Dogen v1.0.28, "Praia das Miragens"
Artesanal market, Praia das Miragens, Moçâmedes, Angola. (C) 2015 David Stanley.

Introduction
Welcome to yet another Dogen release. After a series of hard-fought and seemingly endless sprints, this sprint provided a welcome respite due to its more straightforward nature. Now, this may sound like a funny thing to say, given we had to take what could only be construed as one massive step sideways, instead of continuing down the track beaten by the previous n iterations; but the valuable lesson learnt is that, oftentimes, taking the theoretically longer route yields much faster progress than taking the theoretically shorter route. Of course, had we heeded van de Snepscheut, we would have known:
In theory, there is no difference between theory and practice. But, in practice, there is.
What really matters, and what we keep forgetting, is how things work in practice. As we mention many a times in these release notes, the highly rarefied, highly abstract meta-modeling work is not one for which we are cut out, particularly when dealing with very complex and long-running refactorings. Therefore, anything which can bring the abstraction level as close as possible to normal coding is bound to greatly increase productivity, even if it requires adding "temporary code". With this sprint we finally saw the light and designed an architectural bridge between the dark old world - largely hacked and hard-coded - and the bright and shiny new world - completely data driven and code-generated. What is now patently obvious, but wasn't thus far, is that bridging the gap will let us to move quicker because we don't have to carry so much conceptual baggage in our heads every time we are trying to change a single line of code.
Ah, but we are getting ahead of ourselves! This and much more shall be explained in the release notes, so please read on for some exciting news from the front lines of Dogen development.
User visible changes
This section normally covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. As there were no user facing features, the video discusses the work on internal features instead.
Video 1: Sprint 28 Demo.
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Significant Internal Stories
The main story this sprint was concerned with removing the infamous locator from the C++ and C# models. In addition to that, we also had a small number of stories, all gathered around the same theme. So we shall start with the locator story, but provide a bit of context around the overall effort.
Move C++ locator into physical model
As we explained at length in the previous sprint's release notes, our most pressing concern is finalising the conceptual model for the LPS (Logical-Physical Space). We have a pretty good grasp of what we think the end destination of the LPS will be, so all we are trying to do at present is to refactor the existing code to make use of those new entities and relationships, replacing all that has been hard-coded. Much of the problems that still remain stem from the "formattables subsystem", so it is perhaps worthwhile giving a quick primer of what formattables were, why they came to be and why we are getting rid of them. For this we need to travel in time, to close to the start of Dogen. In those long forgotten days, long before we had the benefit of knowing about MDE (Model Driven Engineering) and domain concepts such as M2M (Model-to-Model) and M2T (Model-to-Text) transforms, we "invented" our own terminology and approach to converting modeling elements into source code. The classes responsible for generating the code were called formatters because we saw them as a "formatting engine" that dumped state into a stream; from there, it logically followed that the things we were "formatting" should be called "formattables", well, because we could not think of a better name.
Crucially, we also assumed that the different technical spaces we were targeting had lots of incompatibilities that stopped us from sharing code between them, which meant that we ended up creating separate models for each of the supported technical spaces - i.e., C++ and C#, which we now call major technical spaces. Each of these ended up with its own formattables namespace. In this world view, there was the belief that we needed to transform models closer to their ultimate technical space representation before we could start generating code. But after doing so, we began to realise that the formattable types were almost identical to their logical and physical counterparts, with a small number of differences.

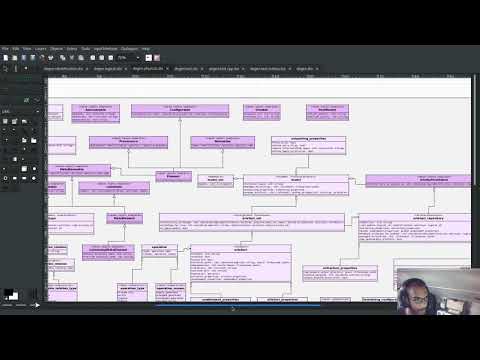
Figure 1: Fragment of the formattables namespace, C++ Technical Space, circa sprint 23.
What we since learned is that the logical and physical models must be able to represent all of the data required in order to generate source code. Where there are commonalities between technical spaces, we should exploit them, but where there are differences, well, they must still be represented within the logical and physical models; there simply is nowhere else to place them. In other words, there isn't a requirement to keep the logical and physical models technical space agnostic, as we long thought was needed; instead, we should aim for a single representation, but also not be afraid of multiple representations where they make more sense. With this began a very long-standing effort to move modeling elements across, one at a time, from formattables and the long forgotten fabric namespaces into their final resting place. The work got into motion circa sprint 18, and fabric was swiftly dealt with, but formattables proved more challenging. Finally, ten sprints later, this long running effort came unstuck when we tried to deal with the representation of paths (or "locations") in the new world because it wasn't merely just "moving types around"; the more the refactoring progressed, the more abstract it was becoming. For a flavour of just how abstract things are getting, have a read on Section "Add Relations Between Archetypes in the PMM" in sprint 26's release notes.
Ultimately, it became clear that we tried to bite more than we could chew. After all, in a completely data driven world, all of the assembly performed in order to generate a path is done by introspecting elements of the logical model, the physical meta-model (PMM) and the physical model (PM). This is extremely abstract work, where all that once were regular programming constructs have now been replaced by a data representation of some kind; and we had no way to validate any of these representations until we reached the final stage of assembling paths together, a sure recipe for failure. We struggled with this on the back-end of the last sprint and the start of this one, but then it suddenly dawned that we could perhaps move one step closer to the end destination without necessarily making the whole journey; going half-way or bridging the gap, if you will. The moment of enlightenment revealed by this sprint was to move the hard-coded concepts in formattables to the new world of transforms and logical/physical entities, without fully making them data-driven. Once we did that, we found we had something to validate against that was much more like-for-like, instead of the massive impedance mismatch we are dealing with at present.
So this sprint we moved the majority of types in formattables into their logical or physical locations. As the story title implies, the bulk of the work was connected to moving the locator class on both C# and C++ formattables. This class had a seemingly straightforward responsibility: to build relative and full paths in the physical domain. However, it was also closely intertwined with the old-world formatters and the generation of dependencies (such as the include directives). It was difficult to unpick all of these different strands that connected the locator to the old world, and encapsulate them all inside of a transform, making use only of data available in the physical meta model and physical model, but once we achieved that all was light.
There were lots of twists and turns, of course, and we did find some cases that do not fit terribly well the present design. For instance, we had assumed that there was a natural progression in terms of projections, i.e.:
- from an external representation;
- to the simplified internal representation in the codec model;
- to the projection into the logical model;
- to the projection into the physical model;
- to, ultimately, the projection into a technical space - i.e., code generation.
As it turns out, sometimes we need to peek into the logical model after the projection to the physical model has been performed, which is not quite so linear as we'd want. This may sound slightly confusing, given that the entire point of the LPS is to have a model that combines both the logical and physical dimensions. Indeed, it is so; but what we do not expect is to have to modify the logical dimension after it was constructed and projected into the physical domain. Sadly, this is the case when computing items that require lists of project items such build files. Problems such as this made it for a tricky journey, but we somehow managed to empty out the C++ formattables model to the last few remaining types - the helpers - which we will hopefully mop up next sprint. C# is not lagging far behind, but we decided to tackle them separately now.
Move stand-alone formattables to physical/logical models
Given that the locator story (above) became a bit of a mammoth - consuming 50% of the total ask - we thought we would separate any formattable types which were not directly related to locator into its own story. As it turns out there were still quite a few, but this story does not really add much to the narrative above given that the objectives were very much the same.
Create a video series on the formattables refactor
A lot of the work for the formattables refactor was captured in a series of coding videos. I guess you'd have to be a pretty ardent fan of Dogen to find these interesting, especially as it is an 18-part series, but if you are, you can finally binge. Mind you, the recording does not cover the entirety of the formattables work, for reasons we shall explain later; at around 15 hours long, it covers just about 30% of the overall time spent on these stories (~49 hours). Table 1 provides an exhaustive list of the videos, with a short description for each one; a link to the playlist itself is available below (c.f. Video 2).
Video 2: Playlist "MASD - Dogen Coding: Formatables Refactor".
With so much taped coding, we ended up penning a few reflections on the process. These are partially a rehashing of what we had already learned (c.f. Sprint 19, section "Recording of coding sessions"), but also contain some new insights. They can be summarised as follows:
- taped coding acts as a motivating factor, for some yet to be explained reason. It's not as if we have viewers or anything, but for some reason the neo-cortex seems to find it easier to get on with work if we think that we are recording. To be fair, we already experienced this with the MDE Papers, which had worked quite well in the past, though we lost the plot there a little bit of late.
- taped coding is great for thinking through a problem in terms of overall design. In fact, it's great if you try to explain the problem out loud in simple terms to a (largely imaginary) lay audience. You are forced to rethink the problem, and in many cases, it's easier to spot flaws with your reasoning as you start to describe it.
- taped coding is not ideal if you need to do "proper" programming, at least for me. This is because it's difficult to concentrate on coding if you are also describing what you are doing - or perhaps I just can't really multitask.
In general, we found that it's often good to do a video as we start a new task, describe the approach and get the task started; but as we get going, if we start to notice that progress is slow, we then tend to finish the video where we are and complete the task offline. The next video then recaps what was done, and begins a new task. Presumably this is not ideal for an audience that wants to experience the reality of development, but we haven't found a way to do this without degrading productivity to unacceptable levels.
| Video | Description |
|---|---|
| Part 1 | In this part we explain the rationale for the work and break it into small, self-contained stories. |
| Part 2 | In this part we read the project path properties from configuration. |
| Part 3 | In this part we attempt to tackle the locator directly, only to find out that there are other types which need to be cleaned up first before we can proceed. |
| Part 4 | In this part we finish the locator source code changes, only to find out that there are test failures. These then result in an investigation that takes us deep into the tracing subsystem. |
| Part 5 | In this part we finally manage to get the legacy locator to work off of the new meta-model properties, and all tests to go green. |
| Part 6 | Yet more work on formattables locator. |
| Part 7 | In this part we try to understand why the new transform is generating different paths from the old transform and fix a few of these cases. |
| Part 8 | In this part we continue investigating incorrect paths being produced by the new paths transform. |
| part 9 | In this part we finally replace the old way of computing the full path with the new (but still hacked) transform. |
| Part 10 | In this part we start to tackle the handling of inclusion directives. |
| Part 11 | In this video we try to implement the legacy dependencies transform, but bump into numerous problems. |
| Part 12 | More work in the inclusion dependencies transform. |
| Part 13 | In this part we finish copying across all functions from the types facet into the legacy inclusion dependencies transform. |
| Part 14 | In this part we start looking at the two remaining transforms in formatables. |
| Part 15 | In this video we first review the changes that were done offline to remove the C++ locator and then start to tackle the stand-alone formatable types in the C++ model. |
| Part 16 | In this part we start to tackle the streaming properties, only to find out it's not quite as trivial as we thought. |
| Part 17 | In this video we recap the work done on the streaming properties, and perform the refactor of the C++ standard. |
| Part 18 | In this video we tackle the C++ aspect properties. |
Table 1: Individual videos on the playlist for the formattables refactor.
Assorted smaller stories
Before we decided on the approach narrated above, we tried to continue to get the data-driven approach done. That resulted in a number of small stories that progressed the approach, but didn't get us very far:
- Directory names and postfixes are PMM properties: Work done to model directory names and file name postfixes correctly in the PMM. This was a very small clean-up effort, that sadly can only be validated when we start assembly paths properly within the PMM.
- Move
enabledandoverwriteintoenablement_properties: another very small tidy-up effort that improved the modeling around enablement related properties. - Tracing of orchestration chains is incorrect : whilst trying to debug a problem, we noticed that the tracing information was incorrect. This is mainly related to chains being reported as transforms and transforms using incorrect names due to copy-and-pasting errors.
- Add full and relative path processing to PM: we progressed this ever-so-slightly but we bumped into many problems so we ended up postponing this story for the next sprint.
- Create a factory transform for parts and archetype kinds: as with the previous story, we gave up on this one.
- Analysis on a formatables refactor: this was the analysis story that revealed the inadequacies of the present attempt of diving straight into a data-driven approach from the existing formattables code.
Presentation for APA
We were invited by the Association of Angolan Programmers (Associação dos Programadores Angolanos) to do a presentation regarding research. It is somewhat tangential to Dogen, in that we do not get into a lot of details with the code itself but it may still be of interest. However, the presentation is in Portuguese. A special shout out and thanks goes to Filipe Mulonde (twitter: @filipe_mulonde) and Alexandre Juca (twitter: @alexjucadev) for inviting me, organising the event and for their work in APA in general.
Video 3: Talk: "Pesquisa científica em Ciência da Computação" (Research in Computer Science).

Resourcing
Sadly, we did not improve our lot this sprint with regards to proper resource attribution. We created one massive story, the locator work, at 50%, and a smattering of smaller stories which are not very representative of the effort. In reality we should have created a number of much smaller stories around the locator work, which is really more of an epic than a story. However, we only realised the magnitude of the task when we were already well into it. At that point, we did split out the other formattable story, at 10% of the ask, but it was a bit too little too late to make amends. At any rate, 61% of the sprint was taken with this formattables effort, and around 18% or so went on the data-driven effort; on the whole, we spent close to 81% on coding tasks, which is pretty decent, particularly if we take into account our "media" commitments. These had a total cost of 8.1%, with the lion's share (6.1%) going towards the presentation for APA. Release notes (5.5%) and backlog grooming (4.7%) were not particularly expensive, which is always good to hear. However, what was not particularly brilliant was our utilisation rate, dwindling to 35% with a total of 42 elapsed days for this sprint. This was largely a function of busy work and personal life. Still, it was a massive increase over the previous sprint's 20%, so we are at least going on the right direction.

Figure 2: Cost of stories for sprint 28.
Roadmap
We actually made some changes to the roadmap this time round, instead of just forwarding all of the items by one sprint as we customarily do. It does see that we have five clear themes to work on at present so we made these into entries in the road map and assigned a sprint each. This is probably far too optimistic, but nonetheless the entire point of the roadmap is to give us a general direction of travel rather than oracular predictions on how long things will take - which we already know too well is a futile effort. What is not quite so cheerful is that the roadmap is already pointing out to March 2021 as the earliest, most optimistic date for completion, which is not reassuring.


Binaries
You can download binaries from either Bintray or GitHub, as per Table 1. All binaries are 64-bit. For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available in zip or tar.gz format.
| Operative System | Format | BinTray | GitHub |
|---|---|---|---|
| Linux Debian/Ubuntu | Deb | dogen_1.0.28_amd64-applications.deb | dogen_1.0.28_amd64-applications.deb |
| OSX | DMG | DOGEN-1.0.28-Darwin-x86_64.dmg | DOGEN-1.0.28-Darwin-x86_64.dmg |
| Windows | MSI | DOGEN-1.0.28-Windows-AMD64.msi | DOGEN-1.0.28-Windows-AMD64.msi |
Table 2: Binary packages for Dogen.
Note: The OSX and Linux binaries are not stripped at present and so are larger than they should be. We have an outstanding story to address this issue, but sadly CMake does not make this a trivial undertaking.
Next Sprint
The goals for the next sprint are:
- to finish formattables refactor;
- to start implement path and dependencies via PMM.
That's all for this release. Happy Modeling!