This folder contains code to fine-tune BERT to estimate the similarity between two arguments. We fine-tune BERT either on the UKP Argument Aspect Similarity Corpus or on the Argument Facet Similarity (AFS) Corpus from Misra et al., 2016.
For the setup, see the README.md in the main folder.
You can download two pre-trained models:
- argument_similarity_ukp_aspects_all.zip - trained on the complete UKP Aspects Corpus
- argument_similarity_misra_all.zip - trained on the complete AFS corpus from Misra et al.
Download and unzip these models. In `inference.py, update the model_path variable to match the path with your unzipped models:
model_path = 'bert_output/ukp_aspects_all'
And then run it:
python inference.py
The output should be something like this for the model trained on the UKP corpus:
Predicted similarities (sorted by similarity):
Sentence A: Eating meat is not cruel or unethical; it is a natural part of the cycle of life.
Sentence B: It is cruel and unethical to kill animals for food when vegetarian options are available
Similarity: 0.99436545
Sentence A: Zoos are detrimental to animals' physical health.
Sentence B: Zoo confinement is psychologically damaging to animals.
Similarity: 0.99386144
[...]
Sentence A: It is cruel and unethical to kill animals for food when vegetarian options are available
Sentence B: Rising levels of human-produced gases released into the atmosphere create a greenhouse effect that traps heat and causes global warming.
Similarity: 0.0057242378
With the Misra AFS model, the output should be something like this:
Predicted similarities (sorted by similarity):
Sentence A: Zoos are detrimental to animals' physical health.
Sentence B: Zoo confinement is psychologically damaging to animals.
Similarity: 0.8723387
Sentence A: Eating meat is not cruel or unethical; it is a natural part of the cycle of life.
Sentence B: It is cruel and unethical to kill animals for food when vegetarian options are available
Similarity: 0.77635074
[...]
Sentence A: Zoos produce helpful scientific research.
Sentence B: Eating meat is not cruel or unethical; it is a natural part of the cycle of life.
Similarity: 0.20616204
Download UKP Argument Aspect Similarity Corpus and unzip it into the datasets folder, so that the file datasets/ukp_aspect/UKP_ASPECT.tsv exists.
In our experiments, we used 4 fold cross-topic validation. To generate the 4 splits, run datasets/ukp_aspect/make_splits.py. This generates 4 folders with respecitive train/dev/test.tsv files, that can be used for training, tuning and testing the performance on the respective fold.
Run train_ukp.sh to train on the UKP Aspects Corpus using this 4 fold cross-topic validation. train_ukp_all.sh fine-tunes BERT on all 28 topics of the UKP Aspects corpus (again, without any dev/test set).
The Argument Facet Similarity (AFS) Corpus must be download from that website and unzipped into the datasets/misra/ folder, i.e., the file datasets/misra/ArgParis_DP.csv should exists after unzipping the AFS corpus.
Run train_misra.sh to train on the Misra AFS Corpus. The train_misra_all.sh fine-tunes BERT on all 3 topics of the AFS data, without any development or test set.
See our paper (Classification and Clustering of Arguments with Contextualized Word Embeddings) for further details.
The performance on the UKP Aspects Corpus is evaluated in 4-fold cross-topic setup. See evaluation_with_clustering.py and evaluation_without_clustering.py to compute the performance scores. In the paper, we achieved the following performances:
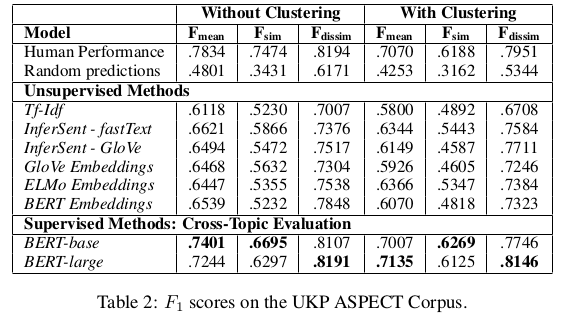
Misra et al., 2016, used 10-fold cross-validation. However, their setup has the drawback that the test data contains sentences that were already seen in the training set (only a specific combination of two sentences were not seen at test time).
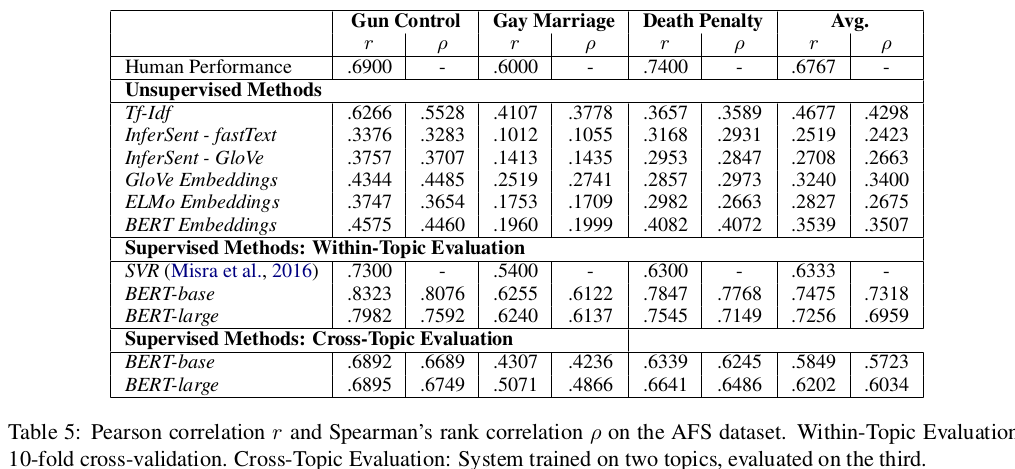
Instead of 10-fold cross-validation, we propose cross-topic evaluation. This also allows to estimate how well the model generalizes to new, unseen topics.
In the paper, we achieve the following correlation scores:
Note: The code published here is a cleaner and nicer version from the code we used for the paper. Results you get from this published code is slightly different to what is reported in the paper, partly due to randomness, partly (maybe) to the slight adaptation we published. Results achieved with this published implementation are usually slightly higher than what was published.