Dogen v1.0.29, "Bar 'O Stop'"
Bar O Stop, Namibe. (C) 2010 Jo Sinfield

Introduction
And so t'was that the 29th sprint of the 1.0 era finally came to a close; and what a bumper sprint it was. If you recall, on Sprint 28 we saw the light and embarked on a coding walkabout to do a "bridge refactor". The rough objective was to complete a number of half-baked refactors, and normalise the entire architecture around key domain concepts that have been absorbed from MDE (Model Driven Engineering) literature. Sprint 29 brings this large wandering to a close - well, at least as much as one can "close" these sort of never ending things - and leaves us on a great position to focus back on "real work". Lest you have forgotten, the "real work" had been to wrap things up with the PMM (Physical Meta-Model), but it had fallen by the wayside since the end of Sprint 27. When this work resumes, we can now reason about the architecture without having to imagine some idealised target state that would probably never arrive (at the rate we were progressing), making the effort a lot less onerous. Alas, this trivialises the sprint somewhat. The truth was that it took over 380 commits and 89 hours of intense effort to get us in this place, and it is difficult to put in words the insane amount of work that makes up this release. Nevertheless, one is compeled to give it a good old go, so settle in for the ride that was Sprint 29.
User visible changes
This section normally covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. As there were no user facing features, the video discusses the work on internal features instead.
Video 1: Sprint 29 Demo.
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Significant Internal Stories
This sprint had two key goals, both of which were achieved:
- moving remaining "formattable" types to logical and physical models.
- Merge
textmodels.
By far, the bulk of the work went on the second of these two goals. In addition, a "stretch" goal appeared towards the end of the sprint, which was to tidy-up and merge the codec model. These goals were implemented by means of four core stories, which captured four different aspects of the work, and were then aided by a cast of smaller stories which, in truth, were more like sub-stories of these "conceptual epics". We shall cover the main stories in the next sections and slot in the smaller stories as required. Finally, there were a number of small "straggler stories" which we'll cover at the end.
Complete the formattables refactor
A very long running saga - nay, a veritable Brazilian soap opera of coding - finally came to an end this sprint with the conclusion of the "formattables" refactor. We shan't repeat ourselves explaining what this work entailed, given that previous release notes had already done so in excruciating detail, but its certainly worth perusing those writings to get an understanding of the pain involved. This sprint we merely had to tie up lose ends and handle the C# aspects of the formattables namespace. As before, all of these objects were moved to "suitable" locations within the LPS (Logical-Physical Space), though perhaps further rounds of modeling clean-ups are required to address the many shortcomings of the "lift-and-shift" approach taken. This was by design, mind you; it would have been very tricky, and extremely slow-going, if we had to do a proper domain analysis for each of these concepts and then determine the correct way of modeling them. Instead, we continued the approach laid out for the C++ model, which was to move these crazy critters to the logical or physical models with the least possible amount of extra work. To be fair, the end result was not completely offensive to our sense of taste, in most cases, but there were indeed instances that required closing one's eyes and "just get on with it", for we kept on being tempted to do things "properly". It takes a Buddhist-monk-like discipline to restrict oneself to a single "kind" of refactor at a time, but it is crucial to do so because otherwise one will be forever stuck in the "refactor loop", which we described in The Refactoring Quagmire all those moons ago.
It is also perhaps worth spending a few moments to reflect on the lessons taught by formattables. On one hand, it is a clear validation of the empirical approach. After all, though the modeling was completely wrong from a domain expertise standpoint, much of what was laid out within this namespace captured the essence of the task at hand. So, what was wrong about formattables? The key problem was that we believed that there were three representations necessary for code-generation:
- the external representation, which is now housed in the
codecmodel; - the "language agnostic" representation, which is now housed in the
logicmodel; - the "language-specific" representation, which was implemented by formattables (i.e.,
text.cppandtext.csharp).
What the empirical approach demonstrated was that there is no clear way to separate the second and third representations, try as we might, because there is just so much overlap between them. The road to the LPS had necessarily to go through formattables, because in theory it appeared so clear and logical that separate TSs (Technical Spaces) should have clean, TS-specific representations which were ready to be written to files. As Mencken stated:
Every complex problem has a solution which is simple, direct, plausible—and wrong.
In fact, It took a great deal of careful reading through the literature, together with a lot of experimentation, to realise that doing so is not at all practical. Thus, it does not seem that it was possible to have avoided making this design mistake. One could even say that this "mistake" is nothing but the empirical approach at play, because you are expected to conduct experiments and accumulate facts about your object of study, and then revise your hypothesis accordingly. The downside, of course, is that it takes a fair amount of time and effort to perform these "revisions" and it certainly feels as if there was "wasted time" which could have been saved if only we started off with the correct design in the first place. Alas, it is not clear how would one simply have the intuition for the correct design without the experimentation. In other words, the programmer's perennial condition.
Move helpers into text model and add them to the PMM
As described in the story above, it has become increasingly clear that the text model is nothing but a repository of M2T (Model to Text) transforms, spread out across TS's and exposed programatically into the PMM for code generation purposes. Therefore, the TS-specific models for C++ and C# no longer make any sense; what is instead required is a combined text model containing all of the text transforms, adequately namespaced, making use of common interfaces and instantiating all of the appropriate PMM entities. This "merging" work fell under the umbrella of the architectural clean up work planned for this sprint.
The first shot across the bow in the merging war concerned moving "helpers" from both C++ and C# models into the combined model. A bit of historical context is perhaps useful here. Helpers, in the M2T sense, have been a pet-peeve of ours for many many moons. Their role is to code-generate functionlets inside of the archetypes (e.g. the "real" M2T transforms). These helpers, via an awfully complicated binding logic which we shall not bore you with, bind to the type system and then end up acting as "mini-adapters" for specific purposes, such as allowing us to use third-party libraries within Dogen, cleaning up strings prior to dumping them in streams and so forth. A code sample should help in clarifying this notion. The below code fragment, taken from logical::entities::element, contains the output three different helper functions:
inline std::string tidy_up_string(std::string s) {
boost::replace_all(s, "\r\n", "<new_line>");
boost::replace_all(s, "\n", "<new_line>");
boost::replace_all(s, "\"", "<quote>");
boost::replace_all(s, "\\", "<backslash>");
return s;
}
namespace boost {
inline bool operator==(const boost::shared_ptr<dogen::variability::entities::configuration>& lhs,
const boost::shared_ptr<dogen::variability::entities::configuration>& rhs) {
return (!lhs && !rhs) ||(lhs && rhs && (*lhs == *rhs));
}
}
namespace boost {
inline std::ostream& operator<<(std::ostream& s, const boost::shared_ptr<dogen::variability::entities::configuration>& v) {
s << "{ " << "\"__type__\": " << "\"boost::shared_ptr\"" << ", "
<< "\"memory\": " << "\"" << static_cast<void*>(v.get()) << "\"" << ", ";
if (v)
s << "\"data\": " << *v;
else
s << "\"data\": ""\"<null>\"";
s << " }";
return s;
}
}The main advantage of the "helper approach" is that one does not have to distribute any additional header files or libraries to compile the generated code, other than the third-party libraries themselves. Sadly, this is not sufficient to compensate for its downsides. This approach has never been particularly efficient or pretty - imagine hundreds of lines such as the above scattered around the code base - but, significantly, it isn't particularly scalable either, because one needs to modify the code generator accordingly for every new third party library, together with the associated (and rather complex) bindings. Our incursions through the literature provided a much cleaner way to address these requirements via hand-crafted PDMs (Platform Definition Models), which are coupled with third-party libraries and are responsible for providing any glue needed by generated code. However, since we've been knee-deep into a cascade of refactoring efforts, we could not bring ourselves to halt the present work once more and context-switch to yet another (possibly) long running refactoring effort. As a result, we decided to keep calm and carry on the burden of moving helpers around, until such time we could refactor them out of existence. The text model merging did present a chance to revisit this decision, but we thought best "to confuse one issue at a time" and decided to "just move" the helpers across to the text model. As it turned out, "just moving" them was no trivial matter. Our troubles begun as soon as we tried to untangle the "helpers" from the "assistant".
At this juncture, your design alarm bells are probably ringing very loudly, and so were ours. After all, a common adage amongst senior developers is that whenever you come up with entities named "assistant", "helper", "manager" and the like, they are giving you a clear and unambiguous indication that you have a slim understanding of the domain; worse, they'll soon devolve into a great big ball of mud, for no one can possibly divine their responsibilities. The blog posts on this matter are far too many to count - i.e., Jeff Atwood, Alan Green, and many Stack Overflow posts such as this one. However, after some investigation, it seemed there was indeed some method in our madness:
- the "helpers" where really PDMs in disguise, and those would be dealt with at some point in the future, so they could be ignored for now;
- the "assistant" had ultimately two distinct responsibilities: 1) to perform some TS-specific transformation of data elements from the logical model, which we now understood to fall under the logical model umbrella; 2) to perform some "formating assistance", providing common routines to a lot of M2T transforms. We implemented some of these refactors, but others were deemed to be outside of the scope of the present exercise, and were therefore added to the backlog.
This was the harbinger of things to come. Much more significantly, assistants and helpers where bound together in a cycle, meaning we could not move them incrementally to the text model as we originally envisioned. As we've elaborated many a times in these pages, cycles are never the bearers of good fortune, so we took upon ourselves breaking the cycle as part of this exercise. Fortunately this was not too difficult, as the parts of the assistant API used by the helpers were fairly self contained. The functionality was encapsulated into an ABC (Abstract Base Class), a decision that is not without controversy, but which suffices amply to address the problem at hand - all the more so given that helpers are to be removed in the not too distant future.
A third stumbling block was that, even though helpers are deprecated and their impact should be contained to legacy code, they still needed to be accessible via the PMM. Sadly, the existing helper code was making use of some of the same features which in the new world are addressed by the PMM, and so we had no choice but to extend the PMM with helper support. Though not ideal, this was done in a fairly painless manner, and it is hopefully self-contained enough that not much of the code base will start to rely on its presence. Once all of these obstacles were resolved, the bulk of the work was fairly repetitive: to move helpers in groups into the text model, tidying up each text template until it produced compilable code.
In the end, the following stories were required to bring the main story to a close:
- Improvements to template processing in logical model: minor fixes to how templates were being handled.
- Convert legacy helpers into new style helpers in C++: the bulk of the adaptation work in the C++ TS.
- Add C++ helpers to the PMM: Adding PMM infrastructure to deal with helpers. Here we are mainly concerned with C++, but to be fair much of the infrastructure is common to all TSs.
- Remove unused wale keys in
text.cpp: minor tidy-up of templates and associated wale (mustache) keys. - Merge
cpp_artefact_transform*wale templates : Removal of unnecessary wale (mustache) templates. - Add C# helpers to the PMM: Modifications to the PMM to cater for C#-specific concerns.
- Move helpers to
textmodel: Remaining work in moving the helpers across to the combinedtextmodel.
Move text transforms in C++ and C# models into text model
Once we had helpers under our belt, we could turn our attention to the more pressing concerns of the M2T transforms. These presented a bigger problem due to scale: there are just far too many text transforms. This was a particularly annoying problem due to how editing in Dia works at present, with severe limitations on copying and pasting across diagrams. Alas, there was nothing for it but patience. Over a long period of time, we performed a similar exercise to that of the helpers and moved each text template into their resting location in the text model. The work was not what you'd call a creative exercise, but nonetheless an important one because the final layout of the text model now mirrors the contents of the PMM - precisely what we had intended from the beginning.

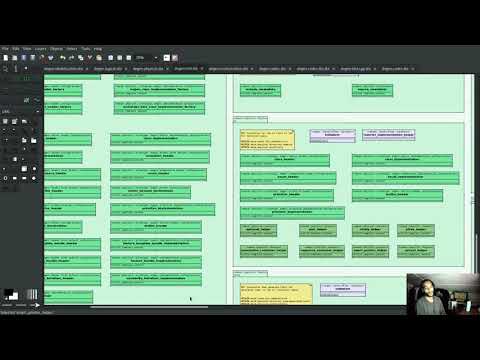
Figure 1: Birds-eye view of the text model
Figure 1 shows a birds-eye view of the text model. On the top-leftmost corner, in orange, you can see the wale (mustache) templates. Next to it is the entities namespace, containing the definition of the LPS (in pink-ish). At the bottom of the picture, with the greener tones, you have the two major TS: C++ (on the bottom left) and C# (on the bottom right, clipped). Each TS shows some of the M2T transforms that composes them. All elements are exposed into the PMM via code-generation.
Clean up and merge codec models
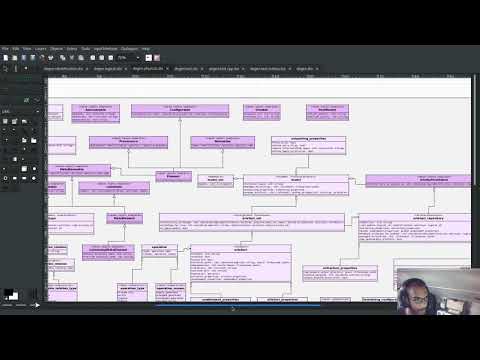
The final "large" architectural problem we had to address was the current approach for the codec models. Long ago, we envisioned a proliferation of the number of codecs for Dogen, and so thought these should be dynamically injected to facilitate the use case. In our view, each codec would extend Dogen to process file types for specific uses, such as adding eCore support, as well as for other, non-UML-based representations. Whilst we still see a need for such an approach, it was originally done with little conceptual understanding of MDE and as such resulted in lots of suis generis terminology. In addition, we ended up with lots of little "modelets" with tiny bits of functionality, because each codec now shares most of its pipeline with the main codec model. Thus, the right approach was to merge all of these models into the codec model, and to move away from legacy terms such as hydrator, encoder and the like, favouring instead the typical MDE terminology of transforms and transform chains. This story covered the bulk of the work, including the merging of the codec.json and codec.org models, but sadly just as we were closing in in the codec.dia model we ran out of time. The work shall be completed early next sprint.

Figure 2: Fragment of the codec model after refactoring.
Other stories related to this work:
- Use MDE terminology in Dia model: the plain (non-codec) representation of Dia got an "MDE tidy-up, following the same pattern as all other models and using transforms rather than hydrators, etc.
Assorted smaller stories
A number of small stories was also worked on:
- Fix some problems with c++ visual studio: assorted improvements to Visual Studio project files; though these are still not ready for end users.
- Orchestration should have an initialiser: instead of copying and pasting the individual initialisers, create a top-level initialiser in orchestration and reuse it.
- Add namespaces to "dummy function": two classes with the same name in different namespaces resulted in the same "dummy" function, resulting in spurious OSX warnings. With this change, we generate the dummy function name from file path resulting in unique names in a component.
- Remove disabled files from project items: C# and C++ Visual Studio solutions contained files for disabled facets, due to the way enablement worked in C#. With the merge to the text model, this caused problems so we now honour disabled facets when generating project files.
- Remove JSON models from Dogen: Remove tests for JSON models within the Dogen product. JSON is still supported within the C++ reference implementation, but at least this way we do not need to regenerate the JSON models every time we change Dogen models which is quite often.
Video series of Dogen coding
This sprint we concluded the video series on the formattables refactor as well as a series on the text model refactor. These are available as playlists. The tables below present a summary of each part. Note that the previous videos for the formattables refactor are available on the release note for Sprint 28.
| Video | Description |
|---|---|
| Part 19 | In this video we get rid of most of the helper related properties in formattables and almost get rid of the formattables model itself, but fail to do so in the end due to some unexpected dependencies. |
| Part 20 | In this part we start to add the PMM infrastructure, beginning with the logical model representation of helpers. However, when we try to use it in anger, the world blows up. |
| Part 21 | In this video we try to generate the helpers implementation but find that there are some very significant errors in how helpers have been modeled. |
| Part 22 | In this episode we complete the transition of types helpers and do a few hash helpers. Apologies for the echo in the sound. |
| Part 23 | In this video we tackle the helpers in the C# Technical Space, as well as other assorted types. |
| Part 24 | In the final part in this series, we finally get rid of the formattables namespace. |
Table 1: Remaining videos on the playlist for the formattables refactor.
Video 2: Playlist "MASD - Dogen Coding: Formatables Refactor".
| Video | Description |
|---|---|
| Part 1 | In this part we introduce the task, and describe the overall approach. We also start to tackle the helpers. |
| Part 2 | In this part we tried to replace the C++ helper interface with the one from Text but we faced all sorts of fundamental issues and had to go back to the drawing board. |
| Part 3 | In this part we spend a lot of time copying and pasting code to adapt the helper M2T transforms to the new interface. We get close to the end of this task but don't quite complete it. |
| Part 4 | In this part we move across all backends and facets to the combined text model. |
| Part 5 | In this part we remove all of the helper parafernalia in text.cpp and text.csharp, bar the helpers themselves, and consolidate it all under the text model. We also move the first helper. |
| Part 6 | In this part we review the helper work we did offline and attempt to move to the new, non-TS-specific way of organising text transforms. |
| Part 7 | In this part we review a number of changes done offline and then deal with the C# assistant, moving it across to the text model. |
| Part 8 | In this part we mostly complete the work on merging the text model. Apologies in advance for this vide as it has a number of problems including bad sound quality as well as several stoppages, and finally, it terminates abruptly due to a machine crash. However we kept it for the record |
| Part 9 | This part is a recap due to the abrupt ending of the previous part, due to a machine crash (damn NVidia drivers for Linux!). |
Table 2: Individual videos on the playlist for the text model refactor.
Video 3: Playlist "MASD - Dogen Coding: Formatables Refactor".
Resourcing
On one hand, the utilisation rate of 35% was not particularly brilliant this sprint, but by pretty much any other metric it has to be considered a model of resource consumption (if you pardon the MDE pun). Almost 89% of the total ask was used on stories directly related to the development process, and whilst the break down of stories was not exactly stellar, we still managed a good spread with the top 3 stories consuming 24.1%, 17.8% and 15.2% respectively. We tend to look closely at this because its a good indicator of the health of the analysis of a sprint, and its always a bad sign when one story dominates the majority of the ask. Nonetheless, when one looks at the story titles in more detail its still clear that there was a certain element of laziness in how the work was split and, as always, there is room for improvement in this department. The 11% on non-core tasks had the usual characteristics, with 5.7% allocated to the release notes, and a very cheap demo at 0.5%. One important note though is that this sprint consumed almost 90 hours in total rather than the more traditional 80, which means that looking at percentage numbers is somewhat misleading, particularly when comparing to a typical sprint. The major downside of this sprint was general tiredness, as usual, given the huge amount of the commitment. Sadly not much can be changed in this department, and ideally we wouldn't want to slow down in the next sprint though the Holidays may have a detrimental effect.

Figure 3: Cost of stories for sprint 29.
Roadmap
The key alteration to the road map - other than the removal of the long standing "formattables refactor" - was the addition of the org-mode codec. We've spent far too many hours dealing with the inadequacies of Dia, and it is by now clear that we have much to gain by moving into Emacs for all our modeling needs (and thus, all our Dogen needs since everything else is already done inside Emacs). Therefore we've decided to take the hit and work on implementing org-mode support next sprint before we resume the PMM work. Other than that we are as we were, though on the plus side the road map does have a very realistic feel now given that we are actually completing targets on a sprint by sprint basis.


Binaries
You can download binaries from either Bintray or GitHub, as per Table 3. All binaries are 64-bit. For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available in zip or tar.gz format.
| Operative System | Format | BinTray | GitHub |
|---|---|---|---|
| Linux Debian/Ubuntu | Deb | dogen_1.0.29_amd64-applications.deb | dogen_1.0.29_amd64-applications.deb |
| OSX | DMG | DOGEN-1.0.29-Darwin-x86_64.dmg | DOGEN-1.0.29-Darwin-x86_64.dmg |
| Windows | MSI | DOGEN-1.0.29-Windows-AMD64.msi | DOGEN-1.0.29-Windows-AMD64.msi |
Table 3: Binary packages for Dogen.
Note 1: The OSX and Linux binaries are not stripped at present and so are larger than they should be. We have an outstanding story to address this issue, but sadly CMake does not make this a trivial undertaking.
Note 2: Due to issues with Travis CI, we had a number of failed OSX builds and we could not produce a final build for this sprint. However, given no user related functionality is provided, we left the link to the last successful build of Sprint 29. The situation with Travis CI is rather uncertain at present so we may remove support for OSX builds altogether next sprint.
Next Sprint
The goals for the next sprint are:
- to finish the codec tidy-up work.
- to implement org mode codec.
- to start implement path and dependencies via PMM.
That's all for this release. Happy Modeling!