[8주차](박준영, 김수환, 오형석) #11
Comments
토비의 스프링 7장 스프링 핵심 기술의 응용1️⃣ DI를 이용해 다양한 구현 방법 적용하기운영 중인 시스템에서 사용하는 정보를 실시간으로 변경하는 작업을 만들 때, 가장 먼저 고려해야 할 사항은 동시성 문제다. 1. ConcurrentHashMap지금까지는 JDK의 HashMap을 사용해왔다. 하지만 HashMap의 경우 멀티 스레드 환경에서 동시에 수정을 시도하거나, 수정과 읽기를 동시에 요청하는 경우 예상치 못한 결과가 발생할 수 있다.
이러한 이유로 어느 정도 안전하면서 성능이 보장되는 동기화된 HashMap으로 이용하기에 적당하다. 하지만 동시성에 대한 부분을 테스트하기엔 간단하지 않다. 2. 내장형 데이터베이스
그렇다고 해서 고작 DAO가 사용할 SQL을 저장하고 관리할 목적으로 별도의 DB를 구성하면 주객전도가 발생하는 상황이다.
내장형 DB는 데이터가 메모리에 저장되기 때문에 IO로 인해 발생하는 부하가 적어서 성능이 뛰어나다. 자바에서는 Derby, HSQL, H2의 내장형 DB가 널리 사용된다. 왜냐하면 모두 JDBC 드라이버를 제공하고 표준 DB와 호환되는 기능을 제공하기 때문에 JDBC 프로그래밍 모델을 그대로 따라서 사용할 수 있다. 특별한 기능으로는 내장형 DB는 애플리케이션 안에서 직접 DB 종료 요청을 할 수 있어야 한다. new EmbeddedDatabaseBuilder()
.setType(내장형 DB 종류)
.addScript(초기화에 사용할 DB 스크립트의 리소스 )
...
.build();
3. 트랜잭션 적용내장형 DB를 통해 조회가 빈번하게 일어나는 중에도 데이터가 깨지는 일 없이 SQL을 수정하도록 보장했다. 하나의 SQL을 수정할 때는 문제가 없지만, 만약 여러 개의 SQL을 한 번에 수정해야 하는 경우에는 심각한 문제가 발생할 수 있다. 한 번에 여러 개의 SQL을 수정하는 이유로는, SQL들이 서로 관련이 있을 가능성이 크다. 비즈니스 로직이 변경되었다면, 그에 영향을 받는 모든 SQl이 변경돼야 하기 때문이다. HashMap과 같은 컬렉션은 트랜잭션 개념을 적용하기 매우 힘들다. 여러 개의 엘리먼트를 트랜잭션과 같은 원자성이 보장된 상태에서 변경하려면 매우 복잡한 과정이 필요하기 때문이다. 기존 updateSql()
public class EmbeddedDbSqlRegistry implements UpdatableSqlRegistry {
SimpleJdbcTemplate jdbc;
public void setDataSource(DataSource dataSource) {
jdbc = new SimpleJdbcTemplate(dataSource); // 인터페이스 분리 원칙을 지키기 위해 DataSource를 주입
}
public void updateSql(Map<String, String> sqlmap) throws SqlUpdateFailureException {
for (Map.Entry<String, String> entry : sqlmap.entrySet()) {
updateSql(entry.getKey(), entry.getValue());
}
}
}트랜잭션 테스트
public class EmbeddedDbSqlRegistryTest extends AbstractUpdatableSqlRegitstryTest {
// …
@Test
public void transactionlUpdate(){
checkFind(“SQL1”,”SQL2”,”SQL3”);
// 초기상태 확인
Map<String, String> sqlmap = new HashMap<String,String>();
sqlmap.put(“KEY1”,”Modified1”);
sqlmap.put(“KEY9999!@#$”,”Modified9999”);
// 존재하지 않는 키를 수정하도록 하면 예외가 발생할 것이다/
// 트랜잭션 테스트를 위해 일부러 실패하도록 설정했다. 롤백을 체크하기 위한 테스트코드.
try{
sqlRegistry.updateSql(sqlmap);
fail();
}
catch(SqlUpdateFailureException e){}
checkFind(“SQL1”,”SQL2”,”SQL3”); // 초기상태와 동일한지 검증한다.
}
}public class EmbeddedDbSqlRegistry implements UpdateSqlRegistry {
SimpleJdbcTemplate jdbc;
TransactionTemplate transactionTemplate;
// JdbcTemplate과 트랜잭션을 동기화해주는 트랜잭션 템플릿. 멀티 스레드 환경에서 공유 가능.
public void setDataSource(DataSource dataSource) {
jdbc = new SimpleJdbcTemplate(dataSource);
transactionTemplate = new TransactionTemplate(new DataSourceTransactionManager(dataSource));
// dataSource로 TransactionManager를 만들고 이를 이용해 TransactionTemplate을 생성한다.
}
// 익명 내부 클래스로 만들어지는 콜백 오브젝트 안에서 사용되기 때문에 final로 선언
public void updateSql(final Map<String, String> sqlmap) throws SqlUpdateFailureException {
transactionTemplate.execute(new TransactionCallbackWithoutResult() {
protected void doInTransactionWithoutResult(TransactionStatus status) {
//트랜잭션 템플릿이 만드는 트랜잭션 경계 안에서 동작할 코드를 콜백 형태로 만들고
// TransactionTemplate의 excute() 메서드에 전달
for (Map.Entry<String, String> entry : sqlmap.entrySet()) {
updateSql(entry.getKey(), entry.getValue());
}
}
});
}
}2️⃣ 스프링 3.1의 DI스프링이 등장한 이후 많은 변화를 겪었다. 하지만 스프링이 근본적으로 지지하는, 객체지향 언어인 자바의 특징과 장점을 극대화하는 프로그래밍 스타일과 이를 지원하는 도구로서의 정체성은 변하지 않았다. 1. 애노테이션의 메타정보 활용자바는 소스코드가 컴파일된 후 클래스 파일에 저장됐다가, JVM에 의해 메모리로 로딩되어 실행된다. 그런데 때로는 자바 코드가 실행되는 것이 목적이 아니라 다른 자바 코드에 의해 데이터처럼 취급되기도 한다. 리플렉션 API가 본래 목적보다 자바 코드의 메타 정보를 데이터로 활용하는 스타일의 프로그래밍 방식에 더 많이 활용되고 있다.
애노테이션 자체가 클래스의 타입에 영향을 주지도 못하고, 일반 코드에서 활용되지 못한다. 그럼에도 애노테이션을 이용하는 표준 기술과 프레임워크가 빠르게 증가했다. @Special
public class MyClass{
...
}
원한다면 클래스의 필드나 메서드 구성도 확인이 가능하다. 단순한 애노테이션 하나를 추가하는 것만으로, 다양한 정보를 얻어낼 수 있다. 리팩토링을 할 때도 차이점이 있다. 리팩토링 중 MyClass의 패키지를 변경하거나 클래스 이름을 바꿨다면 IDE를 활용하여 간단히 이름이나 위치를 바꾸는 리팩토링을 할 수 있다. 반면에, XML은 어느 환경에서나 손쉽게 편집이 가능하고, 내용을 변경하더라도 다시 빌드를 할 필요가 없지만, 애노테이션은 자바 코드에 존재하므로 변경할 때마다 매번 클래스를 새로 컴파일해야 한다. 2. 정책과 관례를 이용한 프로그래밍애너테이션 같은 메타정보를 활용하는 프로그래밍 방식은 코드를 이용해 명시적으로 동작 내용을 기술하는 대신 코드 없이도 미리 약속한 규칙 또는 관례를 따라서 프로그램이 동작하도록 만드는 프로그래밍 스타일을 적극적으로 포용해왔다.
@ContextConfiguration(locations="/test-applicationContext.xml")
@ContextConfiguration(classes=TestApplicationContext.class)
XML로 정의한 transactionManager 빈
<bean id="transactionManager"
class ="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
자바 코드로 정의한 transactionManager 빈
@Bean
public PlaformTransactionManager transactionManager(){
DataSourceTransactionManager tm = new DataSourceTransactionManager();
tm.setDataSource(dataSource());
return tm;
}
@Component
public @interface SomeAnnotation{
...
}
@SomeAnnotation
public class SomeClass{
...
}
지금껏 책을 읽으며 작성해온 코드들은 애플리케이션이 바르게 동작하는 데 필요한 DI 정보와 테스트를 수행하기 위해 만든 DI 정보가 하나의 파일 안에 혼재해 있다. @ContextConfiguration(classes={TestAppContext.class, AppContext.class})
public class UserDaoTest{
...
}
@ContextConfiguration(classes=AppContext.class)
public class UserDao{
...
}그다음으로 SQL 서비스와 관련된 빈들을 분리해보자. @Configuration
public class SqlServiceContext{
...
}
@Configuration
@EnableTransactionManagement
@ComponentScan(basePackages="~~")
@Import(SqlServiceContext)
public class AppContext{
...
}이러한 방식으로 AppContext가 메인 설정 정보가 되고, SqlServiceContex는 보조 설정 정보로 사용할 수 있다.
테스트 환경과 운영 환경에서 다른 빈 정의가 필요한 경우가 있다. 양쪽에 모두 필요하면서 내용만 다른 것들은 설정 정보를 변경하고 조합하는 것 만으로는 한계가 있다. 실행 환경에 따라 빈 구성이 달라지는 내용을 프로파일로 정의해서 만들어두고, 실행 시점에 어떤 프로파일의 빈 설정을 사용할지 지정하는 것이다. 운영 환경에서만 필요한 빈을 담은 빈 설정 클래스
@Configuration
@Profile("test")
public class TestAppContext{
...
}
@Configuration
@Profile("production")
public class ProductionAppContext {
...
}
@Configuration
@EnableTransactionManagement
@ComponentScan(basePackages="~~~")
@Import({SqlServiceContext.class, TestAppContext.class, ProductionAppContext.class})
public class AppContext {
...
}
@RunWith(SpringJUnit4ClassRunner.class)
@ActiveProfiles("test") // 프로파일 사용
@ContextConfiguration(classes=AppContext.class)
public class UserServiceTest {
...
}test 프로파일이 지정된 TestAppContext의 빈 설정은 포함되고, ProductionAppContext의 빈 설정은 production 프로파일로 선언되어 있어 무시된다. |
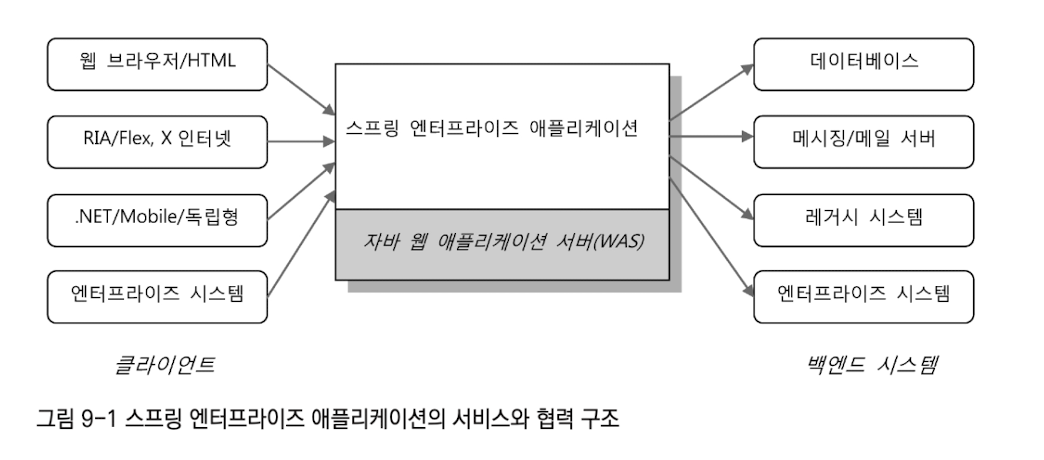
[9장] 스프링 프로젝트 시작하기9장에서는 스프링을 이용해 애플리케이션을 만든다고 할 때 알아야하는 배경지식에 대해 다룬다. 자바 엔터프라이즈 플랫폼과 스프링 애플리케이션스프링은 주로 자바 엔터프라이즈 환경에서 동작하는 애플리케이션을 개발하는데에 사용된다. 즉, 클라이언트의 요청을 받아 작업을 수행하고 그 결과를 반환하는 형식으로 서비스를 제공한다. 클라이언트와 백엔드 시스템스프링이 사용되는 애플리케이션의 기본구조
클라이언트가 웹 브라우저여야 하는 것도 아니며 백엔드 시스템은 DB를 이용해야 하는 것만은 아니다. 자바 서버가 받아들일수 있는 방식으로 요청을 보내기만 한다면 어떤 종류의 클라이언트이든 상관없다. 스프링 엔터프라이즈 애플리케이션은 DB는 물론 메시징 서버, 메일 서버 등 자바가 지원하는 접속방식을 제공하기만 하는 시스템이면 백엔드 시스템으로 이용할 수 있다. 애플리케이션 서버스프링으로 만든 애플리케이션을 자바 서버환경에 배포하려면 JavaEE 서버가 필요하다.
경량급 WAS/ 서블릿 컨테이너
WAS
스프링소스 tcServer
스프링 애플리케이션의 배포 단위독립 웹 모듈
엔터프라이즈 애플리케이션
JAR, WAR, EAR 파일의 가장 큰 차이점은 서로 다른 환경을 대상으로한다는 점이다.
백그라운드 서비스 모듈
개발 도구와 환경스프링3.0 을 적용하기 위해서는 jdk6.0, 적어도 5.0이상을 사용해야한다. 라이브러리 관리와 빌드 툴
리패키징
라이브러리 선정프로젝트 폴더 구조와 라이브러리 선정을 스스로 결정해야 하는 상황이라면 신경써야 할게 많다.
스프링 모듈
라이브러리
Maven & POM
Gradle
Build라는 동적인 요소를 XML로 정의하기에는 어려운 부분이 많다.
애플리케이션 아키텍처아키텍처는 내부 구성요소들이 어떤 책임을 갖고 어떤 방식으로 서로 관계를 맺고 동작하는지 규정하는 것이라고 할 수 있다. 계층형 아키텍처성격이 다른 모듈이 강하게 결합되어 한데 모여 있으면 한 가지 이유로 변경이 일어날 때 그와 상관없는 요소도 함께 영향을 받게 된다. 아키텍처와 관심의 분리이런 원리는 아키텍처 레벨에서 좀 더 큰 단위에 대해서도 동일하게 적용할 수 있다.
이렇게 성격이 다른 것은 아키텍처 레벨에서 분리해주는 게 좋다.
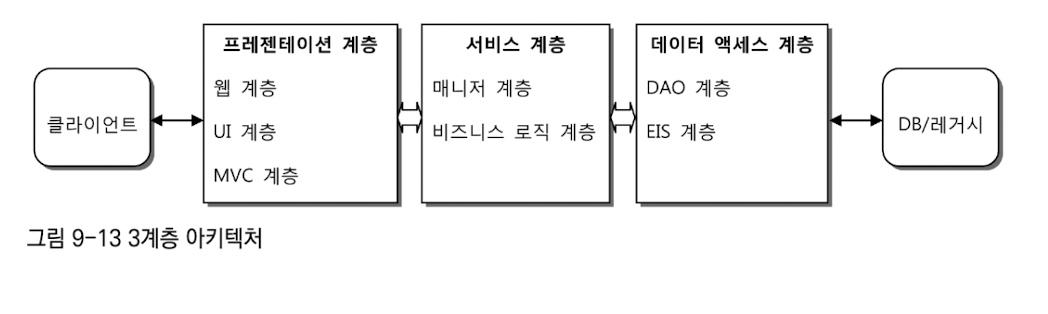
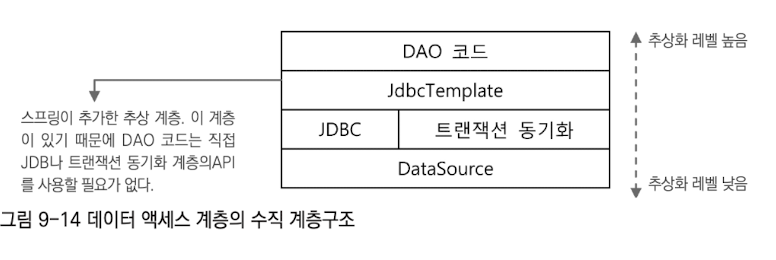
보통 웹 기반의 엔터프라이즈 애플리케이션은 일반적으로 세 개의 계층을 갖는다고해서 3계층 애플리케이션이라고 한다. 3계층 아키텍처와 수직 계층
데이터 액세스 계층
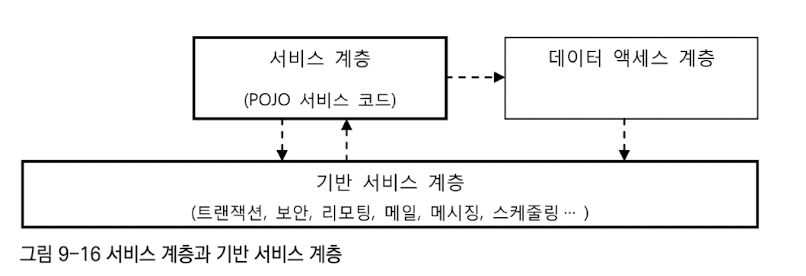
서비스 계층잘 만들어진 스프링 애플리케이션의 서비스 계층 클래스는 이상적인 POJO로 작성된다.
프레젠테이션 계층프레젠테이션 계층은 가장 복잡한 계층이다. 프레젠테이션 계층은 매우 다양한 기술과 프레임워크의 조합을 가질 수 있다.
프레젠테이션 계층은 다른 계층과 달리 클라이언트까지 그 범위를 확장될 수도 있다.
애플리케이션 정보 아키텍처엔터프라이즈 시스템은 본질적으로 동시에 많은 작업이 빠르게 수행돼야 하는 시스템이다.
DB/SQL 중심의 로직 구현 방식데이터 중심구조의 특징은 하나의 업무 트랜잭션에 모든 계층의 코드가 종속되는 경향이 있다는 점이다.
이런 식의 개발 방법과 아키텍처는 예전 엔터프라이즈 시스템에서 흔히 발견할 수 있다.
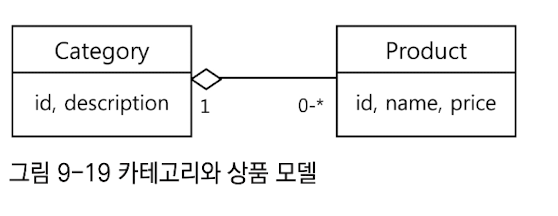
오브젝트 중심 아키텍처오브젝트 중심 아키텍처가 데이터 중심 아키텍처와 다른 특징은 도메인 모델을 반영하는 오브젝트 구조를 만들어두고 그것을 각 계층 사이에서 정보를 전송하는 데 사용한다는 것이다. 오브젝트 중심 아키텍처는 객체지향 분석과 모델링의 결과로 나오는 도메인 모델을 오브젝트 모델로 활용한다. 데이터와 오브젝트카테고리와 상품이라는 두가지 엔티티가 나오는 상황을 예를 들어 보자. 조건에 맞는 모든 카테고리와 상품 정보를 가져와서 화면에 출력하는 기능을 만든다고 할때, 데이터 중심 아키텍처에서는 SQL과 DB관점에서 생각한다. JOIN문을 활용해 2차원 구조의 정보를 만들어 두 정보를 조합 할 수 있다. SELECT c.categoryid , c.description, p.productid, p.name, p.price
FROM product p
JOIN category c on p.categoryid= c.categoryid맵에 필드 이름과 값을 담아 결과를 저장할 수 있다. while(rs.next()){
Map<String,Object> resMap = new HashMap<String, Object>();
resMap.put(“categoryid”,rs.getString(1));
resMap.put(“description“, rs.getString(2));
…
list.add(resMap);
}서비스 계층에 전달되는 것은 데이터 중심 아키텍처 vs 오브젝트 중심 아키텍처결과를 사용하는 서비스 계층이나 프레젠테이션 계층의 코드에서는 DAO메소드에서 두 개의 테이블을 DAO에서 SQL을 변경하거나 필드 개수나 순서, 이름을 바꾼다면 서비스 계층과 프레젠테이션 계층의 코드도 같이 변경돼야 한다.
반면에 오브젝트 중심 아키텍처 에서는 애플리케이션에서 사용되는 정보가 도메인 모델의 구조를 반영해 만들어진 객체 안에 담긴다. 도메인 모델은 애플리케이션 전 계층에서 동일한 의미를 갖는다.
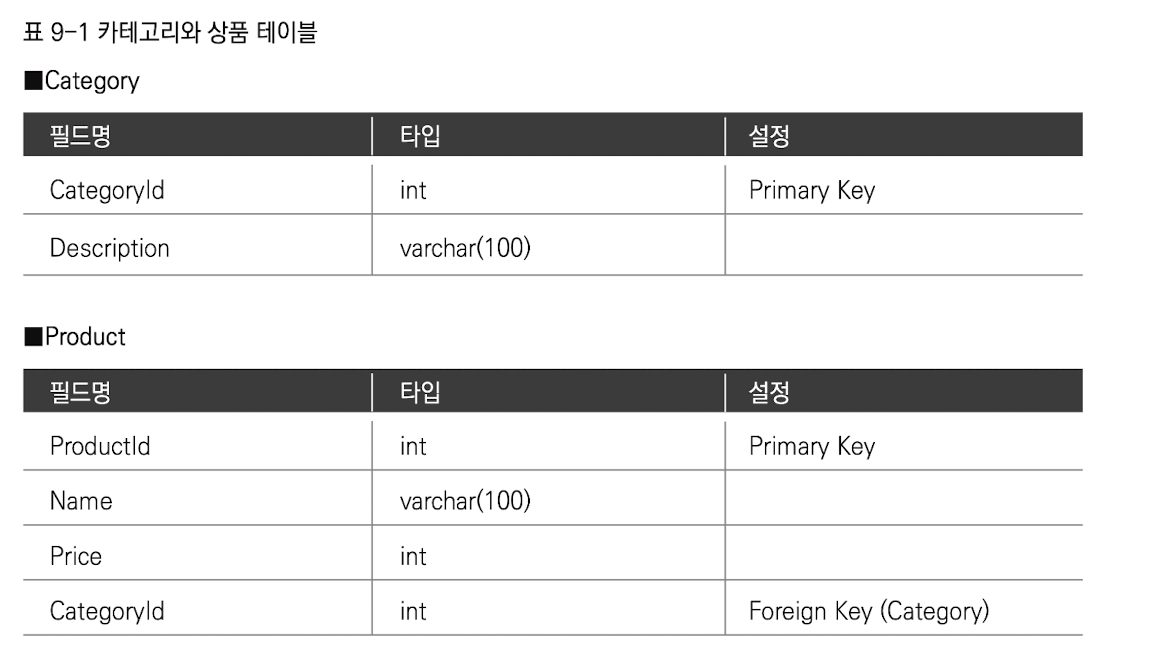
도메인 오브젝트 public class Category{
int categoryid;
String description;
Set<Product> products; // 여러개의 Product를 참조하고있는 컬렉션을 가질수 있다.
…
}
public class Product{
int productid;
Stringname;
int price;
Category category; // 1개의 Category를 가리키는 레퍼런스를 직접 갖고 있다.
…
}자바의 레퍼런스 개념은 상호 참조가 가능 하게 한다.
도메인 오브젝트의 문제점최적화된 SQL을 매번 만들어 사용하는 경우에 비해 성능 면에서 조금은 손해를 감수해야 할 수도 있다.
지연된 로딩(lazy loading) 기법일단 최소한의 오브젝트 정보만 읽어두고 관계하고 있는 오브젝트가 필요한 경우에만 다이내믹하게 DB에서 다시 읽어올 수 있다.
RDB 매핑(ORM) 기술
도메인 오브젝트를 사용하는 오브젝트 중심 아키텍처에서는 가능하다면 ORM과 같은 오브젝트 중심 데이터 액세스 기술을 사용하는 것을 권장한다.
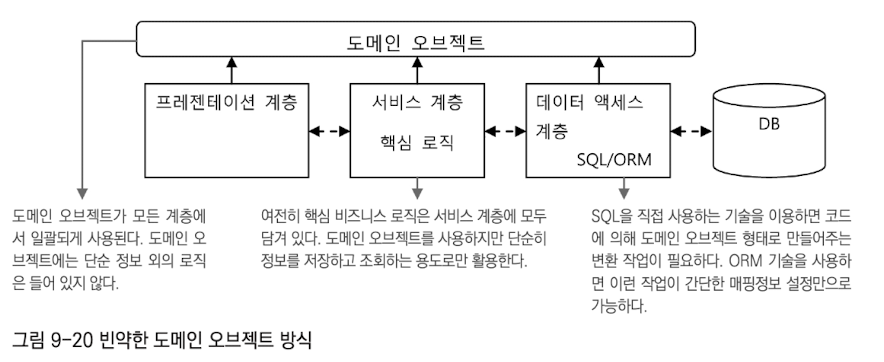
빈약한 도메인 오브젝트도메인 오브젝트에 정보만 담겨 있고, 정보를 활용하는 기능이 없다면 이는 온전한 오브젝트라고 보기 힘들다.
도메인 오브젝트에 넣을 수 있는 기능
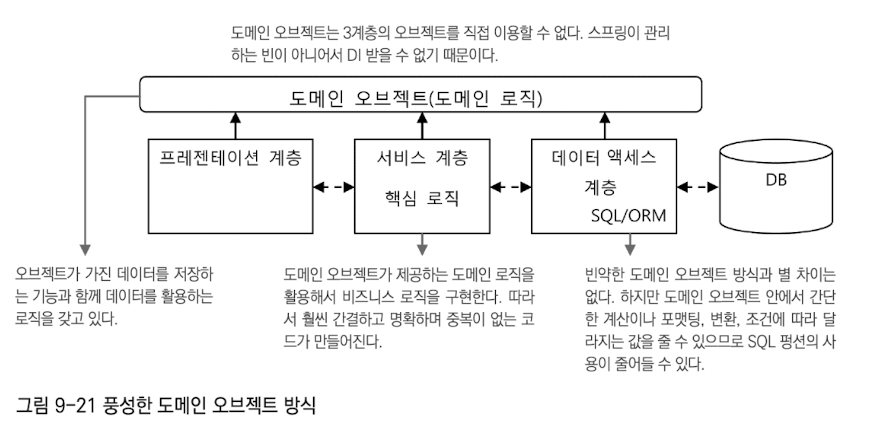
풍성한 도메인 오브젝트 방식빈약한 도메인 오브젝트의 단점을 극복하고 도메인 오브젝트의 객체지향적인 특징을 잘 사용할 수 있도록 개선
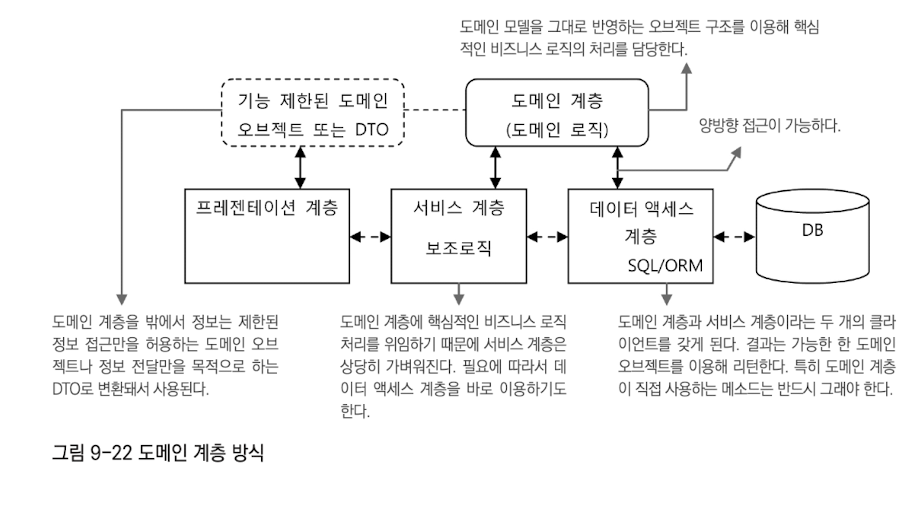
도메인 계층 방식도메인 계층의 역할과 비중을 극대화하려다 보면 기존의 풍성한 도메인 오브젝트의 방식으로는 만족할 수 없다. 도메인 객체가 기존 3계층과 같은 레벨로 격상되어 하나의 계층을 이루게 하는 것이 도메인 계층 방식이다. 도메인 객체 독립된 계층을 다음과 같은 특징을 갖게 된다.
스프링이 관리하지 않는 도메인 오브젝트에 DI를 적용하기 위해서는 AOP가 필요하다.
도메인 오브젝트가 계층을 이루기 전에는 모든 계층에 걸쳐 사용되는 일종의 정보전달 도구 같은 역할을 했다. 도메인 오브젝트가 도메인 계층을 벗어나서도 사용되게 할지 말지 결정해야 한다. 여전히 모든 계층에서 도메인 오브젝트를 사용한다.
도메인 오브젝트는 도메인 계층을 벗어나지 못하게 할 수도 있다.
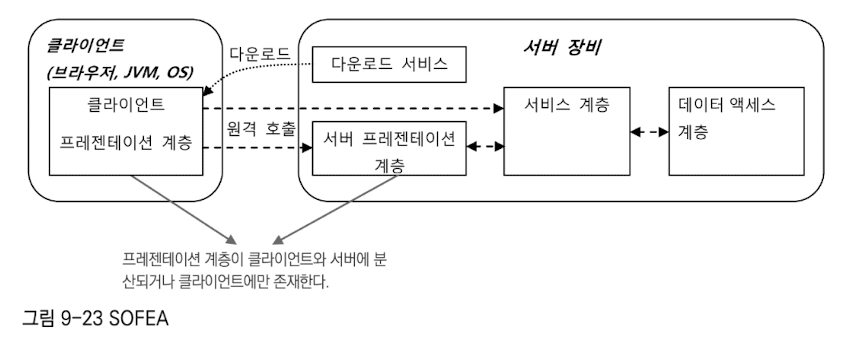
SOFEA (Service Oriented Front End Architecture)프레젠테이션 계층의 코드가 서버에서 클라이언트로 다운로드 되어 클라이언트 장치 안에서 동작하며 서버에 존재하는 프레젠테이션 계층이나 서비스 계층과 통신하는 구조 상태 관리와 빈 스코프아키텍처 설계에서 한 가지 더 신경 써야 할 사항은 상태 관리다. 애플리케이션은 하나의 HTTP 요청의 범위를 넘어서 유지해야 하는 상태정보가 있다.
어떤 식으로든 애플리케이션의 상태와 장시간 진행되는 작업정보는 유지돼야 한다. 스프링은 기본적으로 상태가 유지되지 않는 빈과 객체를 사용하는 것을 권장한다.
|

스프링이란 무엇인가?스프링의 정의
애플리케이션 프레임워크
경량급
자바 엔터프라이즈 개발을 편하게
오픈소스
스프링의 목적8.2.1 엔터프라이즈 개발의 복잡함
복잡함의 근본적인 이유
복잡함을 가중시키는 원인
8.2.2 복잡함을 해결하려는 도전제거될 수 없는 근본적인 복잡함
실패한 해결책: EJB
비 침투적인 방식을 통한 효과적인 해결책: 스프링
8.2.3 복잡함을 상대하는 스프링의 전략기술적 복잡함을 상대하는 전략
비즈니스 애플리케이션 로직의 복잡함을 상대하는 전략
8.3 POJO 프로그래밍
8.3.1 스프링의 핵심: POJO
8.3.2 POJO란 무엇인가?
8.3.3 POJO의 조건
진정한 POJO란 객체지향적인 원리에 충실하면서 환경과 기술에 종속되지 않고 필요에 따라 재활용 될 수 있는 방식으로 설계된 오브젝트를 말함. 그런 POJO에 애플리케이션의 핵심 로직과 기능을 담아 설계하고 개발하는 POJO 프로그래밍이라고 함. 8.3.4 POJO의 장점
8.3.5 POJO 프레임워크
8.4 스프링의 기술
8.4.1 IoC/ DI
8.4.2 AOPAOP 적용 기법
8.3.4 포터블 서비스 추상화 (PSA)
스프링이 어떻게해서 엔터프라이즈 개발이 주는 복잡함을 제거하고, POJO 프로그래밍이라는 효과적인 방법을 사용할 수 있게 하는지에 관심을 갖는 것이 스프링을 가장 빠르게 이해하고 적용할 수 있는 지름길 |
The text was updated successfully, but these errors were encountered: