- Check data contents with SQL\ Using a couple of Python libraries, we can import our files into an SQL database, and use the Except Operator to highlight any differences.\ * The only thing to note is that Except expects the data to be ordered; otherwise, it will highlight everything as a difference.
import sys, sqlite3, pandas as pd
files = [sys.argv[1], sys.argv[2]] #these are the arguments we take
conn = sqlite3.connect(':memory:') #we are spinning an SQL db in memory
cur = conn.cursor()
chunksize = 10000
i=0
for file in files:
i = i+1
for chunk in pd.read_csv(file, chunksize=chunksize): #load the file in chunks in case its too big
chunk.columns = chunk.columns.str.replace(' ', '_') #replacing spaces with underscores for column names
chunk.to_sql(name='file' + str(i), con=conn, if_exists='append')
print('Comparing', files[0], 'to', files[1]) #Compare if all data from File[0] are present in File[1]
cur.execute( '''SELECT * FROM File1
EXCEPT
SELECT * FROM File2''')
i=0
for row in cur:
print(row)
i=i+1
if i==0: print('No Differences')
print('Comparing', files[1], 'to', files[0]) #Compare if all data from File[1] are present in File[0]
cur.execute( '''SELECT * FROM File2
EXCEPT
SELECT * FROM File1''')
i=0
for row in cur:
print(row)
i=i+1
if i==0: print('No Differences')
cur.close()
Running above gives: \

- Check data contents with Pandas\
* prepare data in a dataframe
-
Using the .equals() method
import sys, sqlite3, pandas as pd files = [sys.argv[1], sys.argv[2]] #these are the arguments we take df1 = pd.read_csv(files[0]) df2 = pd.read_csv(files[1]) df3 = df1.equals(df2) print('Matches:', df3)Running above gives: \
-
Using the .any()
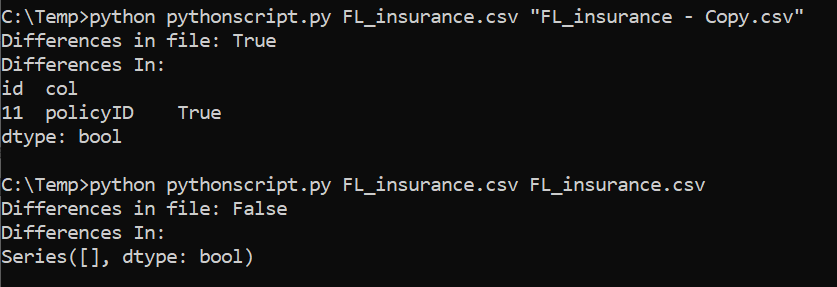
import sys, sqlite3, pandas as pd files = [sys.argv[1], sys.argv[2]] #these are the arguments we take df1 = pd.read_csv(files[0]) df2 = pd.read_csv(files[1]) df3 = (df1 != df2).any(axis=None) print('Differences in file:', df3) df3 = (df1 != df2).any(1) ne_stacked = (df1 != df2).stack() changed = ne_stacked[ne_stacked] changed.index.names = ['id', 'col'] print('Differences In:') print(changed)Running above gives: \
-
Using the .Eq()
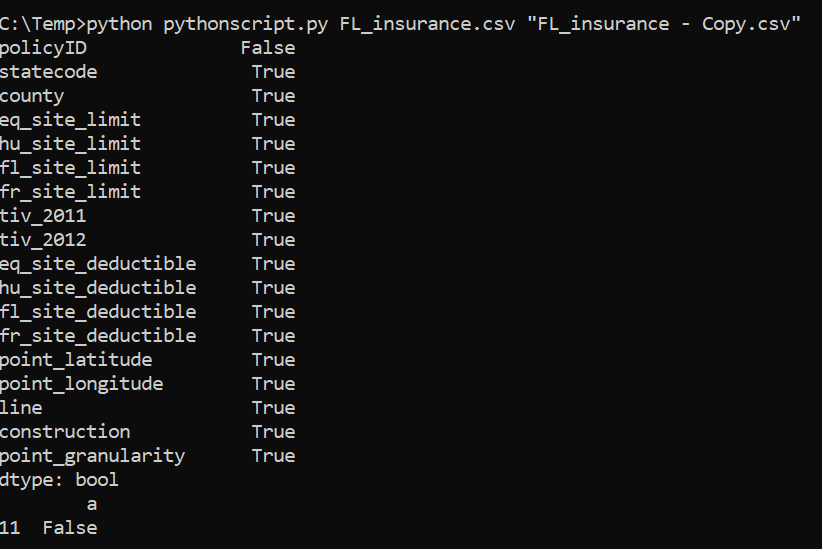
Running above gives: \import sys, sqlite3, pandas as pd, numpy as np files = [sys.argv[1], sys.argv[2]] #these are the arguments we take df1 = pd.read_csv(files[0]) df2 = pd.read_csv(files[1]) df3 = df1.eq(df2) print(df3.all()) #print(df3.all(axis=1)) df4 = df3.all(axis=1) df4 = pd.DataFrame(df4, columns=['Columns']) print(df4[df4['Columns']==False]) -