-
Notifications
You must be signed in to change notification settings - Fork 1
/
Copy pathbidzcards.py
226 lines (210 loc) · 11.2 KB
/
bidzcards.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
# Importing the required libraries
import easyocr
import cv2
import pandas as pd
import re
import sqlite3
import base64
import streamlit as st
from streamlit_option_menu import option_menu
# ----------------------------Creating File To Store The Image------------------------------------------------
file_name='Ravi'
#--------------------------------------------- Establishing Connection With SQL Database With sqlite3---------------------------------------------
conn = sqlite3.connect('data.db', check_same_thread=False)
cursor = conn.cursor()
mytable='CREATE TABLE IF NOT EXISTS Business_data(ID INTEGER PRIMARY KEY AUTOINCREMENT,COMAPANY_NAME TEXT,EMPLOYEE_NAME TEXT,DISIGNATION Text,EMAIL_ID TEXT,CONTACT TEXT,ALTERNATE_CONTACT TEXT,WEBSITE TEXT,ADDRESS TEXT,IMAGE BLOB)'
cursor.execute(mytable)
# writing function to retrive data from card
def upload_database(image):
img = cv2.imread(image)
# ------------------------------------------------------Processing the Image------------------------------------------------------------------
# converting colour image to graycolor image
orig_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Arguments of function cv2.threshold
# cv2.threshold(grayscaled image, threshold value, maximum value of pixel, type of threshold)
# Output is a tuple containg the threshold value and thresholded image
#Threshold to zero
rect,thresh_image = cv2.threshold(orig_img,70,255,cv2.THRESH_TOZERO)
# ----------------------------------------Getting data from image using easyocr------------------------------------------------------
reader = easyocr.Reader(['en'], gpu=False)
res=reader.readtext(thresh_image,detail=0,paragraph=True)
result=reader.readtext(thresh_image,detail=0,paragraph=False)
# -----------------------------------------converting got data to single string------------------------------------------------------
text=''
for i in result:
text=text+' '+i
# -------------------------------------------To Extract The Name --------------------------------------------------------------------------
name=result[0]
text=text.replace(name,'')
# ------------------------------------------ To Extract The Designation --------------------------------------------------------------
designation=result[1]
text=text.replace(designation,'')
# ------------------------------------------To Extract EMAIL-Id---------------------------------------------------------------------------
emails = re.findall(r'[A-Za-z0-9\.\-+_]+@[A-Za-z0-9\.\-+_]+\.[a-z]+', text)
email=[]
for i in emails:
email.append(i)
email_id=email[0]
text=text.replace(email_id,'')
# ------------------------------------------To Extract Contact Numbers---------------------------------------------------------------------------
phoneNums = re.findall(r'[\+\(]?[1-9][0-9 .\-\(\)]{8,}[0-9]', text)
# print(number)
arr=[]
for i in phoneNums:
if len(i)>=10:
arr.append(i)
contact=''
alter_contact=''
if len(arr)>1:
contact=arr[0]
alter_contact=arr[1]
text=text.replace(contact,'')
text=text.replace(alter_contact,'')
else:
contact=arr[0]
alter_contact=' '
text=text.replace(contact,'')
# ------------------------------------------To Extract Address---------------------------------------------------------------------------
address_regex = re.compile(r'\d{2,4}.+\d{6}')
address = ''
for addr in address_regex.findall(text):
address += addr
text = text.replace(addr, '')
# ------------------------------------------To Extract website link---------------------------------------------------------------------------
link_regex = re.compile(r'www.?[\w.]+', re.IGNORECASE)
link= ''
for lin in link_regex.findall(text):
link += lin
text=text.replace(link,'')
# ------------------------------------------ To Extract The Company Name----------------------------------------
a=name+' '+designation
b=designation+' '+name
c=link+' '+email_id
d=email_id+' '+link
e=link
f=email_id
g=contact+' '+alter_contact
h=alter_contact+' '+contact
i=contact
j=alter_contact
arr=[a,b,c,d,e,f,g,h,i,j]
for i in arr:
if i in res:
res.remove(i)
else:
continue
company_name=res[-1]
# ---------------------------------------------------- To Read The Image----------------------------------------
with open(image, 'rb') as f:
img = f.read()
image=base64.b64encode(img)
# --------------------------------------------------Appending Retrived Data To Table -------------------------------------------
mydata='INSERT INTO Business_data(COMAPANY_NAME,EMPLOYEE_NAME,DISIGNATION,EMAIL_ID,CONTACT,ALTERNATE_CONTACT,WEBSITE,ADDRESS,IMAGE)values(?,?,?,?,?,?,?,?,?)'
cursor.execute(mydata,(company_name,name,designation,email_id,contact,alter_contact,link,address,image))
conn.commit()
#------------------------------------- creating function for data extraction--------------------------------------------------
def extracted_data(image):
img = cv2.imread(image)
# ------------------------------------------------------Processing the Image------------------------------------------------------------------
# converting colour image to graycolor image
orig_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Arguments of function cv2.threshold
# cv2.threshold(grayscaled image, threshold value, maximum value of pixel, type of threshold)
# Output is a tuple containg the threshold value and thresholded image
#Threshold to zero
rect,thresh_image = cv2.threshold(orig_img,70,255,cv2.THRESH_TOZERO)
reader = easyocr.Reader(['en'], gpu=False)
result = reader.readtext(thresh_image, paragraph=False, decoder='wordbeamsearch')
img = cv2.imread(image)
for detection in result:
top_left = tuple([int(val) for val in detection[0][0]])
bottom_right = tuple([int(val) for val in detection[0][2]])
text = detection[1]
font = cv2.FONT_HERSHEY_SIMPLEX
img = cv2.rectangle(img, top_left, bottom_right, (204, 0, 34), 5)
img = cv2.putText(img, text, top_left, font, 0.8,(0, 0, 255), 2, cv2.LINE_AA)
# plt.figure(figsize=(10, 10))
# plt.imshow(img)
# plt.show()
return img
#---------------------------------------- Setting The Tage Configuration With Title,Icon for Streamlit App------------------------------
st.set_page_config(page_title='Bizcardx Extraction',page_icon="chart_with_upwards_trend", layout='wide')
# -------------------------------------------------Adding title to the app-----------------------------------------------------------------
st.title(':violet[Bizcardx Data Extraction🖼️]')
#----------------------------- Defining The Menu Bar For Streamlit app----------------------------------------------------------------------
SELECT = option_menu(
menu_title = None,
options = ['Home','Process','Search','Contact'],
icons =['house','bar-chart','search','at'],
default_index=2,
orientation='horizontal',
styles={
'container': {'padding': '0!important', 'background-color': 'white','size':'cover'},
'icon': {'color': 'black', 'font-size': '20px'},
'nav-link': {'font-size': '20px', 'text-align': 'center', 'margin': '-2px', '--hover-color': '#6F36AD'},
'nav-link-selected': {'background-color': '#6F36AD'}
}
)
# -------------------------------------- Creating Home Section------------------------------------------
if SELECT=='Home':
st.subheader('Getting started with EasyOCR for Optical Character Recognition.EasyOCR is the most basic method of implementing OCR. It is a Python library that can read text from photos in over 40 different languages.It is incredibly simple to implement with only a few lines of code and produces good results')
col1,col2=st.columns(2)
with col1:
st.markdown('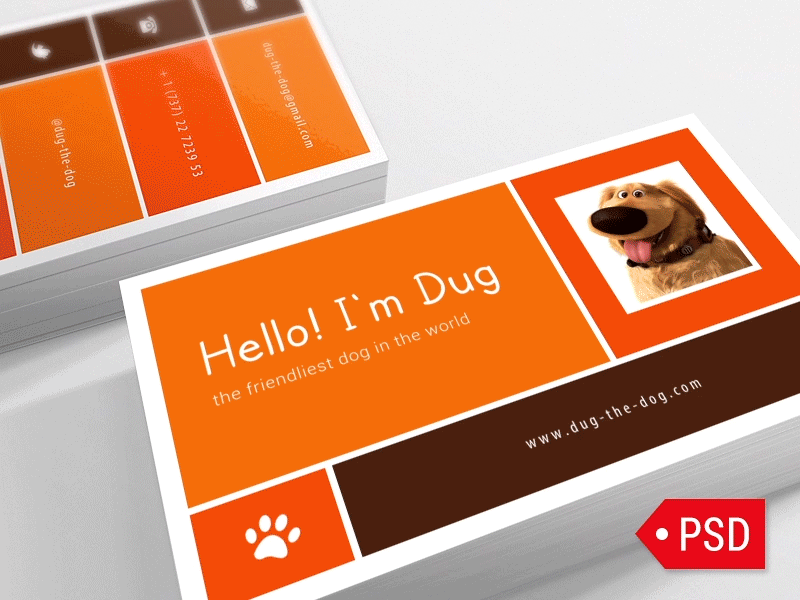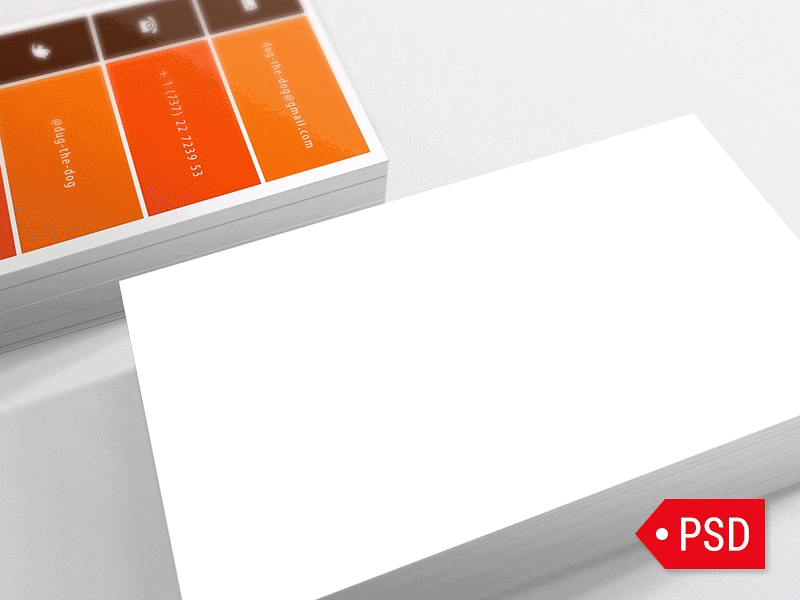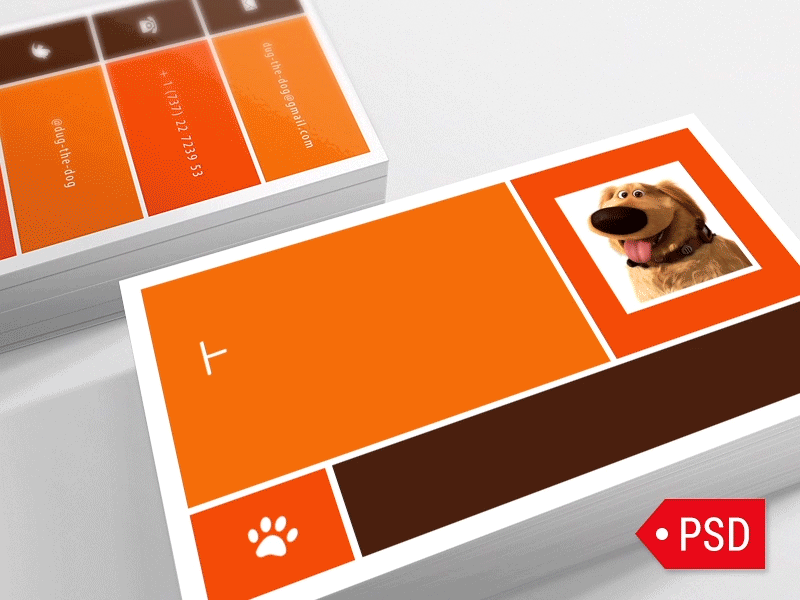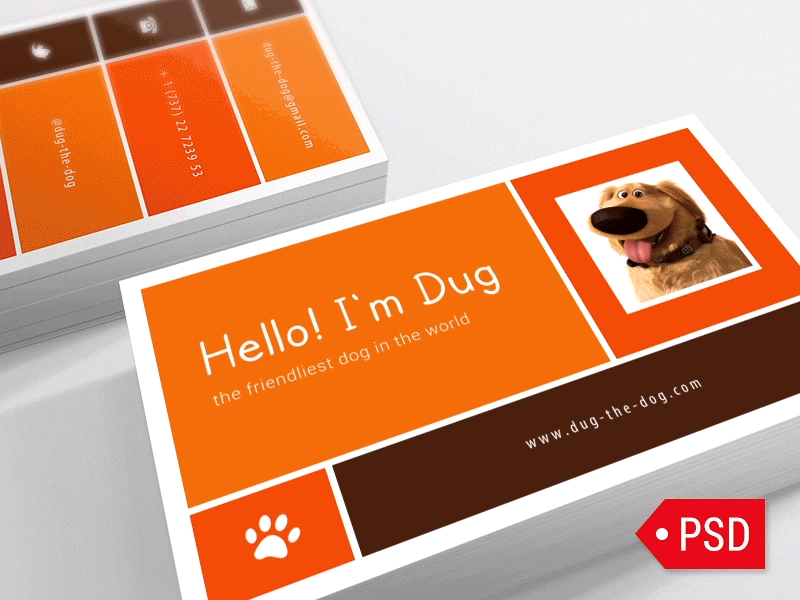')
with col2:
st.markdown('')
# ---------------------------------------Creating Process section-----------------------------------------------------------
if SELECT=="Process":
col1,col2=st.columns(2)
with col1:
st.subheader(':violet[Choose image file to extract data]')
# ---------------------------------------------- Uploading file to streamlit app ------------------------------------------------------
uploaded = st.file_uploader('Choose a image file')
# --------------------------------------- Convert binary values of image to IMAGE ---------------------------------------------------
if uploaded is not None:
with open(f'{file_name}.png', 'wb') as f:
f.write(uploaded.getvalue())
# ------------------------------------------Uploading The Data To Database---------------------------------------------------
st.subheader(':violet[Upload extracted to Database]')
if st.button('Upload data'):
upload_database(f'{file_name}.png')
st.success('Data uploaded to Database successfully!', icon="✅")
# ----------------------------------------Extracting Data From Image (Image view)-------------------------------------------------
with col2:
st.subheader(':violet[Image view of Data]')
if st.button('Extract Data from Image'):
extracted = extracted_data(f'{file_name}.png')
st.image(extracted)
# ---------------------------------- Checking The Database for confirmation--------------------------------------------
cursor.execute('select*from Business_data')
df=pd.DataFrame(cursor.fetchall(),columns=['ID','COMAPANY_NAME','EMPLOYEE_NAME','DISIGNATION','EMAIL_ID','CONTACT','ALTERNATE_CONTACT','WEBSITE','ADDRESS','IMAGE'])
#---------------------------------------Creating Search section-----------------------------------------------------
if SELECT=='Search':
# ----------------------------------- To See The Entair Record-------------------------------------------------------------------
st.title(':violet[To SEE All The Data in Database]')
if st.button('Show All'):
st.write(df)
# ------------------------------------------------To See The Reocrd With Perticular value-------------------------------------------------
st.header(':violet[Search Data by Column]')
column = str(st.radio('Select column to search', ('COMAPANY_NAME','EMPLOYEE_NAME','DISIGNATION','EMAIL_ID','CONTACT','ALTERNATE_CONTACT','WEBSITE','ADDRESS'), horizontal=True))
value = str(st.selectbox('Please select value to search', df[column]))
if st.button('Search Data'):
st.dataframe(df[df[column] == value])
# --------------------------------------------------- Creating Contact Section----------------------------------------------------------------
if SELECT=='Contact':
name = " RAVI CHANDRA PALEM "
mail = (f'{"Mail :"} {"palemravichandra21a@gmail.com"}')
social_media = {"GITHUB": "https://github.com/Palemravichandra ",
"LINKEDIN": "https://www.linkedin.com/in/palem-ravichandra-a73373152/"
}
st.title(name)
st.subheader("An Aspiring DATA-SCIENTIST..!")
st.write("---")
col1,col2=st.columns(2)
with col1:
st.subheader(mail)
#st.write("#")
with col2:
cols = st.columns(len(social_media))
for index, (platform, link) in enumerate(social_media.items()):
cols[index].write(f"[{platform}]({link})")