Releases: MASD-Project/dogen
Dogen v1.0.22, "Cine Teatro Namibe"
Cine Teatro Namibe, Moçamedes, Angola. (C) 2015 MESSYNESSY.

Introduction
Welcome to yet another busy Dogen sprint! Originally, we had intended to focus on the fabled "generation refactor" but, alas, it was not to be (yet again). Our preparatory analysis revealed some fundamental deficiencies on the variability implementation and, before you knew it, we were stuck wading in the guts of the variability subsystem for the entirety of the sprint. On the plus side, the end product was a much better designed subsystem, free of unwanted dependencies, and a newly found clarity in the conceptual model with regards to both logical and physical dimensions. On the down side, the refactor produced a lot of churn with regards to stereotypes and feature names, resulting on a fair bit of breakage to user diagrams. In other words, it was quite the eventful sprint. Let's see how we fared in more detail.
User visible changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. There have been a number of breaking changes, which have been highlighted with the symbol
Video 1: Sprint 22 Demo.

Split templatised from non-templatised variability meta-model elements
A pet peeve of ours, pretty much since profiles were introduced to the meta-model many moons ago, was the name chosen for the stereotype: masd::variability::profile_template. The postfix _template was a glaring leak from the implementation; a result of trying to be "too clever by half" in generalising all profiles to be "profile templates", when, in reality, there were only 2 or 3 cases of actual profile template instantiation across the code base. As it was, with this story we finally tackled this annoyance. However, before we proceed, a word is probably needed on what is meant by "templates" and "instantiation" in this context. The explanation will also prove helpful in understanding much of the remaining work carried out in the release.
Setting the Scene: Quick Primer on Variability Templates
As with many other modeling approaches, MASD divides the modeling of software products into two distinct dimensions: the logical dimension and the physical dimension. The logical dimension is pretty much what you are used to when creating UML class diagrams: the structural world of classes and their relationships (though, of course, in MASD there is a twist to it, but we need to leave that for another time). The physical dimension is, predictably, the world of files and directories. So far, so similar to UML and the like. What MASD does differently, however, is to impose a well-defined shape into the entities that live in the physical dimension, as well as a process by which these instances are derived. That shape is governed by the physical model's meta-model, which has existed since the early days of Dogen, albeit in an implicit manner. It is composed of vocabulary such as kernel (e.g., "masd"), backend (e.g., C++, C#), facet (e.g., "types", "hash", "serialisation" and so forth) and archetype (e.g., "class header", "class implementation", etc.).

Figure 1: Examples of Dogen feature bundles prior to the refactor.
The shape of the physical dimension is a function of the implementation; that is, as we add formatters (model-to-text transforms) to generate new kinds of output, these inject archetypes and facets and so on, augmenting the physical dimension. It became clear early on that adding features needed by all formatters manually was too painful. For example, we need to know if a kernel, backend, facet or archetype is enabled or disabled by the users. Thus a feature called enabled must exist for every element of the physical meta-model. We started by doing this manually, but it soon became obvious that what we were after was a generic way of saying that a feature with a given name n applies to every registered x - with x being an element of a set X, composed of kernels, backends, facets or archetypes. And so it was that variability templates were born. These were subsequently modeled within the logical model as both "feature bundles" (i.e., providing feature definitions, as per Figure 1) and "profile templates" (i.e., groups of configurations created by users for reuse purposes, performing feature selection; see Figure 2). In both cases we had the notion of an "instance template":
#DOGEN masd.variability.template_kind=instance
This was a "pseudo" or "identity" template, which does not really get instantiated but is instead copied across. We also had "real templates", associated with one of the "levels" in physical space (e.g., all, backend, facet, archetype):
#DOGEN masd.variability.template_kind=archetype
An additional modeling error was that, whilst profile templates only allowed a template kind at the profile level (that is, all attributes in the profile are of the same template_kind), we did not take the same approach for feature bundles, opening the gates for all sorts of weird and wonderful permutations: one attribute could be a template of kind instance whereas another could be a template of kind archetype. In practice, we were disciplined enough to avoid any such crazy stunts but, as old saying goes, "a good domain model should make invalid states unrepresentable".

Figure 2: Dogen's Profiles model before the refactor.
One final word on the dependency between the variability model and the physical model. Though its clear that there is a connection between the two models - at the end of the day, templates can only be initialised when we know the lay of the physical land - it is not necessarily the case that the coupling needs to be made in terms of "direct dependencies" (i.e. using a type from the physical model), because it comes at a cost: the graph of dependencies is made more complex because variability is used by many models, and these are then coupled to the physical model by way of this small connection. In truth, these models were joined more due to expediency than thought, for, as we mentioned, most features do not actually need template instantiation. Therefore, our core objective was to decouple the physical model from the variability model.
The tidy-up
One of the side-effects of the decoupling was to make us focus on creating a clear separation between the templatised and non-templatised elements of the logical model modeling variability. This was mainly to avoid increasing the end users cognitive load for no good reason ("why is this a 'template'? what's an 'instance template'?", etc.). As a result, the stereotypes are now as follows:
⚠️ Breaking change: the names and meaning of these stereotypes have changed. User diagrams must be updated.
| Stereotype | Description |
|---|---|
masd::variability::profile_template |
Meta-model element defining a profile template. The template is instantiated over a domain, as we shall explain in the next section. |
masd::variability::profile |
Meta-model element defining a non-templatised profile. This is equivalent to the deprecated template kind of instance. |
masd::variability::feature_template_bundle |
Meta-model element defining a feature bundle template. As with profile templates, the template is instantiated over a domain. Note that all features belong to the same domain and all are templates, cleaning up the previous modeling mistake. |
masd::variability::feature_bundle |
Meta-model element defining a non-templatised feature bundle. This is equivalent to the deprecated template kind of instance. |
masd::variability::initializer |
Replaces the previous masd::variability::feature_template_initializer, providing initialisation for both feature templates and features. |
Table 1: Stereotypes related to feature bundles and profiles.
While we were at it, we took the opportunity to update the colour theme, making the distinction between these elements more obvious:

Figure 3: Colour theme for all variability meta-model elements.
In addition to the stereotype changes, we also modified the approach to template instantiation, as explained on the next story.
Introduce "Domains" for Template Instantiation
The concept of domains was introduced as a way to achieve the before mentioned decoupling of the variability model from the physical model. Domains are simple sets of strings that can be used as the basis for template instantiation. When users declare templates (e.g., profile templates or feature bundle templates), they must now also provide the domain under which instantiation will take place:
#DOGEN masd.variability.instantiation_domain_name=masd
This is, of course, a breaking change:
⚠️ Breaking change:masd.variability.template_kindis no longer supported and must be replaced withmasd.variability.instantiation_domain_name. This feature can only be used at the top level withmasd::variability::profile_templateandmasd::variability::feature_template_bundle....
Dogen v1.0.21, "Nossa Senhora do Rosário"
Igreja de Nossa Senhora do Rosário, Tombwa, Namibe, Angola. (C) 2010 Paulo César Santos.

Introduction
Very much like an iceberg, this sprint was deceptively small on user features but big on internal changes: after several sprints of desperate chasing, we finally completed the mythical "fabric refactor". The coding work was not exactly glamorous, as we engaged on a frontal attack on all "quasi-meta-types" we had previously scattered across the codebase. One by one, each type was polished and moved into the assets meta-model, to be reborn anew as a fully-fledged modeling element. All the while, we tried to avoid breaking the world - but nevertheless did so, frequently. It was grueling work. Having said that, the end of the refactor made for a very exciting sprint, and though the war remains long, we can't help but feel an important battle was won.
So let's have a look at how it all went down.
User visible changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. All features this sprint are related to the addition of new meta-model types, which resulted in a number of breaking changes. These we have highlighted with
Video 1: Sprint 21 Demo.

New meta-model elements
As we explored the lay of the land of our problem domain, we inadvertently found ourselves allowing Dogen to evolve a "special" set of meta-types. These we used to model files deemed inferior in stature to real source code: mostly build-related material, but also some more "regular" source code which could be derived from existing elements - e.g. visitors, serialisation registrars and the like. Due to its second-class-citizen nature, these "special types" were controlled via variability in haphazard ways. Over the years, a plethora of meta-data switches was introduced at the model level but, in the absence of a coherent overall plan, these were ad-hoc and inconsistent. On the main, the switches were used to enable or disable the emission of these "special types", as well as to configure some of their properties. Table 1 provides a listing of these switches.
| Meta-data key | Description |
|---|---|
masd.generation.cpp.cmake.enabled |
Enable the CMake facet. |
masd.generation.cpp.cmake.postfix |
Postfix to use for filename. |
masd.generation.cpp.cmake.source_cmakelists.enabled |
Enable the CMakeLists file in src directory. |
masd.generation.cpp.cmake.source_cmakelists.postfix |
Postfix to use for filename. |
masd.generation.cpp.cmake.include_cmakelists.enabled |
Enable the CMakeLists file in include directory. |
masd.generation.cpp.cmake.include_cmakelists.postfix |
Postfix to use for filename. |
masd.generation.cpp.msbuild.enabled |
Enable the MSBuild facet. |
masd.generation.cpp.msbuild.targets.enabled |
Enable the MSBuild formatter for ODB targets. |
masd.generation.cpp.msbuild.targets.postfix |
Postfix to use for filename. |
masd.generation.cpp.visual_studio.enabled |
Enable the Visual Studio facet. |
masd.generation.cpp.visual_studio.postfix |
Postfix to use for filename. |
masd.generation.cpp.visual_studio.project_solution_guid |
GUID for the Visual studio solution. |
masd.generation.cpp.visual_studio.project_guid |
GUID for the Visual studio project. |
masd.generation.cpp.visual_studio.solution.enabled |
Enables a Visual Studio solution for C++. |
masd.generation.cpp.visual_studio.solution.postfix |
Postfix to use for filename. |
masd.generation.cpp.visual_studio.project.enabled |
Enables a Visual Studio solution for C++. |
masd.generation.cpp.visual_studio.project.postfix |
Postfix to use for filename. |
masd.generation.csharp.visual_studio.project_solution_guid |
GUID for the Visual studio solution. |
masd.generation.csharp.visual_studio.project_guid |
GUID for the Visual studio project. |
masd.generation.csharp.visual_studio.solution.enabled |
Enables a Visual Studio solution for C#. |
masd.generation.csharp.visual_studio.solution.postfix |
Postfix to use for filename. |
masd.generation.csharp.visual_studio.project.enabled |
Enables a Visual Studio project for C#. |
masd.generation.csharp.visual_studio.project.postfix |
Postfix to use for filename. |
Table 1: Meta-data switches related to "special" types.
The meta-data was then latched on to model properties, like so:
#DOGEN masd.generation.cpp.msbuild.enabled=true
#DOGEN masd.generation.csharp.visual_studio.project_guid=9E645ACD-C04A-4734-AB23-C3FCC0F7981B
#DOGEN masd.generation.csharp.visual_studio.project_solution_guid=FAE04EC0-301F-11D3-BF4B-00C04F79EFBC
#DOGEN masd.generation.cpp.cmake.enabled=true
...
As we continued to mull over the problem across sprints, the entire idea of "implicit" element types - injected into the model and treated differently from regular elements - was ultimately understood to be harmful. The approach is in fact an abuse of variability, due to how these elements had been (mis-)modeled. And it had consequences:
- Invisibility: it was not possible to manage variability of the injected types in the same fashion as for all other elements because they were "invisible" to the modeler.
- Difficulty in troubleshooting: it was hard to diagnose when something didn't work as expected, because all of the magic was internal to the code generator.
- Inconsistency in generation: we had a rather inconsistent way of handling different element types; some "just appeared" due to the state of the model (like
registrar); others were a consequence of enabling formatters (e.g.CMakeLists.txt); still others required the presence of stereotypes (e.g.visitor). It was very hard to explain the rationale for each of these to an unsuspecting user. - Inconsistency in population: properties that were common to other elements had to be handled specially via meta-data. For example, adding comments or changing decoration for these elements required bespoke meta-data and associated transforms, even though we already had a pipeline which operated on "regular" elements.
- Inconsistencies in facet spaces: the types did not follow the existing facet conventions - i.e., to be placed on a folder named after the facet, etc. Even in that they were "special".
Programming is nothing if not a quest for the generalisation and removal of special cases, and these types had been a major thorn in the design. Thus the idea of refactoring fabric out of existence was born. With this release we finally removed all of the above meta-data keys, and replaced them with regular meta-model elements, instantiable via the appropriate stereotypes (Table 2). Sadly, a single use case was left, due to the specificity of its implementation: visitors. These shall be addressed on a future release.
⚠️ Breaking change: Users need to update any models which make use of the meta-data in Table 1 and replace them with the corresponding elements and stereotypes.
| Stereotype | Description |
|---|---|
masd::serialization::type_registrar |
The serialisation type registrar used mainly for boost serialisation support. |
masd::visual_studio::solution |
Visual Studio solution support. |
masd::visual_studio::project |
Visual Studio solution support. |
masd::entry_point |
Provides an entry point to a component, e.g. main. |
masd::orm::common_odb_options |
Element modeling the common arguments for ODB. |
masd::visual_studio::msbuild_targets |
Element modeling ODB targets using MSBuild. |
masd::build::cmakelists |
Element modeling build files using CMake. |
masd::assistant |
C# helper type. |
Table 2: Stereotypes for the new meta-model elements .
Now, the observant reader won't fail to notice that the generated code has not changed in any way - well, at least not intentionally. All of these new meta-model elements already existed, but in their previous incarnation variability was used to trigger them (mostly). With this release they are modeled as proper meta-model elements, controlled by the user, and processed in the exact same way as all other elements. This means we can make use of all of the existing machinery in Dogen such as profiles.

Figure 1: Use of new meta-elements in a C++ model.
Whilst this is a big improvement in usability, there are still a number of pitfalls:
- users now need to remember to add types where Dogen used to inject them automatically. This is the case with
registrar, which was generated automatically when a model made use of inheritance. - there are no errors or warnings when a diagram is on an inconsistent state due to the choice of elements used. For example, one can add a solution without a project.

Figure 2: Use of new meta-elements in a C# model.
These are problems that will hopefully be looked into once we eventually reach the validation work, in a few sprints time.
Development Matters
In this se...
Dogen v1.0.20, "Oasis do Arco"
Arco Oasis, Namibe, Moçamedes, Angola. (C) 2011 Paulo César Santos

Introduction
New year, new Dogen sprint! At around two months of elapsed time for 83 hours worth of commitment, this was yet another long, drawn-out affair, and the festive period most certainly did not help matters. Having said that, the sprint was reasonably focused on the mission at hand: making the relational model just about usable. In doing so, it provided its fair share of highs and lows, and taught a great deal of lessons - more than we ever wished for. Ah, the joys, the joys. But, onwards we march!
User visible changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. There were only a few small features this sprint, and there are no breaking changes.
Video 1: Sprint 20 Demo.

Add ODB type overrides to primitives
ORM type overrides had not been used in anger until the relational model was introduced (see below), and, as a result, we did not notice any problems with its implementation. Because the relational model makes heavy use of JSONB, we quickly spotted an issue when declaring type overrides inline with the column (i.e., at the attribute level):
#DOGEN masd.orm.type_override=postgresql,JSONB
According to the ODB manual, this incantation is not sufficient to cope with conversion functions and other more complex uses. And so, with this sprint, type mapping was updated to take advantage of ODB's flexibility. You can now define type mappings at the element level:
#DOGEN masd.orm.type_override=postgresql,JSONB
#DOGEN masd.orm.type_mapping=postgresql,JSONB,TEXT,to_jsonb((?)::jsonb),from_jsonb((?))
#DOGEN masd.orm.type_mapping=sqlite,JSON_TEXT,TEXT,json((?))
You can then make use of it at attribute level, as previously. An even better scenario is to define a masd::primitive for the type, which takes care of it for you, and generates code like so:
#pragma db member(json::value_) column("") pgsql:type("JSONB")
For example uses of JSONB, please look at the discussion on the relational model in section Significant Internal Stories below.
Allow outputting the model's SHA1 hash in decoration
The decoration marker has been expanded to allow recording the SHA1 hash of the target model. This is intended as a simple way to keep track of which model was used to generate the source code. In order to switch it on, simply add add_origin_sha1_hash to the generation marker:

Figure 1: Sample decoration marker, obtained from the C++ Reference Model.
The generated code will then contain the SHA1 hash:
/* -*- mode: c++; tab-width: 4; indent-tabs-mode: nil; c-basic-offset: 4 -*-
*
* This is a code-generated file.
*
* Model SHA1 hash: be42bdb7f246ad4040f17dbcc953222492e1a3bf
* WARNING: do not edit this file manually.
* Generated by MASD Dogen v1.0.20Sadly the SHA1 hash does not match the git hash; however, one can easily use sha1sum to compute the hash manually:
$ sha1sum cpp_ref_impl.lam_model.dia
be42bdb7f246ad4040f17dbcc953222492e1a3bf cpp_ref_impl.lam_model.dia
Before we move on, there are a couple of points worthy of note with regards to this feature. First and foremost, please heed the following warning:
⚠️ : Important: Remember that SHA1 hashes in Dogen are NOT a security measure; they exist only for informational purposes.
Secondly, as we mentioned in the past, features such as these (e.g. date/time, Dogen version, SHA1 hash, etc.) should be used with caution since they may cause unnecessary changes to generated code and thus trigger expensive rebuilds. As such, we recommend that careful consideration is given before enabling it.
Improvements in generation timestamps
For the longest time, Dogen has allowed users to stamp each file it generates with a generation timestamp. This is enabled via the parameter add_date_time, which is part of the generation marker meta-element; for an example of this meta-element see the screenshot above, where it is disabled.
When enabled, a typical output looks like so:
/* -*- mode: c++; tab-width: 4; indent-tabs-mode: nil; c-basic-offset: 4 -*-
*
* This is a code-generated file.
*
* Generation timestamp: 2020-01-22T08:29:41
* WARNING: do not edit this file manually.
* Generated by MASD Dogen v1.0.21
*In this sprint we did some minor improvements around the sourcing of this timestamp. Previously, we obtained it individually for each and every generated file, resulting in a (possibly) moving timestamp across a model generation. With this release, the timestamp for a given activity - e.g. conversion, generation, etc. - is now obtained once upfront and reused by all those who require it. Not only is this approach more performant but it yields a better outcome because users are not particularly interested in the precise second any given file was generated, but care more about knowing when a given model was generated.
In addition, we decided to allow users to control this timestamp externally. The main rationale for this was unit testing, where having a moving timestamp with each test run was just asking for trouble. While we were at it, we also deemed sensible to allow users to override this timestamp, if, for whatever reason, they need to. Now, lest you start to think we are enabling "tampering", we repeat the previous warning:
⚠️ Important: Remember that generation timestamps in Dogen are NOT a security measure; they exist only for informational purposes.
With that disclaimer firmly in hand, lets see how one can override the generation timestamp. A new command line argument was introduced:
Processing:
<SNIP>
--activity-timestamp arg Override the NOW value used for the activity
timestamp. Format: %Y-%m-%dT%H:%M:%S
For instance, to change the generation timestamp of the example above, one could set it to --activity-timestamp 2020-02-01T01:01:01, obtaining the following output:
/* -*- mode: c++; tab-width: 4; indent-tabs-mode: nil; c-basic-offset: 4 -*-
*
* This is a code-generated file.
*
* Generation timestamp: 2020-02-01T01:01:01
* WARNING: do not edit this file manually.
* Generated by MASD Dogen v1.0.21Clearly, this is more of a troubleshooting feature than anything else, but it may prove to be useful.
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Milestones
The 9999th commit was made to Dogen this sprint.

Figure 2: GitHub repo at the 9999th commit.
Significant Internal Stories
The sprint was mostly dominated by one internal story, which this section describes in detail.
Add relational tracing support
This sprint brought to a close work on the relational model. It was the culmination of a multi-sprint effort that required some significant changes to the core of Dogen - particularly to the tracing subsystem, as well as to ORM. The hard-core Dogen fan may be interested in a series of videos which captured the design and development of this feature:
Video 2: Playlist "MASD - Dogen Coding: Relational Model for Tracing".

The (rather long) series of videos reached its "climax" on sprint 21, but (spoiler alert) its "TL; DR" is that it is now possible to dump all information produced by a Dogen run into a relational database. This includes both tracing data as well as all logging, at the user-chosen log level. It is important to note that a full run in this manner is slow: dumping all of Dogen's models (18, at the present count) can take the best part of an hour. Interestingly, the majority of the cost comes from dumping the log at debug level. A dump with just tracing information takes less than 10 minutes, making it reasonably useful. Regardless of the wait, once the data is in the database, the full power of SQL and Postgres can be harnessed.
Implementation-wise, we decided to take path of least resistance and create a small number of tables, code-generated by Dogen and ODB:
musseque=> \dt
List of relations
Schema | Name | Type | Owner
--------+-----------------+-------+-------
DOGEN | LOG_EVENT | table | build
DOGEN | RUN_EV...
Dogen v1.0.19, "Impala Cine"

The open air cinema Impala Cine, in the city of Moçâmedes, Namibe, Angola. (C) 2019 Jornal O Record
Introduction
Whilst a long time in coming due to our return to gainful employment, Sprint 19 still managed to pack a punch both in terms of commitment as well as in exciting new features. To be fair, we didn't really plan to add any of these features beforehand - instead, we found ourselves having to do so in order to progress the real work we should have been focusing on. Alas, nothing ever changes in the life and times of a software developer.
But lets not dilly-dally! Without further ado, here's the review of yet another roller-coaster of a Dogen sprint.
User visible changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. Note that breaking changes are annotated with
Video 1: Click on the thumbnail to view the sprint's demo

Add support for variability overrides in Dogen
The sprint's key feature is variability overrides. It was specifically designed to allow for the overriding of model profiles. In order to understand how the feature came about, we need to revisit a fair bit of Dogen history. As you may recall, since early on, Dogen has enabled users to supply meta-data to determine what source code gets generated for each modeling element. By toggling different meta-data switches, we can express quite differently two otherwise identical model elements: say, one can generate hashing support whereas the other can generate serialisation.
Observing its usage, we soon realised that the toggle switches added more value when organised into "configuration sets" that modeling elements could bind against, and this idea eventually morphed into the present concept of profiles. Profiles are named configurations which provide a defaulting mechanism for individual configurations, so that they could be reused across modeling elements and, eventually, across models. That is to say, profiles stem from the very simple observation that the meta-data used for configuration is, in many cases, common to several models and therefore should be shared. In the MDE and SPLE domains, these ideas have been generalised into the field of Variability Modeling, because, taken as a whole, they give you a dimension in which you can "vary" how any given modeling element is expressed; hence why they are also known in Dogen as "variability modeling", as we intend to be as close as possible to domain terminology.
Figure 1: Snippet from dogen.profiles.dia model.
Of course, like all variability information carried in Dogen models, profiles are themselves associated to models via nothing but plain old meta-data - that is, its just configuration too . A typical Dogen model contains an entry like so:
#DOGEN masd.variability.profile=dogen.profiles.base.default_profile
The masd.variability.profile tells Dogen to reuse the configuration defined by the profile called default_profile - an entitty in the referenced model dogen.profiles (c.f. Figure 1).
This approach has served us well thus far, but it carried an implicit assumption: that models are associated with only one profile. As always, reality turned out to be far messier than our simplistic views. After some thinking, we realised that we have not one but two distinct and conflicting requirements for the generation of Dogen's own models:
- parsimony: from a production perspective, we want to generate the smallest amount of code required so that we avoid bloating our binaries with unnecessary kruft. Thus we want our profiles to be lean and mean and our builds to be fast.
- coverage: from a development and Q&A perspective, we want to test all possible facets with realistic use cases so that we can validate empirically the quality of the generated code. Dogen's own models are a great sample point for this validation, and should therefore make use of as many facets as possible. In this scenario, we don't mind slow builds and big binaries if it means a higher probability of detecting incorrect code.
This dilemma was not entirely obvious at the start because we could afford to generate all facets for all models and just ignore the bloat. However, as the number of facets increased and as the number of elements in each model grew, we eventually started to ran out of build time to compile all of the generated code. If, at this juncture, you are getting a strange sense of déjà vu, you are not alone. Indeed, we had experienced this very issue in the past, leading us to separate the reference models for C# and C++ from the core Dogen product in Sprint 8. But this time round the trouble is with Dogen itself, and there is nothing left to offload because there are no other obvious product boundaries like before. Interestingly, I do not blame the "short" build times offered by the free CI systems; instead, I see it as a feature, not a bug, because the limited build time has forced us to consider very carefully the impact of growth in our code base.
At any rate, as in the past with the reference models, we limped along yet again for a number of sprints, and resorted to "clever" hacks to allow these two conflicting requirements to coexist for as long as possible, such as enabling only a few facets in certain models. However, we kept increasing the generated code a lot, first with the addition of generated tests (Sprint 13) and this sprint with the relational model. The CI just took too many hits and there were no quick hacks that could fix it. As a result, CI become less and less useful because you started to increasingly ignore build statuses. Not being able to trust your CI is a showstopper, of course, so this sprint we finally sat down to solve this problem in a somewhat general manner. We decided to have two separate builds, one for each use case: nightlies for the coverage, since it runs overnight and no one is waiting for them, and CI for the regular production case. And as you probably guessed by now, we needed a way to have a comprehensive profile for nightlies that generates everything but the kitchen sink whereas for regular CI we wanted to create the aforementioned lean and mean profiles. Variability overrides was the chosen solution. From a technical standpoint, we found this approach very satisfying because it makes variability itself variable - something any geek would appreciate.
The implementation is as follows. A new command line option was added to the Processing section, named --variability-override:
Processing:
<snip>
--variability-override arg CSV string with a variability override. Must
have the form of [MODEL_NAME,][ELEMENT_NAME,][ATT
RIBUTE_NAME,]KEY,VALUE
The first three optional elements are used to bind to the target of the override (e.g., [MODEL_ID,][ELEMENT_ID,][ATTRIBUTE_ID,]). The binding logic is somewhat contrived:
- if no model is supplied, the override applies to any model, else it applies to the requested model;
- if no element is supplied, the override is applicable only to the model itself;
- if an element is supplied, the binding applies to that specific element;
- an attribute can only be supplied if an element is supplied. The binding will only activate if it finds a matching element and a matching attribute.
To be honest, given our use case, we only really needed the first type of binding; but since we didn't want to hard-code the functionality, we came up with the simplest possible generalisation we can think of and implemented it. There are no use cases for overrides outside of profiles, so this implementation is as good as any; as soon as we have use cases, the rules can be refined.
Dogen uses this new command line option like so:
if (WITH_FULL_GENERATION)
set(profile "dogen.profiles.base.test_all_facets")
set(DOGEN_PROCESSING_OPTIONS ${DOGEN_PROCESSING_OPTIONS}
--variability-override masd.variability.profile,${profile})
endif()
By supplying WITH_FULL_GENERATION to the nightlies' CMake, we then generate all facets and tests for all facets. We then build and run all of the generated code, including generated tests. Surprisingly, we did not have many issues with most generated code - with a few exceptions, which we had to ignore for now. There are also two failures which require investigation and shall be looked into next sprint. Once the change went in, the CI build times decreased dramatically and are now consistently always below the time out threshold.

Figure 2: Continuous and nightly builds in CDash after the change.
One last mention goes to code coverage. We hummed and harred a lot about the right approach for code c...
Dogen v1.0.18, "Estação dos Comboios"

The new CFM (Caminhos de Ferro de Moçamedes, or Moçamedes Railway) train station, next to the old. Moçamedes, Namibe, Angola. (C) 2018 Armando Chicoa (VOA).
Introduction
At about three quarters of the planned commitment, this sprint was slightly shorter than usual. Nonetheless, it is still packed with intense work and exciting progress: the "meta-model all things" theme continues in full flow, and we just about reached the next great refactoring battlefront - the fabric namespaces in the C# and C++ generation models. Predictably, there are not many user facing stories, as the refactoring continues to gather steam towards the ultimate V2 goal.
User visible changes
This section normally covers stories that affect end users, with the video providing a quick demonstration of the new features. As this sprint had only a very peripheral user visible change (discussed below), we took the opportunity to demo a couple of existing features instead.

Data directory clean up
For the last few sprints we have been chasing an elusive target: the removal of the assortment of non-model JSON files that have long lived in our data directory. If nothing else, anything with a name like "data" triggers immediately the "code smells" part of any developer's brain. With this sprint, we have finally achieved this milestone: the text templates that we use in the C++ and C# models have now been moved into the models themselves, with the addition of the text templates meta-modeling elements.
The change gave us the opportunity to rethink the approach from first principles. As a result, the data directory is no longer, and instead we now have only the library directory under the Dogen shared folder. It too will one day cease to exist, when we implement proper support for the PDMs (Platform Description Models) - but for the next three or four sprints it will continue to house the simplified version of the PDMs as they are currently implemented.
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Significant Internal Stories
There were four very significant stories this sprint, which we cover briefly below.
Use generated static configurations in transforms
First and foremost, consuming the majority of the sprint's resourcing, was the move towards using code generated static configurations. We started this work when we moved feature templates into the meta-model; it seemed only logical to start code-generating the C++ types to represent the dynamic configurations, as well as the "deserialisation" code that converted dynamic configurations to static configurations.
With this release we removed the majority of the hand-crafted uses of static configurations, making the code more readable. As an added bonus, It also means it's much easier to add new features to the code generator now: simply create a new instance of a masd::variability::feature_bundle modeling element, and add the required feature templates. While we were at it, we also cleaned up the way bundles were modeled, meaning we now have less boilerplate to add features and bundles are now more logically consistent.
As an example of how feature bundles are used, here's how we declare the generalisation feature bundle:
{
"name": "features::generalization",
"documentation": "Features related to the generalization relationship.\n",
"stereotypes": [
"masd::variability::feature_bundle"
],
"tagged_values": {
"masd.variability.default_binding_point": "element",
"masd.variability.archetype_location.kernel": "masd",
"masd.variability.template_kind": "instance"
},
"attributes": [
{
"name": "masd.generalization.is_final",
"type": "masd::variability::boolean",
"documentation": "Whether to mark a type as final or not.\n",
"tagged_values": {
"masd.variability.qualified_name": "masd.generalization.is_final",
"masd.variability.is_optional": "true"
}
},
{
"name": "masd.generalization.parent",
"type": "masd::variability::text",
"documentation": "Name of the parent of the current element.\n",
"tagged_values": {
"masd.variability.qualified_name": "masd.generalization.parent",
"masd.variability.is_optional": "true"
}
}
]
},
Users then make use of these features in their diagrams:
#DOGEN masd.generalization.is_final=true
#DOGEN masd.generalization.parent=some_package::some_type
We've already noticed how much quicker the development of new features has been since this new functionality has been added, so this is a great win.
Make wale templates meta-model elements
As explained above, we have been chasing the "meta-modelisation" of all configuration files that lived in the data directory for a long time. Wale text templates were one of the most annoying cases, because they really did not belong in the data directory; after all, text templates are internal to the model that uses them, rather than visible to all users of the code generator.
With this release, we've finished adding support for a logic-less text template meta-modeling element, which represents the text template. We then moved the templates into their respective models, under the new templates directory. The name logic-less was chosen to be close to the domain terminology but it perhaps yet another example of "domain overfitting": it seems it's more a source of confusion rather than enlightenment, as many users (and even domain experts!) are not familiar with the term. We will probably rename it to just "text templates".

Interestingly, in theory, this change should have made possible for users to create their own text templates. However, in practice, it is of extremely limited value because:
- we do not yet have a stable API for the meta-modeling elements;
- nor do we expose these properly to the templates;
- nor do we have a proper logic-less templating engine such as one of the mustache-like clones that exist in C++.
However, it lays an important foundation for the work to come in this space and, though long in coming, the end goal in the area is now very well defined.
Rename the coding model
Ever since we renamed our core model to coding we've been wondering if this was the right name. We've spent a fair bit of time wading through the literature in search of a fitting name, which would simultaneously reflect the domain terminology of MDE, as well as clarifying our intent. We've finally settled on assets, after reading the most enlightening review article by JM Jézéquel: "Model-driven engineering for software product lines".
The new name is also consistent with the fact that we intend to model both products and components within this meta-model, so hopefully the rename is future-proof, and - gasp - final. We have gone through some four or five names since Dogen's inception, so take that with a grain of salt.
Start of Fabric clean-up
One of the most anticipated tasks has been moving the fabric meta-model elements from the C++ and C# generation models into the assets model (as it is now known). This sprint fired the starting shot in this race: we have addressed the modeling of forward declarations in C++'s fabric. These have now been made consistent with the modeling ideas in Fabric. Sadly, many more items remain: some 15 or so elements need to be re-thought and re-modeled, moved into assets and then all of the associated formatting code needs to be updated.
Resourcing
As explained on the introduction, we've had around three quarters of the usual resourcing for this sprint, which was not ideal. On the plus side, over 77% of the sprint's total ask was spent on stories directly related to the sprint's mission, and just shy of 18% on process related work - with the release notes and demo consuming over 12% of that. Finally, we spent the remaining ~4% on spikes, mainly related to investigating the (many) test failures we're experiencing on Windows. Sadly no easy answers were to be found, so the investigation continues.

Planning
The project plan has suffered a couple of major setbacks this sprint. First, predictably, the fabric clean up was not completed this sprint. In addition, it is now clear it will be much harder than what we had estimated, so its now set to cost us the entirety of the next sprint. In addition, the PDM work is significant and it had not yet been added to the project plan.
The updated plan is now as follows.

Instalações do Porto do Namibe, Moçamedes, Angola. (C) 2018, Agricultura e Mar.
Introduction
This was yet another key sprint in our long march towards "meta-modeling all things". With this sprint we have now transformed all remaining JSON files in the data directory into regular modeling elements. We've also started to move the wale templates into the meta-model - which, we have now learned, are called logic-less templates - but sadly ran out of time before we could complete the task.
Our meta-model has grown considerably as this meta-modeling initiative progresses, so part of this sprint was spent organising it into some kind of hierarchical structure. Though by no means final, the present classification has already brought home some benefits. Unfortunately, one of the main objectives of this sprint was not achieved: the code generation of all feature related code. Predictably, it was harder than expected, and will have to be tackled over the next sprint. But all and all, it was a very successful sprint.
User visible changes
This section covers stories that affect end users. The sprint demo provides a quick demonstration of the user visible changes, whereas the remaining sub-sections provide more detail on each feature.
Sprint Demo
Click on the picture below to watch the sprint demo.

Separation of MASD and Dogen
A very important story implemented this sprint was the demarcation of the boundary between Dogen and MASD. Up to now we've been loosely using the masd:: prefix, even for elements that are really not part of MASD. With this sprint we have made an effort to become more accurate, and we now have a very simple test to determine where to place things: MASD is the public API for a code generator that follows its specifications, whereas Dogen is one (of possibly many) implementations of those specifications.
From a end-user perspective, the most important consequence of this change is the renaming of the Dogen binary, from masd.dogen.cli to dogen.cli. However, applying this filtering function to the code base also had a cross-cutting impact:
- Profiles: items such as Dogen's profiles have now been moved over to the
dogennamespace (or conversely, to the C++/C# models reference implementation namespace). That is, where in the past we hadmasd::handcrafted::typeable, it is nowdogen::handcrafted::typeable. Users are of course free to define their own profiles (under their own user defined namespaces), but it is important to make clear that the Dogen-defined profiles are not part of MASD, and are only available to end users if they are extending Dogen itself. - Palettes: As part of this separation, we also moved the colour palette from the C++ Reference Model, where it was incorrectly placed, into MASD. The colouring scheme will be part of the MASD public API. However, we will change the colours at some point in the near future - likely when we finish the meta-modeling work - in an attempt to create a consistent palette across the different element groups.
- LAM and variability models: LAM and the variability models are also part of the MASD public API, rather than just a Dogen-level concept.

Feature Templates as Meta-Model Elements
This sprint makes inroads into making the declaration of new features a more straightforward process. For this we've introduced the new stereotype masd::variability::feature_bundle, which is made up of feature templates. To recap, feature templates are projected over the archetype space, and can be thought of as toggles that control variability within the code generator. Whilst this story is user facing - in the sense that any user model can make use of this functionality - it is mainly of interest in the development of the code generator itself.
With the approach implemented by this sprint, we can now declare each feature within the model that makes use of it - instead of lumping all features together globally as we did in the JSON days - and the code generator now generates all the necessary code to integrate the feature with the code generator itself. However, this sprint we only had time to focus on the "declaration" of the feature templates; next sprint we will look at the "consumption" end and code-generate the infrastructure needed to "read" or "deserialise" the feature from a configuration.
In addition, we've also introduced the masd.variability model (not to be confused with the dogen.variability model), where all of the types used by features are declared. With this, we take one more step to "normalise" these types, making them less special. This is covered in more detail in the next section.
Mappings as Meta-Model Elements
In the past we had a JSON file with mappings between the abstract LAM (Language Agnostic Model) elements and the concrete elements (e.g. c++ and c# model types). Unfortunately, these mappings existed completely apart of the meta-model. With this sprint, we created the new type of masd::mapping::extensible_mappable, which provides a flexible (and extensible) mapping mechanism. We also created the LAM model as a regular Dogen model, using masd::mapping::extensible_mappable and (mostly) mapping to the same types as the JSON file did.

In order to map a type, you now need to declare the mapping at the destination end:
{
"name": "char",
"stereotypes": [
"masd::builtin"
],
"in_global_module": true,
"can_be_primitive_underlier": true,
"tagged_values": {
"masd.mapping.target": "masd.lam.text.character",Ideally, we'd like users to create their own mapping models instead of having to rely on LAM. However, the problem we have at present is that this would require having to modify the Dogen-supplied PDMs (Platform Definition Models), which is not ideal. More thinking is required in order to implement this use case, but a number of steps were taken in the right direction.
In addition, we also created the masd::mapping::fixed_mappable, for the special case of variability types. This model is internal to Dogen and is not expected to be used by end users - unless, of course, they are extending Dogen.

Unlike the extensible mappables, fixed mappables map to one and only one target in one technical space; and the target can be either a name or a name tree. For example, masd::variability::text maps to std::string whereas masd::variability::text_collection maps to std::list<std::string>. These named trees will then be used to make up the properties of the static configuration types which we will code generate next sprint.
New Facet: Lexical Cast
C++ has gained a new facet: lexical_cast. This facet specialises the boost::lexical_cast template function, at present only for Dogen enumerations. This enables the conversion of an enumeration from and to a string. The input string can be fully qualified (e.g. my_enum::my_enumerator) or simple (e.g. my_enumerator). The output string is always fully qualified (e.g. my_enum::my_enumerator). Contrived example usage for an imaginary model my_model:
#include <iostream>
#include "my_model/lexical_cast/my_enum.hpp"
void test() {
// Conversion from enum to string.
using namespace my_model;
my_enum a(my_enum::my_enumerator);
const auto str(boost::lexical_cast<std::string>(my_enum));
std::cout << str << std::endl; // prints my_enum::my_enumerator
// Conversion from string to enum
const auto e(boost::lexical_cast<my_enum>(str));
// e is now my_enum::my_enumerator
}See also the generated tests for more examples.
As with all other facets, you can use lexical cast globally or locally. To use the new facet globally, set the feature masd.generation.cpp.lexical_cast.enabled to true on your model configuration or profile. To use it locally, set it on the configuration of the specific enumeration that requires lexical cast support - or, better yet: create a local profile such as castable, set it there and update the stereotype of the enumeration in question (see the demo above for an example). This is the way all Dogen code is moving now.
Bug-fix: Allow Profiles at the Model Level
An important story was a fix to a brown-paper bag bug: profiles could not be declared directly on the model namespace of a user model. That is, in sprint 16 you needed to create a reference model to declare profiles. With this release you can now have a single model with both your user types and the profile. At some point we'll update the test models to contain all of the new meta-model elements on the target model, to make sure they all work.

Paróquia de São Pedro, Moçamedes, Namibe. Do blog de Maria Jardim.
Introduction
This sprint achieved the long standing objective of moving profiles into the meta-model. We've also continued the work on cleaning up models to better align them to MDE terminology.
User visible changes
This section covers stories that affect end users. The sprint demo provides a quick demonstration of the user visible changes, whereas the below sections provide more detail.

Profiles as meta-model elements
The key story of the sprint was to move variability profiles into the meta-model. For those less familiar with Dogen's variability profiles, the basic idea is that you can create "canned" sets of configurations and then apply them to modeling elements via UML stereotypes.
We had alread made decorations metamodel elements in sprint 14; now that we are also treating profiles as a regular meta-model elements, we have the core features in place to allow users to start defining SPLs. You can create an SPL by creating a shared model containing all of the required configuration such as profiles, decorations etc and then make use of these in the models that make up the product line. As an example, in Dogen we created the "profiles" model masd.dogen.profiles.dia.
The name is not exactly ideal as the model can contain more than just profiles, so we are still searching for a more fitting denomination. The fundamental idea is clear, though: to have a central place where all the configuration of the product is stored, and use it to create "a vocabulary" at the product level, imbued with product specific meaning. For example, one could define profiles such as hashable, serialisable and so forth and then configure these with specific features. hashable could be mapped to the std::hash facet, serialisable to the Boost Serialisation facet and so forth. All of the mapping and naming is defined by the end user. In Dogen we define masd::pretty_printable as follows (using JSON notation):
{
"name": "composable::pretty_printable",
"parents": [
"composable::code_generated"
],
"documentation": "The element has the ability to dump itself to a stream.\n",
"stereotypes": [
"masd::variability::profile_template"
],
"tagged_values": {
"masd.variability.binding_point": "element",
"masd.variability.labels": "masd::pretty_printable"
},
"attributes": [
{
"name": "masd.generation.cpp.io.enabled",
"type": "",
"value": "true",
"tagged_values": {
"masd.variability.archetype_location.kernel": "masd",
"masd.variability.archetype_location.backend": "masd.generation.cpp",
"masd.variability.template_kind": "instance"
}
}
]
},Any modeling element with the stereotype of masd::pretty_printable will now have the ability to dump itself into a stream via the masd.generation.cpp.io facet.
There are a couple of caveats to this feature. Firstly, we are yet to find a good domain based name for what are are calling thus far "profiles". The name is somewhat confusing, because Dogen's variability profiles are entirely unrelated to UML profiles. Our search through the literature continues, so in the future it is entirely possible that profiles will be renamed to a more fitting term.
Secondly, this release only adds the foundational infrastructure for SPL. Many domain elements still need to be added to complete the SPL story, such as the concept of a product, build systems, etc. However, these features are already useful enough, and simplified Dogen's internals considerably.
Removal of "stand-alone" weaving
In the past it was possible to instantiate stitch templates directly from Dogen, using the weaving command, e.g.:
$ masd.dogen.cli weave -t model.dia
However, due to the changes done in variability management, stitch templates are no longer instantiable without going through the entire processing pipeline for models. As such, the feature no longer makes sense, so it was removed.
The long term plan is to remove variability support from stitch templates; once that is in place, we can add weaving once more - though its usefulness in this fashion is somewhat debatable. We shall await for concrete use cases before working on this feature; for now, the story was moved to the bottom of the product backlog.
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Significant Internal Stories
Rather unusually, this sprint was extremely delivery focused, so there were no significant internal stories to speak of.
Resourcing
Amazingly, over 87% of the total ask was taken by stories directly related to the sprint's mission - probably a first in Dogen's development history. The remaining 13% of the time was spent as follows. Release related activities for the previous sprint cost around 5%, including activities such editing the release notes and creating the demo. Backlog grooming was shy of 5%, and around 1.3% of the total ask was spent on reading the academic literature on variability. Spikes had a cost of less than 2%, with the nursing of builds taking 0.8% and Emacs related work only 0.4%. Overall, it was an extremely efficient sprint.

Planning
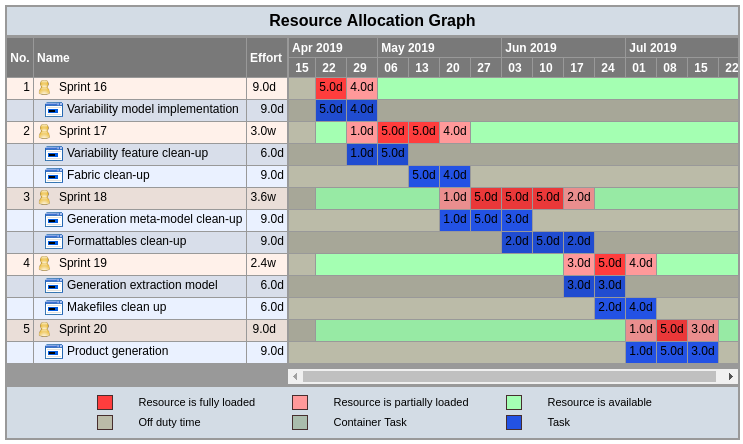
The plan is proceeding as expected. At the end of sprint 16, the plan looks like this:


Next Sprint
The focus on Sprint 17 is to address the other side of variability: the definition of new features. At present we are manually creating features, involving both the creation of the feature definition on its own JSON file and then the source code to implement the reading of the feature from a modeling element. The vision is that the code generator should create code for all of this, off the back of a modeling element (say masd::feature_group). Work has started on this in sprint 16, so hopefully it will be completed in sprint 17.
Binaries
You can download binaries from Bintray for OSX, Linux and Windows (all 64-bit):
For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available below.
Happy Modeling!
Dogen v1.0.15, "Quinzinho"

Joaquim Alberto da Silva ("Quinzinho") playing for the Angolan national team, the Palancas Negras. (C) 2001 Getty Images.
Prelude
This release is named in memory of "Quinzinho", who scored Angola's first goal in the Africa Cup of Nations. Xala Kiambote, Guerreiro.
Introduction
The key objective this sprint was to make inroads with regards to variability management in Dogen models [1]. Readers won't fail to notice that we've started to get more and more technical as we try to align Dogen with the PhD thesis. This trend is only set to increase, because we are approaching the business end of the research project. Also, as expected, the technical work was much harder than expected (if you pardon the pun), so we didn't get as far as exposing variability management to the end user. We are now hoping to reach this significant milestone next sprint.
User visible changes
This section covers stories that affect end users. There were only a few minor user visible changes:
- a rather dodgy bug in C# code generation was found and fixed, whereby we somehow were not generating code for C# models. How this was missed is a veritable comedy of errors, from the way we had designed the system tests to the way diffs were being made. Suffices to say that many lessons were learned and a tightening of the process was put into place to avoid this particular problem from happening again.
- CMake files now use the correct tab variable for emacs, i.e.
cmake-tab-widthinstead oftab-width. - CMake files are no longer hard-coded to generate static libraries. You can generate a shared library by using the CMake variable
-DBUILD_SHARED_LIBS=ON. This change was also made to the Dogen codebase itself, but due to a problem with the Boost.Log build supplied by vcpkg, we can't yet build Dogen using shared libraries [2].
Since there wasn't so much to demo, we provide a quick overview of these changes and also how you can use Dogen with cling. The demo also talks a little bit about JSON models.

Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Significant Internal Stories
The bulk of the work was taken by redesigning the annotations model. We have spent some time re-reading the MDE theory on this subject to make sure we have aligned all terminology with the terms used by domain experts. The final result was the creation of the variability model, composed of a number of transforms. This model has not yet been fully implemented and integrated with the core.
A second significant story this sprint was the reactivation of the boilerplate tests, which was a mop-up effort left from the previous sprint.
Resourcing
Over 54% of the sprint was taken by stories related to its mission statement. We spent around 16% of the total time on process, with just shy of 10% for backlog grooming, and the remainder related to release notes and demo. We've also had a number of interesting spikes, which were rather expensive:
- 10% of the time was spent changing our Emacs configuration. On the plus side, we are now using clangd instead of cquery, whose development has slowed considerably. Given that Google and many other large enterprises contribute to clangd's development, it seems like the right decision. As a bonus, we've also updated clang to v8 - though, sadly, not via Debian's package management, as it is still only in unstable. Let's hope it hits testing soon.
- the bug with C# code generation cost us 5.3% of the total ask.
- we've had a number of issues with our nightly builds, costing us 2.5% of the total ask.
The complete story breakdown is as follows:

Planning
Due to the variability work being harder than expected, the project plan was bumped back by a sprint. At the end of sprint 15, the plan looks like this:

Next Sprint
The focus on Sprint 15 is to finish the variability model, and replace the legacy classes with the new, transform-based approach. If all goes according to plan, this will finally mean we can expose our variability profiles to end users.
Binaries
Please note that we are now shipping clang binaries on Linux rather than the GCC-generated ones. Due to the current refactorings, our GCC builds are taking too long to complete. This does mean that we are now using clang for all our builds.
You can download binaries from Bintray for OSX, Linux and Windows (all 64-bit):
For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available below.
Happy Modeling!
Footnotes
[1] If this is not a topic you are familiar with and you'd like to understand it better, JM Jézéquel's review paper on the subject is probably of interest: "Model-Driven Engineering for Software Product Lines".
[2] vcpkg #6148: Errors building shared library due to Boost Log and PIC
Dogen v1.0.14, "Deserto do Namibe"
Dunes in the Namib Desert, Namibe Province, Angola. (C) 2012 João P. Baptista.

Introduction
This sprint was yet again an extremely busy affair. However, for a change, work was mainly focused on the task at hand rather than on distractions such as testing. As a result, we have finally delivered the first of a number of core meta-model changes that aim to regularise our approach to the modeling of elements across the solution space. In other words, it may appear like a small release to the untrained eye, but it feels like a giant leap to the development team.
As you will not fail to notice, the release notes have been tweaked yet again in response to feedback: we now start with the user visible changes, and proceed to discuss internal matters afterwards.
User visible changes
This section covers stories that affect end users. The sprint demo provides a quick demonstration on the user visible changes, whereas the below sections provide more detail.

Decorative elements are now in meta-model
Before delving into the details of the feature, it is worth providing some context. Up to now we have separated configuration from modeling proper. As a result, there are a number of little configuration files, each declared and consumed by user models via its own ad-hoc mechanisms. As MDE theory became better understood, and as the MASD approach cemented itself, it became clear that these configuration units are indeed worthy of modeling just like any other higher level concept present in a product. This release sees the start of a long process that, when completed, will finally move the architecture to its desired state. Sadly, it will require quite a large engineering effort to get there.
As for the feature itself: this release places the management of modelines, licences, location strings (known in Dogen speak as "generation markers") and other decorative elements into the meta-model. This means that instead of an assortment set of data files of varying formats, these are now contained in a "regular" model and can be extended and/or overridden by users as required.
The masd model defines a number of these which can be readily used:

In order to make use of these new model elements, you need to first define a reference to masd (assuming a Dia model):
#DOGEN masd.injection.reference=masd
And then you can set up the meta-data as required:
#DOGEN masd.generation.decoration.enabled=true
#DOGEN masd.generation.decoration.licence_name=masd.gpl_v3
#DOGEN masd.generation.decoration.modeline_group_name=masd.emacs
#DOGEN masd.generation.decoration.copyright_notice=Copyright (C) 2012-2015 Marco Craveiro <marco.craveiro@gmail.com>
Please note that these keys were previously available with different names, so this is a breaking change. The fields have been updated from:
masd.decoration.enabled
masd.decoration.licence_name
masd.decoration.copyright_notice
masd.decoration.modeline_group_name
to:
masd.generation.decoration.enabled
masd.generation.decoration.licence_name
masd.generation.decoration.copyright_notice
masd.generation.decoration.modeline_group_name
As you can see, from a usage perspective these are very similar to the previous approach (modulus the field name changes). However, the advantage is that you can now define you own modeling elements (licences, etc), on either the target model or a model shared by a number of target models - as in the masd model example above.
Language rename
Sadly, this is not the only breaking change in this release. The "language rename" is explained in more detail below on the internal section, but from a end user perspective, it is a breaking change. The following fields have been renamed:
#DOGEN masd.injection.input_language=cpp
#DOGEN masd.extraction.output_language=cpp
They must be updated to:
#DOGEN masd.injection.input_technical_space=cpp
#DOGEN masd.extraction.output_technical_space=cpp
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Milestones
With this release, we have made the 8888th commit to Dogen! I guess a celebration blog post is in order, though it's always difficult to justify taking more time away from coding.

Significant Internal Stories
Several very important clean-ups were achieved this sprint:
- Move from "languages" to "technical spaces". This is somewhat difficult to explain without getting into the details (which my thesis will explain properly), but with this release we have started a move from mere programming languages towards technical spaces as MDE understands them. This will in time provide a much cleaner conceptual model.
- Simpler qualified name representation. In the past we had relied on maps, and associated qualified names directly with programming languages. With this release we now have a cleaner representation for these.
- Clean-up of the extraction model. This story is related to the user visible feature above, but from an internal perspective. We have now moved all code in the extraction model which didn't belong there. There is only one outstanding task to finish the clean-up of this model, but it already looks in a much better shape.
Resourcing
Most of the sprint's time was spent towards moving extraction model entities into the coding metamodel (~45%). Around 18% of the total time was dedicated to process, with the bulk of it taken by backlog grooming (9.5%), project planning (just below 3%) and the editing of release notes and the creation of the demo for the previous sprint (~2% and ~4% respectively). We also had a couple of spikes.
The first spike had a cost of around 4%, and is related to integrating Report-CI; this is the latest project by Klemens Morgenstern, the amazing coder behind Boost.Process and other core libraries. As always, we are happy to help fellow travellers on their road to product building. In addition, integration was fairly trivial (mainly reviewing Klemens' PRs) and we've already started to see some of the benefits as we start to make use of the reports the tool produces.
The second spike cost circa 3.3% and was related to fixes to the emacs setup. Improvements in the development environment are always welcome, and tend to have a very positive impact, though in ways that are somewhat difficult to measure.
The complete story breakdown is as follows:

Planning
Sprint 14 introduces a project plan. Given Dogen is on the critical path of my PhD, it seemed like a good idea to create some kind of road map that gives an inkling as to when I can start to think of completing it. It has the grandiose name of "project plan", but alas, it is nothing like a project plan for a real industry project. In truth, I've never been a great believer in the estimation process; the objective here is just to have some kind of projection, regardless of how crude, of what is left to do in order to release the fabled v2 release.
At the end of sprint 14, the plan looks like this:


We will keep it updated with each release.
Next Sprint
As per the project plan above, we are expecting to continue the meta-modeling work in the next sprint by tackling a very thorny issue: moving profiles into the meta-model. This is a feature of pivotal importance to make Dogen usable because it will finally mean users can define profiles such as serializable and the like on their own diagrams, associate them with user defined configuration, and ultimately apply them to element types. Profiles are key to unlocking Dogen functionality, so we are extremely excited to finally get to work on this feature.
Binaries
You can download binaries from Bintray for OSX, Linux and Windows (all 64-bit):
Dogen v1.0.13, "Náutico Club"
Esplanada do Náutico Club, Moçamedes, Namibe Province, Angola. (C) 2019 Nautico Club Site.

Introduction
The sprint cadence seems to finally be establishing itself, with sprint 13 offering yet another solid 2-week effort. The main emphasis was on solving the unit testing of generated code. If you recall, we had some sparse manual tests for these, delightfully called the "canned tests". These weren't exactly brilliant, but did provide some kind of coverage. Sadly, we ended up having to disable them due to weird and wonderful failures on OSX and Windows, which we could not reproduce on Linux and which were rather difficult to get to the bottom of via CI because of the way the tests were designed.
As the next few sprints are all about very (hard-)core changes, we had to make sure a strong testing base is in place before we can proceed with the refactoring. As usual, the work was much harder than expected, taking us the best part of two sprints to get to a good place: firsy, sprint 12 was all about the system test story, and now sprint 13 is all about the unit tests story. Fortunately, we still managed to sneak in one useful feature.
The below chart breaks down the cost of each story, percentage-wise, in terms of the total sprint time.

The next sections provide a summary of the most significant stories. As usual, for more details of the work carried out this sprint, see the sprint log.
Internal Changes
In this section we cover stories that consumed significant resources but are only visible internally.
Sprint and product backlog grooming
In this sprint we spent quite a lot of time grooming the backlogs. This is something which never gets much of a mention, but which I believe is one of the most important aspects of Agile: you need to keep your product backlog in good shape. Perhaps spending 15% of the total time of a sprint grooming backlogs may sound a tad excessive, but in our defence we do have a hefty product backlog, with over 550 user stories at various levels of detail. Also, given that we have just finished a massive rewrite of the theoretical basis for Dogen, it is no surprise that a lot of the stories started to bit-rot. This clean up was mainly to look for low hanging fruit and remove all stories which are completely deprecated; subsequent clean-ups will delve more into the detail of the stories.
User visible changes
This section covers stories that affect end users. The sprint demo provides a quick demonstration on the user visible changes, whereas the below sections provide more detail.

{kind=link}
Code generation of tests for dogen models
This story had started on the previous sprint, but, as always, proved to be much more complicated than anticipated. Whilst the story is user facing - in that users can enable it for their own models - its purpose is very much just to test the code generator, so its not really that helpful to end users outside of Dogen.
In theory, adding tests seems just like adding another facet. Since we already have quite a number of these, we were pretty confident this would be a "quick effort". In practice, there were many subtle differences with the test facet which, cumulatively, caused very large problems and forced some difficult changes to the core of Dogen. On the plus side, the pain seems to be worth it, as we are now testing pretty much all facets for all generated code, across both Dogen itself and the Reference Implementation on all supported platforms. Even better, they are all green:

Whilst coverage is extensive, unfortunately we do not yet cover ODB (C++ ORM mapping) nor C# (which still relies on canned tests). In addition, build time has gone up quite considerably, given that we now need to compile the test data facet for all of these types, plus the tests too. The following chart demonstrates this problem:

As a result of this increase, MSVC is no longer able to complete the builds within the allotted time. Fortunately our clang-cl builds are deemed good enough (only one test failure across some 2.7k tests) so we'll be shipping that to users from now on. In the future we will need to look into ways of decreasing build time, as we are very close to the edge on OSX and clang-cl.
Delete empty directories
In the past we used to generate all facets for all models, Dogen and Reference Implementation. However, over time we ended up having to disable most facets as the build time was getting out of control. Dogen correctly deleted all of the generated files when the facets were disabled, but left behind a number of empty directories. Worse: because git does not care about empty directories, we weren't even aware of their existence until some speculative filesystem browsing revealed them. This sprint adds a new knob to delete any empty directory under the project: delete_empty_directories. Together with delete_extra_files, this should mean that most generated lint is taken care of now.
#DOGEN masd.extraction.delete_extra_files=true
#DOGEN masd.extraction.delete_empty_directories=true
Rename of extraction fields
One user facing change was actually a bug. Some generation fields had been placed incorrectly in extraction. This was spotted and fixed in this release. The change is not backwards compatible. As an example, a model with the following fields:
#DOGEN masd.extraction.cpp.enabled=true
#DOGEN masd.extraction.cpp.standard=c++-17
#DOGEN masd.extraction.cpp.msbuild.enabled=false
#DOGEN masd.extraction.cpp.visual_studio.project.enabled=false
#DOGEN masd.extraction.cpp.visual_studio.solution.enabled=false
#DOGEN masd.extraction.csharp.enabled=false
Now becomes:
#DOGEN masd.generation.cpp.enabled=true
#DOGEN masd.generation.cpp.standard=c++-17
#DOGEN masd.generation.cpp.msbuild.enabled=false
#DOGEN masd.generation.cpp.visual_studio.project.enabled=false
#DOGEN masd.generation.cpp.visual_studio.solution.enabled=false
#DOGEN masd.generation.csharp.enabled=false
This change affects all facets in C# and C++, so if you are configuring these directly you will need to manually update your models.
Next Sprint
Though we risk repeating Sprint 12's parting words, we are still of the of opinion that next sprint will finally be all about core metamodel changes. Now we have solid testing in place, our key objective for next sprint is to move all of the decoration related code into the meta-model. We started work on this in the previous sprint but sadly ran out of time. In addition, we hope to finally make some inroads against moving annotations to the metamodel. This will be a significant major feature, at long last.
Binaries
You can download binaries from Bintray for OSX, Linux and Windows (all 64-bit):
Note: Windows builds are now generated using clang-cl rather than MSVC.
For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available below.