Dogen v1.0.23, "Docas de Moçamedes"
Docks in Moçamedes, Namibe, Angola. (C) 2016 Ampe Rogério - Rede Angola

Introduction
Welcome to the first release of Dogen under quarantine. I hope you have been able to stay home and stay safe, in what are very trying times for us all. This release is obviously unimportant in the grand scheme of things, but perhaps it can provide a momentary respite to those of us searching for something else to focus our attention on. The sprint itself was a rather positive one, if somewhat quiet on the user-facing front; of particular note is the fact that we have finally made major inroads on the fabled "generation" refactoring, which we shall cover at length. So get ready for some geeky MDE stories.
User Visible Changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. Since there were only a couple of minor user facing changes, we've used the video to chat about the internal work as well.
Video 1: Sprint 23 Demo.
Generate the MASD Palette
Whilst positive from an end-goal perspective, the growth of the logical model has had a big impact on the MASD palette, and we soon started to struggle to find colours for this zoo of new meta-model elements. Predictably, the more the model grew, the bigger the problem became and the direction of travel was more of the same. We don't have a lot of time for artistic reveries, so this sprint we felt enough's enough and took the first steps in automating the process. To our great astonishment, even something as deceptively simple as "finding decent colours" is a non-trivial question, for which there is published research. So we followed Voltaire's sound advice - le mieux est l'ennemi du bien and all that - and went for the simplest possible approach that could get us moving in the right direction.

Figure 1: Fragment of the old MASD palette, with manually crafted colours.
A trivial new script to generate colours was created. It is based on the above-linked Seaborn python library, as it appears to provide sets of palettes for these kinds of use cases. We are yet to master the technicalities of the library, but at this point we can at least generate groups of colours that are vaguely related. This is clearly only the beginning of the process, both in terms of joining the dots of the scripts (at present you need to manually copy the new palettes into the colouring script) but also as far as finding the right Seaborn palettes to use; as you can see from Figure 2, the new MASD palette has far too many similar colours, making it difficult to visually differentiate meta-model elements. More exploration of Seaborn - and colouring in general - is required.

Figure 2: Fragment of the new MASD palette, with colours generated by a script.
Add org-mode output to dumpspecs
The previous sprint saw the addition of a new command to the Dogen command line tool called dumpspecs:
$ ./dogen.cli --help | tail -n 7
Commands:
generate Generates source code from input models.
convert Converts a model from one codec to another.
dumpspecs Dumps all specs for Dogen.
For command specific options, type <command> --help.
At inception,dumpspecs only supported the plain reporting style, but it became obvious that it could also benefit from providing org-mode output. For this, a new command line option was added: --reporting-style.
$ ./dogen.cli dumpspecs --help
Dogen is a Model Driven Engineering tool that processes models encoded in supported codecs.
Dogen is created by the MASD project.
Displaying options specific to the dumpspecs command.
For global options, type --help.
Dumping specs:
--reporting-style arg Format to use for dumping specs. Valid values: plain,
org-mode. Defaults to org-mode.
The output can be saved to a file for visualisation and further processing:
$ ./dogen.cli dumpspecs --reporting-style org-mode > specs.org
The resulting file can be opened on any editor that supports org-mode, such as Emacs, Vim or Visual Studio Code. Figure 3 provides an example of visualising the output in Emacs.

Figure 3: Using Emacs to visualise the output of dumpspecs in org-mode format.
Development Matters
This section cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, if you are interested on all the gory details of the work carried out this sprint, please see the sprint log.
Milestones
The 11,000th commit was made to the Dogen GitHub repository during this release.

Figure 4: 11,000th commit for Dogen on GitHub.
The Dogen build is now completely warning and error free, across all supported configurations - pleasing to the eye for the OCD'ers amongst us. Of course, now the valgrind defects on the nightly become even more visible, so we'll have to sort those out soon.
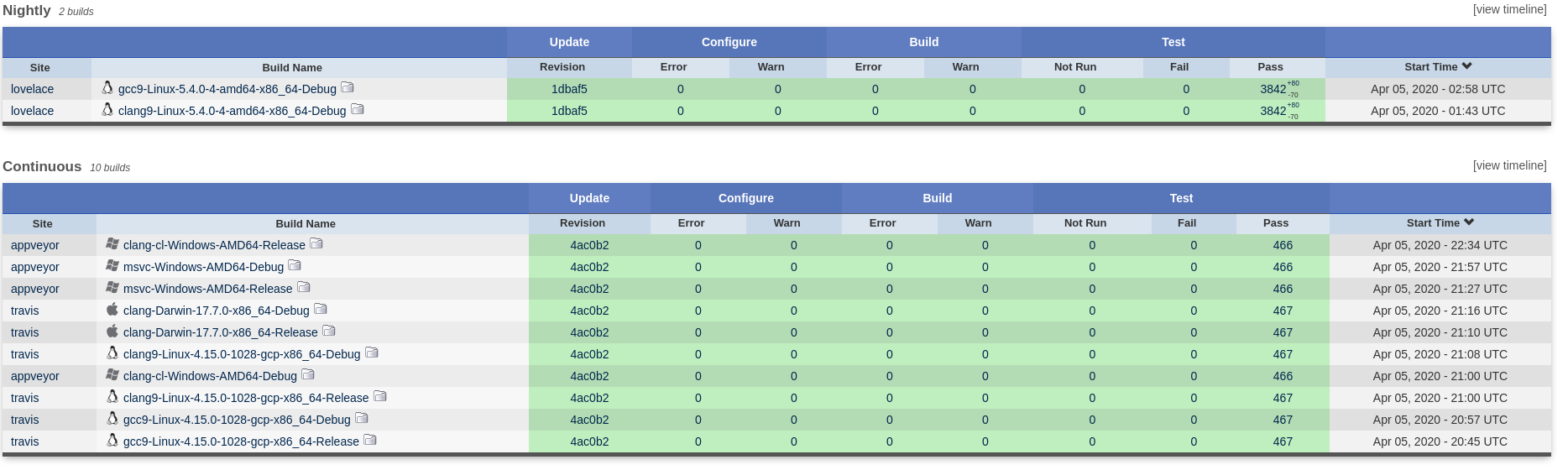
Figure 5: Dogen's CI is finally free of warnings.
Significant Internal Stories
The sprint was dominated by smattering of small and medium-sized stories that, collectively, made up the "generation" refactor work. We've grouped the most significant of them into a handful of "themes", allowing us to cover the refactor in some detail. To be fair, it is difficult to provide all of the required context in order to fully understand the rationale for the work, but we tried our best.
Rename assets to the logical model
One change that was trivial with regards to resourcing but huge in conceptual terms was the rename of assets into the logical model. We'll talk more about the importance of this change in the next section - in the context of the logical-physical space - but here I just want to reflect a little on the historic evolution of this model, as depicted on Table 1.
| Release | Date | Name | Description | Problem |
|---|---|---|---|---|
| v0.0.20 | 16 Nov 2012 | sml |
The Simplified Modeling Language. | It was never really a "language". |
| v0.0.71 | 10 Aug 2015 | tack |
Random sewing term. | No one knew what it meant. |
| v0.0.72 | 21 Oct 2015 | yarn |
Slightly less random sewing term. | Term already used by a popular project; Dogen moves away from sewing terms. |
| v1.0.07 | 1 Jan 2018 | modeling |
Main point of the model. | Too generic a term; used everywhere in both Dogen and MDE. |
| v1.0.10 | 29 Oct 2018 | coding |
Name reflects entities better. | Model is not just about coding elements. |
| v1.0.18 | 2 Jun 2019 | assets |
Literature seems to imply this is a better name. | Name is somewhat vague; anything can be an asset. |
| v1.0.23 | 6 Apr 2020 | logical |
Rise of the logical-physical space and associated conceptual model. | None yet. |
Table 1: Historic evolution of the name of the model with the core Dogen entities.
What this cadence of name changes reveals is a desperate hunt to understand the role of this model in the domain. We are now hoping that it has reached its final resting place, but we'll only know for sure when we complete the write up of the MASD conceptual model.
Towards a physical Model
The processing pipeline for Dogen remains largely unchanged since its early days. Figure 6 is a diagram from sprint 12 describing the pipeline and associated models; other than new names, it is largely applicable to the code as it stands today. However, as we've already hinted, what has changed in quite dramatic fashion is our understanding of the conceptual role of these models. Over time, a picture of a sparse logical-physical space emerged; as elements travel through the pipeline, they are also traveling through this space, transformed by projections that are parameterised by variability, and ultimately materializing as fully-formed artefacts, ready to be written to the filesystem. Beneath those small name changes lies a leap in conceptual understanding of the domain, and posts such as the The Refactoring Quagmire give you a feel for just how long and windy the road to enlightenment has been.

Figure 6: Dogen's processing pipeline circa sprint 12.
For the last few sprints, we have been trying to get the code to behave according to this newly found knowledge. The previous sprint saw us transition the variability model to this brave new world, and this sprint we have turned our attention to the logical and physical models. Whilst the logical model work was just a trivial rename (narrated above), the physical model was a much bigger task than any thus far because all we had was an assortment of unrelated models, very far away from their desired state.
Our starting salvo was composed of three distinct lines of attack:
- Refactor the
archetypesmodelet. The first moment of enlightenment was when we realised that the smallarchetypesmodel was nothing but a disguised meta-model of the physical dimension for the logical-physical space. In effect, it is a metaphysical model though such a name (and associated pun) would probably not be viewed well in academic circles, so we had to refrain from using it. Nonetheless, we took the existingarchetypesmodel and refactored it into the core of thephysicalmodel. Types such asarchetype_locationbecame the basis of the physical meta-model, populated with entities such asbackend,facetandkernel. - Merge the
extractionmodel into thephysicalmodel. More surprisingly, we eventually realised that theextractionmodel was actually representing instances of the physical meta-model, and as such should be merged into it. It was rather difficult to wrap our heads around this concept; to do so, we had to let go of the idea thatartefactsare representations of files in memory, and instead started to view them as elements travelling in the logical-physical space towards their ultimate destination. After a great many whiteboard sessions, these ideas were eventually clarified and then much of the conceptual design fell into place. - Move physical aspects in the
logicalmodel to thephysicalmodel. The last step of our three-pronged approach was to figure out that the proliferation of types with names such asartefact_properties,enablement_propertiesand the like was just a leakage of physical concepts into the logical model. This happened because we did not have a strong conceptual framework, and so never quite knew where to place things. As the physical model started to take shape with the two changes above, we finally resolved this long standing problem, and it suddenly became clear that most of the physical properties we had been associating with logical elements were more adequately modeled as part of the artefacts themselves. This then allows us to cleanly separate thelogicalandphysicalmodels, very much in keeping with the decoupling performed last sprint for thevariabilityandphysicalmodels (the latter known then asarchetypes, of course). The sprint saw us modeling the required types correctly in thephysicalmodel, but the entire tidy-up will be long in completing as the code in question is very fiddly.
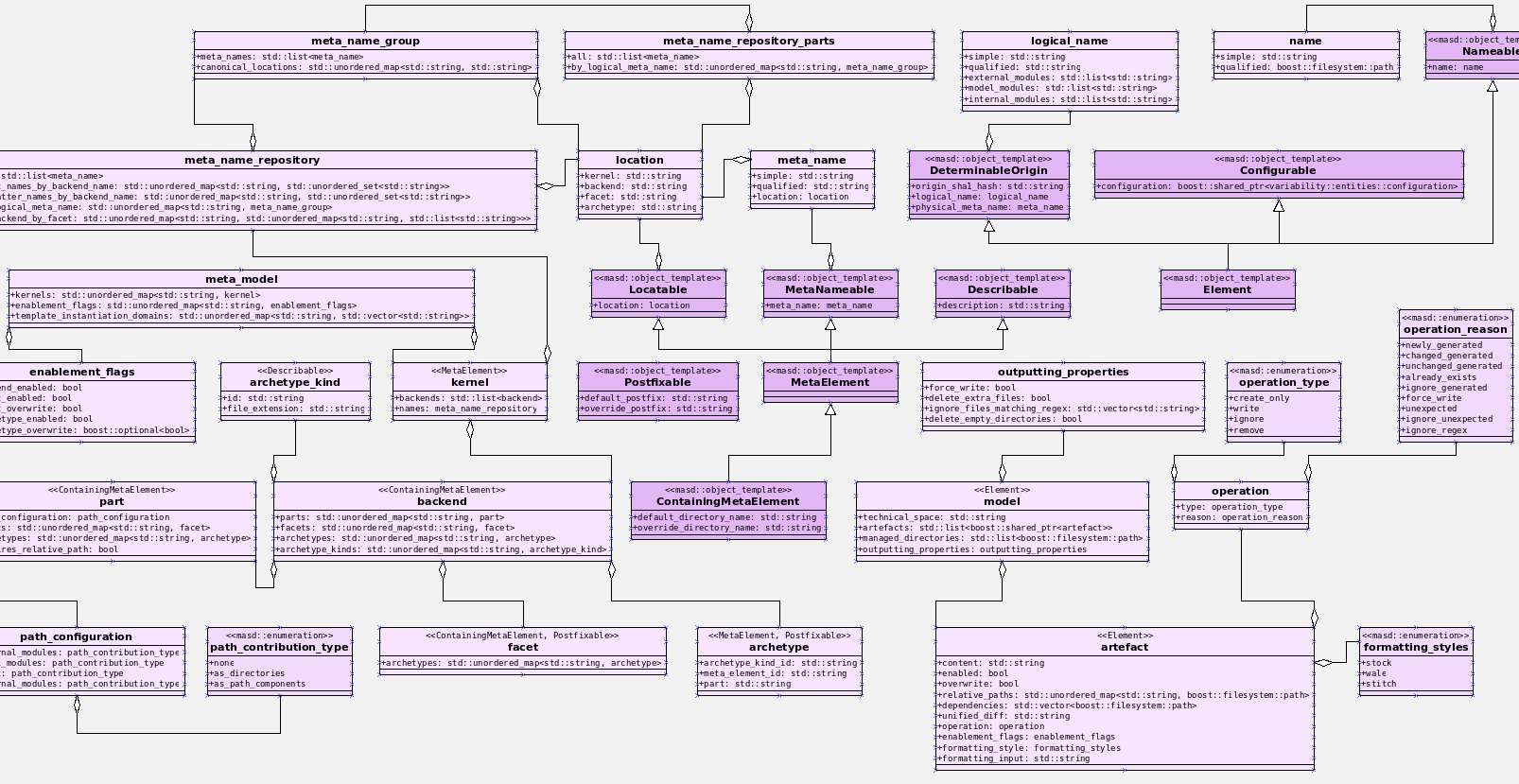
Figure 7: Entities in the physical model.
Once all of these changes were in, we ended up with a physical model with a more coherent look and feel, as Figure 7 atestares. However, we were not quite done. We then turned our attention to one of the biggest challenges within the physical model. For reasons that have been lost in the mists of time, very early on in Dogen's life we decided that all names within a location had to be qualified. This is best illustrated by means of an example. Take the archetype masd.cpp.types.class_header, responsible for creating header files for classes. Its physical location was previously as follows:
- kernel:
masd - backend:
masd.cpp - facet:
masd.cpp.types - archetype:
masd.cpp.types.class_header
This was a remarkably bad idea, with all sorts of consequences and none of them good - not least of which complicating things significantly when trying to come up with a unified approach to file paths processing. So we had to very carefully change the code to use simple names as it should have done in the first place, i.e.:
- kernel:
masd - backend:
cpp - facet:
types - archetype:
class_header
Because so much of the code base depended on the fully qualified name - think formatter registrations, binding of logical model elements, etc - it was an uphill battle to get it to comply with this change. In fact, it was by far the most expensive story of the entire sprint. Fortunately we have tests that give us some modicum of confidence that we have not broken the world when making such fundamental changes, but nonetheless it was grueling work.
Rename the generation Models to m2t
It has long been understood that "formatters" are nothing but model-to-text (M2T) transforms, as per standard MDE terminology. With this sprint, we finally had the time to rename the generation models to their rightful name:
generationbecamem2tgeneration.cppbecamem2t.cppgeneration.csharpbecamem2t.csharp
In addition, as per the previous story, the new role of the m2t model is now to perform the expansion of the logical model into the physical dimension of the logical-physical space. With this sprint we begun this exercise, but sadly only scratched the surface as we ran out of time. Nonetheless, the direction of travel seems clear, and much of the code that is at present duplicated between m2t.cpp and m2t.csharp should find its new home within m2t, in a generalised form that makes use of the shiny new physical meta-model.
Rename the meta-model Namespace to entities
One of the terms that can become very confusing very fast is meta-model. When you are thick in the domain of MDE, pretty much everything you touch is a meta-something, so much so that calling things "meta-models" should be done sparingly and only when it can provide some form of enlightenment to the reader. So it was that we decided to deprecate the widely used namespace meta-model in favour of the much blander entities.
Resourcing
With an astonishing utilisation rate of 66%, this sprint was extremely efficient. Perhaps a tad too efficient, even; next sprint we may need to lower the utilisation rate back closer to 50%, in order to ensure we get adequate rest. We've also managed to focus 80% of the total ask on stories directly related to the sprint mission. Of these, the flattening of the physical names completely dominated the work (over 25%), followed by a smattering of smaller stories. Outside of the sprint's mission, we spent a bit over 17% on process, with 10% on release notes and demo - still a tad high, but manageable - and the rest on maintaining the sprint and product backlog. The small crumbs were spent on "vanity" infrastructure projects: adding support for clang 10 (1%) - which brought noticeable benefits because clangd, as always, has improved in leaps and bounds - and sorting out some rather annoying warnings on Windows' clang-cl (1.3%).

Figure 8: Cost of stories for sprint 22.
Roadmap
We've updated the roadmap with the big themes we envision as being key to the release of Dogen v2. As always, it must be taken with a huge grain of salt, but still there is something very satisfying about seeing the light at the end of the tunnel.


Binaries
You can download binaries from either Bintray or GitHub, as per Table 2. All binaries are 64-bit. For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available in zip or tar.gz format.
| Operative System | Format | BinTray | GitHub |
|---|---|---|---|
| Linux Debian/Ubuntu | Deb | dogen_1.0.23_amd64-applications.deb | dogen_1.0.23_amd64-applications.deb |
| OSX | DMG | DOGEN-1.0.23-Darwin-x86_64.dmg | DOGEN-1.0.23-Darwin-x86_64.dmg |
| Windows | MSI | DOGEN-1.0.23-Windows-AMD64.msi | DOGEN-1.0.23-Windows-AMD64.msi |
Table 2: Binary packages for Dogen.
Note: The OSX and Linux binaries are not stripped at present and so are larger than they should be. We have an outstanding story to address this issue, but sadly CMake does not make this a trivial undertaking.
Next Sprint
We shall continue work on the "generation" refactor - a name that is now not quite as apt given all the model renaming. We are hopeful - but not too hopeful - of completing this work next sprint. Famous last words.
That's all for this release. Happy Modeling!