LDA hyperparameter fix: eta dimensionality and optimization #1024
Conversation
…d compare to the original.
…what changes I have made in the PR.
…aising ValueError if it is. Updated test notebook.
|
There is one problem that remains. The symmetric priors are initialized as instead of Because if While this works fine, I'm not sure if this way of initializing the priors is sound in general. EDIT: Since Matt Hoffman's code (which Gensim's code is based on) uses |
…s,)'. Removed tests of asymmetric eta, and where eta has shape '(num_topics, num_terms)'.
|
PR ready for review. |
|
I agree that this should be changed because when I wrote the original auto_eta code, I didn't realize that gensim was using the smoothed LDA model, and thus I misinterpreted the variables and my code doesn't make sense in the context of the smoothed LDA model. |
|
The failing unit tests are not from my code. There is more on that on issue #971. |
| @@ -0,0 +1,762 @@ | |||
| { | |||
There was a problem hiding this comment.
Please give a better name to the ipynb
There was a problem hiding this comment.
Once we are ready to merge, I'll remove this file.
| @@ -7,6 +7,7 @@ | |||
| from .coherencemodel import CoherenceModel | |||
| from .hdpmodel import HdpModel | |||
| from .ldamodel import LdaModel | |||
| from .ldamodelold import LdaModelOld | |||
There was a problem hiding this comment.
when we merge, there is no need to keep the old code.
There was a problem hiding this comment.
Once we are ready to merge, I'll remove this file.
| @@ -84,7 +84,7 @@ def update_dir_prior(prior, N, logphat, rho): | |||
|
|
|||
| dprior = -(gradf - b) / q | |||
|
|
|||
| if all(rho * dprior + prior > 0): | |||
| if (rho * dprior + prior > 0).all(): | |||
There was a problem hiding this comment.
The old way has never worked for me. Whenever I install Gensim from source I have to change this line. Can we just keep it this way?
There was a problem hiding this comment.
what is the error that you get? which python version?
There was a problem hiding this comment.
I just tested it, and I don't experience this problem any more. Something I've done must have fixed it for me. So I just changed it back.
| @@ -301,17 +303,19 @@ def __init__(self, corpus=None, num_topics=100, id2word=None, | |||
| self.minimum_phi_value = minimum_phi_value | |||
| self.per_word_topics = per_word_topics | |||
|
|
|||
| self.random_state = get_random_state(random_state) | |||
There was a problem hiding this comment.
Oh, there was a reason, but it's not relevant any more. I'll just move it back to its old spot.
| assert (self.eta.shape == (self.num_topics, 1) or self.eta.shape == (self.num_topics, self.num_terms)), ( | ||
| "Invalid eta shape. Got shape %s, but expected (%d, 1) or (%d, %d)" % | ||
| (str(self.eta.shape), self.num_topics, self.num_topics, self.num_terms)) | ||
| assert self.eta.shape == (self.num_terms,), "Invalid alpha shape. Got shape %s, but expected (%d, )" % (str(self.eta.shape), self.num_terms) |
There was a problem hiding this comment.
Ok, re-re-formatted :)
| @@ -0,0 +1,1049 @@ | |||
| #!/usr/bin/env python | |||
There was a problem hiding this comment.
no need for this file in the merge.
There was a problem hiding this comment.
Once we are ready to merge, I'll remove this file.
| model = self.class_(**kwargs) | ||
| self.assertEqual(model.eta.shape, expected_shape) | ||
| self.assertTrue(np.allclose(model.eta, [[0.630602], [0.369398]])) | ||
| self.assertTrue(all(model.eta == np.array([0.5] * num_terms))) |
There was a problem hiding this comment.
where is the assymmetric eta exception test?
There was a problem hiding this comment.
The "asymmetric" option should not be used for eta. It makes arbitrary words more likely apriori, which does not make sense. I have added an exception in the ldamodel.py file to make sure that eta is not equal to "asymmetric".
There was a problem hiding this comment.
where do you test that exception happens?
Please add assertRaises test case
There was a problem hiding this comment.
It is tested here. I added an assertRaise in unit tests.
There was a problem hiding this comment.
that is not a test, it is a check :) just kidding.
|
|
||
| # all should raise an exception for being wrong shape | ||
| kwargs['eta'] = testeta.reshape(tuple(reversed(testeta.shape))) | ||
| self.assertRaises(AssertionError, self.class_, **kwargs) | ||
|
|
||
| kwargs['eta'] = [0.3, 0.3, 0.3] |
There was a problem hiding this comment.
use num_terms+1 instead of just 3 elements
There was a problem hiding this comment.
Done. Although just num_terms, not num_terms+1.
There was a problem hiding this comment.
where is this change? line 213/196 is still the same
There was a problem hiding this comment.
|
I re-introduced the K x V asymmetric prior. While a K vector eta is not correct, there is a special place for the K x V prior. As said in the docstring for eta, using K x V asymmetric prior the user may impose specific priors for each topic (e.g. to coerce a specific topic, or to get a "garbage collection" topic). @tmylk can you read the new docstring, just to check that it's ok? EDIT: @tmylk I made some unit tests for K x V eta (same as were there before). |
| self.assertRaises(AssertionError, self.class_, **kwargs) | ||
|
|
||
| kwargs['eta'] = [0.3, 0.3, 0.3] | ||
| kwargs['eta'] = [0.3] * num_terms |
There was a problem hiding this comment.
this is same as line 188 above
There was a problem hiding this comment.
Rmoved it. Don't know why I put that there.
| @@ -210,15 +201,15 @@ def testEta(self): | |||
| kwargs['eta'] = testeta.reshape(tuple(reversed(testeta.shape))) | |||
| self.assertRaises(AssertionError, self.class_, **kwargs) | |||
|
|
|||
| kwargs['eta'] = [0.3, 0.3, 0.3] | |||
| self.assertRaises(AssertionError, self.class_, **kwargs) | |||
|
|
|||
| kwargs['eta'] = [0.3] | |||
| self.assertRaises(AssertionError, self.class_, **kwargs) | |||
There was a problem hiding this comment.
where did assertraises for a longer eta shape go?
There was a problem hiding this comment.
I'll add an assertRaises where shape of eta is num_terms+1.
|
Let's clean it up and then ready to merge. |
|
@tmylk should the explanation be under "0.13.5, 2016-11-12" in the changelog? Or where should I put it? |
|
@tmylk you said:
What do you mean? What happened? |
|
The explanation should be on the top of CHANGELOG.md |
Working on a problem with the parameter
etaand automatic learning ofeta. For now, the unchanged version is in theldamodelold.pyfile, so that I can compare both versions. There is a notebook indocs/notebooks/lda_tests.ipynbwith the tests I have been doing.The changes I've made improve convergence (increase in bound over iterations), when learning
eta.The problem
Basically,
etais supposed to be eitherwhere V is the size of the vocabulary. In
ldamodel, we instead have the options thatetaiswhere K is the number of topics. As we will see in a little bit, this causes some problems.
Results so far
The figure below shows the bound (
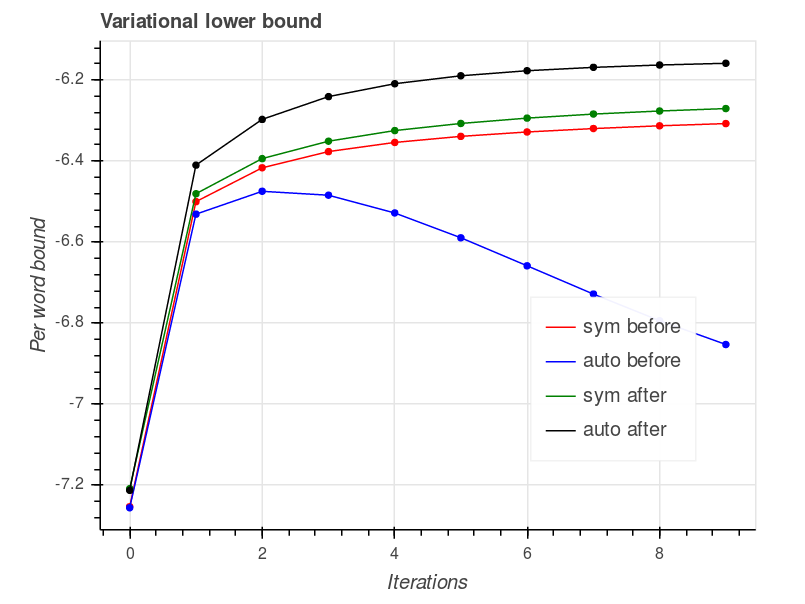
perwordbound) as a function of the number of passes over data. It shows the bound both before and after the changes I made, and foreta='symmetric'and foreta='auto'.The figure above shows that using automatically learned
etaactually decreased the bound before this fix.I also noticed that if we set
iterations=1, andeta='auto', the algorithm diverges. This is no longer a problem with this commit.Asymmetric priors
I added a check that raises a
ValueErrorifetais equal to 'asymmetric'. While a explicit asymmetric prior supplied by the user makes sense (e.g. if the user wants to boost certain words, or has estimated the prior from data), there is no reason for using an arbitrarily initialized asymmetric prior. Furthermore, with the current method of initializing asymmetric priors, and when eta is the same size as the vocabulary, I noticed some convergence problems.As a side note on the topic of asymmetric priors, I'm not sure the current method is ideal. One could, for example, initialize from a gamma distribution the same way lambda and gamma are initialized instead.