Experiments and observations using LangChain with sft models (Tools/Data retrieval) #2193
Comments
|
And this is a prompt that I used when I needed to get tool usage with small models, which does not work with langchain, but it's also not great below 13B params: |
|
this is awesome. I love your idea around dataset generation |
|
Something like this should be considered also. So that in the future we can support those community-created plugins for oai models as well. |
|
This is awesome! Would love to contribute if you open up any issues in the future |
|
Hi @draganjovanovich I am working on converting MOSS dataset which include : Calculator, Search, Text-to-Image and Equation solver for OA format. I might need the dataset format for SFT on tool using, have you decided yet? For now I think the section the model need to learn is Thought, Action-Action Input and Response, the Answer Observation was masked from loss |
|
Please check out my PR for the plugin system, and read plugins.md, and afterward, maybe would be best for us to make a short discord call ? |
|
Is there still work to do where I and my team can help? |
|
Hi, thanks for reaching out. We are now incorporated a simple MVP of a plugin system into the production, this was relevant PR #2765 To see how plugins currently are implemented relevant files are in ./inference/worker/chat_chain* and also plugins.md file for now could be helpful. |
|
Hi, for anyone interested this can be run with 4bit GPTQ quantized 30B models like so: import os
import datetime
# /conda/envs/oasst/bin/pip install gradio
import gradio as gr
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
from transformers import AutoTokenizer, pipeline
from langchain import HuggingFacePipeline, LLMMathChain
from langchain.agents import Tool, initialize_agent
from langchain.memory import ConversationBufferMemory
from langchain.utilities import GoogleSearchAPIWrapper, PythonREPL
# HERE YOU DEFINE ENV VARS FOR TOKENS, AND API KEYS
quantized_model_dir = "/data/models--TheBloke--OpenAssistant-SFT-7-Llama-30B-GPTQ"
tokenizer = AutoTokenizer.from_pretrained(quantized_model_dir, use_fast=True)
hf_config = quantize_config = BaseQuantizeConfig(
bits=4, # quantize model to 4-bit
group_size=128, # it is recommended to set the value to 128
)
model = AutoGPTQForCausalLM.from_quantized(quantized_model_dir, device="cuda:0", use_triton=False,
quantize_config=quantize_config, use_safetensors=True,
model_basename="OpenAssistant-30B-epoch7-GPTQ-4bit-1024g.compat.no-act-order")
"""
# TODO: better to use explicit default pipeline?
from transformers import TextGenerationPipeline
pipeline = TextGenerationPipeline(model=model, tokenizer=tokenizer)
print(pipeline("auto-gptq is")[0]["generated_text"])
"""
pipe = pipeline("text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
top_k= 50,
temperature=0.0,
repetition_penalty = (1/0.83),
)
llm = HuggingFacePipeline(pipeline=pipe)
#TODO: /opt/miniconda/envs/text-generation/lib/python3.9/site-packages/langchain/chains/llm_math/base.py:50: UserWarning: Directly instantiating an LLMMathChain with an #llm is deprecated. Please instantiate with llm_chain argument or using the from_llm class method.
llm_math_chain = LLMMathChain(llm=llm, verbose=True)
# TODO: google API key not available
#search = GoogleSearchAPIWrapper()
python_repl = PythonREPL()
tools = [
Tool(
name="Calculator",
func=llm_math_chain.run,
description="useful for when you need to answer questions about mathematically related topics\nUSE ONLY FOR MATH RELATED QUESTIONS!"
),
Tool(
name="Python REPL",
func=python_repl.run,
description = "A Python shell. Use this to execute python commands. "
"Input should be a valid python command. "
"If you want to see the result, you should print it out "
"with `print(...)`."
)
]
tool_names = [tool.name for tool in tools]
PREFIX = """Consider that you are AI Assistant named AI, AI is designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, Assistant is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.
Assistant is constantly learning and improving, and its capabilities are constantly evolving. It is able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. Additionally, Assistant is able to generate its own text based on the input it receives, allowing it to engage in discussions and provide explanations and descriptions on a wide range of topics.
Overall, Assistant is a powerful tool that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether you need help with a specific question or just want to have a conversation about a particular topic, Assistant is here to assist.
You love to answer questions and you are very good at it.
Assistant has access to the following tools:"""
INSTRUCTIONS = """
To use a tool, please use the following format:
``
Thought: Should I use a tool? Yes
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
``
When you have a response to say to the Human, or if you do not need to use a tool, you MUST use the format:
``
Thought: Should I use a tool? No
AI: [your response here]
``
"""
SUFFIX = """
CHAT HISTORY:
{chat_history}
Current time: {current_time}
Knowledge date cutoff: 2021-09-01
When answering a question, you MUST use the following language: {language}
Begin!
Question: {input}
Thought: Should I use a tool?{agent_scratchpad}"""
memory = ConversationBufferMemory(memory_key="chat_history",# return_messages=True,
input_key="input", output_key='output', ai_prefix='AI', human_prefix='User')
agent = initialize_agent(tools,
llm,
agent="conversational-react-description",
verbose=True,
memory=memory,
return_intermediate_steps=False,
agent_kwargs={'input_variables': ['input', 'agent_scratchpad', 'chat_history', 'current_time', 'language'],
'prefix': PREFIX,
'format_instructions': INSTRUCTIONS,
'suffix': SUFFIX})
agent.agent.llm_chain.verbose=True
depth = 0
def main():
with gr.Blocks() as app:
chatbot = gr.Chatbot(elem_id="chatbot")
state = gr.State([])
with gr.Row():
msg = gr.Textbox(show_label=False, placeholder="Enter text and press enter").style(container=False)
def user(user_message, history):
if history is None:
history = ""
return "", history + [[user_message, None]]
def bot(history):
global depth
depth += 1
prompt = history[-1][0]
res = agent({"input":prompt,
"current_time":datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"language": "English"})
response = res['output']
history[-1][1] = response
# free up some memory if we have too many messages
if depth > 8 or len(memory.buffer) > 512:
memory.chat_memory.messages.pop(0)
return history
msg.submit(user, [msg, chatbot], [msg, chatbot], queue=False).then(
bot, chatbot, chatbot)
app.queue()
app.launch(share=False, server_name="0.0.0.0")
if __name__ == "__main__":
main() |
|
Closing this now we have the plugins system but if there are other parts of it which could be separated out into their own smaller issues feel free to do this |
I have been experimenting with LangChain and my own "Tool usage for LLMs" pipeline for a while now, so here I will show some of my experiment results, observations, and ideas, so we can decide if we want to include something similar in the OA as well.
So from my experience, if we want tools/plugins to be reliable we need a model that will be able to strictly follow the instructions and patterns.
Currently, without any real struggle, I was able to use only llama_30b_sft. All others are failing on the second and often on the first question asked by the prompter.
btw, for regular Q/A without tools and CoT requirements llama_13b_sft seems also fineish...
Of course with the "clever" prompting there is a chance for currently available smaller models to perform better, but I would not recommend it, because they just do not behave "smart" enough.
What I see as a possibility for the usage of smaller models with tools, is that we could prepare such a dataset/s for sft/RLHF, which will help them get better in CoT and follow complex rules and instructions.
For now, it seems like the bottom threshold that we could try is 13B.
All of the statements that I have made are based not only on testing and experimenting with LangChain, but with my custom promptings and helpers (You maybe saw those examples in https://discord.com/channels/1055935572465700980/1067096888530178048 ), to guide the models, in the "right" direction.
model best performed with the following agent:
conversational-react-description
and it will be great if we can achieve to perform well with
zero-shot-react-description also.
Small pseudo/snippet code of custom usage of LangChain with huggingface models:
What I see as useful for OA is that we can use this kind of stuff for:
Some demos:
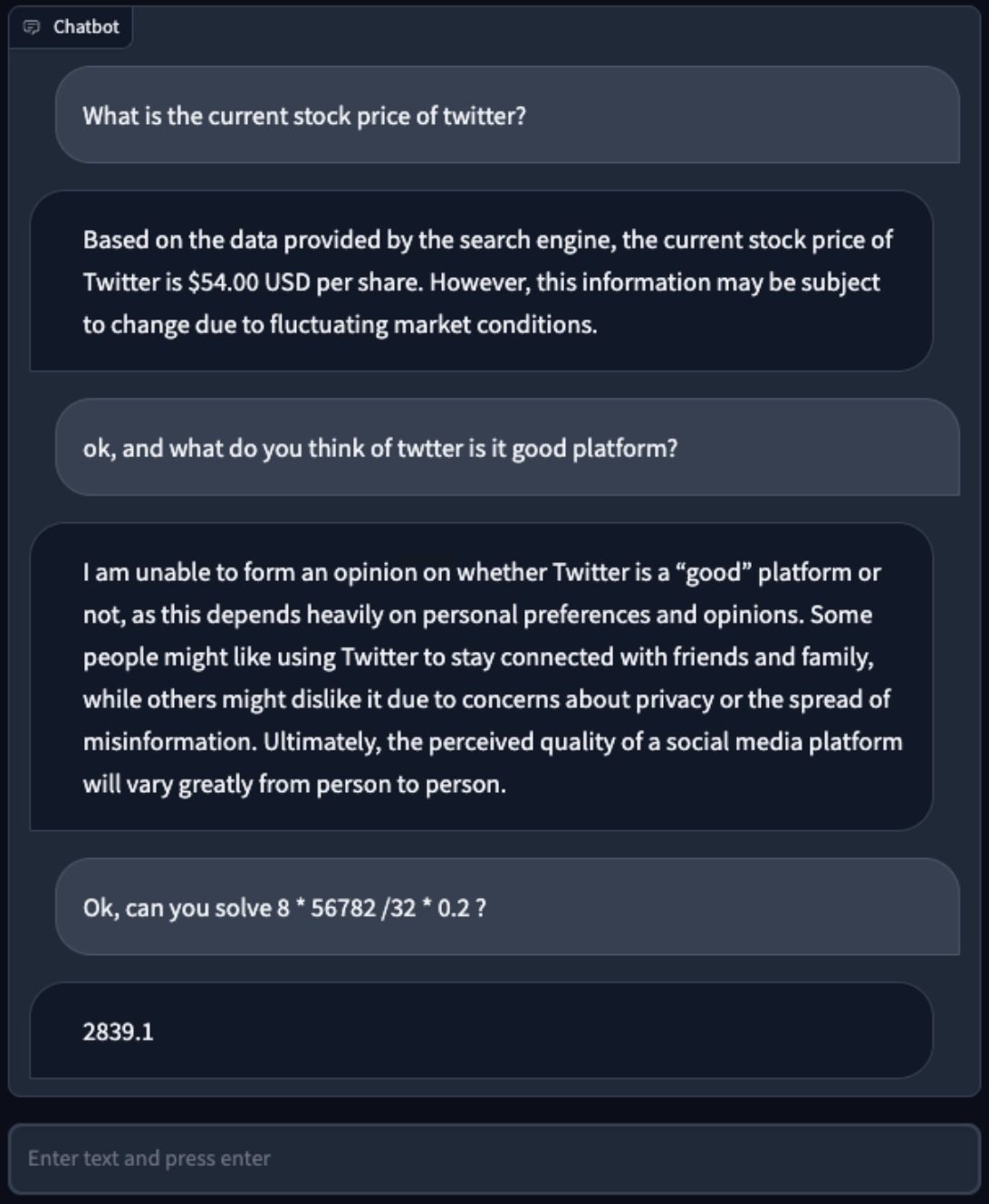
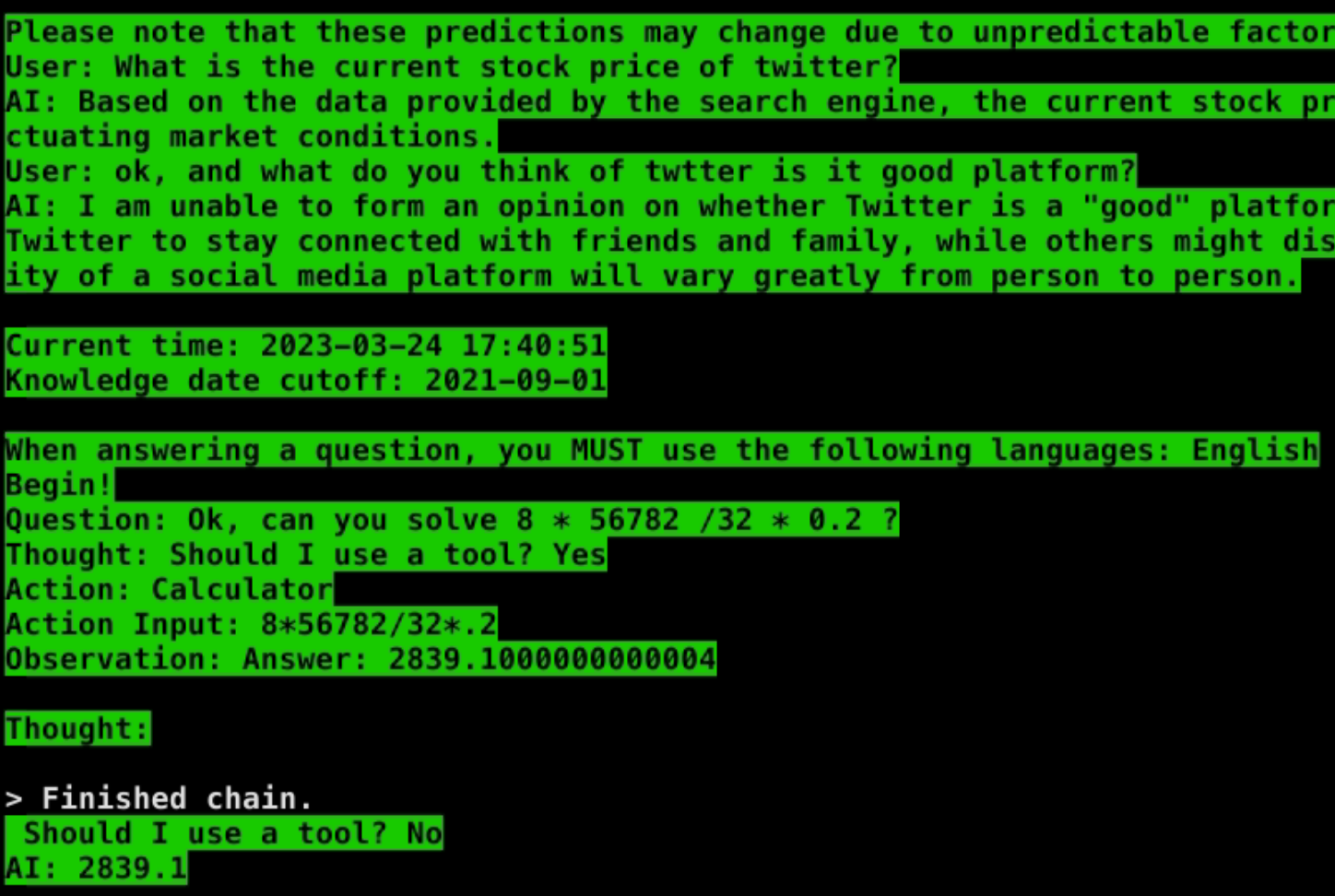
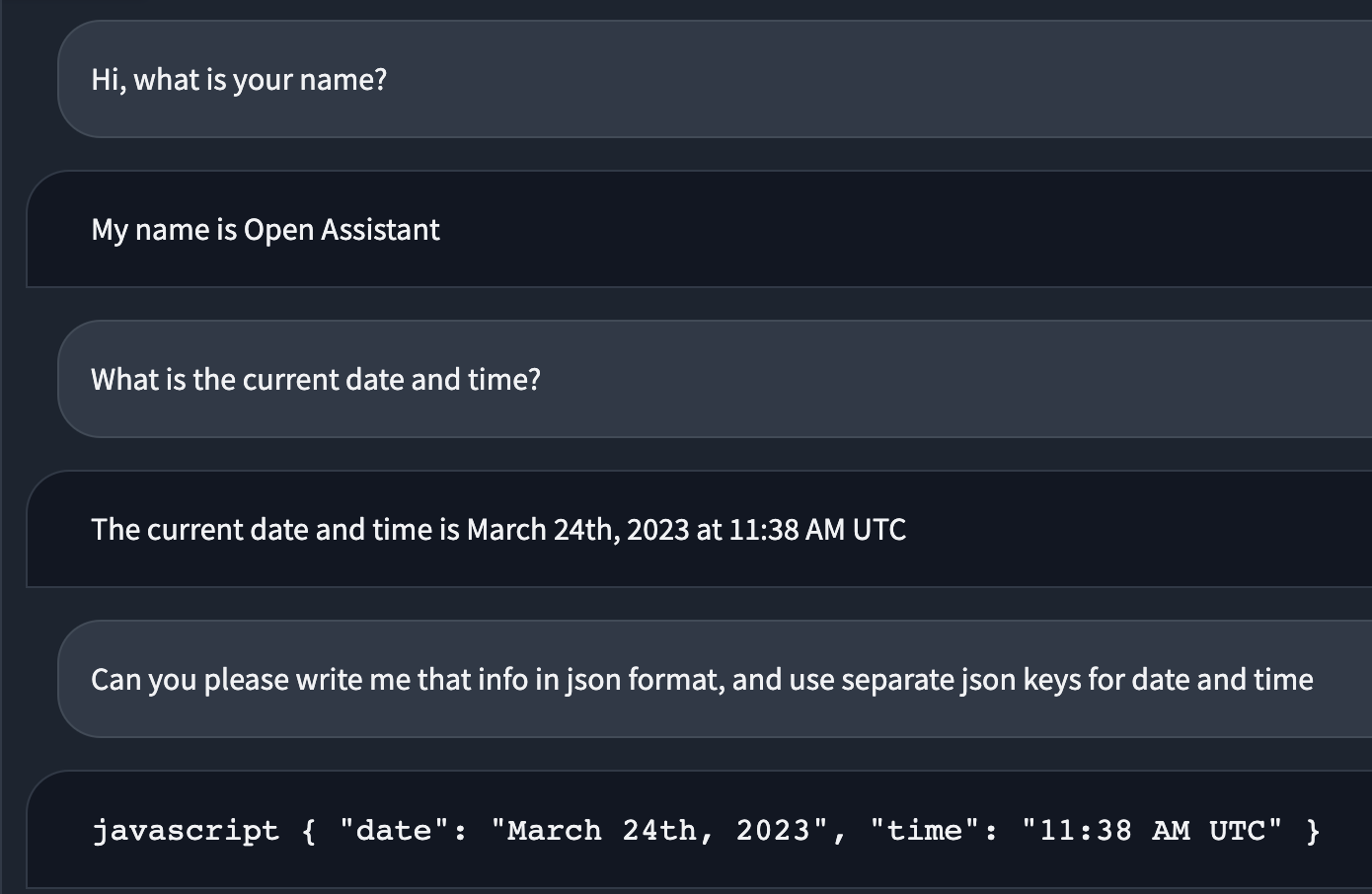
Some background stuff
In this last demo, model generated correct code blocks, but gradio messed up render.
prompt used in most cases when i was trying smaller models, that are unable to follow LangChain patterns:
https://pastebin.pl/view/3541703a
NEW DEMO EXAMPLES: (Added Vision tool)
Vision tool, is just basically laions-coca model + ocr, but it helped llama to generate some interesting comments :)
The text was updated successfully, but these errors were encountered: