=0?t:0;var n=e.getBoundingClientRect();var i=window.innerHeight||document.documentElement.clientHeight;var o=n.top;return o>=0&&o<=i*(t+1)||o<=0&&o>=-(i*t)-n.height},waitElementVisible:function(e,i,o){var t=typeof window!=="undefined";var n=t&&!("onscroll"in window)||typeof navigator!=="undefined"&&/(gle|ing|ro|msn)bot|crawl|spider|yand|duckgo/i.test(navigator.userAgent);if(!t||n){return}o=o&&o>=0?o:0;function r(e){if(Fluid.utils.elementVisible(e,o)){i();return}if("IntersectionObserver"in window){var t=new IntersectionObserver(function(e,t){if(e[0].isIntersecting){i();t.disconnect()}},{threshold:[0],rootMargin:(window.innerHeight||document.documentElement.clientHeight)*o+"px"});t.observe(e)}else{var n=Fluid.utils.listenScroll(function(){if(Fluid.utils.elementVisible(e,o)){Fluid.utils.unlistenScroll(n);i()}})}}if(typeof e==="string"){this.waitElementLoaded(e,function(e){r(e)})}else{r(e)}},waitElementLoaded:function(i,o){var e=typeof window!=="undefined";var t=e&&!("onscroll"in window)||typeof navigator!=="undefined"&&/(gle|ing|ro|msn)bot|crawl|spider|yand|duckgo/i.test(navigator.userAgent);if(!e||t){return}if("MutationObserver"in window){var n=new MutationObserver(function(e,t){var n=document.querySelector(i);if(n){o(n);t.disconnect()}});n.observe(document,{childList:true,subtree:true})}else{document.addEventListener("DOMContentLoaded",function(){var t=function(){var e=document.querySelector(i);if(e){o(e)}else{setTimeout(t,100)}};t()})}},createScript:function(e,t){var n=document.createElement("script");n.setAttribute("src",e);n.setAttribute("type","text/javascript");n.setAttribute("charset","UTF-8");n.async=false;if(typeof t==="function"){if(window.attachEvent){n.onreadystatechange=function(){var e=n.readyState;if(e==="loaded"||e==="complete"){n.onreadystatechange=null;t()}}}else{n.onload=t}}var i=document.getElementsByTagName("script");var o=i.length>0?i[i.length-1]:document.head||document.documentElement;o.parentNode.insertBefore(n,o.nextSibling)},createCssLink:function(e){var t=document.createElement("link");t.setAttribute("rel","stylesheet");t.setAttribute("type","text/css");t.setAttribute("href",e);var n=document.getElementsByTagName("link")[0]||document.getElementsByTagName("head")[0]||document.head||document.documentElement;n.parentNode.insertBefore(t,n)},loadComments:function(e,t){var n=document.querySelector("#comments[lazyload]");if(n){var i=function(){t();n.removeAttribute("lazyload")};Fluid.utils.waitElementVisible(e,i,CONFIG.lazyload.offset_factor)}else{t()}},getBackgroundLightness(e){var t=e;if(typeof e==="string"){t=document.querySelector(e)}var n=t.ownerDocument.defaultView;if(!n){n=window}var i=n.getComputedStyle(t).backgroundColor.replace(/rgba*\(/,"").replace(")","").split(/,\s*/);if(i.length<3){return 0}var o=.213*i[0]+.715*i[1]+.072*i[2];return o===0||o>255/2?1:-1}};function Debouncer(e){this.callback=e;this.ticking=false}Debouncer.prototype={constructor:Debouncer,update:function(){this.callback&&this.callback();this.ticking=false},requestTick:function(){if(!this.ticking){requestAnimationFrame(this.rafCallback||(this.rafCallback=this.update.bind(this)));this.ticking=true}},handleEvent:function(){this.requestTick()}};
\ No newline at end of file
diff --git a/leave/index.html b/leave/index.html
new file mode 100644
index 000000000..2d5ae5da3
--- /dev/null
+++ b/leave/index.html
@@ -0,0 +1,3 @@
+留言板 - 序炁的博客
+
+留言板,想问博主的都可以在这里评论哦!
友情链接不要在这里留言,请去友链页面填表单。
评论使用twikoo系统。
无法访问的博客将在30天内删除,若恢复访问请通过关于页面中的电子邮箱联系我
现可填写下方表单自助申请友链
要求
- 非营利性
- 非资源分享类及盗版传播内容
- 不得含有违反中华人民共和国各法律的内容
- 启用全站https
- 已添加本站友链
- 目前只接受文章数>=5的博客申请
情景引入
邮件服务器性能羸弱,无法胜任设置定时任务这样的重担,所以只能用一些盘外招试试了。
设置 Action
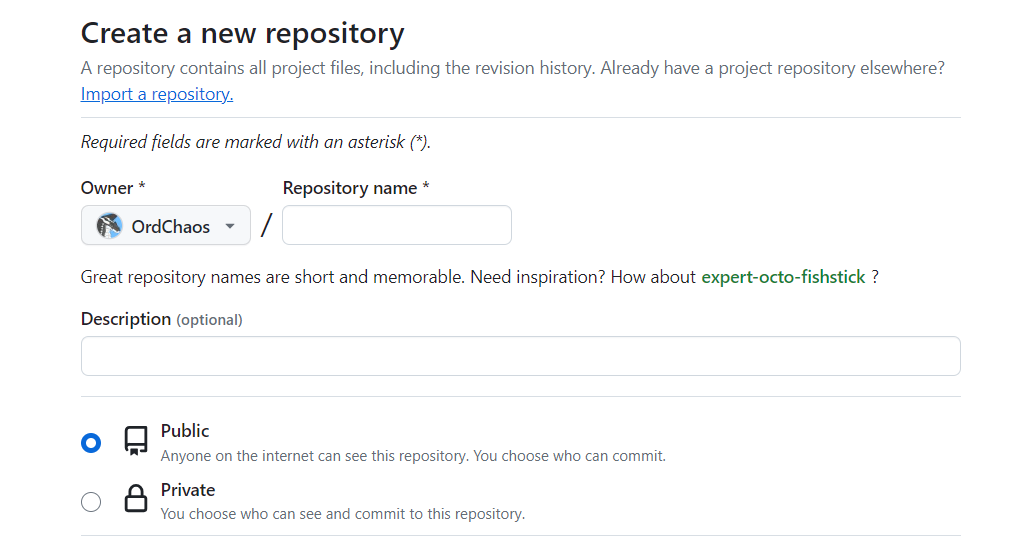
那么首先,本着轻量化的原则,新建一个仓库拿来干这种事:
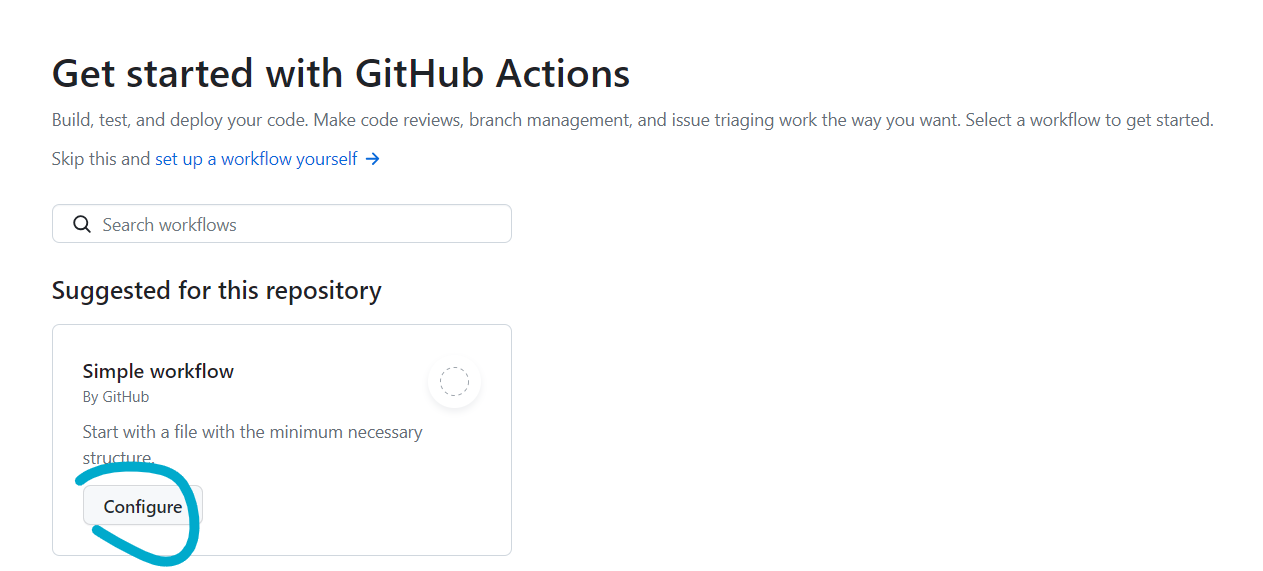
然后切到Action页面:

选择新建一个空白模板:
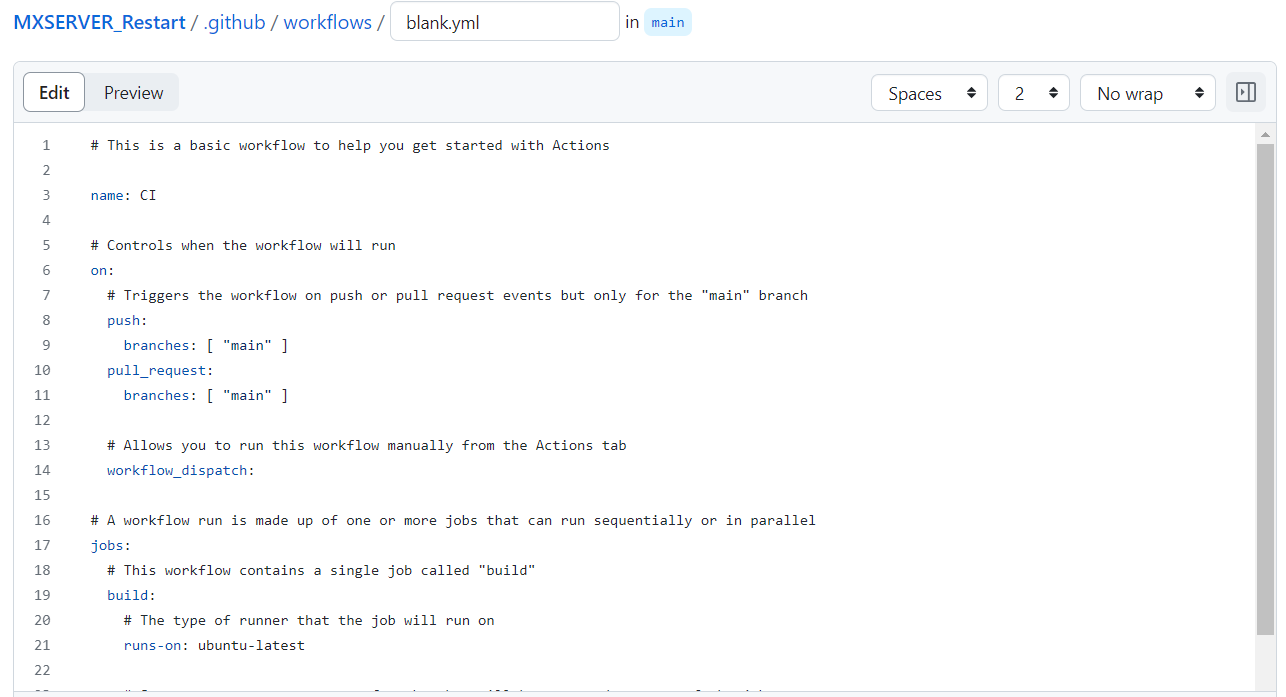
修改Action名称、内容并设置定时,参考我的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| # This is a basic workflow to help you get started with Actions
name: REMX
# Controls when the workflow will run
on:
# Triggers the workflow on push or pull request events but only for the "main" branch
push:
branches: [ "main" ]
schedule:
- cron: "0 20 * * *"
# Allows you to run this workflow manually from the Actions tab
workflow_dispatch:
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
jobs:
# This workflow contains a single job called "build"
build:
# The type of runner that the job will run on
runs-on: ubuntu-latest
# Steps represent a sequence of tasks that will be executed as part of the job
steps:
- name: Checkout Codes
uses: actions/checkout@v3
- name: Restart MX Service
uses: garygrossgarten/github-action-ssh@release
with:
command: ./restart.sh
host: ${{ secrets.HOST }}
username: root
password: ${{ secrets.PASSWORD }}
- name: Finish
run: echo "Action Finish"
|
SSH相关配置自行查看官方文档
保存,然后去设置Secret:
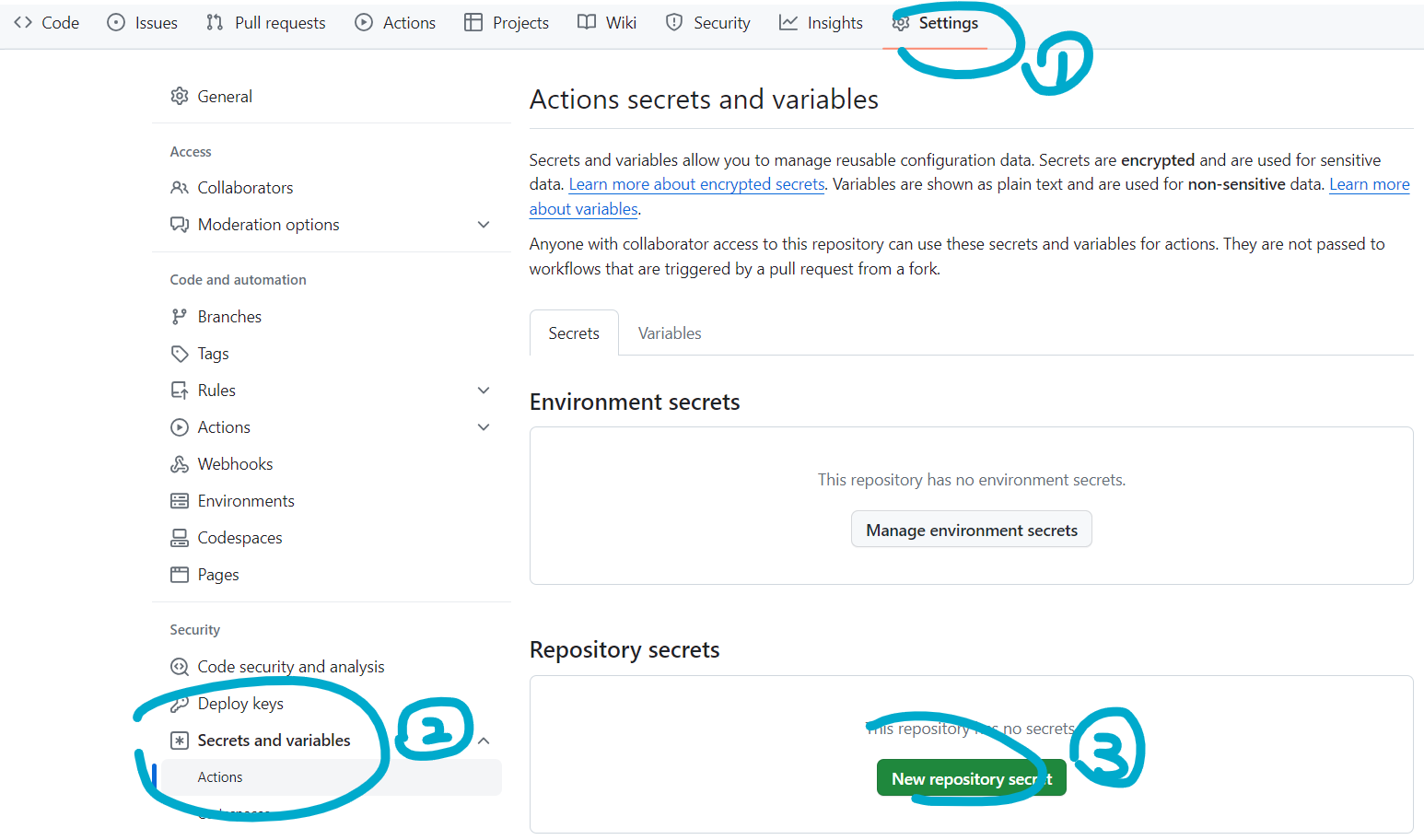
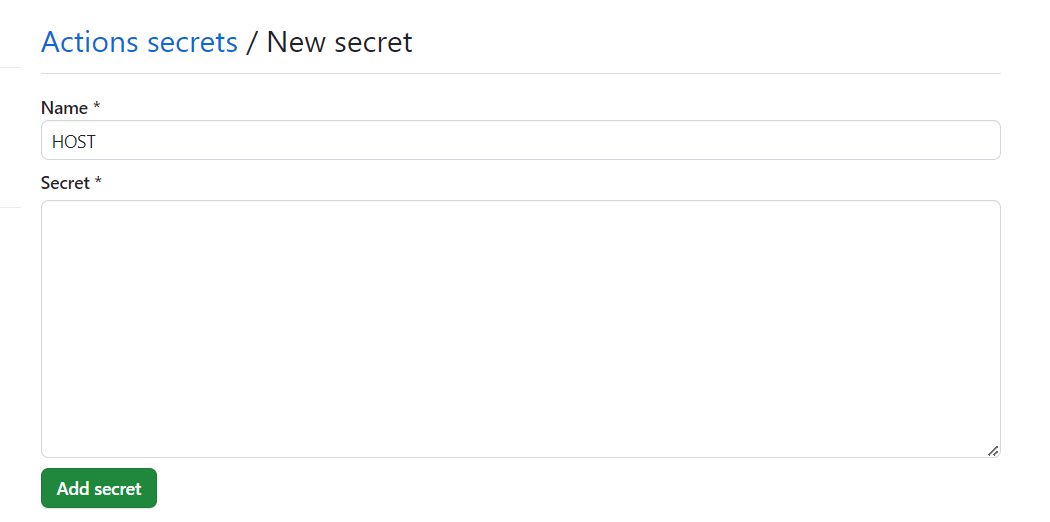
分别设置服务器地址、密码等即可:
大功告成!
结语
上高中之后就没写博文了……
除夕赶出一篇博文,祝新年快乐!!!
也迟来的祝博客两周年快乐!!!
]]>
+
+
+
+
+ 教程
+
+
+
+
+
+
+ 计算机
+
+ 编程
+
+ 教程
+
+ 白嫖
+
+
+
+
+
+
+
+
+ 年中总结,及进16岁生贺
+
+ /posts/95bd9bb8/
+
+ 又是一年生日了,回想上次生日,好像还是在上次一样,那时还是在初三开学前的补课。补课放学的很早,五点就回家了。当时在超市里买了一根价值14块大洋的钟薛糕……说起来真的像是发生在昨天。
1~2月
经过了疫情的洗礼,九年级下学期的开学总算是如期而至,但紧随而来便是对二月调考的紧张。原本武汉是只有元调、四调的,不过由于众所周知的疫情因素,元调从原定的1月4号挪到了2月21号。让我们过了一个安心的元旦和一个安心的寒假。
但该来的还是要来,二调总归也是调考,压迫感并未消失,只是转移到了一个月后。故而新学期伊始,我们就全身心投入到了复习之中。那时我的心里总会浮现出七年级刚开学时班主任在班里说的话,她告诉我们三年很短,元调很重要。初听不知话中意,而现在,已为语中人。
二调的成绩中规中矩吧,523分(523/600),随后便立下了四调要进步15分的目标。但那时我还不知道,这个目标永远没有机会达成了。
3~4月
二调完了就是四调,没什么可说的,该复习复习,该上新课上新课。伴随着一本又一本教材被翻至最后一课、最后一面,初中即将毕业的感受才开始从心中滋生。不论是Graduation还是“从这里出发”,课本中的一句句话,一段段文章都正提醒着我们即将分别的事实。
四调成绩说实话,很不好,只有508。以至于我的母亲对我这个分数不抱什么期望了,也便没有如同二调结束后那样跑前跑后地签各种约。也正因如此,已然退休的她只能在家里独自心焦,这是我的问题。
5~6月
五月有各个区自己的五调,六月便是全武汉市的中考。志愿早在五月九日便截至提交,在此之前,我终于说服了我的父母为我填写武钢三中为第一志愿。“说服”,无奈的选择,毕竟要说二调成绩勉强足够的话,四调成绩面对钢三简直就是依托答辩。但我仍然坚定的选择了这条路,算是对自己的压迫吧,同时也伴随着一股气,一股不服输的精神。
五调前举行了理化生实验考试,和八年级的地理生物一样,采用机考的形式。没什么难度,几乎全班满分通过,只有3人被扣了1分。加上由于疫情取消的体育中考,近乎就是给每个人送了80分。
六月初,抽了一个上午,我们全班在学校里拍了毕业照。学校不大,很快就走遍了整个校园。伴随着感慨,拍完室外照后回班,我们齐心协力在十分钟内办好了一面黑板报。站在黑板报前,我们拍了最后的几张照片。
中考日以前,最后一个在校日,是一个周六。老师在上午或看自习,或做最后的查漏补缺。而下午,老师开了一场动员会,给每个人发了一块粽子玩偶。既代表端午将临,亦有一举高中之意。一场班会结束,打扫完教室,离开学校,颇有一种或解脱、或不舍的情愫。

中考前一天,周一,下午我便前往了考点处。每个文化课老师都在考点门口,为我们一张张派发着准考证。面对那一句句叮嘱,我明白,不能当做是像以前那样的老生常谈了。
中考结束的那一天,考完历史道法的上午。连续更改了两道选择题的我放下了手中的笔,一根根地把中性笔、2B铅笔、涂卡笔以及橡皮擦、垫板、准考证装入了文具袋。走回休息室,再和全班同学及老师走出了考场。此时此刻,心中只有解脱,无暇再顾及其它。
随后就是毕业旅行了,很愉快的出行经历,也为初中三年画上了一个圆满的句号。

7~8月
七月一号一早,昨天刚从青岛回到家的我点进了武汉招考网,惊心动魄的输入姓名、报名号和身份证号。按下蓝色按钮的那一刻,时间仿佛凝滞。好在接下来引入眼帘的数字令我终于放下了心,614分(614/680),是我最高的一次了。
毫无疑问的被钢三录取,之后是钢三的夏令营,一直到七月二十一。食堂很美味,与同学相处得很愉快,校园环境很好,近乎无可挑剔了。

八月,很放松的一个月,这个月一直在玩master duel和原神,开始了摆烂状态(笑)
直到今天,我的生日为止,一切都很放松。
未来……
马上就是钢三的军训了,再之后就是开学,祝我一路顺利吧!
也希望三年后的暑假能像现在一样无忧无虑。
Happy Birthday for Me!
顺便晒一下毕业纪念册!
]]>
+
+
+
+
+ 日常
+
+
+
+
+
+
+ 生日
+
+ 总结
+
+ 个人
+
+
+
+
+
+
+
+
+ 数字生命卡开箱——来自《流浪地球II》
+
+ /posts/b3d3143c/
+
+ 过年档的电影,看完就买了周边。历经半年,终于到手啦!哈哈!《流浪地球II》的官方周边产品大部分都是赛凡做的。怎么说呢……我买的数字生命卡是第二批,看到很多第一批的都有程度不一的瑕疵。不过我这个就还好,没有什么大问题,看来还是有在改进运输和包装质量。
到手差不多就是这么些东西:

其它周边什么的就不多说了,重头戏还是数字生命卡。
数字生命卡
只说外观的话,看起来金属感不是很强,喷个漆观感应该会好一些,但我不会(
别的道具倒是挺还原的,比如说袋子。
别的也没什么可说的了,毕竟这也就是一个128G的U盘和一个读卡器而已。
其它
不说什么了,放几张图吧。
题外话
不是很好评价赛凡的产品了……
我只能说我能接受这个做工,但的确,赛凡的破事很难让我提起好感。
就这样,886!
]]>
+
+
+
+
+ 日常
+
+
+
+
+
+
+ 电影
+
+ 开箱
+
+ 科技
+
+ U盘
+
+ 周边
+
+
+
+
+
+
+
+
+ 文章AI摘要?太酷啦!
+
+ /posts/ec8c9790/
+
+ 看了HEO的如何让博客支持AI摘要,使用TianliGPT自动生成文章的AI摘要,甚是手痒……整一个! 前情提要
的确,我可以直接把HEO现成的部署方案拿来用,但我是一个有追求的人(雾。事实上,直接使用这种解决方案得到的摘要栏与我博客的设计风格并不是很搭,这就要求我自己写一个前端后端是不可能的,这辈子也不可能的。
好,开干!但首先,第一个问题出现了:我博客的设计风格本身就不太统一。首页的说说轮播和说说页面的数量统计用了fluid主题自带的info,而友链朋友圈页面又没有,直接使用了圆角矩形承载统计信息。
为了解决这个问题,我需要用一样东西代替info标签。经过再三深思熟虑,我选用圆角矩形统一替换info.
而后便有了枯燥的漫长(?)css编写时间:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| div.ocxqntcontainer {
display: flex;
align-items: center;
justify-content: center;
height: auto;
}
div.ocxqnt {
border: 1px solid #e9e9e9;
border-radius: 1rem;
padding: 1rem;
text-align: left;
width: 100%;
}
span.memos-t {
margin: 0 1rem;
}
|
就这样,圆角矩形大功告成。
摘要部署
现在这个步骤就变得很简单了,对于我用的fluid主题,编辑layout/post.ejs即可,在article标签中,类为markdown-body的div标签之前加入以下内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| <style>
i.icon-ordchaos-blog-robot, span.ocxq-ai-title {
font-weight: bold;
font-size: 1.2em;
}
span.ocxq-ai-warn {
font-weight: bold;
}
.ocxq-ai-text.typing::after {
content: "_";
margin-left: 2px;
animation: blink 0.7s infinite;
}
@keyframes blink {
50% {
opacity: 0;
}
}
</style>
<script>
let tianliGPT_postSelector = '#board .post-content .markdown-body';
let tianliGPT_key = '5Q5mpqRK5DkwT1X9Gi5e';
</script>
<div class="ocxqntcontainer">
<div class="ocxqnt">
<span id='memos-t'>
<i class="iconfont icon-ordchaos-blog-robot"></i><span id="memos-index-space"> </span><span class="ocxq-ai-title">AI摘要</span>
<br>
<span class="ocxq-ai-text">
生成中...
</span>
<br>
<span class="ocxq-ai-warn">摘要由AI自动生成,仅供参考!</span>
</span>
</div>
</div>
<br>
<script src="https://www.ordchaos.com/js/aisummary.js"></script>
|
这里有几个问题:
- 为什么内容在
id为memos-t的span标签中:因为它同样套用了刚刚写好的圆角矩形,而这个圆角矩形为了适配原有的memos说说而要求内部文字必须拥有memos-t的id. iconfont icon-ordchaos-blog-robot是什么图标:我在iconfont.cn中取用的,因为加入了我的图标库所以拥有图标库前缀icon-ordchaos-blog,若也想选用的话可以直接在iconfont.cn搜索关键词robot找到并添加到自己的图标库- 为什么不把样式代码写到css里面去:我懒
最后在文件的末尾处加上对js文件的引用。
说到js,由于HEO提供的js文件中含有生成前端容器的部分,所以必须要删除这部分内容并对其做出部分修改。过程这里就不放了,实在看不懂的可以参考我改好的被压缩了怎么看啊自己想办法。
而后去爱发电订阅TianliGPT并将api key填入即可。
效果
题外话
最开始因为不想写css而拖了好久……最终因为实在眼馋,欲望盖过了懒病才动身做完。
话说我这样改别人写好的js应该没问题吧……
那就这样,886!
]]>
+
+
+
+
+ 编程
+
+ 教程
+
+
+
+
+
+
+ 计算机
+
+ 编程
+
+ 教程
+
+ javascript
+
+ css
+
+ AI
+
+
+
+
+
+
+
+
+ 哇!是毕业旅行!
+
+ /posts/c2e7460a/
+
+ 初三毕业,结束了忙碌的一年,老师带我们全班去了青岛毕业旅行! 前情提要
武汉今年中考在六月的二十、二十一、二十二号总共三天,考完以后休息放纵两日后,我们全班便踏上了高铁前往青岛。
怎么说呢……说是六天五夜,但武汉与青岛之间的高铁要坐8小时,所以第一天和最后一天都相当于是在高铁上玩一天手机(雾
Day 1 & 2
我们在武汉站登车,高铁从上午十一点一直开到了晚上七点。好在酒店离高铁站很近,走路也就5分钟路程,所以我们就前往了酒店开房。
该说不说,4个人挤双人房的安排是有点逆天的。就算我们没意见,酒店也没意见?!
第二天起来吃了早饭之后我们便走路前往了海边,很近,不过不是海滩。拍了几张照,早上天气真的很差,本来是小雨的天气,结果雨越来越大,风也越来越强。但过了一会天又晴了……
然后就是非常晒人。
下午乘坐青岛地铁去了中山公园附近的沙滩。只能说不愧是夏天,晚上五六点仍然晴空万里。
玩水玩得非常开心,不过也仅限于在海水中跑一跑了。毕竟我可不想和部分其他同学一样弄得浑身湿透。
请同学拍了两张照!
Day 3
走路去了圣弥勒尔大教堂,不过也没进去,就是在外面拍了几张照。

风景很不错,宝宝喜欢妈妈爱。
以及本来还以为会碰到什么传教士什么的,然后我就能回一句”我信铂金龙神巴哈姆特“(大雾,结果没有。
然后就去了老舍故居,看到了《骆驼祥子》相关的很多文物(?)。得亏武汉今年考的是《钢铁是怎样炼成的》,不是《骆驼祥子》,没有被祥子一车创si。
然后就是坐地铁回酒店了,这次是从人民会堂到青岛站。

下午去坐船了,不大不小的船。
我只想说,快艇我不晕,轮船我不晕,所以就是这种两者之间的会晕是吗!!!
下午天气很不好,在海上飘着,外面还下大雨,甚至打雷……
坐了四小时,而后从原港口下了船,感觉像是自找了四小时的罪受,艹。
回酒店后第一时间点了外卖,不然真感觉要吐了。
Day 4
又是地铁!这几天地铁成了我们唯一的陆上交通工具,别的旅行团都会有大巴什么的,我们没有,我们就是坐地铁(
还是人民会堂站下车,这次我们去了小青岛公园。公园环境很好,玩得很开心,甚至还去看了鱼雷洞。
以及走的时候发现了一条绿意盎然的楼梯,拍了张照,很好看(
下午坐一号线去了台东,去了步行街吃晚饭。
兴致突然起来了,和同学一起买了地铁票进站而非使用手机app. 运气挺好,买到了不一样样式的单程票。
下车之后全班就直接分组分头行动了。穿梭于人来人往的小吃摊中,感受到烟火气的缭绕,对于一个忙碌了一整年的初三学生来说实在是太酷啦!
买了铁板豆腐、臭豆腐、鱿鱼和青岛啤酒,香的嘞。
然后去了五四广场,再之后就又回了酒店。
Day 5
又去了海边,不过是坐地铁去的,三号线转二号线。
所以又收集(?)到了两款不一样的地铁票。
还有在五四广场同站换乘。
说实话,天气真的不好,海边景色这几天也看腻了(
浅浅拍了几张照之后就坐地铁回去了,以及又收集到了一种地铁票。
下午老师组织看电影,一起看了端午档的《消失的她》
悬疑片嘛……不是很和我胃口,但是观感还不错。
然后就是吃完饭。老师给了每人80的预算,让分组一起吃晚饭,我就和另外三个同学一起去了海底捞。
第一次去海底捞,服务很好,很符合我的期待,价格也正常,不算很贵,起码没超预算。
点了两个菌菇和麻辣两个汤底,味道就很正常,跟我家里和父母一起煮的火锅差不多。
最后还送了一份面条,海底捞真的,我哭死(大雾
师傅的手艺很好,观赏性十足,爱了爱了。
随便贴几张图吧:
Day 6
早起前往高铁站,赶十点的高铁。
天气阴了这么多天,结果偏偏走的时候才好,我的评价是,6.

坐的复兴号高铁,不过站台另一侧有一辆绿皮火车,于是拍了一张个人觉得很好看的照片:

然后又是玩了一天手机……
最后,晚上6点,回到武汉,与老师同学告别后回到了家,结束了这一场旅行。
题外话
生活记录型的博文,尤其是这么长的,我还是第一次写,有什么不足请多多海涵!
什么?你问中考?
请观阅以下内容:
你说的对,但是《中考》是由武汉教育局自主研发的一款「互联网时代」全新开放世界冒险游戏。游戏发生在一个被称作「HappyPark」的幻想公园,在这里,被「往上提的溢水杯」选中的人将被授予「0.797g沉淀」,导引「两种酸」之力。你将扮演一位名为「有两块抹布的直径0.3m的扫地机器人」的神秘角色,在面积27m2的秘鲁考古遗址中邂逅的紫甘蓝味软糖,和百万年前出士的bright flowers化石一起,找回「简练明快,势巧形密」的家书同时,感受「尽责地爱」,且逐步发掘「点P过定线」的真相。
怎么说呢,今年的题真的很创人。
所以……考的差一点也不要紧啦,哈哈……
···
啊?你真以为我考砸了?
886!
]]>
+
+
+
+
+ 日常
+
+
+
+
+
+
+ 日常
+
+ 旅行
+
+
+
+
+
+
+
+
+ 前、后与中——表达式求值
+
+ /posts/c9c6cb4f/
+
+ 记录一下最近的练习程序与做法,加深记忆,也当个教程吧,毕竟赠人玫瑰手留余香(bushi如果你不知道这些表达式分别指什么东西,可以百度一下,这里不再赘述。
后缀表达式
这个应该是最常见的了,下面讲一下实现。
首先,还是定义函数废话:
然后,进行文件读取,可以用freopen(),不过我这里用的是fopen():
1
2
3
4
5
6
7
8
9
10
| FILE* stream = fopen("input.txt", "r");
stack<double> nums;
while(true) {
char tstr[100];
fscanf(stream, "%s", tstr);
if(feof(stream)) break;
string input = tstr;
}
|
解释一下上面的程序:
stack<double> nums 这个栈后面会用到,这里先不用管fscanf()和scanf()用法一样,唯一的区别是fscanf()用于读取文件流中的信息而非输入流feof()中的参数为文件流,用于判断是否读到结尾,读到则返回真
很显然,这段程序用于分别读入每一段字符,那么接下来便是判断输入了。
代码如下:
1
2
3
4
5
6
7
8
9
10
| while(true) {
if(isdigit(input[0])) {
nums.push(atof(input.c_cstr()));
}
else {
}
}
|
如果输入为整数,则进入数字栈,否则开始计算。
这里使用了isdigit()函数,输入为char类型,用于判断参数是否在'0'与'9'之间。
计算过程很简单,弹出两个数字栈中的数,根据运算符计算即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
else {
double y = nums.top();
nums.pop();
double x = nums.top();
nums.pop();
double temp;
switch(input[0]) {
case '+':
temp = x + y;
break;
case '-':
temp = x - y;
break;
case '*':
temp = x * y;
break;
case '/':
temp = x / y;
break;
}
nums.push(temp);
}
|
尤其要注意减法与除法的操作数与被操作数顺序,毕竟它们可没有交换律。
此时已经计算完成,结果作为栈中唯一的元素处在栈顶,直接输出即可:
1
2
3
4
| fclose(stream);
cout<<nums.top()<<endl;
return 0;
|
大概就是这样。
完整代码还是放一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| #include<bits/stdc++.h>
using namespace std;
inline bool is_num(string str) {
if(str[0] >= '0' && str[0] <= '9') return true;
else return false;
}
int main() {
FILE* stream = fopen("input.txt", "r");
stack<double> nums;
while(true) {
char tstr[100];
fscanf(stream, "%s", tstr);
if(feof(stream)) break;
string input = tstr;
if(is_num(input)) {
nums.push(atof(input.c_str()));
}
else {
double y = nums.top();
nums.pop();
double x = nums.top();
nums.pop();
double temp;
switch(input[0]) {
case '+':
temp = x + y;
break;
case '-':
temp = x - y;
break;
case '*':
temp = x * y;
break;
case '/':
temp = x / y;
break;
}
nums.push(temp);
}
}
fclose(stream);
cout<<nums.top()<<endl;
return 0;
}
|
输入样例:
输出样例:
前缀表达式
细心一点就能发现,它与后缀表达式几乎一样,只是顺序不同。
没错,这正是因为前、后、中缀表达式分别为表达式树的先序、后续与中序遍历。
利用这个性质,将后缀表达式的顺序稍稍更改即可得到前缀表达式求值的程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| #include<bits/stdc++.h>
using namespace std;
inline bool is_num(string str) {
if(str[0] >= '0' && str[0] <= '9') return true;
else return false;
}
int main(){
FILE* stream = fopen("input.txt", "r");
stack<double> nums;
vector<string> input;
while(true) {
char tstr[100];
fscanf(stream, "%s", tstr);
if(feof(stream)) break;
input.push_back(string(tstr));
}
for(int i = input.size() - 1;i >= 0;i--) {
if(is_num(input[i])) {
nums.push(atof(input[i].c_str()));
}
else {
double x = nums.top();
nums.pop();
double y = nums.top();
nums.pop();
double temp;
switch(input[i][0]) {
case '+':
temp = x + y;
break;
case '-':
temp = x - y;
break;
case '*':
temp = x * y;
break;
case '/':
temp = x / y;
break;
}
nums.push(temp);
}
}
fclose(stream);
cout<<nums.top()<<endl;
return 0;
}
|
改成倒序读取即可。
输入样例:
输出样例:
中缀表达式
我们最常用的表达式,处理起来却是最复杂的,因为现在需要考虑优先级与括号了。
这里有几种方法:
递归
首先,定义函数用于取多项式的因子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| int factor() {
int res = 0;
char c = cin.peek();
if(c == '(') {
cin.get();
res = expression();
cin.get();
}
else {
while(isdigit(c)) {
res = 10 * res + c - '0';
cin.get();
c = cin.peek();
}
}
return res;
}
|
先定义结果为0,然后判断输入。若为括号,则将其内容视为新表达式,交由马上要定义的expression()函数计算。否则,按位取出输入中的数即可。
顺带一提,这些代码中的cin.get()与cin.peek()尤其重要,切勿移动位置或轻易替换。至于原因,自己模拟想一下吧。
然后,计算单项式的值,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| int term() {
int res = factor();
while(true) {
char mark = cin.peek();
if(mark == '*' || mark == '/') {
cin.get();
int v = factor();
if(mark == '*') res *= v;
else res /= v;
}
else break;
}
return res;
}
|
先用factor()函数读入因子,然后循环判断该单项式是否读完。若未读完(即该因子与下一个因子间仍用乘号或除号连接)则取下一个因子并计算,否则返回该单项式的值即可。并且很显然,这样的写法就代表输入的表达式中不应当含有任何空格,也只支持整数运算(要浮点数自己改我不干了)。
最后是整个表达式,与计算单项式基本一样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| int expression() {
int res = term();
while(true) {
char mark = cin.peek();
if(mark == '+' || mark == '-') {
cin.get();
int v = term();
if(mark == '+') res += v;
else res -= v;
}
else break;
}
return res;
}
|
读入单项式再计算,直到该表达式计算完毕(即mark取到)或EOF)
主函数其实已经一目了然了,重定向输入再调用expression()即可,就不写了。
输入样例:
输出样例:
栈
这里又分为两种方案:
转为后/前缀表达式再计算
这里的重点是转换的过程,逻辑整体如下(中缀->后缀):
- 输入若为数字,直接放入输出表达式中。若为符号:
- 如果符号栈为空,则放入符号栈中
- 如果符号栈栈顶元素优先级大于等于该符号,则出栈栈顶符号放入表达式,若此时栈顶符号优先级大于等于该符号,则重复以上流程直至小于,而后入栈该符号
- 如果符号栈栈顶元素优先级小于该符号,该符号入栈
- 如果该符号为左括号,直接入栈
- 如果该符号为右括号,则依次出栈符号栈栈顶元素放入表达式中,直至左括号。最后抛弃左括号与右括号
- 若输入完毕,符号栈中仍有符号,则依次出栈放入表达式
代码如下(转为后缀表达式):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| map<char, int> markl;
markl['+'] = 0;
markl['-'] = 0;
markl['*'] = 1;
markl['/'] = 1;
FILE* stream = fopen("input.txt", "r");
stack<char> marks;
vector<string> expression;
while(true) {
char tstr[100];
fscanf(stream, "%s", tstr);
if(feof(stream)) break;
string input = tstr;
if(isdigit(input[0])) {
expression.push_back(input);
}
else if(input[0] == '(') {
marks.push('(');
}
else if(input[0] == ')') {
while(true) {
if(marks.top() == '(') {
marks.pop();
break;
}
char t[2] = {marks.top(), '\0'};
expression.push_back(string(t));
marks.pop();
}
}
else {
if(marks.empty() || marks.top() == '(') {
marks.push(input[0]);
}
else if(markl[input[0]] <= markl[marks.top()]) {
while(!marks.empty() && markl[temp[0]] <= markl[marks.top()]) {
char t[2] = {marks.top(), '\0'};
expression.push_back(string(t));
marks.pop();
}
marks.push(input[0]);
}
else {
marks.push(input[0]);
}
}
}
while(!marks.empty()) {
char t[2] = {marks.top(), '\0'};
expression.push_back(string(t));
marks.pop();
}
|
和上面的逻辑完全一样,唯一要注意的是这里使用了map,可以理解为字典。
然后只需要计算就行,代码就不放了。
前缀表达式的逻辑与代码可以自己想想。
输入输出样例同下面。
直接计算
逻辑和转换本身是一样的,只不过没有了表达式向量,而是直接计算后放入数字栈。
即将所有的对于expression的操作改为计算即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
| #include <bits/stdc++.h>
using namespace std;
double calc(char mark, double x, double y) {
double temp = 0;
switch(mark) {
case '+':
temp = x + y;
break;
case '-':
temp = x - y;
break;
case '*':
temp = x * y;
break;
case '/':
temp = x / y;
break;
}
return temp;
}
int main() {
FILE* stream = fopen("input.txt", "r");
map<char, int> markl;
markl['+'] = 0;
markl['-'] = 0;
markl['*'] = 1;
markl['/'] = 1;
stack<char> marks;
stack<double> nums;
while(true) {
char tstr[100];
fscanf(stream, "%s", tstr);
if(feof(stream)) break;
string temp = tstr;
if(isdigit(temp[0])) {
nums.push(atof(temp.c_str()));
}
else if(temp[0] == '(') {
marks.push('(');
}
else if(temp[0] == ')') {
while(true) {
if(marks.top() == '(') {
marks.pop();
break;
}
double y = nums.top();
nums.pop();
double x = nums.top();
nums.pop();
nums.push(calc(marks.top(), x, y));
marks.pop();
}
}
else if(marks.empty() || marks.top() == '(') {
marks.push(temp[0]);
}
else if(markl[temp[0]] <= markl[marks.top()]) {
while(!marks.empty() && markl[temp[0]] <= markl[marks.top()]) {
double y = nums.top();
nums.pop();
double x = nums.top();
nums.pop();
nums.push(calc(marks.top(), x, y));
marks.pop();
}
marks.push(temp[0]);
}
else {
marks.push(temp[0]);
}
}
while(!marks.empty()) {
double y = nums.top();
nums.pop();
double x = nums.top();
nums.pop();
nums.push(calc(marks.top(), x, y));
marks.pop();
}
fclose(stream);
cout<<nums.top()<<endl;
return 0;
}
|
输入样例:
1
| ( 28 / 7 ) / 2 + ( 8 - 9 )
|
输出样例:
收工!
题外话
这篇大概是我最长的纯原创技术类博文了。。。。。。
好累QAQ
下次再见啦!886!
2023.04.03更新
让ChatGPT改了一个支持浮点数的递归版本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
| #include <iostream>
#include <cstdlib>
#include <cstdio>
using namespace std;
void print_tab(int);
void print_log(string, int);
void print_log(string, int, double);
double expression(int);
double term(int);
double factor(int);
int main() {
freopen("input.txt", "r", stdin);
cout << expression(0) << endl;
return 0;
}
void print_tab(int deep) {
for(int i = 0;i < deep;i++) {
cout << "\t";
}
return;
}
void print_log(string name, int deep) {
print_tab(deep);
cout << name << " {" << endl;
return;
}
void print_log(string name, int deep, double res) {
print_tab(deep);
cout << "} -> res =" << res << endl;
return;
}
double expression(int deep) {
print_log("expression", deep);
double res = term(deep + 1);
while(true) {
char mark = cin.peek();
if(mark == '+' || mark == '-') {
cin.get();
double v = term(deep + 1);
if(mark == '+') res += v;
else res -= v;
}
else break;
}
print_log("expression", deep, res);
return res;
}
double term(int deep) {
print_log("term", deep);
double res = factor(deep + 1);
while(true) {
char mark = cin.peek();
if(mark == '*' || mark == '/') {
cin.get();
double v = factor(deep + 1);
if(mark == '*') res *= v;
else res /= v;
}
else break;
}
print_log("term", deep, res);
return res;
}
double factor(int deep) {
print_log("factor", deep);
double res = 0;
double base = 1.0;
char c = cin.peek();
if(c == '(') {
cin.get();
res = expression(deep + 1);
cin.get();
}
else {
while(isdigit(c) || c == '.') {
if(c == '.') {
cin.get();
c = cin.peek();
while(isdigit(c)) {
res = res + (c - '0') * (base /= 10.0);
cin.get();
c = cin.peek();
}
break;
}
res = res * 10 + c - '0';
cin.get();
c = cin.peek();
}
}
print_tab(deep + 1);
cout << "get_num();" << endl;
print_log("factor", deep, res);
return res;
}
|
神
]]>
+
+
+
+
+ 编程
+
+
+
+
+
+
+ 计算机
+
+ 编程
+
+ c++
+
+ 算法
+
+
+
+
+
+
+
+
+ 迟来的二月调考总结
+
+ /posts/7eb4319/
+
+ 各位,好久不见,距离上次发文的时间过的有点久,其中最大的原因就是万恶的二月调考。现在已经考完一个多月了离四调也就一个月了,这里我来总结一下。 背景要素
以防不知道,本人生在武汉,学籍武汉,参加武汉的统一考试。武汉在九年级时会有几场全市统考,分别为九上的元月调考(期末)与九下的四月调考(期中)和中考(期末)。今年闹疫情,于是原定在一月四号的元调被挪到了二月二十一号(九下开头)。
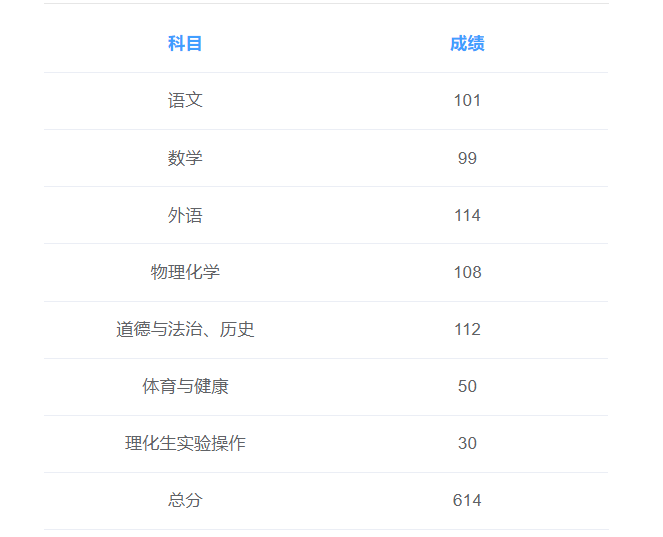
武汉的中考在我这一届改革了,下面对比一下以往和之后的不同:
| 科目 | 分数(前) | 分数(后) |
|---|
| 语文 | 120 | 120 |
| 数学 | 120 | 120 |
| 英语 | 120 | 120 |
| 物理 | 70 | 70 |
| 化学 | 50 | 50 |
| 历史 | \ | 60 |
| 道德与法治 | 40 | 60 |
| 实验 | 0 | 30 |
| 体育 | 30 | 50 |
| 总分 | 550 | 680 |
详解:
- 原本不考历史
- 道德与法治原先只有选择题,现在新加入了材料题,分数构成为
28分选择 + 32分材料。历史分数构成与其一样,且二者合卷 - 实验考试以往不计分,为实操。现在为机考答卷,在120道题(40物理,40化学,40生物)中每个科目随机选10道题目作答,每题一分
- 体育由30分改为50分,构成为
15分平时 + 35分考试。本届由于新冠疫情的原因,取消体育中考(即所有人考试分数计为35)
二调情况
先明确二调的考试内容,为中考所有科目除去体育与实验(四调亦然)
分数不是很方便透露,大致说一下考试情况吧。说来惭愧,正正好好是语数英垮了(bushi
语文选择题眼瞎,错了两题。英语则是阅读理解B篇,神你以为我会说脏话吗?的Live a colorful life,我真感觉不到这么大,真的。
总之就是很意难平。
好消息是化学满分,终于!
签约的话倒不是不能签,只能说是比上不足,比下有余余余余余…
总结
也没什么可说的,给自己加油吧。我是想打竞赛的,文化课成绩必然需要更上一层楼才行。
886!
(鬼知道下次什么时候更新)
]]>
+
+
+
+
+ 个人
+
+
+
+
+
+
+ 总结
+
+ 学习
+
+ 考试
+
+
+
+
+
+
+
+
+ 全站 webp 自动切换,加速访问好帮手
+
+ /posts/23e22de2/
+
+ 原本博客用的都是普通图片,就算有懒加载,一堆圈圈一起转也惹人心烦。现在改为了原图/webp的自适应切换,效果好上不少。 前期准备
首要任务是拿到webp格式的图片,这个看自己。像我用的vps上的Lsky Pro,本地存储。有高性能vps可以试试用Webp-Server配合。但我的轻量应用承受不起,遂作罢。改为了定时shell脚本,一分钟触发一次:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| #!/bin/bash
find . -type f -iname "*.png" | while read file; do
if [ ! -f "${file%.*}.webp" ]; then
cwebp -q 85 "$file" -o "${file%.*}.webp"
fi
done
find . -type f -iname "*.jpg" | while read file; do
if [ ! -f "${file%.*}.webp" ]; then
cwebp -q 85 "$file" -o "${file%.*}.webp"
fi
done
find . -type f -iname "*.jpeg" | while read file; do
if [ ! -f "${file%.*}.webp" ]; then
cwebp -q 85 "$file" -o "${file%.*}.webp"
fi
done
find . -type f -iname "*.tif" | while read file; do
if [ ! -f "${file%.*}.webp" ]; then
cwebp -q 85 "$file" -o "${file%.*}.webp"
fi
done
|
脚本运行时会遍历自己所在的文件夹及其子文件夹,转换所有没有对应webp格式的图片(png,jpg、jpeg与tiff)为webp图片(原图还在,放心)。
这段脚本中使用了cwebp指令,它来源于libwebp。安装可以参考下方:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # 安装编译器以及依赖包
yum install -y gcc make autoconf automake libtool libjpeg-devel libpng-devel
# 请到官网下载最新版本,版本列表:https://storage.googleapis.com/downloads.webmproject.org/releases/webp/
wget https://storage.googleapis.com/downloads.webmproject.org/releases/webp/libwebp-1.2.4.tar.gz
# 解压
tar -zxvf libwebp-1.2.4.tar.gz
# 进入目录
cd libwebp-1.2.4
# 源代码安装环境检查
./configure
# 编译
make
# 安装
make install
|
安装过程中遇到问题请善用百度/Google,本人不对此负责(bushi
做好以上所有工作后,就可以开始下面的内容。
Service Worker
安装
不知道是什么、如何部署的,可以看看CYF大佬的这两篇文章:
如果你已经部署了Service Worker就可以继续了。
脚本
添加一个监听器,监听fetch事件:
1
2
3
| self.addEventListener('fetch', async event => {
});
|
(或者在本来的监听器里面加上)
然后判断流量是否是对图站的请求,可以用一个if来判断:
1
2
3
4
| if(event.request.url.indexOf('your.image.site') !== -1) {
var requestUrl = event.request.url;
}
|
event.request.url是请求的地址,用indexOf()方法来判断地址中是否包含图站地址,若不反回代表没有的-1即为是对图站的请求。
接下来判断浏览器是否支持webp图片,定义一个变量supportsWebp
1
2
3
4
5
6
| var supportsWebp = false;
if (event.request.headers.has('accept')){
supportsWebp = event.request.headers
.get('accept')
.includes('webp');
}
|
如果可以获取到浏览器的Accept头,且头中包含image/webp,即为支持webp,否则为不支持。
然后就可以进一步处理了,若浏览器支持webp,则进行下一步:
1
2
3
4
5
6
| if (supportsWebp) {
}
else {
console.log("[SW] Don't support webp image, skip " + requestUrl + " .");
}
|
然后获取请求的文件类型。最开始的脚本只支持png,jpg、jpeg与tiff这四种格式的图片,所以我们也只能篡改这四种格式图片的请求到webp图片上:
1
2
3
4
5
| var imageUrl = requestUrl.split(".");
if(imageUrl[imageUrl.length - 1] === 'jpg' || imageUrl[imageUrl.length - 1] === 'tif' || imageUrl[imageUrl.length - 1] === 'png' || imageUrl[imageUrl.length - 1] === 'jpeg') {
var newUrl = requestUrl.replace(imageUrl[imageUrl.length - 1], 'webp');
}
|
newUrl中存储了新的请求地址,接下来对它发起请求即可:
1
2
3
| var newRequest = new Request(newUrl);
event.respondWith(fetch(newRequest));
console.log("[SW] Redirect " + requestUrl + " to " + newUrl + " .");
|
当请求完成并图片被完整下载以后,进行缓存,代码如下:
1
2
3
4
5
6
7
8
9
10
| event.waitUntil(
fetch(newRequest).then(function(response) {
if (!response.ok) throw new Error("[SW] Failed to load image: " + newUrl);
caches.open(CACHE_NAME).then(function(cache) {
cache.put(newRequest, response);
});
}).catch(function(error) {
console.log(error);
})
);
|
若获取失败则提示,成功则缓存。
最后,要打断之前的请求,避免降低速度,可以调用event.stopImmediatePropagation()方法打断原始请求。
最后完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| if(event.request.url.indexOf('img.ordchaos.com') !== -1) {
var requestUrl = event.request.url;
var supportsWebp = false;
if (event.request.headers.has('accept')){
supportsWebp = event.request.headers
.get('accept')
.includes('webp');
}
if (supportsWebp) {
var imageUrl = requestUrl.split(".");
if(imageUrl[imageUrl.length - 1] === 'jpg' || imageUrl[imageUrl.length - 1] === 'tif' || imageUrl[imageUrl.length - 1] === 'png' || imageUrl[imageUrl.length - 1] === 'jpeg'){
var newUrl = requestUrl.replace(imageUrl[imageUrl.length - 1], 'webp');
var newRequest = new Request(newUrl);
event.respondWith(fetch(newRequest));
console.log("[SW] Redirect " + requestUrl + " to " + newUrl + " .");
event.waitUntil(
fetch(newRequest).then(function(response) {
if (!response.ok) throw new Error("[SW] Failed to load image: " + newUrl);
caches.open(CACHE_NAME).then(function(cache) {
cache.put(newRequest, response);
});
}).catch(function(error) {
console.log(error);
})
);
event.stopImmediatePropagation();
return;
}
}
else {
console.log("[SW] Don't support webp image, skip " + requestUrl + " .");
}
}
|
你学会了吗?
测试
进入网站,若一切正常,当加载到一张图片时,控制台(F12打开)会提示[SW] Redirect https://your.image.site/path/to/img.png to https://your.image.site/path/to/img.webp .这样的信息。
要测试无webp支持的情景,则点击右上角的三个点。

选择更多工具,找到“渲染”并点击。

勾选“停用webp”即可。
此时,加载图片时会提示[SW] Don't support webp image, skip https://your.image.site/path/to/img.png .
可以试试我这里的这张图片:

若浏览器支持webp则会显示Webp Accept!,否则为Webp Reject!This is a jpg file.
题外话
刚刚放寒假,舒坦。
但与之对应,九上已经结束,还有一学期就中考。。。
加油!我可以的!
那就这样,886!
]]>
+
+
+
+
+ 编程
+
+ 教程
+
+
+
+
+
+
+ 计算机
+
+ 编程
+
+ 教程
+
+ 优化
+
+
+
+
+
+
+
+
+ 自托管 E-mail ,宝宝喜欢妈妈爱
+
+ /posts/3b90dbec/
+
+ 本来一直在用阿里云的企业邮箱,但感觉总是不太好,主要每次都需要进https://qiye.aliyun.com登录。于是趁着黑色星期五RackNerd的优惠,搞了一台vps来搭电子邮局(如果你想搭建,请确认服务器是否支持rDNS以及是否开启25端口)。配置如下(年付$10.28)
| 硬件 | 配置 |
|---|
| CPU | 1核 |
| RAM | 768MB |
| SSD | 10GB |
| 流量 | 1TB |
还是比较磕碜的,不过价格在这,无所谓了。
经历
首先,我需要为vps开通rDNS记录到mx.ordchaos.com上。后台可以自主设置,很方便…

好,很好,我沉得住气。发个工单问一下:

哦!原来如此!好的,继续交流后,rDNS设置成功,但然而我却发现无法访问?!一番探查之后,发现这样一个事实——被墙啦!
于是只得继续发工单:

终于搞定。
Mailu.io部署
设置主机名
在vps的bash中输入:
在其中具有服务器ip地址的一行中,将后面的内容改为(假设你的域名是example.com,服务器ip是88.88.88.88):
1
| 88.88.88.88 mx.example.com mx
|
编辑好后,在vps中执行:
1
2
| echo "mx" > /etc/hostname
hostname -F /etc/hostname
|
这样就设置好了主机名,可以通过hostname命令确认是否设置成功:
前者只会输出mx,后者则会输出mx.example.com。如果不是,那就是设置错了。
设置DNS解析
去你的域名DNS解析服务商,设置以下DNS解析(假设你的域名是example.com,服务器ip是88.88.88.88):
然后去vps服务商,设置rDNS(或者叫做PTR)解析,将88.88.88.88解析到mx.example.com
获取配置
访问Mailu.io的配置生成网页:https://setup.mailu.io
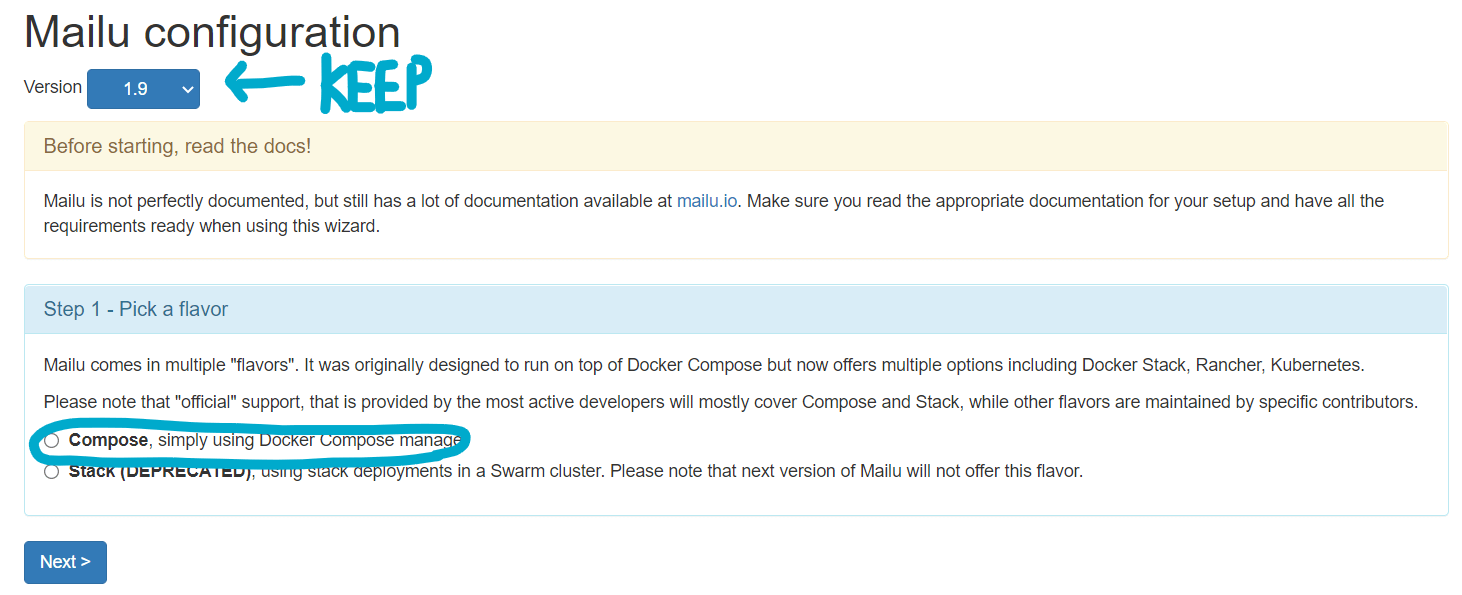
写文时最新版本为1.9,保持不变。下方部署方式选择Compose.
最后,你会看到如下界面:
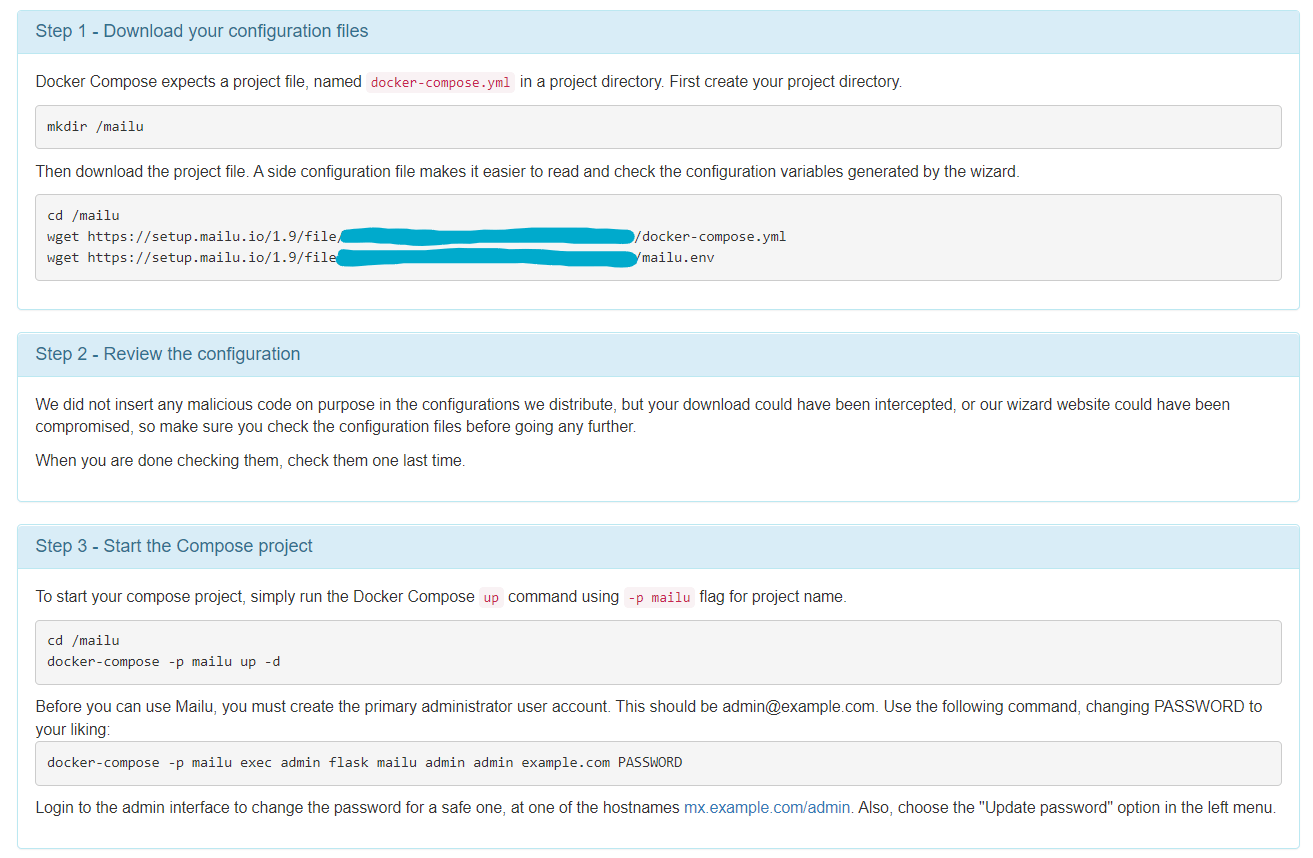
照着界面的指示,回到vps执行指令:
然后回到刚刚的页面,下载配置文件:
1
2
| wget http://setup.mailu.io/1.7/file/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/docker-compose.yml
wget http://setup.mailu.io/1.7/file/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/mailu.env
|
最后执行(假设你的域名是example.com,密码设置为PASSWORD):
1
2
| docker-compose -p mailu up -d
docker-compose -p mailu exec admin flask mailu admin admin example.com PASSWORD
|
就安装完成了。
配置
在浏览器中访问https://mx.example.com登录您的管理员面板:

使用账号admin@example.com和密码PASSWORD登录即可(假设你的域名是example.com,密码设置为PASSWORD)。
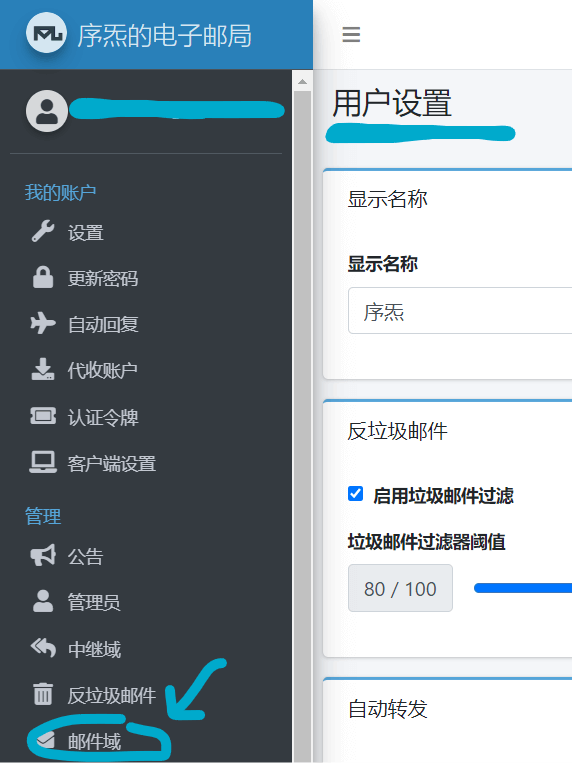
然后点击左侧的“邮件域”:
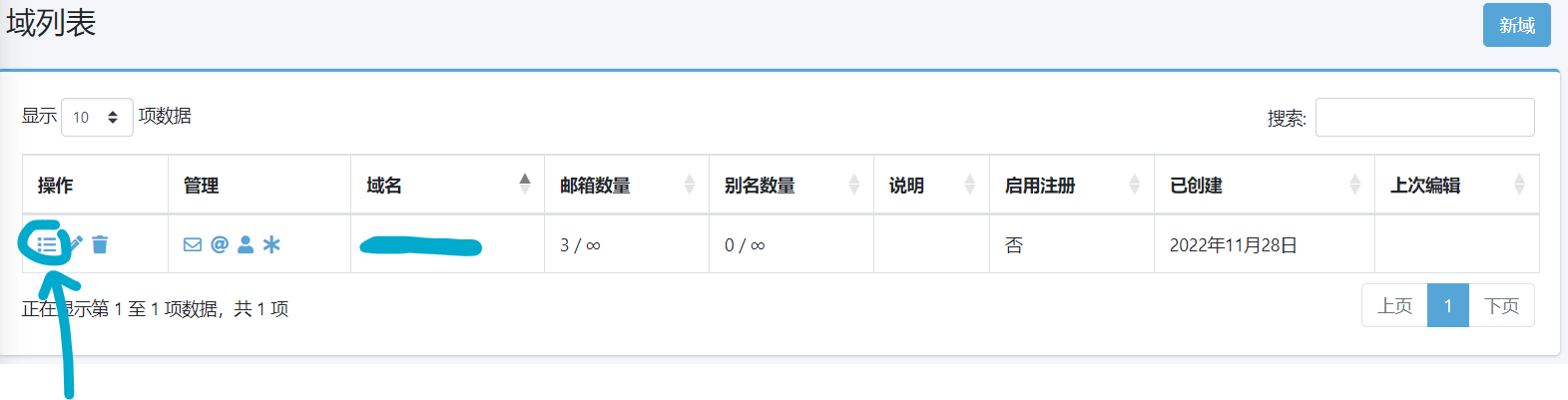
然后点击如下的按钮:
在新界面中点击“生成密钥”,然后复制dkim配置:
1
| dkim._domainkey.example.com. 600 IN TXT "v=DKIM1; k=rsa; p=xxxxxxxxxxxxxxxxxxxxxxxxxxxx" "xxxxxxxxxxxxxxxxxxxxxxxxxxxx"
|
进行域名解析即可。
创建账号
邮件域>用户>添加用户,按需配置即可。
使用
退出管理员账号,访问https://mx.example.com/webmail,登录即可(选择“登录Webmail”)。

测试
在MailTester上可以进行测试,如下是我测试结果:
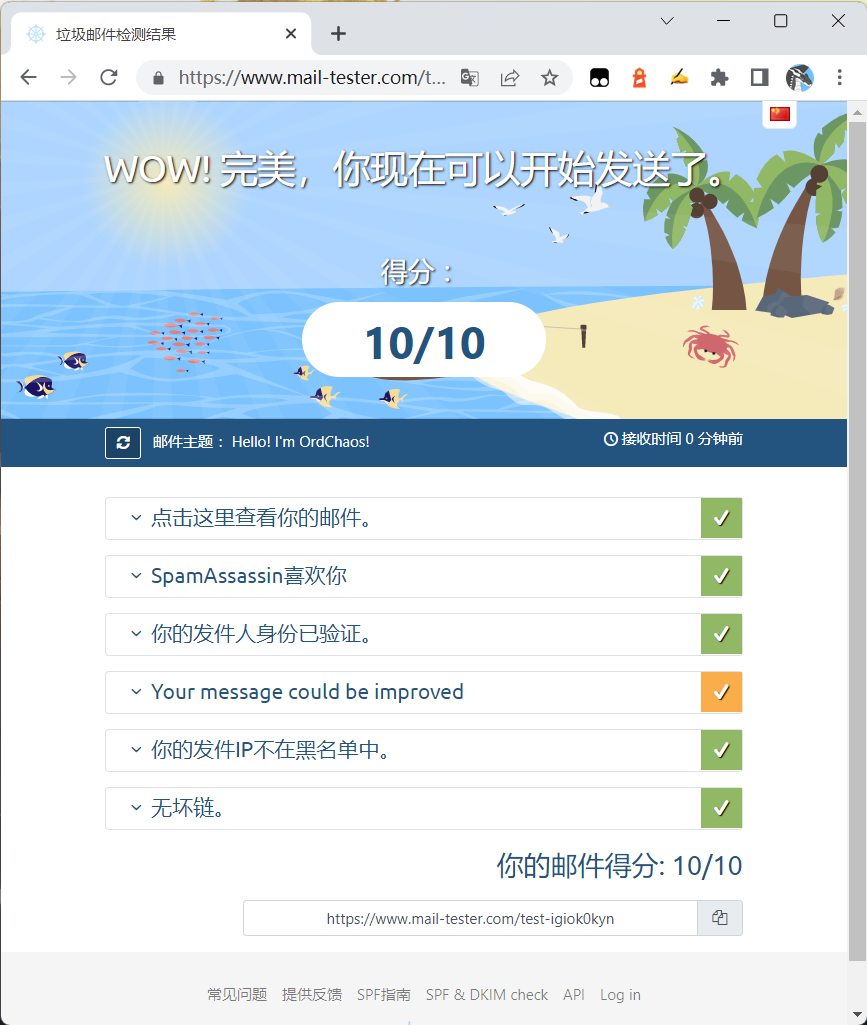
很完美了,对吧(
以前没有超过8过
题外话
完成了很久以前的夙愿。
欢迎跟着做一遍哦!也欢迎提问!
]]>
+
+
+
+
+ 教程
+
+
+
+
+
+
+ 计算机
+
+ 编程
+
+ 教程
+
+ 电子邮件
+
+ vps
+
+
+
+
+
+
+
+
+ 船新说说页面—— Memos 初体验
+
+ /posts/3386e07f/
+
+ 博客的说说真的是一波三折…最开始用的是HexoPlusPlus的说说,很好用也很流畅小巧,但是自Hpp停止开发后就用不了了。
然后改用了bber,也很不错,但是辣鸡腾讯云也是离谱,好好的羊毛突然就不让薅了,同时我的twikoo也被迫迁移到了vercel,只得抛弃。
中途也用过别的说说系统,比如说大名鼎鼎的Artitalk亦或者是iSpeak等等,但是都不太满意,而后因为各式各样的原因放弃。
本来我会一直被这玩意困扰…现在不会了!只因为我发现了它——Memos
开源,私有部署,这不就是我要的完美的说说系统吗?!
后端部署
很简单,首先你要有一台vps,然后装上docker.
随后一句指令即可搞定:
1
| docker run -d --name memos -p 5230:5230 -v ${PWD}/.memos/:/var/opt/memos neosmemo/memos:latest
|
随后Memos就会被部署到5230端口,觉得不方便也可以反向代理,这个教程有很多,这里就不写了。
前端
单页
可以看看我的:说说
样式完全是自己写的…你知道对一位学C++的初三学生而言css是什么东西吗?!好吧随便写写也不算难
js来自immmmm,稍微改了一点点,可以在这里看看被压缩了根本看不了。
总体而言,如果你也想要部署一个和我完全一样的页面,可以用以下html代码:(记得下载js文件)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| <div class='memo-nums'>
<p class='note note-info memo-nums-text'>
共有 <span id='memonums'>「数待载之」</span> 条说说
</p>
</div>
<div id="bber"></div>
<script type="text/javascript">
var bbMemos = {
memos : 'https://memos.ordchaos.top/',
limit : '',
creatorId:'1' ,
domId: '',
}
</script>
<script src="//jsd.ordchaos.top/marked/marked.min.js"></script>
<script src="/js/talk.js"></script>
|
注意这里用了Tag插件,如果用不了记得改改。
首页轮播
这个就比较简单了,直接在主题的index.ejs里加上以下代码即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| <p class='note note-info memo-nums-text'>
<i class="iconfont icon-speakernotes"></i><span id="memos-index-space"> </span><span id='memos-t'>首页说说轮播加载中...</span>
</p>
<script src="/js/lately.min.js"></script>
<script>
let jsonUrl =
"https://memos.ordchaos.top/api/memo?creatorId=1&rowStatus=NORMAL" +
"&t=" +
Date.parse(new Date());
fetch(jsonUrl)
.then((res) => res.json())
.then((resdata) => {
data = resdata.data,
resultIndexMemos = new Array(data.length);
for (var i = 0; i < data.length; i++) {
var talkTime = new Date(
data[i].createdTs * 1000
).toLocaleString();
var talkContent = data[i].content;
var newtalkContent = talkContent
.replace(/```([\s\S]*?)```[\s]*/g, " <code>$1</code> ")
.replace(/`([\s\S ]*?)`[\s]*/g, " <code>$1</code> ")
.replace(/<iframe([\s\S ]*?)iframe>[\s]*/g, "📺")
.replace(/\!\[[\s\S]*?\]\([\s\S]*?\)/g, "🌅")
.replace(/\[[\s\S]*?\]\([\s\S]*?\)/g, "🔗")
.replace(
/\bhttps?:\/\/(?!\S+(?:jpe?g|png|bmp|gif|webp|jfif|gif))\S+/g,
"🔗"
);
if(newtalkContent.length > 25) {
newtalkContent = newtalkContent.substring(0, 25) + '...';
}
resultIndexMemos[i] = `<span class="datetime">${talkTime}</span>: <a href="https://www.ordchaos.com/talk/">${newtalkContent}</a>`;
}
});
var i = 0;
setInterval(function () {
document.getElementById("memos-t").innerHTML = resultIndexMemos[i];
window.Lately && Lately.init({ target: ".datetime" });
i++;
if(i == resultIndexMemos.length) i = 0;
}, 3000);
</script>
|
Tag仍然是不能用就记得改。代码来自eallion,仍然是改了一下原本的逻辑怎么看怎么怪好吧也可能是我没看懂——总而言之,无意冒犯。
javascript总算是好些那么一点点,起码与c++还有那么一点像,外加上自己写GDScript的经验,稍稍改点也不算难事改了一小时
效果
自己去看看不行吗,动动手指的事


题外话
前前后后搞了半个月了,终于是在学习的闲暇时间整完,中途也是收获良多。
那就这样,886!
]]>
+
+
+
+
+ 编程
+
+ 教程
+
+
+
+
+
+
+ javascript
+
+ css
+
+ memos
+
+ html
+
+ 说说
+
+ 前端
+
+
+
+
+
+
+
+
+ Picgo ,我 ...... 我 ......
+
+ /posts/28b74a2d/
+
+ 如题,我要被这个神仙软件气死了。 起因
准备装unity写个游戏,学一学C#,然后就发现C盘爆满飘红。用SpaceSniffer看了一下——好家伙!
Picgo的日志文件,占了我58.6GB.
解释
当Picgo上传图片失败时就会开始疯狂写日志,然后文件大小就爆炸。
解决
删掉日志,从组策略里设置一下日志文件大小限制就好了。
可以参考这个:如何在Windows10系统设置日志文件的最大大小
题外话
就离谱!!!
]]>
+
+
+
+
+ 教程
+
+
+
+
+
+
+ 计算机
+
+ 编程
+
+ 教程
+
+ Picgo
+
+
+
+
+
+
+
+
+ 堆
+
+ /posts/fab451a5/
+
+ 马上就是今年的CSP-J了,一想起自己还有那么多数据结构没学就有点头皮发麻…这篇博文里我就来讲一下堆(Heap),一是方便他人,二是给自己巩固思路。 讲解
按照惯例哪里来的惯例,还是看一下堆是什么东西:
堆(heap)是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵树的数组对象。堆总是满足下列性质:
- 堆中某个结点的值总是不大于或不小于其父结点的值;
- 堆总是一棵完全二叉树。
将根结点最大的堆叫做最大堆或大根堆,根结点最小的堆叫做最小堆或小根堆。
——百度百科 堆
很显然,为了储存堆,我们需要一棵完全二叉树。这里很多人就会想到建树,但其实不用。如果你看过我的学习笔记——二叉树的话,应该会记得完全二叉树的性质之一:
在有n个节点的完全二叉树中,对于编号为i的节点:
- 若i=1,则其无父节点,为根节点,否则其父节点编号为floor(2i)。
- 若2i>n,则i为叶节点,否则其左孩子的编号为2i。
- 若2i<n<2i+1,则i无右孩子,否则其右孩子的编号为2i+1。
——序炁 学习笔记——二叉树
所以我们只需要一个数组就可以存储堆了:数组最开始填入根节点,其左右孩子节点便依次为其后面的两个下标,再往后就以此类推。
那么现在建立一个数据结构用来建堆,很简单,参照下列代码:
1
2
3
4
5
6
| #define MAXSIZE 100000
struct myHeap {
int value[MAXSIZE];
int length;
};
|
对于每一个堆都申请一个MAXSIZE大小的数组用于存储,而后用length变量存储目前的总节点数即可。
那么如何初始化就显而易见,只需要
1
2
3
4
| inline void init(myHeap &heap) {
heap.length = 0;
return;
}
|
像这样将length设为0就大功告成。
插入元素
如果要往一个堆里插入元素,那我们就要先确定这个堆是小根堆还是大根堆,下面的所有代码均默认是小根堆,大根堆自己改去自己想想吧。
首先,在堆末尾加入要插入的元素:
1
2
3
4
| void push(myHeap &heap, int v) {
heap.value[heap.length++] = v;
}
|
length永远指向数组中最后一个存储了数据的位置的下一个位置,所以在value[length]的位置存储数据,然后增加length即可。
但现在这个堆可能不满足小根堆的性质了,怎么办呢?很简单,进行调整即可。将新节点设为当前节点,如果它大于父节点则结束,若小于则交换,而后将交换后的父节点(没错,还是新插入的数据)设为当前节点,重复这个过程直到其大于父节点或其为根节点则结束。
听着有些复杂,但用while循环即可轻松实现:
1
2
3
4
5
6
7
8
9
| void push(myHeap &heap, int v) {
int now = length;
while(heap.value[now - 1] < heap.value[now / 2 - 1] && now != 1) {
swap(heap.value[now - 1], heap.value[now / 2 - 1]);
now /= 2;
}
return;
}
|
完事!
删除元素
删除元素即出队,会弹出根节点。故而这里的方法是把最后一个节点移到根节点的位置覆盖掉它,再进行调整。
覆盖很简单:
1
2
3
4
| void pop(myHeap &heap) {
heap.value[0] = heap.value[--heap.length];
}
|
不要忘记将节点数减一即可。这里用了一个小技巧,本来要写成这样:
1
2
| heap.value[0] = heap.value[heap.length - 1];
heap.length--;
|
竞赛常考之一,++i与i++的区别。不要觉得没用,比如用在这里就非常合适。包括前面的
1
| heap.value[heap.length++] = v;
|
也用了这个方法。
好了,言归正传,下一步是调整节点。显然,这一次需要从上往下调整:将根节点设为当前节点,与自己左右孩子中较小的一个比较,若小于则结束,否则与其交换位置并将当前节点设为交换好的孩子节点(一样指向同样的数据),重复这个过程直到当前节点为叶节点或当前节点小于自己任何一个孩子为止。
同样,上代码:
1
2
3
4
5
6
7
8
9
10
11
12
| void pop(myHeap &heap) {
int now = 1;
while(2 * now <= heap.length) {
int temp = 2 * now - 1;
if(temp + 2 <= heap.length && heap.value[temp] > heap.value[temp + 1]) temp++;
if(heap.value[now - 1] > heap.value[temp]) swap(heap.value[now - 1], heap.value[temp]);
else break;
now = temp + 1;
}
return;
}
|
需要额外注意的是对当前节点是否为叶节点以及是否拥有右孩子的判断,避免因失误导致数据溢出。
应用
其实堆的操作也只有插入与删除,不过就是这么简单的东西也可以玩出不同的花样,下面是两个例子。
洛谷 P1090 NOIP2004 提高组 合并果子
原题链接:洛谷 P1090 NOIP2004 提高组 合并果子
题目描述
在一个果园里,多多已经将所有的果子打了下来,而且按果子的不同种类分成了不同的堆。多多决定把所有的果子合成一堆。
每一次合并,多多可以把两堆果子合并到一起,消耗的体力等于两堆果子的重量之和。可以看出,所有的果子经过n-1次合并之后,就只剩下一堆了。多多在合并果子时总共消耗的体力等于每次合并所耗体力之和。
因为还要花大力气把这些果子搬回家,所以多多在合并果子时要尽可能地节省体力。假定每个果子重量都为1,并且已知果子的种类 数和每种果子的数目,你的任务是设计出合并的次序方案,使多多耗费的体力最少,并输出这个最小的体力耗费值。
例如有3种果子,数目依次为1,2,9. 可以先将1、2堆合并,新堆数目为3,耗费体力为3. 接着,将新堆与原先的第三堆合并,又得到新的堆,数目为12,耗费体力为12。所以多多总共耗费体力为3+12=15。可以证明15为最小的体力耗费值。
输入格式
共两行。
第一行是一个整数n(1≤n≤10000),表示果子的种类数。
第二行包含n个整数,用空格分隔,第i个整数ai(1≤ai≤20000)是第i种果子的数目。
输出格式
一个整数,也就是最小的体力耗费值。输入数据保证这个值小于231.
输入输出样例
输入
输出
分析
简单的贪心算法,每次从所有果子中取两堆数量最小的合并,然后放回去即可。
不一定非要用堆,不过如果只是简单的排序的话会超时。不过你同样也可以用优先队列,或者看看洛谷上那些神犇的题解。
我的方法很简单,只需要建堆,然后从堆中取两个最小值(即小根堆堆顶元素)相加再插回去,直到只剩一个元素即可。其中每一次合并时用一个变量累计总体力,最后输出就行了。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
| #include <bits/stdc++.h>
using namespace std;
#define MAXSIZE 100000
struct myHeap {
int value[MAXSIZE];
int length;
};
void push(myHeap &heap, int v) {
heap.value[heap.length++] = v;
int now = heap.length;
while(heap.value[now - 1] < heap.value[now / 2 - 1] && now != 1) {
swap(heap.value[now - 1], heap.value[now / 2 - 1]);
now /= 2;
}
return;
}
void pop(myHeap &heap) {
heap.value[0] = heap.value[--heap.length];
int now = 1;
while(2 * now <= heap.length) {
int temp = 2 * now - 1;
if(temp + 2 <= heap.length && heap.value[temp] > heap.value[temp + 1]) temp++;
if(heap.value[now - 1] > heap.value[temp]) swap(heap.value[now - 1], heap.value[temp]);
else break;
now = temp + 1;
}
return;
}
inline int get(myHeap heap) {
return heap.value[0];
}
int getPop(myHeap &heap) {
int temp = get(heap);
pop(heap);
return temp;
}
int main() {
int n;
cin>>n;
int temp;
myHeap test;
test.length = 0;
for(int i = 0;i < n;i++) {
cin>>temp;
push(test, temp);
}
int power = 0;
while(test.length != 1) {
int quick[2] = {getPop(test), getPop(test)};
power += quick[0] + quick[1];
push(test, quick[0] + quick[1]);
}
cout<<power<<endl;
return 0;
}
|
其中get函数用于返回堆顶元素,不要也可以,毕竟很简单。
对于这一题是可以AC的,没有问题。
堆排序
既然小根堆的堆顶元素永远最小,那么只要每次都取出堆顶元素直到堆为空不就可以排序了吗?没错,这就是堆排序,时间复杂度为O(nlogn),十分优秀。
代码我就不讲了,自己看吧:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
int main() {
int n;
cin>>n;
int temp;
myHeap test;
test.length = 0;
for(int i = 0;i < n;i++) {
cin>>temp;
push(test, temp);
}
for(int i = 0; i < n; i++) cout<<getPop(test)<<" ";
cout<<endl;
return 0;
}
|
数据量大的时候可以考虑堆排序,因为堆排序的耗时主要在建堆上,建好堆后的调整实际上非常快。
题外话
终于写完了…写了我整整三小时啊!
明天大概也许会有一篇关于图的,以及一篇关于类的。
886!
]]>
+
+
+
+
+ 编程
+
+
+
+
+
+
+ 计算机
+
+ 编程
+
+ c++
+
+
+
+
+
+
+
+
+ 在线写作与博文分享—— NetlifyCMS 与 ShareThis
+
+ /posts/8e1b39a3/
+
+ 没错,任何正常人都不会把标题里这两样东西联系起来,包括我。 NetlifyCMS
最开始看到这玩意是在fluid的官方博客的这一篇博文Hexo Netlify CMS 在线编辑博客(转载的,原文地址在这里),当时就觉得非常不错,但可惜未能按照教程配置成功,只得转投于更贴合于Hexo的HexoPlusPlusHexo艹
直到前几天上个月看到Xingyang在一键推流工具——BlogPusher这一篇文章下的评论:
如果静态博客是部署在 Github 上的话可以试试用 Netlify CMS。相当于架设一个能进行 Git Commit 的 Web app,最重要的就是 0 花费,Private Repo 也可以用。我自己的博客也在用(虽然文章数不是很多())
参考文章:https://cnly.github.io/2018/04/14/just-3-steps-adding-netlify-cms-to-existing-github-pages-site-within-10-minutes.html
很好,但是不太符合我的情况。于是随即翻了翻——
瞳 孔 地 震.jpg
完全可用!撒花!
如果你也没有成功配置Netlify CMS的话也可以试试,教程十分甚至九分简单,个人感觉几乎不存在出错的可能性。
感谢Xingyang!顺便他的博文链接:简单搭建一个 GitHub Repo 静态博客的 CMS 后台内容管理系统
ShareThis
最开始捣鼓了一阵子分享系统,share.js啊,Social Share Button啊等等都尝试过一遍,但我都不太满意,况且分享也不是刚需,于是就此作罢。
直到昨天,我妈问我:“你这个博客怎么分享给别人看啊?”
我突然感觉分享还是有必要的,遂继续开始寻觅,然后就发现了ShareThis
注册
非常简单,进入首页:https://sharethis.com
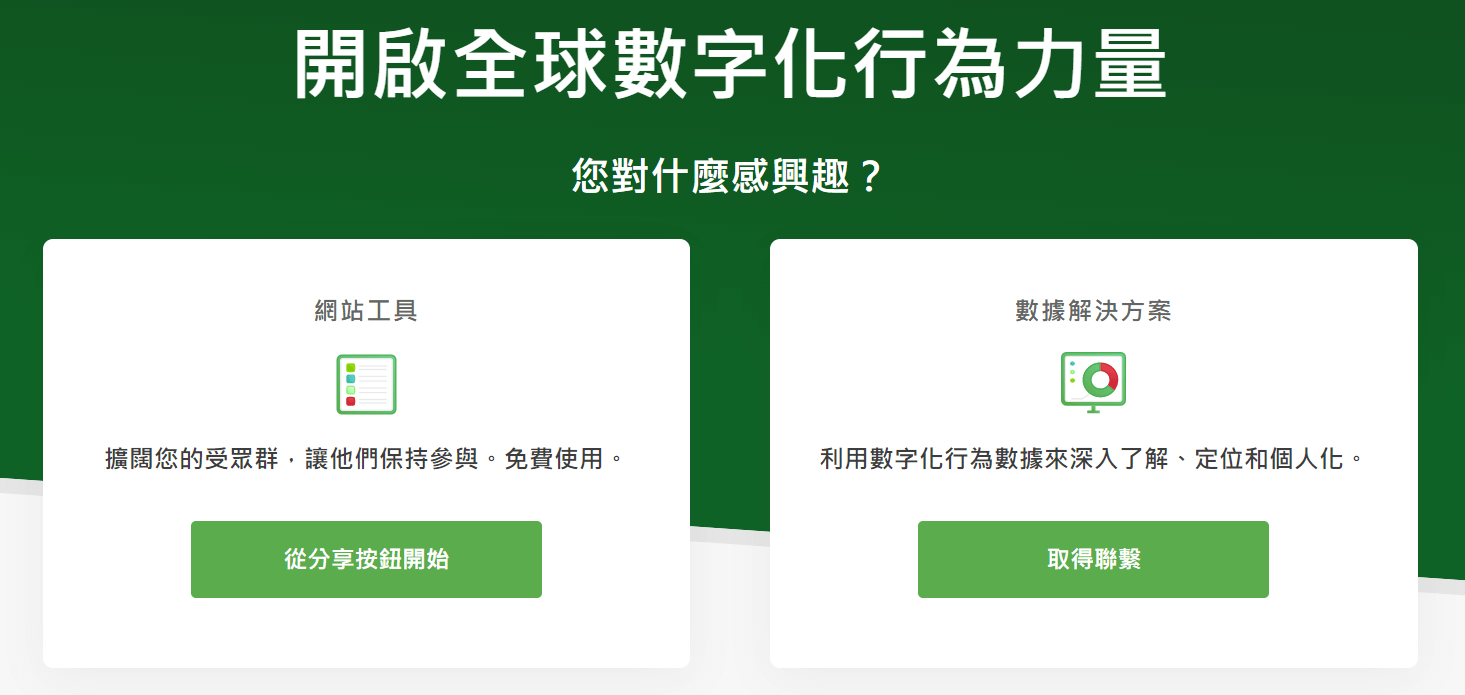
点击“从分享按钮开始”,然后点击第一个选项:
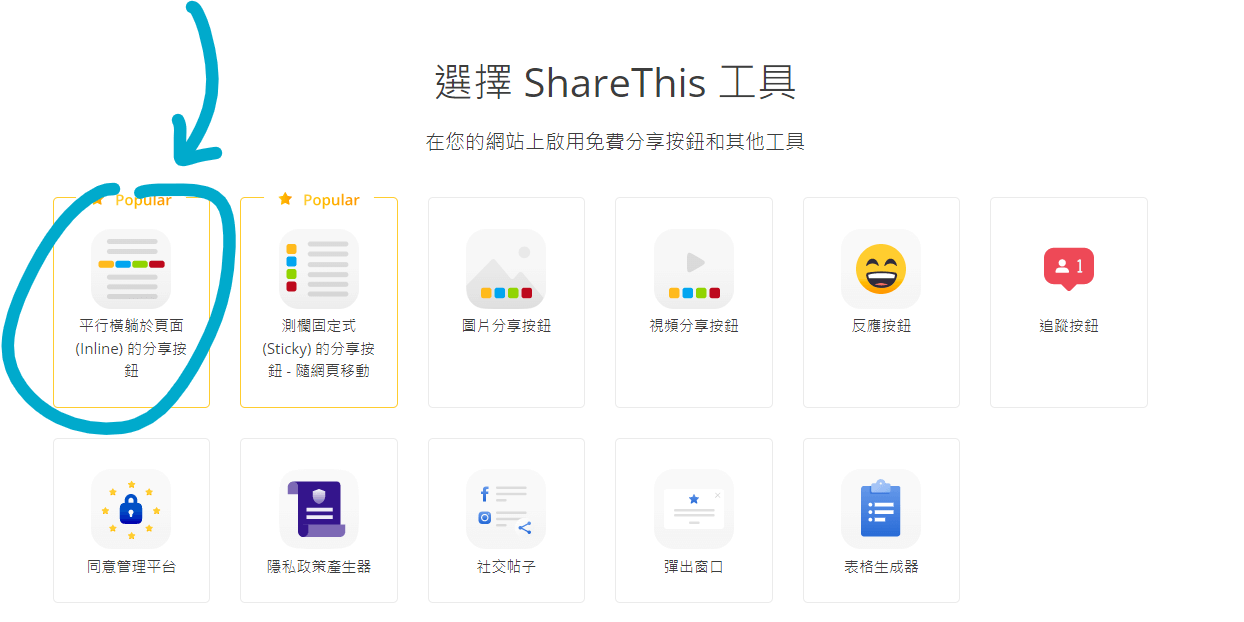
不要急着点击下一步,先用滚轮滚动到页面下方,点击“Customize your Inline Share Buttons”按钮。
在弹出的选项中对按钮进行配置,可以配置包括颜色、媒体、形状等等内容。
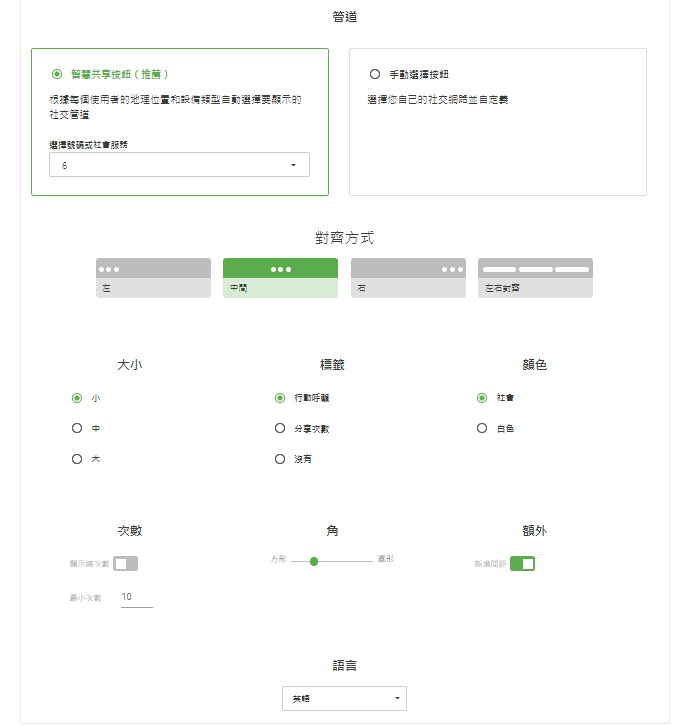
最下方的语言记得调整为中文,然后点击下一步,在新页面中注册登录即可。
随后,你会得到两串代码,分别是js安装代码与按钮引入代码。安装代码放在head中,按钮放在你想插入的地方就好。
大概如下:
1
2
|
<script type='text/javascript' src='https://platform-api.sharethis.com/js/sharethis.js#property=不告诉你&product=inline-share-buttons' async='async'></script>
|
1
2
|
<div class="sharethis-inline-share-buttons"></div>
|
效果
滑到这篇文章底下看吧。
题外话
这篇博文算是对近期我对博客的大改动,但是单独发太短,所以就这么整合在一起了。
那就这样,这篇博文就到这里,886!
]]>
+
+
+
+
+ 教程
+
+
+
+
+
+
+ 计算机
+
+ 教程
+
+ Hexo
+
+
+
+
+
+
+
+
+ 满十四,进十五。愿我青春无悔,不负韶华
+
+ /posts/e84bad58/
+
+ 又大了一岁呢…令青春无悔,愿韶华不负!
希望明年的此刻,我能够无愧于自己。
]]>
+
+
+
+
+ 日常
+
+ 短文
+
+
+
+
+
+
+ 生日
+
+ 短文
+
+
+
+
+
+
+
+
+ 生日当天全款提下第一支(打八折)钟薛糕
+
+ /posts/7e920bb4/
+
+ 送给自己的生日礼物我是大怨种
]]>
+
+
+
+
+ 日常
+
+ 短文
+
+
+
+
+
+
+ 生日
+
+ 短文
+
+
+
+
+
+
+
+
+ Phigros 版本迁移——从 Google Play 到 Tap Tap
+
+ /posts/e8587b82/
+
+ 起因Google Play的版本更新总是慢一些,不知道你行不行,但是我是忍不了别人都玩上了新曲而我却还不能玩的感觉,遂决定迁移存档。
过程
大体参考这一篇文章Phigros存档跨版本转移教程(免root)即可,在这里稍微提一下我遇到的问题
解决问题
在使用abe.jar时,Java报错:
1
| Error: A JNI error has occurred, please check your installation and try again
|
首先在网上查询,找到的第一个方法是删除电脑里共存的JDK,只留下一个,使java -version与javac -version有相同的版本。
我照做,删除了java8,只留下了openjdk17,但是毫无卵用。
于是我继续查询,发现在跨!系!统!转!移!支持安卓和IOS的跨系统存档转移工具!Phigros 存档 IOS 跨系统 备份 还原 转移 同步这一视频中所提供的工具里的abe.jar可用。
总结
如果你也遇到了一样的问题,可以参考我的方法看看是否有效。
若不想下载整个备份工具而只想要abe.jar的话,可以从这里下载:链接(如有侵权,请联系我删除)
]]>
+
+
+
+
+ 教程
+
+ Phigros
+
+
+
+
+
+
+ 计算机
+
+ 编程
+
+ 教程
+
+ adb
+
+ 手机
+
+ phigros
+
+
+
+
+
+
+
+
+ 【多图预警】 AwtrixPro 开源项目的复现
+
+ /posts/774674fe/
+
+ 本人对AwtrixPro垂涎已久,但却懒得复现。暑假的物理作业包含一个对电学有关的实验,遂趁此机会复现一个出来。 材料采购
并不难,跟着官网的这个网页一步步在淘宝上找就可以了。就是记得买焊接工具以及足够量的耗材(指Gpio线材、热熔胶、电工胶带等等)以及外壳(可以用官网上的文件3D打印,淘宝上也有直接卖的)。
这里贴出我购买材料的链接,有兴趣的话可以试一试(加粗的为非必需品,没有注明数量默认1个,没有注明平台默认淘宝或天猫):
硬件制作
PCB+针脚焊接
本人未成功通过此方法复现,下列内容不一定完全正确,仅供参考
参考B站UP主三三三三三文啊的视频【AWTRIX PRO】一起动手做一个高颜值的像素灯,在嘉立创打好板子(注意有贴片,需要开钢网),买好GPIO接口公母头再焊接即可。打板流程可以参考【0基础】从零开始电子DIY!第三集:PCB电路板设计和打样!,这一套教程非常不错,推荐。
打好的板子如下:

焊接好之后(贴片是用的钢网+锡焊膏+风枪):

焊接针脚时若是无法直接使用锡丝与电烙铁焊接完成,也可以用锡焊膏+电烙铁。把锡焊膏涂抹在针脚背面,不用担心粘连,然后用电烙铁分别探入每两个针脚间的空隙,随后依次处理每个针脚就可以了。
然后刷程序、接线、通电、启动即可(至少理论上是这样):

很明显,这里并未启动成功,望高手赐教。
手动飞线
根据官网的接线图进行手动飞线即可,这里因为缺少一个电容(C1, 100nF)且不知道哪里有卖的而未接上DFPlayer模块及喇叭。
这里除了基础配件外,额外加装了光敏电阻、触摸以及Htui21d温湿度模块。基础部分依据教你做一个可编程像素屏制作成功,然后通过自主飞线完成了其它组件的安装。

没有什么难点,注意需要连接多根导线时用钳子分别剪开线的外皮,露出里面的铜/铁/其他金属丝,拧在一起然后用电烙铁与锡焊在一起就可以了。
裸露的金属丝记得用电工胶带或者热熔胶包裹起来,防止意外:


然后装入外壳即可:


再放上格栅、均光片及亚克力面板就完成了:



软件配置
软件这里就不再多提,官网上就有(点击这里访问)。就是说一下我这里是部署在我自己的服务器上,就无需本地服务器如树莓派一类了。
宝塔面板就可以轻松完成配置,也无需ssh连接。
然后安装自己喜欢的软件即可,我这里是这几个:
成品






题外话
从暑假开始一直做到了倒数第二天…心累,不过总算是完成了,也让我发现了我的电工天赋(bushi
那就这样,这篇报告(?)就完成了,感谢你的观看,886
]]>
+
+
+
+
+ 编程
+
+ 硬件
+
+
+
+
+
+
+ 计算机
+
+ 编程
+
+ github
+
+ 开源软件
+
+ awtrix
+
+ 硬件
+
+ 复现
+
+
+
+
+
+
+
+
+ 解决一件困扰我很久的小事
+
+ /posts/8ad10849/
+
+ 起因偶然间看到了这个视频——[Phigros/技术革新] 快速获取自己的B19成绩图,眼馋,也想要,遂跟着做,结果却…
大☆失☆败
手机自始至终没有弹出“完全备份”界面,我百思不得其解,于是在stackoverflow上发了一个问题:
Adb backup does not work on my HarmonyOS 2.0 phone
直到今天之前,没有任何人给出有效回答。
解决
把之前在手机里安装的软件“冰箱”卸载之后就正常了,我也不知道为什么。
从这件事就可以看出我是个…欸,我不说,就是玩
自己去把问题给解答了,这件事就此完结。
题外话
生成都生成了,那就晒一下吧:

小菜一枚,大佬轻喷。
那就这样,886
]]>
+
+
+
+
+ 教程
+
+ Phigros
+
+
+
+
+
+
+ 计算机
+
+ 编程
+
+ 教程
+
+ adb
+
+ 手机
+
+ phigros
+
+ 安卓
+
+ 鸿蒙
+
+
+
+
+
+
+
+
+ Hexo 通过 GitHub Action 自动部署到云虚拟主机
+
+ /posts/1e44a102/
+
+ 购买了十年之约的优惠价硅云虚拟主机用于加速访问,记录一下部署过程。 前提条件
你需要已经配置好了GitHub Action的Hexo自动部署,若是没有,推荐观看以下文章:
这里就不讲了。
编辑Action
打开(本地博客仓库目录)/.github/workflows/(Action配置文件).yml,在最后添加:
1
2
3
4
5
6
7
8
9
| - name: Deploy Files on Ftp Server
uses: SamKirkland/FTP-Deploy-Action@4.3.0
with:
server: (FTP服务器地址)
username: (FTP用户名)
password: (FTP密码)
local-dir: ./public/
server-dir: (FTP服务器文件目录)
port: (FTP服务器端口,一般是21)
|
将括号及内部内容换成自己的信息即可。
这里的方法是使用ftp来上传文件到虚拟主机,是对于所有虚拟主机而言最通用的一种方式了。./public是Hexo默认的静态文件生成本地地址,无需更改。
最后推流到GitHub即可使用。
题外话
本来以为挺复杂,结果就这么点。
最开始使用的是hexo-deployer-ftpsync插件,结果却根本无法正常使用,于是便转为使用docker镜像。
对了,如果有兴趣购买硅云的主机,那请帮个小忙,用我的邀请链接注册吧:邀请链接
那就这样,886
]]>
+
+
+
+
+ 教程
+
+
+
+
+
+
+ 计算机
+
+ 编程
+
+ 教程
+
+ Hexo
+
+ 虚拟主机
+
+ 网站
+
+ GitHub
+
+ 自动化
+
+ GitHub Action
+
+
+
+
+
+
+
+
+ 《梁启超传》议论文素材积累
+
+ /posts/2f728g0f/
+
+ 与之前那一篇一样是暑假的语文作业,也是对这本书全本的分节概括以及议论文的素材积累,外加上对应适用的议论文题材。 第一章 一世纪以来中国的命运——从鸦片战争至梁氏诞生的前夕
第一节 绪说
梁启超生在中国近代最悲惨的100年(1842-1943)年中,虽屡次想跳海自尽,但仍坚决地相信中国必然不亡且断然复兴,所以他才在全然无望中挣扎奋斗。
作文:坚持、毅力、精神
第二节 梁氏生前中国一般的惨况
《奴才好》中足以令人怒发冲冠的描写在当时黑暗社会的情境下甚至不被人认为是严重的怪象。
慈禧太后奢靡无度,倾尽全国财力为自己所用,掏空了国库,令全中国上下不得安宁。
清末国家机构的腐败,如“外交部”(总理衙门)工作人员甚至无法分清澳门与澳洲。
清末军队素质极差,上下组织腐败,不能防国,只能累民。
清末经济建设几乎毫无成效,只因“官与民争”就扩大为了导致清朝覆灭的致命伤。
作文:珍惜、强国、学习
第三节 梁氏生前中国一般的教育状况
清末满朝士大夫都有一种目中无人的气势,自觉这清朝乃是天下第一。
清末全国几乎没有半个学校的教育,教导孩子不去烟馆、青楼而在家里抽大烟、挑“丫头”都成为了“教子有方”。
清末文人及有志青年深受八股文之害,令八股文成为活埋青年的天坑。
清末人民对“洋”存在极深的偏见,如官办“洋学堂”都十分遭人唾弃,只能拉到一批不三不四的学生。校内不教德育、爱国,而只是学习西方下等人的恶俗。
作文:环境、强国、学习
第四节 梁氏后来对于祖国命运的影响
作文:坚持、偶像、伟人
第二章 亡国现象与维新初潮——从梁氏诞生至戊戌政变
第五节 综叙
1873年,梁启超出生。此时近代伟人俱全,又冲破了鸦片战争以来中国所带之枷锁,正是突破了低于底层的黑暗,看见天际的一缕祥光。
作文:努力、坚持、时代
第六节 亡国现象的种种——梁氏生后的中国惨况
梁启超出生之后的中国同样是战争不断,且更偏向于内乱。
此时国际形势大好,西方列强都成为了天之骄子,合力来对付中国一国,令中国无辜受到车裂及凌迟之刑。
日本对中国早有图谋,在其只是一个弹丸之地的效果时就已经企图占据朝鲜与中国,且当时日本名士几乎都有着不一的“吞华论”。
作文:毅力、黑暗、光明、社会、时代
第七节 梁氏幼年的家庭生活及家乡环境
作文:爱国、强国、富国、伟人、偶像
第八节 康梁会接
作文:智慧、计划、学习
第九节 梁氏独立事业的开始
梁启超脱胎于长兴学社创立新学。在这样一种不拘形式而朝气蓬勃的学风之下,造就出了许多具有新思想人才,当时一般的学生只有四十人,而五分之二都成为了革命先烈或开国名人。
梁启超创学会启发心智,推行维新,学会中政治性质强大。在戊戌八月政变失败之后,所有的学会都秘密含有了革命的使命,与前期的学会性质有根本上的不同。
梁启超为推行维新而创办报纸。此时,他已明白,学校、学会、报纸是三位一体互相为用的,缺一不可。所以,在北京办学会的时候,他就已经开始办报。这是梁启超生平新闻事业开始的第一章,也是近代中国有正式意义的新闻开始的第一页。
作文:智慧、方法、强国
第三章 维新的失败与革命的成功
第十节 促成戊戌变法的原因
外因-远因:清政府的闭关锁国政策、杀沙俄实力的突飞猛进、列强对中国的围攻、洋务运动的失败。
外因-近因:日本民治维新的胜利、甲午战争失败的国耻、中国被蚕食的痛苦、防止陷入土耳其不变法而衰弱的覆辙。
内因-远因:清政府长期积累政治恶习的崩溃、满族战斗能力与战斗意识的降低、太平天国运动后实际政权的转移、以慈禧太后为核心的宫廷政变。
内因-近因:慈禧太后与皇帝权力的争夺、满族嫉妒汉族情感的具象化、孙中山先生领导的革命运动的激进,国内舆论更加倾向于维新。
由于以上这十六点各种各样的原因,到戊戌年间维新运动已成瓜熟蒂落的现象,除了冥顽无耻,卖身求荣的少数败类以外,几乎所有人都是渴望政治改革有如甘霖一般。
作文:强国、因果、历史
第十一节 戊戌政变史剧的绘影
戊戌变法的规模既不如日本明治维新,就连康有为公车上书的内容也还有千里之差。但就算只是这样,对于当时的清政府而言,也已经算是大刀阔斧了,此时正是光绪帝把皇威发扬到顶点的时候。
光绪帝想趁着改革的机会罢免几个守旧的大臣,但这些顽固的大臣转而向“老佛爷”求助,于是慈禧太后勃然大怒,将光绪帝囚禁而自己垂帘听政,在实际上掌握了清政府的权力。
康有为、梁启超等“小人”“大逆”受“可恶透顶”的“洋鬼子”的保护,躲开了慈禧太后的清算。其中,谭嗣同本来由日本严密保护,但却自己重新自动出来,愿抛头颅以改造祖国百年的命运。如此的忠与侠实属罕见,也值得我们敬佩。
作文:强国、历史、光明、黑暗、方法
第十二节 政变失败原因的解析
清政府内部早已腐朽不堪,全国大权都在慈禧太后之手,而满人的猜疑程度又大到难以想象,更是有许多守旧的大臣。变法本就是一个不可能完成的任务。
康有为虽然魄力强大、精神勇猛、感情丰富、毅力坚韧,但他同样心胸不广、态度傲慢、个性执拗、理智不强、做事无序、缺乏科学训练、不求上进、所学太杂而不适用其时代,却反而骄然不惭,自谓贯通天地人。
满人生来仇视汉人,排挤汉人,甚至在百维新期间出现了满洲人所谓闹鬼的趣事。在这样的排挤、压迫、攻击之下,维新救国、变法图强本就是一个荒唐的幻想。
一些守旧分子自满于既得利益而不愿其被损伤分毫,故而极力阻挠变法。
作文:方法、强国、历史、革命、国庆
]]>
+
+
+
+
+ 文学
+
+
+
+
+
+
+ 文学
+
+ 作文
+
+ 读后感
+
+ 议论文
+
+ 素材
+
+
+
+
+
+
+
+
+ 免费高速文件分享小技巧
+
+ /posts/618137f7/
+
+ 首先提示一下,这会是一篇非常非常短的博文。 介绍
还在为百度网盘那该死的限速而发愁吗?如果你在网络上分享文件,肯定不想因为下载者因为百度网盘的限速而对你破口大骂(不是 对吧。这里推荐一个老牌云盘——蓝奏云,官网在这里。
不限速,无限空间(单文件限100M),个人还是感觉非常不错,大文件要传上去也可以分卷压缩。
小技巧
网络上无法访问的蓝奏云文件分享可以试着把二级域名改为lanzoui试试哦。
题外话
没啦,就这么短。
886
]]>
+
+
+
+
+ 教程
+
+
+
+
+
+
+ 计算机
+
+ 编程
+
+ 教程
+
+ 白嫖
+
+ 福利
+
+
+
+
+
+
+
+
+ 无需流量费用!阿里云 oss 图床配合阿里云轻量应用服务器部署
+
+ /posts/d9bb8734/
+
+ 我已经有了一台阿里云的香港轻量应用服务器,正好阿里云oss内网下行流量免费,再加上oss上行流量同样免费,于是就可以在省掉所有的流量费用的同时获得一个拥有不错速度的私人图床。 创建
打开阿里云oss页面,点击bucket列表,选择创建bucket:
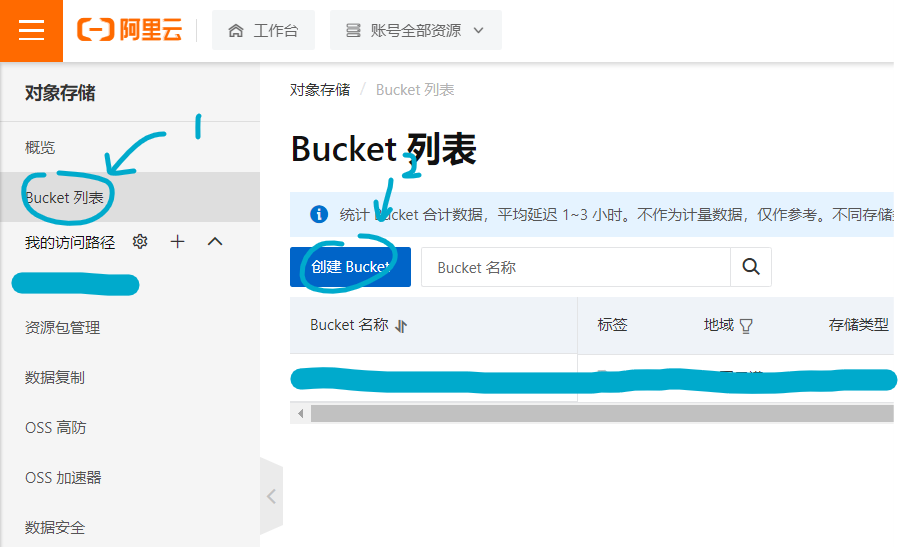
名称随意,但是地域要选择于自己的服务器相同的地区,这样才可以通过内网访问。存储类型选择标准存储,读写权限选择公共读,其余一律默认。
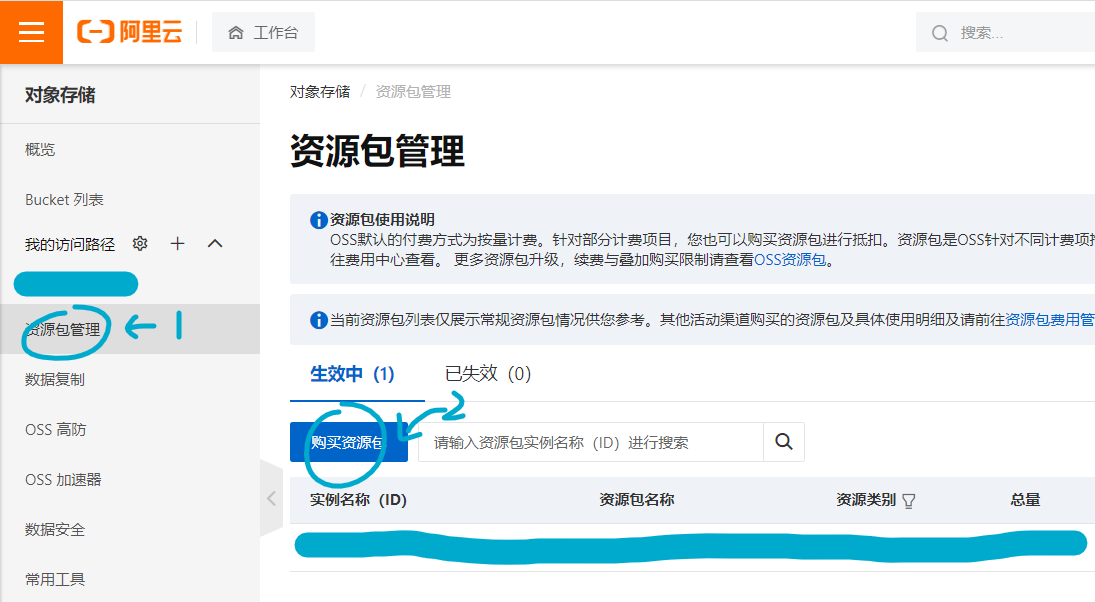
oss桶默认是按量计费,标准可以参考官方文档。你也可以像我一样购买资源包,点击资源包管理,再在新页面中点击购买资源包:
然后在资源包类型一栏中选择标准(LRS)存储包,其余按需选择即可:
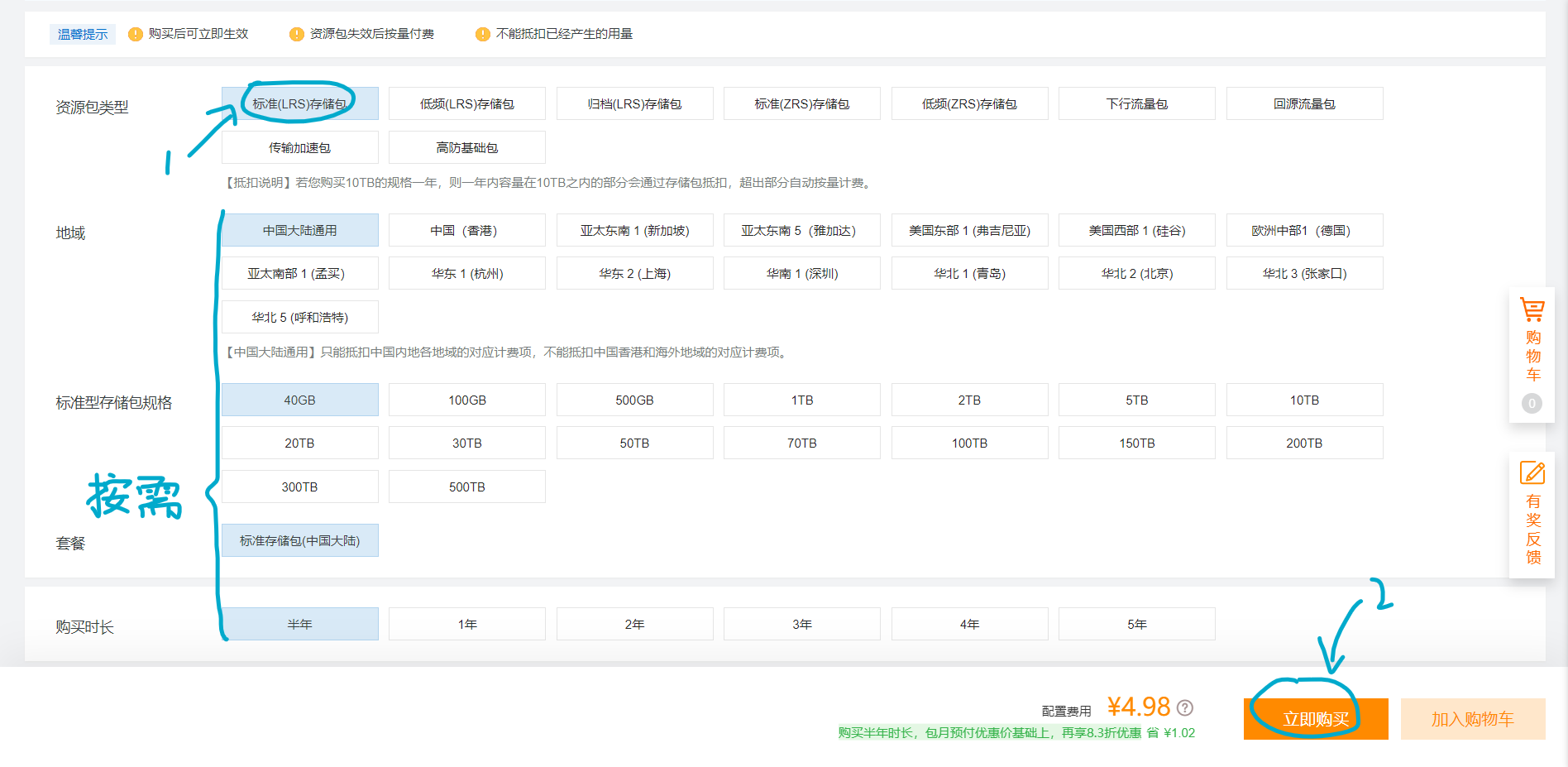
一年仅需9元,个人认为十分划算。
此时存储桶便已创建完成。
服务器反向代理
内网下行流量免费,所以我们要先访问内网,通过服务器反向代理就可以做到这一点。这里通过宝塔面板进行配置。
点击侧栏的网站,然后点击新建站点:
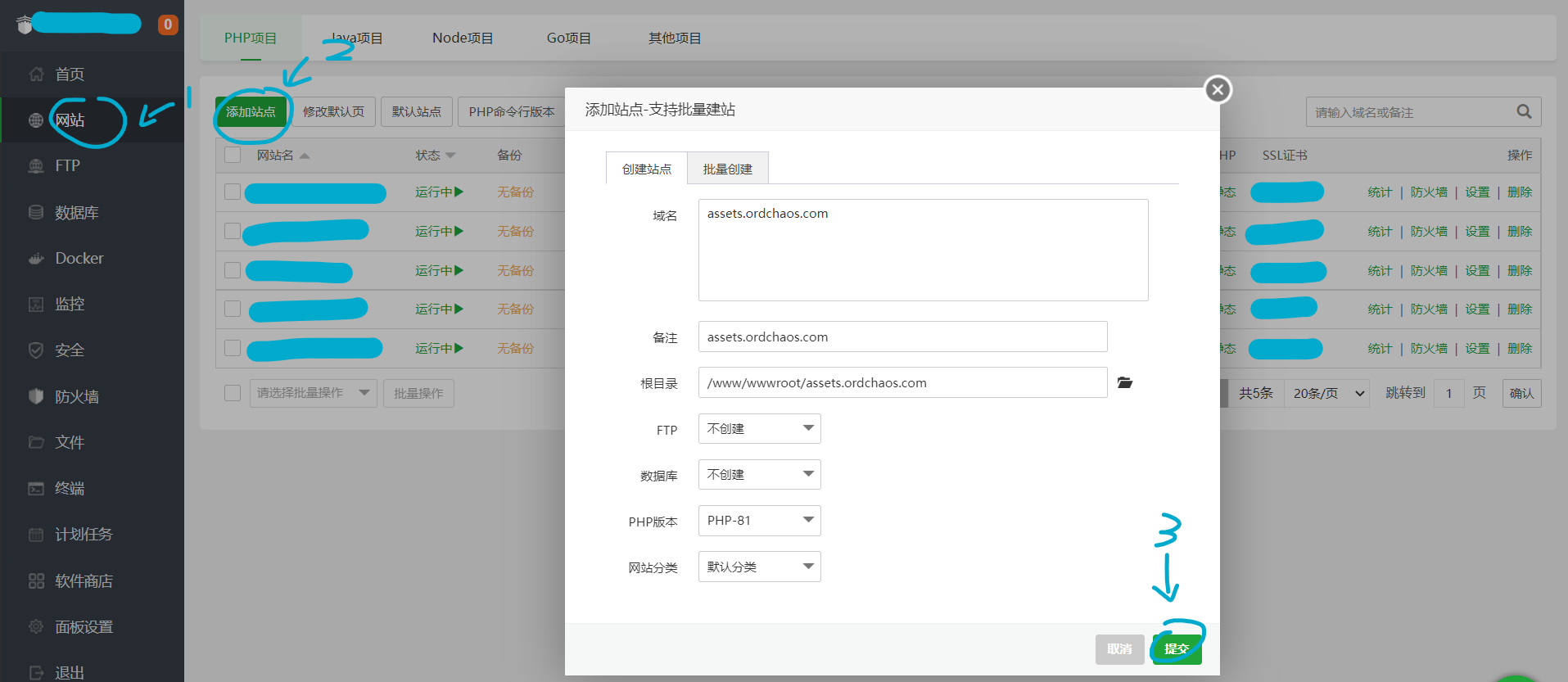
域名填写最终用来访问图片的域名,如这里的 assets.ordchaos.com。其余默认即可,然后选择提交。
之后点击对应网站的设置——反向代理——添加反向代理。名称随意填写,目标URL填写内容如图所示:
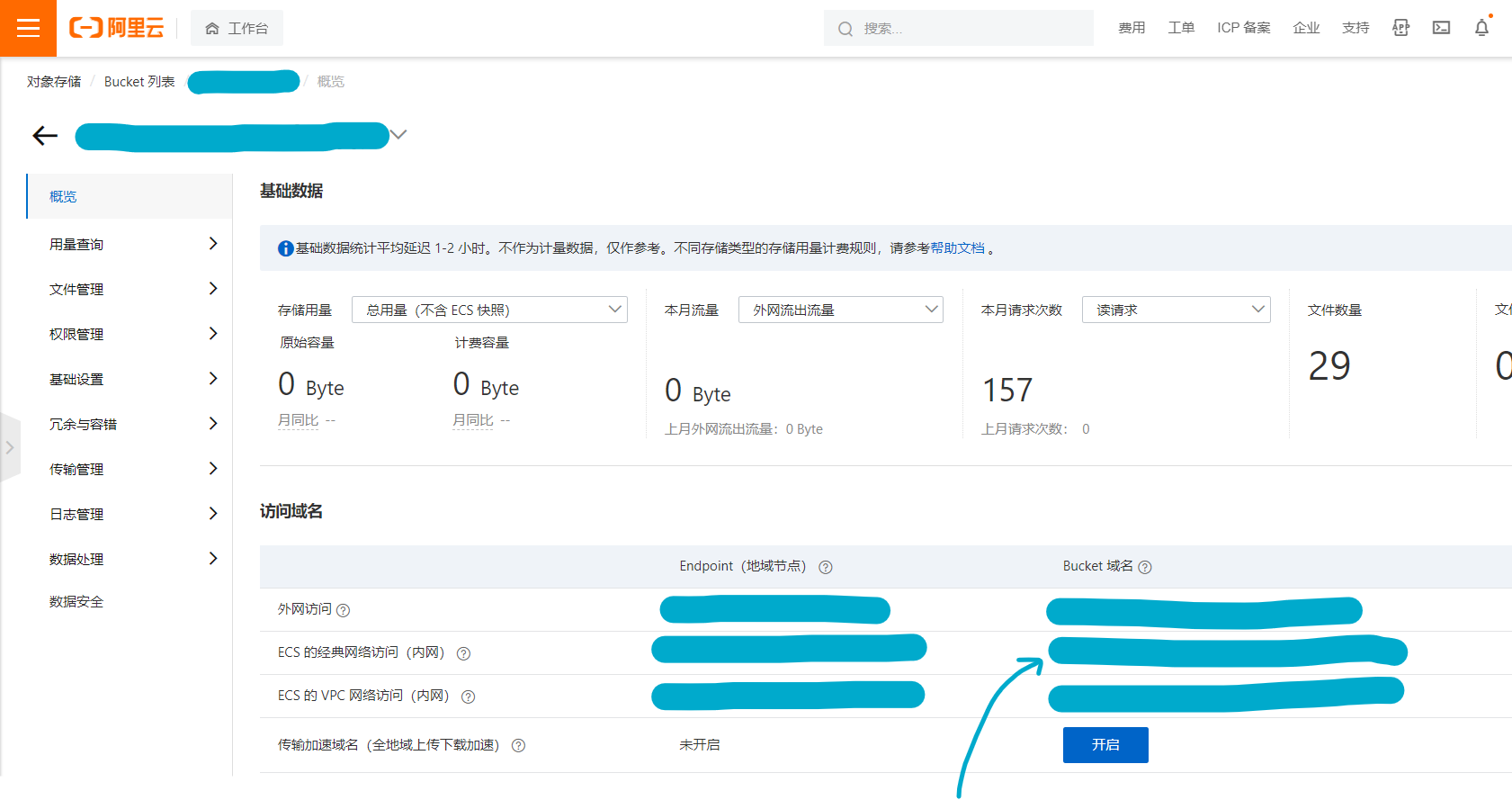
填写对应的内网Bucket域名。
然后点击提交即可。也可以配置缓存,在添加反向代理时点击开启缓存并配置时间就可以了。记得在域名供应商那里添加对应的域名解析到服务器上。
之后可以配置SSL证书,在SSL页面自行配置即可。现在你的桶已经可以通过反向代理来访问了,下面我们来做一些额外的工作。
PicGo配置
PicGo作为一个图片上传工具是非常不错的,拓展性很高。同时作为一款开源软件,其发布在了GitHub上。这里默认已经安装完成了PicGo。
安装S3桶插件
打开PicGo,点击“插件设置”,在搜索框中搜索“s3”,安装第一个就可以了:
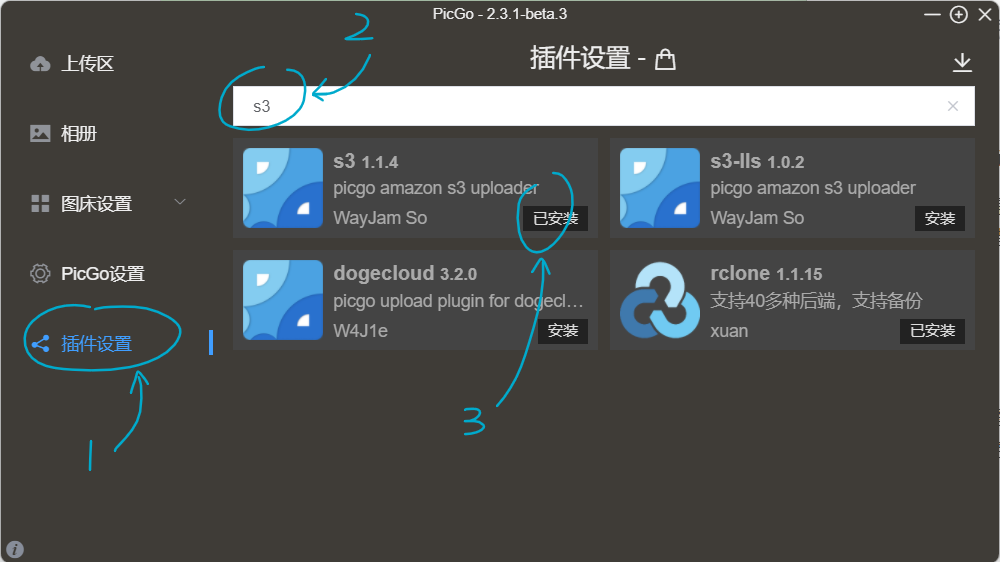
我这里安装过了,所以就显示的是“已安装”。这个插件支持所有s3桶,包括阿里云oss。其实可以直接配置阿里云oss,但是使用s3插件可以自动按规则重命名文件。
获取配置信息
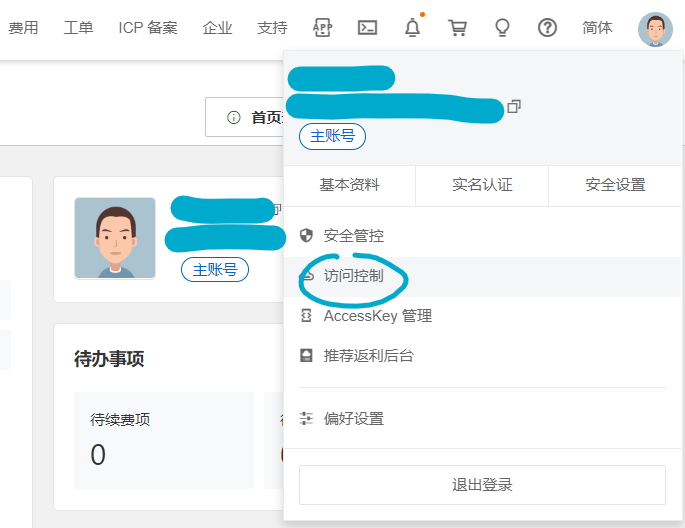
把鼠标移到右上角头像上悬浮,在出现的界面上点击访问控制:
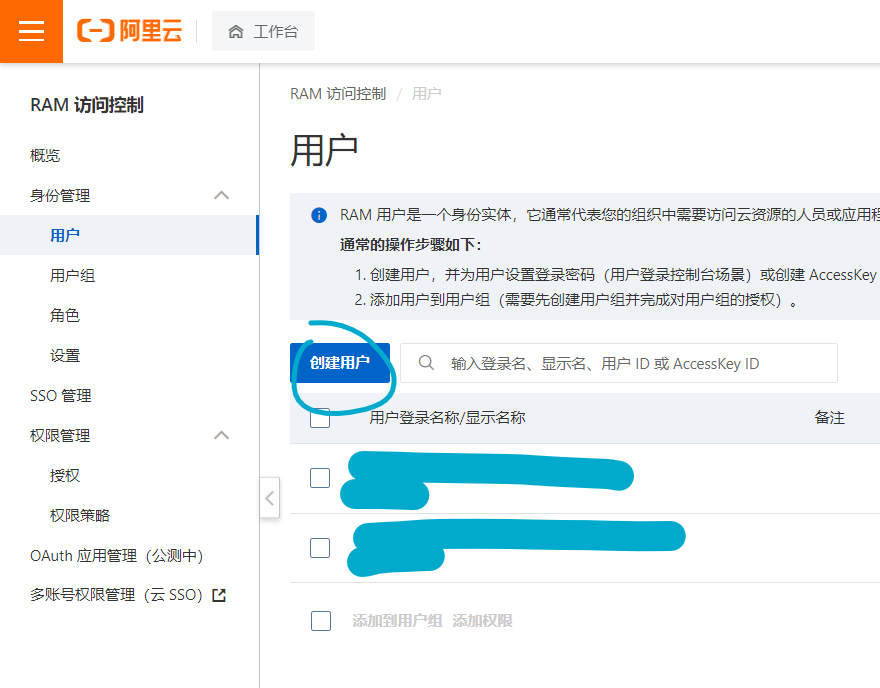
然后点击侧栏的用户,再点击创建用户:
登陆名称与显示名称随意,然后勾选下方的“Open API 调用访问”:
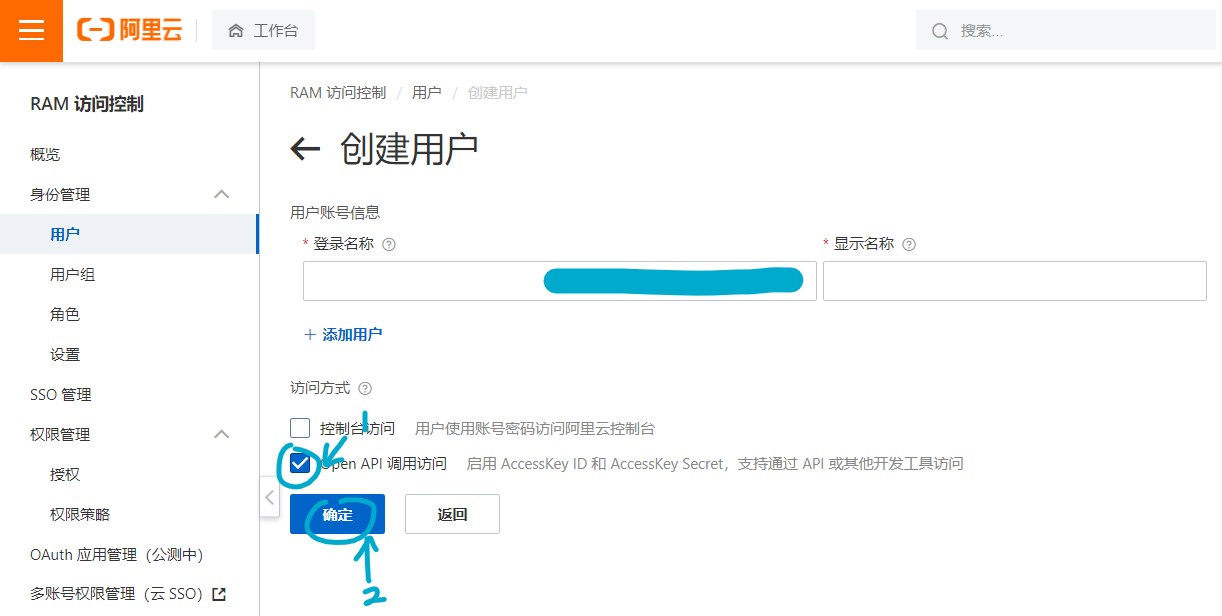
点击确定,验证身份,然后就会出现AccessKey ID 与 Secret,记得保存下来:

然后返回到用户管理页面,点击刚刚创建的RAM账号旁边的添加权限,然后添加控制oss桶的权限即可:
配置PicGo图床
点击图床设置-AmazonS3,填写对应参数即可,大致如下:
- 应用密钥ID:上述获取到的AccessKey ID
- 应用密钥:上述获取到的AccessKey Secret
- 桶:你创建的oss桶的名字
- 权限:public-read(桶权限,公共读)
- 地区:在对应桶的概览页面可以看到桶的外网访问Endpoint,假设是 oss-xxx.aliyuncs.com,则地区为oss-xxx
- 自定义节点:上述的Endpoint
- 文件路径:{year}/{month}/{md5}.{extName}(默认上传到桶的文件路径,格式如下:)
| 格式 | 描述 |
|---|
{year} | 当前日期 - 年 |
{month} | 当前日期 - 月 |
{day} | 当前日期 - 日 |
{fullName} | 完整文件名(含扩展名) |
{fileName} | 文件名(不含扩展名) |
{extName} | 扩展名(不含.) |
{md5} | 图片 MD5 计算值 |
{sha1} | 图片 SHA1 计算值 |
{sha256} | 图片 SHA256 计算值 |
然后点击确定并设为默认图床即可。
大功告成!之后只需要在“上传区”页面就可以一键上传图片并复制链接了。
题外话
目前全站图片都已更换为阿里云oss存储,不得不说速度是真的快。
还有这大概是我目前图最多的一篇博文了吧。
]]>
+
+
+
+
+ 教程
+
+
+
+
+
+
+ 计算机
+
+ 编程
+
+ 教程
+
+ 白嫖
+
+ 福利
+
+ s3桶
+
+
+
+
+
+
+
+
+ 空气成分手抄报
+
+ /posts/e8ce405d/
+
+ 化学的暑假作业,浅浅地用sai2摸了一个图出来,大家看看就好。
]]>
+
+
+
+
+ 美术
+
+ 化学
+
+
+
+
+
+
+ sai
+
+ 手绘
+
+ 画画
+
+ 化学
+
+
+
+
+
+
+
+
+ 【不建议】免费 s3 桶——棱束链联盟
+
+ /posts/46d2370f/
+
+ 小品牌,无法保证SLA,故不再推荐。本站图片现已全部转移到阿里云oss。我是在B站看到棱束链的宣传视频的,点进官网就看见了棱束链联盟的广告。想着免费嘛,就申请了一下。效率还不错,第二天就通过了。现在博客的图片就放在上面,感觉速度不错,至少比之前的blackbaze+cloudflare要快。
申请
很简单,首先进入官网棱束链,在顶栏上点击产品,选择棱束链联盟。

然后就抵达了申请页面:

填写表单,按要求在网站底部加入棱束链提供的Logo,比如我的:(可以自己在网站底部看看)

提交表单,等着就可以了。
如果申请了就记得看一看自己提供的邮箱,通过了就会发邮件通知你。我的话第二天早上就发现通过了,处理速度还是不错的。给到了我10G的空间与20G的流量,诚意很足。
之后进入控制台,点击对象存储,再创建存储桶就可以使用了。
PicGo配置
PicGo作为一个图片上传工具是非常不错的,拓展性很高。同时作为一款开源软件,其发布在了GitHub上。这里默认已经安装完成了PicGo。
安装S3桶插件
打开PicGo,点击“插件设置”,在搜索框中搜索“s3”,安装第一个就可以了:
我这里安装过了,所以就显示的是“已安装”。这个插件支持所有s3桶,比如之前的b2以及这个棱束链。
获取配置信息
secretID与secretKey
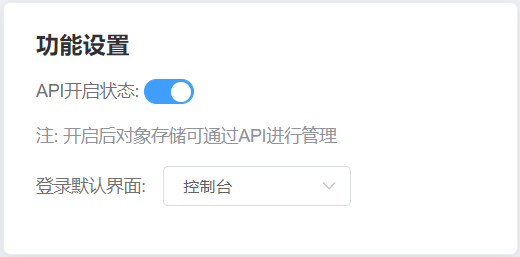
进入棱束链的控制台,点击个人中心,在“功能设置”中开启API并记下secretID与secretKey,若是忘了就只能重新获取。
桶地域信息
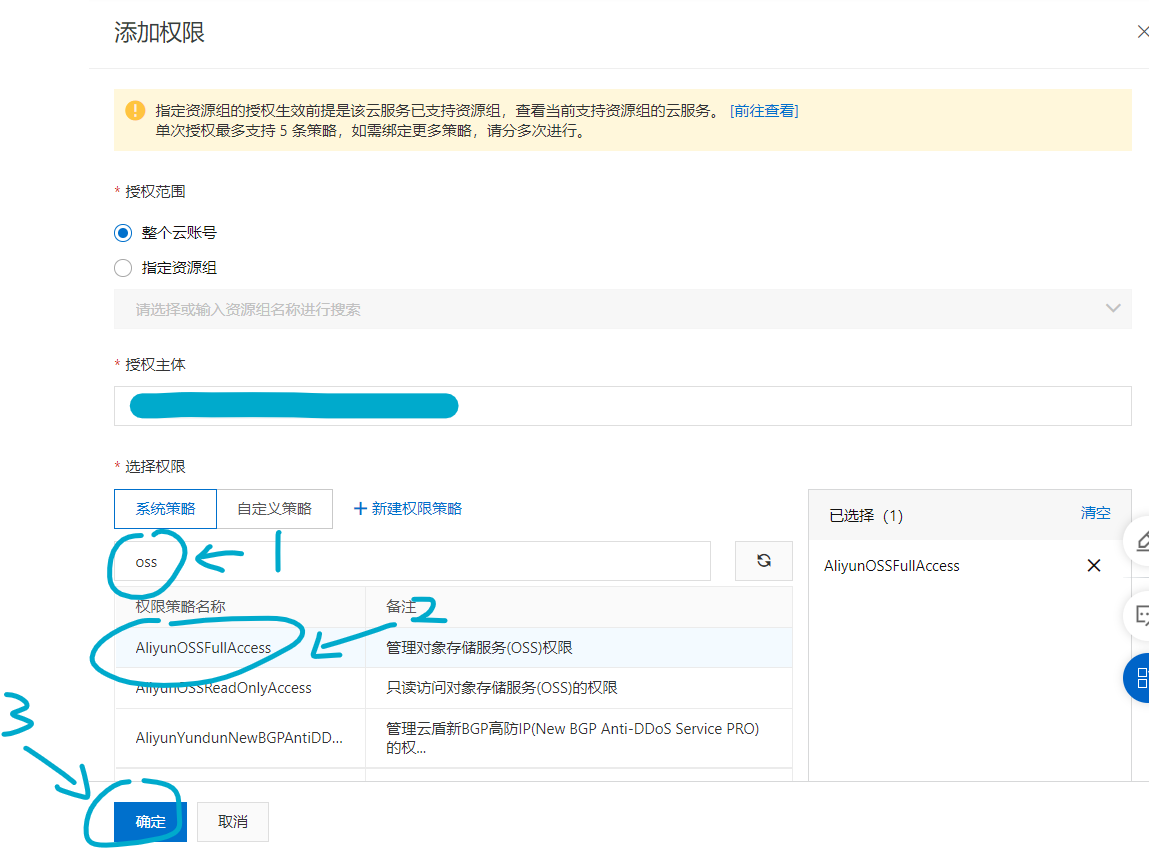
前往存储桶列表,点击桶右侧的“配置”按钮,记下“桶信息”卡片中的地域与端点信息即可。
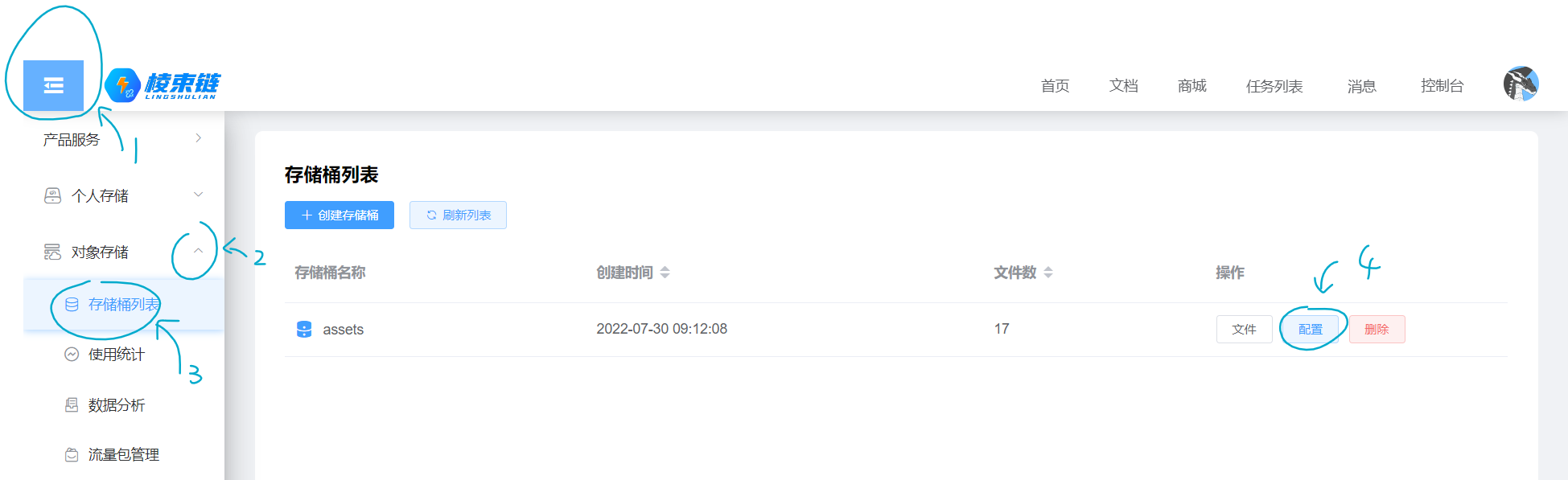
注意,这里的桶一定要是公开桶!
配置PicGo图床
点击图床设置-AmazonS3,填写对应参数即可,大致如下:
- 应用密钥ID:上述获取到的secretId
- 应用密钥:上述获取到的 secretKey
- 桶:上述存储桶的名字
- 权限:public-read(桶权限,公共读)
- 地区:上述获取到的地域
- 自定义节点:上述获取到的端点
- 文件路径:{year}/{month}/{md5}.{extName}(默认上传到桶的文件路径,格式如下:)
| 格式 | 描述 |
|---|
{year} | 当前日期 - 年 |
{month} | 当前日期 - 月 |
{day} | 当前日期 - 日 |
{fullName} | 完整文件名(含扩展名) |
{fileName} | 文件名(不含扩展名) |
{extName} | 扩展名(不含.) |
{md5} | 图片 MD5 计算值 |
{sha1} | 图片 SHA1 计算值 |
{sha256} | 图片 SHA256 计算值 |
然后点击“设为默认图床”并确定即可,之后只需要在“上传区”页面就可以一键上传图片并复制链接了。
题外话
文章部分参考官方文档。
这篇博文不是广告,只是想大家都可以薅一把羊毛并水一篇博文(逃
那就这样,886。
]]>
+
+
+
+
+ 教程
+
+
+
+
+
+
+ 计算机
+
+ 编程
+
+ 教程
+
+ 白嫖
+
+ 福利
+
+ s3桶
+
+
+
+
+
+
+
+
+ 《梁启超传》读后感
+
+ /posts/1e617f9e/
+
+ 在这个暑假中,我读了由梁启超学生吴其昌著作的《梁启超传》,这本书也是作者的绝笔之作。在其去世前的一个月,作者便应邀开始写这一本书,但在他完成书的上卷后便不幸身亡,年仅四十岁,同时留下了这本未完稿的《梁启超传》。这本传记虽然仅有五万字,但是阅读者可以很明显的发现作者吴其昌很完美的继承了其老师梁启超“笔锋常带感情”的特质。作者与梁启超一样,感性的思维较强,喜欢用感性的一面来描述事物,感知事物。梁启超生于一八七三年二月二十三日,字卓如,号任公。清朝光绪年间举人,是中国近代思想家、政治家、教育家、史学家、文学家,也是戊戌变法(百日维新)领袖之一、中国近代维新派、新法家代表人物。
而梁启超生活的时代,正是中国人明最困苦的一段时期。那既是清朝末年,也是我国封建社会的末世。内忧外患,乱象毕现,用作者的话来说,就是“堕入地狱的底层”。然而最可悲的还不在此,而在于当时道德的堕落、思想的颠倒和民智的固陋,堕入地狱的底层而不自知,“哀莫大于心死”!中国从一八四二年到一九四三年这一百年的命运,是“从乐土跌到地狱,又从地狱爬会乐土”是“一个四千年历史上从未有的大转折期”。生活在这个时代的稍有血性的国民看着一个又一个的不平等条约的建立与实施都想“蹈东海而自杀”,比如陈天华。而梁启超,是一个成长在这个最黑暗的地狱底层的有血有泪有志气的满身创伤的青年。他对于中国复兴有着坚定不移的信心,所以他没有去蹈东海,而是在“全然无望”中拼命奋斗、挣扎。只是他到死都没有见到中国再度统一的一天。他的眼前没有希望,但心中却充满了希望与斗志。他师从康有为,发动戊戌变法,创学会,办报纸,达到了其政治生涯的顶峰。然而,就像梁启超后来所说的那样:“戊戌维新之可贵,在精神耳”,戊戌变法是一次及其不彻底的改革,依靠的是无能的光绪帝,只是雷声大雨点小的实行了一百多天,就被慈禧太后为首的封建顽固势力所扼杀。“我欲望鲁兮,龟山蔽之。手无斧柯,奈龟山何!”但全书就这样戛然而止,原因我们都知道了。可就算如此,读完后却仍然令人愤慨与惋惜。
现在看看梁启超本人与现在的社会,会发现虽然中国早已统一,但是却缺乏了梁启超的奋斗的心。这个社会,比起梁梁启超当年所处的,自然要文明、要繁盛得多,可依然存在着不公与不善。为纠正这些不公,惩治这些不善,依然有可能要付出惨重的代价。在风险面前,很多人却望而却步,勇往直前的人是有的,但是因为现状的安稳,这些人正在慢慢减少。所以梁启超赴汤蹈火救国的精神在任何一个时代都不会落后。
梁启超是清末维新运动的领袖之一,是近代资产阶级改良主义者;也是提倡诗界、小说界革命的新文化传播者。戊戌变法失败后,他逃亡日本,虽曾和孙中山联系商议合作,但因为他的老师师康有为所制止,从而做了保皇党,也就是拥护皇帝的一批人的其中之一。辛亥革命之后,他谋位于军阀之中,将自己的旗帜插在了反动派的阵营之中而反对革命,晚年时尤其犹反对共产党。对于他在政治上的反动观点与反动行为当然是应当制止的,可是他的护国、爱国的精神与为国赴汤蹈火的精神,我们这个时代是需要的,这种精神在这个时代也是缺乏的。
一九二九年一月十九日,梁启超在北京协和医院溘然长逝,享年五十六岁。
附一张(参考意义不大的)思维导图:

]]>
+
+
+
+
+ 文学
+
+
+
+
+
+
+ 文学
+
+ 作文
+
+ 读后感
+
+ 议论文
+
+
+
+
+
+
+
+
+ 第五种排序—— std::sort() 函数
+
+ /posts/97a1a73e/
+
+ 上次讲了四种排序算法(没看过的点这里),但是在实际开发或是竞赛中可能没有足够的时间写出一个够用的排序函数,或是需要排序的并非数字,这时便是我们的大宝贝——std::sort()函数登场的时候了。 用法
需要先引用algorithm库,不过我更倾向于在竞赛时直接使用万能库节省记忆时间。然后,需要使用std命名空间,或是直接调用std::sort()。
sort()函数的原型如下:
1
2
3
4
5
| template <class RandomAccessIterator>
void sort(RandomAccessIterator first, RandomAccessIterator last);
template <class RandomAccessIterator, class Compare>
void sort(RandomAccessIterator first, RandomAccessIterator last, Compare comp);
|
对,std::sort()是重载函数,其中包含了是否存在comp的两种版本。std::sort()函数默认从小到大按字典顺序对数据进行排序,用法如下:
1
2
3
| int arr[10] = {12, 10, 48, 28, 22, 33, 19, 13, 27, 38};
std::sort(arr, arr + 10);
for(int i = 0;i < 10;i++) std::cout<<arr[i]<<" ";
|
此时std::sort()函数便会将arr[0]到arr[9]共10个元素进行排列并放回arr数组,所以上述程序运行结果如下:
1
| 10 12 13 19 22 27 28 33 38 48
|
很容易就可以想到,对吧。
进阶
使用std::sort()对各类普通变量排序
对std::string类型变量排序
前面提到了,std::sort()会对数组使用字典序从小到大排序,所以结果就很容易预想到。
看下列程序:
1
2
3
| std::string arr[10] = {"apple", "Apple", "APPLE", "zen", "ordchaos", "OrdChaos", "happy", "x-ray", "xyz", "123aa"};
std::sort(arr, arr + 10);
for(int i = 0;i < 10;i++) std::cout<<arr[i]<<" ";
|
想一想,结果会如何?
结果:123aa APPLE Apple OrdChaos apple happy ordchaos x-ray xyz zen
怎么样,是不是很简单。这种对std::sort()的使用方式可以做按照字母序排列姓名的题目,但是如果题目要求按长度排序怎么办?别着急,慢慢往下看。
使用comp自定义排序顺序
刚刚说过,std::sort()是一个重载函数,有一个含有comp的变体,那么,comp是什么?用来干什么呢?简单来说,comp就是一个返回值为bool类型的函数,在这个函数里你可以自定义sort排序的顺序。这样说你可能不理解,那就来看看下面这个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
| bool cmp(int a, int b) {
return a > b;
}
int main() {
int arr[2][10] = {{12, 10, 48, 28, 22, 33, 19, 13, 27, 38},{12, 10, 48, 28, 22, 33, 19, 13, 27, 38}};
std::sort(arr[0], arr[0] + 10);
std::sort(arr[1], arr[1] + 10, cmp);
for(int i = 0;i < 10;i++) std::cout<<arr[0][i]<<" ";
std::cout<<std::endl;
for(int i = 0;i < 10;i++) std::cout<<arr[1][i]<<" ";
return 0;
}
|
在这里我定义了bool类型函数cmp(),其中若a>b则返回true,否则为false。然后两次调用std::sort(),分别为两个一模一样的数组arr[0]与arr[1]排序,不同的是第二次使用了我们定义的cmp(),那么,结果如何呢?
1
2
| 10 12 13 19 22 27 28 33 38 48
48 38 33 28 27 22 19 13 12 10
|
没错,第二次排序变为了从大到小排序。利用这种方法,我们就可以轻松解决刚刚的问题,像这样:
1
2
3
| bool cmp(std::string a, std::string b) {
return a.length() < b.length();
}
|
把这个函数加入刚刚的程序,再次调用std::sort(),只不过要加入参数cmp。很容易想到结果如下:
(动动脑哦)zen xyz apple Apple APPLE happy x-ray 123aa ordchaos OrdChaos
对std::string类型变量内部进行排序
联想到可以通过类似于str[i]的方式来访问字符串内字符,自认可以写出使用std::sort()排序字符串内字符的方法:
1
2
| std::string str = "rhuMJKhwHefJkUIGuw394y49h";
std::sort(str.begin(), str.end());
|
注意这里必须使用str.begin()与str.end()作为参数而非str与str+str.str.length()。
结果也就是可以料想的,编译运行,程序输出如下:
1
| 34499GHIJJKMUefhhhkruuwwy
|
整 整 齐 齐.jpg
利用comp同样可以实现逆序排序,那就请你自己想想怎么写吧!
使用std::sort()对结构体进行排序
设想一个场景,有一个结构体叫做student,其中含有单个学生的姓名和成绩。这时该如何通过学生成绩对学生姓名进行排序呢?这里用std::sort()就会使最快的方法。
先定义结构体:
1
2
3
4
| struct student {
string name;
int score;
};
|
然后写出对应的comp:
1
2
3
| bool cmp(student a, student b) {
return a.score > b.score;
}
|
之后直接调用std::sort()就可以了,合起来代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| #include<bits/stdc++.h>
using namespace std;
struct student {
string name;
int score;
};
bool cmp(student a, student b) {
return a.score > b.score;
}
int main() {
student stu[3] = {(student){"Tony", 98}, (student){"Betty", 97}, (student){"Lucy", 99}};
sort(stu,stu+3,cmp);
for(int i=0;i<3;i++){
cout<<stu[i].name<<endl;
}
return 0;
}
|
输出可以料想:
这样做的好处是方便拓展,比如说现在结构体变了,存在四个科目的成绩与学生姓名,要求按平均分排序,从之前的程序上修改会非常容易:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| #include<bits/stdc++.h>
using namespace std;
struct student {
string name;
int chinese;
int math;
int english;
int programming;
};
bool cmp(student a, student b) {
return (a.chinese + a.math + a.english + a.programming)/4 > (b.chinese + b.math + b.english + b.programming)/4;
}
int main() {
student stu[3] = {(student){"Tony", 98, 96, 100, 95}, (student){"Betty", 97, 80, 99, 95}, (student){"Lucy", 99, 96, 90, 100}};
sort(stu,stu+3,cmp);
for(int i=0;i<3;i++){
cout<<stu[i].name<<endl;
}
return 0;
}
|
这时结果就会变为Tony Lucy Betty的顺序。比起手写排序,这种情景使用std::sort()会方便不少。
做道题吧
洛谷:P1093 NOIP2007 普及组 奖学金
题目描述
某小学最近得到了一笔赞助,打算拿出其中一部分为学习成绩优秀的前5名学生发奖学金。期末,每个学生都有3门课的成绩:语文、数学、英语。先按总分从高到低排序,如果两个同学总分相同,再按语文成绩从高到低排序,如果两个同学总分和语文成绩都相同,那么规定学号小的同学排在前面,这样,每个学生的排序是唯一确定的。
任务:先根据输入的3门课的成绩计算总分,然后按上述规则排序,最后按排名顺序输出前五名名学生的学号和总分。注意,在前5名同学中,每个人的奖学金都不相同,因此,你必须严格按上述规则排序。例如,在某个正确答案中,如果前两行的输出数据(每行输出两个数:学号、总分) 是:
这两行数据的含义是:总分最高的两个同学的学号依次是7号5号。这两名同学的总分都是279(总分等于输入的语文、数学、英语三科成绩之和),但学号为7的学生语文成绩更高一些。如果你的前两名的输出数据是:
则按输出错误处理,不能得分。
输入格式
共n+1行。
第1行为一个正整数n(n≤300),表示该校参加评选的学生人数。
第2到n+1行,每行有3个用空格隔开的数字,每个数字都在0到100之间。第j行的3个数字依次表示学号为j-1的学生的语文、数学、英语的成绩。每个学生的学号按照输入顺序编号为1~n(恰好是输入数据的行号减1)。
所给的数据都是正确的,不必检验。
输出格式
共5行,每行是两个用空格隔开的正整数,依次表示前5名学生的学号和总分。
输入输出样例
输入1
1
2
3
4
5
6
7
| 6
90 67 80
87 66 91
78 89 91
88 99 77
67 89 64
78 89 98
|
输出1
1
2
3
4
5
| 6 265
4 264
3 258
2 244
1 237
|
输入2
1
2
3
4
5
6
7
8
9
| 8
80 89 89
88 98 78
90 67 80
87 66 91
78 89 91
88 99 77
67 89 64
78 89 98
|
输出2
1
2
3
4
5
| 8 265
2 264
6 264
1 258
5 258
|
分析
这是一道很好的练习结构体的题,核心就是刚刚说的使用std::sort()函数对结构体进行排序,只不过这次的comp会复杂那么一点点。
结构体定义与comp大致如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| struct student {
int num, chinese, math, english;
};
bool cmp(student a,student b) {
if((a.chinese + a.math + a.english) > (b.chinese + b.math + b.english)) return 1;
else if((a.chinese + a.math + a.english) < (b.chinese + b.math + b.english)) return 0;
else {
if(a.chinese > b.chinese) return 1;
else if(a.chinese < b.chinese) return 0;
else {
if(a.num > b.num) return 0;
else return 1;
}
}
}
|
剩下的部分就不必多说了吧,直接上代码:
1
2
3
4
5
6
7
8
9
10
11
12
| int main() {
int n;
std::cin>>n;
student stu[n];
for(int i = 0;i < n;i++) {
stu[i].num = i + 1;
std::cin>>stu[i].chinese>>stu[i].math>>stu[i].english;
}
std::sort(stu,stu + n,cmp);
for(int i = 0;i < 5;i++) std::cout<<stu[i].num<<' '<<stu[i].chinese + stu[i].math + stu[i].english<<std::endl;
return 0;
}
|
完成!

完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| #include<bits/stdc++.h>
using namespace std;
struct student {
int num, chinese, math, english;
};
bool cmp(student a,student b) {
if((a.chinese + a.math + a.english) > (b.chinese + b.math + b.english)) return 1;
else if((a.chinese + a.math + a.english) < (b.chinese + b.math + b.english)) return 0;
else {
if(a.chinese > b.chinese) return 1;
else if(a.chinese < b.chinese) return 0;
else {
if(a.num > b.num) return 0;
else return 1;
}
}
}
int main() {
int n;
cin>>n;
student stu[n];
for(int i = 0;i < n;i++) {
stu[i].num = i + 1;
cin>>stu[i].chinese>>stu[i].math>>stu[i].english;
}
sort(stu,stu + n,cmp);
for(int i = 0;i < 5;i++) cout<<stu[i].num<<' '<<stu[i].chinese + stu[i].math + stu[i].english<<endl;
return 0;
}
|
附加内容
std::sort()的平均时间复杂度是O(nlog(n)),原理是在数据量大时采用快速排序进行分段递归排序,而一旦分段后的数据量小于某个门槛,为避免快速排序的递归调用带来过大的额外负荷,就改用直接插入排序(不是插入排序)。如果递归层次过深,还会改用堆排序。
sort的速度够快,但若是追求极致速度且数据量很大,仍建议手写快速排序或归并排序。
题外话
写这篇文章真的累死…
写了足足一个小时啊啊啊啊啊
白里个白(逃
]]>
+
+
+
+
+ 编程
+
+
+
+
+
+
+ 计算机
+
+ 编程
+
+ c++
+
+
+
+
+
+
+
+
+ 四种排序
+
+ /posts/6a062b97/
+
+ 在这里简单的以浅显易懂的方式写一下竞赛中常用的四种通用排序方式。 冒泡排序
大概是所有人第一次学到的排序方式,毕竟它实在是太经典了。
简单介绍一下原理:
冒泡排序(Bubble Sort),是一种计算机科学领域的较简单的排序算法。
它重复地走访过要排序的元素列,依次比较两个相邻的元素,如果顺序(如从大到小、首字母从Z到A)错误就把他们交换过来。走访元素的工作是重复地进行,直到没有相邻元素需要交换,也就是说该元素列已经排序完成。
这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端(升序或降序排列),就如同碳酸饮料中二氧化碳的气泡最终会上浮到顶端一样,故名“冒泡排序”。
——来自 百度百科 冒泡排序
一言以蔽之,即依次按规律交换相邻元素位置,直至不能交换为止。
知道这一点就好办了,很容易就可以写出程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| void bubbleSort(int f, int l) {
bool flag = 1;
while(true) {
for(int i = f;i < l;i++) {
if(a[i] > a[i + 1]) {
swap(a[i], a[i + 1]);
flag = 0;
}
}
if(flag) break;
else flag = 1;
}
return;
}
|
运行一下,成功排序。
选择排序
听名字就知道,这是一种通过“选择”来排序的算法,它通过每次选择未排序元素中的最大/最小值并与最后一个未排序元素交换位置来进行排序。
附一张原理图(来自菜鸟教程):
代码依旧很简单:
1
2
3
4
5
6
7
8
9
10
| void selectionSort(int f, int l) {
for(int i = f;i <= l;i++) {
int max = f;
for(int j = f + 1;j <= l - i;j++) {
if(a[j] > a[max]) max = j;
}
swap(a[max], a[l - i]);
}
return;
}
|
(甚至比冒泡都简单)
同样的,正常运行。
快速排序
非常经典的排序算法,也是公认最快的的排序算法。原理是用基准数分割,把大于/小于基准数的数放在基准数左边,其余放在右边,此时右边部分个数据皆小于/大于左边所有数据,然后对左右两边区间分别递归调用即可。
先放上代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| void quickSort(int f, int l) {
int i = f, j = l, mid = a[(f + l)/2];
do {
while(a[i] < mid) i++;
while(a[j] > mid) j--;
if(i <= j) {
swap(a[i], a[j]);
i++;
j--;
}
} while(i <= j);
if(f < j) quickSort(f, j);
if(l > i) quickSort(i, l);
return;
}
|
分别从基准数(这里是中间数)左右两边找到第一个大于/小于基准数的元素,交换,然后继续找,直到左右的寻找范围重叠,即代表寻找完毕,递归寻找剩余区间即可。
再放一张动图了解一下原理(图片依旧来自菜鸟教程)
归并排序
归并排序是建立在归并操作上的一种排序算法,该算法是分治法的一个典型应用。方法是将已有序的子序列合并,得到完全有序的序列——即先使每个子序列有序,再使子序列段间有序,最常用的是二路或三路归并排序。这里给出二路归并排序的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| void mergeSort(int f, int l) {
if(f == l) return;
int mid = (f + l)/2;
mergeSort(f, mid);
mergeSort(mid + 1, l);
int i = f, j = mid + 1, k = 0, r[l - f + 1];
while(i <= mid && j <= l) {
if(a[i] <= a[j]) {
r[k] = a[i];
i++;
k++;
} else {
r[k] = a[j];
j++;
k++;
}
}
while(i <= mid) {
r[k] = a[i];
i++;
k++;
}
while(j <= l) {
r[k] = a[j];
j++;
k++;
}
for(int p = f;p <= l;p++) a[p] = r[p - f];
return;
}
|
二路归并排序的原理是先以中间数为基准分割出两个子序列然后分别进行归并排序,然后对有序表进行合并,相信看代码也可以看出来。最后将临时数组的值赋给待排序数组就结束。
效率测试
时间复杂度
算法的时间复杂度是一个函数,它定性描述该算法的运行时间,常用大O来表述。若用函数f(n)描述算法执行所要时间的增长速度,用函数T(n)表示算法需要执行的运算次数存在常数c和函数f(n),使得当n>=c时T(n)<=f(n),记作T(n)=O(f(n)),其中n代表数据规模。显然,n越小,算法运行的越快。
常见时间复杂度等级如下表:
| 分类 | 写作 |
|---|
| 常量阶 | O(1) |
| 对数阶 | O(log(n)) |
| 线性阶 | O(n) |
| 线性对数阶 | O(nlog(n)) |
| n方阶 | O(nn) |
| 指数阶 | O(2n) |
| 阶乘阶 | O(n!) |
以及常用算法的时间复杂度如下表:
| 算法 | 平均时间复杂度 | 最好情况 | 最坏情况 |
|---|
| 冒泡排序 | O(n2) | O(n) | O(n2) |
| 选择排序 | O(n2) | O(n2) | O(n2) |
| 插入排序 | O(n2) | O(n) | O(n2) |
| 希尔排序 | O(nlog2(n)) | O(n2) | O(nlog2(n)) |
| 归并排序 | O(nlog(n)) | O(nlog(n)) | O(nlog(n)) |
| 快速排序 | O(nlog(n)) | O(nlog(n)) | O(n2) |
| 堆排序 | O(nlog(n)) | O(nlog(n)) | O(nlog(n)) |
| 计数排序 | O(n+k) | O(n+k) | O(n+k) |
| 桶排序 | O(n+k) | O(n+k) | O(n2) |
| 基数排序 | O(n×k) | O(n×k) | O(n×k) |
测时
除了时间复杂度,还有一种方式可以测试算法效率——对于相同的数据,直接测试算法排序用时并比较即可。使用ctime头文件中的clock()函数即可获取时间,运行前后的时间差即为运行用时。
于是有代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| int main() {
int n;
cin>>n;
default_random_engine e;
uniform_int_distribution<int> u(0,1000000);
e.seed(time(0));
for(int i = 0;i < n;i++) {
b[i] = u(e);
}
clock_t begin, end;
for(int i = 0;i < n;i++) a[i] = b[i];
begin = clock();
selectionSort(0, n - 1);
end = clock();
cout<<"selectionSort end"<<endl<<"time: "<<double(end - begin) / CLOCKS_PER_SEC * 1000<<"ms"<<endl<<endl;
for(int i = 0;i < n;i++) a[i] = b[i];
begin = clock();
bubbleSort(0, n - 1);
end = clock();
cout<<"bubbleSort end"<<endl<<"time: "<<double(end - begin) / CLOCKS_PER_SEC * 1000<<"ms"<<endl<<endl;
for(int i = 0;i < n;i++) a[i] = b[i];
begin = clock();
mergeSort(0, n - 1);
end = clock();
cout<<"mergeSort end"<<endl<<"time: "<<double(end - begin) / CLOCKS_PER_SEC * 1000<<"ms"<<endl<<endl;
for(int i = 0;i < n;i++) a[i] = b[i];
begin = clock();
quickSort(0, n - 1);
end = clock();
cout<<"qsort end"<<endl<<"time: "<<double(end - begin) / CLOCKS_PER_SEC * 1000<<"ms"<<endl<<endl;
return 0;
}
|
额外使用了random头文件中的函数用来生成在0到1000000间的随机数用于测试(我懒得写用法了,建议出门左拐Google),运行结果(可能)如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
| (input 100000)
selectionSort end
time: 2536ms
bubbleSort end
time: 14222ms
mergeSort end
time: 8ms
quickSort end
time: 6ms
|
简单易懂,对吧。
题外话
又水了一篇文(不是。
还是很开心的,因为以前都没有成功完成过归并排序与快速排序,这次写出来自我感觉非常好。
那就这样,886.
]]>
+
+
+
+
+ 编程
+
+
+
+
+
+
+ 计算机
+
+ 编程
+
+ c++
+
+
+
+
+
+
+
+
+ 一名初中生的 GitHub 学生包申请之路
+
+ /posts/f0f71147/
+
+ 现在上百度搜索“github学生包申请”,结果要么只适用于大学生,要么就是通过各种国外社区大学的录取通知书来白嫖这不欺骗别人大学感情吗。而作为一名初中生,显然这两种方法都不太适合:前者需要大学学籍,后者…后患无穷且麻烦,成功率也不高。这里我就分享一下我与GitHub学生包的经历以及我的申请经验,帮助更多像我一样被同样问题困扰的人。 我与GitHub学生包
小时候没有零花钱,但又想建站,于是整天在Google、百度、Youtube等等地方搜索“免费域名”、“免费空间”…一类内容。终于,让我发现了GitHub学生包这个东西。然并卵,它有年龄限制(13岁以上),这让当时11岁的我感到弱小可怜又无助。然后我就在Youtube上看到了这个:
哇你知道这对我的内心造成了多大的震撼吗?我立马跟着操作了一番,但是却是在最关键也是最重要的一步上卡住了——人家GitHub没有过我的申请。
后来在别的地方看见了freedom的免费域名与忘记是什么地方的免费空间,用wordpress简单做了一个博客懒得写博文,结果到头来一篇文章也没有,这件事也就告一段落。
去年年中突然想起来这一茬,想到那一年我就13岁了,年龄限制已经跨越,我这正经学生身份还不得通过的手到擒来?然后我就上传了自己绝对真实的申请所需的一切信息,然后…又没有过。其实也不是没有过,单纯是审核了两周还一直状态显示pending,我一怒之下就撤销了申请而已自己不是说最多两周吗,于是这件事就又被放下。
再然后又到了今年年初,又想起GitHub学生包来。我一想到我一个学生申请不到学生包就来气,于是又申请了一次。与上一次不同,上一次的材料我交的是期末成绩单,这一次是学校发的奖状。说实话,对用奖状申请这回事我是很不抱希望的,但又没想到在三天后我打开电脑例行检查进度时…
一个绿底白字的Approved就这么糊到了我的脸上。哇我真的,你能理解吗就是那种,无法言表的欣喜,那种恨不得让全世界的人都知道你干成了什么的自豪感,就是这种感觉充满了我当时的脑海。没有别的原因,就是太高兴了。
附一张当时我的聊天记录:
然后自然是各种折腾、体验、白嫖,这些就不在这篇文章的讨论范围之内了。
我的申请经验
第一,千万不要挂梯子,尽量直连GitHub。GitHub会通过地理位置校验你是否可能真正在你所填写的学校就读,所以同样如果浏览器提示你开启地理位置就点同意。
第二,邮箱用自己的也可以,不限定教育邮箱。但是证明你学生身份的材料一定要详细真实,另外可以在How do you plan to use GitHub?(你怎么计划去使用GitHub)中附上材料的英文翻译。
第三,How do you plan to use GitHub?一定要认真填写,不要在网上随便找然后就直接粘贴上去。有能力的就直接用英语写,否则用有道翻译也行。
第四,学校信息越详细越好这不废话,有官网的记得把官网填上当然要是GitHub数据库里有你的学校直接选择就完了。
第五,记得每天看一下申请进度,没准它就会给你一个惊喜。
题外话
相信细心的各位也发现了,申请是在三月就过了的,为什么现在才发博文呢?
答案嘛…因为懒(逃
最后就以一张我现在GitHub上Profile的截图来收尾吧!

]]>
+
+
+
+
+ 教程
+
+
+
+
+
+
+ 计算机
+
+ 编程
+
+ 教程
+
+ 白嫖
+
+ 福利
+
+ github
+
+ 学生
+
+
+
+
+
+
+
+
+ 一键推流工具—— BlogPusher
+
+ /posts/10824f12/
+
+ 近来无事,想着博客推流时的指令有好几条,于是决定写一个小工具简化这个流程这甚至是我第一个实用性的程序 在此之前
我的博客配置好后每次从本地推送源码的指令有四条:
1
2
3
4
| git pull origin master
git add .
git commit -m"xxxxxx"
git push origin master
|
这四条指令都在本地执行,所以每次推流都需要依次输入,而这显然是不方便的,于是我就想写一个能够自动执行这四条指令的工具。
程序设计
很简单,我们可以使用system()函数,其原型如下:
1
| int system(const char *command);
|
给函数传入字符串型的命令行参数就可以在程序中执行命令,于是很容易想到执行这三条命令的代码:
1
2
3
4
| system("git pull origin master");
system("git add .");
system("git push origin master");
|
这样除了commit提交外,其他的指令都可以自动执行。但这肯定是不完善且不可用的,因为commit的提交信息需要在git add与git push之间确定而不能在git push之后。
于是我们需要在程序中获取commit信息,这样就可以在git add之后自动执行commit提交指令。很容易我们就可以想到一种方法:
1
2
3
4
| string commit;
getline(cin, commit);
string commitInput = "git commit -m\"" + commit + "\"";
system(commitInput.c_str());
|
但我认为这样还不够简洁,我们需要的是一行可以直接推流的指令而不是一个需要用户输入的软件,所以我们需要另一种方式——获取命令行。
获取命令行
一般的c++程序中,我们的main函数都是这样定义的:
但为了获取命令行参数,我们就需要像这样定义:
1
2
3
| int main(int argc, char **argv) {
}
|
其中,argc是命令行参数的个数,argv则是一个指针数组,每个指针指向一个字符串,每个字符串是一个命令行参数。当我们执行一个可执行文件时,若是只在命令提示符中输入可执行文件的文件名,像这样:
那么argc的值就是1,而argv[0]的值就是BlogPusher,而若是在命令提示符中输入可执行文件的文件名和参数,像这样:
此时argc的值就是3,argv[0]的值仍是BlogPusher,但后面argv[1]的值则会是Update,argv[2]的值是About。
所以,我们就可以这样获取到我们需要的commit信息了。
Commit信息处理
光是获取还不够,现在我们需要处理我们获取到的参数。在刚刚的例子中,我们可以看到argv数组的分割是以空格为基础的,但commit中可以包含空格,这就使得直接使用argv[1]是不可行的。
所以,我们需要一种方法来处理commit信息,使其可以正确包含空格。其实很简单,只需要加入一个循环,每次循环获取一个字符串并把它放入字符串commit中,在每一个字符串之间加入空格即可。
1
2
3
4
5
6
7
8
| string commit;
string commit;
for(int i = 1; i < argc; i++){
commit += argv[i];
if(i != argc - 1){
commit += " ";
}
}
|
加了一个判断,使得程序不会给commit信息加入多余的空格。现在,commit信息就可以正确的包含空格了。
总结
所有程序合在一起差不多是这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| #include <iostream>
using namespace std;
int main(int argc, char** argv){
string commit;
for(int i = 1; i < argc; i++){
commit += argv[i];
if(i != argc - 1){
commit += " ";
}
}
string commitInput = "git commit -m\"" + commit + "\"";
system("git pull origin master");
system("git add .");
cout<<"git add success"<<endl;
system(commitInput.c_str());
system("git push origin master");
return 0;
}
|
编译,放入博客源码文件夹下。注意此时不要忘记在.gitignore中添加一行blogpusher.*,防止git上传时上传blogpusher文件。
在命令提示符中输入blogpusher Update .gitignore,测试一下,非常完美!
最后优化一下,差不多像这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| #include <iostream>
using namespace std;
int main(int argc, char** argv){
string commit;
for(int i = 1; i < argc; i++){
commit += argv[i];
if(i != argc - 1){
commit += " ";
}
}
string commitInput = "git commit -m\"" + commit + "\"";
cout<<"==========BEGIN PULL=========="<<endl;
system("git pull origin master");
cout<<"==========BEGIN ADD=========="<<endl;
system("git add .");
cout<<"git add success"<<endl;
cout<<"==========BEGIN COMMIT=========="<<endl;
system(commitInput.c_str());
cout<<"==========BEGIN PUSH=========="<<endl;
system("git push origin master");
return 0;
}
|
大功告成!
题外话
这个东西很早就想做了的说…现在做出来了还是十分欣慰。
程序已经开源到了github,欢迎查看。若是帮到了您的话,麻烦点个star,谢谢。
]]>
+
+
+
+
+ 编程
+
+
+
+
+
+
+ 计算机
+
+ 编程
+
+ c++
+
+ github
+
+ 开源软件
+
+
+
+
+
+
+
+
+ 学习笔记——二叉树
+
+ /posts/340b325e/
+
+ 二叉树binary tree,BT 介绍
- 一种特殊的树形结构,是度数为2的树。即二叉树的每个节点最多具有两个子节点,每个节点的字节点分别称为左孩子、右孩子,子树则为左子树,右子树。
- 二叉树可以为空且一定有序。
- 在二叉树的第i层上至多有2i个节点(i>=0)。
- 深度为m的二叉树上至多有1−21−2m+1=2m+1−1个节点(m>=0),一棵深度为m且有2m+1−1个节点的二叉树被称为满二叉树。
- 每一个节点都与深度为m的满二叉树中编号为1~n的节点一一对应的深度为m,有n个节点的二叉树被称为完全二叉树。
- 对于任意一棵二叉树,若其有n0个叶节点,n2个度为2的节点,则一定有n0=n2+1。
- 具有n个节点的完全二叉树的深度是floor(log2n)。
- 在有n个节点的完全二叉树中,对于编号为i的节点:
- 若i=1,则其无父节点,为根节点,否则其父节点编号为floor(2i)。
- 若2i>n,则i为叶节点,否则其左孩子的编号为2i。
- 若2i<n<2i+1,则i无右孩子,否则其右孩子的编号为2i+1。
如下图即二叉树示意图:
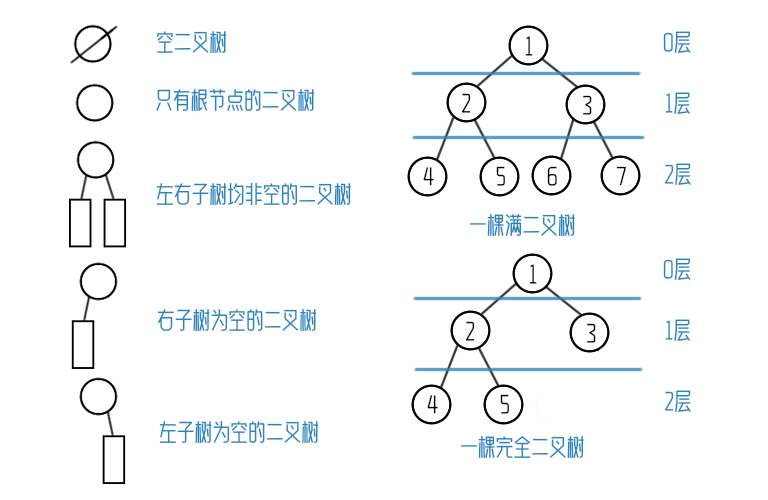
存储结构
单链表结构
1
2
3
4
5
6
7
| struct node {
int data;
node* lc, rc;
};
struct bt {
node* root;
}t;
|
与树一样,其实就是孩子表示法。
双链表结构
1
2
3
4
5
6
7
8
| struct node {
int data;
node* lc, rc;
node* father;
};
struct bt {
node* root;
}t;
|
同理,其实就是父亲孩子表示法。
遍历
- 先序遍历(输出->左孩子->右孩子)
- 中序遍历(左孩子->输出->右孩子)
- 后序遍历(左孩子->右孩子->输出)
普通树转二叉树
- 对于每一个节点,去除除最左边的树枝之外的所有树枝。
- 从最左边的节点开始,依次次将同层的每个兄弟节点横向相连。
- 以根节点为中心,将图形顺时针旋转约45°。
如下图所示:
树的计数
具有n(n>=1且n为整数)个节点的二叉树的种类的数量可以用下方的函数来表示:
f(n)={∑i=0n−1f(i)⋅f(n−i−1)1(n>1)(0⩽n⩽1)
题外话
这是第二篇学习笔记,上一篇可以点击这里查看。
]]>
+
+
+
+
+ 编程
+
+ 数学
+
+
+
+
+
+
+ 计算机
+
+ 编程
+
+ c++
+
+
+
+
+
+
+
+
+ 学习笔记——树
+
+ /posts/d4140423/
+
+ 树tree 介绍
- 由n(n>0)个元素组成的有限结合,是一种非线性的有序结构。
- 每一个其中的元素都被称为结点,除根节点外,其余节点组成的子集称为子树。
- 一棵树由根节点与结点组成,除根节点外每个节点都有前驱结点。一棵树至少有一个节点,此时,该节点即为根节点。换而言之,每棵树有且仅有一个根节点。在一个m层k叉数中最多有1−k1−km+1个节点(k>=1, m>=0)。
- 树是递归定义的,即在一棵子树中,其根节点同样在树中作为结点。
- 一个节点的子树个数称为这个节点的度(degree)。度为零的节点称为叶节点(leaf),不为零的节点称为分支节点(包括根节点),根以外的分支节点被称为内部节点。一棵树中度最大的节点的度被称为这棵树的度。
- 树状结构的图形中,连接两个相关联的结点的线段称位树枝。上端节点为下端节点的父节点,相对应的下端节点为上端节点的子节点,同一个父节点的所有子节点互为兄弟结点。从根节点出发到某个子节点所经过的所有节点均为该子节点的祖先,同理,此此节点为其所有祖先的子孙。
- 一棵树中根节点的层次(level)为0,其余的节点的层次为其父节点的层次加1。与度一样,树中层次最大的节点的层级被称为树的深度(depth)。
- 在树中,从一个节点出发,自上而下的沿着节点与树枝可以到达另一节点,则称它们间存在一条路径(所以显而易见不同子树上的节点间不存在路径)。用路径上的节点个数减一(即树枝个数,或是用层级较大的节点的层数减去较小的节点的层数)表示路径长度。
- 互不相交的数的集合称为森林,即森林是m棵互不相交的树的集合。
如下图即为一颗经典的树:

存储结构
父亲表示法
1
2
3
4
| #define MAX_LENGTH 10
struct node {
int data, father;
}tree[MAX_LENGTH];
|
这种方法容易找到树根,但是找孩子就需要遍历整个线性表,即时间换空间
孩子表示法
1
2
3
4
5
6
7
8
| #define MAX_DEGREE 10
struct node {
int data;
node* children[MAX_DEGREE];
};
struct tree {
node* root;
}t;
|
这种方法不可以从子节点返回父节点
父亲孩子表示法
1
2
3
4
5
6
7
8
| #define MAX_DEGREE 10
struct node {
int data;
node* children[MAX_DEGREE], father;
};
struct tree {
node* root;
}t;
|
是孩子表示法的优化版,可以直接访问任意子节点的父节点,是一种空间换时间的方法
孩子兄弟表示法
1
2
3
4
5
6
7
| struct node {
int data;
node* firstChild, next;
};
struct tree {
node* root;
}t;
|
总结
这些方法没有好坏之分,应当视情况选用
遍历
- 先序遍历(深度优先搜索dfs,从左至右先输出再搜索)
- 后序遍历(深度优先搜索dfs,从左至右先搜索到叶节点再依次输出并回溯)
- 层次遍历(广度优先搜索bfs,按层次从左至右搜索,搜索完一层后搜索下一层)
- 叶节点遍历(按先序遍历的方法遍历,但只访问叶节点)
题外话
这玩意是放暑假前在学校无聊看《信息学奥赛一本通》写的,大概还是有参考价值的吧。
另外还有一篇二叉树的,大概也会发上来。
]]>
+
+
+
+
+ 编程
+
+ 数学
+
+
+
+
+
+
+ 计算机
+
+ 编程
+
+ c++
+
+
+
+
+
+
+
+
+ About Choir
+
+ /posts/79cc3297/
+
+ Hello everybody! I’m 我的姓名, and you can also call me by my English name OrderChaos / OrdChaos. Today, I want to tell you something about chorus there. Yes, I know you may hate the chorus class in the noon, but please don’t hate the chorus itself.Chorus refers to the art category of collective singing of multi-voice vocal works. It requires a high degree of unity of single voice and harmony of melody between voices. It is one of the most popular and widely participated forms of music performance. As the expressive tool of chorus art, the human voice has its unique advantages, which can most directly express the thoughts and emotions in the musical works and stimulate the emotional resonance of the audience.
There are many types of chorus. In terms of voice and timbre, it is divided into two types: unison and chorus. Singing in unison refers to a chorus form in which all chorus members sing the same tune together regardless of their voices. It is often used in mass singing activities and can also be used in some fragments of chorus. Chorus refers to the superposition or contrast of two or more different parts of the chorus. It is one of the most typical forms of chorus. And from the accompaniment form, it is divided into two forms: a cappella and accompaniment. “A cappella” means to sung without instrumental accompaniment. It is a purely vocal art form. For example, the song 半个月亮爬上来 we have learned is an a cappella song. In contrast, accompaniment chorus is a form of chorus with accompaniment. Whether it is harmony, mode, dynamics, speed, or style, mood, and performance, they must be unified into the overall work as required.
Most of the choral songs are sung by the choir. A choir usually has a conductor with others who sing songs. Don’t think that the conductors just need to wave their hands, in fact they should do the things that much more complicated than this. For example, the free extension mark and the fade out mark in the score need to be controlled by the overall situation by the conductor, otherwise the song will become very discordant. Songs with weak or strong rhythm also need conductor to beat the rhythm, songs with different emphasis and emphasis also need to be reminded by the conductor. The coordination of multiple voices is also very important, a little attention will be taken out of tune, so everyone should use their own free time to practice – not make up the number.
Having said so much, I should also play a chorus song to listen to it, right? Let’s listen to 启程 sung by the Globe Jinshengyuzhen Choir (金声玉振合唱团). This is a new song learned this term - why do I know? Because I am a member of it.
(Play the music at this time)
(Say this while playing the intro) By the way, this was originally one of the most popular graduation songs for Japanese middle school students called 旅立ちの日に(Roman: Tabidachinohini), which was widely circulated in Japan. And Globe Jinshengyuzhen Choir have sung its Chinese version.
(Intro will be end at this time)
(While the song play finished, wait)
This song has not been officially announced yet. If you want to listen to the full version, please pay attention to the school’s WeChat public account.
OK! That’s all of my speech. Thank you for your to the full version, please pay . And now, I have a very easy question to ask you: Which country is the song 启程 come from?
(Answer: Japan | Say: Gerat! Thank you for your answer!) OK, that’s really all, thank you again!
]]>
+
+
+
+
+ 英语
+
+ 音乐
+
+
+
+
+
+
+ 演讲稿
+
+ 纯英文
+
+ English
+
+ 合唱
+
+ 音乐
+
+
+
+
+
+
+
+
+ C++ 链表实现队列
+
+ /posts/6270475f/
+
+ 之前介绍了数组队列的实现方法,若是没有看过建议去看看,这次来介绍如何用链表实现队列。 概念引入
首先让我们了解一下什么是链表:
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
——百度百科 链表
所以,首先我们需要定义一个链表出来。
结构搭建
其实基本一样,不过这次要定义两个结构,一个是节点,一个是队列本身:
1
2
3
4
5
6
7
8
9
| struct node {
int v;
node * next;
};
struct myqueue {
node * first;
node * last;
};
|
对于每一个节点,我们需要它储存一个数据与其下一个节点的地址,分别储存在int型变量v与node型指针next中。
而后对于每一个队列或者是链表,我们需要储存其第一个与最后一个节点的地址,分别放在first与last中。
结构体定义完后,同样的初始化:
1
2
3
4
| void init(myqueue *t) {
t->first = t->last = NULL;
return;
}
|
这里让队列的首项与尾项同时为NULL,完成初始化
之后是数据操作的isempty函数,先行判断队列是否为空:
1
2
3
4
| bool isempty(myqueue *t) {
if(t->last == NULL && t->first == NULL) return 1;
else return 0;
}
|
原理很简单,如果队列的尾项与首项都为NULL,则显然此队列为空。
之后是push函数,将一个数据推入队列的最后:
1
2
3
4
5
6
7
8
9
10
| void push(myqueue *t, int s) {
node * temp = new node;
if(isempty(t)) t->first = t->last = temp;
else {
t->last->next = temp;
t->last = t->last->next;
}
temp->v = s;
return;
}
|
创建一个空节点,如果队列为空,则作为首项与尾项,否则作为尾项的下一项,然后给其赋值即可。
第二个是pop函数,删除队列首项,注意先判断队列是否为空:
1
2
3
4
5
6
7
8
9
10
11
12
| void pop(myqueue *t) {
if(isempty(t)) return;
if(t->first == t->last) {
free(t->first);
init(t);
} else {
node * temp = t->first;
t->first = t->first->next;
free(temp);
}
return;
}
|
若pop完队列为空则调用init函数重新化为空队列,否则将首项改为首项的下一项,但记住无论如何都要调用free函数释放原先首项的空间,节省内存。
再就是获取队列的首项、尾项、第n项以及长度,代码相对简单:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| int getf(myqueue *t) {
if(!isempty(t)) return t->first->v;
else return 0;
}
int getl(myqueue *t) {
if(!isempty(t)) return t->last->v;
else return 0;
}
int getlength(myqueue *t) {
if(isempty(t)) return 0;
int length;
node * temp = t->first;
for(length = 1;;length++) {
if(temp == t->last) break;
temp = temp->next;
}
return length;
}
|
特别注意若队列为空,则不应当返回队列所谓的首项与尾项。
对于长度的获取,只需要遍历整个队列,直到搜索到队列尾项再输出长度即可。
解决问题
与之前的问题是一样的,搭建的框架也很相似,故而解答同样基本一致。
问题背景
有n(n <= 100)个小朋友排队打针,他们每个人都有依次自己的编号为1, 2, 3, 4, …, n。他们都很害怕打针,所以当排在自己前面的小朋友打针时就会跑走到队伍最后。试设计一程序,输入小朋友数量,输出他们打针的顺序。
样例输入:5
样例输出:1 3 5 4 2
问题分析
略,可以参考之前的文章。
注意这一次是使用指针来访问队列的,故而此次的程序与上次有略微区别。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| int main() {
myqueue test;
init(&test);
int n;
cin>>n;
for(int i = 1;i <=n;i++) push(&test, i);
for(int i = 1;!isempty(&test);i++) {
if(i%2 == 0) {
int temp = getf(&test);
pop(&test);
push(&test, temp);
}
else {
cout<<getf(&test)<<" ";
pop(&test);
}
}
return 0;
}
|
queue类型
这里对于队列的编写其实还是为了学习与方便理解,事实上可以方便的在引用了头文件queue后直接定义队列,更加方便,竞赛或开发时也更加节省时间。
使用格式如下:
1
2
3
4
5
6
7
8
| #include <queue>
queue<int> Q;
Q.empty();
Q.size();
Q.front();
Q.back();
Q.push();
Q.pop();
|
下面给出使用queue队列的同样问题的解答,请读者自行参考:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| int main() {
queue<int> test;
int n;
cin>>n;
for(int i = 1;i <=n;i++) test.push(i);
for(int i = 1;!test.empty();i++) {
if(i%2 == 0) {
int temp = test.front();
test.pop();
test.push(temp);
}
else {
cout<<test.front()<<" ";
test.pop();
}
}
return 0;
}
|
总结
本次完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
| #include<bits/stdc++.h>
using namespace std;
struct node {
int v;
node * next;
};
struct myqueue {
node * first;
node * last;
};
void init(myqueue *t) {
t->first = t->last = NULL;
return;
}
bool isempty(myqueue *t) {
if(t->last == NULL && t->first == NULL) return 1;
else return 0;
}
void push(myqueue *t, int s) {
node * temp = new node;
if(isempty(t)) t->first = t->last = temp;
else {
t->last->next = temp;
t->last = t->last->next;
}
temp->v = s;
return;
}
void pop(myqueue *t) {
if(isempty(t)) return;
if(t->first == t->last) {
free(t->first);
init(t);
} else {
node * temp = t->first;
t->first = t->first->next;
free(temp);
}
return;
}
int getf(myqueue *t) {
if(!isempty(t)) return t->first->v;
else return 0;
}
int getl(myqueue *t) {
if(!isempty(t)) return t->last->v;
else return 0;
}
int getlength(myqueue *t) {
if(isempty(t)) return 0;
int length;
node * temp = t->first;
for(length = 1;;length++) {
if(temp == t->last) break;
temp = temp->next;
}
return length;
}
int main() {
myqueue test;
init(&test);
int n;
cin>>n;
for(int i = 1;i <=n;i++) push(&test, i);
for(int i = 1;!isempty(&test);i++) {
if(i%2 == 0) {
int temp = getf(&test);
pop(&test);
push(&test, temp);
}
else {
cout<<getf(&test)<<" ";
pop(&test);
}
}
return 0;
}
|
我曾为提升自己而参考了他人的计划表准备施行于自己的日常生活之中,但不到三天便就放弃。无论是其中的两小时阅读时间,半小时健身亦或是额外的课外学习都远非我的课余时间可以容纳。计划不仅没有起到提升自己的作用,且打乱了我本稳定的作息,使我在那几天中萎靡不振,自然可以看出照搬他人经验是如此无用。“长者不为有余,短者不为不足”,长与短各有价值,没有高低贵贱之分,适合自己的远比他人的、华丽的、不切实际的好得多。自己的目标,自己的计划,也总是比他人的更贴合自己的要求。
鲁迅弃医从文,向全世界证明笔比手术刀更尖锐,最终成为世人铭记的文学大师;李白离开黑暗官场,漂泊天涯。一句“安能摧眉折腰事权贵,叫我不得开心颜。”让他领悟了人生的真谛;奥托-瓦拉赫放弃父母所选的文学,油画,而投身于化学,成为享誉全球的化学巨头……他们的人生都因为选择了自己的路而变得独特。若是没有选择适合自己的目标,他们也不会有如此的成就。
“尺有所短,寸有所长。”我们也要找到自己擅长的方面,发扬自己的长处,令自身拥有几个闪光点,不应见到他人便现慕他人的优点,因为自己也定有些地方远非他可以企及。世上的事业千千万万,只有适合自己的才是最好的。人无完人,故而所有人都需要认清自己的强项和弱势,看清自己,找准位置,均衡发展,从而更好的立足于社会之中。
“凫胫虽短,续之则忧,鹤胫虽长,断之则悲。”唯有找到自身定位,确定自我目标,制定自己的计划并为之付出汗水;践行思齐,见不贤而内自省,不断完善与提高自己;善假于物,发展自身特长,才能走上适合自己的路,取得令自身真正为之骄傲的成就。自己的人生需要自己演绎,自己的生活该有自己的选择。选择最适合自己的,才能活出自己的样子,活出自己的精彩。
]]>
+
+
+
+
+ 文学
+
+
+
+
+
+
+ 文学
+
+ 作文
+
+ 议论文
+
+
+
+
+
+
+
+
+ 三角形覆盖正方形的研究
+
+ /posts/4996fe6c/
+
+ 命题
如图1.0.1,等腰三角形GCD与正方形ABCD共边CD;CG、DG分别交AB于点E、点F. 则问不断增加等腰三角形GCD的高,能否使等腰三角形GCD完全覆盖住正方形ABCD?
证明/证伪
设正方形边长为a,三角形GCD的高为x,四边形EFCD的面积为y
方法一
∵ABCD是正方形∴∠A=∠B=90°,AB⊥AC于点A且⊥BD于点B,AB//CD∴△AEC与△BFD都是直角三角形,其中∠A=∠B=90°,且△GCD∽△GEF又∵三角形GEF的高是(x−a),三角形GCD的高是x∴EF:CD=(x−a):x∴EF=CDxx−a=xa(x−a)=xax−a2=a−xa2∴AE=BF=21(AB−EF)=21[a–(a−xa2)]=2xa2∴tan∠BDF=tan∠ACE=ACAE=BDBF=a2xa2当△GCD完全覆盖正方形ABCD时,有∠GDC=∠GCD⩾90°当∠GDC=∠GCD=90°时,tan∠BDF=tan(90°−∠GDC)=tan∠ACE=tan(90°−∠GCD)=tan0°=0∴ACAE=BDBF=a2xa2=0∴2xa2=0,a2=0,a=0此时原式不成立,所以等腰△GCD不能完全覆盖住正方形ABCD当∠GDC=∠GCD>90°时,有∠GDC+∠GCD>180°∵三角形内角和为180°∴此时GCD不是三角形,不符合题设,所以等腰△GCD不能完全覆盖住正方形ABCD综上所述,等腰△GCD不能完全覆盖住正方形ABCD
方法二
∵ABCD是正方形∴AB//CD∴△GCD∽△GEF,四边形EFCD是梯形又∵△GEF的高是(x−a),△GCD的高是x∴EF:CD=(x−a):x∴EF=CDxx−a=xa(x−a)=xax−a2=a−xa2∴S梯形EFCD=21AC(EF+CD)=21[a(a−xa2)+a]=21a(2a−xa2)=a2−2xa3若要让等腰△GCD完全覆盖住正方形ABCD,则显然有S梯形EFCD=S正方形ABCD于是可得a2=a2−2xa3,则2xa3=0,故a3=0,a=0此时原式无意义,所以等腰△GCD不能完全覆盖住正方形ABCD
综上所述,等腰三角形GCD无法完全覆盖住正方形ABCD.
推广
从方法二的证明过程中,可以发现三角形GCD可以不是等腰三角形,此时结论依旧成立。所以我们有真命题:在图1.0.1中三角形GCD无法完全覆盖住正方形ABCD.
探究
在方法二中,我们得出了正方形ABCD的边长a,三角形GCD的高x与梯形EFCD面积y之间的关系式,亦或者说是函数即y=a2−2xa3
那么,若是不让三角形GCD完全覆盖正方形ABCD(不让三角形GCD的高等于无限),而是让其高尽量长,趋近于无限呢?
此时,可得x→∞lim(a2−2xa3)=a2
于是有当三角形GCD的高x趋近于无限时,梯形EFCD的面积趋近于正方形ABCD的面积a², 此时三角形GCD在正方形内的面积趋近正方形ABCD的面积.
结论
图1.0.1中的三角形GCD无法完全覆盖住正方形ABCD,但若三角形GCD的高趋近于无限,则此时三角形GCD在正方形内的面积趋近正方形ABCD的面积.
]]>
+
+
+
+
+ 数学
+
+
+
+
+
+
+ 数学
+
+
+
+
+
+
+
+
+ C++ 数组实现队列
+
+ /posts/da7075f0/
+
+ 队列是常用的数据结构,是广度优先算法中不可或缺的一部分。队列一般使用数组或链表构建,这里会介绍使用数组实现队列的方法。 结构搭建
首先,定义队列结构:
1
2
3
4
5
6
7
| #define MAXSIZE 10000
struct myqueue {
int first;
int last;
int v[MAXSIZE];
};
|
变量first指向首项,last指向尾项其实不是,数据则存在数组v中。为了防止数据溢出,此时定义数组v的范围要尽量大,此处是10000。
再就是初始化队列:
1
2
3
4
| void init(myqueue &t) {
t.first = t.last = 0;
return;
}
|
让first与last都指向数组开头的第0项,很好理解。
之后,开始数据操作。第一个是push函数,将数值存入队列的最后:
1
2
3
4
5
| void push(myqueue &t, int s) {
t.v[t.last] = s;
t.last++;
return;
}
|
注意将last指向后面一项,此时变量last始终指向队列最后一项的下一项,是一个空值。
第二个是pop函数,删除队列首项。不过这里有一个坑,如果队列为空删除便有可能出错,所以要先判断队列是否为空:
1
2
3
4
5
6
7
8
9
10
| bool isempty(myqueue &t) {
if(t.last == t.first) return 1;
else return 0;
}
void pop(myqueue &t) {
if(isempty(t)) return;
t.first++;
return;
}
|
判断队列是否为空很简单,当first=last时,有队列为空(队列非空时,last在最后的数据项的后一位,所以first不可能等于last)。
pop时只需要移动首项的标识,避免了繁琐的数据移送,也无需置空数组的某一项,原因显而易见。但永远抛弃了一部分内存,故而要小心溢出。
再就是获取队列的首项、尾项、第n项以及长度,代码相对简单:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| int getf(myqueue t) {
return t.v[t.first];
}
int getl(myqueue t) {
return t.v[t.last - 1];
}
int getn(myqueue t, int n) {
return t.v[t.first + n];
}
int getlength(myqueue &t) {
return (t.last - t.first);
}
|
这里对于长度的获取需要说一下,理论上长度应当是(last - first + 1),但这里last本身就是数据项的后一项,所以自然就省掉了。
解决问题
现在整个队列已经完全可用了,我们可以尝试用其解决一些实际问题。
问题背景
有n(n <= 100)个小朋友排队打针,他们每个人都有依次自己的编号为1, 2, 3, 4, …, n。他们都很害怕打针,所以当排在自己前面的小朋友打针时就会跑走到队伍最后。试设计一程序,输入小朋友数量,输出他们打针的顺序。
样例输入:5
样例输出:1 3 5 4 2
问题分析
很显然,这样需要模拟过程的题目用队列解答会非常容易,直接使用队列出入队模拟这一过程即可。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| int main() {
myqueue test;
init(test);
int n;
cin>>n;
for(int i = 1;i <=n;i++) push(test, i);
for(int i = 1;!isempty(test);i++) {
if(i%2 == 0) {
int temp = getf(test);
pop(test);
push(test, temp);
}
else {
cout<<getf(test)<<" ";
pop(test);
}
}
return 0;
}
|
代码比较简单,关键还是在于前面对整个队列结构的搭建。
总结
队列的用处非常大,后面广度优先算法也会用到,建议多理解、多练习,掌握的越熟练越好。
本次完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| #include <bits/stdc++.h>
using namespace std;
#define MAXSIZE 10000
struct myqueue {
int first;
int last;
int v[MAXSIZE];
};
void init(myqueue &t) {
t.first = t.last = 0;
return;
}
bool isempty(myqueue &t) {
if(t.last == t.first) return 1;
else return 0;
}
void push(myqueue &t, int s) {
t.v[t.last] = s;
t.last++;
return;
}
void pop(myqueue &t) {
if(isempty(t)) return;
t.first++;
return;
}
int getf(myqueue t) {
return t.v[t.first];
}
int getl(myqueue t) {
return t.v[t.last - 1];
}
int getn(myqueue t, int n) {
return t.v[t.first + n];
}
int getlength(myqueue &t) {
return (t.last - t.first);
}
int main() {
myqueue test;
init(test);
int n;
cin>>n;
for(int i = 1;i <=n;i++) push(test, i);
for(int i = 1;!isempty(test);i++) {
if(i%2 == 0) {
int temp = getf(test);
pop(test);
push(test, temp);
}
else {
cout<<getf(test)<<" ";
pop(test);
}
}
return 0;
}
|
首先,我们应该明确一个概念,即什么是自主学习。自主学习就是随意的学、无拘无束的学吗?显然不是。自主学习是以自学、质疑、讨论等方式深入理解学习内容并获得新知识的一种实践活动,是通过自我导向、激励、监控的方法学习。其需要我们不断地尝试一些适合自己的有效的学习方法,合理的掌控学习时间,以便于专心地投入学习中。
要做到自主学习其实并不难,只需要把学习看作是一件令人快乐和愉悦的事。是的,学习的过程虽苦,却也满含着即将迎来收获的喜悦。完成自主学习的过程大概分为五点:一、了解自己:透过渐趋清明的自我概念、自我价值、自我认知,朝自觉、自足、自在的境态迈进;二、了解环境:透过知识与经验,了解环境的资源及限制;三、寻求自己与环境最佳的互动可能:在了解自己也了解环境的基础上,能找出当下合适的对应;四、着手实现:靠勇气、恒心、毅力,使自己能实践出心中所想,知行合一。五、保有循环向上的检视机制:透过计划->实行->检视->增进的循环,让自己从每次的经验中有所反省和收获。上面的说法比较枯燥,就拿我个人来举例吧,从小学一年级开始,我就对数学很感兴趣,喜欢看一些趣味性的数学书,还经常自以为很厉害,主动寻找“难题”去“考”父母和老师,这其实就是一种出于本能的自主学习过程。后来,我出于对电脑编程的喜爱,出于对计算机的掌控中获得的欣喜感和满足感,编程培训课如无意外我从不缺课,平时还主动上网学习电脑编程知识、了解电脑信息和发展动态,同时,由于编程和设计需要用到大量知识,我也不放松自己对数学、物理、英语、语文甚至美术的学习。如果说小时候对数学难题的解题过程是一种懵懂的自主学习的初级状态,那么之后对编程和相关知识的自主学习就是在了解自我,了解环境的基础上,充分利用现有的时间、精力和资源,通过各种努力,达到自主学习的进阶状态。
同学们,“没有比人更高的山,没有比脚更长的路”,前行的路就在我们自己脚下,命运之门的钥匙就在我们自己手中。让我们从点滴做起,让自主学习成为持之以恒的一种习惯,成为我们自主的生活方式。我衷心祝愿每一位同学能克服自身的惰性,付以恒心与毅力,走向属于你自己的成功!
谢谢大家!
]]>
+
+
+
+
+ 文学
+
+
+
+
+
+
+ 演讲稿
+
+ 文学
+
+ 作文
+
+ 议论文
+
+
+
+
+
+
+
+
+ 尊重客观规律
+
+ /posts/8f132c87/
+
+ 只有尊重客观规律,才能事有所成。西门豹出任邺令,破除封建迷信,转而挖掘渠道、灌溉农田,治理了邺城常有的水灾;鲧以堵治水而无能为力,大禹改堵为疏,完成了治水的大业。这些都是以对客观规律的尊重而得到的成果,也证明了人类若是要认识和改造世界,必须先尊重客观规律。青藏铁路只从西宁修到了格尔木就不再延伸,这份阻碍并非因为资源,而是来源于人们对客观规律的践行——在当时的条件下,这样的施工若是继续下去一定会对当地,甚至整个中国的生态造成破坏。人们不断只有尊重、探索客观规律,才能更好的造福社会。尊重客观规律,是在践行宇宙的真理。“橘生淮南则为橘,生于淮北则为枳,叶徒相似,其实味不同。所以然者何?水土异也。”柑橘在南方能长出甜美饱满的果实,但在北方就只能结出味苦的枸橘。英国文艺复兴时期散文家、哲学家弗朗西斯·培根曾经说过:“只有顺从自然,才能驾驭自然。” 世间万物皆有其自身的规律,许多事物也万万不能强求,“强扭的瓜不甜”。瓜一旦成熟,其瓜蒂部分便会变得干枯,自动脱落,很容易摘;而若是瓜还并未成熟,那么瓜蒂部分必然长得很结实,要想把瓜摘下来就一定要使劲扭。如此摘下的瓜自然都是未成熟的,又怎可能甜?规律是亘古永存的,其具有客观性与普遍性。柑会变成枸橘、瓜会没有甜味,这一切的改变都是客观规律使然。“昔者海鸟止于鲁郊,鲁侯御而觞之于庙。奏《九韶》以为乐,具太牢以为膳。鸟乃眩视忧悲,不敢食一脔,不敢饮一杯,三日而死。”“宋人有闵其苗之不长而揠之者,芒芒然归,谓其人曰:“今日病矣!予助苗长矣!”其子趋而往视之,苗则槁矣。”鲁侯养鸟、揠苗助长,都是不遵守客观规律而造成的后果·。如此可以看出,规律的存在和发生作用都以一定的客观条件为基础,在不具备其根据和条件的情况下,人为的要求某个规律存在和发生作用是不可能的。综上所述,在实际生活中,规律是不可抗拒的。也只有按规律办事,才可能达到所需要的目的。
]]>
+
+
+
+
+ 文学
+
+
+
+
+
+
+ 文学
+
+ 作文
+
+ 议论文
+
+
+
+
+
+
+
+
+ 牺牲少数保护多数是不正义的——一辩发言
+
+ /posts/bff2b1a/
+
+ 尊敬的老师及评委们,大家好!我们的观点十分明确,即牺牲少数保护多数是不正义的。请注意辩题中的措辞,是“不正义”而远非“邪恶”。不正义并非与正义成对立的关系,而是互补——任何称不上正义的行为都可以称之为不正义。不正义不是一个极端的点,而是除了正义这个点外的整条线。所以换句话说,我们认为,牺牲少数保护多数的行为不配称之为正义。“牺牲”本义指古希腊哲学家柏拉图在《理想国》中曾表明正义是客观存在的,所以并不存在所谓“相对的正义”,也不可能从两个角度分别看待一件事正义与否并得出不同的答案。既然我们已知牺牲少数保护多数从某些角度上来看并非正义,那么这件事自然便一直不在正义的范畴之中,于是其只能是不正义的。著名德意志哲学家,德国古典哲学创始人伊曼努尔·康德认为:人,是目的本身,即在任何时候任何人(甚至上帝) 都不能把他只是当作工具来加以利用。若是牺牲少数来保护多数,那不正是把少数人放在了可以随时被“牺牲”、被消耗的“工具”的位置上吗?恶也油然而生。这样的行为无论如何加以粉饰也不可能被称之为正义。人同样存在最高权力,高过任何外界利益总和。我们拥有我们自身,是自由的个体。在此基础上可以构建出人人平等的前提,所以“使社会利益最大化”的行为,即牺牲少数保护多数并非正义。
常常有一句话说“公平即正义”,但是其逻辑性趋近于无。“正”即合于法则的(合于法律的)、规矩的(指相对的两方面中积极的一面),而“义”则是公正合宜的道理或举动(合乎正义或公益的)。所以可以得出正义是指合于法则的公正合宜的行为。而公平,“公”与“私”相对,指属于国家或集体的;“平“则是指一般的,故而“公平”的意思是指集中而大多适用的道理。自然“牺牲少数保护多数”的行为只属于公平而非正义。
我们可以举一个例子,为了救活十个即将饿死的人,杀死其中一个人作食物给另外九个人吃,这样做对吗?从结果上看,活下来的人数比死去的人多,似乎就应该按照这样的办法去做。不过我们可以深思一下,假若按照上述价值观去做,虽然短时间内使社会利益得到了最大化,但是如此侵犯个人的基本权利最终会使社会整体幸福度降低。从长远看,若这种做法流行起来,社会将变得鸡犬不宁人人惶惶不可终日。
最后,我们社会的发展,社会的价值的提升,并不是通过牺牲少数人,牺牲弱势群体来达到的,而是通过平衡社会中不同阶级之间的关系,来使社会达到一种动态的平衡。当弱者出现时我们每个人献出一点爱让他们变得强大。当少数人的利益与多数人的利益冲突时,我们虽然会使少部分人做出牺牲来达到利益的最大化,但是我们不会自诩正义,我们心中会永远记得那些为多数而牺牲的少数,并为补偿他们而不懈奋斗着,因为“无正当补偿便不能剥夺”原则是对共同利益的最好保护。那些剥夺了他人的权益还自称正义的人是这个世界上最大的暴徒。
综上所述,我方认为牺牲少数保护多数是不正义的。谢谢!
]]>
+
+
+
+
+ 文学
+
+ 辩论
+
+
+
+
+
+
+ 演讲稿
+
+ 辩论
+
+ 牺牲
+
+
+
+
+
+
+
+
+ 《四世同堂》读后感
+
+ /posts/92674965/
+
+ 学期末老师列了一条长长的书单,让我们选择两本来写读后感。正巧以前听闻过老舍先生的《四世同堂》,于是便选择了它与另外一本书。在我的印象中,老舍先生的书里我只看《骆驼祥子》。当然肯定不止这一本,只是忘了其它书的名字罢了。但书到货之后我震惊了,因为这本书完全不像我想的那样。这本,不,应该是这套书比我以前所读过的所有书都要厚。而在真实的读过一遍这本书后我却才发现。这个厚度也不算什么,因为它的剧情真的非常好。
《四世同堂》是老舍最著名的长篇小说,这部百万字的巨著描述了卢沟桥事件爆发的一九三七年至日本投降的八年间北京普通市民遭受到的残酷压迫与统治,以及他们面对生与死的自尊与自省。老舍这部书中展示了北平沦陷区一群普通人的生活。通过祁老人、瑞丰、瑞宣、韵梅、钱诗人、小文夫妇、李四爷、白巡长、孙七、小崔、马老太太、常二爷、小妞妞以及大赤包、招弟等人物形象,表现出民族存亡之际,真善美与假恶丑的斗争,崇高的民族气节和苟且偷安、助纣为虐的对照。
老舍在《四世同堂》中对于人物性格的刻画及其的用心,而刻画出的任务同样的非常立体。比如在描写汉奸时:冠晓荷与蓝东阳是小说中的汉奸形象代表,“无事乱飞是苍蝇的工作,而乱飞是早晚会碰到一只死老鼠或一堆牛粪,冠先生是个很体面的苍蝇。”而老舍先生用极妙的笔法对蓝东阳道:“蓝东阳的相貌先引起试官的注意。他长得三分像人,七分倒像鬼。日本人觉得他的相貌是一种资格与保证——这样的人,是地道的汉奸胚子,永远忠于他的主人,而且最会欺压良善。东阳的脸足以引起他的注意,恰好他的举止与态度又是那么卑贱的出众,他得到了宣传处处长。”
而放远了看,实际上,老舍先生描写的这个时代下的中国正是二战期间法西斯侵略活动的最好的印证。读书的时候很容易就会联系到以前看过的海明威著作的《永别了,武器》。这本书讲的是一战期间的故事。一战时交战双方的目的主要是瓜分殖民地,争夺市场和原料产地;二战法西斯国家不仅要打败对方,而且要在全世界范围内建立法西斯制度。这也就解释了为什么日本区区一个弹丸之地,竟然有吞并整个东南亚的野心,且近乎于成功了。书中有写“短腿小鬼可不管你是否是它的一条狗,只要它认为你可疑,不值得信任或没有利用的价值了,旋即投狱、折磨、杀死,没有丝毫的理由。”这就是日本人的强盗逻辑,这就是这个民族嗜血成性的侵略本性。只有我们自己手握武器,狠狠地痛击它,它才能乖乖地缩回乌龟头,在它的小岛上蛰伏不动。
回归书中,回归二战,回归北平。其实无论在什么时代,谁都想过着安适美好的日子,可是当祖国受到侵略,当侵略者剥夺人们正常生活的权力,每一个有正义感和民族感的普通老百姓都会用自己的方式来保卫自己的家园的想法,但是这不可能。人只能在愤激反抗所博得的美名与背负骂名的存活中选择一个。选择其中一边的人是有的,而这些人恰恰会是被后人熟记、明知的。大部分老百姓什么也没有选,而是站在它们之间,想着苟且偷生。我为汉奸们可悲,更为那些觉醒后勇于反抗的人们感到欢欣鼓舞。小说中的一些次要人物就像我们揭示了老百姓们可悲的一面。他们因为一点蝇头小利便偏向了侵略者一方。以往拳打汉奸的金三爷,因为日本人带来的好生意转而感激,之后甚至出卖了钱默吟先生。年轻貌美的招弟,堕落成一个出卖肉体的女人,却还以此为荣。这些没有是非观的行为无疑是贪念在作祟。最后,当抗战最终胜利,人们仿佛才想起了报仇,结尾几个小伙子想找日本老太婆报仇的事再次让人嗤笑和而叹息。人们已经不怎样能高兴起来了,八年的风雨飘摇,战争给人民带来了无尽的苦难,给中国大地留下了累累伤痕。我们不应忘记这段屈辱的过去,要时刻铭记那段冰风冷雨的历史,创造辉煌的未来。
]]>
+
+
+
+
+ 文学
+
+
+
+
+
+
+ 文学
+
+ 作文
+
+ 读后感
+
+ 议论文
+
+
+
+
+
+
+
+
+ 浅探魏晋名士的精神世界
+
+ /posts/d29e300c/
+
+ 提起魏晋,“名士风流”四个字是现代人对它的基本认知,在中华民族几千年的历史长河中,也唯有魏晋南北朝时期独有的世族门阀在政治、经济、文化领域与皇权分庭抗礼甚至占主导地位的条件下,才能形成“魏晋风度”这一独特的文化现象。代表家族如王谢世家,代表人物如竹林七贤等,除了留下大量诗歌、书法、音乐等文化遗产外,还留下了处变不惊、旷达任率、不拘礼法、风神潇洒、不滞于物的精神风貌和思想风格供后世研究探讨。魏晋名士如此“特立独行”的精神世界,它的形成有一个长期过程。东汉末年开始的南北分裂和战乱,党锢之祸、黄巾起义、三国鼎立、司马氏篡权,百多年的血雨腥风,动荡不安,使“汉末名教”作为思想束缚的礼教开始崩塌,士人们不再对皇权盲目崇拜,开始拥有了自我意识,而其中一些有识之士不安于现状,不断追求思想上的创新与突破。他们会去对规则本身的合理性进行考虑,以探寻规则外的广阔天地;他们不仅行为上不愿再受规则的束缚,精神世界也同样不甘压迫;他们开始探索宇宙自然与人生本体的关系,追求新的思辨哲理。
现在看这些名士们的行为,可以发现其实连带着魏晋风度本身,有些只是反常的叛逆性极强的怪异举动,可以认为是在名教长时间压迫下的剧烈反弹。甚至会出现一些较为过激的行为,如在《世说新语》任诞篇中对刘伶的记载:“刘伶恒纵酒放达,或脱衣裸形在屋中。人见讥之,伶曰:我以天地为栋宇,屋市为裈衣,诸君何为入我裈中?”如此行为,只能称得上是“率性而为,任诞放达”了,其叛逆性之强不容否认。
除了战乱,魏晋时期残酷的政治清洗同样令人不安,无论是个人的生命还是家族的命运,全都在统治者、权贵的争权夺势中难以独善,所以魏晋士人在放达不羁的行为中也折射出深深的忧惧和哀伤。故而反抗礼教的名士们便只得走向崇尚老庄,酗酒佯狂,傲啸山林,不与时务的道路,个人认为,这一点是促成魏晋风度中“隐居”行为的重要因素。而从嵇康的性情刚直,阮籍纵酒放达等都能看出些许佐证。
在这样政治黑暗,礼教束缚的年代,尽管出现了文人集体失语的现象,但魏晋名士的特点就是不会停止对成为累赘的礼教的批判与反抗,不会停止对自由人格的永恒追求。在魏晋名士眼中,自由就是顺从自己的天性,任性而为,随心而动。他们具有超脱世俗自由独立的人格理想,所以能一边否定外界社会一边重构自我人格,“人生贵得适意尔”。随着道教的兴起、佛教的传入,开创出儒道互补的士大夫精神,奠定了中国知识分子的人格基础,不可不谓影响深远。
当然任何事情都有其两面性。对于魏晋名士的思想和行为,被后世最为诟病的是“五石散”的服用和空谈玄理的风气。或出于养生、或出于美容、或出于对长生的追求、或出于身份地位的昭示,士人们刻意忽视它的副作用,使服用五石散成为一种“时尚”,造成了了大量人力物力的浪费和对身体的伤害。甚至连家境并不富裕、买不起五石散的人们都会争相模仿:当众倒地,自称“石发”。闹出不少笑话。在《太平广记》中《启颜录﹒魏市人》便有“有一人,于市门前卧,宛转称热”的记载,可见一斑。而魏晋名士的清谈,考验的是口才和思辨,但从开始的成就自己的政治抱负发展到只关心自己一家一姓一族的得失,崇拜浮虚、寄情酒色、不管国事,致使朝野颓唐,甚至间接导致了西晋的亡国,从此流传下来“清谈误国”这句话。
动荡时期的不安全处境和残酷的政治斗争中,要么顺应环境保全生命,要么纵情于山水追求的精神解放,要么饮酒服药带来短暂的麻痹,这种焦灼矛盾的状态或许就是魏晋名士精神世界的形成原因,我们在研究和探索的过程中,不应该将狂放、酗酒、服药等视为风流,而忽视了它所产生的时代背景,不能只看到他们狂放洒脱的一面,更要看到深刻沉重的一面。
我认为,魏晋名士之所以为名士,不是因为不羁和自由,而是因为才学。如竹林七贤中阮籍的诗歌、山涛的文集、嵇康的文集和音乐等等,更有世家中的高门大户王家的书法和谢家的政治成就。但是他们中的大多数却选择清谈、避世,选择隐居甚至堕落。精神上的虚无主义,使他们留名后世,却在当时无所作为,未能为动荡的社会做些什么,亦未能解救悲苦的百姓。历史上每逢乱世,必会产生开放的思想,并由此造福于百姓,有破有立。唯有魏晋名士,思想开放却是破而未立。他们的反抗仅仅只是反抗,却未有切实可行的主张去改变社会现状。
所以,魏晋风度对当世可能仅仅是一种浮于表面的行为艺术,一种看破世俗的有识之士的无能呐喊,一场雷声大雨点小的思想革命。虽然为后世留下了丰富的文学经典,但却几乎未在当时的社会中产生任何正向作用。名士们的精神世界中除了繁多的思想外,难说是否有未民生的思考,抑或是仅仅停留在了“人生贵得适意尔”的“适意”上。故而我们既要学习他们对自由与创新的向往,更要善于学习,善于以辩证的思想去看待他们本身、他们的行为及他们的精神世界,而非盲目追随。
]]>
+
+
+
+
+ 文学
+
+
+
+
+
+
+ 文学
+
+ 作文
+
+ 议论文
+
+
+
+
+
+
+
+
+ 《钢铁是怎样炼成的》读后感
+
+ /posts/bb5ce830/
+
+ 一个人的人生应当这样度过:当他回首往事时,不因虚度年华而悔恨,也不因碌碌无为而羞耻。——题记
保尔是一个无私的人,他总是把党和祖国的利益放在第一位。在战争年代,保尔情愿与父兄们一起上战场;为保卫苏维埃政权,他甘愿同外国武装干涉者和白匪军拼个你死我活。这些都表现保尔了甘愿为革命事业的献身精神。在如此的艰难岁月中,他却能将自己全部的热情投入到了和平劳动之中。虽然他为国家、党与人民做过如此大的贡献,但他却从未骄傲过,也从未考虑过个人的名利、地位,而只想多为党和人民做点事情。党叫他修铁路,他答应;党调他当团干部,他同意——而且都是拼命地做。为了革命他甚至可以牺牲自己个人的私生活,即爱情。他虽然爱丽达,但受到了“牛虻”的影响,所以想要“彻底献身于革命事业”,最后按照“牛虻”的方式与她不告而别。在保尔全身瘫痪、双目失明后,他仍然想继续为党工作。这些都正如他所言:“我的整个生命和全部精力,都献给了世界上最壮丽的事业——为人类的解放而斗争。”
保尔是一个于平凡且伟大的人物。在他的一生中,一直没有过什么惊天动地的伟大业绩:他总是从最平凡的小事做起。面对疾病的沉重打击,虽然他也曾产生过自杀的念头,但是保尔后来也认识到了这是一种任性和不负责任,于是他又重拾了对生活的信心。也正是因为作者的这种塑造,所以保尔才会让我们感受到一种真实感。他是伟大的,也是平凡的。他既是在不断的困境与不幸中真正被煅炼的钢铁,也是一个有血有肉的、让人感到亲切的人。
书中对于保尔残疾后形象的塑造也同样不乏。保尔因不幸而残疾,但尽管自己身体行动不便,他也用自己顽强的毅力克服了种种困难。他在残疾后毫不灰心,反而更加的刻苦学习与奋力工作,同时还开始了文学创作。即使是他双目失明后他也未动摇过其信念,只是拿起了笔,摸索着尝试写作。即便是每写一字,他都需要付出常人根本无法想象的艰辛劳动他也坚持了下来,由此最后他才终于写出了小说《在艰苦暴风里诞生》的一部分。保尔是一个普通的革命战士,但却有着这样钢铁般的坚强意志,这与共产主义事业的召唤是不可分割的。他投身于革命事业,一次又一次的创造着奇迹。
世界上基本没有什么是天生的,所有事物都只有在经过火焰的煅炼后才可以使自身得到不断地升华。保尔是,我们也是。我们每一个人都只有树立伟大的理想、执着的追求,并且在正确的拼搏道路上不断砥砺前行,他才不会被生活的火焰所摧毁,不会被不幸的塑造所扭曲。这样的人会在一段段人生经历中坚强、成熟起来,去绽放自己的力量、迎接更好的自己。
]]>
+
+
+
+
+ 文学
+
+
+
+
+
+
+ 文学
+
+ 作文
+
+ 读后感
+
+ 议论文
+
+
+
+
+
+
+
+
+ About Food
+
+ /posts/53c0d957/
+
+ Hello everybody!Fast food is come from Ancient Roman. At that time, many people didn’t have enough money to buy or rent a house with a kitchen. So many people could only buy food from street vendors. At the same time, there were some pilgrims to Rome to buy fast food, too. That’s the first kind of fast food. And now, fast food has become popular all over the world.
Fast food is tasty, but there are some criticisms of fast food. Lots of fast food are rich in calories as they include considerable amounts of mayonnaise, cheese, salt, fried meat, and oil, thus containing high fat content. Excessive consumption of fatty ingredients such as these results in unbalanced diet. Children who eat fast food tend to eat less fiber, milk, fruits, and non-starchy vegetables. And even adults, like the school’s foreign teacher, Daniel. He likes to eat fast food and snacks. He usually buys snacks after class. Have you seen him? He is very fat and looked very old. But he is only in his 20s. I took his class while I was still in the class GUHONGMING. He hardly ever came upstairs. Because he was too fat to hold his weight. So we always have his class on the first floor. But don’t worry, it happens that some other foods are healthy and good for us, which is also the content of our next section - healthy food.
There are also some other food besides fast food, like vegetables and fruits. We can call then as healthy foods. They can help our body in many ways. First of all, there are many vitamins in them, such as vitamin C, which is very important for the human’s body. In the past, crews on the boat caught on a disease called scurvy. Then they found out a way to cure the disease: eat fruits and vegetables which are rich in vitamin C. So now we can see that healthy food such as fruits and vegetables are very important and good for our human’s body.
Besides, there are some foods that are healthy and have many proteins, such as meat. Proteins play a major role in ensuring your overall well-being. Meanwhile, it is one of the most important components of every cell presenting in the body. In our daily life, we mainly eat vegetables and meat. With the improvement of people’s living standards, people’s interest in meat is getting lower and lower. Many people eat vegetables and fruits as their staple food, and female friends stop eating meat in order to keep fit. But people do not eat meat will lead to inadequate protein intake, will lead to physical weakness, decreased resistance, fatigue, cold, lack of energy, memory loss, low quality of life, affect work and study. So now we can see the importance of healthy food. Let’s eat more healthy food and eat less fast food! Don’t forget that healthy food is good for your body and fast food is not.
]]>
+
+
+
+
+ 英语
+
+
+
+
+
+
+ 演讲稿
+
+ 纯英文
+
+ English
+
+
+
+
+
+
+
+
+ 正常,荒谬——《局外人》读后感
+
+ /posts/7b015599/
+
+ 我不是这里的人,也不是别处的人。世界只是一片陌生的景物,我的精神在此无依无靠,一切与己无关。——题记
《局外人》书中的主人公默尔索虽不能说是冷漠无情,但也是不同于常人的。对于日常起居方面而言,他和大多数人一样。但是他又和大多数人不一样,他并不习惯于使用普通人通用的情感表达方式:他不像大多数人会在母亲,一个赋予他生命、哺育其成长的人的葬礼上嚎啕大哭;而他只是沉默着,甚至心中只想着为什么不早点结束,这样才能回去睡觉。像一个局外人一般,好似任何事情都与他毫无关联。这也是书中对他的第一处道德审判,即养老院中老人对丝毫没有伤心感受的默尔索的不正常的关注。
但是这一场审判是必要的吗?我们有必要在他人的审判之下临时更改自己深信不疑的观点吗?默尔索没有这么做,所以他才没有在母亲的葬礼上哭泣,亦或者是动那么一点点情。他认为死亡原本就是一件自然而然的事情。可是恰恰是因为这样,他才违背了人们约定俗成的道德准则,也为后文中他的悲剧结局埋下了伏笔。
默尔索之后在一种不明不白的状态下以一种正当防卫的姿态杀死了一位阿拉伯人,本身可以判定减刑的事件却正是因为他的“不近人情”——默尔索对任何问题的回答都太过客观,让人感觉不到人情味——而被记者过度渲染,引起了人们对这个案件的过度关注与检察官疯狂对默尔索人格的诋毁抨击。整个过程,默尔索被排挤在外,只剩下了法官与律师、证人的接触,并且谈论的主题还不是这一起案子,而是对默尔索本人的争论,对默尔索的“不孝”的争论。人们就像约定好了一样,顺利地,没有理由地将默尔索判以死刑。
正是因为默尔索的为人处世方式才引得了人们的过分联想。而在整个案件中,几乎所有人都被一种主观的想法所引导,认为他就是一个冷漠无情的杀人犯。可是他真的是一个冷酷无情的杀人犯么?深入了解他的人,喜欢他。泛泛接触过的人却想置他于死地。他仅仅是热爱这个城市,也真正懂得享受当下的美好而已。
正如他所言,一切都“不是我的错”,可是很多事情本就是这样自然而然发生了。
直至默尔索死刑之前他才展现出了一个真实的自己——一个思念自己母亲、怀念儿的日子的人。他开始感到害怕,恐惧死亡,恐惧狱卒的脚步声,恐惧黎明…人都会死,可是大多数人都可以用五十年以上的时间来一点一点消磨这种恐惧,消磨死亡这件事。但当这五十年的恐惧,突然一下子被压缩到了一天里面,在那一天里,一个普通人会想什么呢?或许大多数人会选择寻找情感寄托吧,选择信奉了某一个神,他们通过神鬼来为自己开脱,缓解自己内心的愧疚与不安。可是默尔索依旧没有这么做,对事件始终有着理性且客观认知的他并没有相信神鬼之说。他在被判死刑后,虽然神甫仍然在不依不饶教导默尔索,可他无动于衷,甚至于愤怒、爆发了。
这本书看似是谈主人公的荒谬、不合常理,可其实是反应社会的荒谬及民众的盲目从众。而事实上,这本书中,只有所谓的局外人才是真正清醒的正常人。
]]>
+
+
+
+
+ 文学
+
+
+
+
+
+
+ 文学
+
+ 作文
+
+ 读后感
+
+ 议论文
+
+
+
+
+
+
+
+
+
diff --git a/manifest.json b/manifest.json
new file mode 100644
index 000000000..d8d51f00d
--- /dev/null
+++ b/manifest.json
@@ -0,0 +1 @@
+{"background_color":"#ffffff","description":"序炁OrderChaos的自留地","dir":"ltr","display":"standalone","name":"序炁的博客","orientation":"any","scope":"/","short_name":"序炁的博客","start_url":"/","theme_color":"#fff","categories":[],"screenshots":[],"icons":[{"src":"/img/icons/icon-72x72.png","sizes":"72x72","type":"image/png"},{"src":"/img/icons/icon-96x96.png","sizes":"96x96","type":"image/png"},{"src":"/img/icons/icon-128x128.png","sizes":"128x128","type":"image/png"},{"src":"/img/icons/icon-144x144.png","sizes":"144x144","type":"image/png"},{"src":"/img/icons/icon-152x152.png","sizes":"152x152","type":"image/png"},{"src":"/img/icons/icon-180x180.png","sizes":"180x180","type":"image/png"},{"src":"/img/icons/icon-192x192.png","sizes":"192x192","type":"image/png"},{"src":"/img/icons/icon-384x384.png","sizes":"384x384","type":"image/png"},{"src":"/img/icons/icon-512x512.png","sizes":"512x512","type":"image/png"},{"src":"/img/icons/apple-touch-icon.png","sizes":"180x180","type":"image/png"},{"src":"/img/icons/maskable_icon.png","sizes":"512x512","type":"image/png","purpose":"any maskable"}],"shortcuts":[],"splash_pages":null}
\ No newline at end of file
diff --git a/owo.json b/owo.json
new file mode 100644
index 000000000..8e9151559
--- /dev/null
+++ b/owo.json
@@ -0,0 +1 @@
+{"颜文字":{"type":"emoticon","container":[{"icon":"OωO","text":"Author: DIYgod"},{"icon":"|´・ω・)ノ","text":"Hi"},{"icon":"ヾ(≧∇≦*)ゝ","text":"开心"},{"icon":"(☆ω☆)","text":"星星眼"},{"icon":"(╯‵□′)╯︵┴─┴","text":"掀桌"},{"icon":" ̄﹃ ̄","text":"流口水"},{"icon":"(/ω\)","text":"捂脸"},{"icon":"∠( ᐛ 」∠)_","text":"给跪"},{"icon":"(๑•̀ㅁ•́ฅ)","text":"Hi"},{"icon":"→_→","text":"斜眼"},{"icon":"୧(๑•̀⌄•́๑)૭","text":"加油"},{"icon":"٩(ˊᗜˋ*)و","text":"有木有WiFi"},{"icon":"(ノ°ο°)ノ","text":"前方高能预警"},{"icon":"(´இ皿இ`)","text":"我从未见过如此厚颜无耻之人"},{"icon":"⌇●﹏●⌇","text":"吓死宝宝惹"},{"icon":"(ฅ´ω`ฅ)","text":"已阅留爪"},{"icon":"(╯°A°)╯︵○○○","text":"去吧大师球"},{"icon":"φ( ̄∇ ̄o)","text":"太萌惹"},{"icon":"ヾ(´・ ・`。)ノ\"","text":"咦咦咦"},{"icon":"( ง ᵒ̌皿ᵒ̌)ง⁼³₌₃","text":"气呼呼"},{"icon":"(ó﹏ò。)","text":"我受到了惊吓"},{"icon":"Σ(っ °Д °;)っ","text":"什么鬼"},{"icon":"( ,,´・ω・)ノ\"(´っω・`。)","text":"摸摸头"},{"icon":"╮(╯▽╰)╭ ","text":"无奈"},{"icon":"o(*////▽////*)q ","text":"脸红"},{"icon":">﹏<","text":""},{"icon":"( ๑´•ω•) \"(ㆆᴗㆆ)","text":""}]},"Heo-100":{"type":"image","container":[{"text":"Heo-100-亲亲","icon":" "},{"text":"Heo-100-再见","icon":"
"},{"text":"Heo-100-再见","icon":" "},{"text":"Heo-100-加班","icon":"
"},{"text":"Heo-100-加班","icon":" "},{"text":"Heo-100-发红包","icon":"
"},{"text":"Heo-100-发红包","icon":" "},{"text":"Heo-100-吃瓜","icon":"
"},{"text":"Heo-100-吃瓜","icon":" "},{"text":"Heo-100-吐血","icon":"
"},{"text":"Heo-100-吐血","icon":" "},{"text":"Heo-100-吵架","icon":"
"},{"text":"Heo-100-吵架","icon":" "},{"text":"Heo-100-呲牙笑","icon":"
"},{"text":"Heo-100-呲牙笑","icon":" "},{"text":"Heo-100-哈士奇","icon":"
"},{"text":"Heo-100-哈士奇","icon":" "},{"text":"Heo-100-哭泣","icon":"
"},{"text":"Heo-100-哭泣","icon":" "},{"text":"Heo-100-唱歌","icon":"
"},{"text":"Heo-100-唱歌","icon":" "},{"text":"Heo-100-喜欢","icon":"
"},{"text":"Heo-100-喜欢","icon":" "},{"text":"Heo-100-大笑","icon":"
"},{"text":"Heo-100-大笑","icon":" "},{"text":"Heo-100-头秃","icon":"
"},{"text":"Heo-100-头秃","icon":" "},{"text":"Heo-100-奋斗","icon":"
"},{"text":"Heo-100-奋斗","icon":" "},{"text":"Heo-100-害羞","icon":"
"},{"text":"Heo-100-害羞","icon":" "},{"text":"Heo-100-尴尬","icon":"
"},{"text":"Heo-100-尴尬","icon":" "},{"text":"Heo-100-开心","icon":"
"},{"text":"Heo-100-开心","icon":" "},{"text":"Heo-100-微笑","icon":"
"},{"text":"Heo-100-微笑","icon":" "},{"text":"Heo-100-思考","icon":"
"},{"text":"Heo-100-思考","icon":" "},{"text":"Heo-100-恶心","icon":"
"},{"text":"Heo-100-恶心","icon":" "},{"text":"Heo-100-惊吓","icon":"
"},{"text":"Heo-100-惊吓","icon":" "},{"text":"Heo-100-惊讶","icon":"
"},{"text":"Heo-100-惊讶","icon":" "},{"text":"Heo-100-感动","icon":"
"},{"text":"Heo-100-感动","icon":" "},{"text":"Heo-100-愤怒","icon":"
"},{"text":"Heo-100-愤怒","icon":" "},{"text":"Heo-100-我看好你","icon":"
"},{"text":"Heo-100-我看好你","icon":" "},{"text":"Heo-100-抠鼻","icon":"
"},{"text":"Heo-100-抠鼻","icon":" "},{"text":"Heo-100-捂嘴笑","icon":"
"},{"text":"Heo-100-捂嘴笑","icon":" "},{"text":"Heo-100-捂脸","icon":"
"},{"text":"Heo-100-捂脸","icon":" "},{"text":"Heo-100-擦汗","icon":"
"},{"text":"Heo-100-擦汗","icon":" "},{"text":"Heo-100-滑稽","icon":"
"},{"text":"Heo-100-滑稽","icon":" "},{"text":"Heo-100-烦恼","icon":"
"},{"text":"Heo-100-烦恼","icon":" "},{"text":"Heo-100-熬夜","icon":"
"},{"text":"Heo-100-熬夜","icon":" "},{"text":"Heo-100-爆炸","icon":"
"},{"text":"Heo-100-爆炸","icon":" "},{"text":"Heo-100-牛年进宝","icon":"
"},{"text":"Heo-100-牛年进宝","icon":" "},{"text":"Heo-100-狗头","icon":"
"},{"text":"Heo-100-狗头","icon":" "},{"text":"Heo-100-狗头围脖","icon":"
"},{"text":"Heo-100-狗头围脖","icon":" "},{"text":"Heo-100-狗头胖次","icon":"
"},{"text":"Heo-100-狗头胖次","icon":" "},{"text":"Heo-100-狗头花","icon":"
"},{"text":"Heo-100-狗头花","icon":" "},{"text":"Heo-100-狗头草","icon":"
"},{"text":"Heo-100-狗头草","icon":" "},{"text":"Heo-100-生病","icon":"
"},{"text":"Heo-100-生病","icon":" "},{"text":"Heo-100-疑问","icon":"
"},{"text":"Heo-100-疑问","icon":" "},{"text":"Heo-100-眩晕","icon":"
"},{"text":"Heo-100-眩晕","icon":" "},{"text":"Heo-100-睡觉","icon":"
"},{"text":"Heo-100-睡觉","icon":" "},{"text":"Heo-100-禁言","icon":"
"},{"text":"Heo-100-禁言","icon":" "},{"text":"Heo-100-笑哭","icon":"
"},{"text":"Heo-100-笑哭","icon":" "},{"text":"Heo-100-纠结","icon":"
"},{"text":"Heo-100-纠结","icon":" "},{"text":"Heo-100-绿帽","icon":"
"},{"text":"Heo-100-绿帽","icon":" "},{"text":"Heo-100-耍酷","icon":"
"},{"text":"Heo-100-耍酷","icon":" "},{"text":"Heo-100-被打","icon":"
"},{"text":"Heo-100-被打","icon":" "},{"text":"Heo-100-送福","icon":"
"},{"text":"Heo-100-送福","icon":" "},{"text":"Heo-100-阴险","icon":"
"},{"text":"Heo-100-阴险","icon":" "},{"text":"Heo-100-鬼脸","icon":"
"},{"text":"Heo-100-鬼脸","icon":" "},{"text":"Heo-100-鼓掌","icon":"
"},{"text":"Heo-100-鼓掌","icon":" "}]},"Bilibili":{"type":"image","container":[{"icon":"
"}]},"Bilibili":{"type":"image","container":[{"icon":" ","text":"tv_doge"},{"icon":"
","text":"tv_doge"},{"icon":" ","text":"tv_亲亲"},{"icon":"
","text":"tv_亲亲"},{"icon":" ","text":"tv_偷笑"},{"icon":"
","text":"tv_偷笑"},{"icon":" ","text":"tv_再见"},{"icon":"
","text":"tv_再见"},{"icon":" ","text":"tv_冷漠"},{"icon":"
","text":"tv_冷漠"},{"icon":" ","text":"tv_发怒"},{"icon":"
","text":"tv_发怒"},{"icon":" ","text":"tv_发财"},{"icon":"
","text":"tv_发财"},{"icon":" ","text":"tv_可爱"},{"icon":"
","text":"tv_可爱"},{"icon":" ","text":"tv_吐血"},{"icon":"
","text":"tv_吐血"},{"icon":" ","text":"tv_呆"},{"icon":"
","text":"tv_呆"},{"icon":" ","text":"tv_呕吐"},{"icon":"
","text":"tv_呕吐"},{"icon":" ","text":"tv_困"},{"icon":"
","text":"tv_困"},{"icon":" ","text":"tv_坏笑"},{"icon":"
","text":"tv_坏笑"},{"icon":" ","text":"tv_大佬"},{"icon":"
","text":"tv_大佬"},{"icon":" ","text":"tv_大哭"},{"icon":"
","text":"tv_大哭"},{"icon":" ","text":"tv_委屈"},{"icon":"
","text":"tv_委屈"},{"icon":" ","text":"tv_害羞"},{"icon":"
","text":"tv_害羞"},{"icon":" ","text":"tv_尴尬"},{"icon":"
","text":"tv_尴尬"},{"icon":" ","text":"tv_微笑"},{"icon":"
","text":"tv_微笑"},{"icon":" ","text":"tv_思考"},{"icon":"
","text":"tv_思考"},{"icon":" ","text":"tv_惊吓"}]},"bilibili热词系列":{"type":"image","container":[{"text":"bilibiliHotKey-1","icon":"
","text":"tv_惊吓"}]},"bilibili热词系列":{"type":"image","container":[{"text":"bilibiliHotKey-1","icon":" "},{"text":"bilibiliHotKey-10","icon":"
"},{"text":"bilibiliHotKey-10","icon":" "},{"text":"bilibiliHotKey-11","icon":"
"},{"text":"bilibiliHotKey-11","icon":" "},{"text":"bilibiliHotKey-12","icon":"
"},{"text":"bilibiliHotKey-12","icon":" "},{"text":"bilibiliHotKey-13","icon":"
"},{"text":"bilibiliHotKey-13","icon":" "},{"text":"bilibiliHotKey-14","icon":"
"},{"text":"bilibiliHotKey-14","icon":" "},{"text":"bilibiliHotKey-15","icon":"
"},{"text":"bilibiliHotKey-15","icon":" "},{"text":"bilibiliHotKey-16","icon":"
"},{"text":"bilibiliHotKey-16","icon":" "},{"text":"bilibiliHotKey-17","icon":"
"},{"text":"bilibiliHotKey-17","icon":" "},{"text":"bilibiliHotKey-18","icon":"
"},{"text":"bilibiliHotKey-18","icon":" "},{"text":"bilibiliHotKey-19","icon":"
"},{"text":"bilibiliHotKey-19","icon":" "},{"text":"bilibiliHotKey-2","icon":"
"},{"text":"bilibiliHotKey-2","icon":" "},{"text":"bilibiliHotKey-20","icon":"
"},{"text":"bilibiliHotKey-20","icon":" "},{"text":"bilibiliHotKey-21","icon":"
"},{"text":"bilibiliHotKey-21","icon":" "},{"text":"bilibiliHotKey-22","icon":"
"},{"text":"bilibiliHotKey-22","icon":" "},{"text":"bilibiliHotKey-23","icon":"
"},{"text":"bilibiliHotKey-23","icon":" "},{"text":"bilibiliHotKey-24","icon":"
"},{"text":"bilibiliHotKey-24","icon":" "},{"text":"bilibiliHotKey-25","icon":"
"},{"text":"bilibiliHotKey-25","icon":" "},{"text":"bilibiliHotKey-26","icon":"
"},{"text":"bilibiliHotKey-26","icon":" "},{"text":"bilibiliHotKey-27","icon":"
"},{"text":"bilibiliHotKey-27","icon":" "},{"text":"bilibiliHotKey-28","icon":"
"},{"text":"bilibiliHotKey-28","icon":" "},{"text":"bilibiliHotKey-29","icon":"
"},{"text":"bilibiliHotKey-29","icon":" "},{"text":"bilibiliHotKey-3","icon":"
"},{"text":"bilibiliHotKey-3","icon":" "},{"text":"bilibiliHotKey-30","icon":"
"},{"text":"bilibiliHotKey-30","icon":" "},{"text":"bilibiliHotKey-31","icon":"
"},{"text":"bilibiliHotKey-31","icon":" "},{"text":"bilibiliHotKey-32","icon":"
"},{"text":"bilibiliHotKey-32","icon":" "},{"text":"bilibiliHotKey-4","icon":"
"},{"text":"bilibiliHotKey-4","icon":" "},{"text":"bilibiliHotKey-5","icon":"
"},{"text":"bilibiliHotKey-5","icon":" "},{"text":"bilibiliHotKey-6","icon":"
"},{"text":"bilibiliHotKey-6","icon":" "},{"text":"bilibiliHotKey-7","icon":"
"},{"text":"bilibiliHotKey-7","icon":" "},{"text":"bilibiliHotKey-8","icon":"
"},{"text":"bilibiliHotKey-8","icon":" "},{"text":"bilibiliHotKey-9","icon":"
"},{"text":"bilibiliHotKey-9","icon":" "}]}}
\ No newline at end of file
diff --git a/page/2/index.html b/page/2/index.html
new file mode 100644
index 000000000..5ab66362a
--- /dev/null
+++ b/page/2/index.html
@@ -0,0 +1,3 @@
+序炁的博客
+
+
\ No newline at end of file
diff --git a/page/3/index.html b/page/3/index.html
new file mode 100644
index 000000000..7a284dfed
--- /dev/null
+++ b/page/3/index.html
@@ -0,0 +1,3 @@
+序炁的博客
+
+
\ No newline at end of file
diff --git a/page/4/index.html b/page/4/index.html
new file mode 100644
index 000000000..bb2cbe9d7
--- /dev/null
+++ b/page/4/index.html
@@ -0,0 +1,3 @@
+序炁的博客
+
+
\ No newline at end of file
diff --git a/page/5/index.html b/page/5/index.html
new file mode 100644
index 000000000..b10ebebd0
--- /dev/null
+++ b/page/5/index.html
@@ -0,0 +1,3 @@
+序炁的博客
+
+
\ No newline at end of file
diff --git a/posts/10824f12/index.html b/posts/10824f12/index.html
new file mode 100644
index 000000000..2ddf5c104
--- /dev/null
+++ b/posts/10824f12/index.html
@@ -0,0 +1,3 @@
+一键推流工具—— BlogPusher - 序炁的博客
+
+
"}]}}
\ No newline at end of file
diff --git a/page/2/index.html b/page/2/index.html
new file mode 100644
index 000000000..5ab66362a
--- /dev/null
+++ b/page/2/index.html
@@ -0,0 +1,3 @@
+序炁的博客
+
+
\ No newline at end of file
diff --git a/page/3/index.html b/page/3/index.html
new file mode 100644
index 000000000..7a284dfed
--- /dev/null
+++ b/page/3/index.html
@@ -0,0 +1,3 @@
+序炁的博客
+
+
\ No newline at end of file
diff --git a/page/4/index.html b/page/4/index.html
new file mode 100644
index 000000000..bb2cbe9d7
--- /dev/null
+++ b/page/4/index.html
@@ -0,0 +1,3 @@
+序炁的博客
+
+
\ No newline at end of file
diff --git a/page/5/index.html b/page/5/index.html
new file mode 100644
index 000000000..b10ebebd0
--- /dev/null
+++ b/page/5/index.html
@@ -0,0 +1,3 @@
+序炁的博客
+
+
\ No newline at end of file
diff --git a/posts/10824f12/index.html b/posts/10824f12/index.html
new file mode 100644
index 000000000..2ddf5c104
--- /dev/null
+++ b/posts/10824f12/index.html
@@ -0,0 +1,3 @@
+一键推流工具—— BlogPusher - 序炁的博客
+
+一键推流工具—— BlogPusher
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
近来无事,想着博客推流时的指令有好几条,于是决定写一个小工具简化这个流程这甚至是我第一个实用性的程序
在此之前
我的博客配置好后每次从本地推送源码的指令有四条:
1
2
3
4
| git pull origin master
git add .
git commit -m"xxxxxx"
git push origin master
|
这四条指令都在本地执行,所以每次推流都需要依次输入,而这显然是不方便的,于是我就想写一个能够自动执行这四条指令的工具。
程序设计
很简单,我们可以使用system()函数,其原型如下:
1
| int system(const char *command);
|
给函数传入字符串型的命令行参数就可以在程序中执行命令,于是很容易想到执行这三条命令的代码:
1
2
3
4
| system("git pull origin master");
system("git add .");
system("git push origin master");
|
这样除了commit提交外,其他的指令都可以自动执行。但这肯定是不完善且不可用的,因为commit的提交信息需要在git add与git push之间确定而不能在git push之后。
于是我们需要在程序中获取commit信息,这样就可以在git add之后自动执行commit提交指令。很容易我们就可以想到一种方法:
1
2
3
4
| string commit;
getline(cin, commit);
string commitInput = "git commit -m\"" + commit + "\"";
system(commitInput.c_str());
|
但我认为这样还不够简洁,我们需要的是一行可以直接推流的指令而不是一个需要用户输入的软件,所以我们需要另一种方式——获取命令行。
获取命令行
一般的c++程序中,我们的main函数都是这样定义的:
但为了获取命令行参数,我们就需要像这样定义:
1
2
3
| int main(int argc, char **argv) {
}
|
其中,argc是命令行参数的个数,argv则是一个指针数组,每个指针指向一个字符串,每个字符串是一个命令行参数。当我们执行一个可执行文件时,若是只在命令提示符中输入可执行文件的文件名,像这样:
那么argc的值就是1,而argv[0]的值就是BlogPusher,而若是在命令提示符中输入可执行文件的文件名和参数,像这样:
此时argc的值就是3,argv[0]的值仍是BlogPusher,但后面argv[1]的值则会是Update,argv[2]的值是About。
所以,我们就可以这样获取到我们需要的commit信息了。
Commit信息处理
光是获取还不够,现在我们需要处理我们获取到的参数。在刚刚的例子中,我们可以看到argv数组的分割是以空格为基础的,但commit中可以包含空格,这就使得直接使用argv[1]是不可行的。
所以,我们需要一种方法来处理commit信息,使其可以正确包含空格。其实很简单,只需要加入一个循环,每次循环获取一个字符串并把它放入字符串commit中,在每一个字符串之间加入空格即可。
1
2
3
4
5
6
7
8
| string commit;
string commit;
for(int i = 1; i < argc; i++){
commit += argv[i];
if(i != argc - 1){
commit += " ";
}
}
|
加了一个判断,使得程序不会给commit信息加入多余的空格。现在,commit信息就可以正确的包含空格了。
总结
所有程序合在一起差不多是这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| #include <iostream>
using namespace std;
int main(int argc, char** argv){
string commit;
for(int i = 1; i < argc; i++){
commit += argv[i];
if(i != argc - 1){
commit += " ";
}
}
string commitInput = "git commit -m\"" + commit + "\"";
system("git pull origin master");
system("git add .");
cout<<"git add success"<<endl;
system(commitInput.c_str());
system("git push origin master");
return 0;
}
|
编译,放入博客源码文件夹下。注意此时不要忘记在.gitignore中添加一行blogpusher.*,防止git上传时上传blogpusher文件。
在命令提示符中输入blogpusher Update .gitignore,测试一下,非常完美!
最后优化一下,差不多像这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| #include <iostream>
using namespace std;
int main(int argc, char** argv){
string commit;
for(int i = 1; i < argc; i++){
commit += argv[i];
if(i != argc - 1){
commit += " ";
}
}
string commitInput = "git commit -m\"" + commit + "\"";
cout<<"==========BEGIN PULL=========="<<endl;
system("git pull origin master");
cout<<"==========BEGIN ADD=========="<<endl;
system("git add .");
cout<<"git add success"<<endl;
cout<<"==========BEGIN COMMIT=========="<<endl;
system(commitInput.c_str());
cout<<"==========BEGIN PUSH=========="<<endl;
system("git push origin master");
return 0;
}
|
大功告成!
题外话
这个东西很早就想做了的说…现在做出来了还是十分欣慰。
程序已经开源到了github,欢迎查看。若是帮到了您的话,麻烦点个star,谢谢。
一键推流工具—— BlogPusher
https://www.ordchaos.com/posts/10824f12/
Hexo 通过 GitHub Action 自动部署到云虚拟主机
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
购买了十年之约的优惠价硅云虚拟主机用于加速访问,记录一下部署过程。
前提条件
你需要已经配置好了GitHub Action的Hexo自动部署,若是没有,推荐观看以下文章:
这里就不讲了。
编辑Action
打开(本地博客仓库目录)/.github/workflows/(Action配置文件).yml,在最后添加:
1
2
3
4
5
6
7
8
9
| - name: Deploy Files on Ftp Server
uses: SamKirkland/FTP-Deploy-Action@4.3.0
with:
server: (FTP服务器地址)
username: (FTP用户名)
password: (FTP密码)
local-dir: ./public/
server-dir: (FTP服务器文件目录)
port: (FTP服务器端口,一般是21)
|
将括号及内部内容换成自己的信息即可。
这里的方法是使用ftp来上传文件到虚拟主机,是对于所有虚拟主机而言最通用的一种方式了。./public是Hexo默认的静态文件生成本地地址,无需更改。
最后推流到GitHub即可使用。
题外话
本来以为挺复杂,结果就这么点。
最开始使用的是hexo-deployer-ftpsync插件,结果却根本无法正常使用,于是便转为使用docker镜像。
对了,如果有兴趣购买硅云的主机,那请帮个小忙,用我的邀请链接注册吧:邀请链接
那就这样,886
Hexo 通过 GitHub Action 自动部署到云虚拟主机
https://www.ordchaos.com/posts/1e44a102/
《梁启超传》读后感
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
在这个暑假中,我读了由梁启超学生吴其昌著作的《梁启超传》,这本书也是作者的绝笔之作。在其去世前的一个月,作者便应邀开始写这一本书,但在他完成书的上卷后便不幸身亡,年仅四十岁,同时留下了这本未完稿的《梁启超传》。这本传记虽然仅有五万字,但是阅读者可以很明显的发现作者吴其昌很完美的继承了其老师梁启超“笔锋常带感情”的特质。作者与梁启超一样,感性的思维较强,喜欢用感性的一面来描述事物,感知事物。
梁启超生于一八七三年二月二十三日,字卓如,号任公。清朝光绪年间举人,是中国近代思想家、政治家、教育家、史学家、文学家,也是戊戌变法(百日维新)领袖之一、中国近代维新派、新法家代表人物。
而梁启超生活的时代,正是中国人明最困苦的一段时期。那既是清朝末年,也是我国封建社会的末世。内忧外患,乱象毕现,用作者的话来说,就是“堕入地狱的底层”。然而最可悲的还不在此,而在于当时道德的堕落、思想的颠倒和民智的固陋,堕入地狱的底层而不自知,“哀莫大于心死”!中国从一八四二年到一九四三年这一百年的命运,是“从乐土跌到地狱,又从地狱爬会乐土”是“一个四千年历史上从未有的大转折期”。生活在这个时代的稍有血性的国民看着一个又一个的不平等条约的建立与实施都想“蹈东海而自杀”,比如陈天华。而梁启超,是一个成长在这个最黑暗的地狱底层的有血有泪有志气的满身创伤的青年。他对于中国复兴有着坚定不移的信心,所以他没有去蹈东海,而是在“全然无望”中拼命奋斗、挣扎。只是他到死都没有见到中国再度统一的一天。他的眼前没有希望,但心中却充满了希望与斗志。他师从康有为,发动戊戌变法,创学会,办报纸,达到了其政治生涯的顶峰。然而,就像梁启超后来所说的那样:“戊戌维新之可贵,在精神耳”,戊戌变法是一次及其不彻底的改革,依靠的是无能的光绪帝,只是雷声大雨点小的实行了一百多天,就被慈禧太后为首的封建顽固势力所扼杀。“我欲望鲁兮,龟山蔽之。手无斧柯,奈龟山何!”但全书就这样戛然而止,原因我们都知道了。可就算如此,读完后却仍然令人愤慨与惋惜。
现在看看梁启超本人与现在的社会,会发现虽然中国早已统一,但是却缺乏了梁启超的奋斗的心。这个社会,比起梁梁启超当年所处的,自然要文明、要繁盛得多,可依然存在着不公与不善。为纠正这些不公,惩治这些不善,依然有可能要付出惨重的代价。在风险面前,很多人却望而却步,勇往直前的人是有的,但是因为现状的安稳,这些人正在慢慢减少。所以梁启超赴汤蹈火救国的精神在任何一个时代都不会落后。
梁启超是清末维新运动的领袖之一,是近代资产阶级改良主义者;也是提倡诗界、小说界革命的新文化传播者。戊戌变法失败后,他逃亡日本,虽曾和孙中山联系商议合作,但因为他的老师师康有为所制止,从而做了保皇党,也就是拥护皇帝的一批人的其中之一。辛亥革命之后,他谋位于军阀之中,将自己的旗帜插在了反动派的阵营之中而反对革命,晚年时尤其犹反对共产党。对于他在政治上的反动观点与反动行为当然是应当制止的,可是他的护国、爱国的精神与为国赴汤蹈火的精神,我们这个时代是需要的,这种精神在这个时代也是缺乏的。
一九二九年一月十九日,梁启超在北京协和医院溘然长逝,享年五十六岁。
附一张(参考意义不大的)思维导图:
《梁启超传》读后感
https://www.ordchaos.com/posts/1e617f9e/
全站 webp 自动切换,加速访问好帮手
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
原本博客用的都是普通图片,就算有懒加载,一堆圈圈一起转也惹人心烦。现在改为了原图/webp的自适应切换,效果好上不少。
前期准备
首要任务是拿到webp格式的图片,这个看自己。像我用的vps上的Lsky Pro,本地存储。有高性能vps可以试试用Webp-Server配合。但我的轻量应用承受不起,遂作罢。改为了定时shell脚本,一分钟触发一次:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| #!/bin/bash
find . -type f -iname "*.png" | while read file; do
if [ ! -f "${file%.*}.webp" ]; then
cwebp -q 85 "$file" -o "${file%.*}.webp"
fi
done
find . -type f -iname "*.jpg" | while read file; do
if [ ! -f "${file%.*}.webp" ]; then
cwebp -q 85 "$file" -o "${file%.*}.webp"
fi
done
find . -type f -iname "*.jpeg" | while read file; do
if [ ! -f "${file%.*}.webp" ]; then
cwebp -q 85 "$file" -o "${file%.*}.webp"
fi
done
find . -type f -iname "*.tif" | while read file; do
if [ ! -f "${file%.*}.webp" ]; then
cwebp -q 85 "$file" -o "${file%.*}.webp"
fi
done
|
脚本运行时会遍历自己所在的文件夹及其子文件夹,转换所有没有对应webp格式的图片(png,jpg、jpeg与tiff)为webp图片(原图还在,放心)。
这段脚本中使用了cwebp指令,它来源于libwebp。安装可以参考下方:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # 安装编译器以及依赖包
yum install -y gcc make autoconf automake libtool libjpeg-devel libpng-devel
# 请到官网下载最新版本,版本列表:https://storage.googleapis.com/downloads.webmproject.org/releases/webp/
wget https://storage.googleapis.com/downloads.webmproject.org/releases/webp/libwebp-1.2.4.tar.gz
# 解压
tar -zxvf libwebp-1.2.4.tar.gz
# 进入目录
cd libwebp-1.2.4
# 源代码安装环境检查
./configure
# 编译
make
# 安装
make install
|
安装过程中遇到问题请善用百度/Google,本人不对此负责(bushi
做好以上所有工作后,就可以开始下面的内容。
Service Worker
安装
不知道是什么、如何部署的,可以看看CYF大佬的这两篇文章:
如果你已经部署了Service Worker就可以继续了。
脚本
添加一个监听器,监听fetch事件:
1
2
3
| self.addEventListener('fetch', async event => {
});
|
(或者在本来的监听器里面加上)
然后判断流量是否是对图站的请求,可以用一个if来判断:
1
2
3
4
| if(event.request.url.indexOf('your.image.site') !== -1) {
var requestUrl = event.request.url;
}
|
event.request.url是请求的地址,用indexOf()方法来判断地址中是否包含图站地址,若不反回代表没有的-1即为是对图站的请求。
接下来判断浏览器是否支持webp图片,定义一个变量supportsWebp
1
2
3
4
5
6
| var supportsWebp = false;
if (event.request.headers.has('accept')){
supportsWebp = event.request.headers
.get('accept')
.includes('webp');
}
|
如果可以获取到浏览器的Accept头,且头中包含image/webp,即为支持webp,否则为不支持。
然后就可以进一步处理了,若浏览器支持webp,则进行下一步:
1
2
3
4
5
6
| if (supportsWebp) {
}
else {
console.log("[SW] Don't support webp image, skip " + requestUrl + " .");
}
|
然后获取请求的文件类型。最开始的脚本只支持png,jpg、jpeg与tiff这四种格式的图片,所以我们也只能篡改这四种格式图片的请求到webp图片上:
1
2
3
4
5
| var imageUrl = requestUrl.split(".");
if(imageUrl[imageUrl.length - 1] === 'jpg' || imageUrl[imageUrl.length - 1] === 'tif' || imageUrl[imageUrl.length - 1] === 'png' || imageUrl[imageUrl.length - 1] === 'jpeg') {
var newUrl = requestUrl.replace(imageUrl[imageUrl.length - 1], 'webp');
}
|
newUrl中存储了新的请求地址,接下来对它发起请求即可:
1
2
3
| var newRequest = new Request(newUrl);
event.respondWith(fetch(newRequest));
console.log("[SW] Redirect " + requestUrl + " to " + newUrl + " .");
|
当请求完成并图片被完整下载以后,进行缓存,代码如下:
1
2
3
4
5
6
7
8
9
10
| event.waitUntil(
fetch(newRequest).then(function(response) {
if (!response.ok) throw new Error("[SW] Failed to load image: " + newUrl);
caches.open(CACHE_NAME).then(function(cache) {
cache.put(newRequest, response);
});
}).catch(function(error) {
console.log(error);
})
);
|
若获取失败则提示,成功则缓存。
最后,要打断之前的请求,避免降低速度,可以调用event.stopImmediatePropagation()方法打断原始请求。
最后完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| if(event.request.url.indexOf('img.ordchaos.com') !== -1) {
var requestUrl = event.request.url;
var supportsWebp = false;
if (event.request.headers.has('accept')){
supportsWebp = event.request.headers
.get('accept')
.includes('webp');
}
if (supportsWebp) {
var imageUrl = requestUrl.split(".");
if(imageUrl[imageUrl.length - 1] === 'jpg' || imageUrl[imageUrl.length - 1] === 'tif' || imageUrl[imageUrl.length - 1] === 'png' || imageUrl[imageUrl.length - 1] === 'jpeg'){
var newUrl = requestUrl.replace(imageUrl[imageUrl.length - 1], 'webp');
var newRequest = new Request(newUrl);
event.respondWith(fetch(newRequest));
console.log("[SW] Redirect " + requestUrl + " to " + newUrl + " .");
event.waitUntil(
fetch(newRequest).then(function(response) {
if (!response.ok) throw new Error("[SW] Failed to load image: " + newUrl);
caches.open(CACHE_NAME).then(function(cache) {
cache.put(newRequest, response);
});
}).catch(function(error) {
console.log(error);
})
);
event.stopImmediatePropagation();
return;
}
}
else {
console.log("[SW] Don't support webp image, skip " + requestUrl + " .");
}
}
|
你学会了吗?
测试
进入网站,若一切正常,当加载到一张图片时,控制台(F12打开)会提示[SW] Redirect https://your.image.site/path/to/img.png to https://your.image.site/path/to/img.webp .这样的信息。
要测试无webp支持的情景,则点击右上角的三个点。
选择更多工具,找到“渲染”并点击。
勾选“停用webp”即可。
此时,加载图片时会提示[SW] Don't support webp image, skip https://your.image.site/path/to/img.png .
可以试试我这里的这张图片:
若浏览器支持webp则会显示Webp Accept!,否则为Webp Reject!This is a jpg file.
题外话
刚刚放寒假,舒坦。
但与之对应,九上已经结束,还有一学期就中考。。。
加油!我可以的!
那就这样,886!
全站 webp 自动切换,加速访问好帮手
https://www.ordchaos.com/posts/23e22de2/
Picgo ,我 ...... 我 ......
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
如题,我要被这个神仙软件气死了。
起因
准备装unity写个游戏,学一学C#,然后就发现C盘爆满飘红。用SpaceSniffer看了一下——好家伙!
Picgo的日志文件,占了我58.6GB.
解释
当Picgo上传图片失败时就会开始疯狂写日志,然后文件大小就爆炸。
解决
删掉日志,从组策略里设置一下日志文件大小限制就好了。
可以参考这个:如何在Windows10系统设置日志文件的最大大小
题外话
就离谱!!!
Picgo ,我 ...... 我 ......
https://www.ordchaos.com/posts/28b74a2d/
《梁启超传》议论文素材积累
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
与之前那一篇一样是暑假的语文作业,也是对这本书全本的分节概括以及议论文的素材积累,外加上对应适用的议论文题材。
第一章 一世纪以来中国的命运——从鸦片战争至梁氏诞生的前夕
第一节 绪说
梁启超生在中国近代最悲惨的100年(1842-1943)年中,虽屡次想跳海自尽,但仍坚决地相信中国必然不亡且断然复兴,所以他才在全然无望中挣扎奋斗。
作文:坚持、毅力、精神
第二节 梁氏生前中国一般的惨况
《奴才好》中足以令人怒发冲冠的描写在当时黑暗社会的情境下甚至不被人认为是严重的怪象。
慈禧太后奢靡无度,倾尽全国财力为自己所用,掏空了国库,令全中国上下不得安宁。
清末国家机构的腐败,如“外交部”(总理衙门)工作人员甚至无法分清澳门与澳洲。
清末军队素质极差,上下组织腐败,不能防国,只能累民。
清末经济建设几乎毫无成效,只因“官与民争”就扩大为了导致清朝覆灭的致命伤。
作文:珍惜、强国、学习
第三节 梁氏生前中国一般的教育状况
清末满朝士大夫都有一种目中无人的气势,自觉这清朝乃是天下第一。
清末全国几乎没有半个学校的教育,教导孩子不去烟馆、青楼而在家里抽大烟、挑“丫头”都成为了“教子有方”。
清末文人及有志青年深受八股文之害,令八股文成为活埋青年的天坑。
清末人民对“洋”存在极深的偏见,如官办“洋学堂”都十分遭人唾弃,只能拉到一批不三不四的学生。校内不教德育、爱国,而只是学习西方下等人的恶俗。
作文:环境、强国、学习
第四节 梁氏后来对于祖国命运的影响
作文:坚持、偶像、伟人
第二章 亡国现象与维新初潮——从梁氏诞生至戊戌政变
第五节 综叙
1873年,梁启超出生。此时近代伟人俱全,又冲破了鸦片战争以来中国所带之枷锁,正是突破了低于底层的黑暗,看见天际的一缕祥光。
作文:努力、坚持、时代
第六节 亡国现象的种种——梁氏生后的中国惨况
梁启超出生之后的中国同样是战争不断,且更偏向于内乱。
此时国际形势大好,西方列强都成为了天之骄子,合力来对付中国一国,令中国无辜受到车裂及凌迟之刑。
日本对中国早有图谋,在其只是一个弹丸之地的效果时就已经企图占据朝鲜与中国,且当时日本名士几乎都有着不一的“吞华论”。
作文:毅力、黑暗、光明、社会、时代
第七节 梁氏幼年的家庭生活及家乡环境
作文:爱国、强国、富国、伟人、偶像
第八节 康梁会接
作文:智慧、计划、学习
第九节 梁氏独立事业的开始
梁启超脱胎于长兴学社创立新学。在这样一种不拘形式而朝气蓬勃的学风之下,造就出了许多具有新思想人才,当时一般的学生只有四十人,而五分之二都成为了革命先烈或开国名人。
梁启超创学会启发心智,推行维新,学会中政治性质强大。在戊戌八月政变失败之后,所有的学会都秘密含有了革命的使命,与前期的学会性质有根本上的不同。
梁启超为推行维新而创办报纸。此时,他已明白,学校、学会、报纸是三位一体互相为用的,缺一不可。所以,在北京办学会的时候,他就已经开始办报。这是梁启超生平新闻事业开始的第一章,也是近代中国有正式意义的新闻开始的第一页。
作文:智慧、方法、强国
第三章 维新的失败与革命的成功
第十节 促成戊戌变法的原因
外因-远因:清政府的闭关锁国政策、杀沙俄实力的突飞猛进、列强对中国的围攻、洋务运动的失败。
外因-近因:日本民治维新的胜利、甲午战争失败的国耻、中国被蚕食的痛苦、防止陷入土耳其不变法而衰弱的覆辙。
内因-远因:清政府长期积累政治恶习的崩溃、满族战斗能力与战斗意识的降低、太平天国运动后实际政权的转移、以慈禧太后为核心的宫廷政变。
内因-近因:慈禧太后与皇帝权力的争夺、满族嫉妒汉族情感的具象化、孙中山先生领导的革命运动的激进,国内舆论更加倾向于维新。
由于以上这十六点各种各样的原因,到戊戌年间维新运动已成瓜熟蒂落的现象,除了冥顽无耻,卖身求荣的少数败类以外,几乎所有人都是渴望政治改革有如甘霖一般。
作文:强国、因果、历史
第十一节 戊戌政变史剧的绘影
戊戌变法的规模既不如日本明治维新,就连康有为公车上书的内容也还有千里之差。但就算只是这样,对于当时的清政府而言,也已经算是大刀阔斧了,此时正是光绪帝把皇威发扬到顶点的时候。
光绪帝想趁着改革的机会罢免几个守旧的大臣,但这些顽固的大臣转而向“老佛爷”求助,于是慈禧太后勃然大怒,将光绪帝囚禁而自己垂帘听政,在实际上掌握了清政府的权力。
康有为、梁启超等“小人”“大逆”受“可恶透顶”的“洋鬼子”的保护,躲开了慈禧太后的清算。其中,谭嗣同本来由日本严密保护,但却自己重新自动出来,愿抛头颅以改造祖国百年的命运。如此的忠与侠实属罕见,也值得我们敬佩。
作文:强国、历史、光明、黑暗、方法
第十二节 政变失败原因的解析
清政府内部早已腐朽不堪,全国大权都在慈禧太后之手,而满人的猜疑程度又大到难以想象,更是有许多守旧的大臣。变法本就是一个不可能完成的任务。
康有为虽然魄力强大、精神勇猛、感情丰富、毅力坚韧,但他同样心胸不广、态度傲慢、个性执拗、理智不强、做事无序、缺乏科学训练、不求上进、所学太杂而不适用其时代,却反而骄然不惭,自谓贯通天地人。
满人生来仇视汉人,排挤汉人,甚至在百维新期间出现了满洲人所谓闹鬼的趣事。在这样的排挤、压迫、攻击之下,维新救国、变法图强本就是一个荒唐的幻想。
一些守旧分子自满于既得利益而不愿其被损伤分毫,故而极力阻挠变法。
作文:方法、强国、历史、革命、国庆
《梁启超传》议论文素材积累
https://www.ordchaos.com/posts/2f728g0f/
船新说说页面—— Memos 初体验
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
博客的说说真的是一波三折…
最开始用的是HexoPlusPlus的说说,很好用也很流畅小巧,但是自Hpp停止开发后就用不了了。
然后改用了bber,也很不错,但是辣鸡腾讯云也是离谱,好好的羊毛突然就不让薅了,同时我的twikoo也被迫迁移到了vercel,只得抛弃。
中途也用过别的说说系统,比如说大名鼎鼎的Artitalk亦或者是iSpeak等等,但是都不太满意,而后因为各式各样的原因放弃。
本来我会一直被这玩意困扰…现在不会了!只因为我发现了它——Memos
开源,私有部署,这不就是我要的完美的说说系统吗?!
后端部署
很简单,首先你要有一台vps,然后装上docker.
随后一句指令即可搞定:
1
| docker run -d --name memos -p 5230:5230 -v ${PWD}/.memos/:/var/opt/memos neosmemo/memos:latest
|
随后Memos就会被部署到5230端口,觉得不方便也可以反向代理,这个教程有很多,这里就不写了。
前端
单页
可以看看我的:说说
样式完全是自己写的…你知道对一位学C++的初三学生而言css是什么东西吗?!好吧随便写写也不算难
js来自immmmm,稍微改了一点点,可以在这里看看被压缩了根本看不了。
总体而言,如果你也想要部署一个和我完全一样的页面,可以用以下html代码:(记得下载js文件)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| <div class='memo-nums'>
<p class='note note-info memo-nums-text'>
共有 <span id='memonums'>「数待载之」</span> 条说说
</p>
</div>
<div id="bber"></div>
<script type="text/javascript">
var bbMemos = {
memos : 'https://memos.ordchaos.top/',
limit : '',
creatorId:'1' ,
domId: '',
}
</script>
<script src="//jsd.ordchaos.top/marked/marked.min.js"></script>
<script src="/js/talk.js"></script>
|
注意这里用了Tag插件,如果用不了记得改改。
首页轮播
这个就比较简单了,直接在主题的index.ejs里加上以下代码即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| <p class='note note-info memo-nums-text'>
<i class="iconfont icon-speakernotes"></i><span id="memos-index-space"> </span><span id='memos-t'>首页说说轮播加载中...</span>
</p>
<script src="/js/lately.min.js"></script>
<script>
let jsonUrl =
"https://memos.ordchaos.top/api/memo?creatorId=1&rowStatus=NORMAL" +
"&t=" +
Date.parse(new Date());
fetch(jsonUrl)
.then((res) => res.json())
.then((resdata) => {
data = resdata.data,
resultIndexMemos = new Array(data.length);
for (var i = 0; i < data.length; i++) {
var talkTime = new Date(
data[i].createdTs * 1000
).toLocaleString();
var talkContent = data[i].content;
var newtalkContent = talkContent
.replace(/```([\s\S]*?)```[\s]*/g, " <code>$1</code> ")
.replace(/`([\s\S ]*?)`[\s]*/g, " <code>$1</code> ")
.replace(/<iframe([\s\S ]*?)iframe>[\s]*/g, "📺")
.replace(/\!\[[\s\S]*?\]\([\s\S]*?\)/g, "🌅")
.replace(/\[[\s\S]*?\]\([\s\S]*?\)/g, "🔗")
.replace(
/\bhttps?:\/\/(?!\S+(?:jpe?g|png|bmp|gif|webp|jfif|gif))\S+/g,
"🔗"
);
if(newtalkContent.length > 25) {
newtalkContent = newtalkContent.substring(0, 25) + '...';
}
resultIndexMemos[i] = `<span class="datetime">${talkTime}</span>: <a href="https://www.ordchaos.com/talk/">${newtalkContent}</a>`;
}
});
var i = 0;
setInterval(function () {
document.getElementById("memos-t").innerHTML = resultIndexMemos[i];
window.Lately && Lately.init({ target: ".datetime" });
i++;
if(i == resultIndexMemos.length) i = 0;
}, 3000);
</script>
|
Tag仍然是不能用就记得改。代码来自eallion,仍然是改了一下原本的逻辑怎么看怎么怪好吧也可能是我没看懂——总而言之,无意冒犯。
javascript总算是好些那么一点点,起码与c++还有那么一点像,外加上自己写GDScript的经验,稍稍改点也不算难事改了一小时
效果
自己去看看不行吗,动动手指的事
题外话
前前后后搞了半个月了,终于是在学习的闲暇时间整完,中途也是收获良多。
那就这样,886!
船新说说页面—— Memos 初体验
https://www.ordchaos.com/posts/3386e07f/
学习笔记——二叉树
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
二叉树binary tree,BT
介绍
- 一种特殊的树形结构,是度数为2的树。即二叉树的每个节点最多具有两个子节点,每个节点的字节点分别称为左孩子、右孩子,子树则为左子树,右子树。
- 二叉树可以为空且一定有序。
- 在二叉树的第i层上至多有2i个节点(i>=0)。
- 深度为m的二叉树上至多有1−21−2m+1=2m+1−1个节点(m>=0),一棵深度为m且有2m+1−1个节点的二叉树被称为满二叉树。
- 每一个节点都与深度为m的满二叉树中编号为1~n的节点一一对应的深度为m,有n个节点的二叉树被称为完全二叉树。
- 对于任意一棵二叉树,若其有n0个叶节点,n2个度为2的节点,则一定有n0=n2+1。
- 具有n个节点的完全二叉树的深度是floor(log2n)。
- 在有n个节点的完全二叉树中,对于编号为i的节点:
- 若i=1,则其无父节点,为根节点,否则其父节点编号为floor(2i)。
- 若2i>n,则i为叶节点,否则其左孩子的编号为2i。
- 若2i<n<2i+1,则i无右孩子,否则其右孩子的编号为2i+1。
如下图即二叉树示意图:
存储结构
单链表结构
1
2
3
4
5
6
7
| struct node {
int data;
node* lc, rc;
};
struct bt {
node* root;
}t;
|
与树一样,其实就是孩子表示法。
双链表结构
1
2
3
4
5
6
7
8
| struct node {
int data;
node* lc, rc;
node* father;
};
struct bt {
node* root;
}t;
|
同理,其实就是父亲孩子表示法。
遍历
- 先序遍历(输出->左孩子->右孩子)
- 中序遍历(左孩子->输出->右孩子)
- 后序遍历(左孩子->右孩子->输出)
普通树转二叉树
- 对于每一个节点,去除除最左边的树枝之外的所有树枝。
- 从最左边的节点开始,依次次将同层的每个兄弟节点横向相连。
- 以根节点为中心,将图形顺时针旋转约45°。
如下图所示:
树的计数
具有n(n>=1且n为整数)个节点的二叉树的种类的数量可以用下方的函数来表示:
f(n)={∑i=0n−1f(i)⋅f(n−i−1)1(n>1)(0⩽n⩽1)
题外话
这是第二篇学习笔记,上一篇可以点击这里查看。
学习笔记——二叉树
https://www.ordchaos.com/posts/340b325e/
自托管 E-mail ,宝宝喜欢妈妈爱
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
本来一直在用阿里云的企业邮箱,但感觉总是不太好,主要每次都需要进https://qiye.aliyun.com登录。于是趁着黑色星期五RackNerd的优惠,搞了一台vps来搭电子邮局(如果你想搭建,请确认服务器是否支持rDNS以及是否开启25端口)。
配置如下(年付$10.28)
| 硬件 | 配置 |
|---|
| CPU | 1核 |
| RAM | 768MB |
| SSD | 10GB |
| 流量 | 1TB |
还是比较磕碜的,不过价格在这,无所谓了。
经历
首先,我需要为vps开通rDNS记录到mx.ordchaos.com上。后台可以自主设置,很方便…
好,很好,我沉得住气。发个工单问一下:
哦!原来如此!好的,继续交流后,rDNS设置成功,但然而我却发现无法访问?!一番探查之后,发现这样一个事实——被墙啦!
于是只得继续发工单:
终于搞定。
Mailu.io部署
设置主机名
在vps的bash中输入:
在其中具有服务器ip地址的一行中,将后面的内容改为(假设你的域名是example.com,服务器ip是88.88.88.88):
1
| 88.88.88.88 mx.example.com mx
|
编辑好后,在vps中执行:
1
2
| echo "mx" > /etc/hostname
hostname -F /etc/hostname
|
这样就设置好了主机名,可以通过hostname命令确认是否设置成功:
前者只会输出mx,后者则会输出mx.example.com。如果不是,那就是设置错了。
设置DNS解析
去你的域名DNS解析服务商,设置以下DNS解析(假设你的域名是example.com,服务器ip是88.88.88.88):
然后去vps服务商,设置rDNS(或者叫做PTR)解析,将88.88.88.88解析到mx.example.com
获取配置
访问Mailu.io的配置生成网页:https://setup.mailu.io
写文时最新版本为1.9,保持不变。下方部署方式选择Compose.
最后,你会看到如下界面:
照着界面的指示,回到vps执行指令:
然后回到刚刚的页面,下载配置文件:
1
2
| wget http://setup.mailu.io/1.7/file/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/docker-compose.yml
wget http://setup.mailu.io/1.7/file/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/mailu.env
|
最后执行(假设你的域名是example.com,密码设置为PASSWORD):
1
2
| docker-compose -p mailu up -d
docker-compose -p mailu exec admin flask mailu admin admin example.com PASSWORD
|
就安装完成了。
配置
在浏览器中访问https://mx.example.com登录您的管理员面板:
使用账号admin@example.com和密码PASSWORD登录即可(假设你的域名是example.com,密码设置为PASSWORD)。
然后点击左侧的“邮件域”:
然后点击如下的按钮:
在新界面中点击“生成密钥”,然后复制dkim配置:
1
| dkim._domainkey.example.com. 600 IN TXT "v=DKIM1; k=rsa; p=xxxxxxxxxxxxxxxxxxxxxxxxxxxx" "xxxxxxxxxxxxxxxxxxxxxxxxxxxx"
|
进行域名解析即可。
创建账号
邮件域>用户>添加用户,按需配置即可。
使用
退出管理员账号,访问https://mx.example.com/webmail,登录即可(选择“登录Webmail”)。
测试
在MailTester上可以进行测试,如下是我测试结果:
很完美了,对吧(
以前没有超过8过
题外话
完成了很久以前的夙愿。
欢迎跟着做一遍哦!也欢迎提问!
自托管 E-mail ,宝宝喜欢妈妈爱
https://www.ordchaos.com/posts/3b90dbec/
【不建议】免费 s3 桶——棱束链联盟
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
小品牌,无法保证SLA,故不再推荐。本站图片现已全部转移到阿里云oss。
我是在B站看到棱束链的宣传视频的,点进官网就看见了棱束链联盟的广告。想着免费嘛,就申请了一下。效率还不错,第二天就通过了。现在博客的图片就放在上面,感觉速度不错,至少比之前的blackbaze+cloudflare要快。
申请
很简单,首先进入官网棱束链,在顶栏上点击产品,选择棱束链联盟。
然后就抵达了申请页面:
填写表单,按要求在网站底部加入棱束链提供的Logo,比如我的:(可以自己在网站底部看看)
提交表单,等着就可以了。
如果申请了就记得看一看自己提供的邮箱,通过了就会发邮件通知你。我的话第二天早上就发现通过了,处理速度还是不错的。给到了我10G的空间与20G的流量,诚意很足。
之后进入控制台,点击对象存储,再创建存储桶就可以使用了。
PicGo配置
PicGo作为一个图片上传工具是非常不错的,拓展性很高。同时作为一款开源软件,其发布在了GitHub上。这里默认已经安装完成了PicGo。
安装S3桶插件
打开PicGo,点击“插件设置”,在搜索框中搜索“s3”,安装第一个就可以了:
我这里安装过了,所以就显示的是“已安装”。这个插件支持所有s3桶,比如之前的b2以及这个棱束链。
获取配置信息
secretID与secretKey
进入棱束链的控制台,点击个人中心,在“功能设置”中开启API并记下secretID与secretKey,若是忘了就只能重新获取。
桶地域信息
前往存储桶列表,点击桶右侧的“配置”按钮,记下“桶信息”卡片中的地域与端点信息即可。
注意,这里的桶一定要是公开桶!
配置PicGo图床
点击图床设置-AmazonS3,填写对应参数即可,大致如下:
- 应用密钥ID:上述获取到的secretId
- 应用密钥:上述获取到的 secretKey
- 桶:上述存储桶的名字
- 权限:public-read(桶权限,公共读)
- 地区:上述获取到的地域
- 自定义节点:上述获取到的端点
- 文件路径:{year}/{month}/{md5}.{extName}(默认上传到桶的文件路径,格式如下:)
| 格式 | 描述 |
|---|
{year} | 当前日期 - 年 |
{month} | 当前日期 - 月 |
{day} | 当前日期 - 日 |
{fullName} | 完整文件名(含扩展名) |
{fileName} | 文件名(不含扩展名) |
{extName} | 扩展名(不含.) |
{md5} | 图片 MD5 计算值 |
{sha1} | 图片 SHA1 计算值 |
{sha256} | 图片 SHA256 计算值 |
然后点击“设为默认图床”并确定即可,之后只需要在“上传区”页面就可以一键上传图片并复制链接了。
题外话
文章部分参考官方文档。
这篇博文不是广告,只是想大家都可以薅一把羊毛并水一篇博文(逃
那就这样,886。
【不建议】免费 s3 桶——棱束链联盟
https://www.ordchaos.com/posts/46d2370f/
三角形覆盖正方形的研究
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
命题
如图1.0.1,等腰三角形GCD与正方形ABCD共边CD;CG、DG分别交AB于点E、点F. 则问不断增加等腰三角形GCD的高,能否使等腰三角形GCD完全覆盖住正方形ABCD?
证明/证伪
设正方形边长为a,三角形GCD的高为x,四边形EFCD的面积为y
方法一
∵ABCD是正方形∴∠A=∠B=90°,AB⊥AC于点A且⊥BD于点B,AB//CD∴△AEC与△BFD都是直角三角形,其中∠A=∠B=90°,且△GCD∽△GEF又∵三角形GEF的高是(x−a),三角形GCD的高是x∴EF:CD=(x−a):x∴EF=CDxx−a=xa(x−a)=xax−a2=a−xa2∴AE=BF=21(AB−EF)=21[a–(a−xa2)]=2xa2∴tan∠BDF=tan∠ACE=ACAE=BDBF=a2xa2当△GCD完全覆盖正方形ABCD时,有∠GDC=∠GCD⩾90°当∠GDC=∠GCD=90°时,tan∠BDF=tan(90°−∠GDC)=tan∠ACE=tan(90°−∠GCD)=tan0°=0∴ACAE=BDBF=a2xa2=0∴2xa2=0,a2=0,a=0此时原式不成立,所以等腰△GCD不能完全覆盖住正方形ABCD当∠GDC=∠GCD>90°时,有∠GDC+∠GCD>180°∵三角形内角和为180°∴此时GCD不是三角形,不符合题设,所以等腰△GCD不能完全覆盖住正方形ABCD综上所述,等腰△GCD不能完全覆盖住正方形ABCD
方法二
∵ABCD是正方形∴AB//CD∴△GCD∽△GEF,四边形EFCD是梯形又∵△GEF的高是(x−a),△GCD的高是x∴EF:CD=(x−a):x∴EF=CDxx−a=xa(x−a)=xax−a2=a−xa2∴S梯形EFCD=21AC(EF+CD)=21[a(a−xa2)+a]=21a(2a−xa2)=a2−2xa3若要让等腰△GCD完全覆盖住正方形ABCD,则显然有S梯形EFCD=S正方形ABCD于是可得a2=a2−2xa3,则2xa3=0,故a3=0,a=0此时原式无意义,所以等腰△GCD不能完全覆盖住正方形ABCD
综上所述,等腰三角形GCD无法完全覆盖住正方形ABCD.
推广
从方法二的证明过程中,可以发现三角形GCD可以不是等腰三角形,此时结论依旧成立。所以我们有真命题:在图1.0.1中三角形GCD无法完全覆盖住正方形ABCD.
探究
在方法二中,我们得出了正方形ABCD的边长a,三角形GCD的高x与梯形EFCD面积y之间的关系式,亦或者说是函数即y=a2−2xa3
那么,若是不让三角形GCD完全覆盖正方形ABCD(不让三角形GCD的高等于无限),而是让其高尽量长,趋近于无限呢?
此时,可得x→∞lim(a2−2xa3)=a2
于是有当三角形GCD的高x趋近于无限时,梯形EFCD的面积趋近于正方形ABCD的面积a², 此时三角形GCD在正方形内的面积趋近正方形ABCD的面积.
结论
图1.0.1中的三角形GCD无法完全覆盖住正方形ABCD,但若三角形GCD的高趋近于无限,则此时三角形GCD在正方形内的面积趋近正方形ABCD的面积.
三角形覆盖正方形的研究
https://www.ordchaos.com/posts/4996fe6c/
About Food
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
Hello everybody!
Fast food is come from Ancient Roman. At that time, many people didn’t have enough money to buy or rent a house with a kitchen. So many people could only buy food from street vendors. At the same time, there were some pilgrims to Rome to buy fast food, too. That’s the first kind of fast food. And now, fast food has become popular all over the world.
Fast food is tasty, but there are some criticisms of fast food. Lots of fast food are rich in calories as they include considerable amounts of mayonnaise, cheese, salt, fried meat, and oil, thus containing high fat content. Excessive consumption of fatty ingredients such as these results in unbalanced diet. Children who eat fast food tend to eat less fiber, milk, fruits, and non-starchy vegetables. And even adults, like the school’s foreign teacher, Daniel. He likes to eat fast food and snacks. He usually buys snacks after class. Have you seen him? He is very fat and looked very old. But he is only in his 20s. I took his class while I was still in the class GUHONGMING. He hardly ever came upstairs. Because he was too fat to hold his weight. So we always have his class on the first floor. But don’t worry, it happens that some other foods are healthy and good for us, which is also the content of our next section - healthy food.
There are also some other food besides fast food, like vegetables and fruits. We can call then as healthy foods. They can help our body in many ways. First of all, there are many vitamins in them, such as vitamin C, which is very important for the human’s body. In the past, crews on the boat caught on a disease called scurvy. Then they found out a way to cure the disease: eat fruits and vegetables which are rich in vitamin C. So now we can see that healthy food such as fruits and vegetables are very important and good for our human’s body.
Besides, there are some foods that are healthy and have many proteins, such as meat. Proteins play a major role in ensuring your overall well-being. Meanwhile, it is one of the most important components of every cell presenting in the body. In our daily life, we mainly eat vegetables and meat. With the improvement of people’s living standards, people’s interest in meat is getting lower and lower. Many people eat vegetables and fruits as their staple food, and female friends stop eating meat in order to keep fit. But people do not eat meat will lead to inadequate protein intake, will lead to physical weakness, decreased resistance, fatigue, cold, lack of energy, memory loss, low quality of life, affect work and study. So now we can see the importance of healthy food. Let’s eat more healthy food and eat less fast food! Don’t forget that healthy food is good for your body and fast food is not.
About Food
https://www.ordchaos.com/posts/53c0d957/
免费高速文件分享小技巧
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
首先提示一下,这会是一篇非常非常短的博文。
介绍
还在为百度网盘那该死的限速而发愁吗?如果你在网络上分享文件,肯定不想因为下载者因为百度网盘的限速而对你破口大骂(不是 对吧。这里推荐一个老牌云盘——蓝奏云,官网在这里。
不限速,无限空间(单文件限100M),个人还是感觉非常不错,大文件要传上去也可以分卷压缩。
小技巧
网络上无法访问的蓝奏云文件分享可以试着把二级域名改为lanzoui试试哦。
题外话
没啦,就这么短。
886
免费高速文件分享小技巧
https://www.ordchaos.com/posts/618137f7/
C++ 链表实现队列
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
之前介绍了数组队列的实现方法,若是没有看过建议去看看,这次来介绍如何用链表实现队列。
概念引入
首先让我们了解一下什么是链表:
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
——百度百科 链表
所以,首先我们需要定义一个链表出来。
结构搭建
其实基本一样,不过这次要定义两个结构,一个是节点,一个是队列本身:
1
2
3
4
5
6
7
8
9
| struct node {
int v;
node * next;
};
struct myqueue {
node * first;
node * last;
};
|
对于每一个节点,我们需要它储存一个数据与其下一个节点的地址,分别储存在int型变量v与node型指针next中。
而后对于每一个队列或者是链表,我们需要储存其第一个与最后一个节点的地址,分别放在first与last中。
结构体定义完后,同样的初始化:
1
2
3
4
| void init(myqueue *t) {
t->first = t->last = NULL;
return;
}
|
这里让队列的首项与尾项同时为NULL,完成初始化
之后是数据操作的isempty函数,先行判断队列是否为空:
1
2
3
4
| bool isempty(myqueue *t) {
if(t->last == NULL && t->first == NULL) return 1;
else return 0;
}
|
原理很简单,如果队列的尾项与首项都为NULL,则显然此队列为空。
之后是push函数,将一个数据推入队列的最后:
1
2
3
4
5
6
7
8
9
10
| void push(myqueue *t, int s) {
node * temp = new node;
if(isempty(t)) t->first = t->last = temp;
else {
t->last->next = temp;
t->last = t->last->next;
}
temp->v = s;
return;
}
|
创建一个空节点,如果队列为空,则作为首项与尾项,否则作为尾项的下一项,然后给其赋值即可。
第二个是pop函数,删除队列首项,注意先判断队列是否为空:
1
2
3
4
5
6
7
8
9
10
11
12
| void pop(myqueue *t) {
if(isempty(t)) return;
if(t->first == t->last) {
free(t->first);
init(t);
} else {
node * temp = t->first;
t->first = t->first->next;
free(temp);
}
return;
}
|
若pop完队列为空则调用init函数重新化为空队列,否则将首项改为首项的下一项,但记住无论如何都要调用free函数释放原先首项的空间,节省内存。
再就是获取队列的首项、尾项、第n项以及长度,代码相对简单:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| int getf(myqueue *t) {
if(!isempty(t)) return t->first->v;
else return 0;
}
int getl(myqueue *t) {
if(!isempty(t)) return t->last->v;
else return 0;
}
int getlength(myqueue *t) {
if(isempty(t)) return 0;
int length;
node * temp = t->first;
for(length = 1;;length++) {
if(temp == t->last) break;
temp = temp->next;
}
return length;
}
|
特别注意若队列为空,则不应当返回队列所谓的首项与尾项。
对于长度的获取,只需要遍历整个队列,直到搜索到队列尾项再输出长度即可。
解决问题
与之前的问题是一样的,搭建的框架也很相似,故而解答同样基本一致。
问题背景
有n(n <= 100)个小朋友排队打针,他们每个人都有依次自己的编号为1, 2, 3, 4, …, n。他们都很害怕打针,所以当排在自己前面的小朋友打针时就会跑走到队伍最后。试设计一程序,输入小朋友数量,输出他们打针的顺序。
样例输入:5
样例输出:1 3 5 4 2
问题分析
略,可以参考之前的文章。
注意这一次是使用指针来访问队列的,故而此次的程序与上次有略微区别。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| int main() {
myqueue test;
init(&test);
int n;
cin>>n;
for(int i = 1;i <=n;i++) push(&test, i);
for(int i = 1;!isempty(&test);i++) {
if(i%2 == 0) {
int temp = getf(&test);
pop(&test);
push(&test, temp);
}
else {
cout<<getf(&test)<<" ";
pop(&test);
}
}
return 0;
}
|
queue类型
这里对于队列的编写其实还是为了学习与方便理解,事实上可以方便的在引用了头文件queue后直接定义队列,更加方便,竞赛或开发时也更加节省时间。
使用格式如下:
1
2
3
4
5
6
7
8
| #include <queue>
queue<int> Q;
Q.empty();
Q.size();
Q.front();
Q.back();
Q.push();
Q.pop();
|
下面给出使用queue队列的同样问题的解答,请读者自行参考:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| int main() {
queue<int> test;
int n;
cin>>n;
for(int i = 1;i <=n;i++) test.push(i);
for(int i = 1;!test.empty();i++) {
if(i%2 == 0) {
int temp = test.front();
test.pop();
test.push(temp);
}
else {
cout<<test.front()<<" ";
test.pop();
}
}
return 0;
}
|
总结
本次完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
| #include<bits/stdc++.h>
using namespace std;
struct node {
int v;
node * next;
};
struct myqueue {
node * first;
node * last;
};
void init(myqueue *t) {
t->first = t->last = NULL;
return;
}
bool isempty(myqueue *t) {
if(t->last == NULL && t->first == NULL) return 1;
else return 0;
}
void push(myqueue *t, int s) {
node * temp = new node;
if(isempty(t)) t->first = t->last = temp;
else {
t->last->next = temp;
t->last = t->last->next;
}
temp->v = s;
return;
}
void pop(myqueue *t) {
if(isempty(t)) return;
if(t->first == t->last) {
free(t->first);
init(t);
} else {
node * temp = t->first;
t->first = t->first->next;
free(temp);
}
return;
}
int getf(myqueue *t) {
if(!isempty(t)) return t->first->v;
else return 0;
}
int getl(myqueue *t) {
if(!isempty(t)) return t->last->v;
else return 0;
}
int getlength(myqueue *t) {
if(isempty(t)) return 0;
int length;
node * temp = t->first;
for(length = 1;;length++) {
if(temp == t->last) break;
temp = temp->next;
}
return length;
}
int main() {
myqueue test;
init(&test);
int n;
cin>>n;
for(int i = 1;i <=n;i++) push(&test, i);
for(int i = 1;!isempty(&test);i++) {
if(i%2 == 0) {
int temp = getf(&test);
pop(&test);
push(&test, temp);
}
else {
cout<<getf(&test)<<" ";
pop(&test);
}
}
return 0;
}
|
C++ 链表实现队列
https://www.ordchaos.com/posts/6270475f/
四种排序
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
在这里简单的以浅显易懂的方式写一下竞赛中常用的四种通用排序方式。
冒泡排序
大概是所有人第一次学到的排序方式,毕竟它实在是太经典了。
简单介绍一下原理:
冒泡排序(Bubble Sort),是一种计算机科学领域的较简单的排序算法。
它重复地走访过要排序的元素列,依次比较两个相邻的元素,如果顺序(如从大到小、首字母从Z到A)错误就把他们交换过来。走访元素的工作是重复地进行,直到没有相邻元素需要交换,也就是说该元素列已经排序完成。
这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端(升序或降序排列),就如同碳酸饮料中二氧化碳的气泡最终会上浮到顶端一样,故名“冒泡排序”。
——来自 百度百科 冒泡排序
一言以蔽之,即依次按规律交换相邻元素位置,直至不能交换为止。
知道这一点就好办了,很容易就可以写出程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| void bubbleSort(int f, int l) {
bool flag = 1;
while(true) {
for(int i = f;i < l;i++) {
if(a[i] > a[i + 1]) {
swap(a[i], a[i + 1]);
flag = 0;
}
}
if(flag) break;
else flag = 1;
}
return;
}
|
运行一下,成功排序。
选择排序
听名字就知道,这是一种通过“选择”来排序的算法,它通过每次选择未排序元素中的最大/最小值并与最后一个未排序元素交换位置来进行排序。
附一张原理图(来自菜鸟教程):
代码依旧很简单:
1
2
3
4
5
6
7
8
9
10
| void selectionSort(int f, int l) {
for(int i = f;i <= l;i++) {
int max = f;
for(int j = f + 1;j <= l - i;j++) {
if(a[j] > a[max]) max = j;
}
swap(a[max], a[l - i]);
}
return;
}
|
(甚至比冒泡都简单)
同样的,正常运行。
快速排序
非常经典的排序算法,也是公认最快的的排序算法。原理是用基准数分割,把大于/小于基准数的数放在基准数左边,其余放在右边,此时右边部分个数据皆小于/大于左边所有数据,然后对左右两边区间分别递归调用即可。
先放上代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| void quickSort(int f, int l) {
int i = f, j = l, mid = a[(f + l)/2];
do {
while(a[i] < mid) i++;
while(a[j] > mid) j--;
if(i <= j) {
swap(a[i], a[j]);
i++;
j--;
}
} while(i <= j);
if(f < j) quickSort(f, j);
if(l > i) quickSort(i, l);
return;
}
|
分别从基准数(这里是中间数)左右两边找到第一个大于/小于基准数的元素,交换,然后继续找,直到左右的寻找范围重叠,即代表寻找完毕,递归寻找剩余区间即可。
再放一张动图了解一下原理(图片依旧来自菜鸟教程)
归并排序
归并排序是建立在归并操作上的一种排序算法,该算法是分治法的一个典型应用。方法是将已有序的子序列合并,得到完全有序的序列——即先使每个子序列有序,再使子序列段间有序,最常用的是二路或三路归并排序。这里给出二路归并排序的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| void mergeSort(int f, int l) {
if(f == l) return;
int mid = (f + l)/2;
mergeSort(f, mid);
mergeSort(mid + 1, l);
int i = f, j = mid + 1, k = 0, r[l - f + 1];
while(i <= mid && j <= l) {
if(a[i] <= a[j]) {
r[k] = a[i];
i++;
k++;
} else {
r[k] = a[j];
j++;
k++;
}
}
while(i <= mid) {
r[k] = a[i];
i++;
k++;
}
while(j <= l) {
r[k] = a[j];
j++;
k++;
}
for(int p = f;p <= l;p++) a[p] = r[p - f];
return;
}
|
二路归并排序的原理是先以中间数为基准分割出两个子序列然后分别进行归并排序,然后对有序表进行合并,相信看代码也可以看出来。最后将临时数组的值赋给待排序数组就结束。
效率测试
时间复杂度
算法的时间复杂度是一个函数,它定性描述该算法的运行时间,常用大O来表述。若用函数f(n)描述算法执行所要时间的增长速度,用函数T(n)表示算法需要执行的运算次数存在常数c和函数f(n),使得当n>=c时T(n)<=f(n),记作T(n)=O(f(n)),其中n代表数据规模。显然,n越小,算法运行的越快。
常见时间复杂度等级如下表:
| 分类 | 写作 |
|---|
| 常量阶 | O(1) |
| 对数阶 | O(log(n)) |
| 线性阶 | O(n) |
| 线性对数阶 | O(nlog(n)) |
| n方阶 | O(nn) |
| 指数阶 | O(2n) |
| 阶乘阶 | O(n!) |
以及常用算法的时间复杂度如下表:
| 算法 | 平均时间复杂度 | 最好情况 | 最坏情况 |
|---|
| 冒泡排序 | O(n2) | O(n) | O(n2) |
| 选择排序 | O(n2) | O(n2) | O(n2) |
| 插入排序 | O(n2) | O(n) | O(n2) |
| 希尔排序 | O(nlog2(n)) | O(n2) | O(nlog2(n)) |
| 归并排序 | O(nlog(n)) | O(nlog(n)) | O(nlog(n)) |
| 快速排序 | O(nlog(n)) | O(nlog(n)) | O(n2) |
| 堆排序 | O(nlog(n)) | O(nlog(n)) | O(nlog(n)) |
| 计数排序 | O(n+k) | O(n+k) | O(n+k) |
| 桶排序 | O(n+k) | O(n+k) | O(n2) |
| 基数排序 | O(n×k) | O(n×k) | O(n×k) |
测时
除了时间复杂度,还有一种方式可以测试算法效率——对于相同的数据,直接测试算法排序用时并比较即可。使用ctime头文件中的clock()函数即可获取时间,运行前后的时间差即为运行用时。
于是有代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| int main() {
int n;
cin>>n;
default_random_engine e;
uniform_int_distribution<int> u(0,1000000);
e.seed(time(0));
for(int i = 0;i < n;i++) {
b[i] = u(e);
}
clock_t begin, end;
for(int i = 0;i < n;i++) a[i] = b[i];
begin = clock();
selectionSort(0, n - 1);
end = clock();
cout<<"selectionSort end"<<endl<<"time: "<<double(end - begin) / CLOCKS_PER_SEC * 1000<<"ms"<<endl<<endl;
for(int i = 0;i < n;i++) a[i] = b[i];
begin = clock();
bubbleSort(0, n - 1);
end = clock();
cout<<"bubbleSort end"<<endl<<"time: "<<double(end - begin) / CLOCKS_PER_SEC * 1000<<"ms"<<endl<<endl;
for(int i = 0;i < n;i++) a[i] = b[i];
begin = clock();
mergeSort(0, n - 1);
end = clock();
cout<<"mergeSort end"<<endl<<"time: "<<double(end - begin) / CLOCKS_PER_SEC * 1000<<"ms"<<endl<<endl;
for(int i = 0;i < n;i++) a[i] = b[i];
begin = clock();
quickSort(0, n - 1);
end = clock();
cout<<"qsort end"<<endl<<"time: "<<double(end - begin) / CLOCKS_PER_SEC * 1000<<"ms"<<endl<<endl;
return 0;
}
|
额外使用了random头文件中的函数用来生成在0到1000000间的随机数用于测试(我懒得写用法了,建议出门左拐Google),运行结果(可能)如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
| (input 100000)
selectionSort end
time: 2536ms
bubbleSort end
time: 14222ms
mergeSort end
time: 8ms
quickSort end
time: 6ms
|
简单易懂,对吧。
题外话
又水了一篇文(不是。
还是很开心的,因为以前都没有成功完成过归并排序与快速排序,这次写出来自我感觉非常好。
那就这样,886.
四种排序
https://www.ordchaos.com/posts/6a062b97/
【多图预警】 AwtrixPro 开源项目的复现
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
本人对AwtrixPro垂涎已久,但却懒得复现。暑假的物理作业包含一个对电学有关的实验,遂趁此机会复现一个出来。
材料采购
并不难,跟着官网的这个网页一步步在淘宝上找就可以了。就是记得买焊接工具以及足够量的耗材(指Gpio线材、热熔胶、电工胶带等等)以及外壳(可以用官网上的文件3D打印,淘宝上也有直接卖的)。
这里贴出我购买材料的链接,有兴趣的话可以试一试(加粗的为非必需品,没有注明数量默认1个,没有注明平台默认淘宝或天猫):
硬件制作
PCB+针脚焊接
本人未成功通过此方法复现,下列内容不一定完全正确,仅供参考
参考B站UP主三三三三三文啊的视频【AWTRIX PRO】一起动手做一个高颜值的像素灯,在嘉立创打好板子(注意有贴片,需要开钢网),买好GPIO接口公母头再焊接即可。打板流程可以参考【0基础】从零开始电子DIY!第三集:PCB电路板设计和打样!,这一套教程非常不错,推荐。
打好的板子如下:
焊接好之后(贴片是用的钢网+锡焊膏+风枪):
焊接针脚时若是无法直接使用锡丝与电烙铁焊接完成,也可以用锡焊膏+电烙铁。把锡焊膏涂抹在针脚背面,不用担心粘连,然后用电烙铁分别探入每两个针脚间的空隙,随后依次处理每个针脚就可以了。
然后刷程序、接线、通电、启动即可(至少理论上是这样):
很明显,这里并未启动成功,望高手赐教。
手动飞线
根据官网的接线图进行手动飞线即可,这里因为缺少一个电容(C1, 100nF)且不知道哪里有卖的而未接上DFPlayer模块及喇叭。
这里除了基础配件外,额外加装了光敏电阻、触摸以及Htui21d温湿度模块。基础部分依据教你做一个可编程像素屏制作成功,然后通过自主飞线完成了其它组件的安装。
没有什么难点,注意需要连接多根导线时用钳子分别剪开线的外皮,露出里面的铜/铁/其他金属丝,拧在一起然后用电烙铁与锡焊在一起就可以了。
裸露的金属丝记得用电工胶带或者热熔胶包裹起来,防止意外:
然后装入外壳即可:
再放上格栅、均光片及亚克力面板就完成了:
软件配置
软件这里就不再多提,官网上就有(点击这里访问)。就是说一下我这里是部署在我自己的服务器上,就无需本地服务器如树莓派一类了。
宝塔面板就可以轻松完成配置,也无需ssh连接。
然后安装自己喜欢的软件即可,我这里是这几个:
成品
题外话
从暑假开始一直做到了倒数第二天…心累,不过总算是完成了,也让我发现了我的电工天赋(bushi
那就这样,这篇报告(?)就完成了,感谢你的观看,886
【多图预警】 AwtrixPro 开源项目的复现
https://www.ordchaos.com/posts/774674fe/
About Choir
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
Hello everybody! I’m 我的姓名, and you can also call me by my English name OrderChaos / OrdChaos. Today, I want to tell you something about chorus there. Yes, I know you may hate the chorus class in the noon, but please don’t hate the chorus itself.
Chorus refers to the art category of collective singing of multi-voice vocal works. It requires a high degree of unity of single voice and harmony of melody between voices. It is one of the most popular and widely participated forms of music performance. As the expressive tool of chorus art, the human voice has its unique advantages, which can most directly express the thoughts and emotions in the musical works and stimulate the emotional resonance of the audience.
There are many types of chorus. In terms of voice and timbre, it is divided into two types: unison and chorus. Singing in unison refers to a chorus form in which all chorus members sing the same tune together regardless of their voices. It is often used in mass singing activities and can also be used in some fragments of chorus. Chorus refers to the superposition or contrast of two or more different parts of the chorus. It is one of the most typical forms of chorus. And from the accompaniment form, it is divided into two forms: a cappella and accompaniment. “A cappella” means to sung without instrumental accompaniment. It is a purely vocal art form. For example, the song 半个月亮爬上来 we have learned is an a cappella song. In contrast, accompaniment chorus is a form of chorus with accompaniment. Whether it is harmony, mode, dynamics, speed, or style, mood, and performance, they must be unified into the overall work as required.
Most of the choral songs are sung by the choir. A choir usually has a conductor with others who sing songs. Don’t think that the conductors just need to wave their hands, in fact they should do the things that much more complicated than this. For example, the free extension mark and the fade out mark in the score need to be controlled by the overall situation by the conductor, otherwise the song will become very discordant. Songs with weak or strong rhythm also need conductor to beat the rhythm, songs with different emphasis and emphasis also need to be reminded by the conductor. The coordination of multiple voices is also very important, a little attention will be taken out of tune, so everyone should use their own free time to practice – not make up the number.
Having said so much, I should also play a chorus song to listen to it, right? Let’s listen to 启程 sung by the Globe Jinshengyuzhen Choir (金声玉振合唱团). This is a new song learned this term - why do I know? Because I am a member of it.
(Play the music at this time)
(Say this while playing the intro) By the way, this was originally one of the most popular graduation songs for Japanese middle school students called 旅立ちの日に(Roman: Tabidachinohini), which was widely circulated in Japan. And Globe Jinshengyuzhen Choir have sung its Chinese version.
(Intro will be end at this time)
(While the song play finished, wait)
This song has not been officially announced yet. If you want to listen to the full version, please pay attention to the school’s WeChat public account.
OK! That’s all of my speech. Thank you for your to the full version, please pay . And now, I have a very easy question to ask you: Which country is the song 启程 come from?
(Answer: Japan | Say: Gerat! Thank you for your answer!) OK, that’s really all, thank you again!
About Choir
https://www.ordchaos.com/posts/79cc3297/
正常,荒谬——《局外人》读后感
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
我不是这里的人,也不是别处的人。世界只是一片陌生的景物,我的精神在此无依无靠,一切与己无关。
——题记
《局外人》书中的主人公默尔索虽不能说是冷漠无情,但也是不同于常人的。对于日常起居方面而言,他和大多数人一样。但是他又和大多数人不一样,他并不习惯于使用普通人通用的情感表达方式:他不像大多数人会在母亲,一个赋予他生命、哺育其成长的人的葬礼上嚎啕大哭;而他只是沉默着,甚至心中只想着为什么不早点结束,这样才能回去睡觉。像一个局外人一般,好似任何事情都与他毫无关联。这也是书中对他的第一处道德审判,即养老院中老人对丝毫没有伤心感受的默尔索的不正常的关注。
但是这一场审判是必要的吗?我们有必要在他人的审判之下临时更改自己深信不疑的观点吗?默尔索没有这么做,所以他才没有在母亲的葬礼上哭泣,亦或者是动那么一点点情。他认为死亡原本就是一件自然而然的事情。可是恰恰是因为这样,他才违背了人们约定俗成的道德准则,也为后文中他的悲剧结局埋下了伏笔。
默尔索之后在一种不明不白的状态下以一种正当防卫的姿态杀死了一位阿拉伯人,本身可以判定减刑的事件却正是因为他的“不近人情”——默尔索对任何问题的回答都太过客观,让人感觉不到人情味——而被记者过度渲染,引起了人们对这个案件的过度关注与检察官疯狂对默尔索人格的诋毁抨击。整个过程,默尔索被排挤在外,只剩下了法官与律师、证人的接触,并且谈论的主题还不是这一起案子,而是对默尔索本人的争论,对默尔索的“不孝”的争论。人们就像约定好了一样,顺利地,没有理由地将默尔索判以死刑。
正是因为默尔索的为人处世方式才引得了人们的过分联想。而在整个案件中,几乎所有人都被一种主观的想法所引导,认为他就是一个冷漠无情的杀人犯。可是他真的是一个冷酷无情的杀人犯么?深入了解他的人,喜欢他。泛泛接触过的人却想置他于死地。他仅仅是热爱这个城市,也真正懂得享受当下的美好而已。
正如他所言,一切都“不是我的错”,可是很多事情本就是这样自然而然发生了。
直至默尔索死刑之前他才展现出了一个真实的自己——一个思念自己母亲、怀念儿的日子的人。他开始感到害怕,恐惧死亡,恐惧狱卒的脚步声,恐惧黎明…人都会死,可是大多数人都可以用五十年以上的时间来一点一点消磨这种恐惧,消磨死亡这件事。但当这五十年的恐惧,突然一下子被压缩到了一天里面,在那一天里,一个普通人会想什么呢?或许大多数人会选择寻找情感寄托吧,选择信奉了某一个神,他们通过神鬼来为自己开脱,缓解自己内心的愧疚与不安。可是默尔索依旧没有这么做,对事件始终有着理性且客观认知的他并没有相信神鬼之说。他在被判死刑后,虽然神甫仍然在不依不饶教导默尔索,可他无动于衷,甚至于愤怒、爆发了。
这本书看似是谈主人公的荒谬、不合常理,可其实是反应社会的荒谬及民众的盲目从众。而事实上,这本书中,只有所谓的局外人才是真正清醒的正常人。
正常,荒谬——《局外人》读后感
https://www.ordchaos.com/posts/7b015599/
自主学习
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
尊敬的老师,亲爱的同学们,大家(上午/下午)好!我是八年级的我的姓名,很荣幸今天能站在这里演讲。面对大家真诚的面容,这次我想和大家分享我自主学习的心得。
首先,我们应该明确一个概念,即什么是自主学习。自主学习就是随意的学、无拘无束的学吗?显然不是。自主学习是以自学、质疑、讨论等方式深入理解学习内容并获得新知识的一种实践活动,是通过自我导向、激励、监控的方法学习。其需要我们不断地尝试一些适合自己的有效的学习方法,合理的掌控学习时间,以便于专心地投入学习中。
要做到自主学习其实并不难,只需要把学习看作是一件令人快乐和愉悦的事。是的,学习的过程虽苦,却也满含着即将迎来收获的喜悦。完成自主学习的过程大概分为五点:一、了解自己:透过渐趋清明的自我概念、自我价值、自我认知,朝自觉、自足、自在的境态迈进;二、了解环境:透过知识与经验,了解环境的资源及限制;三、寻求自己与环境最佳的互动可能:在了解自己也了解环境的基础上,能找出当下合适的对应;四、着手实现:靠勇气、恒心、毅力,使自己能实践出心中所想,知行合一。五、保有循环向上的检视机制:透过计划->实行->检视->增进的循环,让自己从每次的经验中有所反省和收获。上面的说法比较枯燥,就拿我个人来举例吧,从小学一年级开始,我就对数学很感兴趣,喜欢看一些趣味性的数学书,还经常自以为很厉害,主动寻找“难题”去“考”父母和老师,这其实就是一种出于本能的自主学习过程。后来,我出于对电脑编程的喜爱,出于对计算机的掌控中获得的欣喜感和满足感,编程培训课如无意外我从不缺课,平时还主动上网学习电脑编程知识、了解电脑信息和发展动态,同时,由于编程和设计需要用到大量知识,我也不放松自己对数学、物理、英语、语文甚至美术的学习。如果说小时候对数学难题的解题过程是一种懵懂的自主学习的初级状态,那么之后对编程和相关知识的自主学习就是在了解自我,了解环境的基础上,充分利用现有的时间、精力和资源,通过各种努力,达到自主学习的进阶状态。
同学们,“没有比人更高的山,没有比脚更长的路”,前行的路就在我们自己脚下,命运之门的钥匙就在我们自己手中。让我们从点滴做起,让自主学习成为持之以恒的一种习惯,成为我们自主的生活方式。我衷心祝愿每一位同学能克服自身的惰性,付以恒心与毅力,走向属于你自己的成功!
谢谢大家!
自主学习
https://www.ordchaos.com/posts/7e535678/
生日当天全款提下第一支(打八折)钟薛糕
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
生日当天全款提下第一支(打八折)钟薛糕
https://www.ordchaos.com/posts/7e920bb4/
迟来的二月调考总结
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
各位,好久不见,距离上次发文的时间过的有点久,其中最大的原因就是万恶的二月调考。现在已经考完一个多月了离四调也就一个月了,这里我来总结一下。
背景要素
以防不知道,本人生在武汉,学籍武汉,参加武汉的统一考试。武汉在九年级时会有几场全市统考,分别为九上的元月调考(期末)与九下的四月调考(期中)和中考(期末)。今年闹疫情,于是原定在一月四号的元调被挪到了二月二十一号(九下开头)。
武汉的中考在我这一届改革了,下面对比一下以往和之后的不同:
| 科目 | 分数(前) | 分数(后) |
|---|
| 语文 | 120 | 120 |
| 数学 | 120 | 120 |
| 英语 | 120 | 120 |
| 物理 | 70 | 70 |
| 化学 | 50 | 50 |
| 历史 | \ | 60 |
| 道德与法治 | 40 | 60 |
| 实验 | 0 | 30 |
| 体育 | 30 | 50 |
| 总分 | 550 | 680 |
详解:
- 原本不考历史
- 道德与法治原先只有选择题,现在新加入了材料题,分数构成为
28分选择 + 32分材料。历史分数构成与其一样,且二者合卷 - 实验考试以往不计分,为实操。现在为机考答卷,在120道题(40物理,40化学,40生物)中每个科目随机选10道题目作答,每题一分
- 体育由30分改为50分,构成为
15分平时 + 35分考试。本届由于新冠疫情的原因,取消体育中考(即所有人考试分数计为35)
二调情况
先明确二调的考试内容,为中考所有科目除去体育与实验(四调亦然)
分数不是很方便透露,大致说一下考试情况吧。说来惭愧,正正好好是语数英垮了(bushi
语文选择题眼瞎,错了两题。英语则是阅读理解B篇,神你以为我会说脏话吗?的Live a colorful life,我真感觉不到这么大,真的。
总之就是很意难平。
好消息是化学满分,终于!
签约的话倒不是不能签,只能说是比上不足,比下有余余余余余…
总结
也没什么可说的,给自己加油吧。我是想打竞赛的,文化课成绩必然需要更上一层楼才行。
886!
(鬼知道下次什么时候更新)
迟来的二月调考总结
https://www.ordchaos.com/posts/7eb4319/
在线写作与博文分享—— NetlifyCMS 与 ShareThis
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
没错,任何正常人都不会把标题里这两样东西联系起来,包括我。
NetlifyCMS
最开始看到这玩意是在fluid的官方博客的这一篇博文Hexo Netlify CMS 在线编辑博客(转载的,原文地址在这里),当时就觉得非常不错,但可惜未能按照教程配置成功,只得转投于更贴合于Hexo的HexoPlusPlusHexo艹
直到前几天上个月看到Xingyang在一键推流工具——BlogPusher这一篇文章下的评论:
如果静态博客是部署在 Github 上的话可以试试用 Netlify CMS。相当于架设一个能进行 Git Commit 的 Web app,最重要的就是 0 花费,Private Repo 也可以用。我自己的博客也在用(虽然文章数不是很多())
参考文章:https://cnly.github.io/2018/04/14/just-3-steps-adding-netlify-cms-to-existing-github-pages-site-within-10-minutes.html
很好,但是不太符合我的情况。于是随即翻了翻——
瞳 孔 地 震.jpg
完全可用!撒花!
如果你也没有成功配置Netlify CMS的话也可以试试,教程十分甚至九分简单,个人感觉几乎不存在出错的可能性。
感谢Xingyang!顺便他的博文链接:简单搭建一个 GitHub Repo 静态博客的 CMS 后台内容管理系统
ShareThis
最开始捣鼓了一阵子分享系统,share.js啊,Social Share Button啊等等都尝试过一遍,但我都不太满意,况且分享也不是刚需,于是就此作罢。
直到昨天,我妈问我:“你这个博客怎么分享给别人看啊?”
我突然感觉分享还是有必要的,遂继续开始寻觅,然后就发现了ShareThis
注册
非常简单,进入首页:https://sharethis.com
点击“从分享按钮开始”,然后点击第一个选项:
不要急着点击下一步,先用滚轮滚动到页面下方,点击“Customize your Inline Share Buttons”按钮。
在弹出的选项中对按钮进行配置,可以配置包括颜色、媒体、形状等等内容。
最下方的语言记得调整为中文,然后点击下一步,在新页面中注册登录即可。
随后,你会得到两串代码,分别是js安装代码与按钮引入代码。安装代码放在head中,按钮放在你想插入的地方就好。
大概如下:
1
2
|
<script type='text/javascript' src='https://platform-api.sharethis.com/js/sharethis.js#property=不告诉你&product=inline-share-buttons' async='async'></script>
|
1
2
|
<div class="sharethis-inline-share-buttons"></div>
|
效果
滑到这篇文章底下看吧。
题外话
这篇博文算是对近期我对博客的大改动,但是单独发太短,所以就这么整合在一起了。
那就这样,这篇博文就到这里,886!
在线写作与博文分享—— NetlifyCMS 与 ShareThis
https://www.ordchaos.com/posts/8e1b39a3/
尊重客观规律
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
只有尊重客观规律,才能事有所成。西门豹出任邺令,破除封建迷信,转而挖掘渠道、灌溉农田,治理了邺城常有的水灾;鲧以堵治水而无能为力,大禹改堵为疏,完成了治水的大业。这些都是以对客观规律的尊重而得到的成果,也证明了人类若是要认识和改造世界,必须先尊重客观规律。青藏铁路只从西宁修到了格尔木就不再延伸,这份阻碍并非因为资源,而是来源于人们对客观规律的践行——在当时的条件下,这样的施工若是继续下去一定会对当地,甚至整个中国的生态造成破坏。人们不断只有尊重、探索客观规律,才能更好的造福社会。
尊重客观规律,是在践行宇宙的真理。“橘生淮南则为橘,生于淮北则为枳,叶徒相似,其实味不同。所以然者何?水土异也。”柑橘在南方能长出甜美饱满的果实,但在北方就只能结出味苦的枸橘。英国文艺复兴时期散文家、哲学家弗朗西斯·培根曾经说过:“只有顺从自然,才能驾驭自然。” 世间万物皆有其自身的规律,许多事物也万万不能强求,“强扭的瓜不甜”。瓜一旦成熟,其瓜蒂部分便会变得干枯,自动脱落,很容易摘;而若是瓜还并未成熟,那么瓜蒂部分必然长得很结实,要想把瓜摘下来就一定要使劲扭。如此摘下的瓜自然都是未成熟的,又怎可能甜?规律是亘古永存的,其具有客观性与普遍性。柑会变成枸橘、瓜会没有甜味,这一切的改变都是客观规律使然。“昔者海鸟止于鲁郊,鲁侯御而觞之于庙。奏《九韶》以为乐,具太牢以为膳。鸟乃眩视忧悲,不敢食一脔,不敢饮一杯,三日而死。”“宋人有闵其苗之不长而揠之者,芒芒然归,谓其人曰:“今日病矣!予助苗长矣!”其子趋而往视之,苗则槁矣。”鲁侯养鸟、揠苗助长,都是不遵守客观规律而造成的后果·。如此可以看出,规律的存在和发生作用都以一定的客观条件为基础,在不具备其根据和条件的情况下,人为的要求某个规律存在和发生作用是不可能的。综上所述,在实际生活中,规律是不可抗拒的。也只有按规律办事,才可能达到所需要的目的。
尊重客观规律
https://www.ordchaos.com/posts/8f132c87/
《四世同堂》读后感
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
学期末老师列了一条长长的书单,让我们选择两本来写读后感。正巧以前听闻过老舍先生的《四世同堂》,于是便选择了它与另外一本书。在我的印象中,老舍先生的书里我只看《骆驼祥子》。当然肯定不止这一本,只是忘了其它书的名字罢了。
但书到货之后我震惊了,因为这本书完全不像我想的那样。这本,不,应该是这套书比我以前所读过的所有书都要厚。而在真实的读过一遍这本书后我却才发现。这个厚度也不算什么,因为它的剧情真的非常好。
《四世同堂》是老舍最著名的长篇小说,这部百万字的巨著描述了卢沟桥事件爆发的一九三七年至日本投降的八年间北京普通市民遭受到的残酷压迫与统治,以及他们面对生与死的自尊与自省。老舍这部书中展示了北平沦陷区一群普通人的生活。通过祁老人、瑞丰、瑞宣、韵梅、钱诗人、小文夫妇、李四爷、白巡长、孙七、小崔、马老太太、常二爷、小妞妞以及大赤包、招弟等人物形象,表现出民族存亡之际,真善美与假恶丑的斗争,崇高的民族气节和苟且偷安、助纣为虐的对照。
老舍在《四世同堂》中对于人物性格的刻画及其的用心,而刻画出的任务同样的非常立体。比如在描写汉奸时:冠晓荷与蓝东阳是小说中的汉奸形象代表,“无事乱飞是苍蝇的工作,而乱飞是早晚会碰到一只死老鼠或一堆牛粪,冠先生是个很体面的苍蝇。”而老舍先生用极妙的笔法对蓝东阳道:“蓝东阳的相貌先引起试官的注意。他长得三分像人,七分倒像鬼。日本人觉得他的相貌是一种资格与保证——这样的人,是地道的汉奸胚子,永远忠于他的主人,而且最会欺压良善。东阳的脸足以引起他的注意,恰好他的举止与态度又是那么卑贱的出众,他得到了宣传处处长。”
而放远了看,实际上,老舍先生描写的这个时代下的中国正是二战期间法西斯侵略活动的最好的印证。读书的时候很容易就会联系到以前看过的海明威著作的《永别了,武器》。这本书讲的是一战期间的故事。一战时交战双方的目的主要是瓜分殖民地,争夺市场和原料产地;二战法西斯国家不仅要打败对方,而且要在全世界范围内建立法西斯制度。这也就解释了为什么日本区区一个弹丸之地,竟然有吞并整个东南亚的野心,且近乎于成功了。书中有写“短腿小鬼可不管你是否是它的一条狗,只要它认为你可疑,不值得信任或没有利用的价值了,旋即投狱、折磨、杀死,没有丝毫的理由。”这就是日本人的强盗逻辑,这就是这个民族嗜血成性的侵略本性。只有我们自己手握武器,狠狠地痛击它,它才能乖乖地缩回乌龟头,在它的小岛上蛰伏不动。
回归书中,回归二战,回归北平。其实无论在什么时代,谁都想过着安适美好的日子,可是当祖国受到侵略,当侵略者剥夺人们正常生活的权力,每一个有正义感和民族感的普通老百姓都会用自己的方式来保卫自己的家园的想法,但是这不可能。人只能在愤激反抗所博得的美名与背负骂名的存活中选择一个。选择其中一边的人是有的,而这些人恰恰会是被后人熟记、明知的。大部分老百姓什么也没有选,而是站在它们之间,想着苟且偷生。我为汉奸们可悲,更为那些觉醒后勇于反抗的人们感到欢欣鼓舞。小说中的一些次要人物就像我们揭示了老百姓们可悲的一面。他们因为一点蝇头小利便偏向了侵略者一方。以往拳打汉奸的金三爷,因为日本人带来的好生意转而感激,之后甚至出卖了钱默吟先生。年轻貌美的招弟,堕落成一个出卖肉体的女人,却还以此为荣。这些没有是非观的行为无疑是贪念在作祟。最后,当抗战最终胜利,人们仿佛才想起了报仇,结尾几个小伙子想找日本老太婆报仇的事再次让人嗤笑和而叹息。人们已经不怎样能高兴起来了,八年的风雨飘摇,战争给人民带来了无尽的苦难,给中国大地留下了累累伤痕。我们不应忘记这段屈辱的过去,要时刻铭记那段冰风冷雨的历史,创造辉煌的未来。
《四世同堂》读后感
https://www.ordchaos.com/posts/92674965/
年中总结,及进16岁生贺
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
又是一年生日了,回想上次生日,好像还是在上次一样,那时还是在初三开学前的补课。补课放学的很早,五点就回家了。当时在超市里买了一根价值14块大洋的钟薛糕……
说起来真的像是发生在昨天。
1~2月
经过了疫情的洗礼,九年级下学期的开学总算是如期而至,但紧随而来便是对二月调考的紧张。原本武汉是只有元调、四调的,不过由于众所周知的疫情因素,元调从原定的1月4号挪到了2月21号。让我们过了一个安心的元旦和一个安心的寒假。
但该来的还是要来,二调总归也是调考,压迫感并未消失,只是转移到了一个月后。故而新学期伊始,我们就全身心投入到了复习之中。那时我的心里总会浮现出七年级刚开学时班主任在班里说的话,她告诉我们三年很短,元调很重要。初听不知话中意,而现在,已为语中人。
二调的成绩中规中矩吧,523分(523/600),随后便立下了四调要进步15分的目标。但那时我还不知道,这个目标永远没有机会达成了。
3~4月
二调完了就是四调,没什么可说的,该复习复习,该上新课上新课。伴随着一本又一本教材被翻至最后一课、最后一面,初中即将毕业的感受才开始从心中滋生。不论是Graduation还是“从这里出发”,课本中的一句句话,一段段文章都正提醒着我们即将分别的事实。
四调成绩说实话,很不好,只有508。以至于我的母亲对我这个分数不抱什么期望了,也便没有如同二调结束后那样跑前跑后地签各种约。也正因如此,已然退休的她只能在家里独自心焦,这是我的问题。
5~6月
五月有各个区自己的五调,六月便是全武汉市的中考。志愿早在五月九日便截至提交,在此之前,我终于说服了我的父母为我填写武钢三中为第一志愿。“说服”,无奈的选择,毕竟要说二调成绩勉强足够的话,四调成绩面对钢三简直就是依托答辩。但我仍然坚定的选择了这条路,算是对自己的压迫吧,同时也伴随着一股气,一股不服输的精神。
五调前举行了理化生实验考试,和八年级的地理生物一样,采用机考的形式。没什么难度,几乎全班满分通过,只有3人被扣了1分。加上由于疫情取消的体育中考,近乎就是给每个人送了80分。
六月初,抽了一个上午,我们全班在学校里拍了毕业照。学校不大,很快就走遍了整个校园。伴随着感慨,拍完室外照后回班,我们齐心协力在十分钟内办好了一面黑板报。站在黑板报前,我们拍了最后的几张照片。
中考日以前,最后一个在校日,是一个周六。老师在上午或看自习,或做最后的查漏补缺。而下午,老师开了一场动员会,给每个人发了一块粽子玩偶。既代表端午将临,亦有一举高中之意。一场班会结束,打扫完教室,离开学校,颇有一种或解脱、或不舍的情愫。
中考前一天,周一,下午我便前往了考点处。每个文化课老师都在考点门口,为我们一张张派发着准考证。面对那一句句叮嘱,我明白,不能当做是像以前那样的老生常谈了。
中考结束的那一天,考完历史道法的上午。连续更改了两道选择题的我放下了手中的笔,一根根地把中性笔、2B铅笔、涂卡笔以及橡皮擦、垫板、准考证装入了文具袋。走回休息室,再和全班同学及老师走出了考场。此时此刻,心中只有解脱,无暇再顾及其它。
随后就是毕业旅行了,很愉快的出行经历,也为初中三年画上了一个圆满的句号。
7~8月
七月一号一早,昨天刚从青岛回到家的我点进了武汉招考网,惊心动魄的输入姓名、报名号和身份证号。按下蓝色按钮的那一刻,时间仿佛凝滞。好在接下来引入眼帘的数字令我终于放下了心,614分(614/680),是我最高的一次了。
毫无疑问的被钢三录取,之后是钢三的夏令营,一直到七月二十一。食堂很美味,与同学相处得很愉快,校园环境很好,近乎无可挑剔了。
八月,很放松的一个月,这个月一直在玩master duel和原神,开始了摆烂状态(笑)
直到今天,我的生日为止,一切都很放松。
未来……
马上就是钢三的军训了,再之后就是开学,祝我一路顺利吧!
也希望三年后的暑假能像现在一样无忧无虑。
Happy Birthday for Me!
顺便晒一下毕业纪念册!
年中总结,及进16岁生贺
https://www.ordchaos.com/posts/95bd9bb8/
第五种排序—— std::sort() 函数
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
上次讲了四种排序算法(没看过的点这里),但是在实际开发或是竞赛中可能没有足够的时间写出一个够用的排序函数,或是需要排序的并非数字,这时便是我们的大宝贝——std::sort()函数登场的时候了。
用法
需要先引用algorithm库,不过我更倾向于在竞赛时直接使用万能库节省记忆时间。然后,需要使用std命名空间,或是直接调用std::sort()。
sort()函数的原型如下:
1
2
3
4
5
| template <class RandomAccessIterator>
void sort(RandomAccessIterator first, RandomAccessIterator last);
template <class RandomAccessIterator, class Compare>
void sort(RandomAccessIterator first, RandomAccessIterator last, Compare comp);
|
对,std::sort()是重载函数,其中包含了是否存在comp的两种版本。std::sort()函数默认从小到大按字典顺序对数据进行排序,用法如下:
1
2
3
| int arr[10] = {12, 10, 48, 28, 22, 33, 19, 13, 27, 38};
std::sort(arr, arr + 10);
for(int i = 0;i < 10;i++) std::cout<<arr[i]<<" ";
|
此时std::sort()函数便会将arr[0]到arr[9]共10个元素进行排列并放回arr数组,所以上述程序运行结果如下:
1
| 10 12 13 19 22 27 28 33 38 48
|
很容易就可以想到,对吧。
进阶
使用std::sort()对各类普通变量排序
对std::string类型变量排序
前面提到了,std::sort()会对数组使用字典序从小到大排序,所以结果就很容易预想到。
看下列程序:
1
2
3
| std::string arr[10] = {"apple", "Apple", "APPLE", "zen", "ordchaos", "OrdChaos", "happy", "x-ray", "xyz", "123aa"};
std::sort(arr, arr + 10);
for(int i = 0;i < 10;i++) std::cout<<arr[i]<<" ";
|
想一想,结果会如何?
结果:123aa APPLE Apple OrdChaos apple happy ordchaos x-ray xyz zen
怎么样,是不是很简单。这种对std::sort()的使用方式可以做按照字母序排列姓名的题目,但是如果题目要求按长度排序怎么办?别着急,慢慢往下看。
使用comp自定义排序顺序
刚刚说过,std::sort()是一个重载函数,有一个含有comp的变体,那么,comp是什么?用来干什么呢?简单来说,comp就是一个返回值为bool类型的函数,在这个函数里你可以自定义sort排序的顺序。这样说你可能不理解,那就来看看下面这个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
| bool cmp(int a, int b) {
return a > b;
}
int main() {
int arr[2][10] = {{12, 10, 48, 28, 22, 33, 19, 13, 27, 38},{12, 10, 48, 28, 22, 33, 19, 13, 27, 38}};
std::sort(arr[0], arr[0] + 10);
std::sort(arr[1], arr[1] + 10, cmp);
for(int i = 0;i < 10;i++) std::cout<<arr[0][i]<<" ";
std::cout<<std::endl;
for(int i = 0;i < 10;i++) std::cout<<arr[1][i]<<" ";
return 0;
}
|
在这里我定义了bool类型函数cmp(),其中若a>b则返回true,否则为false。然后两次调用std::sort(),分别为两个一模一样的数组arr[0]与arr[1]排序,不同的是第二次使用了我们定义的cmp(),那么,结果如何呢?
1
2
| 10 12 13 19 22 27 28 33 38 48
48 38 33 28 27 22 19 13 12 10
|
没错,第二次排序变为了从大到小排序。利用这种方法,我们就可以轻松解决刚刚的问题,像这样:
1
2
3
| bool cmp(std::string a, std::string b) {
return a.length() < b.length();
}
|
把这个函数加入刚刚的程序,再次调用std::sort(),只不过要加入参数cmp。很容易想到结果如下:
(动动脑哦)zen xyz apple Apple APPLE happy x-ray 123aa ordchaos OrdChaos
对std::string类型变量内部进行排序
联想到可以通过类似于str[i]的方式来访问字符串内字符,自认可以写出使用std::sort()排序字符串内字符的方法:
1
2
| std::string str = "rhuMJKhwHefJkUIGuw394y49h";
std::sort(str.begin(), str.end());
|
注意这里必须使用str.begin()与str.end()作为参数而非str与str+str.str.length()。
结果也就是可以料想的,编译运行,程序输出如下:
1
| 34499GHIJJKMUefhhhkruuwwy
|
整 整 齐 齐.jpg
利用comp同样可以实现逆序排序,那就请你自己想想怎么写吧!
使用std::sort()对结构体进行排序
设想一个场景,有一个结构体叫做student,其中含有单个学生的姓名和成绩。这时该如何通过学生成绩对学生姓名进行排序呢?这里用std::sort()就会使最快的方法。
先定义结构体:
1
2
3
4
| struct student {
string name;
int score;
};
|
然后写出对应的comp:
1
2
3
| bool cmp(student a, student b) {
return a.score > b.score;
}
|
之后直接调用std::sort()就可以了,合起来代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| #include<bits/stdc++.h>
using namespace std;
struct student {
string name;
int score;
};
bool cmp(student a, student b) {
return a.score > b.score;
}
int main() {
student stu[3] = {(student){"Tony", 98}, (student){"Betty", 97}, (student){"Lucy", 99}};
sort(stu,stu+3,cmp);
for(int i=0;i<3;i++){
cout<<stu[i].name<<endl;
}
return 0;
}
|
输出可以料想:
这样做的好处是方便拓展,比如说现在结构体变了,存在四个科目的成绩与学生姓名,要求按平均分排序,从之前的程序上修改会非常容易:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| #include<bits/stdc++.h>
using namespace std;
struct student {
string name;
int chinese;
int math;
int english;
int programming;
};
bool cmp(student a, student b) {
return (a.chinese + a.math + a.english + a.programming)/4 > (b.chinese + b.math + b.english + b.programming)/4;
}
int main() {
student stu[3] = {(student){"Tony", 98, 96, 100, 95}, (student){"Betty", 97, 80, 99, 95}, (student){"Lucy", 99, 96, 90, 100}};
sort(stu,stu+3,cmp);
for(int i=0;i<3;i++){
cout<<stu[i].name<<endl;
}
return 0;
}
|
这时结果就会变为Tony Lucy Betty的顺序。比起手写排序,这种情景使用std::sort()会方便不少。
做道题吧
洛谷:P1093 NOIP2007 普及组 奖学金
题目描述
某小学最近得到了一笔赞助,打算拿出其中一部分为学习成绩优秀的前5名学生发奖学金。期末,每个学生都有3门课的成绩:语文、数学、英语。先按总分从高到低排序,如果两个同学总分相同,再按语文成绩从高到低排序,如果两个同学总分和语文成绩都相同,那么规定学号小的同学排在前面,这样,每个学生的排序是唯一确定的。
任务:先根据输入的3门课的成绩计算总分,然后按上述规则排序,最后按排名顺序输出前五名名学生的学号和总分。注意,在前5名同学中,每个人的奖学金都不相同,因此,你必须严格按上述规则排序。例如,在某个正确答案中,如果前两行的输出数据(每行输出两个数:学号、总分) 是:
这两行数据的含义是:总分最高的两个同学的学号依次是7号5号。这两名同学的总分都是279(总分等于输入的语文、数学、英语三科成绩之和),但学号为7的学生语文成绩更高一些。如果你的前两名的输出数据是:
则按输出错误处理,不能得分。
输入格式
共n+1行。
第1行为一个正整数n(n≤300),表示该校参加评选的学生人数。
第2到n+1行,每行有3个用空格隔开的数字,每个数字都在0到100之间。第j行的3个数字依次表示学号为j-1的学生的语文、数学、英语的成绩。每个学生的学号按照输入顺序编号为1~n(恰好是输入数据的行号减1)。
所给的数据都是正确的,不必检验。
输出格式
共5行,每行是两个用空格隔开的正整数,依次表示前5名学生的学号和总分。
输入输出样例
输入1
1
2
3
4
5
6
7
| 6
90 67 80
87 66 91
78 89 91
88 99 77
67 89 64
78 89 98
|
输出1
1
2
3
4
5
| 6 265
4 264
3 258
2 244
1 237
|
输入2
1
2
3
4
5
6
7
8
9
| 8
80 89 89
88 98 78
90 67 80
87 66 91
78 89 91
88 99 77
67 89 64
78 89 98
|
输出2
1
2
3
4
5
| 8 265
2 264
6 264
1 258
5 258
|
分析
这是一道很好的练习结构体的题,核心就是刚刚说的使用std::sort()函数对结构体进行排序,只不过这次的comp会复杂那么一点点。
结构体定义与comp大致如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| struct student {
int num, chinese, math, english;
};
bool cmp(student a,student b) {
if((a.chinese + a.math + a.english) > (b.chinese + b.math + b.english)) return 1;
else if((a.chinese + a.math + a.english) < (b.chinese + b.math + b.english)) return 0;
else {
if(a.chinese > b.chinese) return 1;
else if(a.chinese < b.chinese) return 0;
else {
if(a.num > b.num) return 0;
else return 1;
}
}
}
|
剩下的部分就不必多说了吧,直接上代码:
1
2
3
4
5
6
7
8
9
10
11
12
| int main() {
int n;
std::cin>>n;
student stu[n];
for(int i = 0;i < n;i++) {
stu[i].num = i + 1;
std::cin>>stu[i].chinese>>stu[i].math>>stu[i].english;
}
std::sort(stu,stu + n,cmp);
for(int i = 0;i < 5;i++) std::cout<<stu[i].num<<' '<<stu[i].chinese + stu[i].math + stu[i].english<<std::endl;
return 0;
}
|
完成!
完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| #include<bits/stdc++.h>
using namespace std;
struct student {
int num, chinese, math, english;
};
bool cmp(student a,student b) {
if((a.chinese + a.math + a.english) > (b.chinese + b.math + b.english)) return 1;
else if((a.chinese + a.math + a.english) < (b.chinese + b.math + b.english)) return 0;
else {
if(a.chinese > b.chinese) return 1;
else if(a.chinese < b.chinese) return 0;
else {
if(a.num > b.num) return 0;
else return 1;
}
}
}
int main() {
int n;
cin>>n;
student stu[n];
for(int i = 0;i < n;i++) {
stu[i].num = i + 1;
cin>>stu[i].chinese>>stu[i].math>>stu[i].english;
}
sort(stu,stu + n,cmp);
for(int i = 0;i < 5;i++) cout<<stu[i].num<<' '<<stu[i].chinese + stu[i].math + stu[i].english<<endl;
return 0;
}
|
附加内容
std::sort()的平均时间复杂度是O(nlog(n)),原理是在数据量大时采用快速排序进行分段递归排序,而一旦分段后的数据量小于某个门槛,为避免快速排序的递归调用带来过大的额外负荷,就改用直接插入排序(不是插入排序)。如果递归层次过深,还会改用堆排序。
sort的速度够快,但若是追求极致速度且数据量很大,仍建议手写快速排序或归并排序。
题外话
写这篇文章真的累死…
写了足足一个小时啊啊啊啊啊
白里个白(逃
第五种排序—— std::sort() 函数
https://www.ordchaos.com/posts/97a1a73e/
适合自己的路
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
看到他人的东西,觉得好自己买来,却并非如想象一般;看到他人制定了良好的学习计划,照搬过来,自己却完全无法实施;看到他人读了书,受益颇多,自己却无法读懂……这样的事件可能不常有,但总会在生活中不时发生。所以也就告诉了我们,适合他人的不一定适合自己。
我曾为提升自己而参考了他人的计划表准备施行于自己的日常生活之中,但不到三天便就放弃。无论是其中的两小时阅读时间,半小时健身亦或是额外的课外学习都远非我的课余时间可以容纳。计划不仅没有起到提升自己的作用,且打乱了我本稳定的作息,使我在那几天中萎靡不振,自然可以看出照搬他人经验是如此无用。“长者不为有余,短者不为不足”,长与短各有价值,没有高低贵贱之分,适合自己的远比他人的、华丽的、不切实际的好得多。自己的目标,自己的计划,也总是比他人的更贴合自己的要求。
鲁迅弃医从文,向全世界证明笔比手术刀更尖锐,最终成为世人铭记的文学大师;李白离开黑暗官场,漂泊天涯。一句“安能摧眉折腰事权贵,叫我不得开心颜。”让他领悟了人生的真谛;奥托-瓦拉赫放弃父母所选的文学,油画,而投身于化学,成为享誉全球的化学巨头……他们的人生都因为选择了自己的路而变得独特。若是没有选择适合自己的目标,他们也不会有如此的成就。
“尺有所短,寸有所长。”我们也要找到自己擅长的方面,发扬自己的长处,令自身拥有几个闪光点,不应见到他人便现慕他人的优点,因为自己也定有些地方远非他可以企及。世上的事业千千万万,只有适合自己的才是最好的。人无完人,故而所有人都需要认清自己的强项和弱势,看清自己,找准位置,均衡发展,从而更好的立足于社会之中。
“凫胫虽短,续之则忧,鹤胫虽长,断之则悲。”唯有找到自身定位,确定自我目标,制定自己的计划并为之付出汗水;践行思齐,见不贤而内自省,不断完善与提高自己;善假于物,发展自身特长,才能走上适合自己的路,取得令自身真正为之骄傲的成就。自己的人生需要自己演绎,自己的生活该有自己的选择。选择最适合自己的,才能活出自己的样子,活出自己的精彩。
适合自己的路
https://www.ordchaos.com/posts/ab8676cc/
数字生命卡开箱——来自《流浪地球II》
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
过年档的电影,看完就买了周边。历经半年,终于到手啦!哈哈!
《流浪地球II》的官方周边产品大部分都是赛凡做的。怎么说呢……我买的数字生命卡是第二批,看到很多第一批的都有程度不一的瑕疵。不过我这个就还好,没有什么大问题,看来还是有在改进运输和包装质量。
到手差不多就是这么些东西:
其它周边什么的就不多说了,重头戏还是数字生命卡。
数字生命卡
只说外观的话,看起来金属感不是很强,喷个漆观感应该会好一些,但我不会(
别的道具倒是挺还原的,比如说袋子。
别的也没什么可说的了,毕竟这也就是一个128G的U盘和一个读卡器而已。
其它
不说什么了,放几张图吧。
题外话
不是很好评价赛凡的产品了……
我只能说我能接受这个做工,但的确,赛凡的破事很难让我提起好感。
就这样,886!
数字生命卡开箱——来自《流浪地球II》
https://www.ordchaos.com/posts/b3d3143c/
《钢铁是怎样炼成的》读后感
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
一个人的人生应当这样度过:当他回首往事时,不因虚度年华而悔恨,也不因碌碌无为而羞耻。
——题记
保尔是一个无私的人,他总是把党和祖国的利益放在第一位。在战争年代,保尔情愿与父兄们一起上战场;为保卫苏维埃政权,他甘愿同外国武装干涉者和白匪军拼个你死我活。这些都表现保尔了甘愿为革命事业的献身精神。在如此的艰难岁月中,他却能将自己全部的热情投入到了和平劳动之中。虽然他为国家、党与人民做过如此大的贡献,但他却从未骄傲过,也从未考虑过个人的名利、地位,而只想多为党和人民做点事情。党叫他修铁路,他答应;党调他当团干部,他同意——而且都是拼命地做。为了革命他甚至可以牺牲自己个人的私生活,即爱情。他虽然爱丽达,但受到了“牛虻”的影响,所以想要“彻底献身于革命事业”,最后按照“牛虻”的方式与她不告而别。在保尔全身瘫痪、双目失明后,他仍然想继续为党工作。这些都正如他所言:“我的整个生命和全部精力,都献给了世界上最壮丽的事业——为人类的解放而斗争。”
保尔是一个于平凡且伟大的人物。在他的一生中,一直没有过什么惊天动地的伟大业绩:他总是从最平凡的小事做起。面对疾病的沉重打击,虽然他也曾产生过自杀的念头,但是保尔后来也认识到了这是一种任性和不负责任,于是他又重拾了对生活的信心。也正是因为作者的这种塑造,所以保尔才会让我们感受到一种真实感。他是伟大的,也是平凡的。他既是在不断的困境与不幸中真正被煅炼的钢铁,也是一个有血有肉的、让人感到亲切的人。
书中对于保尔残疾后形象的塑造也同样不乏。保尔因不幸而残疾,但尽管自己身体行动不便,他也用自己顽强的毅力克服了种种困难。他在残疾后毫不灰心,反而更加的刻苦学习与奋力工作,同时还开始了文学创作。即使是他双目失明后他也未动摇过其信念,只是拿起了笔,摸索着尝试写作。即便是每写一字,他都需要付出常人根本无法想象的艰辛劳动他也坚持了下来,由此最后他才终于写出了小说《在艰苦暴风里诞生》的一部分。保尔是一个普通的革命战士,但却有着这样钢铁般的坚强意志,这与共产主义事业的召唤是不可分割的。他投身于革命事业,一次又一次的创造着奇迹。
世界上基本没有什么是天生的,所有事物都只有在经过火焰的煅炼后才可以使自身得到不断地升华。保尔是,我们也是。我们每一个人都只有树立伟大的理想、执着的追求,并且在正确的拼搏道路上不断砥砺前行,他才不会被生活的火焰所摧毁,不会被不幸的塑造所扭曲。这样的人会在一段段人生经历中坚强、成熟起来,去绽放自己的力量、迎接更好的自己。
《钢铁是怎样炼成的》读后感
https://www.ordchaos.com/posts/bb5ce830/
牺牲少数保护多数是不正义的——一辩发言
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
尊敬的老师及评委们,大家好!我们的观点十分明确,即牺牲少数保护多数是不正义的。请注意辩题中的措辞,是“不正义”而远非“邪恶”。不正义并非与正义成对立的关系,而是互补——任何称不上正义的行为都可以称之为不正义。不正义不是一个极端的点,而是除了正义这个点外的整条线。所以换句话说,我们认为,牺牲少数保护多数的行为不配称之为正义。“牺牲”本义指古希腊哲学家柏拉图在《理想国》中曾表明正义是客观存在的,所以并不存在所谓“相对的正义”,也不可能从两个角度分别看待一件事正义与否并得出不同的答案。既然我们已知牺牲少数保护多数从某些角度上来看并非正义,那么这件事自然便一直不在正义的范畴之中,于是其只能是不正义的。
著名德意志哲学家,德国古典哲学创始人伊曼努尔·康德认为:人,是目的本身,即在任何时候任何人(甚至上帝) 都不能把他只是当作工具来加以利用。若是牺牲少数来保护多数,那不正是把少数人放在了可以随时被“牺牲”、被消耗的“工具”的位置上吗?恶也油然而生。这样的行为无论如何加以粉饰也不可能被称之为正义。人同样存在最高权力,高过任何外界利益总和。我们拥有我们自身,是自由的个体。在此基础上可以构建出人人平等的前提,所以“使社会利益最大化”的行为,即牺牲少数保护多数并非正义。
常常有一句话说“公平即正义”,但是其逻辑性趋近于无。“正”即合于法则的(合于法律的)、规矩的(指相对的两方面中积极的一面),而“义”则是公正合宜的道理或举动(合乎正义或公益的)。所以可以得出正义是指合于法则的公正合宜的行为。而公平,“公”与“私”相对,指属于国家或集体的;“平“则是指一般的,故而“公平”的意思是指集中而大多适用的道理。自然“牺牲少数保护多数”的行为只属于公平而非正义。
我们可以举一个例子,为了救活十个即将饿死的人,杀死其中一个人作食物给另外九个人吃,这样做对吗?从结果上看,活下来的人数比死去的人多,似乎就应该按照这样的办法去做。不过我们可以深思一下,假若按照上述价值观去做,虽然短时间内使社会利益得到了最大化,但是如此侵犯个人的基本权利最终会使社会整体幸福度降低。从长远看,若这种做法流行起来,社会将变得鸡犬不宁人人惶惶不可终日。
最后,我们社会的发展,社会的价值的提升,并不是通过牺牲少数人,牺牲弱势群体来达到的,而是通过平衡社会中不同阶级之间的关系,来使社会达到一种动态的平衡。当弱者出现时我们每个人献出一点爱让他们变得强大。当少数人的利益与多数人的利益冲突时,我们虽然会使少部分人做出牺牲来达到利益的最大化,但是我们不会自诩正义,我们心中会永远记得那些为多数而牺牲的少数,并为补偿他们而不懈奋斗着,因为“无正当补偿便不能剥夺”原则是对共同利益的最好保护。那些剥夺了他人的权益还自称正义的人是这个世界上最大的暴徒。
综上所述,我方认为牺牲少数保护多数是不正义的。谢谢!
牺牲少数保护多数是不正义的——一辩发言
https://www.ordchaos.com/posts/bff2b1a/
哇!是毕业旅行!
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
初三毕业,结束了忙碌的一年,老师带我们全班去了青岛毕业旅行!
前情提要
武汉今年中考在六月的二十、二十一、二十二号总共三天,考完以后休息放纵两日后,我们全班便踏上了高铁前往青岛。
怎么说呢……说是六天五夜,但武汉与青岛之间的高铁要坐8小时,所以第一天和最后一天都相当于是在高铁上玩一天手机(雾
Day 1 & 2
我们在武汉站登车,高铁从上午十一点一直开到了晚上七点。好在酒店离高铁站很近,走路也就5分钟路程,所以我们就前往了酒店开房。
该说不说,4个人挤双人房的安排是有点逆天的。就算我们没意见,酒店也没意见?!
第二天起来吃了早饭之后我们便走路前往了海边,很近,不过不是海滩。拍了几张照,早上天气真的很差,本来是小雨的天气,结果雨越来越大,风也越来越强。但过了一会天又晴了……
然后就是非常晒人。
下午乘坐青岛地铁去了中山公园附近的沙滩。只能说不愧是夏天,晚上五六点仍然晴空万里。
玩水玩得非常开心,不过也仅限于在海水中跑一跑了。毕竟我可不想和部分其他同学一样弄得浑身湿透。
请同学拍了两张照!
Day 3
走路去了圣弥勒尔大教堂,不过也没进去,就是在外面拍了几张照。
风景很不错,宝宝喜欢妈妈爱。
以及本来还以为会碰到什么传教士什么的,然后我就能回一句”我信铂金龙神巴哈姆特“(大雾,结果没有。
然后就去了老舍故居,看到了《骆驼祥子》相关的很多文物(?)。得亏武汉今年考的是《钢铁是怎样炼成的》,不是《骆驼祥子》,没有被祥子一车创si。
然后就是坐地铁回酒店了,这次是从人民会堂到青岛站。
下午去坐船了,不大不小的船。
我只想说,快艇我不晕,轮船我不晕,所以就是这种两者之间的会晕是吗!!!
下午天气很不好,在海上飘着,外面还下大雨,甚至打雷……
坐了四小时,而后从原港口下了船,感觉像是自找了四小时的罪受,艹。
回酒店后第一时间点了外卖,不然真感觉要吐了。
Day 4
又是地铁!这几天地铁成了我们唯一的陆上交通工具,别的旅行团都会有大巴什么的,我们没有,我们就是坐地铁(
还是人民会堂站下车,这次我们去了小青岛公园。公园环境很好,玩得很开心,甚至还去看了鱼雷洞。
以及走的时候发现了一条绿意盎然的楼梯,拍了张照,很好看(
下午坐一号线去了台东,去了步行街吃晚饭。
兴致突然起来了,和同学一起买了地铁票进站而非使用手机app. 运气挺好,买到了不一样样式的单程票。
下车之后全班就直接分组分头行动了。穿梭于人来人往的小吃摊中,感受到烟火气的缭绕,对于一个忙碌了一整年的初三学生来说实在是太酷啦!
买了铁板豆腐、臭豆腐、鱿鱼和青岛啤酒,香的嘞。
然后去了五四广场,再之后就又回了酒店。
Day 5
又去了海边,不过是坐地铁去的,三号线转二号线。
所以又收集(?)到了两款不一样的地铁票。
还有在五四广场同站换乘。
说实话,天气真的不好,海边景色这几天也看腻了(
浅浅拍了几张照之后就坐地铁回去了,以及又收集到了一种地铁票。
下午老师组织看电影,一起看了端午档的《消失的她》
悬疑片嘛……不是很和我胃口,但是观感还不错。
然后就是吃完饭。老师给了每人80的预算,让分组一起吃晚饭,我就和另外三个同学一起去了海底捞。
第一次去海底捞,服务很好,很符合我的期待,价格也正常,不算很贵,起码没超预算。
点了两个菌菇和麻辣两个汤底,味道就很正常,跟我家里和父母一起煮的火锅差不多。
最后还送了一份面条,海底捞真的,我哭死(大雾
师傅的手艺很好,观赏性十足,爱了爱了。
随便贴几张图吧:
Day 6
早起前往高铁站,赶十点的高铁。
天气阴了这么多天,结果偏偏走的时候才好,我的评价是,6.
坐的复兴号高铁,不过站台另一侧有一辆绿皮火车,于是拍了一张个人觉得很好看的照片:
然后又是玩了一天手机……
最后,晚上6点,回到武汉,与老师同学告别后回到了家,结束了这一场旅行。
题外话
生活记录型的博文,尤其是这么长的,我还是第一次写,有什么不足请多多海涵!
什么?你问中考?
请观阅以下内容:
你说的对,但是《中考》是由武汉教育局自主研发的一款「互联网时代」全新开放世界冒险游戏。游戏发生在一个被称作「HappyPark」的幻想公园,在这里,被「往上提的溢水杯」选中的人将被授予「0.797g沉淀」,导引「两种酸」之力。你将扮演一位名为「有两块抹布的直径0.3m的扫地机器人」的神秘角色,在面积27m2的秘鲁考古遗址中邂逅的紫甘蓝味软糖,和百万年前出士的bright flowers化石一起,找回「简练明快,势巧形密」的家书同时,感受「尽责地爱」,且逐步发掘「点P过定线」的真相。
怎么说呢,今年的题真的很创人。
所以……考的差一点也不要紧啦,哈哈……
···
啊?你真以为我考砸了?
886!
哇!是毕业旅行!
https://www.ordchaos.com/posts/c2e7460a/
前、后与中——表达式求值
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
记录一下最近的练习程序与做法,加深记忆,也当个教程吧,毕竟赠人玫瑰手留余香(bushi
如果你不知道这些表达式分别指什么东西,可以百度一下,这里不再赘述。
后缀表达式
这个应该是最常见的了,下面讲一下实现。
首先,还是定义函数废话:
然后,进行文件读取,可以用freopen(),不过我这里用的是fopen():
1
2
3
4
5
6
7
8
9
10
| FILE* stream = fopen("input.txt", "r");
stack<double> nums;
while(true) {
char tstr[100];
fscanf(stream, "%s", tstr);
if(feof(stream)) break;
string input = tstr;
}
|
解释一下上面的程序:
stack<double> nums 这个栈后面会用到,这里先不用管fscanf()和scanf()用法一样,唯一的区别是fscanf()用于读取文件流中的信息而非输入流feof()中的参数为文件流,用于判断是否读到结尾,读到则返回真
很显然,这段程序用于分别读入每一段字符,那么接下来便是判断输入了。
代码如下:
1
2
3
4
5
6
7
8
9
10
| while(true) {
if(isdigit(input[0])) {
nums.push(atof(input.c_cstr()));
}
else {
}
}
|
如果输入为整数,则进入数字栈,否则开始计算。
这里使用了isdigit()函数,输入为char类型,用于判断参数是否在'0'与'9'之间。
计算过程很简单,弹出两个数字栈中的数,根据运算符计算即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
else {
double y = nums.top();
nums.pop();
double x = nums.top();
nums.pop();
double temp;
switch(input[0]) {
case '+':
temp = x + y;
break;
case '-':
temp = x - y;
break;
case '*':
temp = x * y;
break;
case '/':
temp = x / y;
break;
}
nums.push(temp);
}
|
尤其要注意减法与除法的操作数与被操作数顺序,毕竟它们可没有交换律。
此时已经计算完成,结果作为栈中唯一的元素处在栈顶,直接输出即可:
1
2
3
4
| fclose(stream);
cout<<nums.top()<<endl;
return 0;
|
大概就是这样。
完整代码还是放一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| #include<bits/stdc++.h>
using namespace std;
inline bool is_num(string str) {
if(str[0] >= '0' && str[0] <= '9') return true;
else return false;
}
int main() {
FILE* stream = fopen("input.txt", "r");
stack<double> nums;
while(true) {
char tstr[100];
fscanf(stream, "%s", tstr);
if(feof(stream)) break;
string input = tstr;
if(is_num(input)) {
nums.push(atof(input.c_str()));
}
else {
double y = nums.top();
nums.pop();
double x = nums.top();
nums.pop();
double temp;
switch(input[0]) {
case '+':
temp = x + y;
break;
case '-':
temp = x - y;
break;
case '*':
temp = x * y;
break;
case '/':
temp = x / y;
break;
}
nums.push(temp);
}
}
fclose(stream);
cout<<nums.top()<<endl;
return 0;
}
|
输入样例:
输出样例:
前缀表达式
细心一点就能发现,它与后缀表达式几乎一样,只是顺序不同。
没错,这正是因为前、后、中缀表达式分别为表达式树的先序、后续与中序遍历。
利用这个性质,将后缀表达式的顺序稍稍更改即可得到前缀表达式求值的程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| #include<bits/stdc++.h>
using namespace std;
inline bool is_num(string str) {
if(str[0] >= '0' && str[0] <= '9') return true;
else return false;
}
int main(){
FILE* stream = fopen("input.txt", "r");
stack<double> nums;
vector<string> input;
while(true) {
char tstr[100];
fscanf(stream, "%s", tstr);
if(feof(stream)) break;
input.push_back(string(tstr));
}
for(int i = input.size() - 1;i >= 0;i--) {
if(is_num(input[i])) {
nums.push(atof(input[i].c_str()));
}
else {
double x = nums.top();
nums.pop();
double y = nums.top();
nums.pop();
double temp;
switch(input[i][0]) {
case '+':
temp = x + y;
break;
case '-':
temp = x - y;
break;
case '*':
temp = x * y;
break;
case '/':
temp = x / y;
break;
}
nums.push(temp);
}
}
fclose(stream);
cout<<nums.top()<<endl;
return 0;
}
|
改成倒序读取即可。
输入样例:
输出样例:
中缀表达式
我们最常用的表达式,处理起来却是最复杂的,因为现在需要考虑优先级与括号了。
这里有几种方法:
递归
首先,定义函数用于取多项式的因子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| int factor() {
int res = 0;
char c = cin.peek();
if(c == '(') {
cin.get();
res = expression();
cin.get();
}
else {
while(isdigit(c)) {
res = 10 * res + c - '0';
cin.get();
c = cin.peek();
}
}
return res;
}
|
先定义结果为0,然后判断输入。若为括号,则将其内容视为新表达式,交由马上要定义的expression()函数计算。否则,按位取出输入中的数即可。
顺带一提,这些代码中的cin.get()与cin.peek()尤其重要,切勿移动位置或轻易替换。至于原因,自己模拟想一下吧。
然后,计算单项式的值,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| int term() {
int res = factor();
while(true) {
char mark = cin.peek();
if(mark == '*' || mark == '/') {
cin.get();
int v = factor();
if(mark == '*') res *= v;
else res /= v;
}
else break;
}
return res;
}
|
先用factor()函数读入因子,然后循环判断该单项式是否读完。若未读完(即该因子与下一个因子间仍用乘号或除号连接)则取下一个因子并计算,否则返回该单项式的值即可。并且很显然,这样的写法就代表输入的表达式中不应当含有任何空格,也只支持整数运算(要浮点数自己改我不干了)。
最后是整个表达式,与计算单项式基本一样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| int expression() {
int res = term();
while(true) {
char mark = cin.peek();
if(mark == '+' || mark == '-') {
cin.get();
int v = term();
if(mark == '+') res += v;
else res -= v;
}
else break;
}
return res;
}
|
读入单项式再计算,直到该表达式计算完毕(即mark取到)或EOF)
主函数其实已经一目了然了,重定向输入再调用expression()即可,就不写了。
输入样例:
输出样例:
栈
这里又分为两种方案:
转为后/前缀表达式再计算
这里的重点是转换的过程,逻辑整体如下(中缀->后缀):
- 输入若为数字,直接放入输出表达式中。若为符号:
- 如果符号栈为空,则放入符号栈中
- 如果符号栈栈顶元素优先级大于等于该符号,则出栈栈顶符号放入表达式,若此时栈顶符号优先级大于等于该符号,则重复以上流程直至小于,而后入栈该符号
- 如果符号栈栈顶元素优先级小于该符号,该符号入栈
- 如果该符号为左括号,直接入栈
- 如果该符号为右括号,则依次出栈符号栈栈顶元素放入表达式中,直至左括号。最后抛弃左括号与右括号
- 若输入完毕,符号栈中仍有符号,则依次出栈放入表达式
代码如下(转为后缀表达式):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| map<char, int> markl;
markl['+'] = 0;
markl['-'] = 0;
markl['*'] = 1;
markl['/'] = 1;
FILE* stream = fopen("input.txt", "r");
stack<char> marks;
vector<string> expression;
while(true) {
char tstr[100];
fscanf(stream, "%s", tstr);
if(feof(stream)) break;
string input = tstr;
if(isdigit(input[0])) {
expression.push_back(input);
}
else if(input[0] == '(') {
marks.push('(');
}
else if(input[0] == ')') {
while(true) {
if(marks.top() == '(') {
marks.pop();
break;
}
char t[2] = {marks.top(), '\0'};
expression.push_back(string(t));
marks.pop();
}
}
else {
if(marks.empty() || marks.top() == '(') {
marks.push(input[0]);
}
else if(markl[input[0]] <= markl[marks.top()]) {
while(!marks.empty() && markl[temp[0]] <= markl[marks.top()]) {
char t[2] = {marks.top(), '\0'};
expression.push_back(string(t));
marks.pop();
}
marks.push(input[0]);
}
else {
marks.push(input[0]);
}
}
}
while(!marks.empty()) {
char t[2] = {marks.top(), '\0'};
expression.push_back(string(t));
marks.pop();
}
|
和上面的逻辑完全一样,唯一要注意的是这里使用了map,可以理解为字典。
然后只需要计算就行,代码就不放了。
前缀表达式的逻辑与代码可以自己想想。
输入输出样例同下面。
直接计算
逻辑和转换本身是一样的,只不过没有了表达式向量,而是直接计算后放入数字栈。
即将所有的对于expression的操作改为计算即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
| #include <bits/stdc++.h>
using namespace std;
double calc(char mark, double x, double y) {
double temp = 0;
switch(mark) {
case '+':
temp = x + y;
break;
case '-':
temp = x - y;
break;
case '*':
temp = x * y;
break;
case '/':
temp = x / y;
break;
}
return temp;
}
int main() {
FILE* stream = fopen("input.txt", "r");
map<char, int> markl;
markl['+'] = 0;
markl['-'] = 0;
markl['*'] = 1;
markl['/'] = 1;
stack<char> marks;
stack<double> nums;
while(true) {
char tstr[100];
fscanf(stream, "%s", tstr);
if(feof(stream)) break;
string temp = tstr;
if(isdigit(temp[0])) {
nums.push(atof(temp.c_str()));
}
else if(temp[0] == '(') {
marks.push('(');
}
else if(temp[0] == ')') {
while(true) {
if(marks.top() == '(') {
marks.pop();
break;
}
double y = nums.top();
nums.pop();
double x = nums.top();
nums.pop();
nums.push(calc(marks.top(), x, y));
marks.pop();
}
}
else if(marks.empty() || marks.top() == '(') {
marks.push(temp[0]);
}
else if(markl[temp[0]] <= markl[marks.top()]) {
while(!marks.empty() && markl[temp[0]] <= markl[marks.top()]) {
double y = nums.top();
nums.pop();
double x = nums.top();
nums.pop();
nums.push(calc(marks.top(), x, y));
marks.pop();
}
marks.push(temp[0]);
}
else {
marks.push(temp[0]);
}
}
while(!marks.empty()) {
double y = nums.top();
nums.pop();
double x = nums.top();
nums.pop();
nums.push(calc(marks.top(), x, y));
marks.pop();
}
fclose(stream);
cout<<nums.top()<<endl;
return 0;
}
|
输入样例:
1
| ( 28 / 7 ) / 2 + ( 8 - 9 )
|
输出样例:
收工!
题外话
这篇大概是我最长的纯原创技术类博文了。。。。。。
好累QAQ
下次再见啦!886!
2023.04.03更新
让ChatGPT改了一个支持浮点数的递归版本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
| #include <iostream>
#include <cstdlib>
#include <cstdio>
using namespace std;
void print_tab(int);
void print_log(string, int);
void print_log(string, int, double);
double expression(int);
double term(int);
double factor(int);
int main() {
freopen("input.txt", "r", stdin);
cout << expression(0) << endl;
return 0;
}
void print_tab(int deep) {
for(int i = 0;i < deep;i++) {
cout << "\t";
}
return;
}
void print_log(string name, int deep) {
print_tab(deep);
cout << name << " {" << endl;
return;
}
void print_log(string name, int deep, double res) {
print_tab(deep);
cout << "} -> res =" << res << endl;
return;
}
double expression(int deep) {
print_log("expression", deep);
double res = term(deep + 1);
while(true) {
char mark = cin.peek();
if(mark == '+' || mark == '-') {
cin.get();
double v = term(deep + 1);
if(mark == '+') res += v;
else res -= v;
}
else break;
}
print_log("expression", deep, res);
return res;
}
double term(int deep) {
print_log("term", deep);
double res = factor(deep + 1);
while(true) {
char mark = cin.peek();
if(mark == '*' || mark == '/') {
cin.get();
double v = factor(deep + 1);
if(mark == '*') res *= v;
else res /= v;
}
else break;
}
print_log("term", deep, res);
return res;
}
double factor(int deep) {
print_log("factor", deep);
double res = 0;
double base = 1.0;
char c = cin.peek();
if(c == '(') {
cin.get();
res = expression(deep + 1);
cin.get();
}
else {
while(isdigit(c) || c == '.') {
if(c == '.') {
cin.get();
c = cin.peek();
while(isdigit(c)) {
res = res + (c - '0') * (base /= 10.0);
cin.get();
c = cin.peek();
}
break;
}
res = res * 10 + c - '0';
cin.get();
c = cin.peek();
}
}
print_tab(deep + 1);
cout << "get_num();" << endl;
print_log("factor", deep, res);
return res;
}
|
神
前、后与中——表达式求值
https://www.ordchaos.com/posts/c9c6cb4f/
浅探魏晋名士的精神世界
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
提起魏晋,“名士风流”四个字是现代人对它的基本认知,在中华民族几千年的历史长河中,也唯有魏晋南北朝时期独有的世族门阀在政治、经济、文化领域与皇权分庭抗礼甚至占主导地位的条件下,才能形成“魏晋风度”这一独特的文化现象。代表家族如王谢世家,代表人物如竹林七贤等,除了留下大量诗歌、书法、音乐等文化遗产外,还留下了处变不惊、旷达任率、不拘礼法、风神潇洒、不滞于物的精神风貌和思想风格供后世研究探讨。
魏晋名士如此“特立独行”的精神世界,它的形成有一个长期过程。东汉末年开始的南北分裂和战乱,党锢之祸、黄巾起义、三国鼎立、司马氏篡权,百多年的血雨腥风,动荡不安,使“汉末名教”作为思想束缚的礼教开始崩塌,士人们不再对皇权盲目崇拜,开始拥有了自我意识,而其中一些有识之士不安于现状,不断追求思想上的创新与突破。他们会去对规则本身的合理性进行考虑,以探寻规则外的广阔天地;他们不仅行为上不愿再受规则的束缚,精神世界也同样不甘压迫;他们开始探索宇宙自然与人生本体的关系,追求新的思辨哲理。
现在看这些名士们的行为,可以发现其实连带着魏晋风度本身,有些只是反常的叛逆性极强的怪异举动,可以认为是在名教长时间压迫下的剧烈反弹。甚至会出现一些较为过激的行为,如在《世说新语》任诞篇中对刘伶的记载:“刘伶恒纵酒放达,或脱衣裸形在屋中。人见讥之,伶曰:我以天地为栋宇,屋市为裈衣,诸君何为入我裈中?”如此行为,只能称得上是“率性而为,任诞放达”了,其叛逆性之强不容否认。
除了战乱,魏晋时期残酷的政治清洗同样令人不安,无论是个人的生命还是家族的命运,全都在统治者、权贵的争权夺势中难以独善,所以魏晋士人在放达不羁的行为中也折射出深深的忧惧和哀伤。故而反抗礼教的名士们便只得走向崇尚老庄,酗酒佯狂,傲啸山林,不与时务的道路,个人认为,这一点是促成魏晋风度中“隐居”行为的重要因素。而从嵇康的性情刚直,阮籍纵酒放达等都能看出些许佐证。
在这样政治黑暗,礼教束缚的年代,尽管出现了文人集体失语的现象,但魏晋名士的特点就是不会停止对成为累赘的礼教的批判与反抗,不会停止对自由人格的永恒追求。在魏晋名士眼中,自由就是顺从自己的天性,任性而为,随心而动。他们具有超脱世俗自由独立的人格理想,所以能一边否定外界社会一边重构自我人格,“人生贵得适意尔”。随着道教的兴起、佛教的传入,开创出儒道互补的士大夫精神,奠定了中国知识分子的人格基础,不可不谓影响深远。
当然任何事情都有其两面性。对于魏晋名士的思想和行为,被后世最为诟病的是“五石散”的服用和空谈玄理的风气。或出于养生、或出于美容、或出于对长生的追求、或出于身份地位的昭示,士人们刻意忽视它的副作用,使服用五石散成为一种“时尚”,造成了了大量人力物力的浪费和对身体的伤害。甚至连家境并不富裕、买不起五石散的人们都会争相模仿:当众倒地,自称“石发”。闹出不少笑话。在《太平广记》中《启颜录﹒魏市人》便有“有一人,于市门前卧,宛转称热”的记载,可见一斑。而魏晋名士的清谈,考验的是口才和思辨,但从开始的成就自己的政治抱负发展到只关心自己一家一姓一族的得失,崇拜浮虚、寄情酒色、不管国事,致使朝野颓唐,甚至间接导致了西晋的亡国,从此流传下来“清谈误国”这句话。
动荡时期的不安全处境和残酷的政治斗争中,要么顺应环境保全生命,要么纵情于山水追求的精神解放,要么饮酒服药带来短暂的麻痹,这种焦灼矛盾的状态或许就是魏晋名士精神世界的形成原因,我们在研究和探索的过程中,不应该将狂放、酗酒、服药等视为风流,而忽视了它所产生的时代背景,不能只看到他们狂放洒脱的一面,更要看到深刻沉重的一面。
我认为,魏晋名士之所以为名士,不是因为不羁和自由,而是因为才学。如竹林七贤中阮籍的诗歌、山涛的文集、嵇康的文集和音乐等等,更有世家中的高门大户王家的书法和谢家的政治成就。但是他们中的大多数却选择清谈、避世,选择隐居甚至堕落。精神上的虚无主义,使他们留名后世,却在当时无所作为,未能为动荡的社会做些什么,亦未能解救悲苦的百姓。历史上每逢乱世,必会产生开放的思想,并由此造福于百姓,有破有立。唯有魏晋名士,思想开放却是破而未立。他们的反抗仅仅只是反抗,却未有切实可行的主张去改变社会现状。
所以,魏晋风度对当世可能仅仅是一种浮于表面的行为艺术,一种看破世俗的有识之士的无能呐喊,一场雷声大雨点小的思想革命。虽然为后世留下了丰富的文学经典,但却几乎未在当时的社会中产生任何正向作用。名士们的精神世界中除了繁多的思想外,难说是否有未民生的思考,抑或是仅仅停留在了“人生贵得适意尔”的“适意”上。故而我们既要学习他们对自由与创新的向往,更要善于学习,善于以辩证的思想去看待他们本身、他们的行为及他们的精神世界,而非盲目追随。
浅探魏晋名士的精神世界
https://www.ordchaos.com/posts/d29e300c/
学习笔记——树
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
树tree
介绍
- 由n(n>0)个元素组成的有限结合,是一种非线性的有序结构。
- 每一个其中的元素都被称为结点,除根节点外,其余节点组成的子集称为子树。
- 一棵树由根节点与结点组成,除根节点外每个节点都有前驱结点。一棵树至少有一个节点,此时,该节点即为根节点。换而言之,每棵树有且仅有一个根节点。在一个m层k叉数中最多有1−k1−km+1个节点(k>=1, m>=0)。
- 树是递归定义的,即在一棵子树中,其根节点同样在树中作为结点。
- 一个节点的子树个数称为这个节点的度(degree)。度为零的节点称为叶节点(leaf),不为零的节点称为分支节点(包括根节点),根以外的分支节点被称为内部节点。一棵树中度最大的节点的度被称为这棵树的度。
- 树状结构的图形中,连接两个相关联的结点的线段称位树枝。上端节点为下端节点的父节点,相对应的下端节点为上端节点的子节点,同一个父节点的所有子节点互为兄弟结点。从根节点出发到某个子节点所经过的所有节点均为该子节点的祖先,同理,此此节点为其所有祖先的子孙。
- 一棵树中根节点的层次(level)为0,其余的节点的层次为其父节点的层次加1。与度一样,树中层次最大的节点的层级被称为树的深度(depth)。
- 在树中,从一个节点出发,自上而下的沿着节点与树枝可以到达另一节点,则称它们间存在一条路径(所以显而易见不同子树上的节点间不存在路径)。用路径上的节点个数减一(即树枝个数,或是用层级较大的节点的层数减去较小的节点的层数)表示路径长度。
- 互不相交的数的集合称为森林,即森林是m棵互不相交的树的集合。
如下图即为一颗经典的树:
存储结构
父亲表示法
1
2
3
4
| #define MAX_LENGTH 10
struct node {
int data, father;
}tree[MAX_LENGTH];
|
这种方法容易找到树根,但是找孩子就需要遍历整个线性表,即时间换空间
孩子表示法
1
2
3
4
5
6
7
8
| #define MAX_DEGREE 10
struct node {
int data;
node* children[MAX_DEGREE];
};
struct tree {
node* root;
}t;
|
这种方法不可以从子节点返回父节点
父亲孩子表示法
1
2
3
4
5
6
7
8
| #define MAX_DEGREE 10
struct node {
int data;
node* children[MAX_DEGREE], father;
};
struct tree {
node* root;
}t;
|
是孩子表示法的优化版,可以直接访问任意子节点的父节点,是一种空间换时间的方法
孩子兄弟表示法
1
2
3
4
5
6
7
| struct node {
int data;
node* firstChild, next;
};
struct tree {
node* root;
}t;
|
总结
这些方法没有好坏之分,应当视情况选用
遍历
- 先序遍历(深度优先搜索dfs,从左至右先输出再搜索)
- 后序遍历(深度优先搜索dfs,从左至右先搜索到叶节点再依次输出并回溯)
- 层次遍历(广度优先搜索bfs,按层次从左至右搜索,搜索完一层后搜索下一层)
- 叶节点遍历(按先序遍历的方法遍历,但只访问叶节点)
题外话
这玩意是放暑假前在学校无聊看《信息学奥赛一本通》写的,大概还是有参考价值的吧。
另外还有一篇二叉树的,大概也会发上来。
学习笔记——树
https://www.ordchaos.com/posts/d4140423/
无需流量费用!阿里云 oss 图床配合阿里云轻量应用服务器部署
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
我已经有了一台阿里云的香港轻量应用服务器,正好阿里云oss内网下行流量免费,再加上oss上行流量同样免费,于是就可以在省掉所有的流量费用的同时获得一个拥有不错速度的私人图床。
创建
打开阿里云oss页面,点击bucket列表,选择创建bucket:
名称随意,但是地域要选择于自己的服务器相同的地区,这样才可以通过内网访问。存储类型选择标准存储,读写权限选择公共读,其余一律默认。
oss桶默认是按量计费,标准可以参考官方文档。你也可以像我一样购买资源包,点击资源包管理,再在新页面中点击购买资源包:
然后在资源包类型一栏中选择标准(LRS)存储包,其余按需选择即可:
一年仅需9元,个人认为十分划算。
此时存储桶便已创建完成。
服务器反向代理
内网下行流量免费,所以我们要先访问内网,通过服务器反向代理就可以做到这一点。这里通过宝塔面板进行配置。
点击侧栏的网站,然后点击新建站点:
域名填写最终用来访问图片的域名,如这里的 assets.ordchaos.com。其余默认即可,然后选择提交。
之后点击对应网站的设置——反向代理——添加反向代理。名称随意填写,目标URL填写内容如图所示:
填写对应的内网Bucket域名。
然后点击提交即可。也可以配置缓存,在添加反向代理时点击开启缓存并配置时间就可以了。记得在域名供应商那里添加对应的域名解析到服务器上。
之后可以配置SSL证书,在SSL页面自行配置即可。现在你的桶已经可以通过反向代理来访问了,下面我们来做一些额外的工作。
PicGo配置
PicGo作为一个图片上传工具是非常不错的,拓展性很高。同时作为一款开源软件,其发布在了GitHub上。这里默认已经安装完成了PicGo。
安装S3桶插件
打开PicGo,点击“插件设置”,在搜索框中搜索“s3”,安装第一个就可以了:
我这里安装过了,所以就显示的是“已安装”。这个插件支持所有s3桶,包括阿里云oss。其实可以直接配置阿里云oss,但是使用s3插件可以自动按规则重命名文件。
获取配置信息
把鼠标移到右上角头像上悬浮,在出现的界面上点击访问控制:
然后点击侧栏的用户,再点击创建用户:
登陆名称与显示名称随意,然后勾选下方的“Open API 调用访问”:
点击确定,验证身份,然后就会出现AccessKey ID 与 Secret,记得保存下来:
然后返回到用户管理页面,点击刚刚创建的RAM账号旁边的添加权限,然后添加控制oss桶的权限即可:
配置PicGo图床
点击图床设置-AmazonS3,填写对应参数即可,大致如下:
- 应用密钥ID:上述获取到的AccessKey ID
- 应用密钥:上述获取到的AccessKey Secret
- 桶:你创建的oss桶的名字
- 权限:public-read(桶权限,公共读)
- 地区:在对应桶的概览页面可以看到桶的外网访问Endpoint,假设是 oss-xxx.aliyuncs.com,则地区为oss-xxx
- 自定义节点:上述的Endpoint
- 文件路径:{year}/{month}/{md5}.{extName}(默认上传到桶的文件路径,格式如下:)
| 格式 | 描述 |
|---|
{year} | 当前日期 - 年 |
{month} | 当前日期 - 月 |
{day} | 当前日期 - 日 |
{fullName} | 完整文件名(含扩展名) |
{fileName} | 文件名(不含扩展名) |
{extName} | 扩展名(不含.) |
{md5} | 图片 MD5 计算值 |
{sha1} | 图片 SHA1 计算值 |
{sha256} | 图片 SHA256 计算值 |
然后点击确定并设为默认图床即可。
大功告成!之后只需要在“上传区”页面就可以一键上传图片并复制链接了。
题外话
目前全站图片都已更换为阿里云oss存储,不得不说速度是真的快。
还有这大概是我目前图最多的一篇博文了吧。
无需流量费用!阿里云 oss 图床配合阿里云轻量应用服务器部署
https://www.ordchaos.com/posts/d9bb8734/
C++ 数组实现队列
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
队列是常用的数据结构,是广度优先算法中不可或缺的一部分。队列一般使用数组或链表构建,这里会介绍使用数组实现队列的方法。
结构搭建
首先,定义队列结构:
1
2
3
4
5
6
7
| #define MAXSIZE 10000
struct myqueue {
int first;
int last;
int v[MAXSIZE];
};
|
变量first指向首项,last指向尾项其实不是,数据则存在数组v中。为了防止数据溢出,此时定义数组v的范围要尽量大,此处是10000。
再就是初始化队列:
1
2
3
4
| void init(myqueue &t) {
t.first = t.last = 0;
return;
}
|
让first与last都指向数组开头的第0项,很好理解。
之后,开始数据操作。第一个是push函数,将数值存入队列的最后:
1
2
3
4
5
| void push(myqueue &t, int s) {
t.v[t.last] = s;
t.last++;
return;
}
|
注意将last指向后面一项,此时变量last始终指向队列最后一项的下一项,是一个空值。
第二个是pop函数,删除队列首项。不过这里有一个坑,如果队列为空删除便有可能出错,所以要先判断队列是否为空:
1
2
3
4
5
6
7
8
9
10
| bool isempty(myqueue &t) {
if(t.last == t.first) return 1;
else return 0;
}
void pop(myqueue &t) {
if(isempty(t)) return;
t.first++;
return;
}
|
判断队列是否为空很简单,当first=last时,有队列为空(队列非空时,last在最后的数据项的后一位,所以first不可能等于last)。
pop时只需要移动首项的标识,避免了繁琐的数据移送,也无需置空数组的某一项,原因显而易见。但永远抛弃了一部分内存,故而要小心溢出。
再就是获取队列的首项、尾项、第n项以及长度,代码相对简单:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| int getf(myqueue t) {
return t.v[t.first];
}
int getl(myqueue t) {
return t.v[t.last - 1];
}
int getn(myqueue t, int n) {
return t.v[t.first + n];
}
int getlength(myqueue &t) {
return (t.last - t.first);
}
|
这里对于长度的获取需要说一下,理论上长度应当是(last - first + 1),但这里last本身就是数据项的后一项,所以自然就省掉了。
解决问题
现在整个队列已经完全可用了,我们可以尝试用其解决一些实际问题。
问题背景
有n(n <= 100)个小朋友排队打针,他们每个人都有依次自己的编号为1, 2, 3, 4, …, n。他们都很害怕打针,所以当排在自己前面的小朋友打针时就会跑走到队伍最后。试设计一程序,输入小朋友数量,输出他们打针的顺序。
样例输入:5
样例输出:1 3 5 4 2
问题分析
很显然,这样需要模拟过程的题目用队列解答会非常容易,直接使用队列出入队模拟这一过程即可。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| int main() {
myqueue test;
init(test);
int n;
cin>>n;
for(int i = 1;i <=n;i++) push(test, i);
for(int i = 1;!isempty(test);i++) {
if(i%2 == 0) {
int temp = getf(test);
pop(test);
push(test, temp);
}
else {
cout<<getf(test)<<" ";
pop(test);
}
}
return 0;
}
|
代码比较简单,关键还是在于前面对整个队列结构的搭建。
总结
队列的用处非常大,后面广度优先算法也会用到,建议多理解、多练习,掌握的越熟练越好。
本次完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| #include <bits/stdc++.h>
using namespace std;
#define MAXSIZE 10000
struct myqueue {
int first;
int last;
int v[MAXSIZE];
};
void init(myqueue &t) {
t.first = t.last = 0;
return;
}
bool isempty(myqueue &t) {
if(t.last == t.first) return 1;
else return 0;
}
void push(myqueue &t, int s) {
t.v[t.last] = s;
t.last++;
return;
}
void pop(myqueue &t) {
if(isempty(t)) return;
t.first++;
return;
}
int getf(myqueue t) {
return t.v[t.first];
}
int getl(myqueue t) {
return t.v[t.last - 1];
}
int getn(myqueue t, int n) {
return t.v[t.first + n];
}
int getlength(myqueue &t) {
return (t.last - t.first);
}
int main() {
myqueue test;
init(test);
int n;
cin>>n;
for(int i = 1;i <=n;i++) push(test, i);
for(int i = 1;!isempty(test);i++) {
if(i%2 == 0) {
int temp = getf(test);
pop(test);
push(test, temp);
}
else {
cout<<getf(test)<<" ";
pop(test);
}
}
return 0;
}
|
C++ 数组实现队列
https://www.ordchaos.com/posts/da7075f0/
满十四,进十五。愿我青春无悔,不负韶华
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
又大了一岁呢…
令青春无悔,愿韶华不负!
希望明年的此刻,我能够无愧于自己。
满十四,进十五。愿我青春无悔,不负韶华
https://www.ordchaos.com/posts/e84bad58/
Phigros 版本迁移——从 Google Play 到 Tap Tap
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
起因
Google Play的版本更新总是慢一些,不知道你行不行,但是我是忍不了别人都玩上了新曲而我却还不能玩的感觉,遂决定迁移存档。
过程
大体参考这一篇文章Phigros存档跨版本转移教程(免root)即可,在这里稍微提一下我遇到的问题
解决问题
在使用abe.jar时,Java报错:
1
| Error: A JNI error has occurred, please check your installation and try again
|
首先在网上查询,找到的第一个方法是删除电脑里共存的JDK,只留下一个,使java -version与javac -version有相同的版本。
我照做,删除了java8,只留下了openjdk17,但是毫无卵用。
于是我继续查询,发现在跨!系!统!转!移!支持安卓和IOS的跨系统存档转移工具!Phigros 存档 IOS 跨系统 备份 还原 转移 同步这一视频中所提供的工具里的abe.jar可用。
总结
如果你也遇到了一样的问题,可以参考我的方法看看是否有效。
若不想下载整个备份工具而只想要abe.jar的话,可以从这里下载:链接(如有侵权,请联系我删除)
Phigros 版本迁移——从 Google Play 到 Tap Tap
https://www.ordchaos.com/posts/e8587b82/
空气成分手抄报
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
化学的暑假作业,浅浅地用sai2摸了一个图出来,大家看看就好。
空气成分手抄报
https://www.ordchaos.com/posts/e8ce405d/
使用Github Action定时重启邮件服务
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
主要是邮件服务器的容器经常崩溃,所以尝试设置定时任务来解决这个问题。
情景引入
邮件服务器性能羸弱,无法胜任设置定时任务这样的重担,所以只能用一些盘外招试试了。
设置 Action
那么首先,本着轻量化的原则,新建一个仓库拿来干这种事:
然后切到Action页面:
选择新建一个空白模板:
修改Action名称、内容并设置定时,参考我的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| # This is a basic workflow to help you get started with Actions
name: REMX
# Controls when the workflow will run
on:
# Triggers the workflow on push or pull request events but only for the "main" branch
push:
branches: [ "main" ]
schedule:
- cron: "0 20 * * *"
# Allows you to run this workflow manually from the Actions tab
workflow_dispatch:
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
jobs:
# This workflow contains a single job called "build"
build:
# The type of runner that the job will run on
runs-on: ubuntu-latest
# Steps represent a sequence of tasks that will be executed as part of the job
steps:
- name: Checkout Codes
uses: actions/checkout@v3
- name: Restart MX Service
uses: garygrossgarten/github-action-ssh@release
with:
command: ./restart.sh
host: ${{ secrets.HOST }}
username: root
password: ${{ secrets.PASSWORD }}
- name: Finish
run: echo "Action Finish"
|
SSH相关配置自行查看官方文档
保存,然后去设置Secret:
分别设置服务器地址、密码等即可:
大功告成!
结语
上高中之后就没写博文了……
除夕赶出一篇博文,祝新年快乐!!!
也迟来的祝博客两周年快乐!!!
使用Github Action定时重启邮件服务
https://www.ordchaos.com/posts/e9c784c5/
文章AI摘要?太酷啦!
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
看了HEO的如何让博客支持AI摘要,使用TianliGPT自动生成文章的AI摘要,甚是手痒……整一个!
前情提要
的确,我可以直接把HEO现成的部署方案拿来用,但我是一个有追求的人(雾。事实上,直接使用这种解决方案得到的摘要栏与我博客的设计风格并不是很搭,这就要求我自己写一个前端后端是不可能的,这辈子也不可能的。
好,开干!但首先,第一个问题出现了:我博客的设计风格本身就不太统一。首页的说说轮播和说说页面的数量统计用了fluid主题自带的info,而友链朋友圈页面又没有,直接使用了圆角矩形承载统计信息。
为了解决这个问题,我需要用一样东西代替info标签。经过再三深思熟虑,我选用圆角矩形统一替换info.
而后便有了枯燥的漫长(?)css编写时间:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| div.ocxqntcontainer {
display: flex;
align-items: center;
justify-content: center;
height: auto;
}
div.ocxqnt {
border: 1px solid #e9e9e9;
border-radius: 1rem;
padding: 1rem;
text-align: left;
width: 100%;
}
span.memos-t {
margin: 0 1rem;
}
|
就这样,圆角矩形大功告成。
摘要部署
现在这个步骤就变得很简单了,对于我用的fluid主题,编辑layout/post.ejs即可,在article标签中,类为markdown-body的div标签之前加入以下内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| <style>
i.icon-ordchaos-blog-robot, span.ocxq-ai-title {
font-weight: bold;
font-size: 1.2em;
}
span.ocxq-ai-warn {
font-weight: bold;
}
.ocxq-ai-text.typing::after {
content: "_";
margin-left: 2px;
animation: blink 0.7s infinite;
}
@keyframes blink {
50% {
opacity: 0;
}
}
</style>
<script>
let tianliGPT_postSelector = '#board .post-content .markdown-body';
let tianliGPT_key = '5Q5mpqRK5DkwT1X9Gi5e';
</script>
<div class="ocxqntcontainer">
<div class="ocxqnt">
<span id='memos-t'>
<i class="iconfont icon-ordchaos-blog-robot"></i><span id="memos-index-space"> </span><span class="ocxq-ai-title">AI摘要</span>
<br>
<span class="ocxq-ai-text">
生成中...
</span>
<br>
<span class="ocxq-ai-warn">摘要由AI自动生成,仅供参考!</span>
</span>
</div>
</div>
<br>
<script src="https://www.ordchaos.com/js/aisummary.js"></script>
|
这里有几个问题:
- 为什么内容在
id为memos-t的span标签中:因为它同样套用了刚刚写好的圆角矩形,而这个圆角矩形为了适配原有的memos说说而要求内部文字必须拥有memos-t的id. iconfont icon-ordchaos-blog-robot是什么图标:我在iconfont.cn中取用的,因为加入了我的图标库所以拥有图标库前缀icon-ordchaos-blog,若也想选用的话可以直接在iconfont.cn搜索关键词robot找到并添加到自己的图标库- 为什么不把样式代码写到css里面去:我懒
最后在文件的末尾处加上对js文件的引用。
说到js,由于HEO提供的js文件中含有生成前端容器的部分,所以必须要删除这部分内容并对其做出部分修改。过程这里就不放了,实在看不懂的可以参考我改好的被压缩了怎么看啊自己想办法。
而后去爱发电订阅TianliGPT并将api key填入即可。
效果
题外话
最开始因为不想写css而拖了好久……最终因为实在眼馋,欲望盖过了懒病才动身做完。
话说我这样改别人写好的js应该没问题吧……
那就这样,886!
文章AI摘要?太酷啦!
https://www.ordchaos.com/posts/ec8c9790/
一名初中生的 GitHub 学生包申请之路
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
现在上百度搜索“github学生包申请”,结果要么只适用于大学生,要么就是通过各种国外社区大学的录取通知书来白嫖这不欺骗别人大学感情吗。而作为一名初中生,显然这两种方法都不太适合:前者需要大学学籍,后者…后患无穷且麻烦,成功率也不高。这里我就分享一下我与GitHub学生包的经历以及我的申请经验,帮助更多像我一样被同样问题困扰的人。
我与GitHub学生包
小时候没有零花钱,但又想建站,于是整天在Google、百度、Youtube等等地方搜索“免费域名”、“免费空间”…一类内容。终于,让我发现了GitHub学生包这个东西。然并卵,它有年龄限制(13岁以上),这让当时11岁的我感到弱小可怜又无助。然后我就在Youtube上看到了这个:
哇你知道这对我的内心造成了多大的震撼吗?我立马跟着操作了一番,但是却是在最关键也是最重要的一步上卡住了——人家GitHub没有过我的申请。
后来在别的地方看见了freedom的免费域名与忘记是什么地方的免费空间,用wordpress简单做了一个博客懒得写博文,结果到头来一篇文章也没有,这件事也就告一段落。
去年年中突然想起来这一茬,想到那一年我就13岁了,年龄限制已经跨越,我这正经学生身份还不得通过的手到擒来?然后我就上传了自己绝对真实的申请所需的一切信息,然后…又没有过。其实也不是没有过,单纯是审核了两周还一直状态显示pending,我一怒之下就撤销了申请而已自己不是说最多两周吗,于是这件事就又被放下。
再然后又到了今年年初,又想起GitHub学生包来。我一想到我一个学生申请不到学生包就来气,于是又申请了一次。与上一次不同,上一次的材料我交的是期末成绩单,这一次是学校发的奖状。说实话,对用奖状申请这回事我是很不抱希望的,但又没想到在三天后我打开电脑例行检查进度时…
一个绿底白字的Approved就这么糊到了我的脸上。哇我真的,你能理解吗就是那种,无法言表的欣喜,那种恨不得让全世界的人都知道你干成了什么的自豪感,就是这种感觉充满了我当时的脑海。没有别的原因,就是太高兴了。
附一张当时我的聊天记录:
然后自然是各种折腾、体验、白嫖,这些就不在这篇文章的讨论范围之内了。
我的申请经验
第一,千万不要挂梯子,尽量直连GitHub。GitHub会通过地理位置校验你是否可能真正在你所填写的学校就读,所以同样如果浏览器提示你开启地理位置就点同意。
第二,邮箱用自己的也可以,不限定教育邮箱。但是证明你学生身份的材料一定要详细真实,另外可以在How do you plan to use GitHub?(你怎么计划去使用GitHub)中附上材料的英文翻译。
第三,How do you plan to use GitHub?一定要认真填写,不要在网上随便找然后就直接粘贴上去。有能力的就直接用英语写,否则用有道翻译也行。
第四,学校信息越详细越好这不废话,有官网的记得把官网填上当然要是GitHub数据库里有你的学校直接选择就完了。
第五,记得每天看一下申请进度,没准它就会给你一个惊喜。
题外话
相信细心的各位也发现了,申请是在三月就过了的,为什么现在才发博文呢?
答案嘛…因为懒(逃
最后就以一张我现在GitHub上Profile的截图来收尾吧!
一名初中生的 GitHub 学生包申请之路
https://www.ordchaos.com/posts/f0f71147/
堆
AI摘要
生成中...
摘要由AI自动生成,仅供参考!
马上就是今年的CSP-J了,一想起自己还有那么多数据结构没学就有点头皮发麻…这篇博文里我就来讲一下堆(Heap),一是方便他人,二是给自己巩固思路。
讲解
按照惯例哪里来的惯例,还是看一下堆是什么东西:
堆(heap)是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵树的数组对象。堆总是满足下列性质:
- 堆中某个结点的值总是不大于或不小于其父结点的值;
- 堆总是一棵完全二叉树。
将根结点最大的堆叫做最大堆或大根堆,根结点最小的堆叫做最小堆或小根堆。
——百度百科 堆
很显然,为了储存堆,我们需要一棵完全二叉树。这里很多人就会想到建树,但其实不用。如果你看过我的学习笔记——二叉树的话,应该会记得完全二叉树的性质之一:
在有n个节点的完全二叉树中,对于编号为i的节点:
- 若i=1,则其无父节点,为根节点,否则其父节点编号为floor(2i)。
- 若2i>n,则i为叶节点,否则其左孩子的编号为2i。
- 若2i<n<2i+1,则i无右孩子,否则其右孩子的编号为2i+1。
——序炁 学习笔记——二叉树
所以我们只需要一个数组就可以存储堆了:数组最开始填入根节点,其左右孩子节点便依次为其后面的两个下标,再往后就以此类推。
那么现在建立一个数据结构用来建堆,很简单,参照下列代码:
1
2
3
4
5
6
| #define MAXSIZE 100000
struct myHeap {
int value[MAXSIZE];
int length;
};
|
对于每一个堆都申请一个MAXSIZE大小的数组用于存储,而后用length变量存储目前的总节点数即可。
那么如何初始化就显而易见,只需要
1
2
3
4
| inline void init(myHeap &heap) {
heap.length = 0;
return;
}
|
像这样将length设为0就大功告成。
插入元素
如果要往一个堆里插入元素,那我们就要先确定这个堆是小根堆还是大根堆,下面的所有代码均默认是小根堆,大根堆自己改去自己想想吧。
首先,在堆末尾加入要插入的元素:
1
2
3
4
| void push(myHeap &heap, int v) {
heap.value[heap.length++] = v;
}
|
length永远指向数组中最后一个存储了数据的位置的下一个位置,所以在value[length]的位置存储数据,然后增加length即可。
但现在这个堆可能不满足小根堆的性质了,怎么办呢?很简单,进行调整即可。将新节点设为当前节点,如果它大于父节点则结束,若小于则交换,而后将交换后的父节点(没错,还是新插入的数据)设为当前节点,重复这个过程直到其大于父节点或其为根节点则结束。
听着有些复杂,但用while循环即可轻松实现:
1
2
3
4
5
6
7
8
9
| void push(myHeap &heap, int v) {
int now = length;
while(heap.value[now - 1] < heap.value[now / 2 - 1] && now != 1) {
swap(heap.value[now - 1], heap.value[now / 2 - 1]);
now /= 2;
}
return;
}
|
完事!
删除元素
删除元素即出队,会弹出根节点。故而这里的方法是把最后一个节点移到根节点的位置覆盖掉它,再进行调整。
覆盖很简单:
1
2
3
4
| void pop(myHeap &heap) {
heap.value[0] = heap.value[--heap.length];
}
|
不要忘记将节点数减一即可。这里用了一个小技巧,本来要写成这样:
1
2
| heap.value[0] = heap.value[heap.length - 1];
heap.length--;
|
竞赛常考之一,++i与i++的区别。不要觉得没用,比如用在这里就非常合适。包括前面的
1
| heap.value[heap.length++] = v;
|
也用了这个方法。
好了,言归正传,下一步是调整节点。显然,这一次需要从上往下调整:将根节点设为当前节点,与自己左右孩子中较小的一个比较,若小于则结束,否则与其交换位置并将当前节点设为交换好的孩子节点(一样指向同样的数据),重复这个过程直到当前节点为叶节点或当前节点小于自己任何一个孩子为止。
同样,上代码:
1
2
3
4
5
6
7
8
9
10
11
12
| void pop(myHeap &heap) {
int now = 1;
while(2 * now <= heap.length) {
int temp = 2 * now - 1;
if(temp + 2 <= heap.length && heap.value[temp] > heap.value[temp + 1]) temp++;
if(heap.value[now - 1] > heap.value[temp]) swap(heap.value[now - 1], heap.value[temp]);
else break;
now = temp + 1;
}
return;
}
|
需要额外注意的是对当前节点是否为叶节点以及是否拥有右孩子的判断,避免因失误导致数据溢出。
应用
其实堆的操作也只有插入与删除,不过就是这么简单的东西也可以玩出不同的花样,下面是两个例子。
洛谷 P1090 NOIP2004 提高组 合并果子
原题链接:洛谷 P1090 NOIP2004 提高组 合并果子
题目描述
在一个果园里,多多已经将所有的果子打了下来,而且按果子的不同种类分成了不同的堆。多多决定把所有的果子合成一堆。
每一次合并,多多可以把两堆果子合并到一起,消耗的体力等于两堆果子的重量之和。可以看出,所有的果子经过n-1次合并之后,就只剩下一堆了。多多在合并果子时总共消耗的体力等于每次合并所耗体力之和。
因为还要花大力气把这些果子搬回家,所以多多在合并果子时要尽可能地节省体力。假定每个果子重量都为1,并且已知果子的种类 数和每种果子的数目,你的任务是设计出合并的次序方案,使多多耗费的体力最少,并输出这个最小的体力耗费值。
例如有3种果子,数目依次为1,2,9. 可以先将1、2堆合并,新堆数目为3,耗费体力为3. 接着,将新堆与原先的第三堆合并,又得到新的堆,数目为12,耗费体力为12。所以多多总共耗费体力为3+12=15。可以证明15为最小的体力耗费值。
输入格式
共两行。
第一行是一个整数n(1≤n≤10000),表示果子的种类数。
第二行包含n个整数,用空格分隔,第i个整数ai(1≤ai≤20000)是第i种果子的数目。
输出格式
一个整数,也就是最小的体力耗费值。输入数据保证这个值小于231.
输入输出样例
输入
输出
分析
简单的贪心算法,每次从所有果子中取两堆数量最小的合并,然后放回去即可。
不一定非要用堆,不过如果只是简单的排序的话会超时。不过你同样也可以用优先队列,或者看看洛谷上那些神犇的题解。
我的方法很简单,只需要建堆,然后从堆中取两个最小值(即小根堆堆顶元素)相加再插回去,直到只剩一个元素即可。其中每一次合并时用一个变量累计总体力,最后输出就行了。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
| #include <bits/stdc++.h>
using namespace std;
#define MAXSIZE 100000
struct myHeap {
int value[MAXSIZE];
int length;
};
void push(myHeap &heap, int v) {
heap.value[heap.length++] = v;
int now = heap.length;
while(heap.value[now - 1] < heap.value[now / 2 - 1] && now != 1) {
swap(heap.value[now - 1], heap.value[now / 2 - 1]);
now /= 2;
}
return;
}
void pop(myHeap &heap) {
heap.value[0] = heap.value[--heap.length];
int now = 1;
while(2 * now <= heap.length) {
int temp = 2 * now - 1;
if(temp + 2 <= heap.length && heap.value[temp] > heap.value[temp + 1]) temp++;
if(heap.value[now - 1] > heap.value[temp]) swap(heap.value[now - 1], heap.value[temp]);
else break;
now = temp + 1;
}
return;
}
inline int get(myHeap heap) {
return heap.value[0];
}
int getPop(myHeap &heap) {
int temp = get(heap);
pop(heap);
return temp;
}
int main() {
int n;
cin>>n;
int temp;
myHeap test;
test.length = 0;
for(int i = 0;i < n;i++) {
cin>>temp;
push(test, temp);
}
int power = 0;
while(test.length != 1) {
int quick[2] = {getPop(test), getPop(test)};
power += quick[0] + quick[1];
push(test, quick[0] + quick[1]);
}
cout<<power<<endl;
return 0;
}
|
其中get函数用于返回堆顶元素,不要也可以,毕竟很简单。
对于这一题是可以AC的,没有问题。
堆排序
既然小根堆的堆顶元素永远最小,那么只要每次都取出堆顶元素直到堆为空不就可以排序了吗?没错,这就是堆排序,时间复杂度为O(nlogn),十分优秀。
代码我就不讲了,自己看吧:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
int main() {
int n;
cin>>n;
int temp;
myHeap test;
test.length = 0;
for(int i = 0;i < n;i++) {
cin>>temp;
push(test, temp);
}
for(int i = 0; i < n; i++) cout<<getPop(test)<<" ";
cout<<endl;
return 0;
}
|
数据量大的时候可以考虑堆排序,因为堆排序的耗时主要在建堆上,建好堆后的调整实际上非常快。
题外话
终于写完了…写了我整整三小时啊!
明天大概也许会有一篇关于图的,以及一篇关于类的。
886!
堆
https://www.ordchaos.com/posts/fab451a5/
-
+ 使用Github Action定时重启邮件服务
+ https://www.ordchaos.com/posts/e9c784c5/
+ https://www.ordchaos.com/posts/e9c784c5/
+ Fri, 09 Feb 2024 18:52:38 GMT
+
+ <p>主要是邮件服务器的容器经常崩溃,所以尝试设置定时任务来解决这个问题。</p>
+
+
+
+ 主要是邮件服务器的容器经常崩溃,所以尝试设置定时任务来解决这个问题。
情景引入
邮件服务器性能羸弱,无法胜任设置定时任务这样的重担,所以只能用一些盘外招试试了。
设置 Action
那么首先,本着轻量化的原则,新建一个仓库拿来干这种事:
然后切到Action页面:
选择新建一个空白模板:
修改Action名称、内容并设置定时,参考我的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| # This is a basic workflow to help you get started with Actions
name: REMX
# Controls when the workflow will run
on:
# Triggers the workflow on push or pull request events but only for the "main" branch
push:
branches: [ "main" ]
schedule:
- cron: "0 20 * * *"
# Allows you to run this workflow manually from the Actions tab
workflow_dispatch:
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
jobs:
# This workflow contains a single job called "build"
build:
# The type of runner that the job will run on
runs-on: ubuntu-latest
# Steps represent a sequence of tasks that will be executed as part of the job
steps:
- name: Checkout Codes
uses: actions/checkout@v3
- name: Restart MX Service
uses: garygrossgarten/github-action-ssh@release
with:
command: ./restart.sh
host: ${{ secrets.HOST }}
username: root
password: ${{ secrets.PASSWORD }}
- name: Finish
run: echo "Action Finish"
|
SSH相关配置自行查看官方文档
保存,然后去设置Secret:
分别设置服务器地址、密码等即可:
大功告成!
结语
上高中之后就没写博文了……
除夕赶出一篇博文,祝新年快乐!!!
也迟来的祝博客两周年快乐!!!
]]>
+
+
+ 教程
+
+
+ 计算机
+
+ 编程
+
+ 教程
+
+ 白嫖
+
+
+ https://www.ordchaos.com/posts/e9c784c5/#disqus_thread
+
+
+
+ -
+ 年中总结,及进16岁生贺
+ https://www.ordchaos.com/posts/95bd9bb8/
+ https://www.ordchaos.com/posts/95bd9bb8/
+ Thu, 24 Aug 2023 17:28:53 GMT
+
+ 与初中生活告别,迈入新的人生阶段
+
+
+
+ 又是一年生日了,回想上次生日,好像还是在上次一样,那时还是在初三开学前的补课。补课放学的很早,五点就回家了。当时在超市里买了一根价值14块大洋的钟薛糕……
说起来真的像是发生在昨天。
1~2月
经过了疫情的洗礼,九年级下学期的开学总算是如期而至,但紧随而来便是对二月调考的紧张。原本武汉是只有元调、四调的,不过由于众所周知的疫情因素,元调从原定的1月4号挪到了2月21号。让我们过了一个安心的元旦和一个安心的寒假。
但该来的还是要来,二调总归也是调考,压迫感并未消失,只是转移到了一个月后。故而新学期伊始,我们就全身心投入到了复习之中。那时我的心里总会浮现出七年级刚开学时班主任在班里说的话,她告诉我们三年很短,元调很重要。初听不知话中意,而现在,已为语中人。
二调的成绩中规中矩吧,523分(523/600),随后便立下了四调要进步15分的目标。但那时我还不知道,这个目标永远没有机会达成了。
3~4月
二调完了就是四调,没什么可说的,该复习复习,该上新课上新课。伴随着一本又一本教材被翻至最后一课、最后一面,初中即将毕业的感受才开始从心中滋生。不论是Graduation还是“从这里出发”,课本中的一句句话,一段段文章都正提醒着我们即将分别的事实。
四调成绩说实话,很不好,只有508。以至于我的母亲对我这个分数不抱什么期望了,也便没有如同二调结束后那样跑前跑后地签各种约。也正因如此,已然退休的她只能在家里独自心焦,这是我的问题。
5~6月
五月有各个区自己的五调,六月便是全武汉市的中考。志愿早在五月九日便截至提交,在此之前,我终于说服了我的父母为我填写武钢三中为第一志愿。“说服”,无奈的选择,毕竟要说二调成绩勉强足够的话,四调成绩面对钢三简直就是依托答辩。但我仍然坚定的选择了这条路,算是对自己的压迫吧,同时也伴随着一股气,一股不服输的精神。
五调前举行了理化生实验考试,和八年级的地理生物一样,采用机考的形式。没什么难度,几乎全班满分通过,只有3人被扣了1分。加上由于疫情取消的体育中考,近乎就是给每个人送了80分。
六月初,抽了一个上午,我们全班在学校里拍了毕业照。学校不大,很快就走遍了整个校园。伴随着感慨,拍完室外照后回班,我们齐心协力在十分钟内办好了一面黑板报。站在黑板报前,我们拍了最后的几张照片。
中考日以前,最后一个在校日,是一个周六。老师在上午或看自习,或做最后的查漏补缺。而下午,老师开了一场动员会,给每个人发了一块粽子玩偶。既代表端午将临,亦有一举高中之意。一场班会结束,打扫完教室,离开学校,颇有一种或解脱、或不舍的情愫。
中考前一天,周一,下午我便前往了考点处。每个文化课老师都在考点门口,为我们一张张派发着准考证。面对那一句句叮嘱,我明白,不能当做是像以前那样的老生常谈了。
中考结束的那一天,考完历史道法的上午。连续更改了两道选择题的我放下了手中的笔,一根根地把中性笔、2B铅笔、涂卡笔以及橡皮擦、垫板、准考证装入了文具袋。走回休息室,再和全班同学及老师走出了考场。此时此刻,心中只有解脱,无暇再顾及其它。
随后就是毕业旅行了,很愉快的出行经历,也为初中三年画上了一个圆满的句号。
7~8月
七月一号一早,昨天刚从青岛回到家的我点进了武汉招考网,惊心动魄的输入姓名、报名号和身份证号。按下蓝色按钮的那一刻,时间仿佛凝滞。好在接下来引入眼帘的数字令我终于放下了心,614分(614/680),是我最高的一次了。
毫无疑问的被钢三录取,之后是钢三的夏令营,一直到七月二十一。食堂很美味,与同学相处得很愉快,校园环境很好,近乎无可挑剔了。
八月,很放松的一个月,这个月一直在玩master duel和原神,开始了摆烂状态(笑)
直到今天,我的生日为止,一切都很放松。
未来……
马上就是钢三的军训了,再之后就是开学,祝我一路顺利吧!
也希望三年后的暑假能像现在一样无忧无虑。
Happy Birthday for Me!
顺便晒一下毕业纪念册!
]]>
+
+
+ 日常
+
+
+ 生日
+
+ 总结
+
+ 个人
+
+
+ https://www.ordchaos.com/posts/95bd9bb8/#disqus_thread
+
+
+
+ -
+ 数字生命卡开箱——来自《流浪地球II》
+ https://www.ordchaos.com/posts/b3d3143c/
+ https://www.ordchaos.com/posts/b3d3143c/
+ Sun, 23 Jul 2023 16:00:58 GMT
+
+ <p>过年档的电影,看完就买了周边。历经半年,终于到手啦!哈哈!</p>
+
+
+
+ 过年档的电影,看完就买了周边。历经半年,终于到手啦!哈哈!
《流浪地球II》的官方周边产品大部分都是赛凡做的。怎么说呢……我买的数字生命卡是第二批,看到很多第一批的都有程度不一的瑕疵。不过我这个就还好,没有什么大问题,看来还是有在改进运输和包装质量。
到手差不多就是这么些东西:
其它周边什么的就不多说了,重头戏还是数字生命卡。
数字生命卡
只说外观的话,看起来金属感不是很强,喷个漆观感应该会好一些,但我不会(
别的道具倒是挺还原的,比如说袋子。
别的也没什么可说的了,毕竟这也就是一个128G的U盘和一个读卡器而已。
其它
不说什么了,放几张图吧。
题外话
不是很好评价赛凡的产品了……
我只能说我能接受这个做工,但的确,赛凡的破事很难让我提起好感。
就这样,886!
]]>
+
+
+ 日常
+
+
+ 电影
+
+ 开箱
+
+ 科技
+
+ U盘
+
+ 周边
+
+
+ https://www.ordchaos.com/posts/b3d3143c/#disqus_thread
+
+
+
+ -
+ 文章AI摘要?太酷啦!
+ https://www.ordchaos.com/posts/ec8c9790/
+ https://www.ordchaos.com/posts/ec8c9790/
+ Thu, 06 Jul 2023 16:05:00 GMT
+
+ <p>看了HEO的<a href="https://blog.zhheo.com/p/ec57d8b2.html">如何让博客支持AI摘要,使用TianliGPT自动生成文章的AI摘要</a>,甚是手痒……整一个!</p>
+
+
+
+ 看了HEO的如何让博客支持AI摘要,使用TianliGPT自动生成文章的AI摘要,甚是手痒……整一个!
前情提要
的确,我可以直接把HEO现成的部署方案拿来用,但我是一个有追求的人(雾。事实上,直接使用这种解决方案得到的摘要栏与我博客的设计风格并不是很搭,这就要求我自己写一个前端后端是不可能的,这辈子也不可能的。
好,开干!但首先,第一个问题出现了:我博客的设计风格本身就不太统一。首页的说说轮播和说说页面的数量统计用了fluid主题自带的info,而友链朋友圈页面又没有,直接使用了圆角矩形承载统计信息。
为了解决这个问题,我需要用一样东西代替info标签。经过再三深思熟虑,我选用圆角矩形统一替换info.
而后便有了枯燥的漫长(?)css编写时间:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| div.ocxqntcontainer {
display: flex;
align-items: center;
justify-content: center;
height: auto;
}
div.ocxqnt {
border: 1px solid #e9e9e9;
border-radius: 1rem;
padding: 1rem;
text-align: left;
width: 100%;
}
span.memos-t {
margin: 0 1rem;
}
|
就这样,圆角矩形大功告成。
摘要部署
现在这个步骤就变得很简单了,对于我用的fluid主题,编辑layout/post.ejs即可,在article标签中,类为markdown-body的div标签之前加入以下内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| <style>
i.icon-ordchaos-blog-robot, span.ocxq-ai-title {
font-weight: bold;
font-size: 1.2em;
}
span.ocxq-ai-warn {
font-weight: bold;
}
.ocxq-ai-text.typing::after {
content: "_";
margin-left: 2px;
animation: blink 0.7s infinite;
}
@keyframes blink {
50% {
opacity: 0;
}
}
</style>
<script>
let tianliGPT_postSelector = '#board .post-content .markdown-body';
let tianliGPT_key = '5Q5mpqRK5DkwT1X9Gi5e';
</script>
<div class="ocxqntcontainer">
<div class="ocxqnt">
<span id='memos-t'>
<i class="iconfont icon-ordchaos-blog-robot"></i><span id="memos-index-space"> </span><span class="ocxq-ai-title">AI摘要</span>
<br>
<span class="ocxq-ai-text">
生成中...
</span>
<br>
<span class="ocxq-ai-warn">摘要由AI自动生成,仅供参考!</span>
</span>
</div>
</div>
<br>
<script src="https://www.ordchaos.com/js/aisummary.js"></script>
|
这里有几个问题:
- 为什么内容在
id为memos-t的span标签中:因为它同样套用了刚刚写好的圆角矩形,而这个圆角矩形为了适配原有的memos说说而要求内部文字必须拥有memos-t的id. iconfont icon-ordchaos-blog-robot是什么图标:我在iconfont.cn中取用的,因为加入了我的图标库所以拥有图标库前缀icon-ordchaos-blog,若也想选用的话可以直接在iconfont.cn搜索关键词robot找到并添加到自己的图标库- 为什么不把样式代码写到css里面去:我懒
最后在文件的末尾处加上对js文件的引用。
说到js,由于HEO提供的js文件中含有生成前端容器的部分,所以必须要删除这部分内容并对其做出部分修改。过程这里就不放了,实在看不懂的可以参考我改好的被压缩了怎么看啊自己想办法。
而后去爱发电订阅TianliGPT并将api key填入即可。
效果
题外话
最开始因为不想写css而拖了好久……最终因为实在眼馋,欲望盖过了懒病才动身做完。
话说我这样改别人写好的js应该没问题吧……
那就这样,886!
]]>
+
+
+ 编程
+
+ 教程
+
+
+ 计算机
+
+ 编程
+
+ 教程
+
+ javascript
+
+ css
+
+ AI
+
+
+ https://www.ordchaos.com/posts/ec8c9790/#disqus_thread
+
+
+
+ -
+ 哇!是毕业旅行!
+ https://www.ordchaos.com/posts/c2e7460a/
+ https://www.ordchaos.com/posts/c2e7460a/
+ Sat, 01 Jul 2023 16:17:37 GMT
+
+ <p>初三毕业,结束了忙碌的一年,老师带我们全班去了青岛毕业旅行!</p>
+
+
+
+ 初三毕业,结束了忙碌的一年,老师带我们全班去了青岛毕业旅行!
前情提要
武汉今年中考在六月的二十、二十一、二十二号总共三天,考完以后休息放纵两日后,我们全班便踏上了高铁前往青岛。
怎么说呢……说是六天五夜,但武汉与青岛之间的高铁要坐8小时,所以第一天和最后一天都相当于是在高铁上玩一天手机(雾
Day 1 & 2
我们在武汉站登车,高铁从上午十一点一直开到了晚上七点。好在酒店离高铁站很近,走路也就5分钟路程,所以我们就前往了酒店开房。
该说不说,4个人挤双人房的安排是有点逆天的。就算我们没意见,酒店也没意见?!
第二天起来吃了早饭之后我们便走路前往了海边,很近,不过不是海滩。拍了几张照,早上天气真的很差,本来是小雨的天气,结果雨越来越大,风也越来越强。但过了一会天又晴了……
然后就是非常晒人。
下午乘坐青岛地铁去了中山公园附近的沙滩。只能说不愧是夏天,晚上五六点仍然晴空万里。
玩水玩得非常开心,不过也仅限于在海水中跑一跑了。毕竟我可不想和部分其他同学一样弄得浑身湿透。
请同学拍了两张照!
Day 3
走路去了圣弥勒尔大教堂,不过也没进去,就是在外面拍了几张照。
风景很不错,宝宝喜欢妈妈爱。
以及本来还以为会碰到什么传教士什么的,然后我就能回一句”我信铂金龙神巴哈姆特“(大雾,结果没有。
然后就去了老舍故居,看到了《骆驼祥子》相关的很多文物(?)。得亏武汉今年考的是《钢铁是怎样炼成的》,不是《骆驼祥子》,没有被祥子一车创si。
然后就是坐地铁回酒店了,这次是从人民会堂到青岛站。
下午去坐船了,不大不小的船。
我只想说,快艇我不晕,轮船我不晕,所以就是这种两者之间的会晕是吗!!!
下午天气很不好,在海上飘着,外面还下大雨,甚至打雷……
坐了四小时,而后从原港口下了船,感觉像是自找了四小时的罪受,艹。
回酒店后第一时间点了外卖,不然真感觉要吐了。
Day 4
又是地铁!这几天地铁成了我们唯一的陆上交通工具,别的旅行团都会有大巴什么的,我们没有,我们就是坐地铁(
还是人民会堂站下车,这次我们去了小青岛公园。公园环境很好,玩得很开心,甚至还去看了鱼雷洞。
以及走的时候发现了一条绿意盎然的楼梯,拍了张照,很好看(
下午坐一号线去了台东,去了步行街吃晚饭。
兴致突然起来了,和同学一起买了地铁票进站而非使用手机app. 运气挺好,买到了不一样样式的单程票。
下车之后全班就直接分组分头行动了。穿梭于人来人往的小吃摊中,感受到烟火气的缭绕,对于一个忙碌了一整年的初三学生来说实在是太酷啦!
买了铁板豆腐、臭豆腐、鱿鱼和青岛啤酒,香的嘞。
然后去了五四广场,再之后就又回了酒店。
Day 5
又去了海边,不过是坐地铁去的,三号线转二号线。
所以又收集(?)到了两款不一样的地铁票。
还有在五四广场同站换乘。
说实话,天气真的不好,海边景色这几天也看腻了(
浅浅拍了几张照之后就坐地铁回去了,以及又收集到了一种地铁票。
下午老师组织看电影,一起看了端午档的《消失的她》
悬疑片嘛……不是很和我胃口,但是观感还不错。
然后就是吃完饭。老师给了每人80的预算,让分组一起吃晚饭,我就和另外三个同学一起去了海底捞。
第一次去海底捞,服务很好,很符合我的期待,价格也正常,不算很贵,起码没超预算。
点了两个菌菇和麻辣两个汤底,味道就很正常,跟我家里和父母一起煮的火锅差不多。
最后还送了一份面条,海底捞真的,我哭死(大雾
师傅的手艺很好,观赏性十足,爱了爱了。
随便贴几张图吧:
Day 6
早起前往高铁站,赶十点的高铁。
天气阴了这么多天,结果偏偏走的时候才好,我的评价是,6.
坐的复兴号高铁,不过站台另一侧有一辆绿皮火车,于是拍了一张个人觉得很好看的照片:
然后又是玩了一天手机……
最后,晚上6点,回到武汉,与老师同学告别后回到了家,结束了这一场旅行。
题外话
生活记录型的博文,尤其是这么长的,我还是第一次写,有什么不足请多多海涵!
什么?你问中考?
请观阅以下内容:
你说的对,但是《中考》是由武汉教育局自主研发的一款「互联网时代」全新开放世界冒险游戏。游戏发生在一个被称作「HappyPark」的幻想公园,在这里,被「往上提的溢水杯」选中的人将被授予「0.797g沉淀」,导引「两种酸」之力。你将扮演一位名为「有两块抹布的直径0.3m的扫地机器人」的神秘角色,在面积27m2的秘鲁考古遗址中邂逅的紫甘蓝味软糖,和百万年前出士的bright flowers化石一起,找回「简练明快,势巧形密」的家书同时,感受「尽责地爱」,且逐步发掘「点P过定线」的真相。
怎么说呢,今年的题真的很创人。
所以……考的差一点也不要紧啦,哈哈……
···
啊?你真以为我考砸了?
886!
]]>
+
+
+ 日常
+
+
+ 日常
+
+ 旅行
+
+
+ https://www.ordchaos.com/posts/c2e7460a/#disqus_thread
+
+
+
+ -
+ 前、后与中——表达式求值
+ https://www.ordchaos.com/posts/c9c6cb4f/
+ https://www.ordchaos.com/posts/c9c6cb4f/
+ Sun, 02 Apr 2023 10:09:31 GMT
+
+ <p>记录一下最近的练习程序与做法,加深记忆,也当个教程吧,毕竟赠人玫瑰手留余香(bushi</p>
+
+
+
+ 记录一下最近的练习程序与做法,加深记忆,也当个教程吧,毕竟赠人玫瑰手留余香(bushi
如果你不知道这些表达式分别指什么东西,可以百度一下,这里不再赘述。
后缀表达式
这个应该是最常见的了,下面讲一下实现。
首先,还是定义函数废话:
然后,进行文件读取,可以用freopen(),不过我这里用的是fopen():
1
2
3
4
5
6
7
8
9
10
| FILE* stream = fopen("input.txt", "r");
stack<double> nums;
while(true) {
char tstr[100];
fscanf(stream, "%s", tstr);
if(feof(stream)) break;
string input = tstr;
}
|
解释一下上面的程序:
stack<double> nums 这个栈后面会用到,这里先不用管fscanf()和scanf()用法一样,唯一的区别是fscanf()用于读取文件流中的信息而非输入流feof()中的参数为文件流,用于判断是否读到结尾,读到则返回真
很显然,这段程序用于分别读入每一段字符,那么接下来便是判断输入了。
代码如下:
1
2
3
4
5
6
7
8
9
10
| while(true) {
if(isdigit(input[0])) {
nums.push(atof(input.c_cstr()));
}
else {
}
}
|
如果输入为整数,则进入数字栈,否则开始计算。
这里使用了isdigit()函数,输入为char类型,用于判断参数是否在'0'与'9'之间。
计算过程很简单,弹出两个数字栈中的数,根据运算符计算即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
else {
double y = nums.top();
nums.pop();
double x = nums.top();
nums.pop();
double temp;
switch(input[0]) {
case '+':
temp = x + y;
break;
case '-':
temp = x - y;
break;
case '*':
temp = x * y;
break;
case '/':
temp = x / y;
break;
}
nums.push(temp);
}
|
尤其要注意减法与除法的操作数与被操作数顺序,毕竟它们可没有交换律。
此时已经计算完成,结果作为栈中唯一的元素处在栈顶,直接输出即可:
1
2
3
4
| fclose(stream);
cout<<nums.top()<<endl;
return 0;
|
大概就是这样。
完整代码还是放一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| #include<bits/stdc++.h>
using namespace std;
inline bool is_num(string str) {
if(str[0] >= '0' && str[0] <= '9') return true;
else return false;
}
int main() {
FILE* stream = fopen("input.txt", "r");
stack<double> nums;
while(true) {
char tstr[100];
fscanf(stream, "%s", tstr);
if(feof(stream)) break;
string input = tstr;
if(is_num(input)) {
nums.push(atof(input.c_str()));
}
else {
double y = nums.top();
nums.pop();
double x = nums.top();
nums.pop();
double temp;
switch(input[0]) {
case '+':
temp = x + y;
break;
case '-':
temp = x - y;
break;
case '*':
temp = x * y;
break;
case '/':
temp = x / y;
break;
}
nums.push(temp);
}
}
fclose(stream);
cout<<nums.top()<<endl;
return 0;
}
|
输入样例:
输出样例:
前缀表达式
细心一点就能发现,它与后缀表达式几乎一样,只是顺序不同。
没错,这正是因为前、后、中缀表达式分别为表达式树的先序、后续与中序遍历。
利用这个性质,将后缀表达式的顺序稍稍更改即可得到前缀表达式求值的程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| #include<bits/stdc++.h>
using namespace std;
inline bool is_num(string str) {
if(str[0] >= '0' && str[0] <= '9') return true;
else return false;
}
int main(){
FILE* stream = fopen("input.txt", "r");
stack<double> nums;
vector<string> input;
while(true) {
char tstr[100];
fscanf(stream, "%s", tstr);
if(feof(stream)) break;
input.push_back(string(tstr));
}
for(int i = input.size() - 1;i >= 0;i--) {
if(is_num(input[i])) {
nums.push(atof(input[i].c_str()));
}
else {
double x = nums.top();
nums.pop();
double y = nums.top();
nums.pop();
double temp;
switch(input[i][0]) {
case '+':
temp = x + y;
break;
case '-':
temp = x - y;
break;
case '*':
temp = x * y;
break;
case '/':
temp = x / y;
break;
}
nums.push(temp);
}
}
fclose(stream);
cout<<nums.top()<<endl;
return 0;
}
|
改成倒序读取即可。
输入样例:
输出样例:
中缀表达式
我们最常用的表达式,处理起来却是最复杂的,因为现在需要考虑优先级与括号了。
这里有几种方法:
递归
首先,定义函数用于取多项式的因子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| int factor() {
int res = 0;
char c = cin.peek();
if(c == '(') {
cin.get();
res = expression();
cin.get();
}
else {
while(isdigit(c)) {
res = 10 * res + c - '0';
cin.get();
c = cin.peek();
}
}
return res;
}
|
先定义结果为0,然后判断输入。若为括号,则将其内容视为新表达式,交由马上要定义的expression()函数计算。否则,按位取出输入中的数即可。
顺带一提,这些代码中的cin.get()与cin.peek()尤其重要,切勿移动位置或轻易替换。至于原因,自己模拟想一下吧。
然后,计算单项式的值,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| int term() {
int res = factor();
while(true) {
char mark = cin.peek();
if(mark == '*' || mark == '/') {
cin.get();
int v = factor();
if(mark == '*') res *= v;
else res /= v;
}
else break;
}
return res;
}
|
先用factor()函数读入因子,然后循环判断该单项式是否读完。若未读完(即该因子与下一个因子间仍用乘号或除号连接)则取下一个因子并计算,否则返回该单项式的值即可。并且很显然,这样的写法就代表输入的表达式中不应当含有任何空格,也只支持整数运算(要浮点数自己改我不干了)。
最后是整个表达式,与计算单项式基本一样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| int expression() {
int res = term();
while(true) {
char mark = cin.peek();
if(mark == '+' || mark == '-') {
cin.get();
int v = term();
if(mark == '+') res += v;
else res -= v;
}
else break;
}
return res;
}
|
读入单项式再计算,直到该表达式计算完毕(即mark取到)或EOF)
主函数其实已经一目了然了,重定向输入再调用expression()即可,就不写了。
输入样例:
输出样例:
栈
这里又分为两种方案:
转为后/前缀表达式再计算
这里的重点是转换的过程,逻辑整体如下(中缀->后缀):
- 输入若为数字,直接放入输出表达式中。若为符号:
- 如果符号栈为空,则放入符号栈中
- 如果符号栈栈顶元素优先级大于等于该符号,则出栈栈顶符号放入表达式,若此时栈顶符号优先级大于等于该符号,则重复以上流程直至小于,而后入栈该符号
- 如果符号栈栈顶元素优先级小于该符号,该符号入栈
- 如果该符号为左括号,直接入栈
- 如果该符号为右括号,则依次出栈符号栈栈顶元素放入表达式中,直至左括号。最后抛弃左括号与右括号
- 若输入完毕,符号栈中仍有符号,则依次出栈放入表达式
代码如下(转为后缀表达式):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| map<char, int> markl;
markl['+'] = 0;
markl['-'] = 0;
markl['*'] = 1;
markl['/'] = 1;
FILE* stream = fopen("input.txt", "r");
stack<char> marks;
vector<string> expression;
while(true) {
char tstr[100];
fscanf(stream, "%s", tstr);
if(feof(stream)) break;
string input = tstr;
if(isdigit(input[0])) {
expression.push_back(input);
}
else if(input[0] == '(') {
marks.push('(');
}
else if(input[0] == ')') {
while(true) {
if(marks.top() == '(') {
marks.pop();
break;
}
char t[2] = {marks.top(), '\0'};
expression.push_back(string(t));
marks.pop();
}
}
else {
if(marks.empty() || marks.top() == '(') {
marks.push(input[0]);
}
else if(markl[input[0]] <= markl[marks.top()]) {
while(!marks.empty() && markl[temp[0]] <= markl[marks.top()]) {
char t[2] = {marks.top(), '\0'};
expression.push_back(string(t));
marks.pop();
}
marks.push(input[0]);
}
else {
marks.push(input[0]);
}
}
}
while(!marks.empty()) {
char t[2] = {marks.top(), '\0'};
expression.push_back(string(t));
marks.pop();
}
|
和上面的逻辑完全一样,唯一要注意的是这里使用了map,可以理解为字典。
然后只需要计算就行,代码就不放了。
前缀表达式的逻辑与代码可以自己想想。
输入输出样例同下面。
直接计算
逻辑和转换本身是一样的,只不过没有了表达式向量,而是直接计算后放入数字栈。
即将所有的对于expression的操作改为计算即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
| #include <bits/stdc++.h>
using namespace std;
double calc(char mark, double x, double y) {
double temp = 0;
switch(mark) {
case '+':
temp = x + y;
break;
case '-':
temp = x - y;
break;
case '*':
temp = x * y;
break;
case '/':
temp = x / y;
break;
}
return temp;
}
int main() {
FILE* stream = fopen("input.txt", "r");
map<char, int> markl;
markl['+'] = 0;
markl['-'] = 0;
markl['*'] = 1;
markl['/'] = 1;
stack<char> marks;
stack<double> nums;
while(true) {
char tstr[100];
fscanf(stream, "%s", tstr);
if(feof(stream)) break;
string temp = tstr;
if(isdigit(temp[0])) {
nums.push(atof(temp.c_str()));
}
else if(temp[0] == '(') {
marks.push('(');
}
else if(temp[0] == ')') {
while(true) {
if(marks.top() == '(') {
marks.pop();
break;
}
double y = nums.top();
nums.pop();
double x = nums.top();
nums.pop();
nums.push(calc(marks.top(), x, y));
marks.pop();
}
}
else if(marks.empty() || marks.top() == '(') {
marks.push(temp[0]);
}
else if(markl[temp[0]] <= markl[marks.top()]) {
while(!marks.empty() && markl[temp[0]] <= markl[marks.top()]) {
double y = nums.top();
nums.pop();
double x = nums.top();
nums.pop();
nums.push(calc(marks.top(), x, y));
marks.pop();
}
marks.push(temp[0]);
}
else {
marks.push(temp[0]);
}
}
while(!marks.empty()) {
double y = nums.top();
nums.pop();
double x = nums.top();
nums.pop();
nums.push(calc(marks.top(), x, y));
marks.pop();
}
fclose(stream);
cout<<nums.top()<<endl;
return 0;
}
|
输入样例:
1
| ( 28 / 7 ) / 2 + ( 8 - 9 )
|
输出样例:
收工!
题外话
这篇大概是我最长的纯原创技术类博文了。。。。。。
好累QAQ
下次再见啦!886!
2023.04.03更新
让ChatGPT改了一个支持浮点数的递归版本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
| #include <iostream>
#include <cstdlib>
#include <cstdio>
using namespace std;
void print_tab(int);
void print_log(string, int);
void print_log(string, int, double);
double expression(int);
double term(int);
double factor(int);
int main() {
freopen("input.txt", "r", stdin);
cout << expression(0) << endl;
return 0;
}
void print_tab(int deep) {
for(int i = 0;i < deep;i++) {
cout << "\t";
}
return;
}
void print_log(string name, int deep) {
print_tab(deep);
cout << name << " {" << endl;
return;
}
void print_log(string name, int deep, double res) {
print_tab(deep);
cout << "} -> res =" << res << endl;
return;
}
double expression(int deep) {
print_log("expression", deep);
double res = term(deep + 1);
while(true) {
char mark = cin.peek();
if(mark == '+' || mark == '-') {
cin.get();
double v = term(deep + 1);
if(mark == '+') res += v;
else res -= v;
}
else break;
}
print_log("expression", deep, res);
return res;
}
double term(int deep) {
print_log("term", deep);
double res = factor(deep + 1);
while(true) {
char mark = cin.peek();
if(mark == '*' || mark == '/') {
cin.get();
double v = factor(deep + 1);
if(mark == '*') res *= v;
else res /= v;
}
else break;
}
print_log("term", deep, res);
return res;
}
double factor(int deep) {
print_log("factor", deep);
double res = 0;
double base = 1.0;
char c = cin.peek();
if(c == '(') {
cin.get();
res = expression(deep + 1);
cin.get();
}
else {
while(isdigit(c) || c == '.') {
if(c == '.') {
cin.get();
c = cin.peek();
while(isdigit(c)) {
res = res + (c - '0') * (base /= 10.0);
cin.get();
c = cin.peek();
}
break;
}
res = res * 10 + c - '0';
cin.get();
c = cin.peek();
}
}
print_tab(deep + 1);
cout << "get_num();" << endl;
print_log("factor", deep, res);
return res;
}
|
神
]]>
+
+
+ 编程
+
+
+ 计算机
+
+ 编程
+
+ c++
+
+ 算法
+
+
+ https://www.ordchaos.com/posts/c9c6cb4f/#disqus_thread
+
+
+
+ -
+ 迟来的二月调考总结
+ https://www.ordchaos.com/posts/7eb4319/
+ https://www.ordchaos.com/posts/7eb4319/
+ Sun, 26 Mar 2023 10:14:38 GMT
+
+ 一些自己的话
+
+
+
+ 各位,好久不见,距离上次发文的时间过的有点久,其中最大的原因就是万恶的二月调考。现在已经考完一个多月了离四调也就一个月了,这里我来总结一下。
背景要素
以防不知道,本人生在武汉,学籍武汉,参加武汉的统一考试。武汉在九年级时会有几场全市统考,分别为九上的元月调考(期末)与九下的四月调考(期中)和中考(期末)。今年闹疫情,于是原定在一月四号的元调被挪到了二月二十一号(九下开头)。
武汉的中考在我这一届改革了,下面对比一下以往和之后的不同:
| 科目 | 分数(前) | 分数(后) |
|---|
| 语文 | 120 | 120 |
| 数学 | 120 | 120 |
| 英语 | 120 | 120 |
| 物理 | 70 | 70 |
| 化学 | 50 | 50 |
| 历史 | \ | 60 |
| 道德与法治 | 40 | 60 |
| 实验 | 0 | 30 |
| 体育 | 30 | 50 |
| 总分 | 550 | 680 |
详解:
- 原本不考历史
- 道德与法治原先只有选择题,现在新加入了材料题,分数构成为
28分选择 + 32分材料。历史分数构成与其一样,且二者合卷 - 实验考试以往不计分,为实操。现在为机考答卷,在120道题(40物理,40化学,40生物)中每个科目随机选10道题目作答,每题一分
- 体育由30分改为50分,构成为
15分平时 + 35分考试。本届由于新冠疫情的原因,取消体育中考(即所有人考试分数计为35)
二调情况
先明确二调的考试内容,为中考所有科目除去体育与实验(四调亦然)
分数不是很方便透露,大致说一下考试情况吧。说来惭愧,正正好好是语数英垮了(bushi
语文选择题眼瞎,错了两题。英语则是阅读理解B篇,神你以为我会说脏话吗?的Live a colorful life,我真感觉不到这么大,真的。
总之就是很意难平。
好消息是化学满分,终于!
签约的话倒不是不能签,只能说是比上不足,比下有余余余余余…
总结
也没什么可说的,给自己加油吧。我是想打竞赛的,文化课成绩必然需要更上一层楼才行。
886!
(鬼知道下次什么时候更新)
]]>
+
+
+ 个人
+
+
+ 总结
+
+ 学习
+
+ 考试
+
+
+ https://www.ordchaos.com/posts/7eb4319/#disqus_thread
+
+
+
+ -
+ 全站 webp 自动切换,加速访问好帮手
+ https://www.ordchaos.com/posts/23e22de2/
+ https://www.ordchaos.com/posts/23e22de2/
+ Thu, 12 Jan 2023 09:42:10 GMT
+
+ <p>原本博客用的都是普通图片,就算有懒加载,一堆圈圈一起转也惹人心烦。现在改为了原图/webp的自适应切换,效果好上不少。</p>
+
+
+
+ 原本博客用的都是普通图片,就算有懒加载,一堆圈圈一起转也惹人心烦。现在改为了原图/webp的自适应切换,效果好上不少。
前期准备
首要任务是拿到webp格式的图片,这个看自己。像我用的vps上的Lsky Pro,本地存储。有高性能vps可以试试用Webp-Server配合。但我的轻量应用承受不起,遂作罢。改为了定时shell脚本,一分钟触发一次:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| #!/bin/bash
find . -type f -iname "*.png" | while read file; do
if [ ! -f "${file%.*}.webp" ]; then
cwebp -q 85 "$file" -o "${file%.*}.webp"
fi
done
find . -type f -iname "*.jpg" | while read file; do
if [ ! -f "${file%.*}.webp" ]; then
cwebp -q 85 "$file" -o "${file%.*}.webp"
fi
done
find . -type f -iname "*.jpeg" | while read file; do
if [ ! -f "${file%.*}.webp" ]; then
cwebp -q 85 "$file" -o "${file%.*}.webp"
fi
done
find . -type f -iname "*.tif" | while read file; do
if [ ! -f "${file%.*}.webp" ]; then
cwebp -q 85 "$file" -o "${file%.*}.webp"
fi
done
|
脚本运行时会遍历自己所在的文件夹及其子文件夹,转换所有没有对应webp格式的图片(png,jpg、jpeg与tiff)为webp图片(原图还在,放心)。
这段脚本中使用了cwebp指令,它来源于libwebp。安装可以参考下方:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # 安装编译器以及依赖包
yum install -y gcc make autoconf automake libtool libjpeg-devel libpng-devel
# 请到官网下载最新版本,版本列表:https://storage.googleapis.com/downloads.webmproject.org/releases/webp/
wget https://storage.googleapis.com/downloads.webmproject.org/releases/webp/libwebp-1.2.4.tar.gz
# 解压
tar -zxvf libwebp-1.2.4.tar.gz
# 进入目录
cd libwebp-1.2.4
# 源代码安装环境检查
./configure
# 编译
make
# 安装
make install
|
安装过程中遇到问题请善用百度/Google,本人不对此负责(bushi
做好以上所有工作后,就可以开始下面的内容。
Service Worker
安装
不知道是什么、如何部署的,可以看看CYF大佬的这两篇文章:
如果你已经部署了Service Worker就可以继续了。
脚本
添加一个监听器,监听fetch事件:
1
2
3
| self.addEventListener('fetch', async event => {
});
|
(或者在本来的监听器里面加上)
然后判断流量是否是对图站的请求,可以用一个if来判断:
1
2
3
4
| if(event.request.url.indexOf('your.image.site') !== -1) {
var requestUrl = event.request.url;
}
|
event.request.url是请求的地址,用indexOf()方法来判断地址中是否包含图站地址,若不反回代表没有的-1即为是对图站的请求。
接下来判断浏览器是否支持webp图片,定义一个变量supportsWebp
1
2
3
4
5
6
| var supportsWebp = false;
if (event.request.headers.has('accept')){
supportsWebp = event.request.headers
.get('accept')
.includes('webp');
}
|
如果可以获取到浏览器的Accept头,且头中包含image/webp,即为支持webp,否则为不支持。
然后就可以进一步处理了,若浏览器支持webp,则进行下一步:
1
2
3
4
5
6
| if (supportsWebp) {
}
else {
console.log("[SW] Don't support webp image, skip " + requestUrl + " .");
}
|
然后获取请求的文件类型。最开始的脚本只支持png,jpg、jpeg与tiff这四种格式的图片,所以我们也只能篡改这四种格式图片的请求到webp图片上:
1
2
3
4
5
| var imageUrl = requestUrl.split(".");
if(imageUrl[imageUrl.length - 1] === 'jpg' || imageUrl[imageUrl.length - 1] === 'tif' || imageUrl[imageUrl.length - 1] === 'png' || imageUrl[imageUrl.length - 1] === 'jpeg') {
var newUrl = requestUrl.replace(imageUrl[imageUrl.length - 1], 'webp');
}
|
newUrl中存储了新的请求地址,接下来对它发起请求即可:
1
2
3
| var newRequest = new Request(newUrl);
event.respondWith(fetch(newRequest));
console.log("[SW] Redirect " + requestUrl + " to " + newUrl + " .");
|
当请求完成并图片被完整下载以后,进行缓存,代码如下:
1
2
3
4
5
6
7
8
9
10
| event.waitUntil(
fetch(newRequest).then(function(response) {
if (!response.ok) throw new Error("[SW] Failed to load image: " + newUrl);
caches.open(CACHE_NAME).then(function(cache) {
cache.put(newRequest, response);
});
}).catch(function(error) {
console.log(error);
})
);
|
若获取失败则提示,成功则缓存。
最后,要打断之前的请求,避免降低速度,可以调用event.stopImmediatePropagation()方法打断原始请求。
最后完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| if(event.request.url.indexOf('img.ordchaos.com') !== -1) {
var requestUrl = event.request.url;
var supportsWebp = false;
if (event.request.headers.has('accept')){
supportsWebp = event.request.headers
.get('accept')
.includes('webp');
}
if (supportsWebp) {
var imageUrl = requestUrl.split(".");
if(imageUrl[imageUrl.length - 1] === 'jpg' || imageUrl[imageUrl.length - 1] === 'tif' || imageUrl[imageUrl.length - 1] === 'png' || imageUrl[imageUrl.length - 1] === 'jpeg'){
var newUrl = requestUrl.replace(imageUrl[imageUrl.length - 1], 'webp');
var newRequest = new Request(newUrl);
event.respondWith(fetch(newRequest));
console.log("[SW] Redirect " + requestUrl + " to " + newUrl + " .");
event.waitUntil(
fetch(newRequest).then(function(response) {
if (!response.ok) throw new Error("[SW] Failed to load image: " + newUrl);
caches.open(CACHE_NAME).then(function(cache) {
cache.put(newRequest, response);
});
}).catch(function(error) {
console.log(error);
})
);
event.stopImmediatePropagation();
return;
}
}
else {
console.log("[SW] Don't support webp image, skip " + requestUrl + " .");
}
}
|
你学会了吗?
测试
进入网站,若一切正常,当加载到一张图片时,控制台(F12打开)会提示[SW] Redirect https://your.image.site/path/to/img.png to https://your.image.site/path/to/img.webp .这样的信息。
要测试无webp支持的情景,则点击右上角的三个点。
选择更多工具,找到“渲染”并点击。
勾选“停用webp”即可。
此时,加载图片时会提示[SW] Don't support webp image, skip https://your.image.site/path/to/img.png .
可以试试我这里的这张图片:
若浏览器支持webp则会显示Webp Accept!,否则为Webp Reject!This is a jpg file.
题外话
刚刚放寒假,舒坦。
但与之对应,九上已经结束,还有一学期就中考。。。
加油!我可以的!
那就这样,886!
]]>
+
+
+ 编程
+
+ 教程
+
+
+ 计算机
+
+ 编程
+
+ 教程
+
+ 优化
+
+
+ https://www.ordchaos.com/posts/23e22de2/#disqus_thread
+
+
+
+ -
+ 自托管 E-mail ,宝宝喜欢妈妈爱
+ https://www.ordchaos.com/posts/3b90dbec/
+ https://www.ordchaos.com/posts/3b90dbec/
+ Mon, 28 Nov 2022 13:40:50 GMT
+
+ <p>本来一直在用阿里云的企业邮箱,但感觉总是不太好,主要每次都需要进<code>https://qiye.aliyun.com</code>登录。于是趁着黑色星期五<a href="https://racknerd.com/">RackNerd</a>的优惠,搞了一台vps来搭电子邮局(如果你想搭建,请确认服务器是否支持rDNS以及是否开启25端口)。</p>
+
+
+
+ 本来一直在用阿里云的企业邮箱,但感觉总是不太好,主要每次都需要进
https://qiye.aliyun.com登录。于是趁着黑色星期五RackNerd的优惠,搞了一台vps来搭电子邮局(如果你想搭建,请确认服务器是否支持rDNS以及是否开启25端口)。配置如下(年付$10.28)
| 硬件 | 配置 |
|---|
| CPU | 1核 |
| RAM | 768MB |
| SSD | 10GB |
| 流量 | 1TB |
还是比较磕碜的,不过价格在这,无所谓了。
经历
首先,我需要为vps开通rDNS记录到mx.ordchaos.com上。后台可以自主设置,很方便…
好,很好,我沉得住气。发个工单问一下:
哦!原来如此!好的,继续交流后,rDNS设置成功,但然而我却发现无法访问?!一番探查之后,发现这样一个事实——被墙啦!
于是只得继续发工单:
终于搞定。
Mailu.io部署
设置主机名
在vps的bash中输入:
在其中具有服务器ip地址的一行中,将后面的内容改为(假设你的域名是example.com,服务器ip是88.88.88.88):
1
| 88.88.88.88 mx.example.com mx
|
编辑好后,在vps中执行:
1
2
| echo "mx" > /etc/hostname
hostname -F /etc/hostname
|
这样就设置好了主机名,可以通过hostname命令确认是否设置成功:
前者只会输出mx,后者则会输出mx.example.com。如果不是,那就是设置错了。
设置DNS解析
去你的域名DNS解析服务商,设置以下DNS解析(假设你的域名是example.com,服务器ip是88.88.88.88):
然后去vps服务商,设置rDNS(或者叫做PTR)解析,将88.88.88.88解析到mx.example.com
获取配置
访问Mailu.io的配置生成网页:https://setup.mailu.io
写文时最新版本为1.9,保持不变。下方部署方式选择Compose.
最后,你会看到如下界面:
照着界面的指示,回到vps执行指令:
然后回到刚刚的页面,下载配置文件:
1
2
| wget http://setup.mailu.io/1.7/file/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/docker-compose.yml
wget http://setup.mailu.io/1.7/file/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/mailu.env
|
最后执行(假设你的域名是example.com,密码设置为PASSWORD):
1
2
| docker-compose -p mailu up -d
docker-compose -p mailu exec admin flask mailu admin admin example.com PASSWORD
|
就安装完成了。
配置
在浏览器中访问https://mx.example.com登录您的管理员面板:
使用账号admin@example.com和密码PASSWORD登录即可(假设你的域名是example.com,密码设置为PASSWORD)。
然后点击左侧的“邮件域”:
然后点击如下的按钮:
在新界面中点击“生成密钥”,然后复制dkim配置:
1
| dkim._domainkey.example.com. 600 IN TXT "v=DKIM1; k=rsa; p=xxxxxxxxxxxxxxxxxxxxxxxxxxxx" "xxxxxxxxxxxxxxxxxxxxxxxxxxxx"
|
进行域名解析即可。
创建账号
邮件域>用户>添加用户,按需配置即可。
使用
退出管理员账号,访问https://mx.example.com/webmail,登录即可(选择“登录Webmail”)。
测试
在MailTester上可以进行测试,如下是我测试结果:
很完美了,对吧(
以前没有超过8过
题外话
完成了很久以前的夙愿。
欢迎跟着做一遍哦!也欢迎提问!
]]>
+
+
+ 教程
+
+
+ 计算机
+
+ 编程
+
+ 教程
+
+ 电子邮件
+
+ vps
+
+
+ https://www.ordchaos.com/posts/3b90dbec/#disqus_thread
+
+
+
+ -
+ 船新说说页面—— Memos 初体验
+ https://www.ordchaos.com/posts/3386e07f/
+ https://www.ordchaos.com/posts/3386e07f/
+ Sat, 26 Nov 2022 12:42:15 GMT
+
+ <p>博客的说说真的是一波三折…</p>
+
+
+
+ 博客的说说真的是一波三折…
最开始用的是HexoPlusPlus的说说,很好用也很流畅小巧,但是自Hpp停止开发后就用不了了。
然后改用了bber,也很不错,但是辣鸡腾讯云也是离谱,好好的羊毛突然就不让薅了,同时我的twikoo也被迫迁移到了vercel,只得抛弃。
中途也用过别的说说系统,比如说大名鼎鼎的Artitalk亦或者是iSpeak等等,但是都不太满意,而后因为各式各样的原因放弃。
本来我会一直被这玩意困扰…现在不会了!只因为我发现了它——Memos
开源,私有部署,这不就是我要的完美的说说系统吗?!
后端部署
很简单,首先你要有一台vps,然后装上docker.
随后一句指令即可搞定:
1
| docker run -d --name memos -p 5230:5230 -v ${PWD}/.memos/:/var/opt/memos neosmemo/memos:latest
|
随后Memos就会被部署到5230端口,觉得不方便也可以反向代理,这个教程有很多,这里就不写了。
前端
单页
可以看看我的:说说
样式完全是自己写的…你知道对一位学C++的初三学生而言css是什么东西吗?!好吧随便写写也不算难
js来自immmmm,稍微改了一点点,可以在这里看看被压缩了根本看不了。
总体而言,如果你也想要部署一个和我完全一样的页面,可以用以下html代码:(记得下载js文件)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| <div class='memo-nums'>
<p class='note note-info memo-nums-text'>
共有 <span id='memonums'>「数待载之」</span> 条说说
</p>
</div>
<div id="bber"></div>
<script type="text/javascript">
var bbMemos = {
memos : 'https://memos.ordchaos.top/',
limit : '',
creatorId:'1' ,
domId: '',
}
</script>
<script src="//jsd.ordchaos.top/marked/marked.min.js"></script>
<script src="/js/talk.js"></script>
|
注意这里用了Tag插件,如果用不了记得改改。
首页轮播
这个就比较简单了,直接在主题的index.ejs里加上以下代码即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| <p class='note note-info memo-nums-text'>
<i class="iconfont icon-speakernotes"></i><span id="memos-index-space"> </span><span id='memos-t'>首页说说轮播加载中...</span>
</p>
<script src="/js/lately.min.js"></script>
<script>
let jsonUrl =
"https://memos.ordchaos.top/api/memo?creatorId=1&rowStatus=NORMAL" +
"&t=" +
Date.parse(new Date());
fetch(jsonUrl)
.then((res) => res.json())
.then((resdata) => {
data = resdata.data,
resultIndexMemos = new Array(data.length);
for (var i = 0; i < data.length; i++) {
var talkTime = new Date(
data[i].createdTs * 1000
).toLocaleString();
var talkContent = data[i].content;
var newtalkContent = talkContent
.replace(/```([\s\S]*?)```[\s]*/g, " <code>$1</code> ")
.replace(/`([\s\S ]*?)`[\s]*/g, " <code>$1</code> ")
.replace(/<iframe([\s\S ]*?)iframe>[\s]*/g, "📺")
.replace(/\!\[[\s\S]*?\]\([\s\S]*?\)/g, "🌅")
.replace(/\[[\s\S]*?\]\([\s\S]*?\)/g, "🔗")
.replace(
/\bhttps?:\/\/(?!\S+(?:jpe?g|png|bmp|gif|webp|jfif|gif))\S+/g,
"🔗"
);
if(newtalkContent.length > 25) {
newtalkContent = newtalkContent.substring(0, 25) + '...';
}
resultIndexMemos[i] = `<span class="datetime">${talkTime}</span>: <a href="https://www.ordchaos.com/talk/">${newtalkContent}</a>`;
}
});
var i = 0;
setInterval(function () {
document.getElementById("memos-t").innerHTML = resultIndexMemos[i];
window.Lately && Lately.init({ target: ".datetime" });
i++;
if(i == resultIndexMemos.length) i = 0;
}, 3000);
</script>
|
Tag仍然是不能用就记得改。代码来自eallion,仍然是改了一下原本的逻辑怎么看怎么怪好吧也可能是我没看懂——总而言之,无意冒犯。
javascript总算是好些那么一点点,起码与c++还有那么一点像,外加上自己写GDScript的经验,稍稍改点也不算难事改了一小时
效果
自己去看看不行吗,动动手指的事
题外话
前前后后搞了半个月了,终于是在学习的闲暇时间整完,中途也是收获良多。
那就这样,886!
]]>
+
+
+ 编程
+
+ 教程
+
+
+ javascript
+
+ css
+
+ memos
+
+ html
+
+ 说说
+
+ 前端
+
+
+ https://www.ordchaos.com/posts/3386e07f/#disqus_thread
+
+
+
+ -
+ Picgo ,我 ...... 我 ......
+ https://www.ordchaos.com/posts/28b74a2d/
+ https://www.ordchaos.com/posts/28b74a2d/
+ Fri, 04 Nov 2022 08:40:50 GMT
+
+ <p>如题,我要被这个神仙软件气死了。</p>
+
+
+
+ 如题,我要被这个神仙软件气死了。
起因
准备装unity写个游戏,学一学C#,然后就发现C盘爆满飘红。用SpaceSniffer看了一下——好家伙!
Picgo的日志文件,占了我58.6GB.
解释
当Picgo上传图片失败时就会开始疯狂写日志,然后文件大小就爆炸。
解决
删掉日志,从组策略里设置一下日志文件大小限制就好了。
可以参考这个:如何在Windows10系统设置日志文件的最大大小
题外话
就离谱!!!
]]>
+
+
+ 教程
+
+
+ 计算机
+
+ 编程
+
+ 教程
+
+ Picgo
+
+
+ https://www.ordchaos.com/posts/28b74a2d/#disqus_thread
+
+
+
+ -
+ 堆
+ https://www.ordchaos.com/posts/fab451a5/
+ https://www.ordchaos.com/posts/fab451a5/
+ Fri, 16 Sep 2022 19:22:59 GMT
+
+ <p>马上就是今年的CSP-J了,一想起自己还有那么多数据结构没学就有点头皮发麻…这篇博文里我就来讲一下堆(Heap),一是方便他人,二是给自己巩固思路。</p>
+
+
+
+ 马上就是今年的CSP-J了,一想起自己还有那么多数据结构没学就有点头皮发麻…这篇博文里我就来讲一下堆(Heap),一是方便他人,二是给自己巩固思路。
讲解
按照惯例哪里来的惯例,还是看一下堆是什么东西:
堆(heap)是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵树的数组对象。堆总是满足下列性质:
- 堆中某个结点的值总是不大于或不小于其父结点的值;
- 堆总是一棵完全二叉树。
将根结点最大的堆叫做最大堆或大根堆,根结点最小的堆叫做最小堆或小根堆。
——百度百科 堆
很显然,为了储存堆,我们需要一棵完全二叉树。这里很多人就会想到建树,但其实不用。如果你看过我的学习笔记——二叉树的话,应该会记得完全二叉树的性质之一:
在有n个节点的完全二叉树中,对于编号为i的节点:
- 若i=1,则其无父节点,为根节点,否则其父节点编号为floor(2i)。
- 若2i>n,则i为叶节点,否则其左孩子的编号为2i。
- 若2i<n<2i+1,则i无右孩子,否则其右孩子的编号为2i+1。
——序炁 学习笔记——二叉树
所以我们只需要一个数组就可以存储堆了:数组最开始填入根节点,其左右孩子节点便依次为其后面的两个下标,再往后就以此类推。
那么现在建立一个数据结构用来建堆,很简单,参照下列代码:
1
2
3
4
5
6
| #define MAXSIZE 100000
struct myHeap {
int value[MAXSIZE];
int length;
};
|
对于每一个堆都申请一个MAXSIZE大小的数组用于存储,而后用length变量存储目前的总节点数即可。
那么如何初始化就显而易见,只需要
1
2
3
4
| inline void init(myHeap &heap) {
heap.length = 0;
return;
}
|
像这样将length设为0就大功告成。
插入元素
如果要往一个堆里插入元素,那我们就要先确定这个堆是小根堆还是大根堆,下面的所有代码均默认是小根堆,大根堆自己改去自己想想吧。
首先,在堆末尾加入要插入的元素:
1
2
3
4
| void push(myHeap &heap, int v) {
heap.value[heap.length++] = v;
}
|
length永远指向数组中最后一个存储了数据的位置的下一个位置,所以在value[length]的位置存储数据,然后增加length即可。
但现在这个堆可能不满足小根堆的性质了,怎么办呢?很简单,进行调整即可。将新节点设为当前节点,如果它大于父节点则结束,若小于则交换,而后将交换后的父节点(没错,还是新插入的数据)设为当前节点,重复这个过程直到其大于父节点或其为根节点则结束。
听着有些复杂,但用while循环即可轻松实现:
1
2
3
4
5
6
7
8
9
| void push(myHeap &heap, int v) {
int now = length;
while(heap.value[now - 1] < heap.value[now / 2 - 1] && now != 1) {
swap(heap.value[now - 1], heap.value[now / 2 - 1]);
now /= 2;
}
return;
}
|
完事!
删除元素
删除元素即出队,会弹出根节点。故而这里的方法是把最后一个节点移到根节点的位置覆盖掉它,再进行调整。
覆盖很简单:
1
2
3
4
| void pop(myHeap &heap) {
heap.value[0] = heap.value[--heap.length];
}
|
不要忘记将节点数减一即可。这里用了一个小技巧,本来要写成这样:
1
2
| heap.value[0] = heap.value[heap.length - 1];
heap.length--;
|
竞赛常考之一,++i与i++的区别。不要觉得没用,比如用在这里就非常合适。包括前面的
1
| heap.value[heap.length++] = v;
|
也用了这个方法。
好了,言归正传,下一步是调整节点。显然,这一次需要从上往下调整:将根节点设为当前节点,与自己左右孩子中较小的一个比较,若小于则结束,否则与其交换位置并将当前节点设为交换好的孩子节点(一样指向同样的数据),重复这个过程直到当前节点为叶节点或当前节点小于自己任何一个孩子为止。
同样,上代码:
1
2
3
4
5
6
7
8
9
10
11
12
| void pop(myHeap &heap) {
int now = 1;
while(2 * now <= heap.length) {
int temp = 2 * now - 1;
if(temp + 2 <= heap.length && heap.value[temp] > heap.value[temp + 1]) temp++;
if(heap.value[now - 1] > heap.value[temp]) swap(heap.value[now - 1], heap.value[temp]);
else break;
now = temp + 1;
}
return;
}
|
需要额外注意的是对当前节点是否为叶节点以及是否拥有右孩子的判断,避免因失误导致数据溢出。
应用
其实堆的操作也只有插入与删除,不过就是这么简单的东西也可以玩出不同的花样,下面是两个例子。
洛谷 P1090 NOIP2004 提高组 合并果子
原题链接:洛谷 P1090 NOIP2004 提高组 合并果子
题目描述
在一个果园里,多多已经将所有的果子打了下来,而且按果子的不同种类分成了不同的堆。多多决定把所有的果子合成一堆。
每一次合并,多多可以把两堆果子合并到一起,消耗的体力等于两堆果子的重量之和。可以看出,所有的果子经过n-1次合并之后,就只剩下一堆了。多多在合并果子时总共消耗的体力等于每次合并所耗体力之和。
因为还要花大力气把这些果子搬回家,所以多多在合并果子时要尽可能地节省体力。假定每个果子重量都为1,并且已知果子的种类 数和每种果子的数目,你的任务是设计出合并的次序方案,使多多耗费的体力最少,并输出这个最小的体力耗费值。
例如有3种果子,数目依次为1,2,9. 可以先将1、2堆合并,新堆数目为3,耗费体力为3. 接着,将新堆与原先的第三堆合并,又得到新的堆,数目为12,耗费体力为12。所以多多总共耗费体力为3+12=15。可以证明15为最小的体力耗费值。
输入格式
共两行。
第一行是一个整数n(1≤n≤10000),表示果子的种类数。
第二行包含n个整数,用空格分隔,第i个整数ai(1≤ai≤20000)是第i种果子的数目。
输出格式
一个整数,也就是最小的体力耗费值。输入数据保证这个值小于231.
输入输出样例
输入
输出
分析
简单的贪心算法,每次从所有果子中取两堆数量最小的合并,然后放回去即可。
不一定非要用堆,不过如果只是简单的排序的话会超时。不过你同样也可以用优先队列,或者看看洛谷上那些神犇的题解。
我的方法很简单,只需要建堆,然后从堆中取两个最小值(即小根堆堆顶元素)相加再插回去,直到只剩一个元素即可。其中每一次合并时用一个变量累计总体力,最后输出就行了。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
| #include <bits/stdc++.h>
using namespace std;
#define MAXSIZE 100000
struct myHeap {
int value[MAXSIZE];
int length;
};
void push(myHeap &heap, int v) {
heap.value[heap.length++] = v;
int now = heap.length;
while(heap.value[now - 1] < heap.value[now / 2 - 1] && now != 1) {
swap(heap.value[now - 1], heap.value[now / 2 - 1]);
now /= 2;
}
return;
}
void pop(myHeap &heap) {
heap.value[0] = heap.value[--heap.length];
int now = 1;
while(2 * now <= heap.length) {
int temp = 2 * now - 1;
if(temp + 2 <= heap.length && heap.value[temp] > heap.value[temp + 1]) temp++;
if(heap.value[now - 1] > heap.value[temp]) swap(heap.value[now - 1], heap.value[temp]);
else break;
now = temp + 1;
}
return;
}
inline int get(myHeap heap) {
return heap.value[0];
}
int getPop(myHeap &heap) {
int temp = get(heap);
pop(heap);
return temp;
}
int main() {
int n;
cin>>n;
int temp;
myHeap test;
test.length = 0;
for(int i = 0;i < n;i++) {
cin>>temp;
push(test, temp);
}
int power = 0;
while(test.length != 1) {
int quick[2] = {getPop(test), getPop(test)};
power += quick[0] + quick[1];
push(test, quick[0] + quick[1]);
}
cout<<power<<endl;
return 0;
}
|
其中get函数用于返回堆顶元素,不要也可以,毕竟很简单。
对于这一题是可以AC的,没有问题。
堆排序
既然小根堆的堆顶元素永远最小,那么只要每次都取出堆顶元素直到堆为空不就可以排序了吗?没错,这就是堆排序,时间复杂度为O(nlogn),十分优秀。
代码我就不讲了,自己看吧:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
int main() {
int n;
cin>>n;
int temp;
myHeap test;
test.length = 0;
for(int i = 0;i < n;i++) {
cin>>temp;
push(test, temp);
}
for(int i = 0; i < n; i++) cout<<getPop(test)<<" ";
cout<<endl;
return 0;
}
|
数据量大的时候可以考虑堆排序,因为堆排序的耗时主要在建堆上,建好堆后的调整实际上非常快。
题外话
终于写完了…写了我整整三小时啊!
明天大概也许会有一篇关于图的,以及一篇关于类的。
886!
]]>
+
+
+ 编程
+
+
+ 计算机
+
+ 编程
+
+ c++
+
+
+ https://www.ordchaos.com/posts/fab451a5/#disqus_thread
+
+
+
+ -
+ 在线写作与博文分享—— NetlifyCMS 与 ShareThis
+ https://www.ordchaos.com/posts/8e1b39a3/
+ https://www.ordchaos.com/posts/8e1b39a3/
+ Sat, 10 Sep 2022 15:10:28 GMT
+
+ <p>没错,任何正常人都不会把标题里这两样东西联系起来,包括我。</p>
+
+
+
+ 没错,任何正常人都不会把标题里这两样东西联系起来,包括我。
NetlifyCMS
最开始看到这玩意是在fluid的官方博客的这一篇博文Hexo Netlify CMS 在线编辑博客(转载的,原文地址在这里),当时就觉得非常不错,但可惜未能按照教程配置成功,只得转投于更贴合于Hexo的HexoPlusPlusHexo艹
直到前几天上个月看到Xingyang在一键推流工具——BlogPusher这一篇文章下的评论:
如果静态博客是部署在 Github 上的话可以试试用 Netlify CMS。相当于架设一个能进行 Git Commit 的 Web app,最重要的就是 0 花费,Private Repo 也可以用。我自己的博客也在用(虽然文章数不是很多())
参考文章:https://cnly.github.io/2018/04/14/just-3-steps-adding-netlify-cms-to-existing-github-pages-site-within-10-minutes.html
很好,但是不太符合我的情况。于是随即翻了翻——
瞳 孔 地 震.jpg
完全可用!撒花!
如果你也没有成功配置Netlify CMS的话也可以试试,教程十分甚至九分简单,个人感觉几乎不存在出错的可能性。
感谢Xingyang!顺便他的博文链接:简单搭建一个 GitHub Repo 静态博客的 CMS 后台内容管理系统
ShareThis
最开始捣鼓了一阵子分享系统,share.js啊,Social Share Button啊等等都尝试过一遍,但我都不太满意,况且分享也不是刚需,于是就此作罢。
直到昨天,我妈问我:“你这个博客怎么分享给别人看啊?”
我突然感觉分享还是有必要的,遂继续开始寻觅,然后就发现了ShareThis
注册
非常简单,进入首页:https://sharethis.com
点击“从分享按钮开始”,然后点击第一个选项:
不要急着点击下一步,先用滚轮滚动到页面下方,点击“Customize your Inline Share Buttons”按钮。
在弹出的选项中对按钮进行配置,可以配置包括颜色、媒体、形状等等内容。
最下方的语言记得调整为中文,然后点击下一步,在新页面中注册登录即可。
随后,你会得到两串代码,分别是js安装代码与按钮引入代码。安装代码放在head中,按钮放在你想插入的地方就好。
大概如下:
1
2
|
<script type='text/javascript' src='https://platform-api.sharethis.com/js/sharethis.js#property=不告诉你&product=inline-share-buttons' async='async'></script>
|
1
2
|
<div class="sharethis-inline-share-buttons"></div>
|
效果
滑到这篇文章底下看吧。
题外话
这篇博文算是对近期我对博客的大改动,但是单独发太短,所以就这么整合在一起了。
那就这样,这篇博文就到这里,886!
]]>
+
+
+ 教程
+
+
+ 计算机
+
+ 教程
+
+ Hexo
+
+
+ https://www.ordchaos.com/posts/8e1b39a3/#disqus_thread
+
+
+
+ -
+ 满十四,进十五。愿我青春无悔,不负韶华
+ https://www.ordchaos.com/posts/e84bad58/
+ https://www.ordchaos.com/posts/e84bad58/
+ Wed, 24 Aug 2022 20:00:00 GMT
+
+ 十五岁啦!希望初三及中考顺利!
+
+
+
+ 又大了一岁呢…
令青春无悔,愿韶华不负!
希望明年的此刻,我能够无愧于自己。
]]>
+
+
+ 日常
+
+ 短文
+
+
+ 生日
+
+ 短文
+
+
+ https://www.ordchaos.com/posts/e84bad58/#disqus_thread
+
+
+
+ -
+ 生日当天全款提下第一支(打八折)钟薛糕
+ https://www.ordchaos.com/posts/7e920bb4/
+ https://www.ordchaos.com/posts/7e920bb4/
+ Wed, 24 Aug 2022 17:46:00 GMT
+
+ 记我的第一支(不知道是不是最后一支)钟薛糕
+
+
+
+
送给自己的生日礼物我是大怨种
]]>
+
+
+ 日常
+
+ 短文
+
+
+ 生日
+
+ 短文
+
+
+ https://www.ordchaos.com/posts/7e920bb4/#disqus_thread
+
+
+
+ -
+ Phigros 版本迁移——从 Google Play 到 Tap Tap
+ https://www.ordchaos.com/posts/e8587b82/
+ https://www.ordchaos.com/posts/e8587b82/
+ Sun, 21 Aug 2022 18:20:50 GMT
+
+ Google Play的版本更新总是慢一些,不知道你行不行,但是我是忍不了别人都玩上了新曲而我却还不能玩的感觉,遂决定迁移存档
+
+
+
+ 起因
Google Play的版本更新总是慢一些,不知道你行不行,但是我是忍不了别人都玩上了新曲而我却还不能玩的感觉,遂决定迁移存档。
过程
大体参考这一篇文章Phigros存档跨版本转移教程(免root)即可,在这里稍微提一下我遇到的问题
解决问题
在使用abe.jar时,Java报错:
1
| Error: A JNI error has occurred, please check your installation and try again
|
首先在网上查询,找到的第一个方法是删除电脑里共存的JDK,只留下一个,使java -version与javac -version有相同的版本。
我照做,删除了java8,只留下了openjdk17,但是毫无卵用。
于是我继续查询,发现在跨!系!统!转!移!支持安卓和IOS的跨系统存档转移工具!Phigros 存档 IOS 跨系统 备份 还原 转移 同步这一视频中所提供的工具里的abe.jar可用。
总结
如果你也遇到了一样的问题,可以参考我的方法看看是否有效。
若不想下载整个备份工具而只想要abe.jar的话,可以从这里下载:链接(如有侵权,请联系我删除)
]]>
+
+
+ 教程
+
+ Phigros
+
+
+ 计算机
+
+ 编程
+
+ 教程
+
+ adb
+
+ 手机
+
+ phigros
+
+
+ https://www.ordchaos.com/posts/e8587b82/#disqus_thread
+
+
+
+ -
+ 【多图预警】 AwtrixPro 开源项目的复现
+ https://www.ordchaos.com/posts/774674fe/
+ https://www.ordchaos.com/posts/774674fe/
+ Fri, 19 Aug 2022 18:04:08 GMT
+
+ <p>本人对AwtrixPro垂涎已久,但却懒得复现。暑假的物理作业包含一个对电学有关的实验,遂趁此机会复现一个出来。</p>
+
+
+
+ 本人对AwtrixPro垂涎已久,但却懒得复现。暑假的物理作业包含一个对电学有关的实验,遂趁此机会复现一个出来。
材料采购
并不难,跟着官网的这个网页一步步在淘宝上找就可以了。就是记得买焊接工具以及足够量的耗材(指Gpio线材、热熔胶、电工胶带等等)以及外壳(可以用官网上的文件3D打印,淘宝上也有直接卖的)。
这里贴出我购买材料的链接,有兴趣的话可以试一试(加粗的为非必需品,没有注明数量默认1个,没有注明平台默认淘宝或天猫):
硬件制作
PCB+针脚焊接
本人未成功通过此方法复现,下列内容不一定完全正确,仅供参考
参考B站UP主三三三三三文啊的视频【AWTRIX PRO】一起动手做一个高颜值的像素灯,在嘉立创打好板子(注意有贴片,需要开钢网),买好GPIO接口公母头再焊接即可。打板流程可以参考【0基础】从零开始电子DIY!第三集:PCB电路板设计和打样!,这一套教程非常不错,推荐。
打好的板子如下:
焊接好之后(贴片是用的钢网+锡焊膏+风枪):
焊接针脚时若是无法直接使用锡丝与电烙铁焊接完成,也可以用锡焊膏+电烙铁。把锡焊膏涂抹在针脚背面,不用担心粘连,然后用电烙铁分别探入每两个针脚间的空隙,随后依次处理每个针脚就可以了。
然后刷程序、接线、通电、启动即可(至少理论上是这样):
很明显,这里并未启动成功,望高手赐教。
手动飞线
根据官网的接线图进行手动飞线即可,这里因为缺少一个电容(C1, 100nF)且不知道哪里有卖的而未接上DFPlayer模块及喇叭。
这里除了基础配件外,额外加装了光敏电阻、触摸以及Htui21d温湿度模块。基础部分依据教你做一个可编程像素屏制作成功,然后通过自主飞线完成了其它组件的安装。
没有什么难点,注意需要连接多根导线时用钳子分别剪开线的外皮,露出里面的铜/铁/其他金属丝,拧在一起然后用电烙铁与锡焊在一起就可以了。
裸露的金属丝记得用电工胶带或者热熔胶包裹起来,防止意外:
然后装入外壳即可:
再放上格栅、均光片及亚克力面板就完成了:
软件配置
软件这里就不再多提,官网上就有(点击这里访问)。就是说一下我这里是部署在我自己的服务器上,就无需本地服务器如树莓派一类了。
宝塔面板就可以轻松完成配置,也无需ssh连接。
然后安装自己喜欢的软件即可,我这里是这几个:
成品
题外话
从暑假开始一直做到了倒数第二天…心累,不过总算是完成了,也让我发现了我的电工天赋(bushi
那就这样,这篇报告(?)就完成了,感谢你的观看,886
]]>
+
+
+ 编程
+
+ 硬件
+
+
+ 计算机
+
+ 编程
+
+ github
+
+ 开源软件
+
+ awtrix
+
+ 硬件
+
+ 复现
+
+
+ https://www.ordchaos.com/posts/774674fe/#disqus_thread
+
+
+
+ -
+ 解决一件困扰我很久的小事
+ https://www.ordchaos.com/posts/8ad10849/
+ https://www.ordchaos.com/posts/8ad10849/
+ Fri, 19 Aug 2022 09:40:50 GMT
+
+ 偶然间看到了这个视频——[Phigros/技术革新]快速获取自己的B19成绩图,眼馋,也想要,遂跟着做,结果却......
+
+
+
+ 起因
偶然间看到了这个视频——[Phigros/技术革新] 快速获取自己的B19成绩图,眼馋,也想要,遂跟着做,结果却…
大☆失☆败
手机自始至终没有弹出“完全备份”界面,我百思不得其解,于是在stackoverflow上发了一个问题:
Adb backup does not work on my HarmonyOS 2.0 phone
直到今天之前,没有任何人给出有效回答。
解决
把之前在手机里安装的软件“冰箱”卸载之后就正常了,我也不知道为什么。
从这件事就可以看出我是个…欸,我不说,就是玩
自己去把问题给解答了,这件事就此完结。
题外话
生成都生成了,那就晒一下吧:
小菜一枚,大佬轻喷。
那就这样,886
]]>
+
+
+ 教程
+
+ Phigros
+
+
+ 计算机
+
+ 编程
+
+ 教程
+
+ adb
+
+ 手机
+
+ phigros
+
+ 安卓
+
+ 鸿蒙
+
+
+ https://www.ordchaos.com/posts/8ad10849/#disqus_thread
+
+
+
+ -
+ Hexo 通过 GitHub Action 自动部署到云虚拟主机
+ https://www.ordchaos.com/posts/1e44a102/
+ https://www.ordchaos.com/posts/1e44a102/
+ Tue, 16 Aug 2022 18:04:50 GMT
+
+ <p>购买了<a href="https://www.foreverblog.cn/">十年之约</a>的优惠价<a href="https://www.vpsor.cn/">硅云</a>虚拟主机用于加速访问,记录一下部署过程。</p>
+
+
+
+ 购买了十年之约的优惠价硅云虚拟主机用于加速访问,记录一下部署过程。
前提条件
你需要已经配置好了GitHub Action的Hexo自动部署,若是没有,推荐观看以下文章:
这里就不讲了。
编辑Action
打开(本地博客仓库目录)/.github/workflows/(Action配置文件).yml,在最后添加:
1
2
3
4
5
6
7
8
9
| - name: Deploy Files on Ftp Server
uses: SamKirkland/FTP-Deploy-Action@4.3.0
with:
server: (FTP服务器地址)
username: (FTP用户名)
password: (FTP密码)
local-dir: ./public/
server-dir: (FTP服务器文件目录)
port: (FTP服务器端口,一般是21)
|
将括号及内部内容换成自己的信息即可。
这里的方法是使用ftp来上传文件到虚拟主机,是对于所有虚拟主机而言最通用的一种方式了。./public是Hexo默认的静态文件生成本地地址,无需更改。
最后推流到GitHub即可使用。
题外话
本来以为挺复杂,结果就这么点。
最开始使用的是hexo-deployer-ftpsync插件,结果却根本无法正常使用,于是便转为使用docker镜像。
对了,如果有兴趣购买硅云的主机,那请帮个小忙,用我的邀请链接注册吧:邀请链接
那就这样,886
]]>
+
+
+ 教程
+
+
+ 计算机
+
+ 编程
+
+ 教程
+
+ Hexo
+
+ 虚拟主机
+
+ 网站
+
+ GitHub
+
+ 自动化
+
+ GitHub Action
+
+
+ https://www.ordchaos.com/posts/1e44a102/#disqus_thread
+
+
+
+ -
+ 《梁启超传》议论文素材积累
+ https://www.ordchaos.com/posts/2f728g0f/
+ https://www.ordchaos.com/posts/2f728g0f/
+ Sat, 13 Aug 2022 13:33:00 GMT
+
+ <p>与<a href="https://www.ordchaos.com/posts/1e617f9e/">之前那一篇</a>一样是暑假的语文作业,也是对这本书全本的分节概括以及议论文的素材积累,外加上对应适用的议论文题材。</p>
+
+
+
+ 与之前那一篇一样是暑假的语文作业,也是对这本书全本的分节概括以及议论文的素材积累,外加上对应适用的议论文题材。
第一章 一世纪以来中国的命运——从鸦片战争至梁氏诞生的前夕
第一节 绪说
梁启超生在中国近代最悲惨的100年(1842-1943)年中,虽屡次想跳海自尽,但仍坚决地相信中国必然不亡且断然复兴,所以他才在全然无望中挣扎奋斗。
作文:坚持、毅力、精神
第二节 梁氏生前中国一般的惨况
《奴才好》中足以令人怒发冲冠的描写在当时黑暗社会的情境下甚至不被人认为是严重的怪象。
慈禧太后奢靡无度,倾尽全国财力为自己所用,掏空了国库,令全中国上下不得安宁。
清末国家机构的腐败,如“外交部”(总理衙门)工作人员甚至无法分清澳门与澳洲。
清末军队素质极差,上下组织腐败,不能防国,只能累民。
清末经济建设几乎毫无成效,只因“官与民争”就扩大为了导致清朝覆灭的致命伤。
作文:珍惜、强国、学习
第三节 梁氏生前中国一般的教育状况
清末满朝士大夫都有一种目中无人的气势,自觉这清朝乃是天下第一。
清末全国几乎没有半个学校的教育,教导孩子不去烟馆、青楼而在家里抽大烟、挑“丫头”都成为了“教子有方”。
清末文人及有志青年深受八股文之害,令八股文成为活埋青年的天坑。
清末人民对“洋”存在极深的偏见,如官办“洋学堂”都十分遭人唾弃,只能拉到一批不三不四的学生。校内不教德育、爱国,而只是学习西方下等人的恶俗。
作文:环境、强国、学习
第四节 梁氏后来对于祖国命运的影响
作文:坚持、偶像、伟人
第二章 亡国现象与维新初潮——从梁氏诞生至戊戌政变
第五节 综叙
1873年,梁启超出生。此时近代伟人俱全,又冲破了鸦片战争以来中国所带之枷锁,正是突破了低于底层的黑暗,看见天际的一缕祥光。
作文:努力、坚持、时代
第六节 亡国现象的种种——梁氏生后的中国惨况
梁启超出生之后的中国同样是战争不断,且更偏向于内乱。
此时国际形势大好,西方列强都成为了天之骄子,合力来对付中国一国,令中国无辜受到车裂及凌迟之刑。
日本对中国早有图谋,在其只是一个弹丸之地的效果时就已经企图占据朝鲜与中国,且当时日本名士几乎都有着不一的“吞华论”。
作文:毅力、黑暗、光明、社会、时代
第七节 梁氏幼年的家庭生活及家乡环境
作文:爱国、强国、富国、伟人、偶像
第八节 康梁会接
作文:智慧、计划、学习
第九节 梁氏独立事业的开始
梁启超脱胎于长兴学社创立新学。在这样一种不拘形式而朝气蓬勃的学风之下,造就出了许多具有新思想人才,当时一般的学生只有四十人,而五分之二都成为了革命先烈或开国名人。
梁启超创学会启发心智,推行维新,学会中政治性质强大。在戊戌八月政变失败之后,所有的学会都秘密含有了革命的使命,与前期的学会性质有根本上的不同。
梁启超为推行维新而创办报纸。此时,他已明白,学校、学会、报纸是三位一体互相为用的,缺一不可。所以,在北京办学会的时候,他就已经开始办报。这是梁启超生平新闻事业开始的第一章,也是近代中国有正式意义的新闻开始的第一页。
作文:智慧、方法、强国
第三章 维新的失败与革命的成功
第十节 促成戊戌变法的原因
外因-远因:清政府的闭关锁国政策、杀沙俄实力的突飞猛进、列强对中国的围攻、洋务运动的失败。
外因-近因:日本民治维新的胜利、甲午战争失败的国耻、中国被蚕食的痛苦、防止陷入土耳其不变法而衰弱的覆辙。
内因-远因:清政府长期积累政治恶习的崩溃、满族战斗能力与战斗意识的降低、太平天国运动后实际政权的转移、以慈禧太后为核心的宫廷政变。
内因-近因:慈禧太后与皇帝权力的争夺、满族嫉妒汉族情感的具象化、孙中山先生领导的革命运动的激进,国内舆论更加倾向于维新。
由于以上这十六点各种各样的原因,到戊戌年间维新运动已成瓜熟蒂落的现象,除了冥顽无耻,卖身求荣的少数败类以外,几乎所有人都是渴望政治改革有如甘霖一般。
作文:强国、因果、历史
第十一节 戊戌政变史剧的绘影
戊戌变法的规模既不如日本明治维新,就连康有为公车上书的内容也还有千里之差。但就算只是这样,对于当时的清政府而言,也已经算是大刀阔斧了,此时正是光绪帝把皇威发扬到顶点的时候。
光绪帝想趁着改革的机会罢免几个守旧的大臣,但这些顽固的大臣转而向“老佛爷”求助,于是慈禧太后勃然大怒,将光绪帝囚禁而自己垂帘听政,在实际上掌握了清政府的权力。
康有为、梁启超等“小人”“大逆”受“可恶透顶”的“洋鬼子”的保护,躲开了慈禧太后的清算。其中,谭嗣同本来由日本严密保护,但却自己重新自动出来,愿抛头颅以改造祖国百年的命运。如此的忠与侠实属罕见,也值得我们敬佩。
作文:强国、历史、光明、黑暗、方法
第十二节 政变失败原因的解析
清政府内部早已腐朽不堪,全国大权都在慈禧太后之手,而满人的猜疑程度又大到难以想象,更是有许多守旧的大臣。变法本就是一个不可能完成的任务。
康有为虽然魄力强大、精神勇猛、感情丰富、毅力坚韧,但他同样心胸不广、态度傲慢、个性执拗、理智不强、做事无序、缺乏科学训练、不求上进、所学太杂而不适用其时代,却反而骄然不惭,自谓贯通天地人。
满人生来仇视汉人,排挤汉人,甚至在百维新期间出现了满洲人所谓闹鬼的趣事。在这样的排挤、压迫、攻击之下,维新救国、变法图强本就是一个荒唐的幻想。
一些守旧分子自满于既得利益而不愿其被损伤分毫,故而极力阻挠变法。
作文:方法、强国、历史、革命、国庆
]]>
+
+
+ 文学
+
+
+ 文学
+
+ 作文
+
+ 读后感
+
+ 议论文
+
+ 素材
+
+
+ https://www.ordchaos.com/posts/2f728g0f/#disqus_thread
+
+
+
+
+
diff --git a/sitemap.xml b/sitemap.xml
new file mode 100644
index 000000000..d8d555291
--- /dev/null
+++ b/sitemap.xml
@@ -0,0 +1,1025 @@
+
+
+
+
+ https://www.ordchaos.com/manifest.json
+
+ 2024-02-10
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/owo.json
+
+ 2024-02-10
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/leave/index.html
+
+ 2024-02-10
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/talk/index.html
+
+ 2024-02-10
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/about/index.html
+
+ 2024-02-10
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/fcircle/index.html
+
+ 2024-02-10
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/23e22de2/
+
+ 2024-02-10
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/e9c784c5/
+
+ 2024-02-09
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/95bd9bb8/
+
+ 2023-08-24
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/b3d3143c/
+
+ 2023-07-23
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/ec8c9790/
+
+ 2023-07-06
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/c2e7460a/
+
+ 2023-07-01
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/c9c6cb4f/
+
+ 2023-04-03
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/7eb4319/
+
+ 2023-03-26
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/3b90dbec/
+
+ 2022-11-28
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/3386e07f/
+
+ 2022-11-26
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/28b74a2d/
+
+ 2022-11-04
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/fab451a5/
+
+ 2022-09-16
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/8e1b39a3/
+
+ 2022-09-10
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/e84bad58/
+
+ 2022-08-24
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/7e920bb4/
+
+ 2022-08-24
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/e8587b82/
+
+ 2022-08-21
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/774674fe/
+
+ 2022-08-19
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/8ad10849/
+
+ 2022-08-19
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/1e44a102/
+
+ 2022-08-16
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/2f728g0f/
+
+ 2022-08-13
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/618137f7/
+
+ 2022-08-10
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/d9bb8734/
+
+ 2022-08-09
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/46d2370f/
+
+ 2022-08-09
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/e8ce405d/
+
+ 2022-08-06
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/1e617f9e/
+
+ 2022-08-05
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/97a1a73e/
+
+ 2022-08-02
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/6a062b97/
+
+ 2022-08-01
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/f0f71147/
+
+ 2022-07-27
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/10824f12/
+
+ 2022-07-25
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/340b325e/
+
+ 2022-07-01
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/d4140423/
+
+ 2022-07-01
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/79cc3297/
+
+ 2022-06-15
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/6270475f/
+
+ 2022-06-04
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/ab8676cc/
+
+ 2022-05-12
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/4996fe6c/
+
+ 2022-05-04
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/da7075f0/
+
+ 2022-04-09
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/7e535678/
+
+ 2022-01-27
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/8f132c87/
+
+ 2021-12-25
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/bff2b1a/
+
+ 2021-12-13
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/92674965/
+
+ 2021-07-31
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/d29e300c/
+
+ 2021-06-23
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/bb5ce830/
+
+ 2021-04-23
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/53c0d957/
+
+ 2021-03-20
+
+ monthly
+ 0.6
+
+
+
+ https://www.ordchaos.com/posts/7b015599/
+
+ 2020-12-10
+
+ monthly
+ 0.6
+
+
+
+
+ https://www.ordchaos.com/
+ 2024-02-10
+ daily
+ 1.0
+
+
+
+
+ https://www.ordchaos.com/tags/%E6%BC%94%E8%AE%B2%E7%A8%BF/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E7%BA%AF%E8%8B%B1%E6%96%87/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/English/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E5%90%88%E5%94%B1/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E9%9F%B3%E4%B9%90/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E8%AE%A1%E7%AE%97%E6%9C%BA/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E7%BC%96%E7%A8%8B/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/c/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E6%95%99%E7%A8%8B/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/Hexo/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E8%99%9A%E6%8B%9F%E4%B8%BB%E6%9C%BA/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E7%BD%91%E7%AB%99/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/GitHub/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E8%87%AA%E5%8A%A8%E5%8C%96/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/GitHub-Action/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/adb/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E6%89%8B%E6%9C%BA/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/phigros/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/Picgo/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E6%96%87%E5%AD%A6/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E4%BD%9C%E6%96%87/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E8%AF%BB%E5%90%8E%E6%84%9F/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E8%AE%AE%E8%AE%BA%E6%96%87/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E7%B4%A0%E6%9D%90/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E7%99%BD%E5%AB%96/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E7%A6%8F%E5%88%A9/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/s3%E6%A1%B6/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/github/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E5%BC%80%E6%BA%90%E8%BD%AF%E4%BB%B6/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/awtrix/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E7%A1%AC%E4%BB%B6/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E5%A4%8D%E7%8E%B0/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E5%AD%A6%E7%94%9F/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E6%95%B0%E5%AD%A6/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E4%BC%98%E5%8C%96/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E7%AE%97%E6%B3%95/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E6%97%A5%E5%B8%B8/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E6%97%85%E8%A1%8C/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E7%94%9F%E6%97%A5/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E6%80%BB%E7%BB%93/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E4%B8%AA%E4%BA%BA/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E7%94%B5%E5%BD%B1/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E5%BC%80%E7%AE%B1/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E7%A7%91%E6%8A%80/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/U%E7%9B%98/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E5%91%A8%E8%BE%B9/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/javascript/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/css/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/AI/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E7%9F%AD%E6%96%87/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E8%BE%A9%E8%AE%BA/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E7%89%BA%E7%89%B2/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/sai/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E6%89%8B%E7%BB%98/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E7%94%BB%E7%94%BB/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E5%8C%96%E5%AD%A6/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E7%94%B5%E5%AD%90%E9%82%AE%E4%BB%B6/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/vps/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/memos/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/html/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E8%AF%B4%E8%AF%B4/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E5%89%8D%E7%AB%AF/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E5%AE%89%E5%8D%93/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E9%B8%BF%E8%92%99/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E5%AD%A6%E4%B9%A0/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/tags/%E8%80%83%E8%AF%95/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+
+
+ https://www.ordchaos.com/categories/%E8%8B%B1%E8%AF%AD/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/categories/%E7%BC%96%E7%A8%8B/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/categories/%E6%95%99%E7%A8%8B/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/categories/%E9%9F%B3%E4%B9%90/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/categories/%E6%96%87%E5%AD%A6/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/categories/%E7%A1%AC%E4%BB%B6/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/categories/%E6%95%B0%E5%AD%A6/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/categories/Phigros/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/categories/%E6%97%A5%E5%B8%B8/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/categories/%E8%BE%A9%E8%AE%BA/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/categories/%E7%BE%8E%E6%9C%AF/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/categories/%E7%9F%AD%E6%96%87/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/categories/%E4%B8%AA%E4%BA%BA/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
+ https://www.ordchaos.com/categories/%E5%8C%96%E5%AD%A6/
+ 2024-02-10
+ weekly
+ 0.2
+
+
+
diff --git a/sw.js b/sw.js
new file mode 100644
index 000000000..9a6f631d7
--- /dev/null
+++ b/sw.js
@@ -0,0 +1 @@
+const CACHE_NAME="OCXQCache";let cachelist=["https://img.ordchaos.com/img/2023/01/557e41f1eba9dab1399774a8ef7e679a.jpg","https://img.ordchaos.com/img/2023/01/557e41f1eba9dab1399774a8ef7e679a.webp","/img/loading.gif","/css/navbar.css","/css/custom.css","/css/fcircle-ext.css","/css/notice.css","/js/jump.js","/js/tw_cn_tran.js","/js/rand.js","/js/lately.min.js","/js/duration.js","/js/jquery.min.js","/js/moment.min.js","/js/aisummary.js","/owo.json"];self.addEventListener("install",async function(t){self.skipWaiting(),t.waitUntil(caches.open(CACHE_NAME).then(function(t){return console.log("[SW] Opened cache."),t.addAll(cachelist)}))}),self.addEventListener("fetch",async t=>{var e=t.request.url;if(-1===t.request.url.indexOf("hm.baidu.com")){if(-1!==t.request.url.indexOf("img.ordchaos.com")){var n=!1;if(t.request.headers.has("accept")&&(n=t.request.headers.get("accept").includes("webp")),n){var s=e.split(".");if("jpg"===s[s.length-1]||"tif"===s[s.length-1]||"png"===s[s.length-1]||"jpeg"===s[s.length-1]){var r=e.replace(s[s.length-1],"webp"),c=new Request(r);return t.respondWith(fetch(c)),console.log("[SW] Redirect "+e+" to "+r+" ."),t.waitUntil(fetch(c).then(function(t){if(!t.ok)throw new Error("[SW] Failed to load image: "+r);caches.open(CACHE_NAME).then(function(e){e.put(c,t)})}).catch(function(t){console.log(t)})),void t.stopImmediatePropagation()}}else console.log("[SW] Don't support webp image, skip "+e+" .")}try{t.respondWith(handle(t.request))}catch(e){t.respondWith(handleerr(t.request,e))}}});const handleerr=async(t,e)=>new Response(`CDN分流器遇到了致命错误
\n ${e}`,{headers:{"content-type":"text/html; charset=utf-8"}});let cdn={gh:{jsdelivr:{url:"https://cdn.jsdelivr.net/gh"},jsdelivr_fastly:{url:"https://fastly.jsdelivr.net/gh"},jsdelivr_gcore:{url:"https://gcore.jsdelivr.net/gh"},jsdelivr_ocxq:{url:"https://jsd.ordchaos.top/gh"}},combine:{jsdelivr:{url:"https://cdn.jsdelivr.net/combine"},jsdelivr_fastly:{url:"https://fastly.jsdelivr.net/combine"},jsdelivr_gcore:{url:"https://gcore.jsdelivr.net/combine"},jsdelivr_ocxq:{url:"https://jsd.ordchaos.top/combine"}},npm:{eleme:{url:"https://npm.elemecdn.com"},jsdelivr:{url:"https://cdn.jsdelivr.net/npm"},zhimg:{url:"https://unpkg.zhimg.com"},unpkg:{url:"https://unpkg.com"},bdstatic:{url:"https://code.bdstatic.com/npm"},tianli:{url:"https://cdn1.tianli0.top/npm"},sourcegcdn:{url:"https://npm.sourcegcdn.com/npm"},jsdelivr_ocxq:{url:"https://jsd.ordchaos.top/npm"}}};const is_latest=t=>"latest"===t.replace("https://","").split("/")[1].split("@")[1],cache_url_list=[/(http:\/\/|https:\/\/)cdn\.jsdelivr\.net/g,/(http:\/\/|https:\/\/)fastly\.jsdelivr\.net/g,/(http:\/\/|https:\/\/)gcore\.jsdelivr\.net/g,/(http:\/\/|https:\/\/)jsd\.ordchaos\.top/g,/(http:\/\/|https:\/\/)npm\.elemecdn\.com/g,/(http:\/\/|https:\/\/)cdn\.bootcss\.com/g,/(http:\/\/|https:\/\/)zhimg\.unpkg\.com/g,/(http:\/\/|https:\/\/)unpkg\.com/g,/(http:\/\/|https:\/\/)code\.bdstatic\.com/g,/(http:\/\/|https:\/\/)cdn1\.tianli0\.top/g,/(http:\/\/|https:\/\/)npm\.sourcegcdn\.com/g,/(http:\/\/|https:\/\/)cdn\.bootcdn\.net/g],handle=async function(t){const e=t.url,n=e.split("/")[2];let s=[];for(let r in cdn)for(let c in cdn[r])if(n==cdn[r][c].url.split("https://")[1].split("/")[0]&&e.match(cdn[r][c].url)){s=[];for(let t in cdn[r])s.push(e.replace(cdn[r][c].url,cdn[r][t].url));return e.indexOf("@latest/")>-1?lfetch(s,e):caches.match(t).then(function(n){return n||lfetch(s,e).then(function(e){return caches.open(CACHE_NAME).then(function(n){return n.put(t,e.clone()),e})})})}for(var r in cache_url_list){if(is_latest(t.url))return fetch(t);if(t.url.match(cache_url_list[r]))return caches.match(t).then(function(e){return e||fetch(t).then(function(e){return caches.open(CACHE_NAME).then(function(n){return n.put(t,e.clone()),e})})})}return fetch(t)},lfetch=async(t,e)=>{let n=new AbortController;const s=async t=>new Response(await t.arrayBuffer(),{status:t.status,headers:t.headers});return Promise.any||(Promise.any=function(t){return new Promise((e,n)=>{let s=(t=Array.isArray(t)?t:[]).length,r=[];if(0===s)return n(new AggregateError("All promises were rejected"));t.forEach(t=>{t.then(t=>{e(t)},t=>{s--,r.push(t),0===s&&n(new AggregateError(r))})})})}),Promise.any(t.map(t=>new Promise((e,r)=>{fetch(t,{signal:n.signal}).then(s).then(t=>{200==t.status?(n.abort(),e(t)):r(t)})})))};
\ No newline at end of file
diff --git a/sw.origin.js b/sw.origin.js
new file mode 100644
index 000000000..449dc7ccf
--- /dev/null
+++ b/sw.origin.js
@@ -0,0 +1,244 @@
+const CACHE_NAME = 'OCXQCache';
+let cachelist = [
+ 'https://img.ordchaos.com/img/2023/01/557e41f1eba9dab1399774a8ef7e679a.jpg',
+ 'https://img.ordchaos.com/img/2023/01/557e41f1eba9dab1399774a8ef7e679a.webp',
+ '/img/loading.gif',
+ '/css/navbar.css',
+ '/css/custom.css',
+ '/css/fcircle-ext.css',
+ '/css/notice.css',
+ '/js/jump.js',
+ '/js/tw_cn_tran.js',
+ '/js/rand.js',
+ '/js/lately.min.js',
+ '/js/duration.js',
+ '/js/jquery.min.js',
+ '/js/moment.min.js',
+ '/js/aisummary.js',
+ '/owo.json'
+];
+self.addEventListener('install', async function (installEvent) {
+ self.skipWaiting();
+ installEvent.waitUntil(
+ caches.open(CACHE_NAME)
+ .then(function (cache) {
+ console.log('[SW] Opened cache.');
+ return cache.addAll(cachelist);
+ })
+ );
+});
+self.addEventListener('fetch', async event => {
+ var requestUrl = event.request.url;
+ if(event.request.url.indexOf('hm.baidu.com') !== -1) {
+ return;
+ }
+
+ if(event.request.url.indexOf('img.ordchaos.com') !== -1) {
+ var supportsWebp = false;
+ if (event.request.headers.has('accept')){
+ supportsWebp = event.request.headers
+ .get('accept')
+ .includes('webp');
+ }
+ if (supportsWebp) {
+ var imageUrl = requestUrl.split(".");
+ if(imageUrl[imageUrl.length - 1] === 'jpg' || imageUrl[imageUrl.length - 1] === 'tif' || imageUrl[imageUrl.length - 1] === 'png' || imageUrl[imageUrl.length - 1] === 'jpeg'){
+ var newUrl = requestUrl.replace(imageUrl[imageUrl.length - 1], 'webp');
+ var newRequest = new Request(newUrl);
+ event.respondWith(fetch(newRequest));
+ console.log("[SW] Redirect " + requestUrl + " to " + newUrl + " .");
+ event.waitUntil(
+ fetch(newRequest).then(function(response) {
+ if (!response.ok) throw new Error("[SW] Failed to load image: " + newUrl);
+ caches.open(CACHE_NAME).then(function(cache) {
+ cache.put(newRequest, response);
+ });
+ }).catch(function(error) {
+ console.log(error);
+ })
+ );
+ event.stopImmediatePropagation();
+ return;
+ }
+ }
+ else {
+ console.log("[SW] Don't support webp image, skip " + requestUrl + " .");
+ }
+ }
+
+ try {
+ event.respondWith(handle(event.request))
+ } catch (msg) {
+ event.respondWith(handleerr(event.request, msg))
+ }
+});
+const handleerr = async (req, msg) => {
+ return new Response(`CDN分流器遇到了致命错误
+ ${msg}`, { headers: { "content-type": "text/html; charset=utf-8" } })
+}
+let cdn = {//镜像列表
+ "gh": {
+ jsdelivr: {
+ "url": "https://cdn.jsdelivr.net/gh"
+ },
+ jsdelivr_fastly: {
+ "url": "https://fastly.jsdelivr.net/gh"
+ },
+ jsdelivr_gcore: {
+ "url": "https://gcore.jsdelivr.net/gh"
+ },
+ jsdelivr_ocxq: {
+ "url": "https://jsd.ordchaos.top/gh"
+ }
+ },
+ "combine": {
+ jsdelivr: {
+ "url": "https://cdn.jsdelivr.net/combine"
+ },
+ jsdelivr_fastly: {
+ "url": "https://fastly.jsdelivr.net/combine"
+ },
+ jsdelivr_gcore: {
+ "url": "https://gcore.jsdelivr.net/combine"
+ },
+ jsdelivr_ocxq: {
+ "url": "https://jsd.ordchaos.top/combine"
+ }
+ },
+ "npm": {
+ eleme: {
+ "url": "https://npm.elemecdn.com"
+ },
+ jsdelivr: {
+ "url": "https://cdn.jsdelivr.net/npm"
+ },
+ zhimg: {
+ "url": "https://unpkg.zhimg.com"
+ },
+ unpkg: {
+ "url": "https://unpkg.com"
+ },
+ bdstatic: {
+ "url": "https://code.bdstatic.com/npm"
+ },
+ tianli: {
+ "url": "https://cdn1.tianli0.top/npm"
+ },
+ sourcegcdn: {
+ "url": "https://npm.sourcegcdn.com/npm"
+ },
+ jsdelivr_ocxq: {
+ "url": "https://jsd.ordchaos.top/npm"
+ }
+
+ }
+}
+
+const is_latest = (url) => {
+ return url.replace('https://', '').split('/')[1].split('@')[1] === 'latest';
+}
+
+const cache_url_list = [
+ /(http:\/\/|https:\/\/)cdn\.jsdelivr\.net/g,
+ /(http:\/\/|https:\/\/)fastly\.jsdelivr\.net/g,
+ /(http:\/\/|https:\/\/)gcore\.jsdelivr\.net/g,
+ /(http:\/\/|https:\/\/)jsd\.ordchaos\.top/g,
+ /(http:\/\/|https:\/\/)npm\.elemecdn\.com/g,
+ /(http:\/\/|https:\/\/)cdn\.bootcss\.com/g,
+ /(http:\/\/|https:\/\/)zhimg\.unpkg\.com/g,
+ /(http:\/\/|https:\/\/)unpkg\.com/g,
+ /(http:\/\/|https:\/\/)code\.bdstatic\.com/g,
+ /(http:\/\/|https:\/\/)cdn1\.tianli0\.top/g,
+ /(http:\/\/|https:\/\/)npm\.sourcegcdn\.com/g,
+ /(http:\/\/|https:\/\/)cdn\.bootcdn\.net/g
+];
+
+//主控函数
+const handle = async function (req) {
+ const urlStr = req.url
+ const domain = (urlStr.split('/'))[2]
+
+ let urls = []
+ for (let i in cdn) {
+ for (let j in cdn[i]) {
+ if (domain == cdn[i][j].url.split('https://')[1].split('/')[0] && urlStr.match(cdn[i][j].url)) {
+ urls = []
+ for (let k in cdn[i]) {
+ urls.push(urlStr.replace(cdn[i][j].url, cdn[i][k].url))
+ }
+ if (urlStr.indexOf('@latest/') > -1) {
+ return lfetch(urls, urlStr)
+ } else {
+ return caches.match(req).then(function (resp) {
+ return resp || lfetch(urls, urlStr).then(function (res) {
+ return caches.open(CACHE_NAME).then(function (cache) {
+ cache.put(req, res.clone());
+ return res;
+ });
+ });
+ })
+ }
+ }
+ }
+ }
+
+ for (var i in cache_url_list) {
+ if (is_latest(req.url)) { return fetch(req) }
+ if (req.url.match(cache_url_list[i])) {
+ return caches.match(req).then(function (resp) {
+ return resp || fetch(req).then(function (res) {
+ return caches.open(CACHE_NAME).then(function (cache) {
+ cache.put(req, res.clone());
+ return res;
+ });
+ });
+ })
+ }
+ }
+
+ return fetch(req);
+}
+
+const lfetch = async (urls, url) => {
+ let controller = new AbortController();
+ const PauseProgress = async (res) => {
+ return new Response(await (res).arrayBuffer(), { status: res.status, headers: res.headers });
+ };
+ if (!Promise.any) {
+ Promise.any = function (promises) {
+ return new Promise((resolve, reject) => {
+ promises = Array.isArray(promises) ? promises : []
+ let len = promises.length
+ let errs = []
+ if (len === 0) return reject(new AggregateError('All promises were rejected'))
+ promises.forEach((promise) => {
+ promise.then(value => {
+ resolve(value)
+ }, err => {
+ len--
+ errs.push(err)
+ if (len === 0) {
+ reject(new AggregateError(errs))
+ }
+ })
+ })
+ })
+ }
+ }
+ return Promise.any(urls.map(urls => {
+ return new Promise((resolve, reject) => {
+ fetch(urls, {
+ signal: controller.signal
+ })
+ .then(PauseProgress)
+ .then(res => {
+ if (res.status == 200) {
+ controller.abort();
+ resolve(res)
+ } else {
+ reject(res)
+ }
+ })
+ })
+ }))
+}
\ No newline at end of file
diff --git a/tags/AI/index.html b/tags/AI/index.html
new file mode 100644
index 000000000..b12569e2a
--- /dev/null
+++ b/tags/AI/index.html
@@ -0,0 +1,3 @@
+标签 - AI - 序炁的博客
+
+
\ No newline at end of file
diff --git a/tags/English/index.html b/tags/English/index.html
new file mode 100644
index 000000000..3717a64ba
--- /dev/null
+++ b/tags/English/index.html
@@ -0,0 +1,3 @@
+标签 - English - 序炁的博客
+
+
\ No newline at end of file
diff --git a/tags/GitHub-Action/index.html b/tags/GitHub-Action/index.html
new file mode 100644
index 000000000..98ea7ce44
--- /dev/null
+++ b/tags/GitHub-Action/index.html
@@ -0,0 +1,3 @@
+标签 - GitHub Action - 序炁的博客
+
+
\ No newline at end of file
diff --git a/tags/GitHub/index.html b/tags/GitHub/index.html
new file mode 100644
index 000000000..079dda1cc
--- /dev/null
+++ b/tags/GitHub/index.html
@@ -0,0 +1,3 @@
+标签 - GitHub - 序炁的博客
+
+
\ No newline at end of file
diff --git a/tags/Hexo/index.html b/tags/Hexo/index.html
new file mode 100644
index 000000000..7a9ec7d36
--- /dev/null
+++ b/tags/Hexo/index.html
@@ -0,0 +1,3 @@
+标签 - Hexo - 序炁的博客
+
+
\ No newline at end of file
diff --git a/tags/Picgo/index.html b/tags/Picgo/index.html
new file mode 100644
index 000000000..2f7053940
--- /dev/null
+++ b/tags/Picgo/index.html
@@ -0,0 +1,3 @@
+标签 - Picgo - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/U\347\233\230/index.html" "b/tags/U\347\233\230/index.html"
new file mode 100644
index 000000000..dd104b954
--- /dev/null
+++ "b/tags/U\347\233\230/index.html"
@@ -0,0 +1,3 @@
+标签 - U盘 - 序炁的博客
+
+
\ No newline at end of file
diff --git a/tags/adb/index.html b/tags/adb/index.html
new file mode 100644
index 000000000..e233c15f2
--- /dev/null
+++ b/tags/adb/index.html
@@ -0,0 +1,3 @@
+标签 - adb - 序炁的博客
+
+
\ No newline at end of file
diff --git a/tags/awtrix/index.html b/tags/awtrix/index.html
new file mode 100644
index 000000000..c49072a54
--- /dev/null
+++ b/tags/awtrix/index.html
@@ -0,0 +1,3 @@
+标签 - awtrix - 序炁的博客
+
+
\ No newline at end of file
diff --git a/tags/c/index.html b/tags/c/index.html
new file mode 100644
index 000000000..736acc08d
--- /dev/null
+++ b/tags/c/index.html
@@ -0,0 +1,3 @@
+标签 - c++ - 序炁的博客
+
+
\ No newline at end of file
diff --git a/tags/css/index.html b/tags/css/index.html
new file mode 100644
index 000000000..67e2e618e
--- /dev/null
+++ b/tags/css/index.html
@@ -0,0 +1,3 @@
+标签 - css - 序炁的博客
+
+
\ No newline at end of file
diff --git a/tags/github/index.html b/tags/github/index.html
new file mode 100644
index 000000000..fe9a97d75
--- /dev/null
+++ b/tags/github/index.html
@@ -0,0 +1,3 @@
+标签 - github - 序炁的博客
+
+
\ No newline at end of file
diff --git a/tags/html/index.html b/tags/html/index.html
new file mode 100644
index 000000000..6a6491108
--- /dev/null
+++ b/tags/html/index.html
@@ -0,0 +1,3 @@
+标签 - html - 序炁的博客
+
+
\ No newline at end of file
diff --git a/tags/index.html b/tags/index.html
new file mode 100644
index 000000000..3fa776183
--- /dev/null
+++ b/tags/index.html
@@ -0,0 +1,3 @@
+标签 - 序炁的博客
+
+
\ No newline at end of file
diff --git a/tags/javascript/index.html b/tags/javascript/index.html
new file mode 100644
index 000000000..a3c86beb0
--- /dev/null
+++ b/tags/javascript/index.html
@@ -0,0 +1,3 @@
+标签 - javascript - 序炁的博客
+
+
\ No newline at end of file
diff --git a/tags/memos/index.html b/tags/memos/index.html
new file mode 100644
index 000000000..be17900cd
--- /dev/null
+++ b/tags/memos/index.html
@@ -0,0 +1,3 @@
+标签 - memos - 序炁的博客
+
+
\ No newline at end of file
diff --git a/tags/phigros/index.html b/tags/phigros/index.html
new file mode 100644
index 000000000..e6703ed5a
--- /dev/null
+++ b/tags/phigros/index.html
@@ -0,0 +1,3 @@
+标签 - phigros - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/s3\346\241\266/index.html" "b/tags/s3\346\241\266/index.html"
new file mode 100644
index 000000000..9e8631839
--- /dev/null
+++ "b/tags/s3\346\241\266/index.html"
@@ -0,0 +1,3 @@
+标签 - s3桶 - 序炁的博客
+
+
\ No newline at end of file
diff --git a/tags/sai/index.html b/tags/sai/index.html
new file mode 100644
index 000000000..ebacfc160
--- /dev/null
+++ b/tags/sai/index.html
@@ -0,0 +1,3 @@
+标签 - sai - 序炁的博客
+
+
\ No newline at end of file
diff --git a/tags/vps/index.html b/tags/vps/index.html
new file mode 100644
index 000000000..e97075372
--- /dev/null
+++ b/tags/vps/index.html
@@ -0,0 +1,3 @@
+标签 - vps - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\344\270\252\344\272\272/index.html" "b/tags/\344\270\252\344\272\272/index.html"
new file mode 100644
index 000000000..097956048
--- /dev/null
+++ "b/tags/\344\270\252\344\272\272/index.html"
@@ -0,0 +1,3 @@
+标签 - 个人 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\344\274\230\345\214\226/index.html" "b/tags/\344\274\230\345\214\226/index.html"
new file mode 100644
index 000000000..b4d848597
--- /dev/null
+++ "b/tags/\344\274\230\345\214\226/index.html"
@@ -0,0 +1,3 @@
+标签 - 优化 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\344\275\234\346\226\207/index.html" "b/tags/\344\275\234\346\226\207/index.html"
new file mode 100644
index 000000000..be01e636b
--- /dev/null
+++ "b/tags/\344\275\234\346\226\207/index.html"
@@ -0,0 +1,3 @@
+标签 - 作文 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\345\211\215\347\253\257/index.html" "b/tags/\345\211\215\347\253\257/index.html"
new file mode 100644
index 000000000..0b340e809
--- /dev/null
+++ "b/tags/\345\211\215\347\253\257/index.html"
@@ -0,0 +1,3 @@
+标签 - 前端 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\345\214\226\345\255\246/index.html" "b/tags/\345\214\226\345\255\246/index.html"
new file mode 100644
index 000000000..4e1dcc5c1
--- /dev/null
+++ "b/tags/\345\214\226\345\255\246/index.html"
@@ -0,0 +1,3 @@
+标签 - 化学 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\345\220\210\345\224\261/index.html" "b/tags/\345\220\210\345\224\261/index.html"
new file mode 100644
index 000000000..2ef80ec1b
--- /dev/null
+++ "b/tags/\345\220\210\345\224\261/index.html"
@@ -0,0 +1,3 @@
+标签 - 合唱 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\345\221\250\350\276\271/index.html" "b/tags/\345\221\250\350\276\271/index.html"
new file mode 100644
index 000000000..05d21029f
--- /dev/null
+++ "b/tags/\345\221\250\350\276\271/index.html"
@@ -0,0 +1,3 @@
+标签 - 周边 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\345\244\215\347\216\260/index.html" "b/tags/\345\244\215\347\216\260/index.html"
new file mode 100644
index 000000000..4508da469
--- /dev/null
+++ "b/tags/\345\244\215\347\216\260/index.html"
@@ -0,0 +1,3 @@
+标签 - 复现 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\345\255\246\344\271\240/index.html" "b/tags/\345\255\246\344\271\240/index.html"
new file mode 100644
index 000000000..3cbb8ab59
--- /dev/null
+++ "b/tags/\345\255\246\344\271\240/index.html"
@@ -0,0 +1,3 @@
+标签 - 学习 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\345\255\246\347\224\237/index.html" "b/tags/\345\255\246\347\224\237/index.html"
new file mode 100644
index 000000000..a359f6cdf
--- /dev/null
+++ "b/tags/\345\255\246\347\224\237/index.html"
@@ -0,0 +1,3 @@
+标签 - 学生 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\345\256\211\345\215\223/index.html" "b/tags/\345\256\211\345\215\223/index.html"
new file mode 100644
index 000000000..4a357c13f
--- /dev/null
+++ "b/tags/\345\256\211\345\215\223/index.html"
@@ -0,0 +1,3 @@
+标签 - 安卓 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\345\274\200\346\272\220\350\275\257\344\273\266/index.html" "b/tags/\345\274\200\346\272\220\350\275\257\344\273\266/index.html"
new file mode 100644
index 000000000..03e1b15e9
--- /dev/null
+++ "b/tags/\345\274\200\346\272\220\350\275\257\344\273\266/index.html"
@@ -0,0 +1,3 @@
+标签 - 开源软件 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\345\274\200\347\256\261/index.html" "b/tags/\345\274\200\347\256\261/index.html"
new file mode 100644
index 000000000..15db91afa
--- /dev/null
+++ "b/tags/\345\274\200\347\256\261/index.html"
@@ -0,0 +1,3 @@
+标签 - 开箱 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\346\200\273\347\273\223/index.html" "b/tags/\346\200\273\347\273\223/index.html"
new file mode 100644
index 000000000..c4fa0164c
--- /dev/null
+++ "b/tags/\346\200\273\347\273\223/index.html"
@@ -0,0 +1,3 @@
+标签 - 总结 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\346\211\213\346\234\272/index.html" "b/tags/\346\211\213\346\234\272/index.html"
new file mode 100644
index 000000000..44c8e5f76
--- /dev/null
+++ "b/tags/\346\211\213\346\234\272/index.html"
@@ -0,0 +1,3 @@
+标签 - 手机 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\346\211\213\347\273\230/index.html" "b/tags/\346\211\213\347\273\230/index.html"
new file mode 100644
index 000000000..4d95acdf2
--- /dev/null
+++ "b/tags/\346\211\213\347\273\230/index.html"
@@ -0,0 +1,3 @@
+标签 - 手绘 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\346\225\231\347\250\213/index.html" "b/tags/\346\225\231\347\250\213/index.html"
new file mode 100644
index 000000000..d6da64c9a
--- /dev/null
+++ "b/tags/\346\225\231\347\250\213/index.html"
@@ -0,0 +1,3 @@
+标签 - 教程 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\346\225\260\345\255\246/index.html" "b/tags/\346\225\260\345\255\246/index.html"
new file mode 100644
index 000000000..9e3b3e83a
--- /dev/null
+++ "b/tags/\346\225\260\345\255\246/index.html"
@@ -0,0 +1,3 @@
+标签 - 数学 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\346\226\207\345\255\246/index.html" "b/tags/\346\226\207\345\255\246/index.html"
new file mode 100644
index 000000000..64fd688be
--- /dev/null
+++ "b/tags/\346\226\207\345\255\246/index.html"
@@ -0,0 +1,3 @@
+标签 - 文学 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\346\227\205\350\241\214/index.html" "b/tags/\346\227\205\350\241\214/index.html"
new file mode 100644
index 000000000..d586d22ec
--- /dev/null
+++ "b/tags/\346\227\205\350\241\214/index.html"
@@ -0,0 +1,3 @@
+标签 - 旅行 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\346\227\245\345\270\270/index.html" "b/tags/\346\227\245\345\270\270/index.html"
new file mode 100644
index 000000000..d8f5c7403
--- /dev/null
+++ "b/tags/\346\227\245\345\270\270/index.html"
@@ -0,0 +1,3 @@
+标签 - 日常 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\346\274\224\350\256\262\347\250\277/index.html" "b/tags/\346\274\224\350\256\262\347\250\277/index.html"
new file mode 100644
index 000000000..917a4d53a
--- /dev/null
+++ "b/tags/\346\274\224\350\256\262\347\250\277/index.html"
@@ -0,0 +1,3 @@
+标签 - 演讲稿 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\347\211\272\347\211\262/index.html" "b/tags/\347\211\272\347\211\262/index.html"
new file mode 100644
index 000000000..4a347e8e7
--- /dev/null
+++ "b/tags/\347\211\272\347\211\262/index.html"
@@ -0,0 +1,3 @@
+标签 - 牺牲 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\347\224\237\346\227\245/index.html" "b/tags/\347\224\237\346\227\245/index.html"
new file mode 100644
index 000000000..0e8f910a4
--- /dev/null
+++ "b/tags/\347\224\237\346\227\245/index.html"
@@ -0,0 +1,3 @@
+标签 - 生日 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\347\224\265\345\255\220\351\202\256\344\273\266/index.html" "b/tags/\347\224\265\345\255\220\351\202\256\344\273\266/index.html"
new file mode 100644
index 000000000..b9d452a98
--- /dev/null
+++ "b/tags/\347\224\265\345\255\220\351\202\256\344\273\266/index.html"
@@ -0,0 +1,3 @@
+标签 - 电子邮件 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\347\224\265\345\275\261/index.html" "b/tags/\347\224\265\345\275\261/index.html"
new file mode 100644
index 000000000..c377b0401
--- /dev/null
+++ "b/tags/\347\224\265\345\275\261/index.html"
@@ -0,0 +1,3 @@
+标签 - 电影 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\347\224\273\347\224\273/index.html" "b/tags/\347\224\273\347\224\273/index.html"
new file mode 100644
index 000000000..4f1369382
--- /dev/null
+++ "b/tags/\347\224\273\347\224\273/index.html"
@@ -0,0 +1,3 @@
+标签 - 画画 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\347\231\275\345\253\226/index.html" "b/tags/\347\231\275\345\253\226/index.html"
new file mode 100644
index 000000000..4bce367f8
--- /dev/null
+++ "b/tags/\347\231\275\345\253\226/index.html"
@@ -0,0 +1,3 @@
+标签 - 白嫖 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\347\237\255\346\226\207/index.html" "b/tags/\347\237\255\346\226\207/index.html"
new file mode 100644
index 000000000..c935798b1
--- /dev/null
+++ "b/tags/\347\237\255\346\226\207/index.html"
@@ -0,0 +1,3 @@
+标签 - 短文 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\347\241\254\344\273\266/index.html" "b/tags/\347\241\254\344\273\266/index.html"
new file mode 100644
index 000000000..656df94b2
--- /dev/null
+++ "b/tags/\347\241\254\344\273\266/index.html"
@@ -0,0 +1,3 @@
+标签 - 硬件 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\347\246\217\345\210\251/index.html" "b/tags/\347\246\217\345\210\251/index.html"
new file mode 100644
index 000000000..03e877720
--- /dev/null
+++ "b/tags/\347\246\217\345\210\251/index.html"
@@ -0,0 +1,3 @@
+标签 - 福利 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\347\247\221\346\212\200/index.html" "b/tags/\347\247\221\346\212\200/index.html"
new file mode 100644
index 000000000..6eead3235
--- /dev/null
+++ "b/tags/\347\247\221\346\212\200/index.html"
@@ -0,0 +1,3 @@
+标签 - 科技 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\347\256\227\346\263\225/index.html" "b/tags/\347\256\227\346\263\225/index.html"
new file mode 100644
index 000000000..fae7ee9c2
--- /dev/null
+++ "b/tags/\347\256\227\346\263\225/index.html"
@@ -0,0 +1,3 @@
+标签 - 算法 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\347\264\240\346\235\220/index.html" "b/tags/\347\264\240\346\235\220/index.html"
new file mode 100644
index 000000000..d4eeaeea7
--- /dev/null
+++ "b/tags/\347\264\240\346\235\220/index.html"
@@ -0,0 +1,3 @@
+标签 - 素材 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\347\272\257\350\213\261\346\226\207/index.html" "b/tags/\347\272\257\350\213\261\346\226\207/index.html"
new file mode 100644
index 000000000..5a27245b4
--- /dev/null
+++ "b/tags/\347\272\257\350\213\261\346\226\207/index.html"
@@ -0,0 +1,3 @@
+标签 - 纯英文 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\347\274\226\347\250\213/index.html" "b/tags/\347\274\226\347\250\213/index.html"
new file mode 100644
index 000000000..68b584b0e
--- /dev/null
+++ "b/tags/\347\274\226\347\250\213/index.html"
@@ -0,0 +1,3 @@
+标签 - 编程 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\347\274\226\347\250\213/page/2/index.html" "b/tags/\347\274\226\347\250\213/page/2/index.html"
new file mode 100644
index 000000000..fbfc1d99c
--- /dev/null
+++ "b/tags/\347\274\226\347\250\213/page/2/index.html"
@@ -0,0 +1,3 @@
+标签 - 编程 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\347\275\221\347\253\231/index.html" "b/tags/\347\275\221\347\253\231/index.html"
new file mode 100644
index 000000000..94e66ac54
--- /dev/null
+++ "b/tags/\347\275\221\347\253\231/index.html"
@@ -0,0 +1,3 @@
+标签 - 网站 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\350\200\203\350\257\225/index.html" "b/tags/\350\200\203\350\257\225/index.html"
new file mode 100644
index 000000000..bbce81f90
--- /dev/null
+++ "b/tags/\350\200\203\350\257\225/index.html"
@@ -0,0 +1,3 @@
+标签 - 考试 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\350\207\252\345\212\250\345\214\226/index.html" "b/tags/\350\207\252\345\212\250\345\214\226/index.html"
new file mode 100644
index 000000000..382779a57
--- /dev/null
+++ "b/tags/\350\207\252\345\212\250\345\214\226/index.html"
@@ -0,0 +1,3 @@
+标签 - 自动化 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\350\231\232\346\213\237\344\270\273\346\234\272/index.html" "b/tags/\350\231\232\346\213\237\344\270\273\346\234\272/index.html"
new file mode 100644
index 000000000..7b620c162
--- /dev/null
+++ "b/tags/\350\231\232\346\213\237\344\270\273\346\234\272/index.html"
@@ -0,0 +1,3 @@
+标签 - 虚拟主机 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\350\256\241\347\256\227\346\234\272/index.html" "b/tags/\350\256\241\347\256\227\346\234\272/index.html"
new file mode 100644
index 000000000..38c2af6d4
--- /dev/null
+++ "b/tags/\350\256\241\347\256\227\346\234\272/index.html"
@@ -0,0 +1,3 @@
+标签 - 计算机 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\350\256\241\347\256\227\346\234\272/page/2/index.html" "b/tags/\350\256\241\347\256\227\346\234\272/page/2/index.html"
new file mode 100644
index 000000000..a0af156a4
--- /dev/null
+++ "b/tags/\350\256\241\347\256\227\346\234\272/page/2/index.html"
@@ -0,0 +1,3 @@
+标签 - 计算机 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\350\256\256\350\256\272\346\226\207/index.html" "b/tags/\350\256\256\350\256\272\346\226\207/index.html"
new file mode 100644
index 000000000..27e6f59e4
--- /dev/null
+++ "b/tags/\350\256\256\350\256\272\346\226\207/index.html"
@@ -0,0 +1,3 @@
+标签 - 议论文 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\350\257\264\350\257\264/index.html" "b/tags/\350\257\264\350\257\264/index.html"
new file mode 100644
index 000000000..bbff0386e
--- /dev/null
+++ "b/tags/\350\257\264\350\257\264/index.html"
@@ -0,0 +1,3 @@
+标签 - 说说 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\350\257\273\345\220\216\346\204\237/index.html" "b/tags/\350\257\273\345\220\216\346\204\237/index.html"
new file mode 100644
index 000000000..4d98b8fdc
--- /dev/null
+++ "b/tags/\350\257\273\345\220\216\346\204\237/index.html"
@@ -0,0 +1,3 @@
+标签 - 读后感 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\350\276\251\350\256\272/index.html" "b/tags/\350\276\251\350\256\272/index.html"
new file mode 100644
index 000000000..5626ab850
--- /dev/null
+++ "b/tags/\350\276\251\350\256\272/index.html"
@@ -0,0 +1,3 @@
+标签 - 辩论 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\351\237\263\344\271\220/index.html" "b/tags/\351\237\263\344\271\220/index.html"
new file mode 100644
index 000000000..0fdc9b34f
--- /dev/null
+++ "b/tags/\351\237\263\344\271\220/index.html"
@@ -0,0 +1,3 @@
+标签 - 音乐 - 序炁的博客
+
+
\ No newline at end of file
diff --git "a/tags/\351\270\277\350\222\231/index.html" "b/tags/\351\270\277\350\222\231/index.html"
new file mode 100644
index 000000000..765655e7b
--- /dev/null
+++ "b/tags/\351\270\277\350\222\231/index.html"
@@ -0,0 +1,3 @@
+标签 - 鸿蒙 - 序炁的博客
+
+
\ No newline at end of file
diff --git a/talk/index.html b/talk/index.html
new file mode 100644
index 000000000..432555008
--- /dev/null
+++ b/talk/index.html
@@ -0,0 +1,3 @@
+说说 - 序炁的博客
+
+
\ No newline at end of file
diff --git a/xml/local-search.xml b/xml/local-search.xml
new file mode 100644
index 000000000..d7d0c01cf
--- /dev/null
+++ b/xml/local-search.xml
@@ -0,0 +1,45 @@
+
+
+ {% if posts %}
+ {% for post in posts.toArray() %}
+ {% if post.indexing == undefined or post.indexing %}
+
+ {{ post.title }}
+
+ {{ [url, post.path] | urlJoin | uriencode }}
+ {% if content %}
+
+ {% endif %}
+ {% if post.categories and post.categories.length>0 %}
+
+ {% for cate in post.categories.toArray() %}
+ {{ cate.name }}
+ {% endfor %}
+
+ {% endif %}
+ {% if post.tags and post.tags.length>0 %}
+
+ {% for tag in post.tags.toArray() %}
+ {{ tag.name }}
+ {% endfor %}
+
+ {% endif %}
+
+ {% endif %}
+ {% endfor %}
+ {% endif %}
+ {% if pages %}
+ {% for page in pages.toArray() %}
+ {% if post.indexing == undefined or post.indexing %}
+
+ {{ page.title }}
+
+ {{ [url, post.path] | urlJoin | uriencode }}
+ {% if content %}
+
+ {% endif %}
+
+ {% endif %}
+ {% endfor %}
+ {% endif %}
+


















































































 "};x.incLocalStorageShares=function(t,e){var n,i,o,r,s,a,l,c,d;n=x.storage.get("st_shares_"+e);if(n){i=((o=n[t])!=null?o.value:void 0)+1||0;d=((r=n["total"])!=null?r.value:void 0)+1||0;if((s=n[t])!=null){s.value=i}if((a=n[t])!=null){a.label=x.formatNumber(i)}if((l=n["total"])!=null){l.value=d}if((c=n["total"])!=null){c.label=x.formatNumber(d)}n["update_time"]=Math.round(new Date/1e3);return x.storage.set("st_shares_"+e,n)}};x.inc=function(t){var e;e=x.parseNumber(t.innerText);t.innerText=x.formatNumber(e+1);x.addClass(t,"st-grow");return setTimeout(function(){return x.removeClass(t,"st-grow")},400)};x.isEnter=function(t){return t.which===13||t.keyCode===13};x.isEsc=function(t){var e;return(e=t.key)==="Escape"||e==="Esc"||t.keyCode===27};x.isValidEmail=function(t){var e;e=/[^\.\s@][^\s@]*(?!\.)@[^\.\s@]+(?:\.[^\.\s@]+)*/;return e.test(t)};x.js=function(t,e){var n,i;n=document.createElement("script");n.async=1;n.src=t;if(e){n.id=e}i=document.getElementsByTagName("script")[0];return i.parentNode.insertBefore(n,i)};x.ldjson=function(){var t,e,n,i,o;t=document.querySelector('script[type="application/ld+json"]');if(t){try{o=JSON.parse(t.innerText);if(!Array.isArray(o)){o=[o]}for(e=0,i=o.length;e
"};x.incLocalStorageShares=function(t,e){var n,i,o,r,s,a,l,c,d;n=x.storage.get("st_shares_"+e);if(n){i=((o=n[t])!=null?o.value:void 0)+1||0;d=((r=n["total"])!=null?r.value:void 0)+1||0;if((s=n[t])!=null){s.value=i}if((a=n[t])!=null){a.label=x.formatNumber(i)}if((l=n["total"])!=null){l.value=d}if((c=n["total"])!=null){c.label=x.formatNumber(d)}n["update_time"]=Math.round(new Date/1e3);return x.storage.set("st_shares_"+e,n)}};x.inc=function(t){var e;e=x.parseNumber(t.innerText);t.innerText=x.formatNumber(e+1);x.addClass(t,"st-grow");return setTimeout(function(){return x.removeClass(t,"st-grow")},400)};x.isEnter=function(t){return t.which===13||t.keyCode===13};x.isEsc=function(t){var e;return(e=t.key)==="Escape"||e==="Esc"||t.keyCode===27};x.isValidEmail=function(t){var e;e=/[^\.\s@][^\s@]*(?!\.)@[^\.\s@]+(?:\.[^\.\s@]+)*/;return e.test(t)};x.js=function(t,e){var n,i;n=document.createElement("script");n.async=1;n.src=t;if(e){n.id=e}i=document.getElementsByTagName("script")[0];return i.parentNode.insertBefore(n,i)};x.ldjson=function(){var t,e,n,i,o;t=document.querySelector('script[type="application/ld+json"]');if(t){try{o=JSON.parse(t.innerText);if(!Array.isArray(o)){o=[o]}for(e=0,i=o.length;e













