https://www.cnblogs.com/The-explosion/p/13392630.html 编程语言 1、编程语言
编程语言(programming language)是用来定义计算机程序的形式语言。它是一种被标准化的交流技巧,用来向CPU发出指令。
编程语言的描述一般可以分为语法及语义。语法是说明编程语言中,哪些符号或文字的组合方式是正确的,语义则是对于编程的解释。
2、语言分类
编程语言俗称“计算机语言”,种类非常的多,总的来说可以分成机器语言、汇编语言、高级语言三大类。电脑每做的一次动作,一个步骤,都是按照已经用计算机语言编好的程序来执行的,程序是计算机要执行的指令的集合,而程序全部都是用我们所掌握的语言来编写的。所以人们要控制计算机一定要通过 计算机语言向计算机发出命令。 目前通用的编程语言有两种形式: 汇编语言和 高级语言。
有许多用于特殊用途的语言,只在特殊情况下使用。例如,PHP专门用来显示网页;Perl更适合文本处理;C语言被广泛用于操作系统和编译器的开发(所谓的系统编程)。
编程语言有很多种,常用的有C语言、C++、Java、C#、Python、PHP、JavaScript、Go语言、Objective-C、Swift、汇编语言等,每种语言都有自己擅长的方面,例如:

2.1、机器语言
机器语言由于计算机内部只能接受 二进制代码,因此,用二进制代码0和1描述的指令称为 机器指令,全部机器指令的集合构成计算机的机器语言,用机器语言 编程的程序称为 目标程序。只有 目标程序才能被计算机直接识别和执行。但是机器语言编写的程序无明显特征,难以记忆,不便阅读和书写,且依赖于具体机种,局限性很大,机器语言属于低级语言。
2.2、汇编语言
汇编语言的实质和机器语言是相同的,都是直接对 硬件操作,只不过指令采用了英文缩写的标识符,更容易识别和记忆。它同样需要编程者将每一步具体的操作用命令的形式写出来。
汇编程序通常由三部分组成: 指令、 伪指令和 宏指令。 汇编程序的每一句指令只能对应实际操作过程中的一个很细微的动作。例如移动、自增,因此汇编源程序一般比较冗长、复杂、容易出错,而且使用汇编语言编程需要有更多的计算机专业知识,但汇编语言的优点也是显而易见的,用汇编语言所能完成的操作不是一般高级语言所能够实现的,而且源程序经汇编生成的 可执行文件不仅比较小,而且执行速度很快。
2.3、高级语言
高级语言是大多数 编程者的选择。和汇编语言相比,它不但将许多相关的 机器指令合成为单条指令,并且去掉了与具体操作有关但与完成工作无关的细节,例如使用 堆栈、 寄存器等,这样就大大简化了程序中的指令。同时,由于省略了很多细节, 编程者也就不需要有太多的专业知识。
高级语言主要是相对于汇编语言而言,它并不是特指某一种具体的语言,而是包括了很多编程语言,像最简单的编程语言 PASCAL语言也属于高级语言。
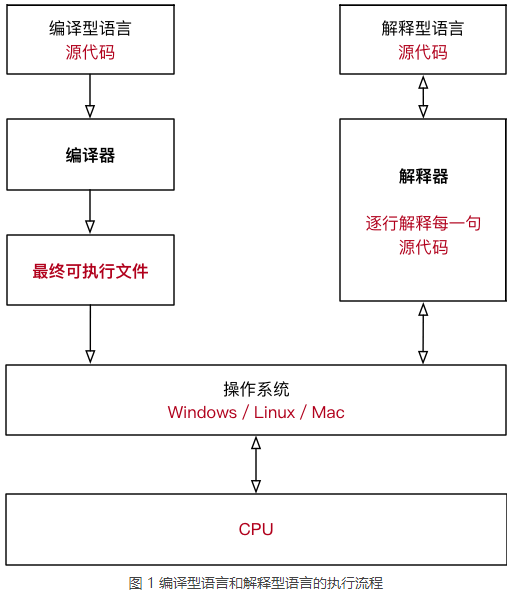
高级语言所编制的程序不能直接被计算机识别,必须经过转换才能被执行,按转换方式可将它们分为编译型语言和解释型语言。
(1)编译型语言
编译是指在应用源程序执行之前,就将程序源代码“翻译”成目标代码(机器语言),因此其目标程序可以脱离其语言环境独立执行,使用比较方便、效率较高。但应用程序一旦需要修改,必须先修改源代码,再重新编译生成新的目标文件(* .obj,也就是 OBJ文件)才能执行,只有目标文件而没有源代码,修改很不方便。
对于编译型语言,开发完成以后需要将所有的源代码都转换成可执行程序,比如 Windows 下的.exe文件,可执行程序里面包含的就是机器码。只要我们拥有可执行程序,就可以随时运行,不用再重新编译了,也就是“一次编译,无限次运行”。
在运行的时候,我们只需要编译生成的可执行程序,不再需要源代码和编译器了,所以说编译型语言可以脱离开发环境运行。
编译型语言一般是不能跨平台的,也就是不能在不同的操作系统之间随意切换。编译型语言不能跨平台表现在两个方面:
1) 可执行程序不能跨平台
可执行程序不能跨平台很容易理解,因为不同操作系统对可执行文件的内部结构有着截然不同的要求,彼此之间也不能兼容。不能跨平台是天经地义,能跨平台反而才是奇葩。
比如,不能将 Windows 下的可执行程序拿到 Linux 下使用,也不能将 Linux 下的可执行程序拿到 Mac OS 下使用(虽然它们都是类 Unix 系统)。
另外,相同操作系统的不同版本之间也不一定兼容,比如不能将 x64 程序(Windows 64 位程序)拿到 x86 平台(Windows 32 位平台)下运行。但是反之一般可行,因为 64 位 Windows 对 32 位程序作了很好的兼容性处理。
2) 源代码不能跨平台
不同平台支持的函数、类型、变量等都可能不同,基于某个平台编写的源代码一般不能拿到另一个平台下编译。我们以C语言为例来说明。
【实例1】在C语言中要想让程序暂停可以使用“睡眠”函数,在 Windows 平台下该函数是 Sleep(),在 Linux 平台下该函数是 sleep(),首字母大小写不同。其次,Sleep() 的参数是毫秒,sleep() 的参数是秒,单位也不一样。
以上两个原因导致使用暂停功能的C语言程序不能跨平台,除非在代码层面做出兼容性处理,非常麻烦。
【实例2】虽然不同平台的C语言都支持 long 类型,但是不同平台的 long 的长度却不同,例如,Windows 64 位平台下的 long 占用 4 个字节,Linux 64 位平台下的 long 占用 8 个字节。
我们在 Linux 64 位平台下编写代码时,将 0x2f1e4ad23 赋值给 long 类型的变量是完全没有问题的,但是这样的赋值在 Windows 平台下就会导致数值溢出,让程序产生错误的运行结果。
让人苦恼的,这样的错误一般不容易察觉,因为编译器不会报错,我们也记不住不同类型的取值范围。
(2)解释型语言
执行方式类似于我们日常生活中的“ 同声翻译”,应用程序源代码一边由相应语言的 解释器“翻译”成目标代码(机器语言),一边执行,因此效率比较低,而且不能生成可独立执行的 可执行文件,应用程序不能脱离其解释器,但这种方式比较灵活,可以动态地调整、修改应用程序。如较早时期的 Qbasic语言。
对于解释型语言,每次执行程序都需要一边转换一边执行,用到哪些源代码就将哪些源代码转换成机器码,用不到的不进行任何处理。每次执行程序时可能使用不同的功能,这个时候需要转换的源代码也不一样。
因为每次执行程序都需要重新转换源代码,所以解释型语言的执行效率天生就低于编译型语言,甚至存在数量级的差距。计算机的一些底层功能,或者关键算法,一般都使用 C/C++ 实现,只有在应用层面(比如网站开发、批处理、小工具等)才会使用解释型语言。
在运行解释型语言的时候,我们始终都需要源代码和解释器,所以说它无法脱离开发环境。
当我们说“下载一个程序(软件)”时,不同类型的语言有不同的含义:
对于编译型语言,我们下载到的是可执行文件,源代码被作者保留,所以编译型语言的程序一般是闭源的。 对于解释型语言,我们下载到的是所有的源代码,因为作者不给源代码就没法运行,所以解释型语言的程序一般是开源的。
相比于编译型语言,解释型语言几乎都能跨平台,“一次编写,到处运行”是真是存在的,而且比比皆是。那么,为什么解释型语言就能快平台呢?这一切都要归功于解释器!
我们所说的跨平台,是指源代码跨平台,而不是解释器跨平台。解释器用来将源代码转换成机器码,它就是一个可执行程序,是绝对不能跨平台的。
官方需要针对不同的平台开发不同的解释器,这些解释器必须要能够遵守同样的语法,识别同样的函数,完成同样的功能,只有这样,同样的代码在不同平台的执行结果才是相同的。
你看,解释型语言之所以能够跨平台,是因为有了解释器这个中间层。在不同的平台下,解释器会将相同的源代码转换成不同的机器码,解释器帮助我们屏蔽了不同平台之间的差异。
(3)脚本语言
脚本语言(Script language,scripting language,scripting programming language)是为了缩短传统的编写-编译-链接-运行(edit-compile-link-run)过程而创建的计算机编程语言。此命名起源于一个 脚本“screenplay”,每次运行都会使对话框逐字重复。
早期的 脚本语言经常被称为 批量处理语言或工作控制语言。一个 脚本通常是解释运行而非编译。
虽然许多 脚本语言都超越了计算机简单任务自动化的领域,成熟到可以编写精巧的程序,但仍然还是被称为脚本。几乎所有计算机系统的各个层次都有一种 脚本语言。包括操作系统层,如 计算机游戏,网络应用程序,字处理文档,网络 软件等。在许多方面,高级编程语言和 脚本语言之间互相交叉,二者之间没有明确的界限。
脚本编程速度更快,且 脚本文件明显小于如同类C 程序文件。这种灵活性是以执行效率为代价的。脚本通常是解释执行的,速度可能很慢,且运行时更耗内存。在很多案例中,如编写一些数十行的小 脚本,它所带来的编写优势就远远超过了运行时的劣势,尤其是在当前 程序员工资趋高和硬件成本趋低时。
脚本语言是一种解释性的语言,例如Python 、 vbscript、javascript、installshield script、ActionScript等等,它不像C/C++ 等可以编译成 二进制代码,以可执行文件的形式存在。】
3、语言的语法以及编译器
每种语言都有自己的语法以及对应的编译器,不同的环境下也对应着不同的编译器。
每种语言有着自己的语言标准,根据语言标准和运行环境的不同(比如windows和Linux)会有不同的编译器对语言进行编译,最后生成可执行的二进制代码
3.1、语法
编程语法的掌握程度对于熟练运用编程语言有非常直接的影响,因为语法知识是基本的编程规则,通过掌握编程语法能够了解编程语言的特点以及功能边界。不同的编程语言具有不同的语法规则,这也在根本上决定了编程语言的应用场景。
3.2、编译器
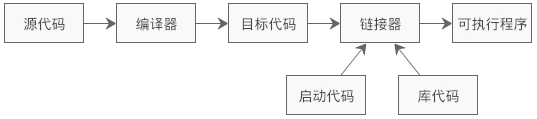
简单讲,编译器就是将“一种语言(通常为高级语言)”翻译为“另一种语言(通常为低级语言)”的程序。一个现代编译器的主要工作流程:源代码 (source code) → 预处理器 (preprocessor) → 编译器 (compiler) → 目标代码 (object code) → 链接器(Linker) → 可执行程序 (executables)。
编译器能够识别代码中的词汇、句子以及各种特定的格式,并将他们转换成计算机能够识别的二进制形式,这个过程称为编译(Compile)。
编译也可以理解为“翻译”,类似于将中文翻译成英文、将英文翻译成象形文字,它是一个复杂的过程,大致包括词法分析、语法分析、语义分析、性能优化、生成可执行文件五个步骤,期间涉及到复杂的算法和硬件架构。对于学计算机或者软件的大学生,“编译原理”是一门专业课程,有兴趣的读者请自行阅读《编译原理》一书。
编译器可以 100% 保证你的代码从语法上讲是正确的,因为哪怕有一点小小的错误,编译也不能通过,编译器会告诉你哪里错了,便于你的更改。
代码经过编译以后,并没有生成最终的可执行文件(.exe 文件),而是生成了一种叫做目标文件(Object File)的中间文件(或者说临时文件)。目标文件也是二进制形式的,它和可执行文件的格式是一样的。
目标文件经过链接(Link)以后才能变成可执行文件。既然目标文件和可执行文件的格式是一样的,为什么还要再链接一次呢,直接作为可执行文件不行吗?不行的!因为编译只是将我们自己写的代码变成了二进制形式,它还需要和系统组件(比如标准库、动态链接库等)结合起来,这些组件都是程序运行所必须的。
链接(Link)其实就是一个“打包”的过程,它将所有二进制形式的目标文件和系统组件组合成一个可执行文件。完成链接的过程也需要一个特殊的软件,叫做链接器(Linker)。
编译是针对一个源文件的,有多少个源文件就需要编译多少次,就会生成多少个目标文件。
不同版本的编译器不仅实现了语言的标准,而且在此基础上各自作了一些扩充,使之更加方便、完美。
高级计算机语言便于人编写,阅读交流,维护。机器语言是计算机能直接解读、运行的。编译器将汇编或高级计算机语言源程序(Source program)作为输入,翻译成目标语言(Target language)机器代码的等价程序。源代码一般为高级语言 (High-level language), 如Pascal、C、C++、Java、汉语编程等或汇编语言,而目标则是机器语言的目标代码(Object code),有时也称作机器代码(Machine code)。
对于C#、VB等高级语言而言,此时编译器完成的功能是把源码(SourceCode)编译成通用中间语言(MSIL/CIL)的字节码(ByteCode)。最后运行的时候通过通用语言运行库的转换,编程最终可以被CPU直接计算的机器码(NativeCode)。
(1)、编译器工作原理
编译是从源代码(通常为高级语言)到能直接被计算机或虚拟机执行的目标代码(通常为低级语言或机器语言)的翻译过程。然而,也存在从低级语言到高级语言的编译器,这类编译器中用来从由高级语言生成的低级语言代码重新生成高级语言代码的又被叫做反编译器。也有从一种高级语言生成另一种高级语言的编译器,或者生成一种需要进一步处理的的中间代码的编译器(又叫级联)。
典型的编译器输出是由包含入口点的名字和地址, 以及外部调用(到不在这个目标文件中的函数调用)的机器代码所组成的目标文件。一组目标文件,不必是同一编译器产生,但使用的编译器必需采用同样的输出格式,可以链接在一起并生成可以由用户直接执行的EXE, 所以我们电脑上的文件都是经过编译后的文件。
(2)、编译器分类
编译器可以生成用来在与编译器本身所在的计算机和操作系统(平台)相同的环境下运行的目标代码,这种编译器又叫做“本地”编译器。另外,编译器也可以生成用来在其它平台上运行的目标代码,这种编译器又叫做交叉编译器。交叉编译器在生成新的硬件平台时非常有用。“源码到源码编译器”是指用一种高级语言作为输入,输出也是高级语言的编译器。例如: 自动并行化编译器经常采用一种高级语言作为输入,转换其中的代码,并用并行代码注释对它进行注释(如OpenMP)或者用语言构造进行注释(如FORTRAN的DOALL指令)。
4、库函数
库函数一般是指编译器提供的可在源程序中调用的函数。可分为两类,一类是语言标准规定的库函数,一类是编译器特定的库函数。标准库函数一般在所有编译器中通用,而第二类则是依赖于编译器是否提供。由于版权原因,库函数的源代码一般是不可见的,但在头文件中你可以看到它对外的接口。
库函数(Library function)是把函数放到库里,供别人使用的一种方式。方法是把一些常用到的函数编完放到一个文件里,供不同的人进行调用。调用的时候把它所在的文件名用#include<>加到里面就可以了。一般是放到lib文件里的。
库函数一般都集成到集成开发环境中,供开发人员使用。
库函数一般分为动态库和静态库,具体见https://www.cnblogs.com/The-explosion/p/12250602.html
5、集成开发环境
集成开发环境(IDE,Integrated Development Environment )是用于提供程序开发环境的应用程序,一般包括代码编辑器、编译器、调试器和图形用户界面等工具。集成了代码编写功能、分析功能、编译功能、调试功能等一体化的开发软件服务套。所有具备这一特性的软件或者软件套(组)都可以叫集成开发环境。如微软的Visual Studio系列,Borland的C++ Builder、Delphi系列等。该程序可以独立运行,也可以和其它程序并用。IDE多被用于开发HTML应用软件。例如,许多人在设计网站时使用IDE(如HomeSite、DreamWeaver等),因为很多项任务会自动生成。
分类: EXPLOIT--->动态库和静态库